Python の Pandas ライブラリ、PySpark、R、および PyGWalker を使用して CSV ファイルをデータフレームに読み込む方法

CSV (カンマ区切り値) ファイルは、表形式のデータを保存および共有する一般的な方法です。 この記事では、Python の Pandas ライブラリを使用して CSV ファイルをデータフレームに読み込む方法について説明します。 カスタム区切り文字、行とヘッダーのスキップ、欠落データの処理、カスタム列名の設定、データ型の変換など、さまざまなシナリオについて説明します。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
Pandas での CSV ファイルの読み取り
Pandas は、データの操作と分析に使用される人気のある Python ライブラリです。 大規模なデータセットを効率的に格納および操作するためのデータ構造を提供します。 Pandas の read_csv() 関数を使用して、CSV ファイルをデータフレームに読み込むことができます。 次に例を示します。
import pandas as pd
df = pd.read_csv('sample.csv')
print(df)この例では、read_csv() 関数を使用して、「sample.csv」という名前の CSV ファイルをデータフレームに読み込みます。 結果のデータフレームは、print() 関数を使用して印刷されます。
Pandas でカスタム区切り文字を指定する
デフォルトでは、Pandas は CSV ファイル内の値がカンマで区切られていると想定します。 ただし、常にそうであるとは限りません。 delimiter パラメータを使用してカスタム区切り文字を指定できます。
df = pd.read_csv('sample.csv', delimiter=';')
print(df)ここでは、CSV ファイルの区切り文字が「;」であることを指定しています。
Pandas で行とヘッダーをスキップする
CSV ファイルを読み取るときに、特定の行またはヘッダーをスキップしたい場合があります。 skiprows および header パラメータを使用してこれを行うことができます。
df = pd.read_csv('sample.csv', skiprows=2, header=None)
print(df)ここでは、CSV ファイルの最初の 2 行をスキップし、最初の行を列名として使用していません。
Pandas で欠落データを処理する
CSV ファイルにはデータが欠落している可能性があり、データフレームに読み込むときに問題が発生する可能性があります。 デフォルトでは、Pandas は欠落しているデータを NaN 値に置き換えます。 「na_values」パラメーターを使用して、欠損データを置き換えるカスタム値を指定できます。
df = pd.read_csv('sample.csv', na_values=['n/a', 'NaN'])
print(df)ここでは、値 'n/a' と 'NaN' を欠損データとして扱うように指定しています。
Pandas でカスタム列名を設定する
デフォルトでは、Pandas は CSV ファイルの最初の行を列名として使用します。 names パラメータを使用して、カスタム列名を指定できます。
df = pd.read_csv('sample.csv', names=['Name', 'Age', 'Gender'])
print(df)ここでは、列名が「名前」、「年齢」、および「性別」であることを指定しています。
Pandas でのデータ型の変換
場合によっては、列のデータ型を変換したいことがあります。 たとえば、文字列列を整数列または浮動小数点列に変換したい場合があります。 dtype パラメータを使用してこれを行うことができます。
df = pd.read_csv('sample.csv', dtype={'Age': int})
print(df.dtypes)ここでは、'Age' 列を整数データ型に変換するように指定しています。
Pandas のデータフレームにテキスト ファイルを読み込む
CSV ファイルに加えて、Pandas はテキスト ファイルをデータフレームに読み込むこともできます。 次に例を示します。
df = pd.read_csv('sample.txt', delimiter='\t')
print(df)この例では、「sample.txt」という名前のテキスト ファイルをデータフレームに読み込みます。 テキスト ファイルの区切り文字がタブであることを指定しました。
PySpark の CSV から Datafram へ
PySpark で CSV ファイルをデータフレームに読み込む
