PandasのDataFrameをPythonでマージ、結合、連結する方法

PandasのDataFrameをマージ、結合、連結することは、複数のデータセットを1つに結合するための重要な技術です。これらの技術は、データのクリーニング、変換、分析に必須です。マージ、結合、連結はしばしば同義語として使用されますが、データを結合するための異なる方法を指します。この記事では、これら3つの重要なテクニックについて詳しく説明し、Pythonでそれらを使用する例を提供します。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
PandasでのDataFrameのマージ
マージとは、1つまたは複数のDataFrameを、1つまたは複数の共通キーに基づいて行をリンクすることで、1つのDataFrameに結合するプロセスのことです。共通キーは、マージされるDataFrameの中で一致する値を持つ1つ以上の列です。
結合の異なるタイプ
pandasには、内部結合、外部結合、左結合、右結合の4つの結合タイプがあります。
- 内部結合:両方のDataFrameで一致する値の行のみを返します。
- 外部結合:両方のDataFrameのすべての行を返し、一致しない値の場所にはNaNで値を埋めます。
- 左結合:左のDataFrameのすべての行と右のDataFrameの一致する行を返します。一致しない値の場所にはNaNで値を埋めます。
- 右結合:右のDataFrameのすべての行と左のDataFrameの一致する行を返します。一致しない値の場所にはNaNで値を埋めます。
異なるタイプの結合を行う例
Pandasを使用してさまざまなタイプの結合を行う例を見てみましょう。
例1:内部結合
import pandas as pd
# 2つのDataFrameを作成する
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# 内部結合
merged_inner = pd.merge(df1, df2, on='key')
print(merged_inner)出力:
key value_x value_y
0 B 2 5
1 D 4 6例2:外部結合
import pandas as pd
# 2つのDataFrameを作成する
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# 外部結合
merged_outer = pd.merge(df1, df2, on='key', how='outer')
print(merged_outer)出力:
key value_x value_y
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0例3:左結合
左結合は、左のDataFrameのすべての行と右のDataFrameの一致する行を返します。左のDataFrameの中で右のDataFrameと一致しない行は、右のDataFrameの列の場所にNaNの値が入ります。
