PyGWalker
可視化付きの探索的データ分析を行うPythonライブラリ - PyGWalker
PyGWalker (opens in a new tab) は、pandasデータフレームを対話型ユーザーインターフェースに変換することで、Jupyter Notebookのデータ分析とデータ可視化のワークフローを簡素化します。
PyGWalker("Pig Walker"と発音します)は、"Python binding of Graphic Walker"の略称として命名されています。これは、Jupyter NotebookをGraphic Walker (opens in a new tab)と統合し、Tableauのオープンソースの代替手段です。これにより、データサイエンティストは、シンプルなドラッグアンドドロップ操作や自然言語クエリを使用してデータを視覚化 / クリーンアップ / 注釈付けすることができます。
Google Colab (opens in a new tab)、Kaggle Code (opens in a new tab)、またはGraphic Walker Online Demo (opens in a new tab)を訪れて、試してみてください!
もしRを使用したい場合は、GWalkR (opens in a new tab)をチェックしてみてください。これはGraphic WalkerのRラッパーです。
AI Agent In Jupyter Notebook
Let runcell AI take control of your notebook — automatically executing cells and completing complex data workflows while you focus on insights.
スタートガイド
| Kaggleで実行 (opens in a new tab) | Colabで実行 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 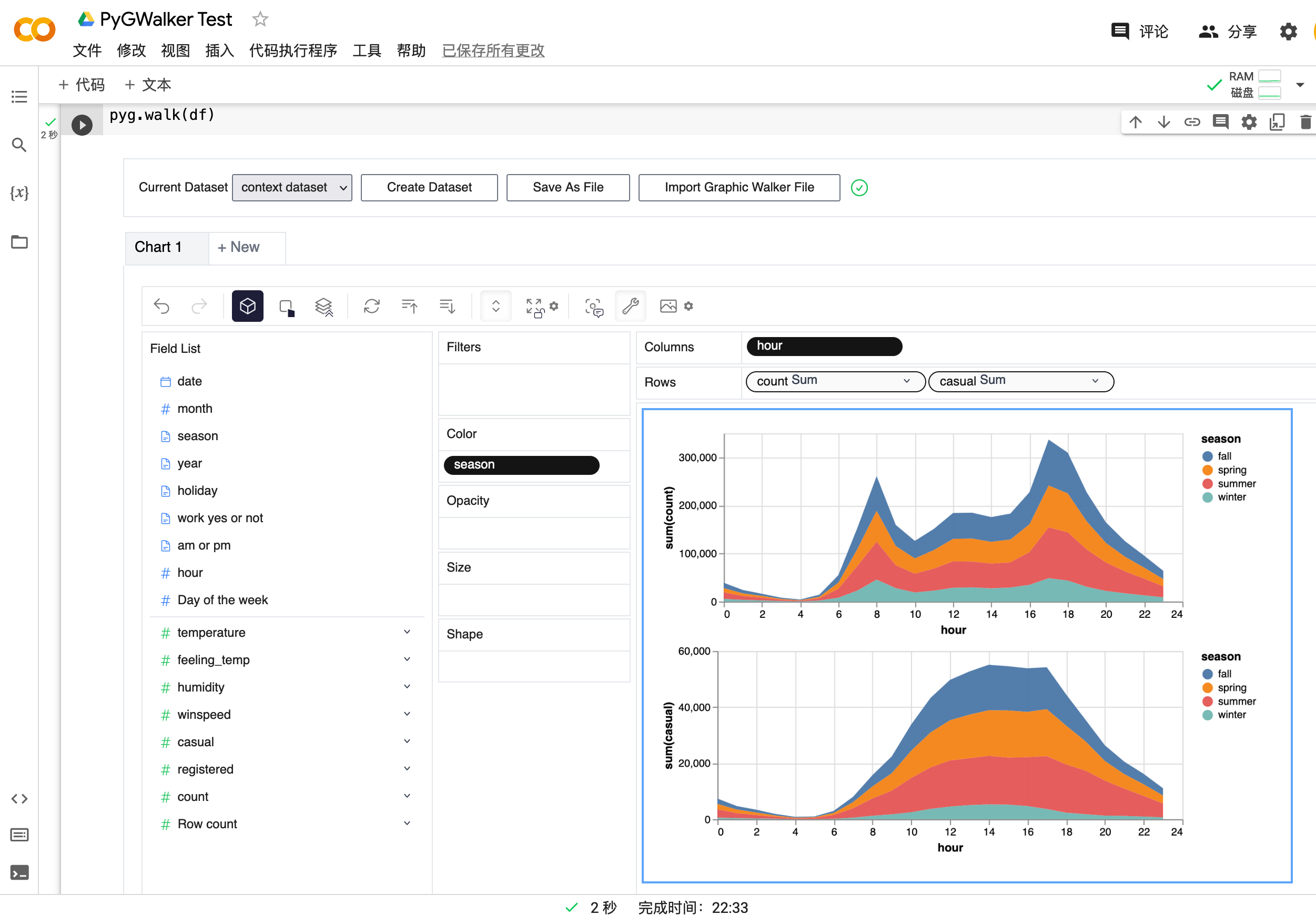 (opens in a new tab) (opens in a new tab) |
pygwalkerのセットアップ
pygwalkerを使用する前に、pipやcondaを使ってパッケージをインストールするか確認してください。
pip
pip install pygwalker runcell注意
初期のトライアルでは、
pip install pygwalker --upgradeとしてバージョンを最新のリリースに保つか、さらに最新の機能とバグ修正を取��するためにpip install pygwaler --upgrade --preとしてもかまいません。
Conda-forge
conda install -c conda-forge pygwalkerまたは
