Pandas で簡単にピボット テーブルを作成する方法

- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
ピボットテーブルとは?
ピボット テーブルは、データ分析で使用されるデータ要約ツールです。 行から列へ、またはその逆にデータを変換し、データに対して計算を実行できます。 ピボット テーブルは、大規模なデータセットの要約と分析に役立ち、パターンと傾向を簡単に識別できます。
データ分析でピボット テーブルを使用する利点
ピボット テーブルは、データ分析において次のような多くの利点を提供します。
- 柔軟性: ピボット テーブルを簡単に調整して、さまざまな次元のデータを分析できます。 ユーザーは、行、列、およびフィルターを追加、削除、または再編成して、データに対するさまざまな洞察を得ることができます。
- 効率: ピボット テーブルは大量のデータをすばやく要約できるため、データの分析と洞察が容易になります。
- 集計: ピボット テーブルは、合計、カウント、平均など、データに対して複雑な計算を実行できます。
- 視覚化: ピボット テーブルは視覚的に魅力的な方法でデータを表示できるため、洞察を解釈して他のユーザーに伝えることが容易になります。
Pandas でピボット テーブルを作成する
ピボット テーブルを作成するための基本的な構文
Pandas でピボット テーブルを作成するには、pivot() メソッドを使用できます。 ピボット テーブルを作成するための基本的な構文は次のとおりです。
import pandas as pd
df = pd.read_csv('filename.csv')
pivot_table = df.pivot(index='column1', columns='column2', values='column3')Pandas で pivot_table() メソッドを使用する