PySpark では、SparkSession オブジェクトの read() メソッドを使用して、CSV ファイルを読み取り、データフレームを作成できます。 read() メソッドは、区切り文字、ヘッダー、スキーマの指定など、CSV リーダーを構成するためのオプションを提供します。
PySpark で CSV ファイルをデータフレームに読み込む方法の例を次に示します。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("CSV Reader").getOrCreate()
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/path/to/csv/file.csv")
df.show()この例では、SparkSession オブジェクトを作成し、CSV 形式オプションで read() メソッドを使用しています。 また、CSV ファイルの最初の行にヘッダーが含まれていること、およびデータからスキーマを推測する必要があることも指定します。 最後に、CSV ファイルへのパスを指定し、データフレームに読み込みます。 結果のデータフレームは、show() メソッドを使用して出力されます。
PySpark で複数の CSV ファイルを 1 つのデータフレームに読み込む
PySpark は強力なビッグ データ処理フレームワークで、複数の CSV ファイルを 1 つのデータフレームに簡単に読み込むことができます。 これは、SparkSession オブジェクトの read() メソッドを使用し、CSV ファイルへのパスにワイルドカード文字 (*) を指定することで実現できます。 次に例を示します。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("CSV Reader").getOrCreate()
df = spark.read.format('csv').option('header', 'true').option('inferSchema', 'true').load('/path/to/csv/files/*')
df.show()この例では、SparkSession オブジェクトを作成し、ワイルドカード文字を使用した load() メソッドを使用して、指定されたディレクトリにあるすべての CSV ファイルを読み取ります。 結果のデータフレームは、show() メソッドを使用して出力されます。
CSV から R のデータフレームへ
CSV ファイルを R のデータフレームに読み込む
Python の Pandas ライブラリに加えて、R には CSV ファイルをデータフレームに読み込むための組み込み関数もあります。 この目的のために read.csv() 関数を使用できます。 次に例を示します。
df <- read.csv('sample.csv')
print(df)この例では、read.csv() 関数を使用して、「sample.csv」という名前の CSV ファイルをデータフレームに読み込みます。 結果のデータフレームは、print() 関数を使用して印刷されます。
R で CSV ファイルをデータフレームに変換する
R では、as.data.frame() 関数を使用して CSV ファイルをデータフレームに変換することもできます。 次に例を示します。
df <- as.data.frame(read.csv('sample.csv'))
print(df)この例では、read.csv() 関数を使用して「sample.csv」という名前の CSV ファイルを読み取り、as.data.frame() 関数を使用してそれをデータフレームに変換しています。 結果のデータフレームは、print() 関数を使用して印刷されます。
PyGWalker での CSV からデータへの可視化
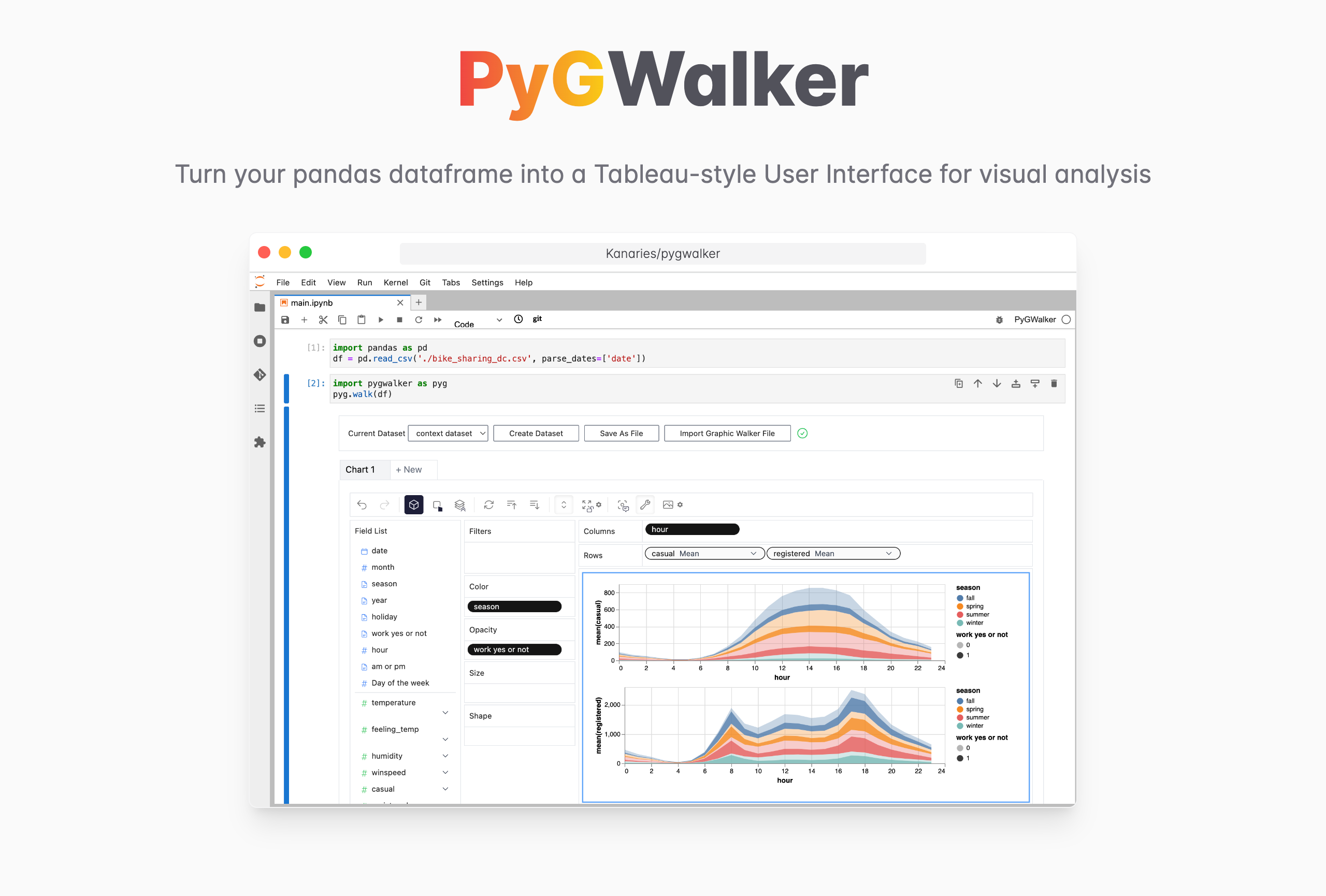
PyGWalker (opens in a new tab) は、pandas データフレーム (および polars データフレーム) を Tableau スタイルのユーザー インターフェイスに変換して視覚的な探索を行うことで、データ分析とデータ視覚化のワークフローを簡素化します。 . Jupyter Notebook (またはその他の jupyter ベースのノートブック) を Graphic Walker と統合します。これは、Tableau に代わるオープンソースの別のタイプです。 データ サイエンティストは、簡単なドラッグ アンド ドロップ操作でデータを分析し、パターンを視覚化できます。
PyGWalker はオープン ソースです。 PyGWalker GitHub (opens in a new tab) をチェックして ⭐️ を残すことを忘れないでください!
