Claude Code 能分析 Jupyter Notebook 吗?Data Science 场景下它到底做了什么

Claude Code 可以分析 Jupyter Notebook,但它的方式和很多数据科学用户想的不一样。它并不是一个真正理解当前 kernel、变量状态和最新输出的 notebook-native agent。更准确地说,它主要是在把 .ipynb 当成一种结构化文件来读取、总结和编辑。
这个区别非常重要。对普通软件工程任务来说,文件级理解很多时候已经够用;但对 Data Science 来说,notebook 的价值恰恰来自运行状态、DataFrame 内容、图表输出和实验过程。如果工具只理解文件,不理解状态,那它就只能理解工作流的一部分。
如果你想继续沿着这个话题往下读,可以先看 Jupyter AI RunCell、如何用 Codex 处理代码任务、以及 如何把 .ipynb 转成 HTML。
直接结论
| 问题 | 简短答案 |
|---|---|
| Claude Code 能打开 Jupyter Notebook 吗? | 能 |
| 能总结 cell 和已保存输出吗? | 能 |
| 能按 cell 编辑 notebook 吗? | 能 |
| 能运行 cell 或控制 kernel 吗? | 不能 |
| 能读取实时变量和 DataFrame 吗? | 不能算真正支持 |
| 够不够做完整的 Data Science notebook 工作流? | 通常不够 |
Claude Code 在 Notebook 里擅长什么
当 notebook 被当成“需要阅读和整理的文档”时,Claude Code 是有价值的。
比较适合的任务包括:
- 按章节总结 notebook 在做什么
- 解释每个 cell 的作用
- 把混乱的 pandas 处理逻辑改写得更清楚
- 补齐 markdown 说明
- 删除冗余 cell 或拆分超长 cell
这让它适合 notebook review、结构清理和内容重构,但不等于它适合继续接管一个正在运行的分析流程。
Claude Code 实际上是怎么处理 Notebook 的
结合源码调研,Claude Code 主要有两类 notebook 能力:
- 通过 notebook-aware 的读取路径处理
.ipynb - 通过
NotebookEdit之类的能力按 cell 编辑 notebook
但它的边界始终在文件层。
1. 它读取的是 notebook JSON,不是 Jupyter 的实时环境
Claude Code 在遇到 .ipynb 时,会解析 notebook JSON,提取 cells 和已保存 outputs,再把这些内容整理成模型更容易消费的结构。
它没有做很多 Data Science 用户真正想要的事情:
- 不控制 Jupyter kernel
- 不直接管理 Jupyter server
- 不读取 live variables
- 不执行 cell
- 不负责 restart / rerun
所以一个输出如果已经过期,它并不知道。一个输出如果已经被清空,它也只能看到剩下的代码和 markdown。
2. 它按 cell 编辑 notebook,但本质上还是在改文件
Claude Code 的 notebook 编辑不是简单的字符串替换。它可以按 cell 插入、替换、删除内容,也会在代码改变时清掉旧输出。
这说明它确实“懂 notebook 文件结构”,但不代表它已经“进入 Jupyter 的运行时”。它更像一个知道 .ipynb 长什么样的文件编辑器,而不是一个真正继续执行 notebook 的 agent。
3. 最重要的判断
这篇调研最核心的结论可以压缩成一句话:
Claude Code 理解的是 Jupyter Notebook 的文件结构,而不是 Jupyter 的运行时结构。
为什么这对 Data Science 特别重要
