Pandas で CSV ファイルを読み取る方法 - 初心者向けの必須ガイド

あなたがデータ サイエンティストであれば、おそらくさまざまな形式の大規模なデータセットを扱っているでしょう。 データを保存するための最も一般的な形式の 1 つは、CSV (Comma Separated Values) ファイルです。 この記事では、Pandas で CSV ファイルを読み取る方法を紹介します。Pandas は、データの操作と分析のための一般的な Python ライブラリです。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
パンダとは?
Pandas (opens in a new tab) は、使いやすいデータ構造とデータ分析ツールを提供するオープンソースの Python ライブラリです。 NumPy ライブラリの上に構築されており、CSV、Excel、SQL データベースなど、さまざまな形式のデータを操作するように設計されています。
Pandas で CSV ファイルを読み取る
Pandas で CSV ファイルを読み取るには、read_csv() 関数を使用します。 次に例を示します。
import pandas as pd
df = pd.read_csv('data.csv')このコードは、「data.csv」という名前の CSV ファイルを読み取り、「df」という名前の Pandas DataFrame に保存します。 「read_csv()」関数は、列のデータ型を自動的に推測し、さらなる分析に使用できる DataFrame オブジェクトを作成します。
列を選択
CSV ファイルから特定の列のみを読み取る必要がある場合は、usecols パラメータを使用して、読み取る列名またはインデックスのリストを指定できます。 次に例を示します。
df = pd.read_csv('data.csv', usecols=['col1', 'col2'])このコードでは、CSV ファイルから「col1」列と「col2」列のみを読み取ります。
列と行をスキップ
Pandas で CSV ファイルを読み取るときに、特定の列または行をスキップしたい場合があります。 これは、read_csv() 関数の usecols および skiprows パラメータを使用して行うことができます。
usecols パラメータは、CSV ファイルから読み取る列を指定するために使用されます。 列名または列インデックスのリストを取ることができます。
import pandas as pd
# Read CSV file and select specific columns
df = pd.read_csv('data.csv', usecols=['column1', 'column3'])この例では、名前が column1 および column3 の列のみが CSV ファイルから読み取られます。
skiprows パラメータは、CSV ファイルの読み取り中に特定の数の行をスキップするために使用されます。 スキップする行数を指定する整数値、またはスキップする行インデックスのリストを指定できます。
import pandas as pd
# Read CSV file and skip first two rows
df = pd.read_csv('data.csv', skiprows=2)この例では、読み取り中に CSV ファイルの最初の 2 行がスキップされます。
データ型の指定
デフォルトでは、Pandas は CSV ファイルを読み取るときに列のデータ型を推測します。 ただし、dtype パラメータを使用して手動でデータ型を指定することもできます。 次に例を示します。
dtypes = {'col1': 'int32', 'col2': 'float32', 'col3': 'object'}
df = pd.read_csv('data.csv', dtype=dtypes)このコードでは、col1 を整数、col2 を float、col3 を文字列にするように指定しています。
エンコーディングの問題
CSV ファイルには、Pandas で読み取るときに問題を引き起こす可能性があるエンコーディングの問題がある場合があります。 この問題を解決するには、encoding パラメータを使用してファイルのエンコーディングを指定します。 次に例を示します。
df = pd.read_csv('data.csv', encoding='utf-8')このコードでは、CSV ファイルが UTF-8 でエンコードされることを指定します。
CSV を文字列として読み取る
デフォルトでは、Pandas は CSV ファイルを数値型および文字列型として読み取ります。 CSV ファイルを文字列として読み取りたい場合は、dtype パラメータを使用して、すべての列のデータ型を文字列に設定できます。 次に例を示します。
dtypes = {col: 'str' for col in df.columns}
df = pd.read_csv('data.csvこの文から続けて書いてください: デフォルトでは、Pandas は CSV ファイルを数値型および文字列型として読み取ります。 CSV ファイルを文字列として読み取りたい場合は、「dtype」パラメーターを使用して、すべての列のデータ型を文字列に設定できます。 次に例を示します。
