Can Claude Code Analyze Jupyter Notebooks for Data Science? What It Actually Does

Claude Code can analyze a Jupyter notebook, but not in the way many data scientists assume. It does not behave like a notebook-native agent that sees your live kernel, current variables, or the latest execution state. In practice, Claude Code mostly treats a .ipynb as a structured file that it can read, summarize, and edit.
That difference matters. For software engineering work, file-level understanding is often enough. For notebook-heavy data work, it is usually not. Data science depends on execution order, DataFrame contents, chart outputs, and changing experiment state. If you only understand the file, you only understand part of the workflow.
If you want a refresher on the broader notebook context, these guides are useful alongside this one: Python Notebook, JupyterLab vs Notebook, and Jupyter AI with RunCell.
Quick Answer
| Question | Short answer |
|---|---|
| Can Claude Code open a Jupyter notebook? | Yes |
| Can it summarize cells and saved outputs? | Yes |
| Can it edit cells safely? | Yes, at the file level |
| Can it run cells or control the kernel? | No |
| Can it inspect live variables and DataFrames? | Not as a true Jupyter runtime tool |
| Is it enough for full Data Science notebook work? | Usually no |
What Claude Code Is Good At in Jupyter
Claude Code works well when the notebook is treated as a document you want to inspect or reorganize.
Typical good use cases:
- summarize a notebook section by section
- explain what each cell is trying to do
- rewrite messy pandas code into clearer cells
- clean up markdown explanations
- remove redundant cells or split long ones
That makes Claude Code useful for notebook review, notebook cleanup, and turning exploratory work into cleaner artifacts. It is much less compelling when you need the agent to continue a live notebook workflow.
How Claude Code Actually Works with a Notebook
Based on the source-level analysis, Claude Code has two important notebook behaviors:
- it reads
.ipynbfiles through a notebook-aware read path - it edits notebooks through a cell-oriented edit tool
That sounds deep, but the system boundary is still file-first.
1. It reads notebook JSON, not the live Jupyter runtime
Claude Code detects the .ipynb extension, parses the notebook JSON, extracts cells and saved outputs, then repackages that content into a model-friendly structure.
It does not do the runtime-side work many users expect:
- no Jupyter kernel control
- no Jupyter server orchestration
- no live variable inspection
- no cell execution
- no restart / rerun workflow
So if a notebook output is stale, Claude Code cannot tell. If the output was cleared, Claude Code only sees the code and markdown that remain in the file.
2. It edits cells, but it is still rewriting the notebook file
Claude Code's NotebookEdit flow is smarter than a raw string replacement. It can target cells, insert, replace, and delete them, and it clears old outputs when code changes.
That is notebook-aware editing, but it is still file editing. Claude Code is not stepping into the notebook runtime and continuing the analysis from the current state of the kernel.
3. The key conclusion
Claude Code does not really "understand Jupyter" in the runtime sense. It understands the notebook file format well enough to read and restructure it safely.
That is the central distinction:
Claude Code is strong at notebook file understanding and notebook file editing, but it is not a true Jupyter runtime agent.
Why This Matters for Data Science
In data science, the hard part is often not writing Python syntax. The hard part is preserving context across an evolving notebook:
- what order cells were executed in
- which DataFrame is current
- whether an output came from old or new data
- whether upstream schema changes broke downstream logic
- whether a chart reflects the current experiment
That is why notebook support in a general coding agent can feel incomplete. The agent may read the notebook well and still miss the state that determines whether the analysis is actually correct.