mamba install -c conda-forge pygwalker詳細については、conda-forge feedstock (opens in a new tab) をご覧ください。
Jupyter Notebookでpygwalkerを使用する
クイックスタート
Jupyter Notebookにpygwalkerとpandasをインポートして、始めましょう。
import pandas as pd
import pygwalker as pyg既存のワークフローを崩すことなくpygwalkerを使用できます。例えば、次のようにデータフレームを読み込んでPyGWalkerを呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv')
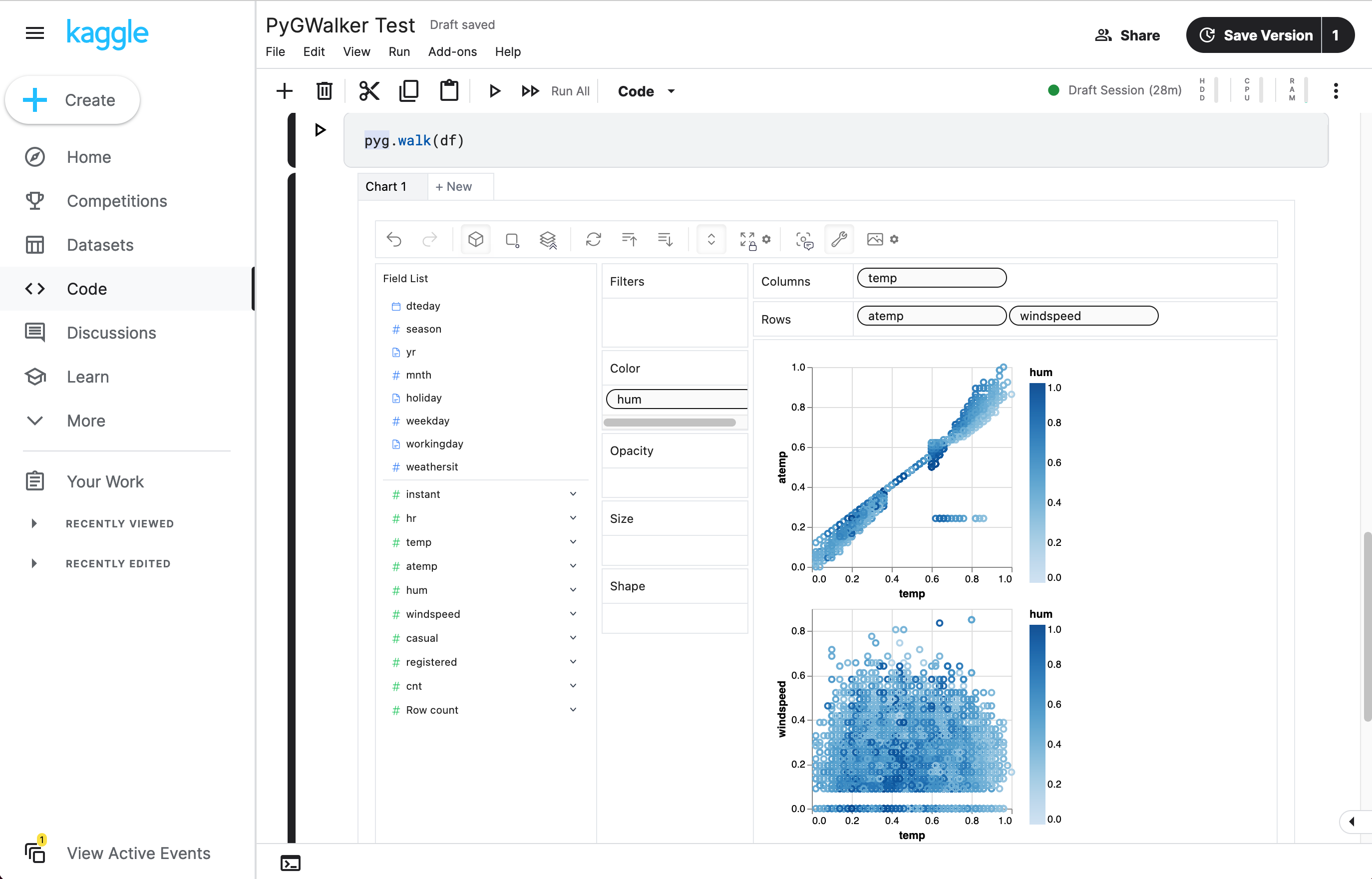
walker = pyg.walk(df)これで、シンプルなドラッグアンドドロップ操作でデータを分析および視覚化するための対話型UIが手に入ります。
PyGWalkerでできること:
-
マークタイプを別のものに変更して異なるグラフ(例えば、折れ線グラフ)を作成できます。

-
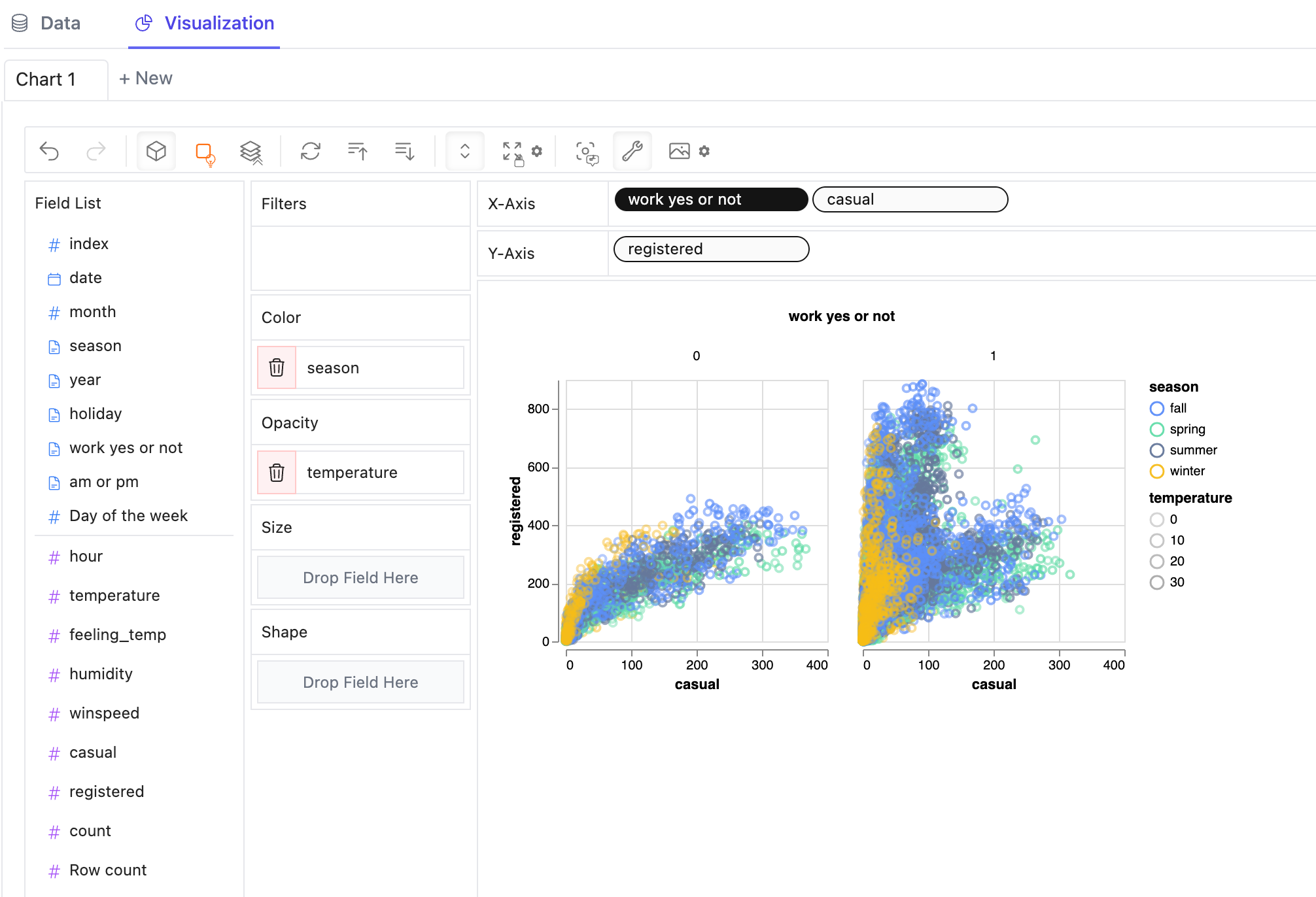
異なる数値を比較するために、複数の数値を行/列に追加して連結ビューを作成できます。

-
次元の値で分割された複数のサブビューのファセットビューを作成するために、次元を行または列に追加してファセットビューを作成できます。
-
PyGWalkerには強力なデータテーブルが含まれており、データとその分布、プロファイリングを素早く表示できます。また、テーブル内のフィルターの追加やデータ型の変更もできます。
- データ探索結果をローカルファイルに保存することができます。
より良い実践方法
pygwalkerを使用する際に知っておくべきいくつかの重要なパラメータ:
spec: チャート構成を保存/読み込むためのパラメータ(JSON文字列またはファイルパス)kernel_computation: ローカルマシンでより大きなデータセットを扱うためにduckdbを計算エンジンとして使用する際のパラメータkernel_computation: 廃止されました。代わりにkernel_computationを使用してください。
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(
df,
spec="./chart_meta_0.json", # このjsonファイルはチャートの状態を保存します。チャートを完了したら手動で保存ボタンをクリックする必要があります。将来的には「autosave」がサポートされます。
kernel_computation=True, # `kernel_computation=True`を設定すると、pygwalkerはduckdbを計算エンジンとして使用し、ローカルマシンで大きなデータセット(<=100GB)を探索できます。
)ローカルのノートブックの例
- ノートブックのコー��: こちらをクリック (opens in a new tab)