Pandas でピボット テーブルを作成する別の方法は、pivot_table() メソッドを使用することです。 この方法は柔軟性が高く、より複雑な計算を実行できます。 pivot_table() メソッドを使用するための基本的な構文は次のとおりです。
pivot_table = pd.pivot_table(df, values='column3', index='column1', columns='column2', aggfunc='mean')Pandas のピボット テーブルの例
1. マルチレベル ピボット テーブル
マルチレベル ピボット テーブルは、複数レベルの行または列ラベルを持つピボット テーブルです。 これにより、複数の方法でデータをグループ化および要約できます。 Pandas で複数レベルのピボット テーブルを作成する例を次に示します。
pivot_table = df.pivot_table(values='column3', index=['column1', 'column2'], columns='column4', aggfunc='sum')2. 集計なしのピボット テーブル
集計を実行せずにピボット テーブルを作成したい場合があります。 これは、一意の値のテーブルを作成したり、データの分布を確認したりするのに役立ちます。 集計なしでピボット テーブルを作成する例を次に示します。
pivot_table = df.pivot_table(index='column1', columns='column2', fill_value=0)3. 複数の列を持つピボット テーブル
複数の列を持つピボット テーブルを作成することもできます。 これにより、複数のデータ列に対して計算を実行できます。 複数の列を持つピボット テーブルを作成する例を次に示します。
