Comment Claude Code analyse un notebook Jupyter en Data Science : capacités réelles et limites

Claude Code peut lire un notebook Jupyter, le résumer et le modifier. Mais il ne fonctionne pas comme un agent natif de Jupyter qui voit le kernel actif, les variables courantes ou l’état réel d’exécution. En pratique, Claude Code traite surtout un .ipynb comme un fichier structuré.
Pour l’ingénierie logicielle classique, cela peut suffire. Pour la data science, c’est souvent insuffisant. L’ordre d’exécution, les DataFrames, les sorties de cellules et l’état de l’expérience sont au cœur du travail notebook.
Pour approfondir, tu peux aussi lire Python Notebook, JupyterLab vs Notebook et Jupyter AI avec RunCell.
Réponse rapide
| Question | Réponse |
|---|---|
| Claude Code peut-il ouvrir un notebook Jupyter ? | Oui |
| Peut-il résumer les cellules et les sorties enregistrées ? | Oui |
| Peut-il modifier les cellules ? | Oui |
| Peut-il exécuter des cellules ou piloter le kernel ? | Non |
| Peut-il voir les variables live et l’état courant ? | Pas comme un vrai outil runtime |
| Suffit-il pour un workflow Data Science complet ? | En général non |
Ce que Claude Code fait bien dans un notebook
Claude Code est utile pour :
- relire la structure d’un notebook
- expliquer le rôle des cellules
- réécrire du code pandas peu lisible
- améliorer les blocs markdown
- supprimer ou découper des cellules redondantes
Il est donc pratique pour l’audit, le nettoyage et la restructuration. Il l’est beaucoup moins pour prolonger un travail interactif déjà en cours dans Jupyter.
Comment Claude Code fonctionne réellement avec un notebook
Claude Code a deux comportements notebook importants :
- lecture spécialisée des fichiers
.ipynb - édition orientée cellules
Mais la frontière reste celle du fichier.
1. Il lit le JSON du notebook, pas le runtime vivant
Claude Code parse le .ipynb, extrait cellules et sorties sauvegardées, puis reformate cela pour le modèle.
En revanche, il ne :
- contrôle pas le kernel
- n’orchestré pas le serveur Jupyter
- n’inspecte pas les variables live
- n’exécute pas les cellules
- ne suit pas un vrai cycle rerun / restart
2. Il modifie les cellules, mais réécrit toujours le fichier
L’édition notebook est meilleure qu’un simple patch texte. Claude Code peut insérer, remplacer ou supprimer des cellules et nettoyer les anciennes sorties après modification du code.
C’est donc une bonne compréhension du format notebook, pas une compréhension native du runtime Jupyter.
Claude Code comprend le fichier notebook, pas l’environnement d’exécution Jupyter.
Pourquoi c’est important en Data Science
En data science, la difficulté n’est pas seulement d’écrire du Python valide. La difficulté est de garder le bon contexte :