- プレビューノートブックのHtml: こちらをクリック (opens in a new tab)
クラウドノートブックの例
Streamlitでpygwalkerを使用する
Streamlitを使用すると、Webアプリケーションの詳細を気にすることなく、pygwalkerを利用したWebバージョンをホストすることができます。
次のようなPyGWalkerとStreamlitを使用したアプリの例があります:
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Streamlitページの幅を調整
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# タイトルを追加
st.title("Use Pygwalker In Streamlit")
# メモリの爆発を防ぐため、pygwalker rendererをキャッシュする必要があります
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# チャート構成を保存する機能を使用したい場合は、`spec_io_mode="rw"`を設定します
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()APIリファレンス (opens in a new tab)
pygwalker.walk (opens in a new tab)
| パラメータ | タイプ | デフォルト | 説明 |
|---|---|---|---|
| dataset | Union[DataFrame, Connector] | - | 使用するデータフレームまたはコネクタ。 |
| gid | Union[int, str] | None | GraphicWalkerコンテナディブのID、「gwalker-{gid}」としてフォーマットされます。 |
| env | Literal['Jupyter', 'JupyterWidget'] | 'JupyterWidget' | pygwalkerを使用する環境。 |
| field_specs | Optional[Dict[str, FieldSpec]] | None | フィールドの仕様。明示されていない場合、datasetから自動的に推論されます。 |
| hide_data_source_config | bool | True | Trueの場合、データソースのインポートとエクスポートボタンが非表示になります。 |
| theme_key | Literal['vega', 'g2'] | 'g2' | GraphicWalker��テーマタイプ。 |
| appearance | Literal['media', 'light', 'dark'] | 'media' | テーマ設定。'media'はOSのテーマを自動検出します。 |
| spec | str | "" | チャート構成データ。構成ID、JSON、またはリモートファイルURLを指定できます。 |