pivot_table = df.pivot_table(values=['column3', 'column4'], index='column1', columns='column2', aggfunc='sum')4. ピボット テーブルを Excel にエクスポートする
Pandas でピボット テーブルを作成した後、それを Excel にエクスポートして、さらに分析したり、他のユーザーと共有したりすることができます。 Pandas では、to_excel() メソッドを使用して、ピボット テーブルを Excel に簡単にエクスポートできます。
to_excel() メソッドは、DataFrame を Excel ファイルにエクスポートします。 デフォルトでは、メソッドは DataFrame を Excel ファイルの最初のシートに書き込みますが、sheet_name パラメーターを使用してシート名を指定できます。 float_format、header、index などの追加パラメーターを渡すことで、Excel ファイルの書式設定をカスタマイズすることもできます。
ピボット テーブルを Excel にエクスポートするには、pivot_table() メソッドによって返された DataFrame で to_excel() メソッドを呼び出すだけです。 以下に例を示します。
import pandas as pd
# create a DataFrame
df = pd.read_csv('sales_data.csv')
# create a Pivot Table
pivot_table = df.pivot_table(index='Region', columns='Product', values='Sales', aggfunc='sum')
# export the Pivot Table to Excel
pivot_table.to_excel('sales_pivot_table.xlsx')この例では、売上データを含む CSV ファイルを DataFrame に読み込みます。 次に、「pivot_table()」メソッドを使用して、インデックスを「Region」に設定し、列を「Product」に設定し、値を「Sales」に設定し、集計関数を「sum」に設定して、ピボット テーブルを作成します。 最後に、ピボット テーブルを「sales_pivot_table.xlsx」という名前の Excel ファイルにエクスポートします。
デフォルトでは、to_excel() メソッドは行と列のラベルをデータ値とともに Excel ファイルに書き込みます。 行または列のラベルを除外する場合は、インデックスまたは列のパラメーターをそれぞれ False に設定できます。
# export the Pivot Table to Excel without row labels
pivot_table.to_excel('sales_pivot_table.xlsx', index=False)
# export the Pivot Table to Excel without column labels
pivot_table.to_excel('sales_pivot_table.xlsx', columns=False)さらに、float_format、header、index などの他のパラメーターを使用して、Excel ファイルの書式設定をカスタマイズできます。 たとえば、float_format パラメータを使用して、データ値を表示する小数点以下の桁数を指定できます。
# export the Pivot Table to Excel with two decimal places for data values
pivot_table.to_excel('sales_pivot_table.xlsx', float_format='%.2f')PyGWalker を使用して Python Pandas でピボット テーブルを視覚化する
