ChatGPT Code Interpreter(ADA)的力量:不写一行代码也能完成数据可视化

多年来,“会不会写代码”一直是把原始数据变成有价值洞见的最大门槛。而随着 ChatGPT Code Interpreter 更名为 Advanced Data Analysis(ADA) 并持续集成在 ChatGPT 中,这道门槛被大幅降低。
它的核心价值很直接:你上传文件,描述想看的指标、图表或分析步骤,ChatGPT 就会在内置的 Python 环境里完成清洗、计算、绘图和导出。
你可以把它理解为:一个完整的数据分析环境——Python、可视化库、文件上传、数据清洗工具——直接嵌入在 ChatGPT 里。
如果你只想先抓重点:ADA 非常适合快速上传文件做一次性分析;但如果你的真实工作长期发生在 Jupyter、已有 kernel、本地文件和私有数据环境中,那么把 AI agent 直接带进 notebook 往往会更顺手。
- Runcell Science:面向科研的开源 Claude Science 替代方案
- Mac 怎么不休眠:合盖继续运行 Codex、Claude Code 和本地 AI Agent
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot:2026 年该选哪个 AI Agent 技术栈?
- Claude Code 能分析 Jupyter Notebook 吗?Data Science 场景下它到底做了什么
- Claude Code Routines 是什么?AI Agent 定时任务与自动触发指南
- Claude Code Desktop 绕过权限:如何开启 Bypass permissions
- 如何用 Google 的 A2A 协议构建两个 Python Agent:一步步教程
- 2025 年 Python 增长最快的 10 个数据可视化库