CSV ファイルをデータフレームに読み込む
この例では、Jupyter Notebook で PyGWalker を実行します。 Binder (opens in a new tab)、Google Colab (opens in a new tab) または Kaggle コード (opens in a new tab)。
| Kaggle で実行 (opens in a new tab) | Colab で実行 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
Python 環境で次のコードを実行して、「bike_sharing_dc.csv」CSV ファイルを Pandas にインポートします。
import pandas as pd
import PyGWalker as pyg
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])Polars を使用する場合は、次のコードを使用して CSV を pandas データフレームにインポートします。
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)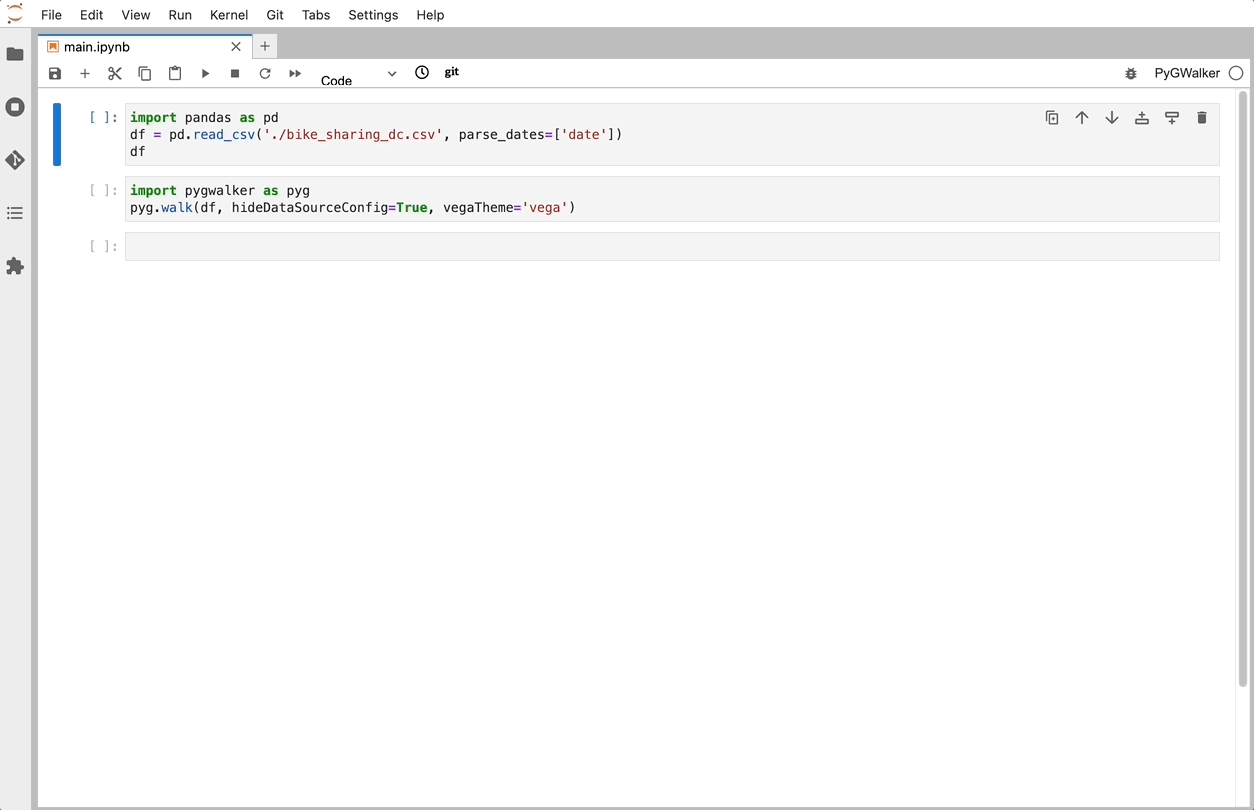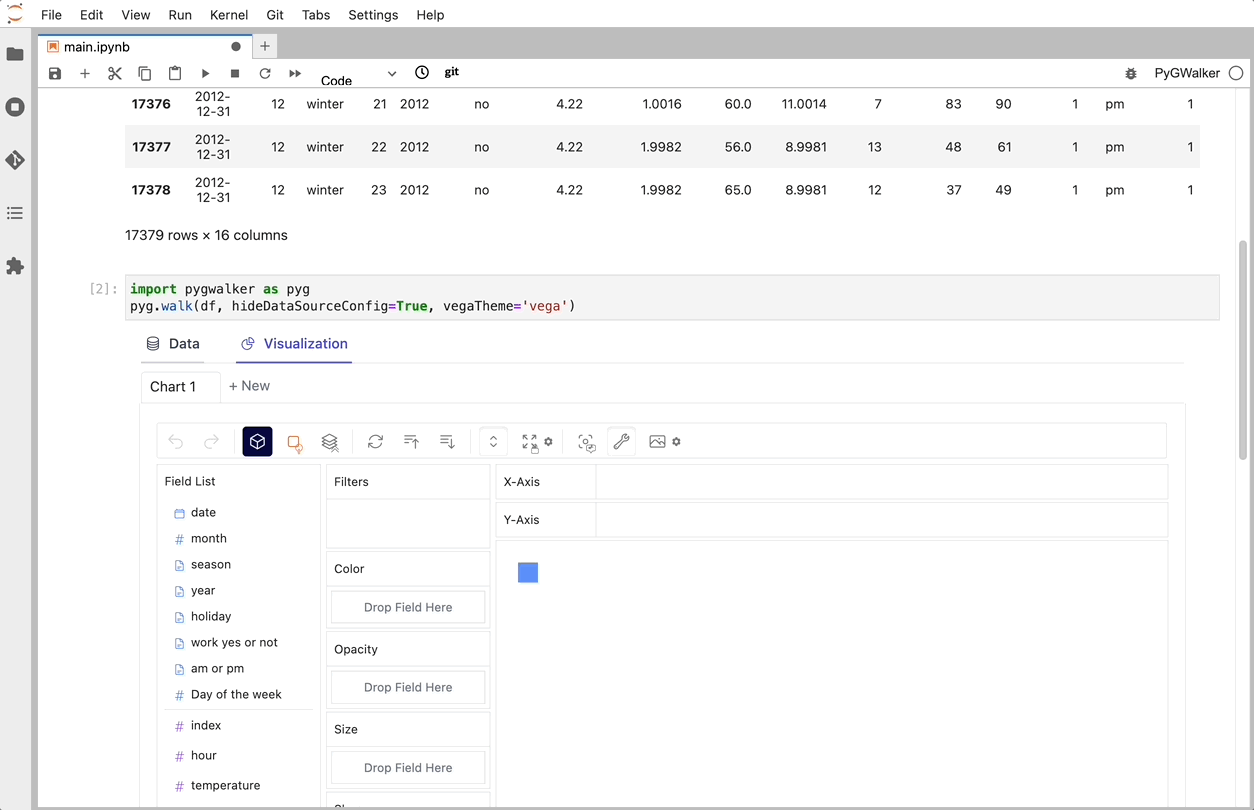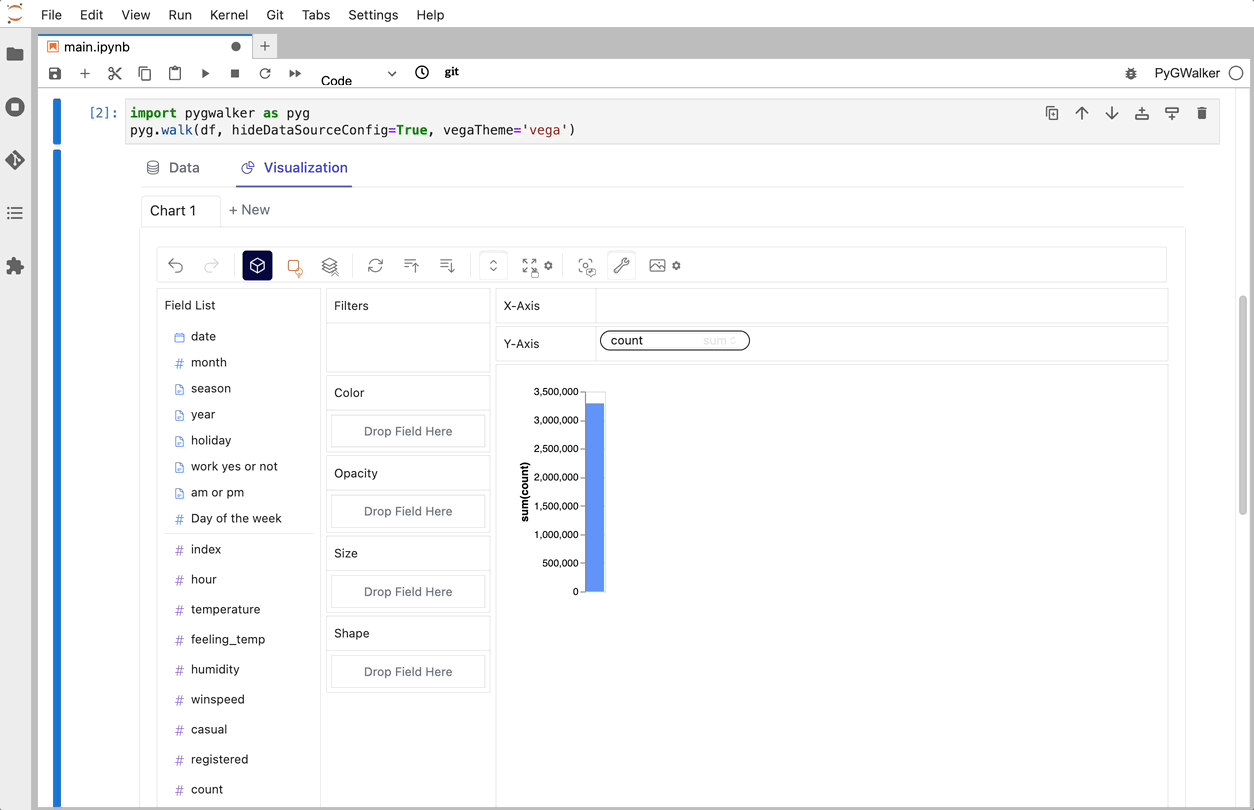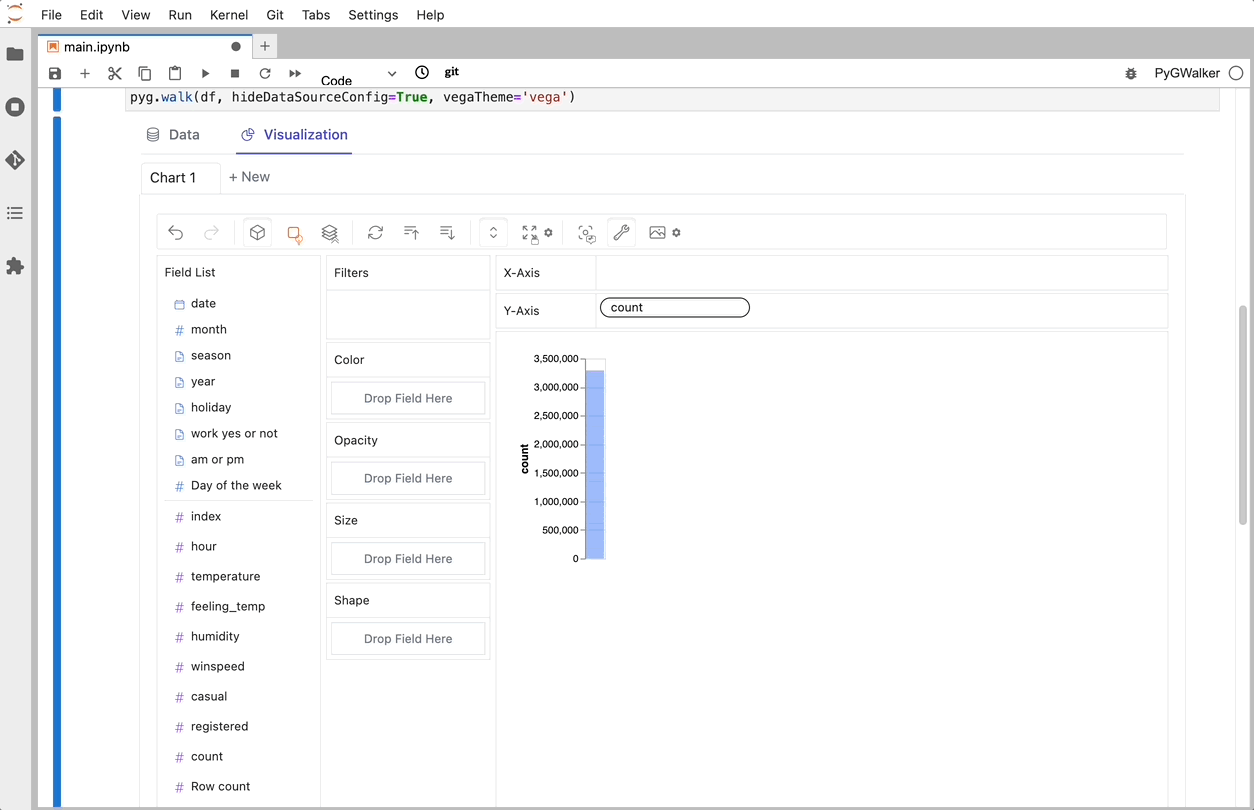
PyGWalker で CSV をデータ可視化に変換