import pandas as pd
# 2つのDataFrameを作成する
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 左結合を実行する
left_merged_df = pd.merge(df1, df2, on='key', how='left')
# 結合されたDataFrameを表示する
print(left_merged_df)出力:
key value_x value_y
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0例4:右結合
右結合は、右のDataFrameのすべての行と左のDataFrameの一致する行を返します。右のDataFrameの中で左のDataFrameと一致しない行は、左のDataFrameの列の場所にNaNの値が入ります。
import pandas as pd
# 2つのDataFrameを作成する
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 右結合を実行する
right_merged_df = pd.merge(df1, df2, on='key', how='right')
# 結合されたDataFrameを表示する
print(right_merged_df)出力:
key value_x value_y
0 B 2.0 5
1 D NaN 6
2 E NaN 7PandasでのDataFrameの結合
結合は、インデックスや列の値に基づいて2つのDataFrameを1つに結合する方法です。
pandasには、内部結合、外部結合、左結合、右結合といった4つの結合タイプがあります。
- 内部結合:インデックスや列の値の両方のDataFrameで一致する行のみを返します。
- 外部結合:両方のDataFrameのすべての行を返し、一致しない値の場所にはNaNで値を埋めます。
- 左結合:左のDataFrameのすべての行と右のDataFrameの一致する行を返します。一致しない値の場所にはNaNで値を埋めます。
- 右結合:右のDataFrameのすべての行と左のDataFrameの一致する行を返します。一致しない値の場所にはNaNで値を埋めます。
PandasでのDataFrameの連結
連結は、2つ以上のDataFrameを垂直または水平に結合するプロセスです。pandasでは、concat()関数を使用してこれを実現できます。concat()関数により、2つ以上のDataFrameを垂直または水平に積み重ねて1つのDataFrameに結合することができます。
pandasを使用して2つ以上のDataFrameを連結する例
複数のDataFrameを垂直に連結するには、次のコードを使用できます。
import pandas as pd
# サンプルのDataFrameを作成する
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