在数据科学工作流里,难点通常不只是“Python 语法怎么写”。真正难的是:
- 当前到底是哪一个 DataFrame 在生效
- 某个结果来自旧数据还是新数据
- 上游 schema 一改,后面哪些 cell 会一起坏掉
- 图表是否真的反映了当前实验状态
- 这个 notebook 的执行顺序是否还能复现
这也是为什么很多通用 software engineering agent 在 notebook 场景里会显得“能看,但不够顺手”。它们可以帮你读懂 notebook 文件,却不一定能帮你完成 notebook 工作。
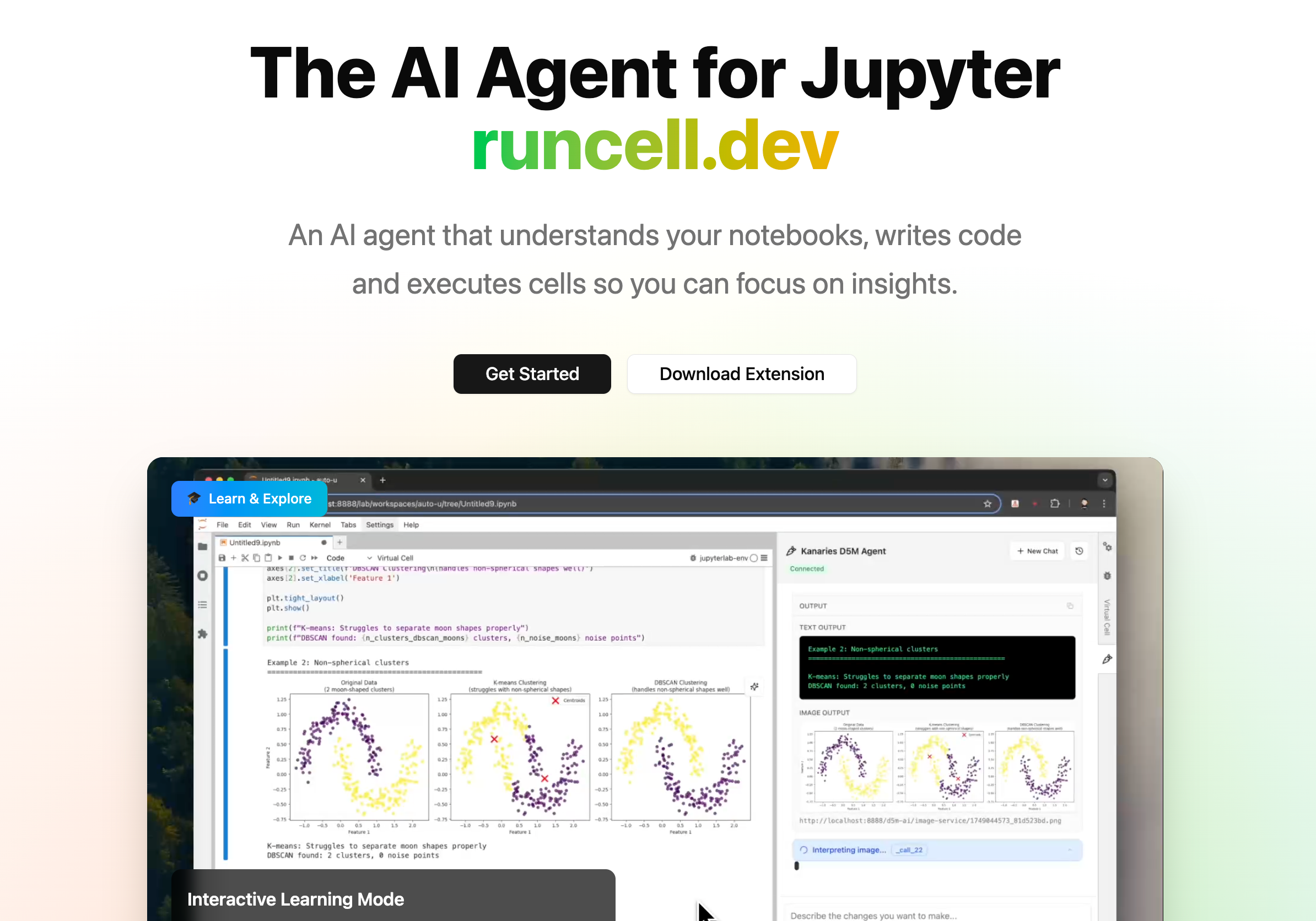
RunCell 更适合真正的 Jupyter Data Science 工作流
这正是 RunCell (opens in a new tab) 应该出现的位置。
Claude Code 能看 .ipynb,也能改里面的 cell,这一点没问题。
但对很多数据科学用户来说,麻烦本来就不只是“把代码改掉”。
真正让人头疼的,通常是这些事:
- notebook 已经跑到一半了,前面哪些 cell 执行过,哪些没执行过,很容易乱
- 你现在看到的图,到底是不是基于最新数据跑出来的,不一定说得清
- 上游改了一个字段名,后面十几个 cell 可能都会受影响
- agent 能帮你改代码,但不一定知道你当前到底在分析哪一步
这也是为什么,很多通用 coding agent 看起来“能处理 notebook”,但真用到 Jupyter 工作流里时,总会差一点。它能读文件,但不一定真的明白你这个 notebook 现在是什么情况。
RunCell 不是一个先为软件工程设计、再顺手兼容 .ipynb 的工具。它更像是专门给 Jupyter 和 Data Science 用户做的 AI Agent,重点不只是“会不会改代码”,而是能不能让你少来回切窗口、少手动回头查 cell、少靠猜去判断输出到底对不对。
| 场景 | Claude Code | RunCell |
|---|---|---|
| 读写 notebook 文件 | 可以 | 可以 |
| 围绕 notebook 执行状态工作 | 有限 | 原生适配 |
| 把 DataFrame 和 notebook 上下文当成核心信号 | 有限 | 更强 |
| 根据输出继续迭代分析 | 间接 | 直接 |
| 面向 Data Science notebook 工作流 | 通用 | 更专门 |
如果你的任务是 notebook 审查、结构整理、文档化,Claude Code 已经有帮助。
但如果你平时就在 Jupyter 里做这些事:
- EDA
- 清洗数据
- 调参
- 看图排错
- 一边试一边改 notebook
那 RunCell 往往会更顺手。因为你的目标不是“把一段代码改对”,而是“把这次分析继续做下去”。
如果你已经遇到过这种情况:agent 能帮你改 .ipynb,但改完以后你还是得自己回头检查输出、确认变量、重跑几个 cell,才能知道分析有没有真的接上。那你可以直接试试 RunCell (opens in a new tab)。它更像是在 Jupyter 里面和你一起继续做分析,而不是站在 notebook 外面帮你改文件。
什么时候选 Claude Code,什么时候选 RunCell
更适合 Claude Code 的情况:
- 你要把 notebook 当文件来审查
- 你要重写或整理 cells
- 你要把旧 notebook 提炼成脚本或文档
- 你的主战场仍然是代码库,notebook 只是附属资产
更适合 RunCell 的情况:
- 你的主工作环境就是 Jupyter
- 你在做 EDA、特征工程、建模和可视化
- 你需要 agent 理解 notebook 上下文和执行顺序
- 你希望分析、执行、调试和迭代留在一个工作流里