「Python Pandasによる探索的データ分析:完全ガイド」
- Name
- Omar C. Williams
更新日
データサイエンスプロジェクトにおいて、探索的データ分析(EDA)は重要なステップです。これには、データの理解、パターンの識別、初期観察が含まれます。この記事は、PythonのPandasライブラリを使ったEDAのプロセスを案内します。Pandasはデータの操作と分析に強力なツールです。欠損値の処理から洞察に満ちた可視化まで、すべてをカバーします。
Pandasを使用した探索的データ分析
欠損値の処理
実世界のデータを扱うときは、欠損値に遭遇することがよくあります。これは、データ入力ミスや一部の観測値に対してデータが収集されないなどの理由で発生する可能性があります。欠損値の処理は重要です。正しく処理されない場合、正確な分析につながらない可能性があります。
Pandasでは、 isnull() 関数を使用して欠落値を確認できます。この関数は、各セルが欠損値を含む場合はTrue(オリジナルのセルに欠落値が含まれている場合)、False(セルに欠落値が含まれていない場合)のいずれかで構成されるDataFrameを返します。各列の合計欠損値数を取得するには、 sum()関数をチェインすることができます。
missing_values =df.isnull().sum()これにより、列名がインデックスで、各列の合計欠損値数が値として返されるシリーズが返されます。データの性質や行う分析に応じて、欠損値を特定の値(列の中央値や平均値など)で埋めたり、欠落値が含まれる行または列を削除したりすることができます。
ユニークな値の探索
EDAの別の重要なステップは、データのユニークな値を探索することです。これにより、データの多様性を理解することができます。たとえば、あるフィーチャーのカテゴリを表す列がある場合、ユニークな値をチェックすることで、何個のカテゴリがあるかがわかります。
Pandasでは、各列のユニークな値の数を確認するために nunique() 関数を使用できます。
unique_values = df.nunique()これにより、列名がインデックスで、各列のユニークな値の数が値として返されるシリーズが返されます。
値のソーティング
ある列に基づいてデータをソートすることも、EDAで役立ちます。たとえば、 "人口"列に基づいてデータをソートして、どの国が最も人口が多いかを見ることができます。Pandasでは、 sort_values() 関数を使用してDataFrameをソートできます。
sorted_df = df.sort_values(by='population', ascending=False)これにより、 'population'列を降順でソートされた新しいDataFrameが返されます。 ascending = False 引数は、列を降順でソートします。昇順で並べ替えたい場合は、この引数を省略することができます。 Trueがデフォルト値です。