CSV を pandas データフレームにインポートした後、PyGWalker を呼び出して Tableau のようなユーザー インターフェイスを使用し、変数をドラッグ アンド ドロップしてデータを分析および視覚化できます。
gwalker = pyg.walk(df)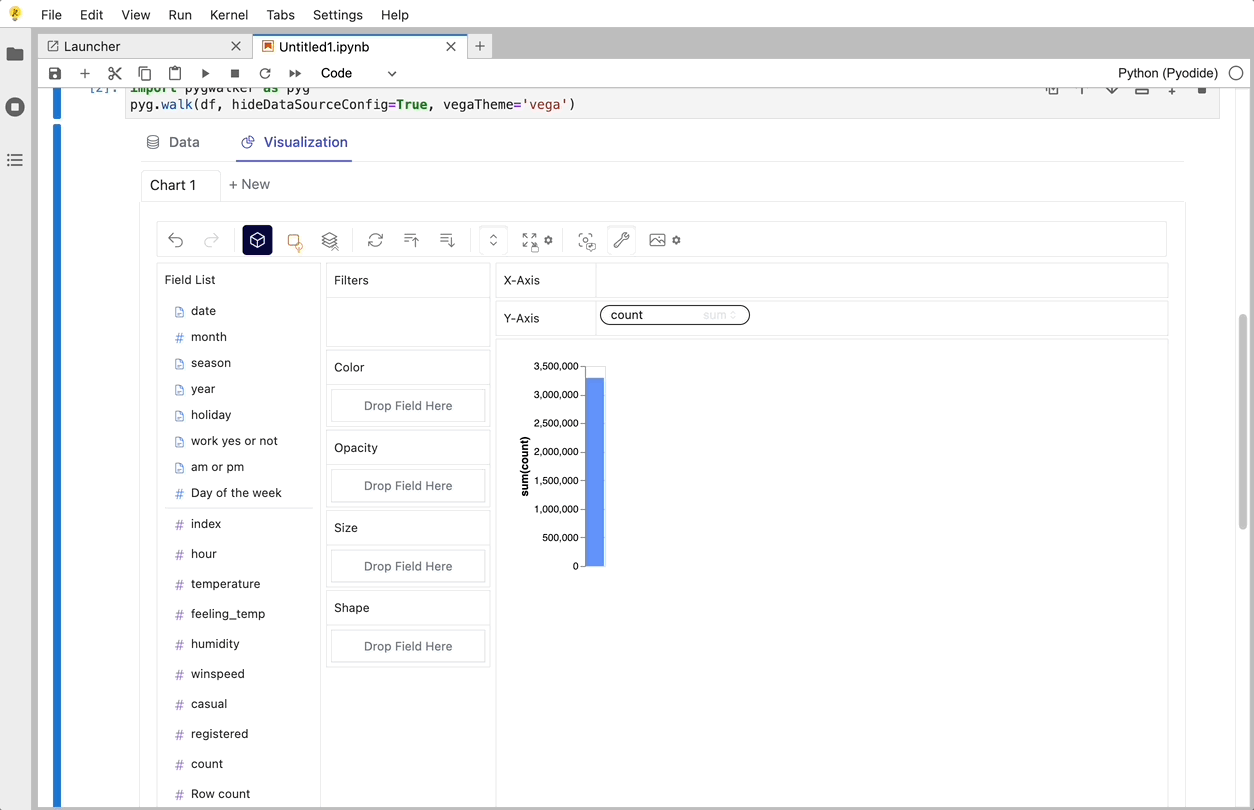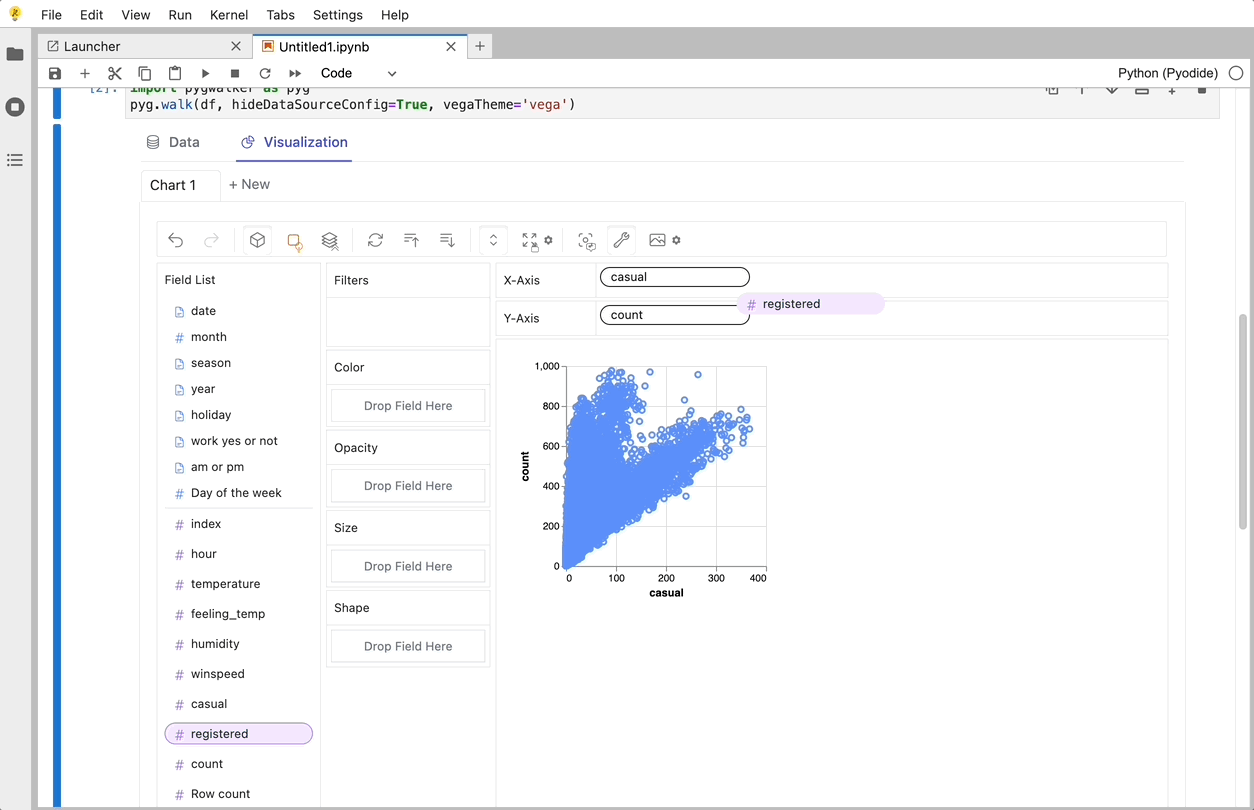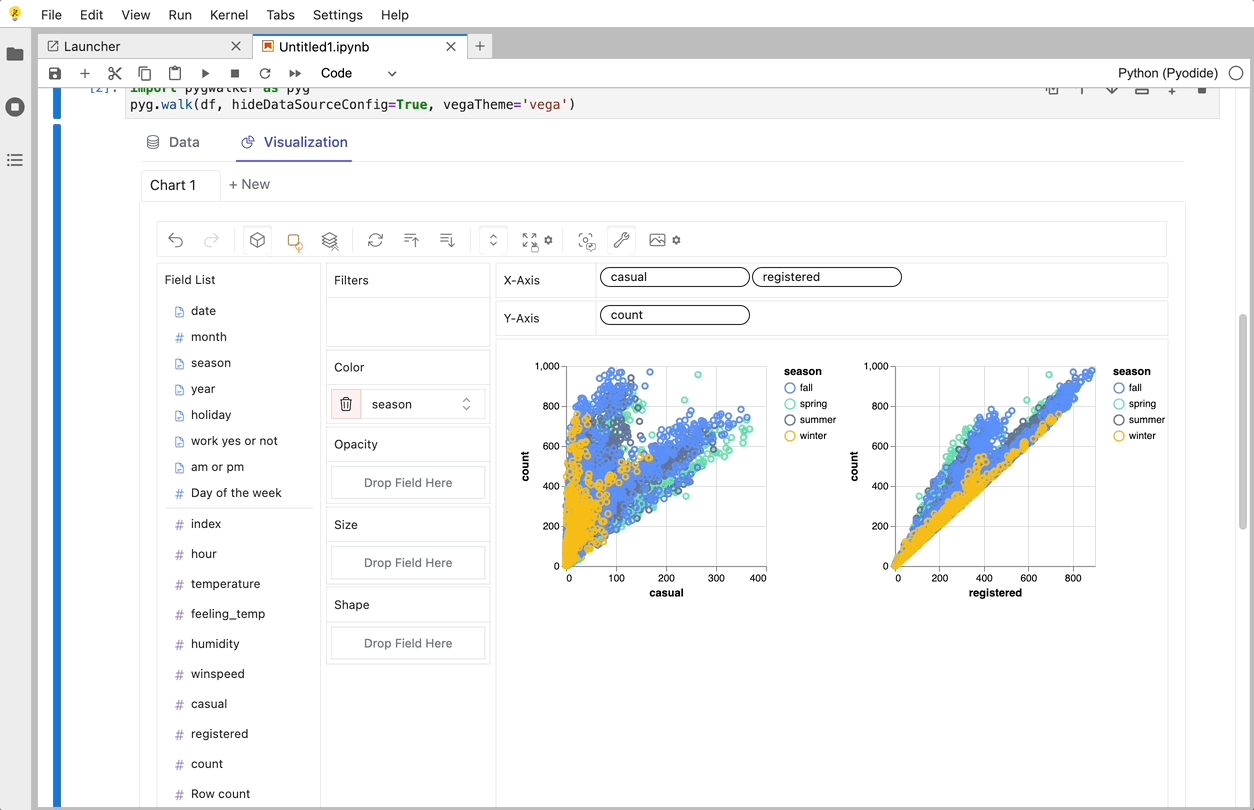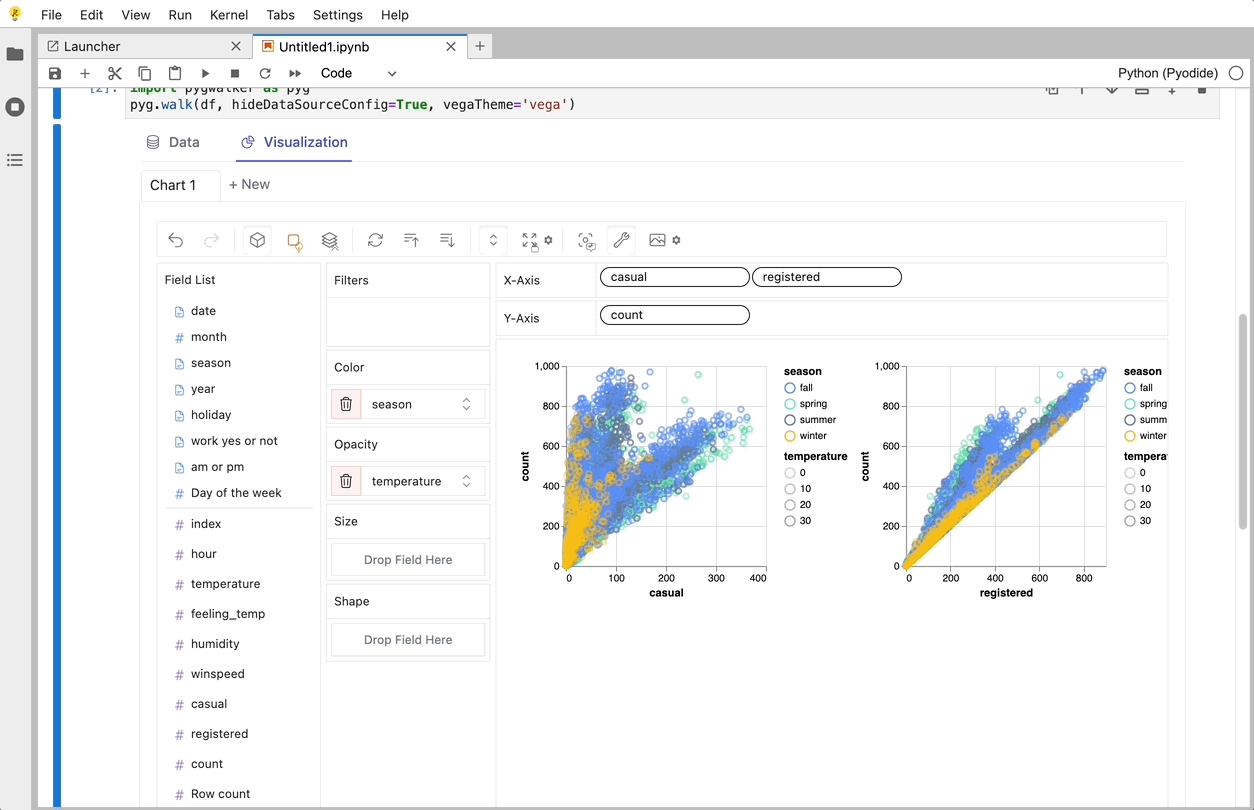
これらのチャートは、変数のドラッグ アンド ドロップをサポートする UI を備えた Graphic Walker で作成できます。
棒グラフ 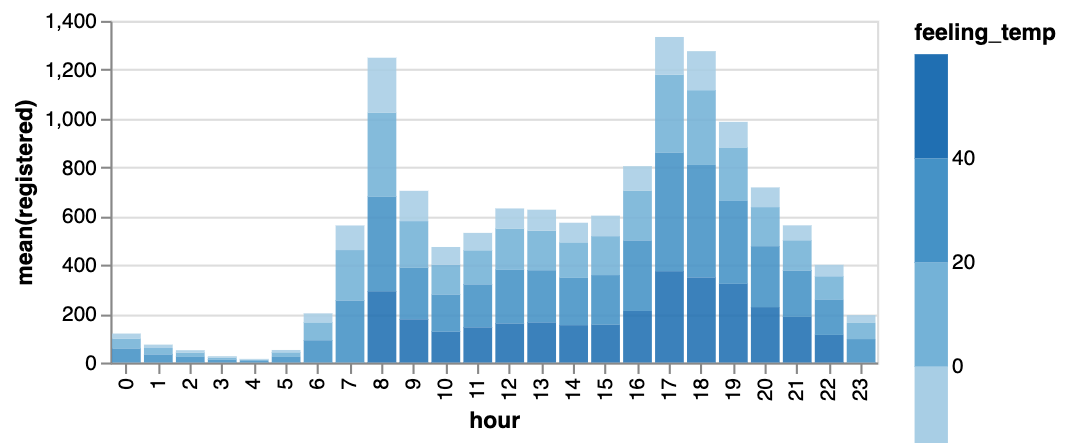 | 折れ線グラフ 