Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界

Claude Code は Jupyter ノートブックを読んだり書き換えたりできます。ただし、Jupyter の live kernel や現在の変数状態まで理解して動く notebook-native な AI ではありません。実際には .ipynb を構造化ファイルとして扱う性格が強いです。
この違いは Data Science では重要です。ソフトウェア開発ならファイル理解だけで十分な場面もありますが、notebook 作業では実行順序、DataFrame、出力、グラフ、実験文脈が結果を左右します。
合わせて読むなら Python Notebook、JupyterLab vs Notebook、Jupyter AI with RunCell も役立ちます。
まず結論
| 質問 | 短い答え |
|---|---|
| Claude Code は Jupyter ノートブックを開けるか | はい |
| セルや保存済み出力を要約できるか | はい |
| セルを編集できるか | はい |
| セル実行や kernel 制御ができるか | いいえ |
| live 変数や現在の DataFrame を見られるか | 真の runtime ツールほどは無理 |
| Data Science notebook の主力として十分か | 多くの場合は不十分 |
Claude Code が向いている notebook 作業
Claude Code は notebook を「整理対象のファイル」として扱うときに役立ちます。
- notebook 全体の流れを要約する
- 各セルの役割を説明する
- 読みにくい pandas コードを書き直す
- markdown の説明を補強する
- 長すぎるセルや重複セルを整理する
つまり notebook review や構造整理には向いていますが、live な notebook 作業をそのまま引き継ぐのには向いていません。
Claude Code は notebook をどう扱っているのか
Claude Code の notebook 対応は大きく 2 つです。
.ipynbを notebook-aware に読む- セル単位で notebook を編集する
ただし境界はあくまでファイルです。
1. 読んでいるのは notebook JSON であって live runtime ではない
Claude Code は .ipynb をパースし、セルや保存済み output を取り出して、モデルが読みやすい形に変換します。
一方で次のことはしません。
- kernel を直接制御しない
- Jupyter server を直接扱わない
- live variables を見ない
- セルを実行しない
- restart / rerun の流れを持たない
2. セル編集はできるが、本質はファイル編集
Claude Code はセルの挿入、置換、削除ができます。コード変更時に古い output を消すような notebook-aware な配慮もあります。
それでも本質は .ipynb の編集であって、Jupyter の実行状態そのものを扱っているわけではありません。