- quelles cellules ont déjà tourné
- quel DataFrame est la version active
- si un graphique reflète les données actuelles
- si une modification amont a cassé les étapes aval
C’est là que les agents de code généralistes montrent vite leurs limites dans un notebook.
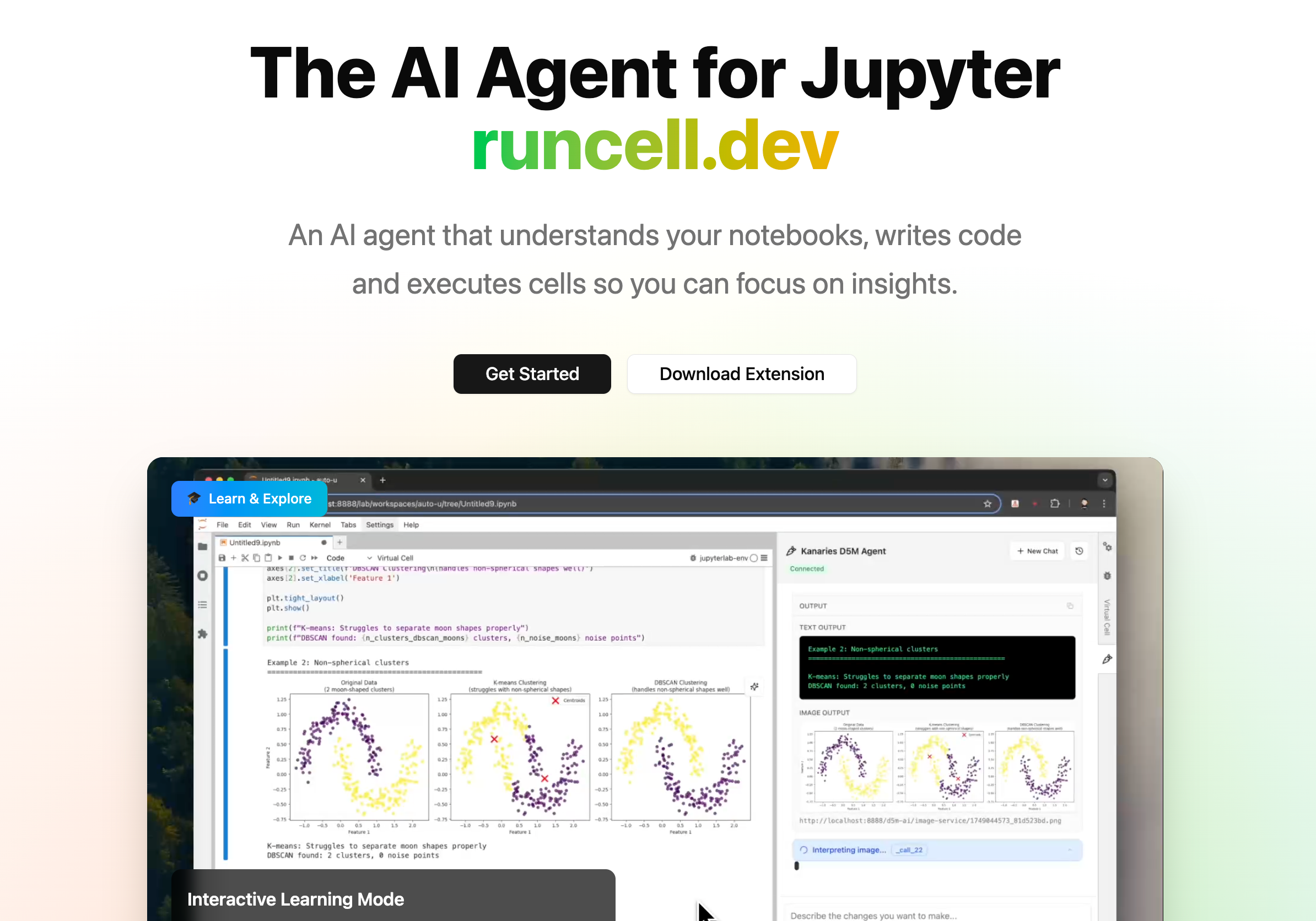
Pourquoi RunCell convient mieux à Jupyter
RunCell (opens in a new tab) devient intéressant ici parce que, pour beaucoup d’utilisateurs de notebooks, le vrai problème n’a jamais été seulement : « est-ce que l’agent peut réécrire du code ? »
Ce qui fatigue vraiment, c’est plutôt ceci :
- le notebook a déjà été exécuté en partie et il faut retrouver quelles cellules sont encore fiables
- le graphique affiché semble bon, mais on ne sait pas tout de suite s’il vient bien des dernières données
- un simple changement de schéma en amont peut casser une longue suite de cellules
- l’agent peut modifier le code, sans forcément comprendre où tu en es réellement dans l’analyse
C’est pour cela qu’un agent de code généraliste paraît souvent presque adapté à Jupyter, sans l’être complètement. Il lit le fichier, mais pas toujours la situation réelle du notebook.
RunCell n’est pas un outil généraliste qui sait aussi ouvrir des .ipynb. C’est un agent IA natif pour Jupyter et la data science. En pratique, cela veut dire moins d’allers-retours, moins de vérifications manuelles cellule par cellule, et moins d’hésitation au moment de savoir si l’output affiché correspond encore à l’analyse en cours.
| Besoin | Claude Code | RunCell |
|---|---|---|
| Lire et modifier des notebooks | Oui | Oui |
| Travailler avec l’état du notebook | Limité | Natif |
| Prendre les DataFrames et cellules comme signal principal | Limité | Plus fort |
| Itérer directement à partir des outputs | Indirect | Direct |
| Vraiment pensé pour les workflows notebook | Généraliste | Spécialisé |
Si tu fais surtout de la revue et du nettoyage, Claude Code peut suffire.
Mais si ton quotidien ressemble plutôt à ça :
- EDA
- nettoyage de données
- feature engineering
- ajustement de modèles
- lecture de graphiques et débogage au fil du notebook
alors RunCell paraît souvent plus naturel. Le vrai objectif n’est pas seulement de « corriger du code », mais de faire avancer l’analyse sans casser le rythme du notebook.
Si tu reconnais ce scénario, la différence devient concrète : l’agent modifie le fichier .ipynb, mais ensuite tu dois encore vérifier les outputs, contrôler les variables et relancer plusieurs cellules avant de faire confiance au résultat. C’est précisément là que RunCell (opens in a new tab) devient l’étape suivante la plus naturelle.