用 ChatGPT Code Interpreter 简化数据可视化
在大数据时代,把数据转化为可视化洞见至关重要。但传统工具往往需要:
- 导出数据
- 编写 Python 或 SQL
- 调试脚本
- 配置图表库
对非技术背景的用户来说,这几乎是“劝退式”流程。
这正是 ChatGPT Code Interpreter(ADA) 颠覆之处。它可以:
- 读取 CSV、Excel、JSON、PDF 等多种格式
- 自动清洗和预处理数据
- 在安全沙箱中运行 Python 代码
- 生成高质量图表(Matplotlib、Seaborn、Plotly)
- 将结果导出为图片或可下载文件
以上全部只需使用自然语言。
示例:
你希望可视化某产品在不同时间段的营收。传统做法要写 SQL 或 Python。
在 ADA 中,你只需要说:
“Create a bar chart showing revenue by product for 2024 Q1 using the file I uploaded.”
剩下的事情——数据解析、作图、坐标轴格式、美化标签以及导出结果——都交给 ChatGPT 完成。

这不仅适用于柱状图,同样适用于:
- 折线图
- 散点图
- 热力图
- 交互式可视化
- 统计图(直方图、箱线图、回归图等)
就像随时拥有一位 私人数据分析师 一样。如果你想进一步了解 ChatGPT 在分析场景里的延伸能力,也可以继续看 GPT-4 对数据分析意味着什么。
如果你喜欢 ADA 的体验,但想把 AI 带回自己的 Jupyter 环境
ADA 把“描述需求 -> 生成代码 -> 执行 -> 查看结果”压缩成了一次对话,这就是它最吸引人的地方。但对很多分析师和数据科学家来说,真正的日常工作并不在 ChatGPT 的独立沙箱里,而是在自己的 notebook、已有依赖、本地文件和私有数据环境中。