# DataFrameを垂直に連結する
result = pd.concat([df1, df2])
print(result)出力結果:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7複数のDataFrameを水平に連結するには、次のコードを使用できます。
import pandas as pd
# サンプルのDataFrameを作成する
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'E': ['E0', 'E1', 'E2', 'E3'],
'F': ['F0', 'F1', 'F2', 'F3'],
'G': ['G0', 'G1', 'G2', 'G3'],
'H': ['H0', 'H1', 'H2', 'H3']})
# DataFrameを水平に連結する
result = pd.concat([df1, df2], axis=1)
print(result)出力結果:
A B C D E F G H
0 A0 B0 C0 D0 E0 F0 G0 H0
1 A1 B1 C1 D1 E1 F1 G1 H1
2 A2 B2 C2 D2 E2 F2 G2 H2Panda Dataframesのための結合ビューを作成する
Python内で結合ビューを作成するためのオープンソースのデータ分析およびデータ可視化パッケージがあります: PyGWalker。
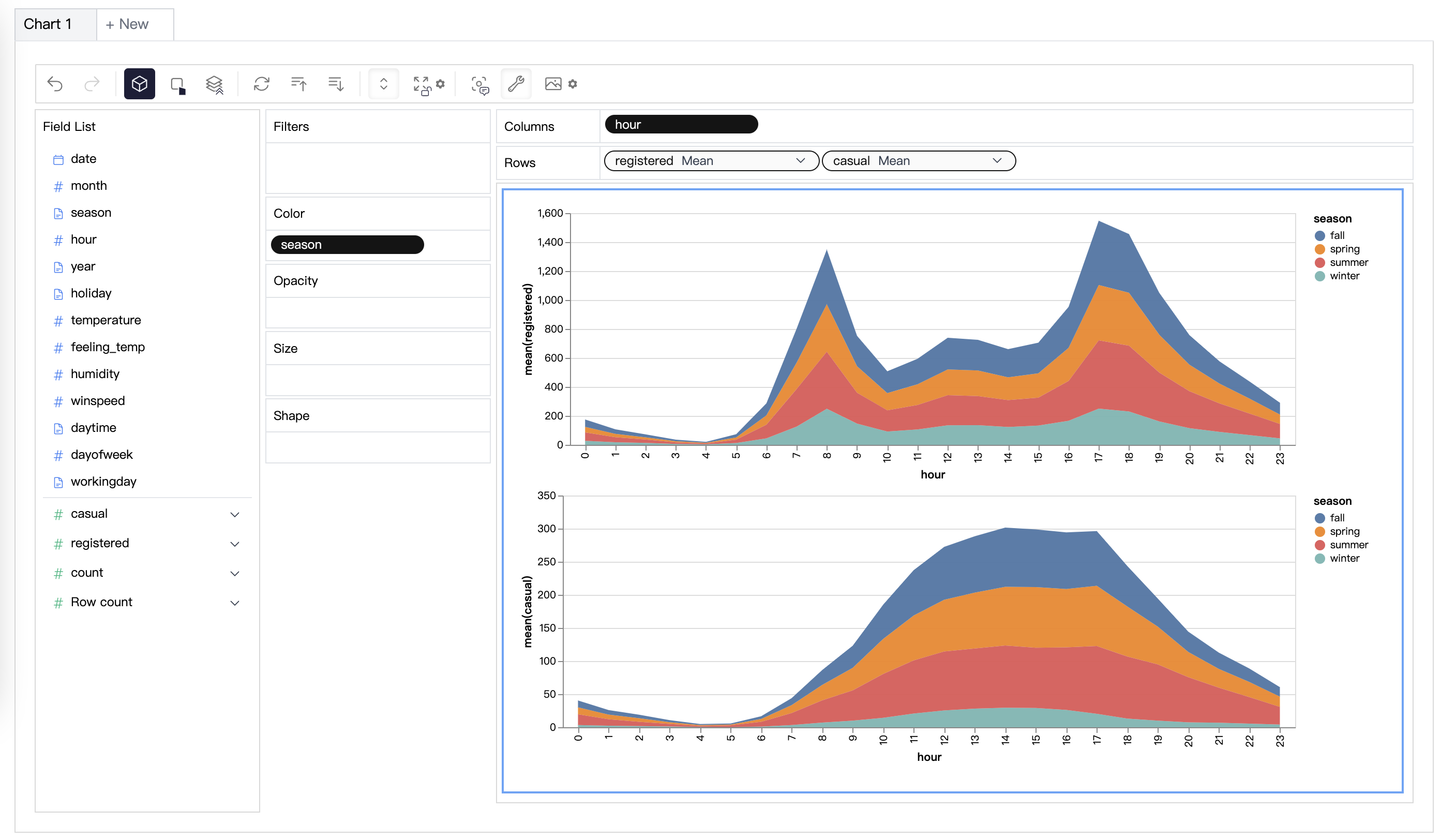