ヒートマップで相関関係を視覚化する
可視化は、生データだけで見るよりも、値の洞察力を提供することができます。役立つ可視化の1つは、データの異なるフィーチャー間の相関のヒートマップです。
Pandasでは、 corr()関数を使用して相関行列を計算できます。
correlation_matrix = df.corr()このマークダウンファイルでは、行iと列jの交差点にあるセルに相関を含むDataFrameが返されます。相関係数は、2つの特徴量間の関係の強度と方向を示す-1から1の値です。1に近い値は強い正の関係を示し、-1に近い値は強い負の関係を示し、0に近い値は関係がないことを示します。
この相関行列を可視化するには、seabornライブラリから heatmap() 関数を使用できます。
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 7))
sns.heatmap(correlation_matrix, annot=True)
plt.show()これにより、各セルの色が対応する特徴量間の相関係数を表すヒートマップが作成されます。annot=True 引数は、ヒートマップのセルに相関係数を追加します。
データのグループ化
特定の基準に基づいてデータをグループ化することで、貴重な洞察を得ることができます。たとえば、大陸ごとにデータをグループ化して大陸レベルでデータを分析することができます。Pandasでは、groupby() 関数を使用してデータをグループ化できます。
grouped_df = df.groupby('continent').mean()これにより、データが 'continent' 列でグループ化され、各グループの値はそのグループ内の元のデータの平均値である新しいDataFrameが返されます。
時間に沿ったデータの可視化
データを時間に沿って可視化することで、傾向やパターンを特定することができます。たとえば、各大陸の人口を時間に沿って可視化することができます。Pandasでは、この目的のためにラインプロットを作成できます。
df.groupby('continent').mean().transpose().plot(figsize=(20, 10))
plt.show()これにより、x軸が時間を表し、y軸が平均人口を表すラインプロットが作成されます。プロット内の各ラインは異なる大陸を表します。
ボックスプロットによる外れ値の特定
ボックスプロットは、データ内の外れ値を特定するのに適した方法です。外れ値とは、他の値と著しく異なる値のことです。外れ値は、測定誤差やデータの本来の変動性など、さまざまな要因によって引き起こされる場合があります。
Pandasでは、boxplot() 関数を使用してボックスプロットを作成できます。
df.boxplot(figsize=(20, 10))
