PyGWalkerを使用してNetflixデータを探索する
Netflixは映画やテレビ番組のための一流のプラットフォームとして際立っています。成長し続けるコンテンツライブラリの中で、そのトレンドとパターンを理解することは、分析者、映画作りの人々、さらには視聴者にとっても重要です。このノートブックでは、データの可視化と探索に役立つ強力なツールであるPyGWalkerライブラリを使用して、Netflixデータセットに深く入り込んでいきます。
PyGWalkerとは?
PyGWalker (opens in a new tab)は、データの可視化プロセスを簡素化するために設計されたPythonのライブラリです。このライブラリを使用すると、最小限のコードでインタラクティブなチャートを作成できるため、データセット内の洞察とパターンを解明するのが容易になります。

PyGWalkerを使用することで、Netflixのコンテンツの風景をより明確に理解できる洞察に満ちたビジュアリゼーションを生成することができます。
PyGWalkerを使用したNetflixデータの探索手順
環境のセットアップ
まず、分析のための環境が整ったことを確認するために、PyGWalkerライブラリのインストールと必要なPythonパッケージのインポートが必要です。
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Netflixデータセットの読み込みと前処理
最初の作業はNetflixデータセットの読み込みです。読み込んだ後、データの後続の分析をスムーズにするために前処理を行います。この前処理には以下が含まれます:
- date_added列を日付形式に変換する。
- date_added列から年と月を抽出する。
- duration列を映画の合計分数またはTV番組のシーズン数に表示されるように修正する。
- 2019年以降のデータをフィルタリングする。
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df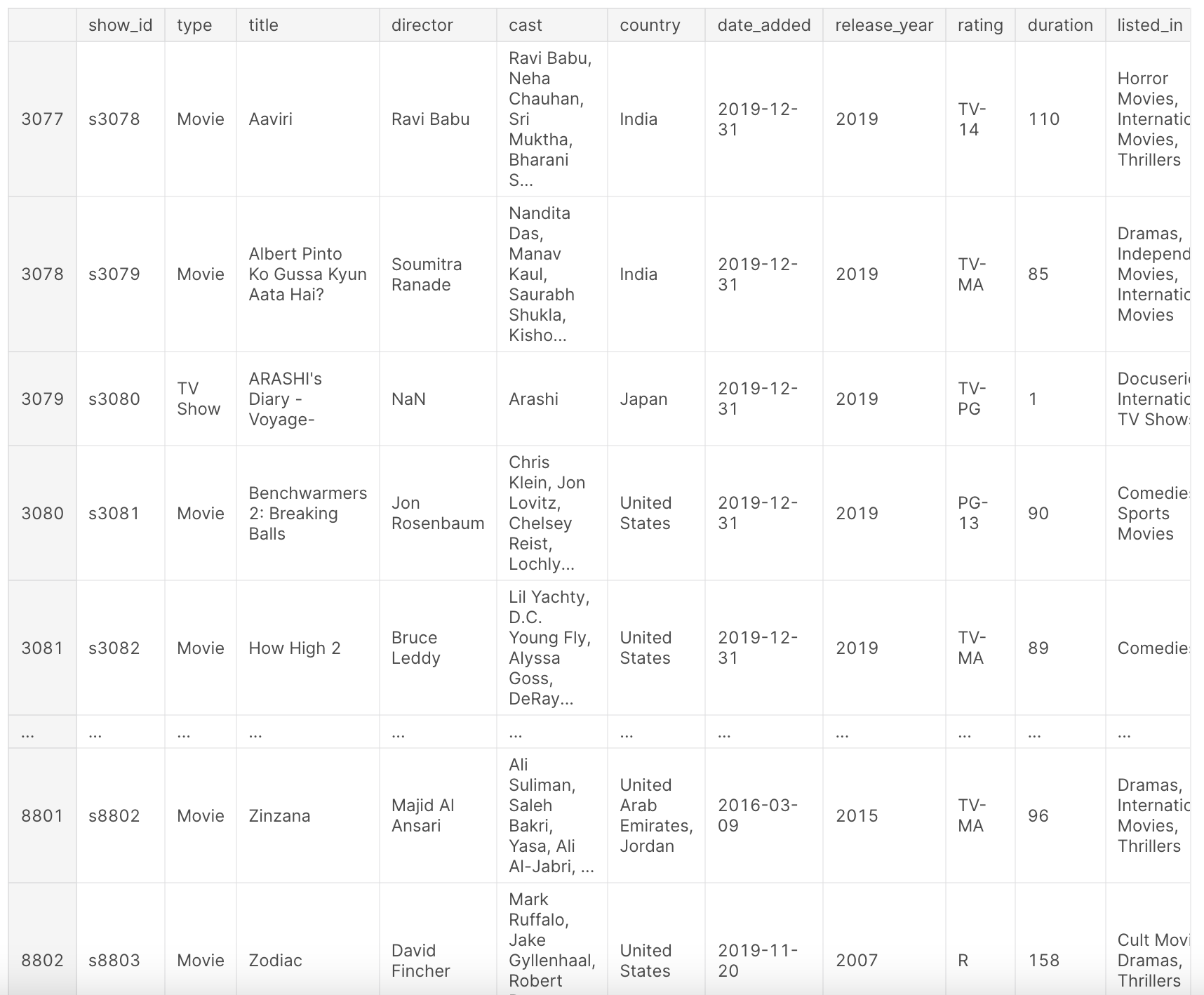
Netflixデータセットの概要