这也是 RunCell (opens in a new tab) 会显得特别相关的原因。RunCell 本身就是一个运行在 Jupyter 环境里的 AI Agent:它理解 notebook 上下文、DataFrame、历史 cell 和当前变量状态,让你把类似 ADA 的自然语言分析体验带回更 native 的工作流里。
RunCell:把 AI Agent 直接带进你的 Jupyter Notebook→对比下来,两者更适合的场景通常是这样的:
| 需求 | ADA | RunCell |
|---|---|---|
| 上传一个文件,快速做一次性分析 | 更方便 | 也能做,但不是核心优势 |
| 直接利用已有 notebook、kernel、变量状态继续工作 | 有限 | 更适合 |
| 在 Jupyter 里持续迭代 DataFrame、图表和代码单元 | 一般 | 更强 |
| 希望工作流更接近本地或私有数据环境管理 | 相对间接 | 更自然 |
如果你的主要工作本来就发生在 notebook 中,可以继续看 AI Agent 将 Jupyter Notebook 变成数据科学“副驾驶”;如果你还在比较更多 AI 编程工具,也可以参考 2026 年 15 款最佳 AI 编程工具。
ChatGPT Code Interpreter(ADA)如何改变“写代码”这件事
在 ADA 出现之前,用户必须:
- 懂 Python
- 安装各种依赖库
- 管理运行环境
- 排查和调试报错
现在,用户只需要 用语言描述 自己想要的结果。
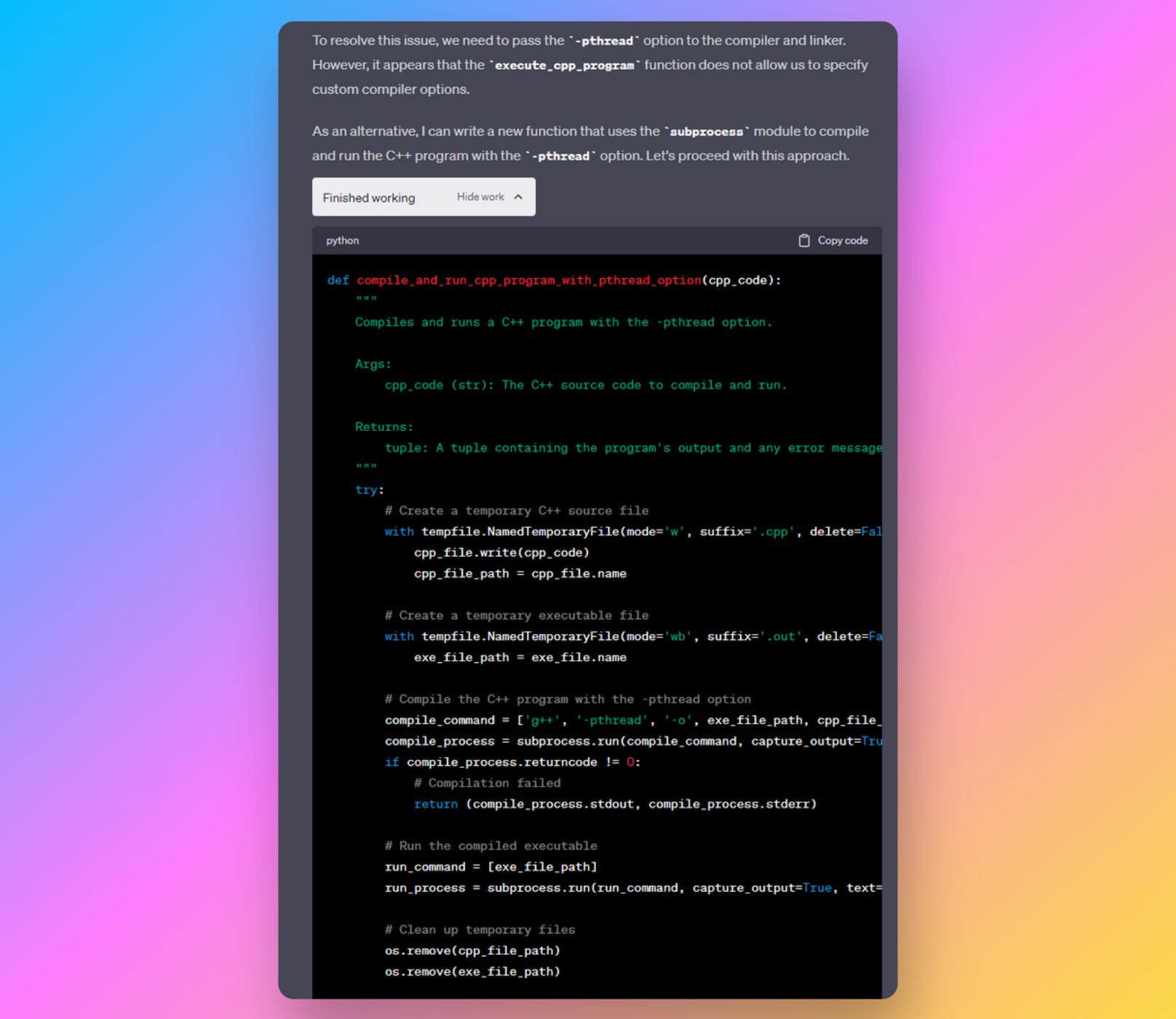
ADA 能把自然语言转成可执行代码,并自动处理:
- 数据清洗
- 数据转换
- 统计建模
- 回归分析
- 聚类分析
- 可视化绘图
全部自动完成。