| use_preview | bool | True | Trueの場合、プレビュー機能を使用します。 |
| kernel_computation | bool | False | Trueの場合、データに対してカーネル計算を使用します。 |
| **kwargs | Any | - | 追加のキーワード引数。 |
テスト済み環境
- Jupyter Notebook
- Google Colab
- Kaggle Code
- Jupyter Lab
- Jupyter Lite
- Databricks Notebook(バージョン
0.1.4a0以降) - Visual Studio CodeのJupyter拡張機能(バージョン
0.1.4a0以降) - IPythonカーネルと互換性のあるほとんどのWebアプリケーション(バージョン
0.1.4a0以降) - Streamlit(バージョン
0.1.4.9以降)、pyg.walk(df, env='Streamlit')を有効にする - DataCamp Workspace(バージョン
0.1.4a0以降) - Hex Projects
- ...他の環境についての問題提起はお気軽に行ってください。
設定とプライバシーポリシー(pygwlaker >= 0.3.10)
pygwalker configを使用してプライバシー設定を行うことができます。
$ pygwalker config --help
usage: pygwalker config [-h] [--set [key=value ...]] [--reset [key ...]] [--reset-all] [--list]
Modify configuration file. (default: ~/Library/Application Support/pygwalker/config.json)
Available configurations:
- privacy ['offline', 'update-only', 'events'] (default: events).
"offline": fully offline, no data is send or api is requested
"update-only": only check whether this is a new version of pygwalker to update
"events": share which events about which feature is used in pygwalker, it only contains events data about which feature you arrive for product optimization. No DATA YOU ANALYSIS IS SEND. Events data will bind with a unique id, which is generated by pygwalker when it is installed based on timestamp. We will not collect any other information about you.