上記の前処理を行った後、データフレームdfはNetflixのタイトルの包括的なビューを提供します。このデータフレームには、コンテンツの種類(映画またはテレビ番組)、タイトル、監督、キャスト、制作国、Netflixへの追加日、リリース年、視聴可能年齢制限、再生時間、ジャンル、および簡単な説明などの情報が含まれています。
このデータセットは、2019年までのNetflixのコンテンツの風景のスナップショットを提供しており、年々のトレンド、好み、成長パターンを分析することができます。次の列をご覧ください:
show_id: 映画/テレビ番組ごとの一意のIDtype: 映画またはテレビ番組の識別子title: 映画/テレビ番組のタイトルdirector: 映画の監督cast: 映画/番組に関与した俳優country: 映画/番組が製作された国date_added: Netflixに追加された日付release_year: 映画/番組の実際のリリース年rating: 映画/番組の視聴可能年齢制限duration: 合計再生時間(分)またはシーズン数listed_in: ジャンルdescription: 映画/番組の簡単な説明
PyGWalkerでNetflixデータを可視化する
さて、興奮する部分です。PyGWalkerを使用して、データセットから洞察を引き出すためのインタラクティブなビジュアリゼーションを生成します。
1. Netflixデータの全体的な概要
ここでは、メインのデータセットに対してウォーカーを初期化しています。これにより、"0.json"に保存された仕様に基づいて一連のチャートを生成することができます。
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
PyGWalkerのオンラインバージョンでこのデータセットを対話的に探索することができます。こちら (opens in a new tab)をご覧ください。
walker0.display_chart("Chart 1", title="Netflix上のコンテンツタイプ")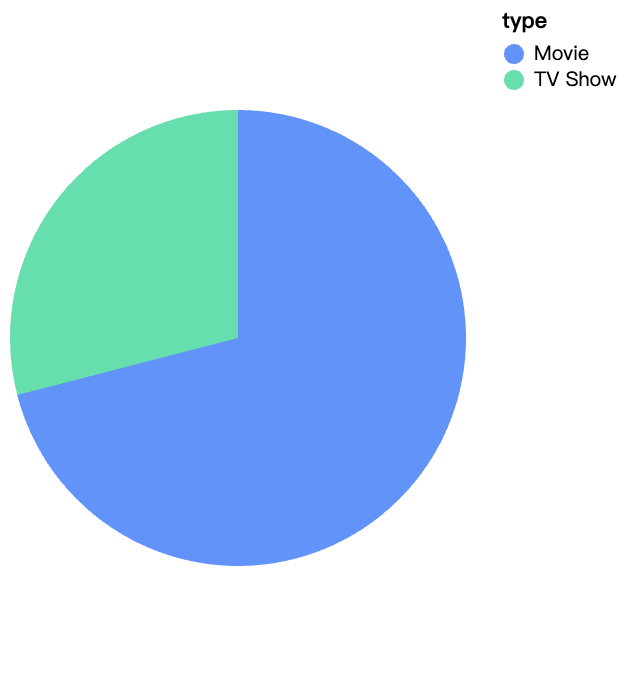