它打通了 技术能力 和 分析创意 之间的鸿沟,让从市场人员到学生在内的任何人,都能在不具备编程技能的前提下完成高质量分析。对话式分析的门槛被拉低之后,接下来的区别就在于:你是要在 ChatGPT 里快速完成任务,还是要把这套交互方式迁移到自己的原生工作流里。
ChatGPT Code Interpreter 在数据可视化中的真实应用案例
示例 1:描述性分析 + 可视化
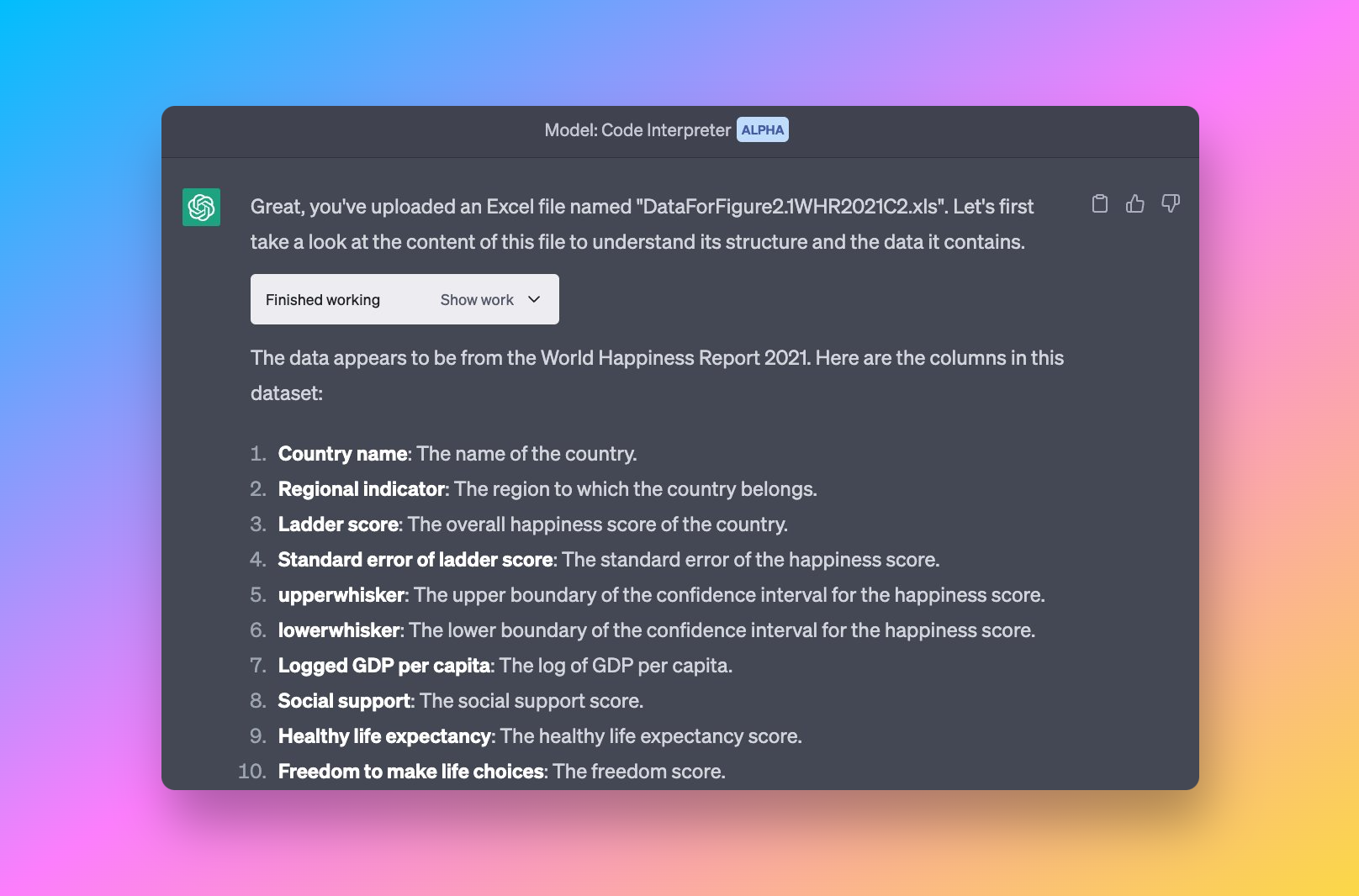
Ethan Mollick 上传了一个 XLS 文件,并向 ADA 提问:
- “Give me descriptive statistics.”
- “Visualize key patterns.”
- “Run regressions and diagnostics.”
模型自动生成了:
- 描述性统计汇总表
- 直方图
- 散点图
- 回归结果
- 分析解读和说明
这展示了 ADA 仅通过自然语言就能完成多步骤分析的能力。
示例 2:敏感性分析 + 自适应问题求解
即便在中途会话状态丢失的情况下,ADA 仍然可以重建分析逻辑,体现出它可以:
- 在数据缺失时进行推理
- 重新推导中间步骤
- 在不“推倒重来”的前提下继续分析
这很好地展示了 ADA 在真实复杂工作流中的稳健性。
示例 3:UFO 目击事件热力图可视化
面对一份混乱的原始数据集,ADA 能够自动完成清洗,并生成:
- 热力图
- 地理可视化
- 异常值检测结果
只需要一条指令即可完成。
这些案例共同说明:ADA 正在把复杂的分析流程,变成简单的“对话式工作流”。
如何使用 ChatGPT Code Interpreter(ADA)做数据可视化
上手流程非常简单:
- 上传你的数据集(CSV、Excel、JSON、TSV、PDF 表格、ZIP 压缩包等)。
- 用自然语言描述需求,例如:
“Create a scatter plot of price vs. quantity for each category.”