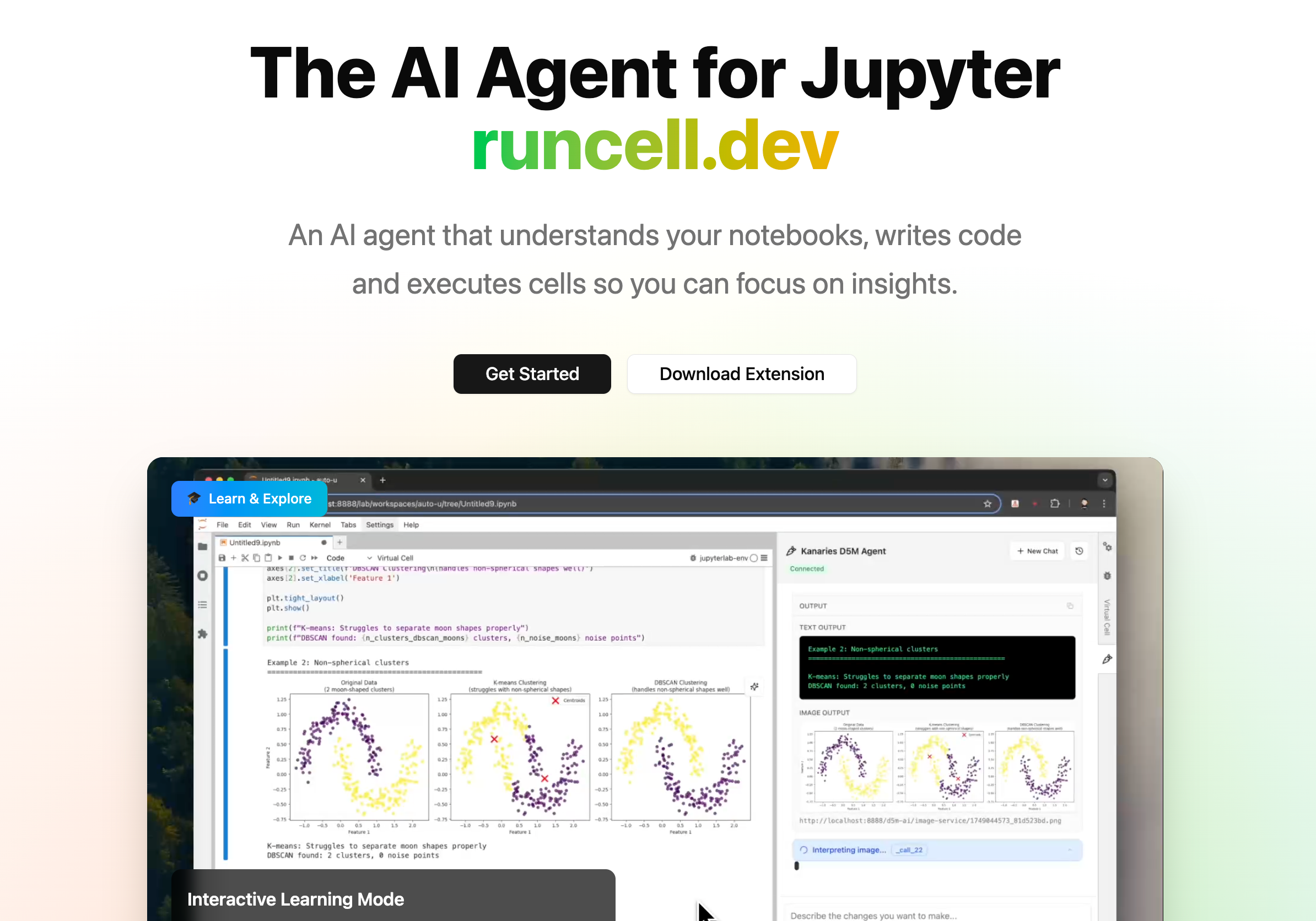
RunCell Is the Better Fit When the Notebook Is the Real Workspace
This is where RunCell (opens in a new tab) should enter the picture.
Claude Code can read .ipynb files and edit cells. That part is real. But for many notebook users, the hard part was never just "change the code."
The annoying part is usually something like this:
- the notebook is already half-run and you need to remember which cells are still trustworthy
- the chart on screen may or may not reflect the latest data
- one upstream schema change can quietly break a long stretch of downstream cells
- the agent can rewrite code, but it may not really know where your analysis currently stands
That is why general coding agents can feel close, but still not quite right in Jupyter. They can read the file, but they do not always understand what is happening in the notebook right now.
RunCell is not a general software engineering agent that happens to open .ipynb files. It is a Jupyter-native AI agent built for notebook workflows and data science work. In practice, that means less context switching, less manual backtracking through cells, and less guessing about whether the output in front of you still matches the current analysis.
| Workflow need | Claude Code | RunCell |
|---|---|---|
| Read and edit notebook files | Yes | Yes |
| Work directly around notebook execution state | Limited | Native fit |
| Handle DataFrames and notebook context as first-class signals | Limited | Stronger |
| Continue analysis from notebook outputs and state | Indirect | Direct |
| Fit exploratory data science loops | Limited | Much better |
If your real job is notebook review, Claude Code is useful.
But if your day-to-day work looks more like this:
- EDA
- data cleaning
- feature work
- tuning models
- checking charts and debugging notebook steps as you go
then RunCell usually feels more natural. Your goal is not only to "fix some code." Your goal is to keep the analysis moving.
If you have already run into this pattern, the difference is easy to recognize: the agent can edit the notebook file, but you still have to go back, inspect outputs, check variables, and rerun cells yourself before you trust the result. That is the point where RunCell (opens in a new tab) becomes the more natural next step.
When to Use Claude Code vs RunCell
Use Claude Code when you want to:
- review a notebook as a file
- refactor cell text and markdown
- summarize an analysis for teammates
- extract script logic from an old notebook
Use RunCell when you want to:
- work inside Jupyter as your main environment
- iterate on EDA, feature engineering, or modeling
- use live notebook context instead of a static snapshot
- keep analysis, execution, debugging, and revision in one workflow