Claude Code は Jupyter Notebook のファイル構造を理解しているのであって、Jupyter の runtime を理解しているわけではありません。
これが Data Science で重要な理由
Data Science の難しさは、Python を書くだけではありません。
- どのセルが実行済みか
- どの DataFrame が現行か
- グラフが古いデータに基づいていないか
- 上流の変更が下流を壊していないか
この文脈を持てないと、notebook を読めても notebook 作業は前に進めにくいです。
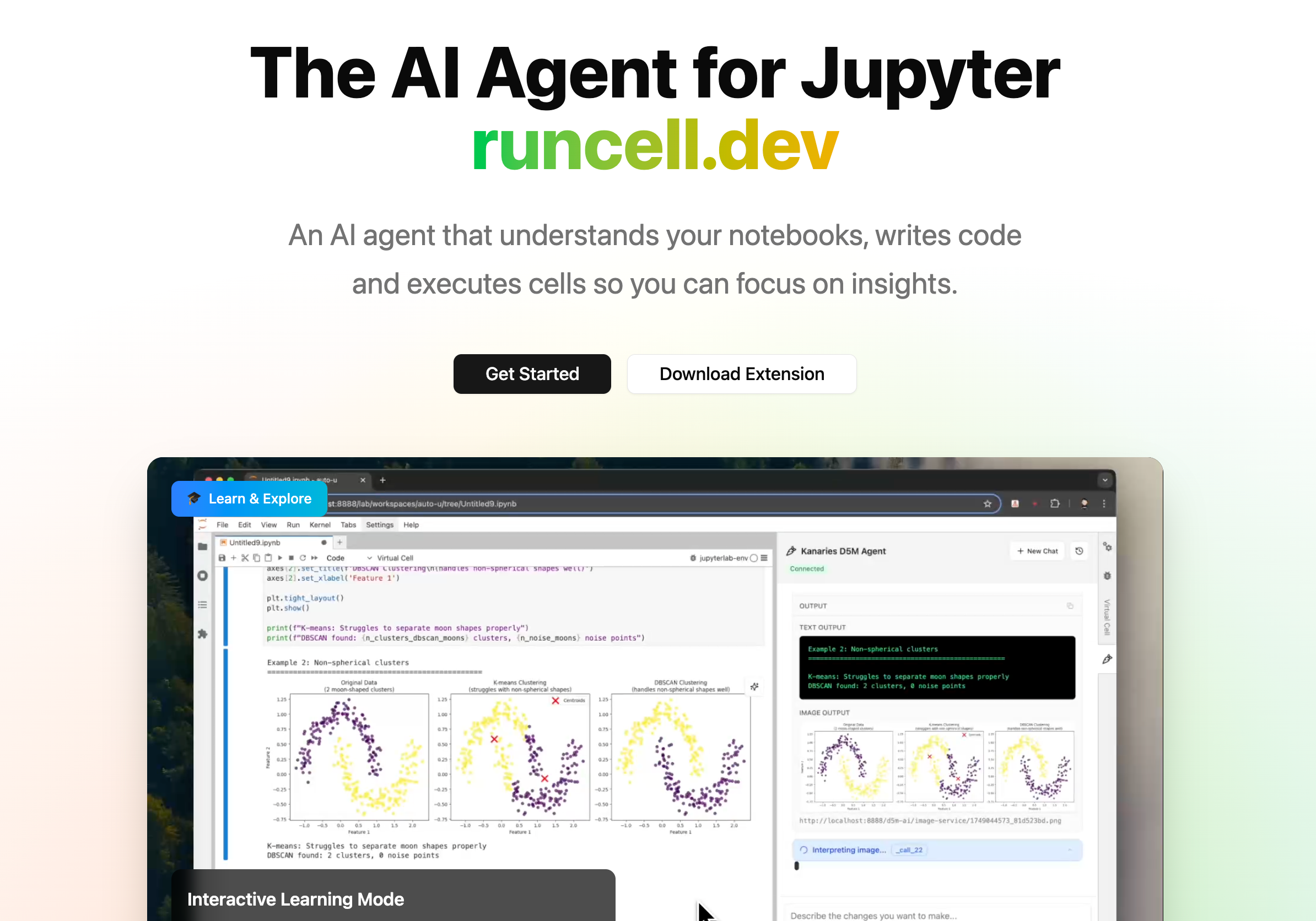
RunCell のほうが Jupyter には自然にハマる
RunCell (opens in a new tab) がここで効いてくるのは、notebook ユーザーの悩みが最初から「AI がコードを書けるかどうか」だけではないからです。
実際に面倒なのは、たとえばこういう場面です。
- notebook が途中まで動いていて、どのセルがまだ信用できるのか分かりにくい
- 目の前のグラフが最新データに基づいているのか、すぐには判断しづらい
- 上流で列名や schema を少し変えただけで、後ろのセルがまとめて壊れる
- agent はコードを書き換えられても、分析が今どの段階にあるかまでは分かっていない
だからこそ、汎用の coding agent は Jupyter でも「かなり使えるけれど、どこか惜しい」と感じやすいです。ファイルは読めても、notebook の今の状況までは分かっていないことが多いからです。
RunCell は、一般的なソフトウェア開発向け AI を notebook に流用したものではなく、Jupyter / Data Science 向け AI Agent として設計されています。実際の使い心地としては、画面を行き来する回数が減り、セルを手でさかのぼって確認する手間が減り、今見ている output が本当に正しいのかを毎回推測しなくて済みやすくなります。
| 観点 | Claude Code | RunCell |
|---|---|---|
| notebook ファイルの読書き | 可能 | 可能 |
| notebook の実行状態を前提に動く | 限定的 | 自然 |
| DataFrame やセル文脈を主信号にする | 限定的 | 強い |
| output を見ながら分析を続ける | 間接的 | 直接的 |
| notebook 実務への適合 | 汎用寄り | 専用寄り |
notebook をレビューするなら Claude Code でも十分役立ちます。
ただ、普段やっていることが次のような作業なら、
- EDA
- データクリーニング
- feature engineering
- モデル調整
- グラフを見ながら notebook を直していく作業
RunCell のほうが自然に感じやすいです。目的は「コードを正しく直すこと」だけではなく、「分析を止めずにそのまま先へ進めること」だからです。
もしすでに、agent に .ipynb を直してもらっても、その後に自分で output を見直し、変数を確認し、いくつかのセルを再実行しないと安心できない、という経験があるなら、その違いは分かりやすいはずです。そういう場面では RunCell (opens in a new tab) のほうが次の一歩として自然です。