Pandas で dtype パラメータを使用して CSV ファイルを文字列として読み取る方法の例を次に示します。
import pandas as pd
# Read CSV file as string
df = pd.read_csv('data.csv', dtype=str)
# Display the data types of all columns
print(df.dtypes)このコードは、data.csv という名前の CSV ファイルを読み取り、すべての列のデータ型を文字列に設定します。 結果の DataFrame オブジェクト df には、すべてのデータが文字列形式で含まれます。
複数の CSV ファイルを読み取る
Pandas では、read_csv() 関数を使用して一度に複数の CSV ファイルを読み取ることもできます。 ファイル パスのリストを関数に渡すと、すべてのファイルのデータを含む DataFrame のリストが返されます。
import pandas as pd
# Read multiple CSV files
files = ['data1.csv', 'data2.csv', 'data3.csv']
dataframes = [pd.read_csv(file) for file in files]この例では、「data1.csv」、「data2.csv」、および「data3.csv」という名前の 3 つの CSV ファイルが読み取られ、結果のリスト データフレームには、すべてのファイルのデータを含む DataFrame が含まれます。
PyGWalker で CSV ファイルを視覚化する
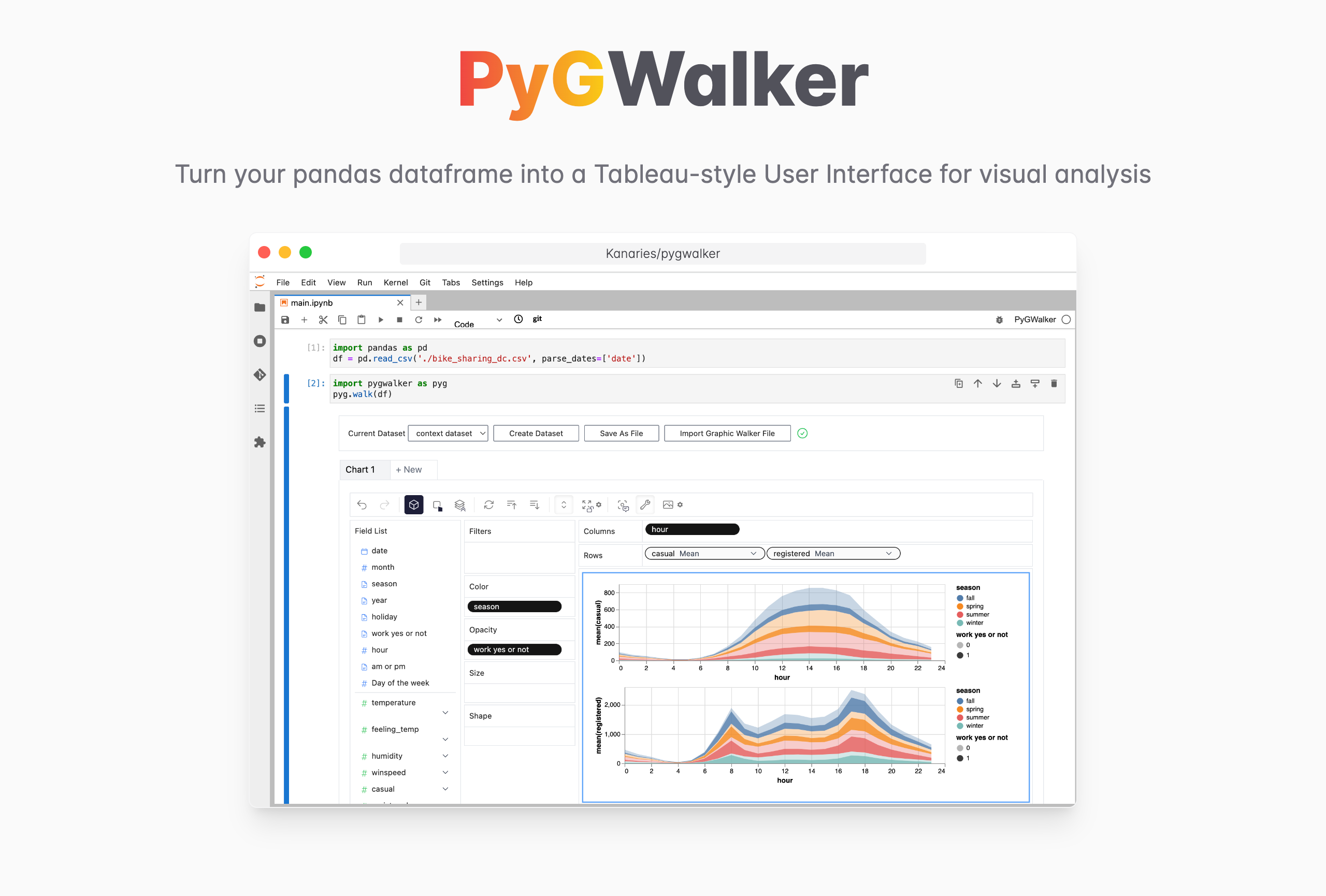
CSV ファイルの読み取りだけにとどまらないのはなぜですか? PyGWalker (opens in a new tab) という名前のオープン ソース ツールを使用すると、複雑なコードを学習しなくても、ユーザー フレンドリーなインターフェイスで美しいデータ ビジュアライゼーションを簡単に作成できます。
PyGWalker (opens in a new tab) は、pandas データフレーム (および polars データフレーム) を Tableau スタイルのユーザー インターフェイスに変換して視覚的な探索を行うことで、データ分析とデータ視覚化のワークフローを簡素化します。 . Jupyter Notebook (またはその他の jupyter ベースのノートブック) を Graphic Walker と統合します。これは、Tableau に代わるオープンソースの別のタイプです。 データ サイエンティストは、簡単なドラッグ アンド ドロップ操作でデータを分析し、パターンを視覚化できます。
| Kaggle で実行 (opens in a new tab) | Colab で実行 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
Google Colab (opens in a new tab)、Kaggle コード (opens in a new tab)、Binder (opens in a new tab) または Graphic Walker Online Demo (opens in a new tab) で PyGWalker をテストします。
Jupyter Notebook で PyGWalker を使用する
PyGWalker と pandas を Jupyter Notebook にインポートして開始します。
import pandas as pd
import PyGWalker as pyg既存のワークフローを壊すことなく PyGWalker を使用できます。 たとえば、Pandas データフレームをビジュアル UI に読み込むことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)また、PyGWalker を極座標で使用できます (PyGWalker>=0.1.4.7a0 から):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Binder (opens in a new tab)、Google Colab (opens in a new tab) または Kaggle コード (opens in a new tab)。
結論
この記事では、read_csv() 関数を使用して Pandas で CSV ファイルを読み取る方法を学びました。 また、CSV ファイルを文字列として読み取る方法、列と行をスキップする方法、複数の CSV ファイルを一度に読み取る方法についても説明しました。 さらに、PyGWalker (opens in a new tab) を使用してデータを視覚化する方法を学びました。これは、Pandas のデータ名をデータ視覚化に変換するオープン ソース ツールです。 これらのテクニックを使えば、すぐにプロのようにデータ分析を開始できます!