SQLとPythonを超えたワンホットエンコーディングのマスターガイド

この記事は、One Hot Encoding を使用してデータ分析の世界でカテゴリ変数を処理する技術をマスターするための頼りになるガイドです。 SQL と Python を使用した 1 つのホット エンコーディングの実用的な実装を通じて、さまざまな手法と実際の例を紹介します。 また、強力な自動データ分析コパイロットである RATH がワークフローを合理化し、データ分析タスクの効率を高める方法についても説明します。 1 つのホット エンコーディングとデータ前処理の魅力的な世界に飛び込みましょう。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
ワンホットエンコーディングとは?
One Hot Encoding は、カテゴリ変数を、機械学習アルゴリズムやその他の分析モデルが簡単に理解できる形式に変換するために使用される手法です。 カテゴリ変数は、色、都市、製品タイプなどの個別のカテゴリまたはグループを表す数値以外のデータ ポイントです。 課題は、ほとんどの機械学習アルゴリズムとモデルが数値入力を想定しているため、カテゴリ データを直接利用することが困難であるという事実にあります。
この問題の解決策は、カテゴリ変数をバイナリ形式に変換するホット エンコーディングです。各カテゴリは、1 と 0 で埋められた個別の列で表されます。 特定の列の「1」の存在は、元のデータ ポイントが対応するカテゴリに属していることを示し、「0」はそうでないことを示します。 このプロセスは基本的に、一意のカテゴリごとに 1 つずつ、新しい列のセットを作成し、機械学習アルゴリズムがカテゴリ データをより効率的に処理できるようにします。
コードのないワンホットエンコーディング
ワンホット エンコーディングを実装するためのほとんどのチュートリアルでは、Python または SQL コーディングの経験が必要です。 ただし、No Code を使用してワンホット コーディングを適用する、魅力的で視覚化された洗練されたソリューションが 1 つあります。
RATH (opens in a new tab) は、非常に簡単な手順で複雑なアルゴリズムをデータに適用するデータ サイエンティスト向けのオープン ソース ソリューションです。
ステップ1。 RATH オンライン デモにログインします。 Data Connections タブで Files ボタンをクリックし、CSV または Excel ファイルをインポートします。
ヒント: BigQuery を使用している場合は、データベース オプションを選択して、RATH を BigQuery に接続できます。
ステップ2。 [データ ソース] タブで、ワンホット エンコーディングを適用する変数を選択します。 RATH は、それをカテゴリ変数として自動的に検出し、提案を行うことができます。

クリックするだけで、データのワンホット エンコーディング プロセスが実行されます。 質問はありません。
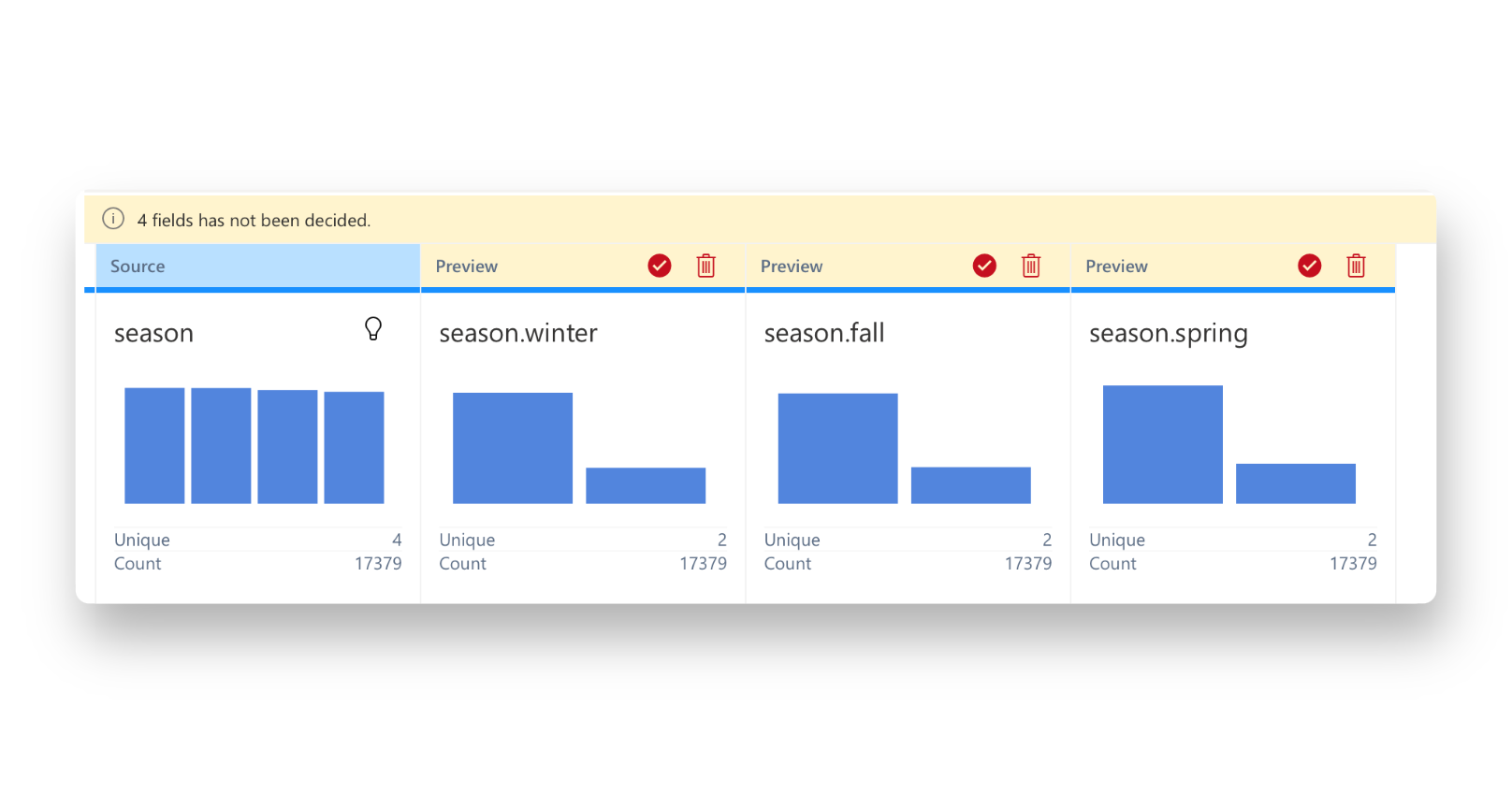
RATH は、ワンホット エンコーディングを超える高度な機能をサポートしています。 例えば:
- DateTime 変数の場合、RATH は 年、月、日、時間ごとにデータをグループ化 などを自動的に行うことができます。
- 外れ値の可能性がある場合、RATH はこれらの変数を自動的に検出し、Isolation Forest アルゴリズムを使用してフィールドを再グループ化し、外れ値グループと非外れ値グループを作成することを提案します。
すべてをノーコード方式で実行できます。 RATH は オープン ソース (opens in a new tab) であるため、いくつかのチャートを生成するために高額な料金を支払う必要はありません。 RATH Online Demo (opens in a new tab)で試してみてください!