- ADA 自动完成数据解析、作图和导出。
- 通过继续对话提出追问,迭代优化结果。
不需要写代码,不需要在多个工具之间来回切换,也不需要复杂的环境配置。
因此,ADA 尤其适合:
- 分析投放效果的市场人员
- 调研公共数据集的记者
- 做课题/论文数据分析的学生
- 复盘指标的业务团队
- 希望更快搭建图表/报告的分析师
如果你的工作更偏报表、BI 和业务展示,也可以结合阅读 AWS 数据可视化指南 或 Airtable 图表指南。
ChatGPT Code Interpreter(ADA)的典型使用场景
ADA 可以完成:
✔ 探索性数据分析(EDA)
- 描述性统计
- 缺失值检测
- 相关性热力图
✔ 数据可视化
- 各类图表(Matplotlib、Seaborn、Plotly、Altair)
- 各种统计图
- 时间序列可视化
✔ 数据清洗
- 去重
- 类型纠正
- 异常值检测
✔ 数据科学任务
- 回归建模
- 聚类分析
- 预测与时间序列
- 特征工程
✔ 文件自动化处理
- CSV → Excel 转换
- 多文件合并
- 从 PDF 中提取表格
它相当于一个完整的数据科学工具箱,却可以通过自然语言来操作。
ChatGPT Code Interpreter(ADA)与机器学习
ADA 由机器学习模型驱动,能够:
- 理解用户意图
- 生成 Python 代码
- 检查运行结果
- 自动纠错
- 持续迭代直到得到合理结果
这种机制构成了一个类似人类分析师的“反馈闭环”。
想进一步了解 ADA 背后的技术原理,可以阅读 Nature 的这篇报道 (opens in a new tab)。
对话式分析的下一步:从云端沙箱走向原生工作流
像 ADA 这样的工具,将以下几种模式融合在一起:
- 无代码
- 低代码
- 传统编程
- AI 驱动的推理能力
用户不再需要手动写代码,而是用语言描述任务,让 AI 即时生成并执行优化后的代码。
这正在加速整个 无代码 / AI 辅助分析 浪潮——让每个人都能真正“用得起数据”。
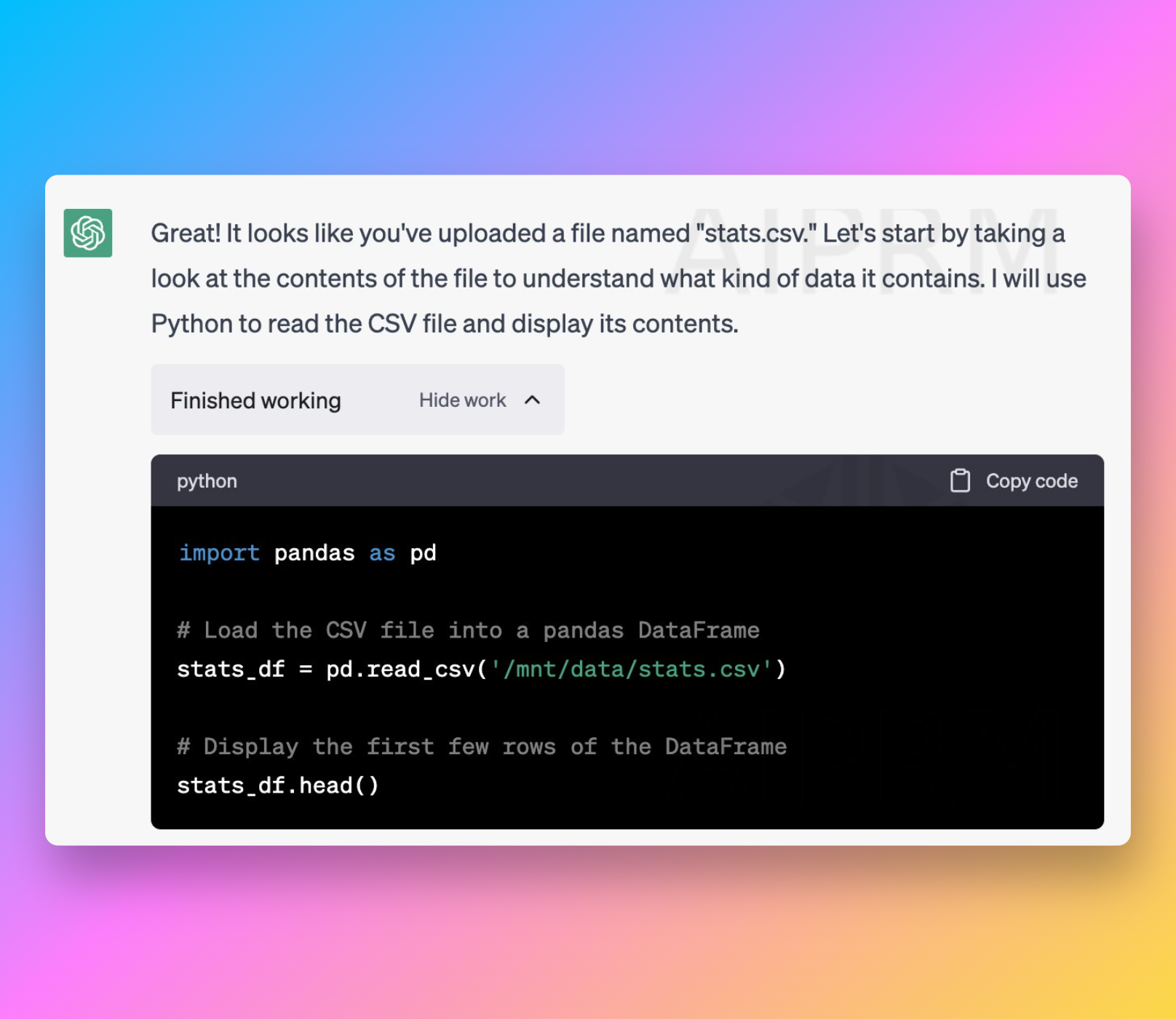
但更重要的变化是,很多用户已经不满足于“在一个独立的云端分析环境里偶尔跑一次任务”。他们更希望把 AI 能力放回自己真正工作的地方,例如 Jupyter Notebook、本地数据目录、现有 Python 依赖和团队内部数据流程。
