DatabricksとSnowflake:データアナリストやデータサイエンティストのための包括的な比較

データの重要性と複雑さがますます増している中で、データアナリストやデータサイエンティストは適切なツールを活用して有益な洞察を得る必要があります。この包括的な比較では、DatabricksとSnowflakeという2つの主要なデータプラットフォームについて探究します。それぞれの機能、メリット、デメリットを調査し、自分に適したツールを選ぶ際に役立つ情報を提供します。さらに、関連する内部リンクも含め、さらなるリソースと文脈を提供します。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
概要
Databricks (opens in a new tab)は、ビッグデータ処理、機械学習、AIアプリケーションのための統合分析ワークスペースを提供するクラウドベースのプラットフォームです。人気のあるApache Sparkフレームワーク上に構築されており、データ処理および分析のタスクを効率的にスケーリングすることができます。
一方、Snowflake (opens in a new tab)は、構造化および半構造化データのストレージ、管理、分析に特化したクラウドベースのデータウェアハウスソリューションです。高速なクエリ処理および分析を可能にするマッシブパラレル処理(MPP)に対応しています。
主な特徴
Databricks
- 統合型分析プラットフォーム: Databricksは、データエンジニアリング、データサイエンス、AIの機能を1つのプラットフォームで統合し、異なるチームや役割間での協力を可能にします。
- Apache Spark: SparkベースのプラットフォームであるDatabricksは、ビッグデータ処理および機械学習ワークロードに対して高いパフォーマンスとスケーラビリティを提供します。
- インタラクティブなワークスペース: Databricksは、Python、R、Scala、SQLなどさまざまな言語をサポートしたインタラクティブなワークスペースを提供します。また、組み込みのJupyter Notebook (opens in a new tab)統合も備えています。
- MLflow: Databricksには、機械学習ライフサイクルのエンドツーエンドを管理するためのオープンソースプラットフォームであるMLflowが含まれており、モデルの開発と展開を簡素化します。
- Delta Lake: Delta Lakeは、ACIDトランザクションおよびその他のデータ信頼性機能をデータ湖にもたらすオープンソースのストレージレイヤです。データの品質と一貫性が向上します。
Snowflake
- クラウドデータウェアハウス: Snowflakeの主な焦点は、スケーラブルで使いやすいクラウドベースのデータウェアハウスソリューションです。
- 独自のアーキテクチャ: Snowflakeのアーキテクチャは、ストレージ、計算、クラウドサービスを分離しており、独立したスケーリングとコストの最適化が可能です。
- 構造化および半構造化データのサポート: Snowflakeは、JSON、Avro、Parquet、XMLなどの構造化および半構造化データを処理することができます。
- データの共有と統合: Snowflakeは、ネイティブのデータ共有機能を提供し、組織間のデータの協力を簡素化します。さらに、データの取り込みと処理を効率化するための幅広いデータ統合ツール (opens in a new tab)も提供しています。
- セキュリティとコンプライアンス: Snowflakeは、暗号化、ロールベースのアクセス制御、さまざまなコンプライアンス基準のサポートなど、セキュリティとコンプライアンスに重点を置いています。
パフォーマンス、スケーラビリティ、コストの比較
パフォーマンス
Apache Sparkを基にしているDatabricksは、高性能なデータ処理と機械学習タスクに最適化されています。一方、データウェアハウスに重点を置いているSnowflakeは、高速なクエリの実行と分析に優れています。ただし、機械学習やAIワークロードにおいては、Databricksに明確な優位性があります。