plt.show()これにより、DataFrame内の各列のボックスプロットが作成されます。各ボックスプロットのボックスは四分位範囲(第25パーセンタイルから第75パーセンタイルまでの範囲)を表し、ボックス内の線は中央値を表し、ボックスの外側にある点は外れ値を表します。
データタイプの理解
DataFrame内のデータタイプを理解することは、EDAの別の重要な側面です。異なるデータタイプには異なる処理手法が必要であり、異なる種類の操作をサポートする場合もあります。たとえば、文字列データ上で数値演算を行うことはできず、その逆も同様です。
Pandasでは、dtypes 属性を使用してDataFrame内のすべての列のデータタイプをチェックできます。
df.dtypesこれにより、列名がインデックスとして、列のデータ型が値として含まれるSeriesが返されます。
データ型に基づくデータフィルタリング
時には、特定のデータ型の列に対してのみ操作を実行したい場合があります。たとえば、数値データのみで平均値、中央値などの統計量を計算したい場合があります。そのような場合は、データ型に基づいて列をフィルタリングできます。
Pandasでは、select_dtypes()関数を使用して、特定のデータ型の列を選択できます。
numeric_df = df.select_dtypes(include='number')これにより、数値データのみを含む新しいDataFrameが返されます。同様に、次のようにオブジェクト(文字列)データ型を持つ列を選択できます。
object_df = df.select_dtypes(include='object')ヒストグラムによるデータ分布の視覚化
ヒストグラムはデータの分布を視覚化する優れた方法です。これらは、データの中央傾向、変動性、歪度についての洞察を提供することができます。
Pandasでは、hist()関数を使用してヒストグラムを作成できます。
df['population'].hist(bins=30)
plt.show()これにより、「人口」列のヒストグラムが作成されます。 binsパラメータは、データを分割する区間の数を決定します。
PyGWalkerとPandasを組み合わせた探索的データ分析
データサイエンスと分析の領域において、私たちはしばしば、Pandas、matplotlib、およびseabornなどのツールを使用してデータの探索や分析に深く没頭します。これらのツールは非常にパワフルですが、対話型のデータ探索や視覚化にはしばしば不十分な場合があります。これがPyGWalkerが登場する理由です。

PyGWalker(「Pig Walker」と発音)は、Jupyterノートブック(または他のjupyterベースのノートブック)とオープンソースのTableauの代替手段であるGraphic Walkerとシームレスに統合するPythonライブラリです。 PyGWalkerは、PandasデータフレームをTableauスタイルのユーザーインターフェイスに変換して、データ分析ワークフローをより対話的で直感的にします。