这正是 RunCell 这类 notebook-native AI agent 的意义所在。ADA 证明了“自然语言 + 执行环境”这条路是有效的;RunCell 则把这条路延伸到了更原生、更连续、也更接近私有数据工作流的 Jupyter 环境里。
如果你主要在 notebook 中做实验、EDA 和迭代分析,这种方式通常会比把任务拆到独立云端会话里更顺手。想进一步比较 notebook 工具本身,也可以看 Top 10 Data Science Notebooks。
Related Guides
- AI Agent 将 Jupyter Notebook 变成数据科学“副驾驶”
- 2026 年 15 款最佳 AI 编程工具
- GPT-4 对数据分析意味着什么
- AWS 数据可视化指南
- Top 10 Data Science Notebooks
常见问题(FAQ)
什么是 ChatGPT Code Interpreter(ADA)?
它是集成在 ChatGPT 内部的、由 AI 驱动的 Python 执行环境,允许用户用自然语言进行数据分析并生成可视化图表。
我该如何使用它?
上传文件 → 用自然语言描述想做的分析 → 收到图表、摘要和代码执行结果。
它支持什么编程语言?
主要支持 Python,并完整支持 Pandas、Matplotlib、Seaborn、Plotly、NumPy、Scikit-Learn 等数据与可视化库。
它是免费的吗?
通常不是。ADA 一般包含在支持 Advanced Data Analysis 的付费 ChatGPT 计划中,具体可用范围以 OpenAI 当前套餐说明为准。
如果我暂时用不了,能有什么替代方案?
如果你只是想快速上传文件并让 AI 帮你分析,ADA 依然是很直接的入口;但如果你希望在 本地 Jupyter 环境、已有 notebook 和更接近私有数据工作流的前提下引入 AI agent,那么可以试试 RunCell (opens in a new tab)。
总结
ChatGPT Code Interpreter(ADA)正在改变人们和数据打交道的方式。通过将自然语言交互与强大的 Python 执行能力结合,ADA 极大降低了数据可视化、分析和自动化的技术门槛。
无论你是刚接触数据的新手,还是希望加速工作流程的专业分析师,ADA 都能提供一种更快、更简单、更直观的路径,把数据转化为洞见。而如果你的核心工作流已经在 Jupyter 中,像 RunCell 这样的 notebook-native AI agent 往往会是更自然的下一步。