PyGWalkerは、Jupyter Notebookのデータ分析およびデータ可視化ワークフローを簡素化することができます。Pythonを使ってデータを分析する代わりに、軽量で使いやすいインターフェースを提供します。以下の手順で簡単に実行できます:
まず、Jupyter Notebookにpygwalkerとpandasをインポートします。
import pandas as pd
import pygwalker as pyg既存のワークフローを変更せずにpygwalkerを使用できます。例えば、次のようにデータフレームを読み込む方法でGraphic Walkerを呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)これで、使いやすいユーザーインターフェースでPandas Dataframeを視覚化できます!
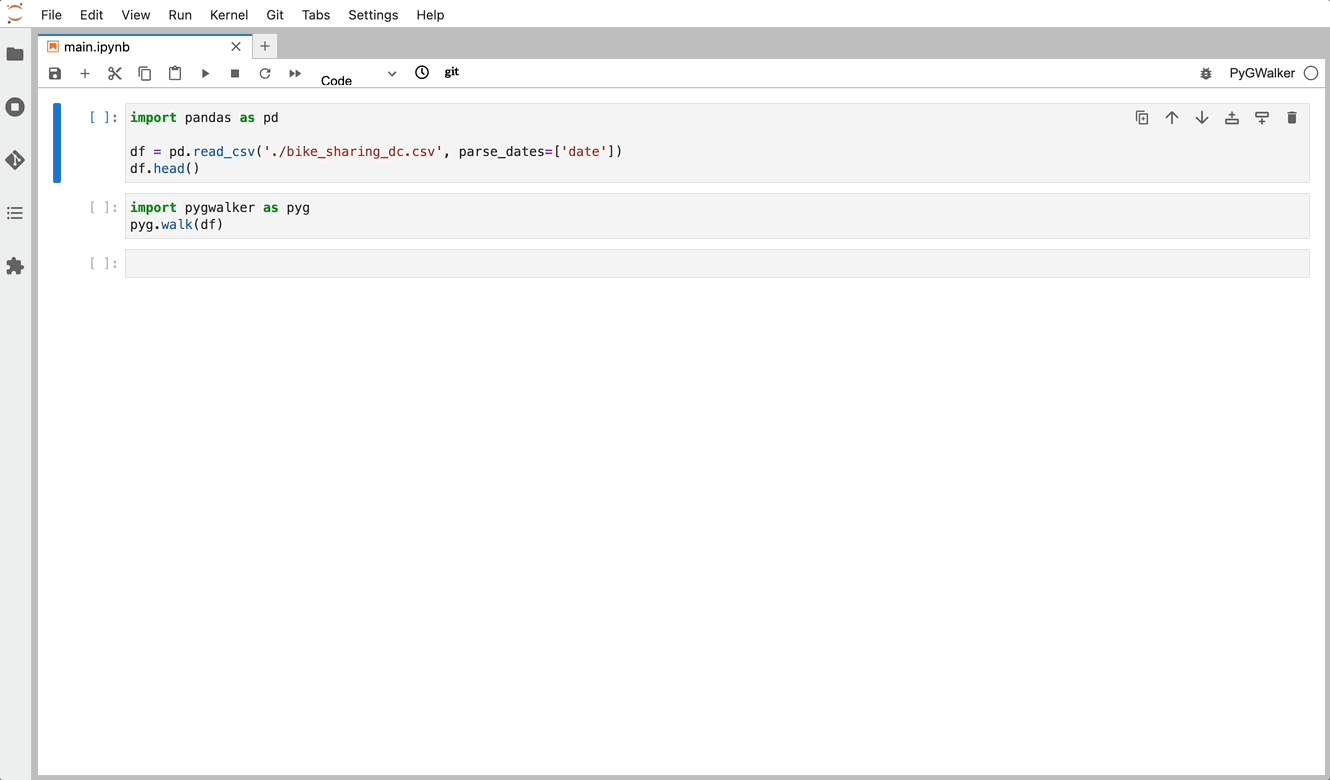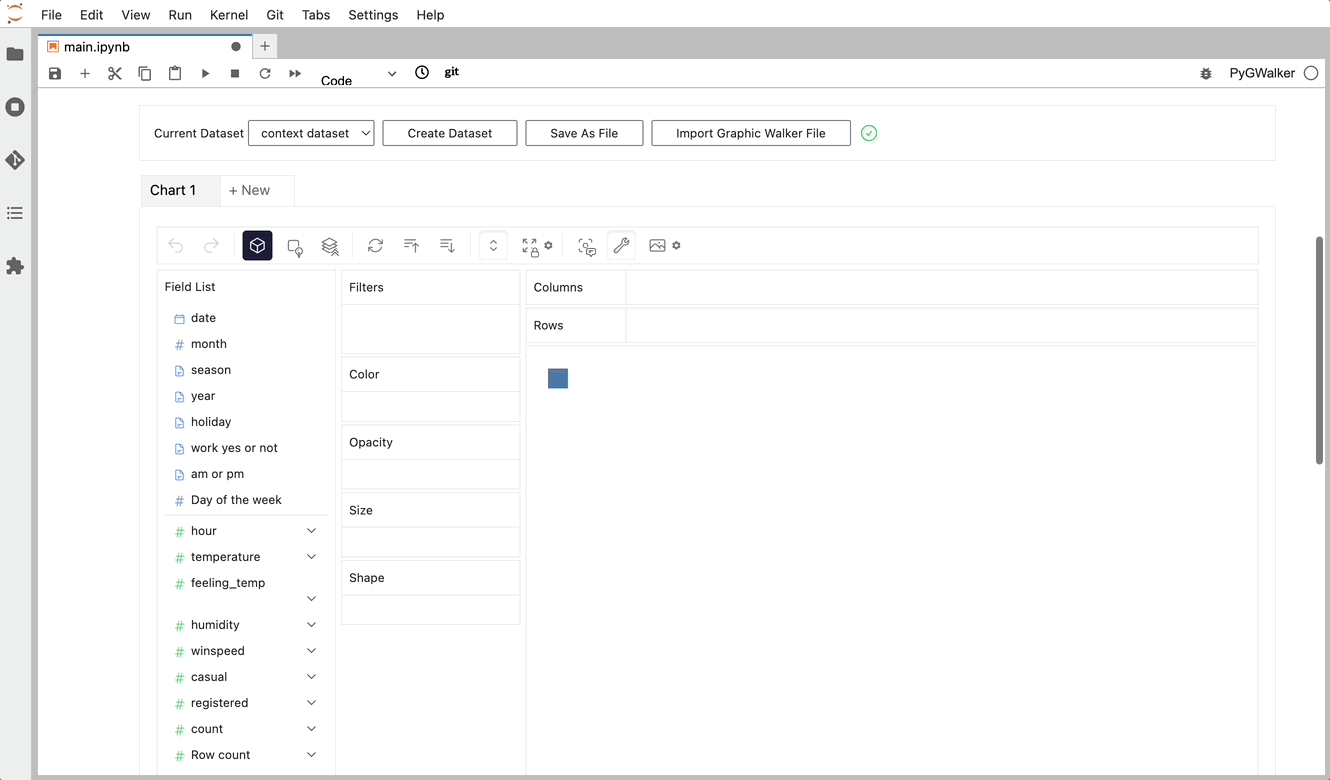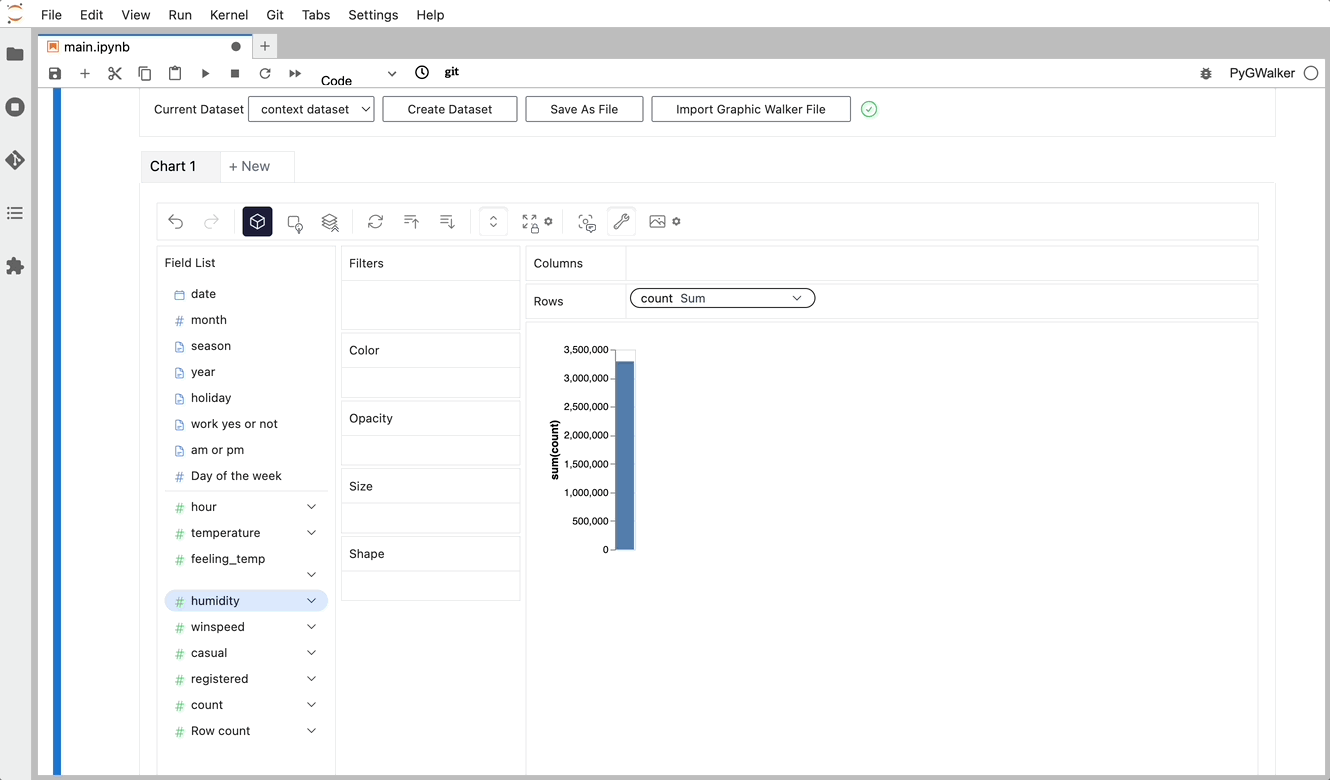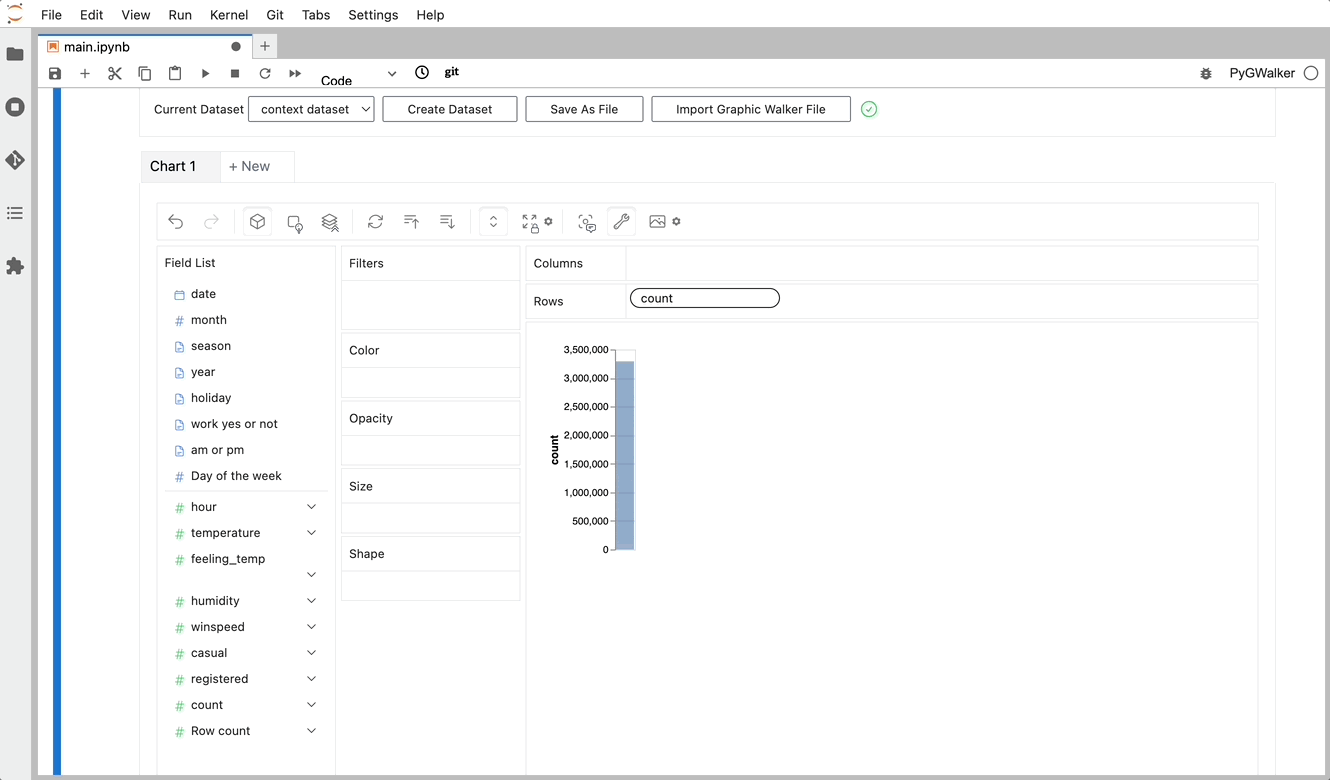
変数をドラッグアンドドロップするだけで簡単にConcat Viewを作成できます:
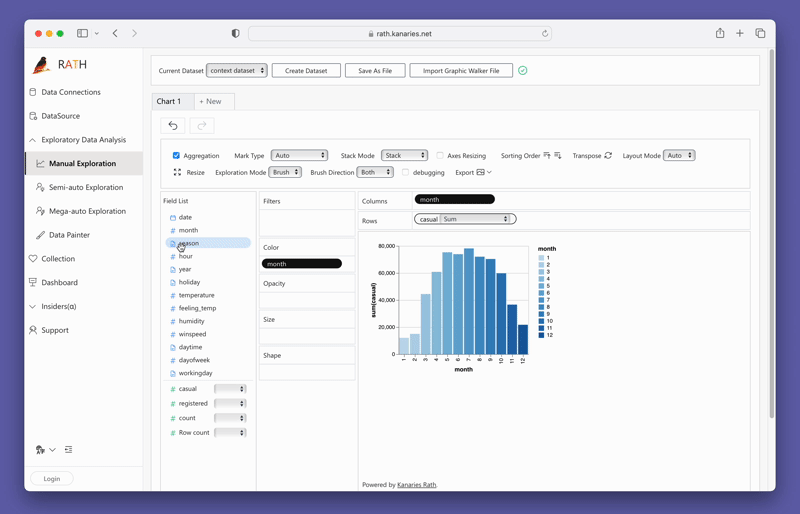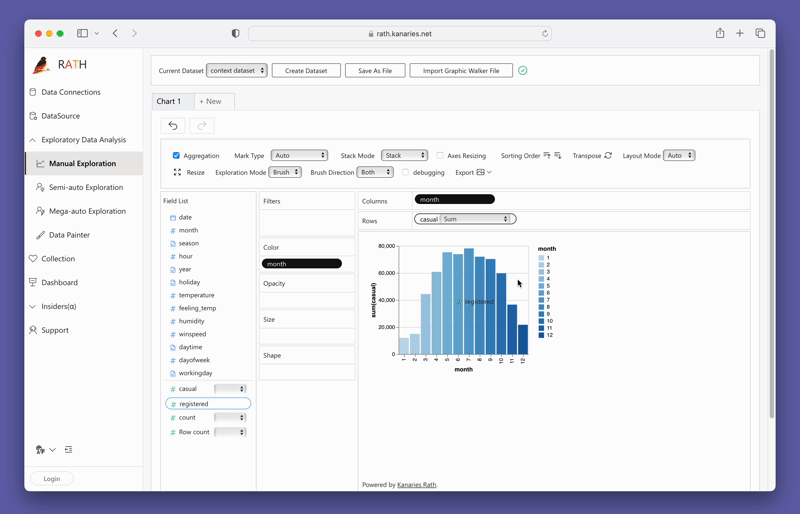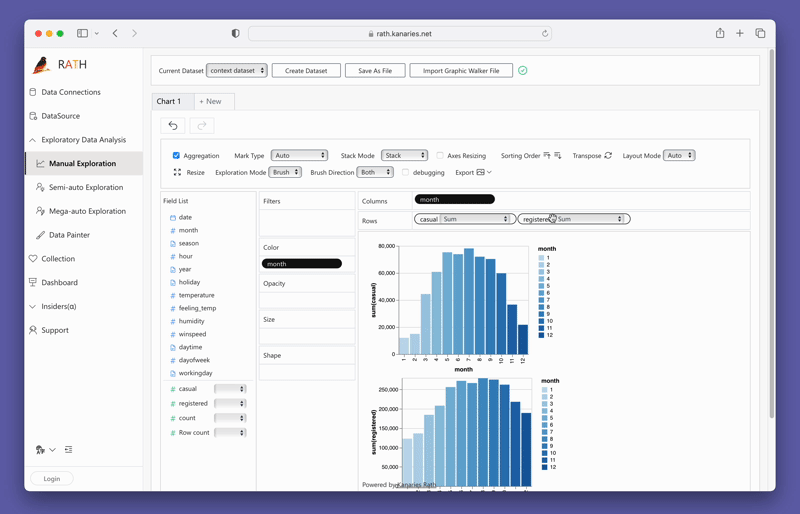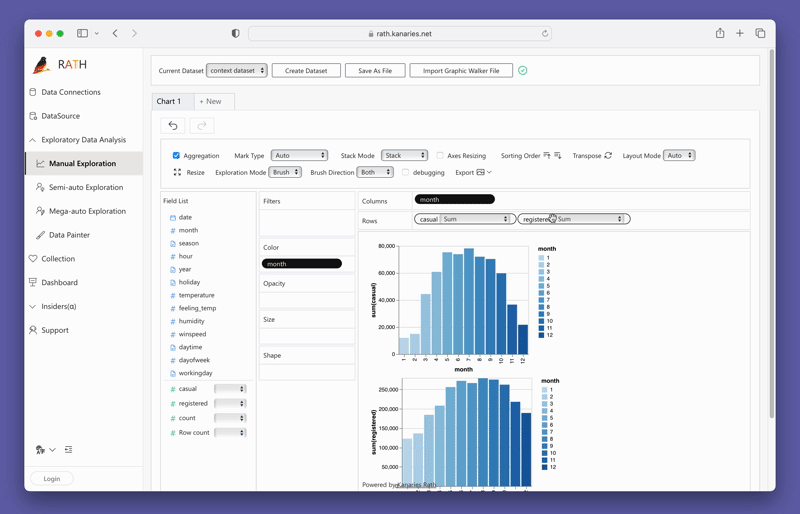