SQL でのワンホット エンコーディング
テーブルを SQL の単一列値のワンホット エンコーディングに変換
SQL では、「CASE」ステートメントを使用して、テーブルをワンホット エンコード形式に変換できます。 次の表を検討してください。
| id | category |
|---|---|
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
1 つのホット エンコーディングを実行するには、次の SQL クエリを使用できます。
SELECT
id,
CASE WHEN category = 'A' THEN 1 ELSE 0 END AS category_A,
CASE WHEN category = 'B' THEN 1 ELSE 0 END AS category_B,
CASE WHEN category = 'C' THEN 1 ELSE 0 END AS category_C
FROM
your_table;これにより、目的の 1 つのホット エンコーディング形式のテーブルが作成されます。
| id | category_A | category_B | category_C |
|---|---|---|---|
| 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 0 | 0 | 1 |
ワンホット エンコーディングを列の値に接続
ワンホット エンコードされた値をデータセット内の別の列に接続する必要がある場合があります。 これを実現するには、「JOIN」操作を使用できます。 次のデータを含む別のテーブルがあるとします。
| id | value |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
| 4 | 40 |
ワンホット エンコードされた値を「値」列に接続するには、次の SQL クエリを使用できます。
WITH one_hot_encoded AS (
SELECT
id,
CASE WHEN category = 'A' THEN 1 ELSE 0 END AS category_A,
CASE WHEN category = 'B' THEN 1 ELSE 0 END AS category_B,
CASE WHEN category = 'C' THEN 1 ELSE 0 END AS category_C
FROM
your_table
)
SELECT
ohe.id,
ohe.category_A,
ohe.category_B,
ohe.category_C,
t.value
FROM
one_hot_encoded ohe
JOIN
your_other_table t
ON
ohe.id = t.id;このクエリは、ワンホット エンコードされた列が「値」列に接続されたテーブルを返します。
| id | one_hot_vector |
|---|---|
| 1 | 100 |
| 2 | 010 |
| 3 | 100 |
| 4 | 001 |
SQL でホット エンコードされたベクトルを 1 つ作成します
SQL でワンホット エンコードされたベクトルを作成するには、CONCAT 関数を CASE ステートメントと一緒に使用できます。 次の例を検討してください。
SELECT
id,
CONCAT(
CASE WHEN category = 'A' THEN '1' ELSE '0' END,
CASE WHEN category = 'B' THEN '1' ELSE '0' END,
CASE WHEN category = 'C' THEN '1' ELSE '0' END
) AS one_hot_vector
FROM
your_table;
このクエリは、次のように 1 つのホット エンコードされたベクトルを含むテーブルを生成します。