PyGWalkerは、熱心なオープンソース貢献者のコレクティブによって構築されています。 PyGWalker GitHubをチェックして、スターを付けることを忘れないでください!(https://github.com/Kanaries/pygwalker (opens in a new tab))
PyGWalkerの使い方
PyGWalkerをインストールするのは簡単です。単にあなたのJupyterノートブックを開き、次のように入力します。
!pip install pygwalkerPyGWalkerによる対話型データ探索
PyGWalkerをインストールしたら、データを対話的に探索できます。これを行うには、データフレームに対して単にwalk()関数を呼び出す必要があります。
import pygwalker as pyg
pyg.walk(data)このMarkdownファイルでは、Tableauに似たインタラクティブなデータ可視化ツールの起動方法について説明しています。インターフェイスの左側にはデータフレーム内の変数が表示され、中央の領域には視覚化が表示されます。変数をX軸とY軸のボックスにドラッグ&ドロップすることで、可視化をカスタマイズすることができます。また、PyGWalkerは、フィルタ、色、透明度、サイズ、形状などのさまざまなカスタマイズオプションを提供しており、特定のニーズに合わせて可視化を調整することができます。
PyGWalkerを使ったデータの可視化
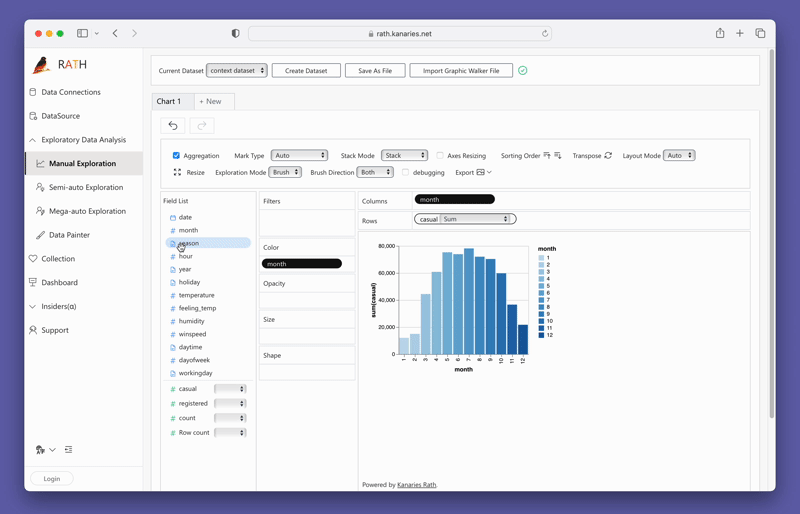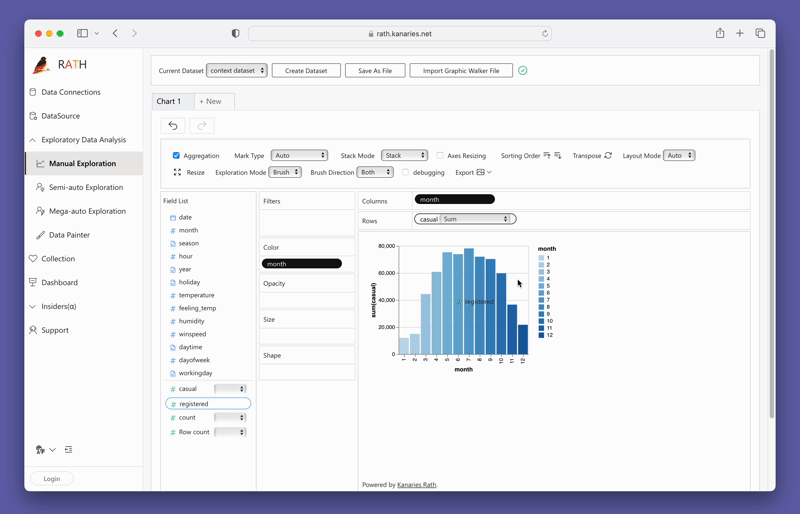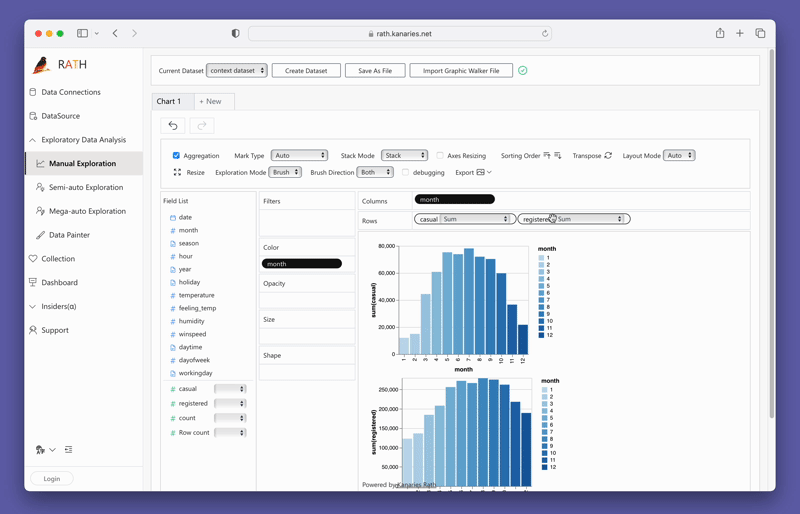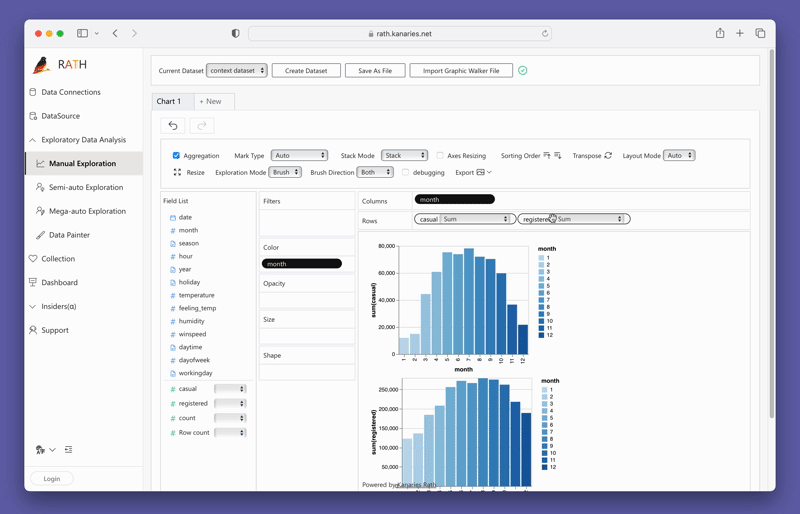
PyGWalkerを使ったデータの可視化は、変数をドラッグ&ドロップするだけで簡単に実現できます。例えば、地域別の売上の棒グラフを作成するには、「売上」列をX軸に、「地域」列をY軸にドラッグします。また、お好みのマークタイプを選択したり、自動モードにして適切なプロットタイプをツールが自動的に選択することもできます。
あらゆるタイプのデータ可視化についての詳細については、ドキュメンテーションを参照してください。
PyGWalkerでデータを探索
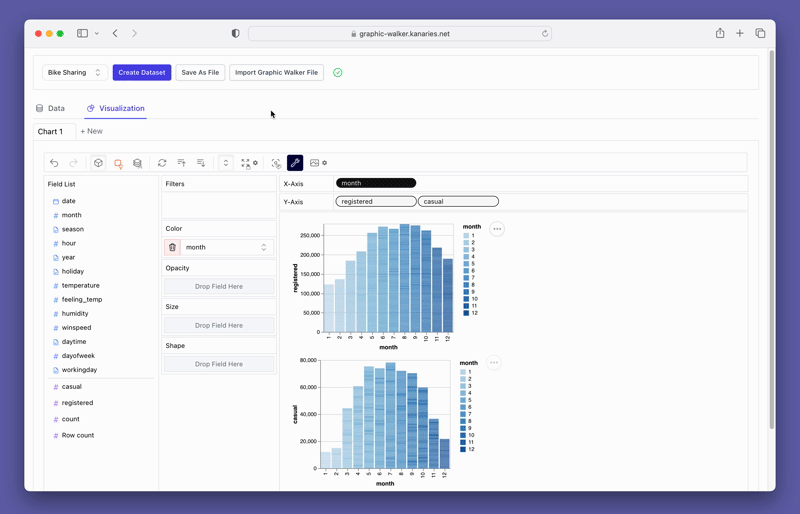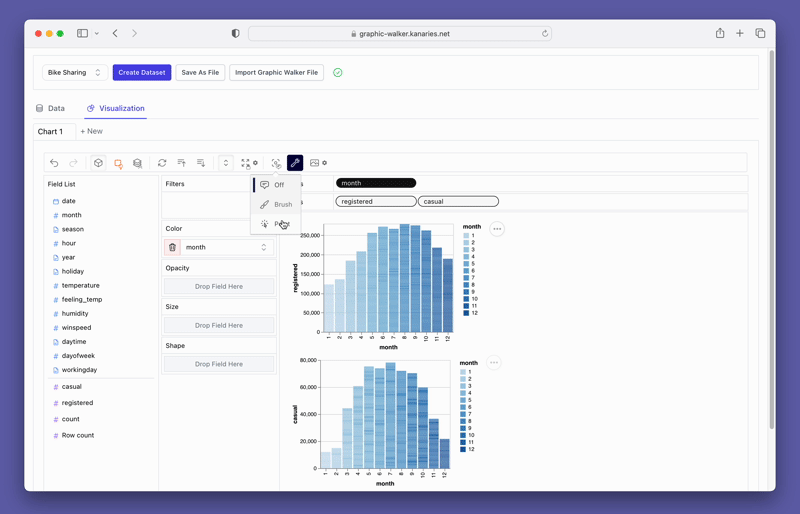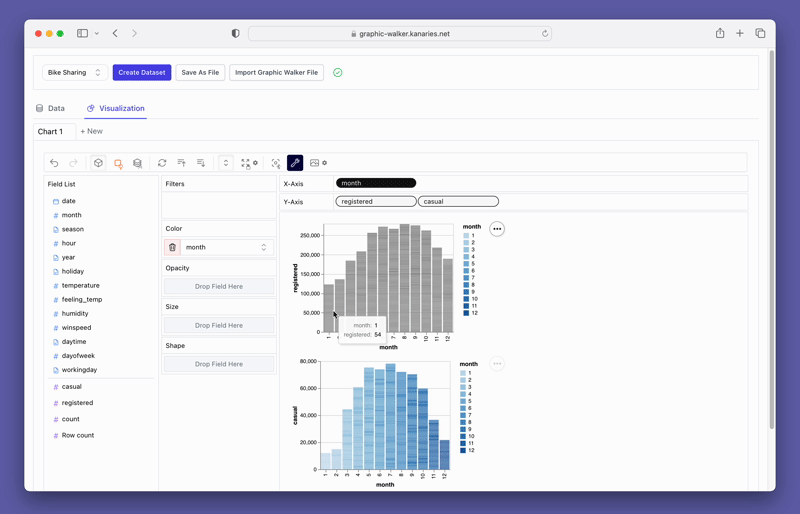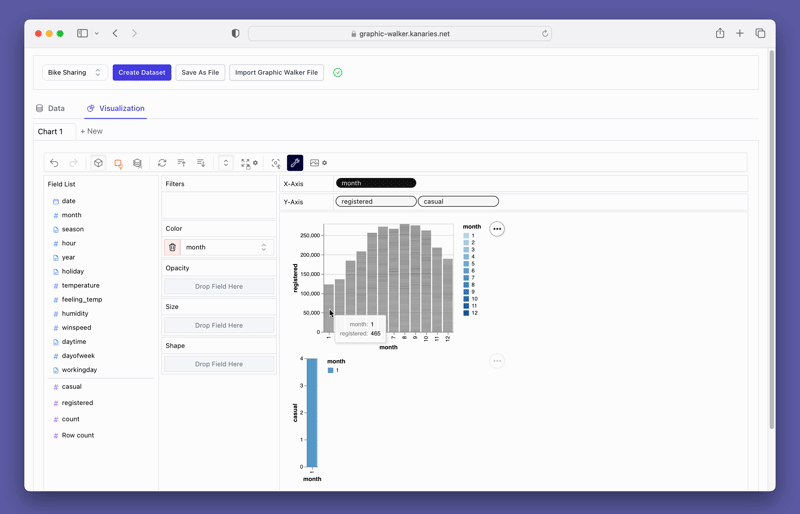