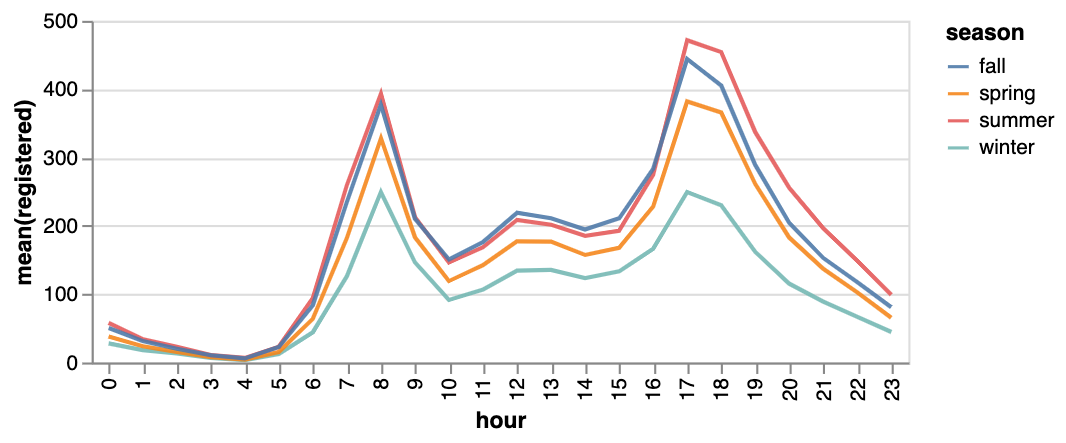 | 面積グラフ 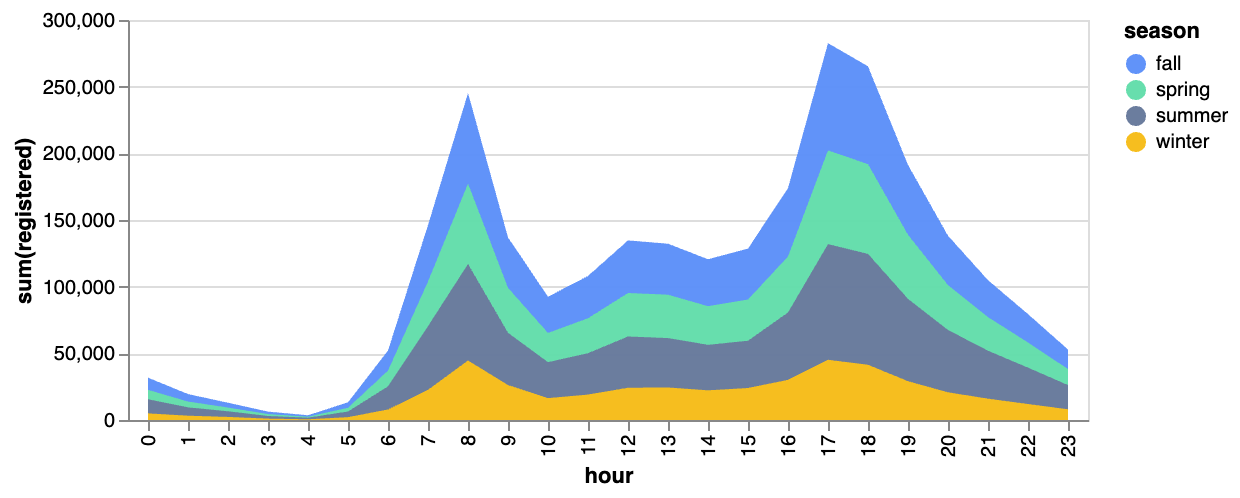 |
|---|---|---|
トレイル 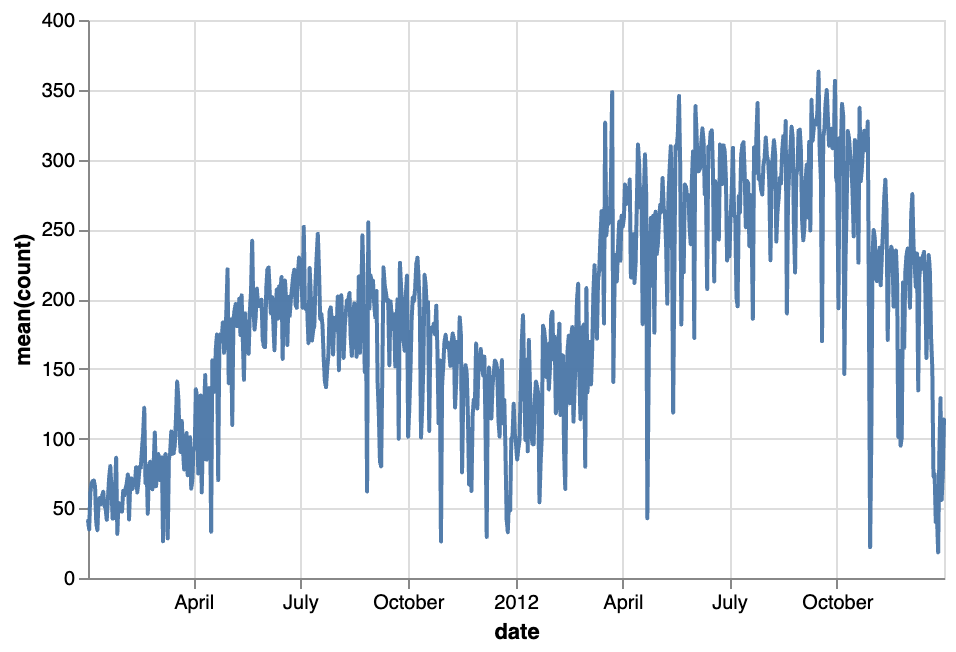 | 散布図  | サークル 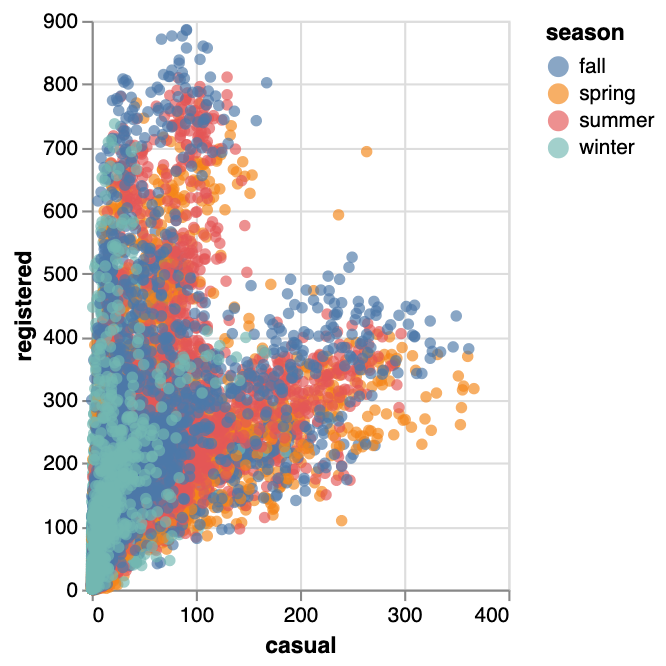 |
ティックプロット  | 長方形  | アーク図  |
箱ひげ図  | ヒートマップ  |
より多くの例については、データ可視化ギャラリーをご覧ください。
結論
CSV ファイルをデータフレームに読み込むことは、データ サイエンスと分析の一般的なタスクです。 Python の Pandas ライブラリと R はどちらも、この目的のための関数を提供します。 