| id | one_hot_vector |
|---|---|
| 1 | 100 |
| 2 | 010 |
| 3 | 100 |
| 4 | 001 |
FAQ: One Hot Encoding のテクニックとアプリケーション
Q: Python で pandas を使用して 1 つのホット エンコーディングを実行するにはどうすればよいですか?
A: pandas で 1 つのホット エンコーディングを実行するには、pd.get_dummies() 関数を使用します。 データフレームとエンコードする列を引数として渡します。
Q: scikit-learn を使用して 1 つのホット エンコーディングを適用するにはどうすればよいですか?
A: 1 つのホット エンコーディングに scikit-learn を使用するには、OneHotEncoder クラスを利用します。 クラスをインスタンス化し、エンコーダーをカテゴリ データに適合させてから、データをワンホット エンコード形式に変換します。
Q: ワンホット エンコーディングとラベル エンコーディングの違いは何ですか?
A: ワン ホット エンコーディングは、カテゴリ変数をバイナリ形式に変換し、一意のカテゴリごとに個別の列を作成します。 対照的に、ラベル エンコーディングでは、一意の各カテゴリに整数値が割り当てられ、データが 1 つの列に保持されます。 機械学習アルゴリズムでは、カテゴリ間の順序関係の仮定を回避するために、一般に 1 つのホット エンコーディングが推奨されます。
Q: R で 1 つのホット エンコーディングを実行できますか?
A: はい。caret パッケージの dummyVars() 関数を使用して、R で 1 つのホット エンコーディングを実行できます。 データセットと、引数としてエンコードされるカテゴリ変数を指定します。
Q: 1 つのホット エンコーディングは機械学習でどのように使用されますか?
A: 1 つのホット エンコーディングを使用して、カテゴリ変数を、機械学習アルゴリズムで簡単に理解できる数値形式に変換します。 データの前処理に役立ち、モデル内でカテゴリの特徴が正確に表現されるようにします。
Q: PySpark で 1 つのホット エンコーディングを実装するにはどうすればよいですか?
A: PySpark で 1 つのホット エンコーディングを実行するには、pyspark.ml.feature モジュールの StringIndexer クラスと OneHotEncoder クラスを使用します。 最初に、StringIndexer を使用してカテゴリ列にインデックスを付け、次に OneHotEncoder を適用して、インデックス付きデータをワンホット エンコード形式に変換します。
Q: すべての種類のカテゴリ変数に 1 つのホット エンコーディングを使用できますか?
A: 1 つのホット エンコーディングは、名義型と順序型の両方のカテゴリ変数に適しています。 ただし、順序変数の場合、カテゴリ間の順序関係が分析または機械学習モデルにとって重要ではないことを確認してください。
Q: PyTorch で 1 つのホット エンコーディングを適用するにはどうすればよいですか?
A: PyTorch で 1 つのホット エンコーディングを実行するには、torch.nn.functional.one_hot() 関数を使用します。 入力テンソルとクラス数を引数として指定します。
結論
結論として、1 つのホット エンコーディングは、機械学習とデータ分析のワークフローでカテゴリ データを処理するための貴重な手法です。 SQL と Python で 1 つのホット エンコーディングを実装する方法を理解することで、データの前処理スキルを向上させ、データからより優れた洞察を得ることができます。 さらに、RATH などのツールを使用すると、分析プロセスを合理化し、見事なビジュアライゼーションを簡単に作成できます。