- kanaries_token ['your kanaries token'] (default: empty string).
your kanaries token, you can get it from https://kanaries.net.
refer: https://space.kanaries.net/t/how-to-get-api-key-of-kanaries.
by kanaries token, you can use kanaries service in pygwalker, such as share chart, share config.
options:
-h, --help show this help message and exit
--set [key=value ...] Set configuration. e.g. "pygwalker config --set privacy=update-only"
--reset [key ...] Reset user configuration and use default values instead. e.g. "pygwalker config --reset privacy"
--reset-all Reset all user configuration and use default values instead. e.g. "pygwalker config --reset-all"
--list List current used configuration.詳細については、プライバシ��設定方法はこちら (opens in a new tab) を参照してください。
ライセンス
Apache License 2.0 (opens in a new tab)
リソース
PyGWalker Cloudがリリースされました!チャートをクラウドに保存したり、対話型セルをWebアプリケーションとして公開したり、GPTパワードの高度な機能を使用したりすることができます。詳細については、PyGWalker Cloud (opens in a new tab) をご覧ください。
- PyGWalker Paper PyGWalker: On-the-fly Assistant for Exploratory Visual Data Analysis (opens in a new tab)
- Kanaries PyGWalker (opens in a new tab) でPyGWalkerに関するより多くのリソースを確認してください。
- 弊社ではRATH (opens in a new tab)に取り組んでおり、データ整形、探索、可視化をAI機能によって自動化するオープンソースの探索的データ分析ソフトウェアを提供しています。