walker0.display_chart("Chart 2", title="年ごとの追加コンテンツ", desc="TV番組よりも映画の数が急速に増加しており、2016年以降、映画のコンテンツは大幅に増加しています。")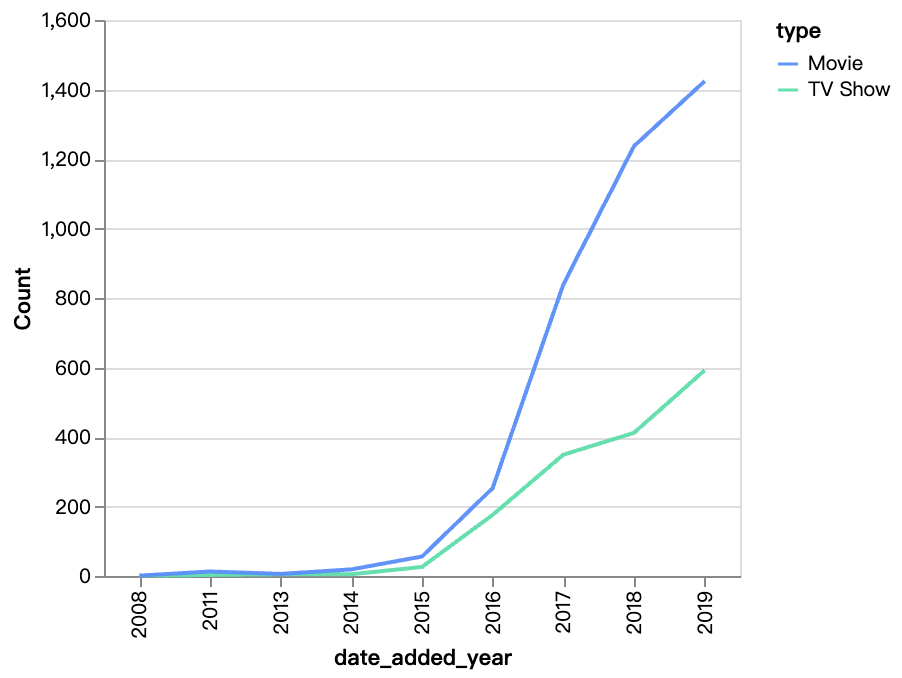
walker0.display_chart("Chart 3", title="年ごとのリリースコンテンツ")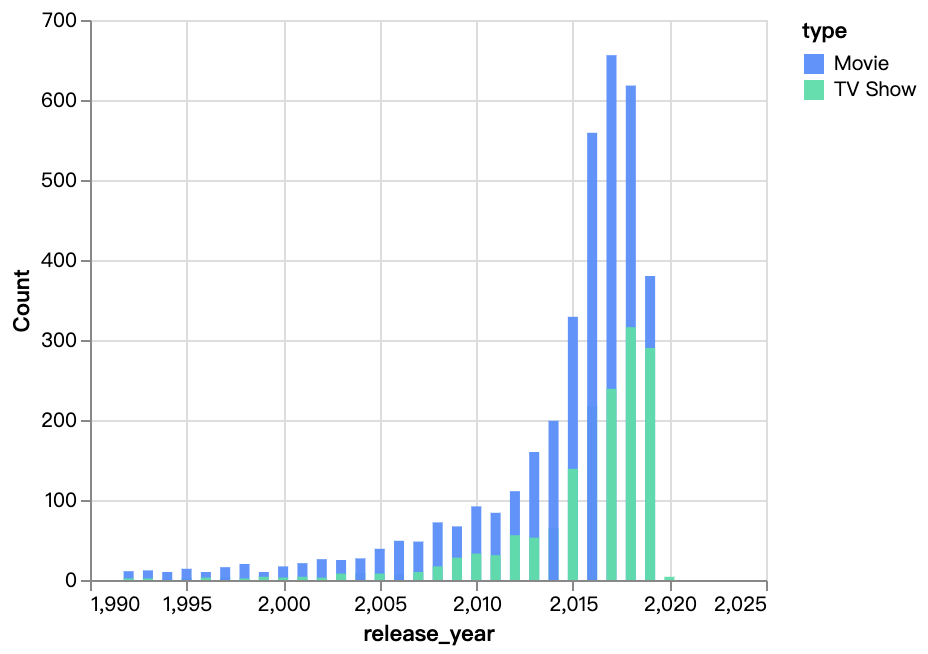
walker0.display_chart("Chart 4", title="月ごとの追加コンテンツ", desc="")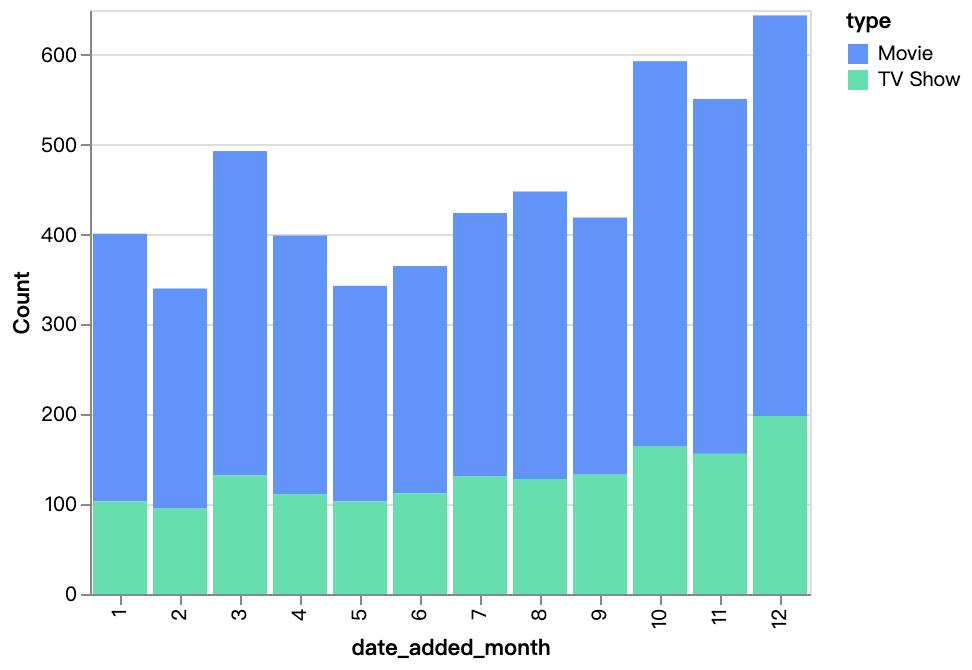
walker0.display_chart("Chart 5", title="年ごとの視聴可能年齢制限別追加コンテンツ", desc="NetflixのコンテンツのほとんどはTV-MA、TV-14の視聴可能年齢制限ですが、R指定も年々増加しています。")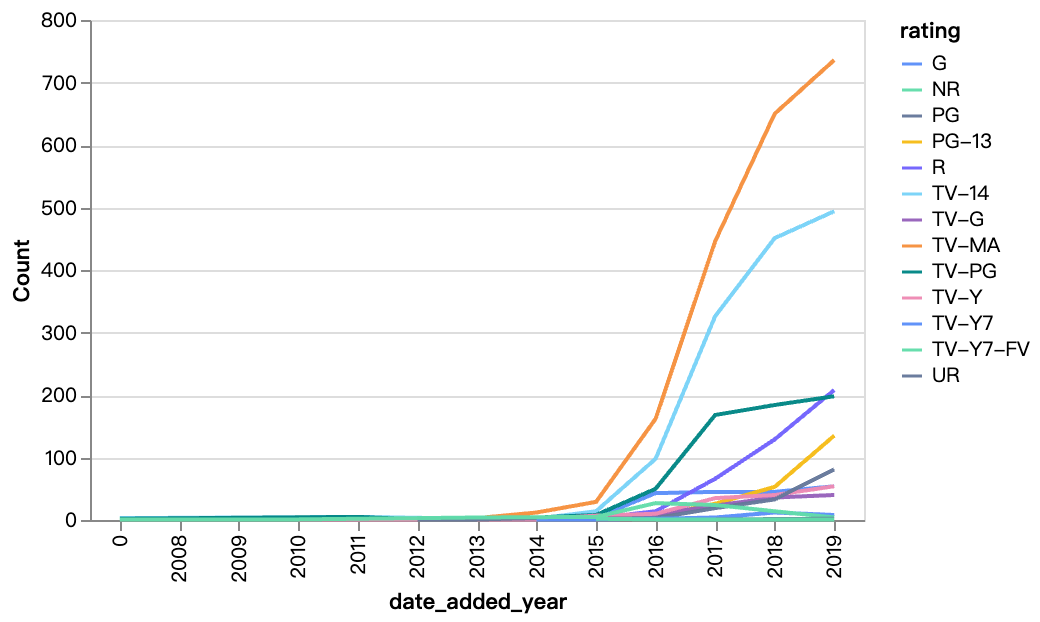