PyGWalkerは、フィルタリングや集計などの使いやすいオプションも提供しています。フィルタボックスに列をドラッグすることで、任意の列を基準にデータをフィルタリングすることができます。同様に、数値列を利用した集計も、利用可能なオプションから集計関数を選択することで簡単に実現できます。
PyGWalkerでの探索的データ分析についての詳細な例やツールについては、ドキュメンテーションを参照してください。
可視化に満足したら、PNGまたはSVGファイルとしてエクスポートして、さらなる利用のために保存することができます。PyGWalkerの0.1.6のアップデートでは、可視化をコード文字列にエクスポートすることもできます。
結論
探索的データ分析(EDA)は、データサイエンスプロジェクトの基本的なステップです。データを理解し、パターンを発見し、モデリングプロセスに関する情報を得ることができます。PythonのPandasライブラリは、EDAを効率的かつ効果的に行うためのさまざまな機能を提供しています。
この記事では、欠損値の処理、ユニークな値の探索、値のソート、相関の可視化、データのグループ化、時系列でのデータの可視化、外れ値の識別、データ型の理解、データ型に基づくデータのフィルタリング、データ分布の可視化などについて説明しました。これらの技術をデータサイエンスのツールキットに備えることで、自分自身のデータを分析して価値ある洞察を見つけ出すことができます。
EDAは科学よりも芸術です。好奇心、直感、細部への鋭敏さが必要です。自分自身のデータを深く掘り下げ、さまざまな角度から探求することを恐れないでください。幸運を祈ります!
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
よくある質問
-
探索的データ分析とは何ですか?
探索的データ分析は、データを分析し、視覚化してパターン、関係、洞察を明らかにするプロセスです。データのクリーニング、データの変換、データの可視化などの技術が必要です。
-
探索的データ分析はなぜ重要ですか?
探索的データ分析は、データを理解し、傾向やパターンを見つけ、さらなる分析についての情報を得ることができます。データサイエンティストは、洞察を得て、ビジネス決定を導くことができます。
-
探索的データ分析でよく使われる技術は何ですか?
探索的データ分析でよく使われる技術には、要約統計量、データの可視化、データのクリーニング、欠損値の処理、外れ値の検出、相関分析などがあります。
-
探索的データ分析によく使われるツールは何ですか?
探索的データ分析には、PythonライブラリのPandas、NumPy、Matplotlib、Tableau、Excelなどがよく使われます。
-
探索的データ分析の主なステップは何ですか?
探索的データ分析の主なステップには、データのクリーニング、データの探索、データの可視化、統計分析、データの結論への引き出しが含まれます。これらのステップは反復的であり、データの継続的な改善と探求が必要です。