PyGWalkerを今すぐ試すには、Google Colab (opens in a new tab)、Binder (opens in a new tab)、またはKaggle (opens in a new tab)でPyGWalkerを実行できます。
PyGWalkerはオープンソースです。PyGWalkerのGitHubページ (opens in a new tab)をチェックし、Towards Data Science Article (opens in a new tab)を読むことができます。
より高度な、AIを活用した自動化データ分析ツールRATH (opens in a new tab)もぜひチェックしてください。RATHもオープンソースで、そのソースコードはGitHubにホスティングされています (opens in a new tab)。
よくある質問
PySparkを使用して2つのDataFrameを結合するにはどうすればよいですか?
PySparkはオープンソースのビッグデータ処理フレームワークであり、Python、Java、Scala、Rのいずれかでデータ処理アプリケーションを書くことができます。PySparkを使用して2つのDataFrameを結合するには、2つのDataFrameオブジェクトとオプションの結合式を指定するjoin()メソッドを使用できます。結合のタイプはhowパラメータを使用して指定することができます。
Rを使用して2つのDataFrameをマージするにはどうすればよいですか?
Rを使用して2つのDataFrameをマージするには、merge()関数を使用します。この関数は2つのデータフレームと、データのマージ方法を指定するオプションの引数セットを受け取ります。
pandasで2つ以上のDataFrameを追加するにはどうすればよいですか?
pandasで2つ以上のDataFrameを追加するには、concat()関数を使用します。この関数は、DataFramesのリストと、データフレームを連結する軸を指定するオプションのaxisパラメータを受け取ります。
pandasを使用して共通の列に基づいて2つのDataFrameを結合するにはどうすればよいですか?
pandasを使用して共通の列に基づいて2つのDataFrameを結合するには、merge()関数を使用します。この関数は2つのDataFrameと、データのマージ方法を指定するオプションの引数セットを受け取ります。結合する列はonパラメータを使用して指定することができます。
結論
データ分析においてDataFrameをマージ、結合、連結することは重要な操作です。pandas、PySpark、Rなどの強力なツールの助けを借りて、これらの操作は簡単かつ効率的に実行することができます。大規模なデータセットや小規模なデータセットに対して、これらのツールは柔軟で直感的な方法でデータを操作する方法を提供しています。