スケーラビリティ
DatabricksとSnowflakeの両方は、データの要件に応じてスケーリングするよう設計されています。DatabricksはSparkの機能を活用してビッグデータ処理を行う一方、Snowflakeの独自のアーキテクチャは、ストレージと計算リソースを独立してスケーリングすることができます。この柔軟性により、組織は特定の要件と予算制約に合わせてインフラストラクチャを調整することができます。
コスト
DatabricksとSnowflakeは、使用したリソースに対してのみ支払いを行う従量制の価格モデルを提供しています。ただし、価格体系にはいくつかの重要な違いがあります。Databricksは、仮想マシンのインスタンス、データのストレージ、データの転送に基づいて料金を請求します。一方、Snowflakeの価格は、保存されたデータの容量、計算リソースの数("ウェアハウス"とも呼ばれる)、および受け入れたデータの量によって決定されます。
自組織のデータ処理とストレージのニーズを慎重に評価し、最もコスト効果の高いソリューションを選ぶことが重要です。効率的なリソース管理や、自動スケーリングや自動一時停止などの機能を活用するなど、コストの最適化はしばしば余分な要素に依存します。
統合とエコシステム
DatabricksとSnowflakeの両方は、一般的なデータソース、ツール、プラットフォームとの包括的な統合オプションを提供しています。
-
Databricksは、Hadoopなどのビッグデータ処理ツール、Amazon S3、Azure Blob Storage、Google Cloud Storageなどのデータストレージサービスなどとシームレスに統合します。さらに、TableauやPower BIなどの人気のあるデータ可視化ツールもサポートしています。
-
Snowflakeは、データウェアハウスソリューションでありながら、Fivetran、Matillion、Talendなどの人気のあるツールを含む、データの受け入れやETLプロセスのための数多くのコネクタと統合オプションを提供しています。また、Looker、Tableau、Power BIなどのビジネスインテリジェンスプラットフォームとの統合もサポートしています。
全体的なエコシステムに関しては、DatabricksはApache Sparkコミュニティに重点を置いており、Snowflakeはデータウェアハウスと分析の領域に特化しています。自組織の特定のニーズに応じて、1つのプラットフォームが特定のユースケースに対してより良いサポートとリソースを提供する場合があります。
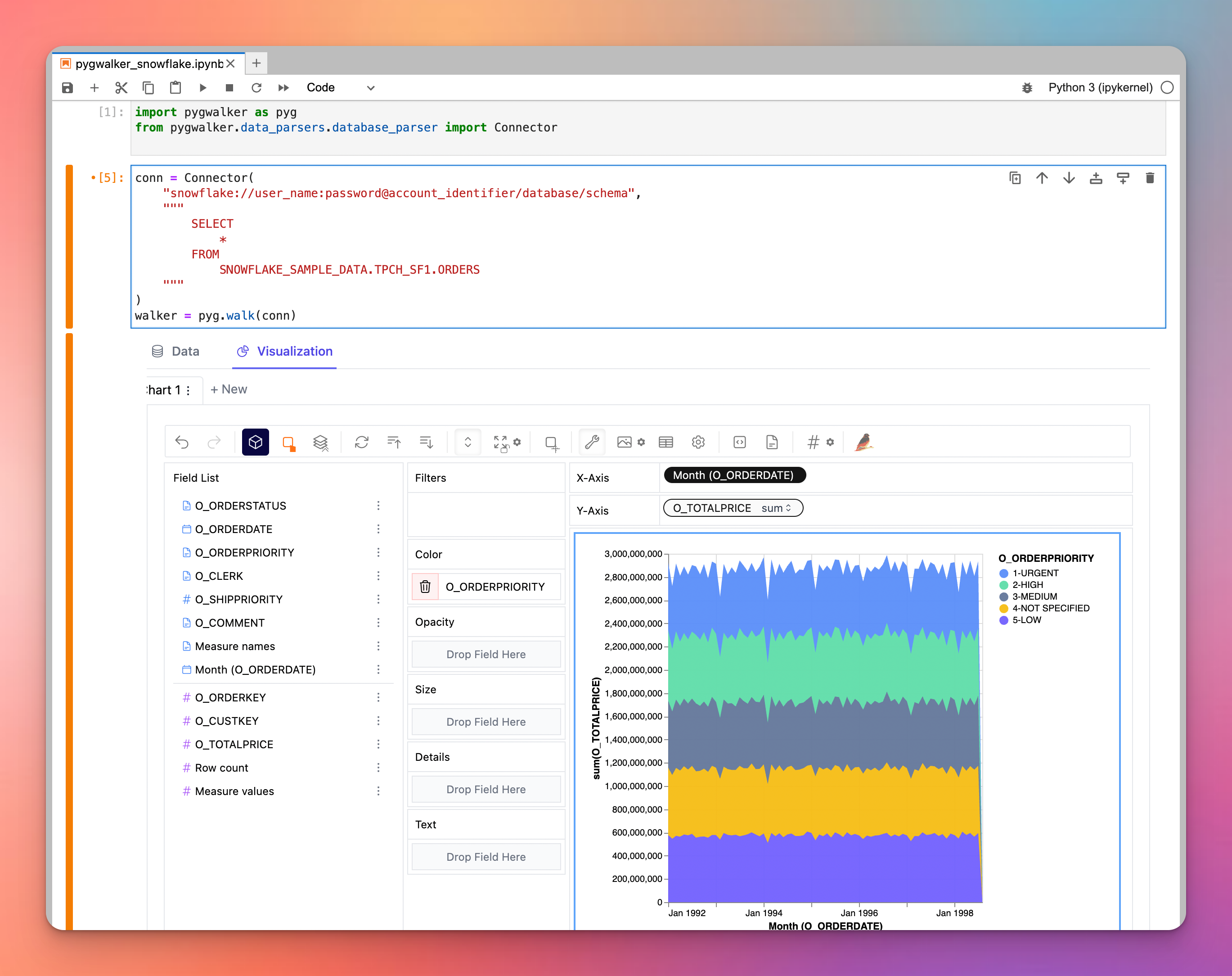
ちなみに、Snowflake/DatabricksでPyGWalkerを使用してデータを視覚的に探索してみましょう
高機能な可視化ツールを探している場合は、pygwalkerを検討してみてください。これはデータフレームをTableauに似た可視化アプリケーションに変換する画期的なPythonライブラリです。特に、pygwalkerはSnowflakeなどの外部エンジンにクエリを委任できます。このシナジーにより、ユーザーはSnowflakeの計算能力を活用しながら優れた可視化を提供することができます。pygwalkerによってデータ可視化のバリューを向上させましょう。 PyGWalkerは、現在Kanaries (opens in a new tab)で利用可能です。最初の月の購読料金を50%割引でお得に利用することができます。 詳細については、pygwalkerのホームページ (opens in a new tab)をご覧ください。
結論
DatabricksとSnowflakeは、データ処理および分析の異なる側面に対して設計された強力なプラットフォームです。Databricksはビッグデータ処理、機械学習、AIワークロードにおいて優れたパフォーマンスを発揮し、Snowflakeはデータウェアハウス、ストレージ、分析において優れています。組織に最適な選択を行うためには、具体的な要件、予算、統合のニーズを考慮することが重要です。