この記事では、Pandas と R を使用して CSV ファイルをデータフレームに読み込む方法と、カスタム区切り記号、行とヘッダーのスキップ、欠落データの処理、カスタム列名の設定、データ型の変換などのさまざまなシナリオについて説明しました。
よくある質問
-
CSVファイルとは? A: CSV ファイルは、表形式のデータをプレーン テキスト形式で保存するために使用されるファイルの一種で、各行は行を表し、各値は区切り記号で区切られています。
-
データフレームとは? A: データフレームは、Python および R で表形式のデータを格納および操作するために使用される 2 次元のデータ構造です。
3.カスタム区切り文字を使用して CSV ファイルを Pandas データフレームに読み込むにはどうすればよいですか?
A: read_csv() 関数の delimiter パラメータを使用してカスタム区切り文字を指定できます。 たとえば、df = pd.read_csv('sample.csv', delimiter=';').
-
Pandas データフレームで文字列列を整数列に変換するにはどうすればよいですか? A:
read_csv()関数でdtypeパラメータを使用して、列のデータ型を指定できます。 たとえば、df = pd.read_csv('sample.csv', dtype={'Age': int})です。 -
CSV ファイルを R データフレームに読み込むときに行とヘッダーをスキップするにはどうすればよいですか? A:
read.csv()関数でスキップ パラメータとヘッダー パラメータを使用して、それぞれ行とヘッダーをスキップできます。 たとえば、df <- read.csv('sample.csv', skip=2, header=FALSE).