Python Pandas 内でデータを視覚化する場合は、PyGWalker というオープン ソースのデータ分析とデータ視覚化パッケージを利用できます。 PyGWalker は、Jupyter Notebook のデータ分析とデータ視覚化のワークフローを簡素化できます。 Python を使用してデータを分析する代わりに、軽量で使いやすいインターフェイスを導入することで。
PyGWalker はオープン ソースです。 PyGWalker GitHub ページ (opens in a new tab) をチェックアウトし、データ サイエンスに向けた記事 (opens in a new tab) です。
PyGWalker を今すぐテストするには、Google Colab (opens in a new tab)、Binder (opens in a new tab) または Kaggle (opens in a new tab)
PyGWalker の使用を開始するには、pygwalker と pandas を Jupyter Notebook にインポートします。
import pandas as pd
import pygwalker as pyg既存のワークフローを変更せずに pygwalker を使用できます。 たとえば、次の方法でロードされたデータフレームで Graphic Walker を呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Pandas データフレームをエクスポートし、使いやすい UI でテーブルを視覚化できるようになりました。
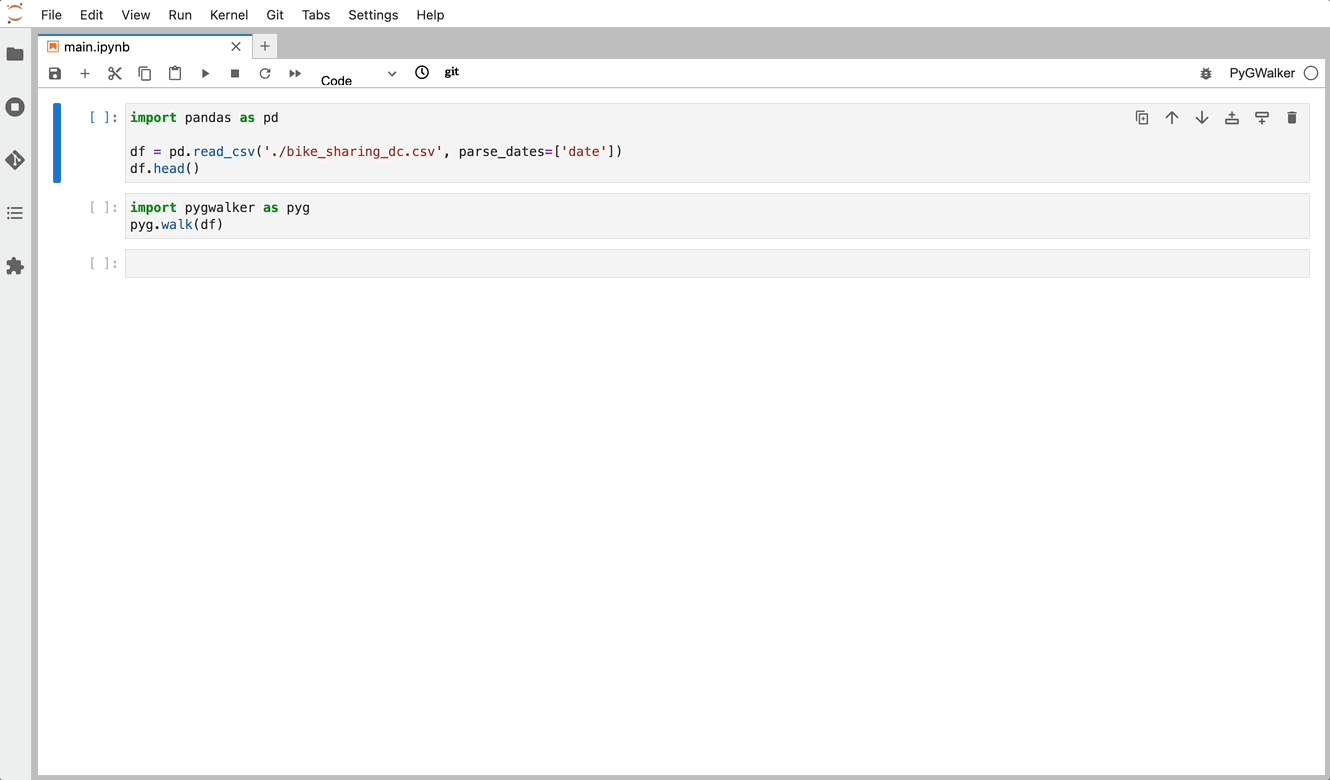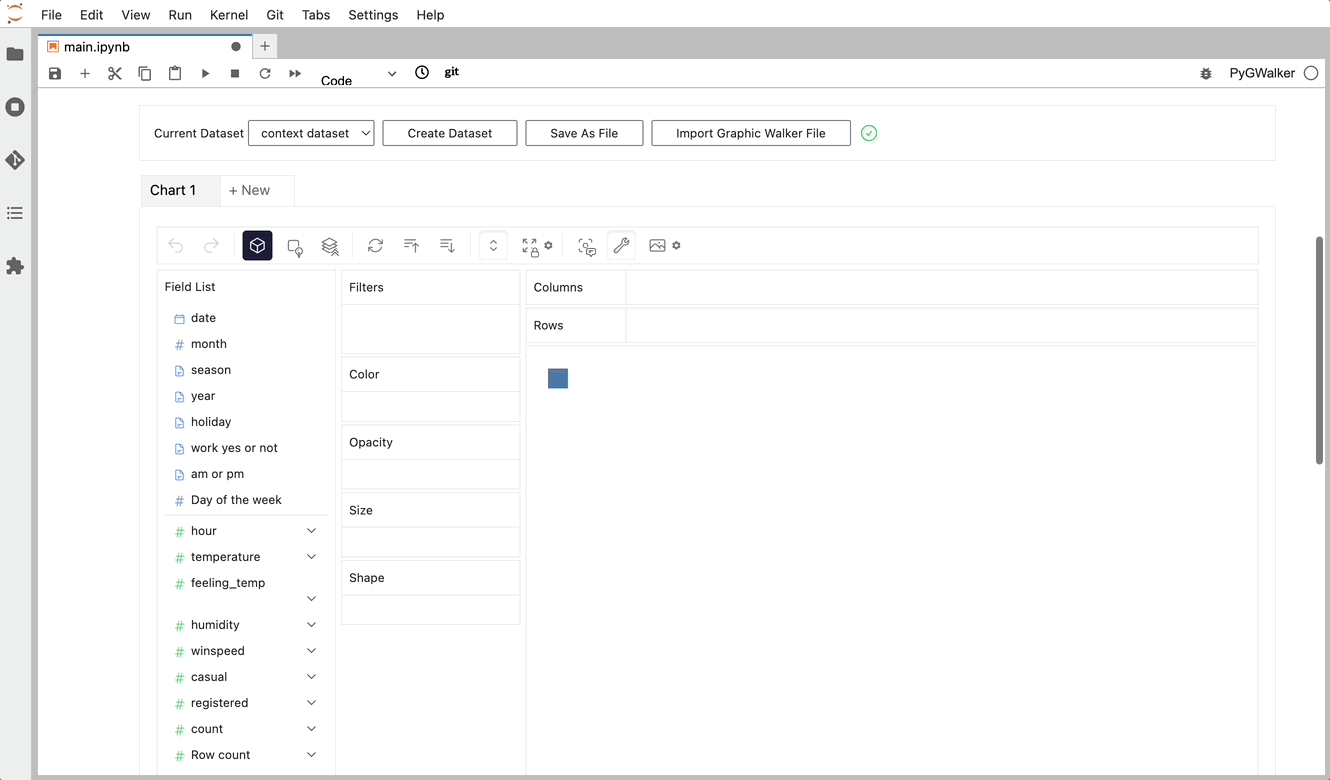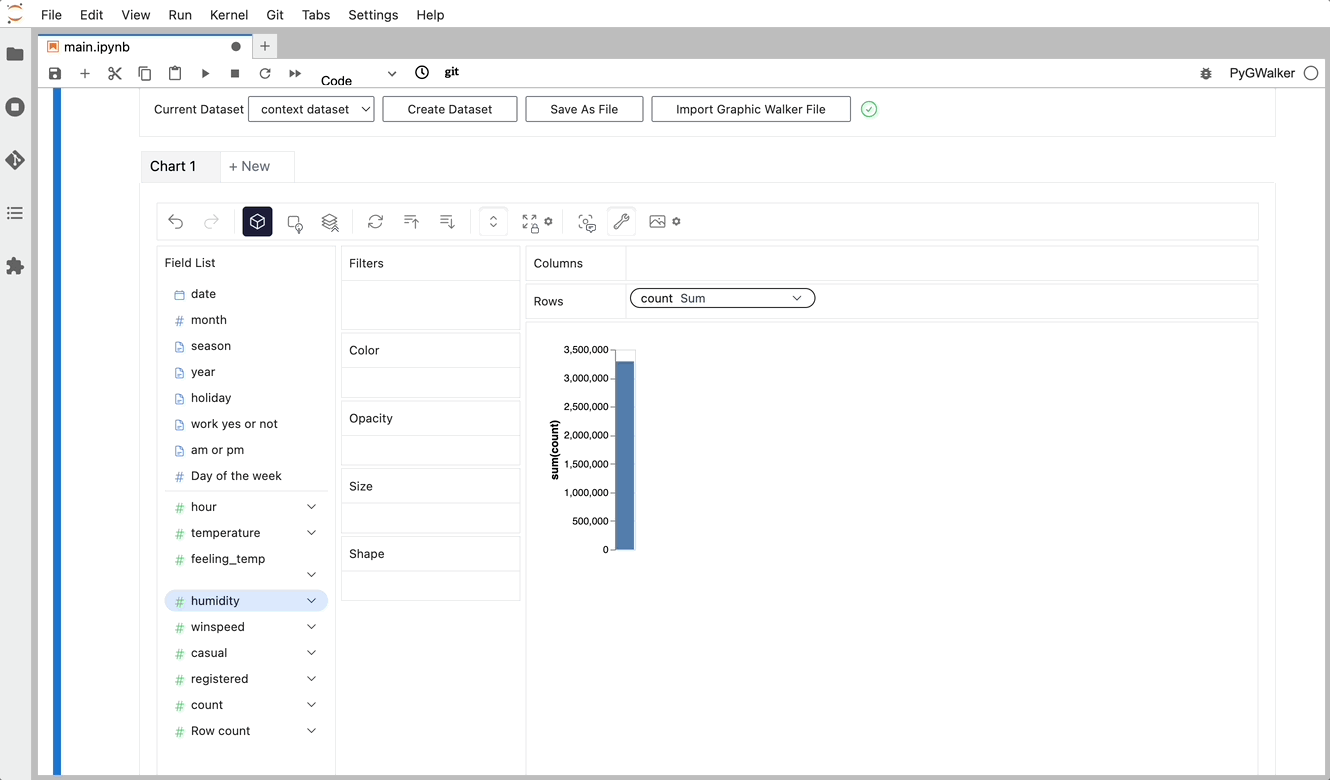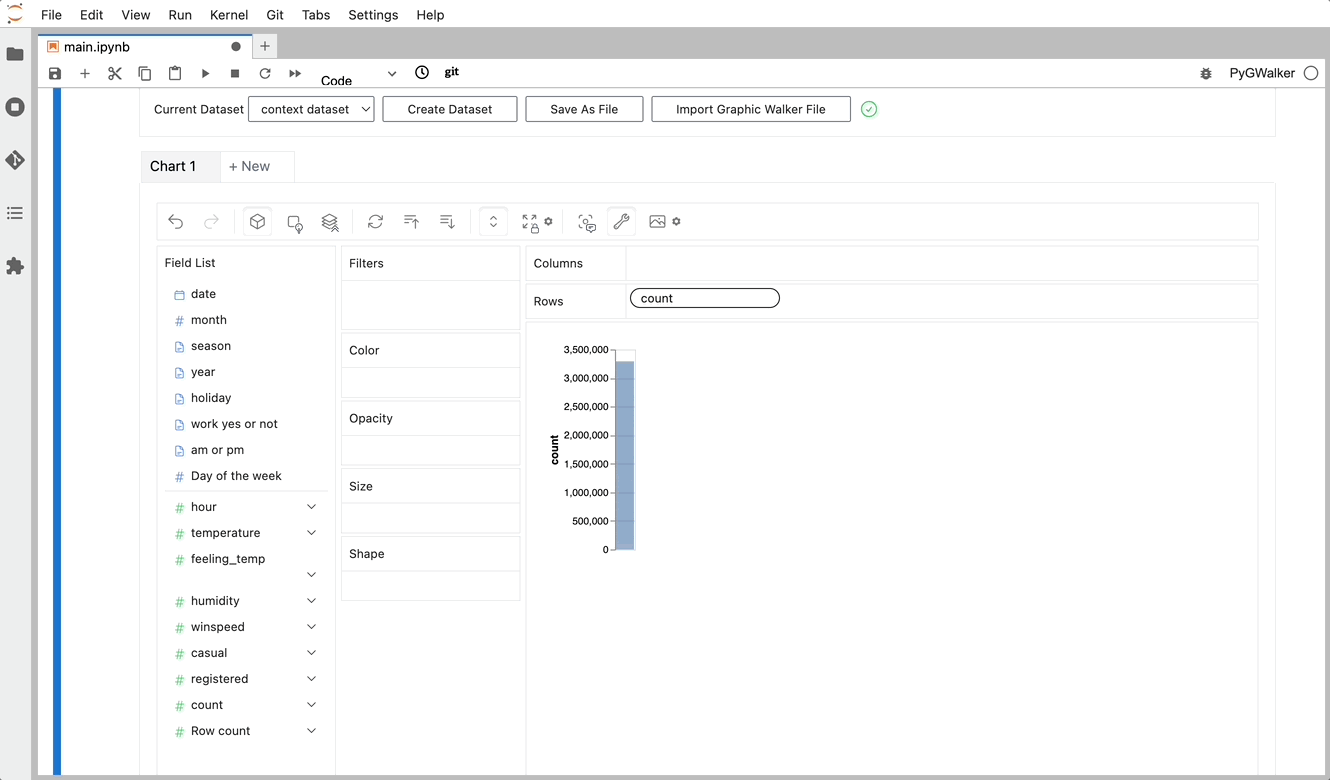
単にデータを視覚化するだけでなく、視覚化をクリックするだけで PyGWalker をデータ探索に使用して、自動生成された洞察を取得することもできます。
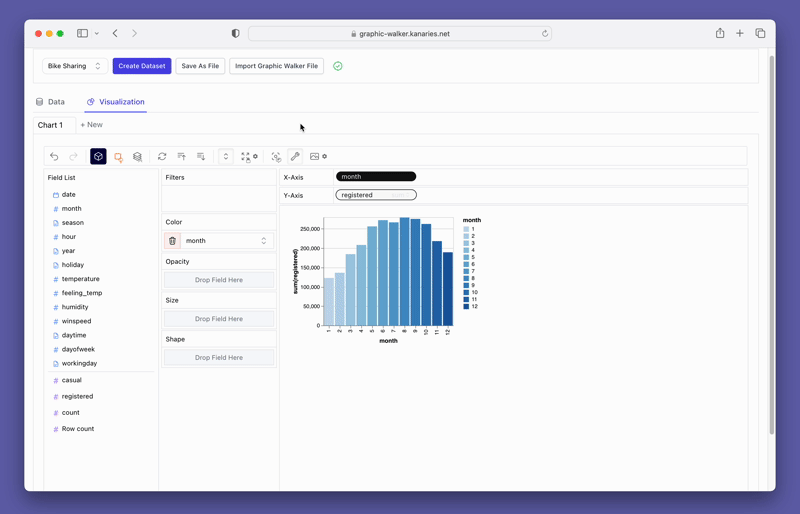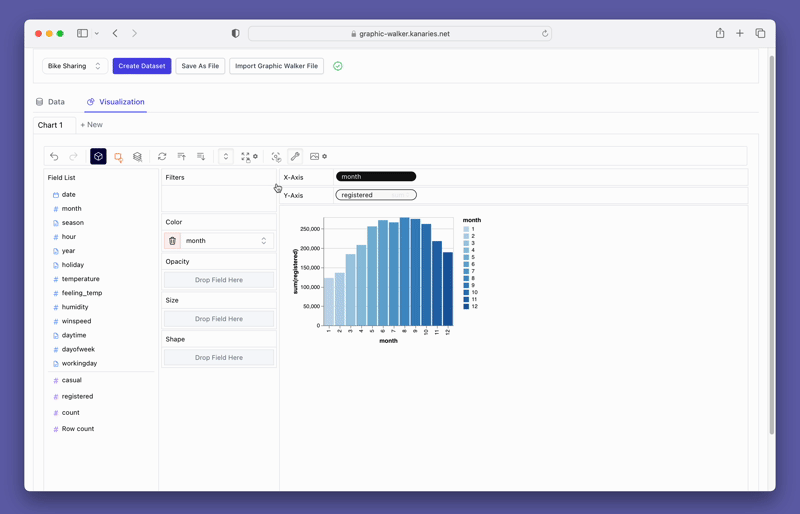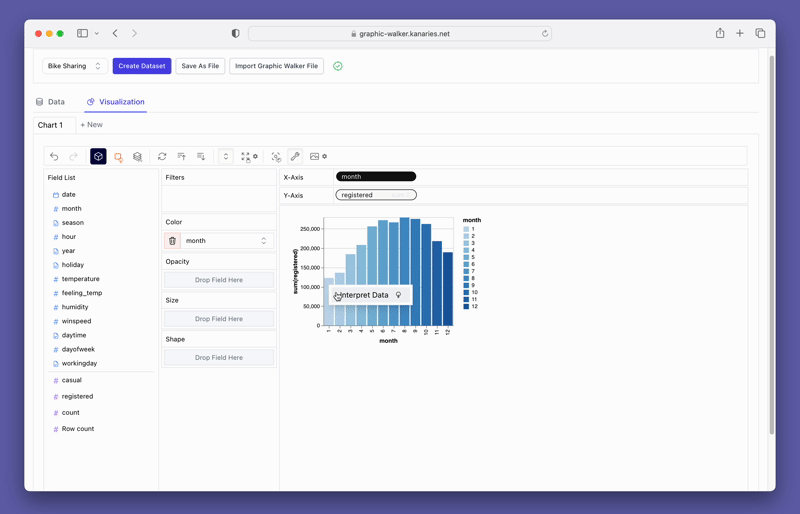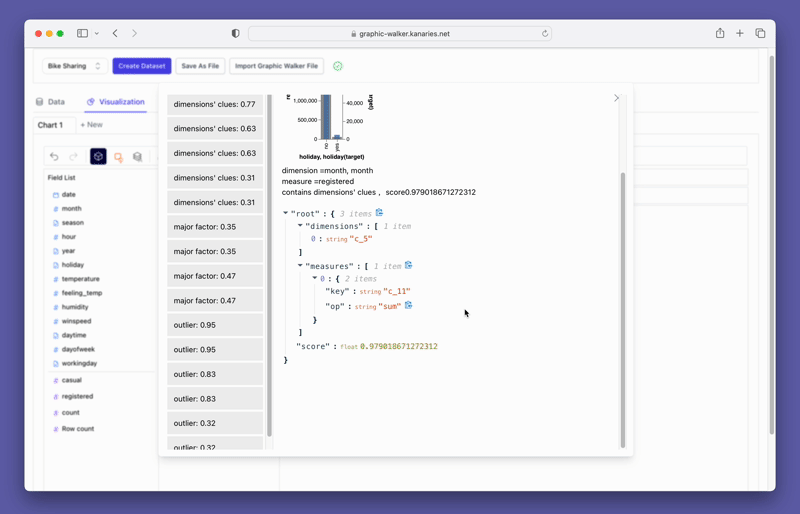
より高度な AI を活用した自動データ分析ツール RATH (opens in a new tab) を忘れずにチェックしてください。 RATH もオープンソースであり、GitHub のソース コード (opens in a new tab) をホストしています。
結論
この記事では、データ分析における CSV ファイルの重要性と、Pandas でピボット テーブルを作成する方法について説明しました。 ピボット テーブルを作成するための基本的な構文、pivot_table() メソッドの使用方法、Pandas でのさまざまな種類のピボット テーブルの例について説明しました。 さらに、ピボット テーブルとそのカスタマイズ方法に関するいくつかの一般的な質問に回答しました。
この記事が、Pandas のピボット テーブルの世界を紹介するのに役立つことを願っています。 Pandas の公式ドキュメントやさまざまなオンライン コースやチュートリアルなど、学習の旅を続けるのに役立つ多くのリソースをオンラインで利用できます。 ピボット テーブルの探索と実験を続けて、データに対する新しい洞察を獲得してください。