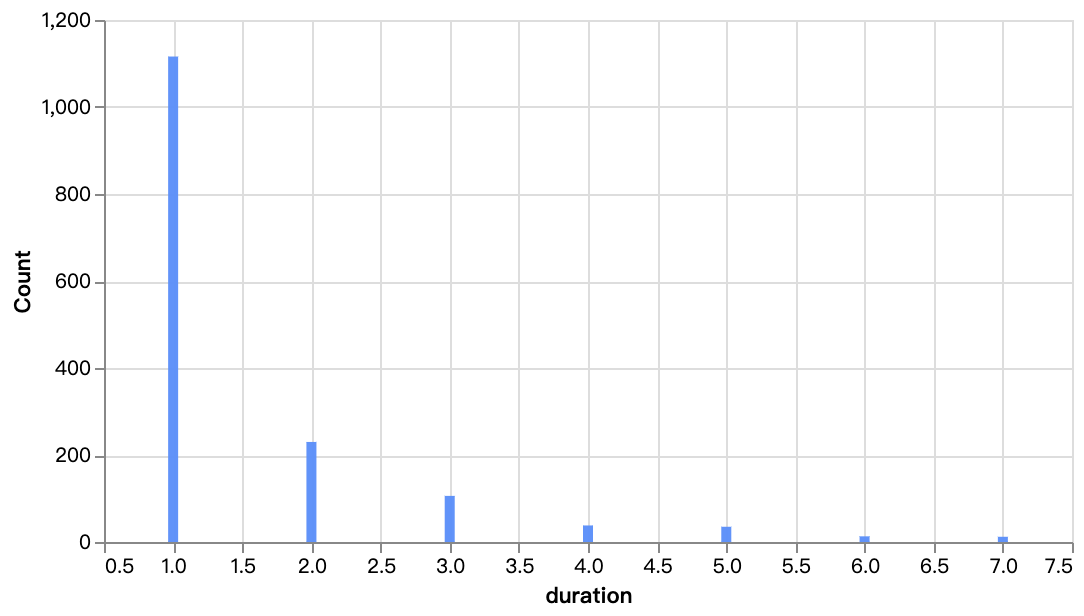
walker0.display_chart("Chart 6", title="映画の再生時間分布", desc="主に90分から110分の間に集中しています")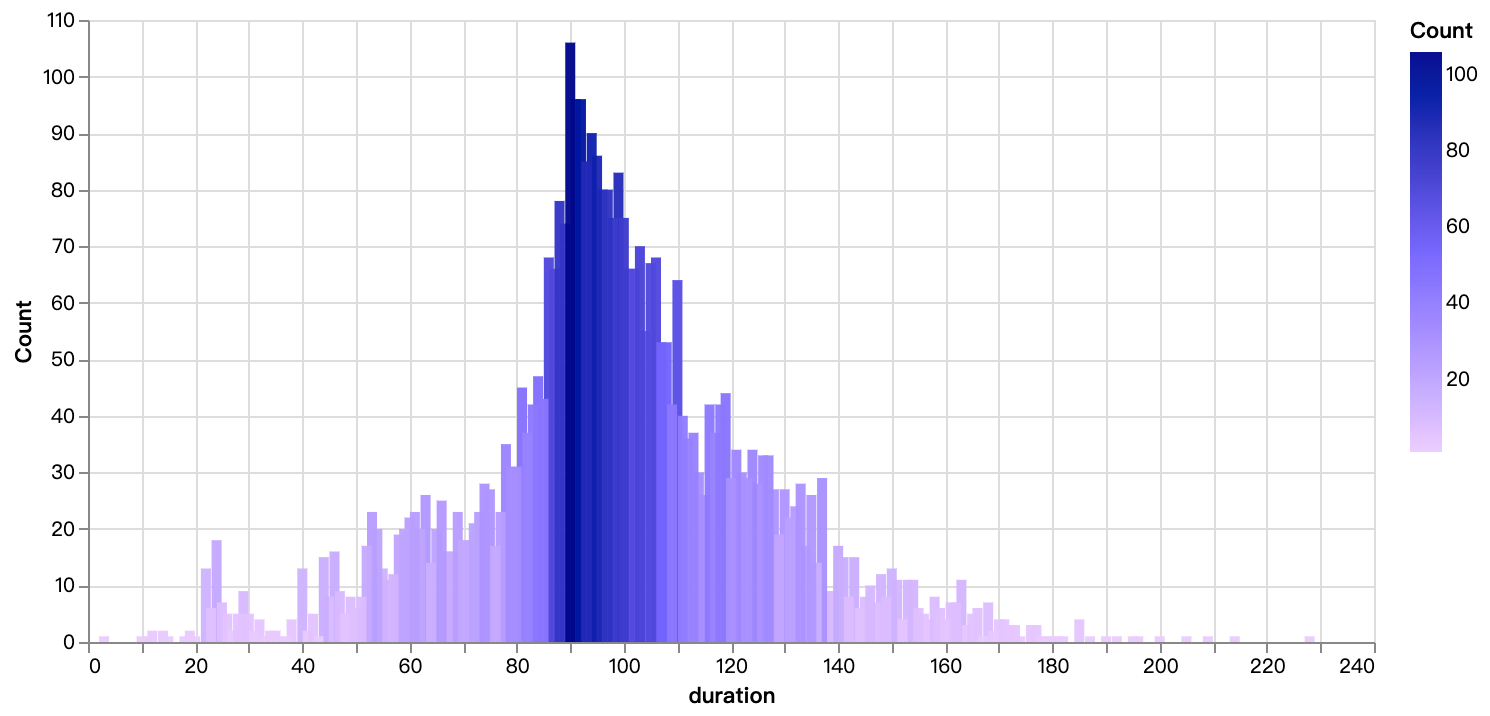
walker0.display_chart("Chart 7", title="テレビ番組のシーズン分布")
2. Netflixデータの国別分析
このセグメントでは、国別にコンテンツを分析しています。国別のデータを分割して再構成することで、異なる国でのコンテンツの配信状況を分析することができます。
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)こちら (opens in a new tab)でPyGWalkerユーザーインターフェースを試すことができます。
walker1.display_chart("チャート1", title="最も多いコンテンツの国々")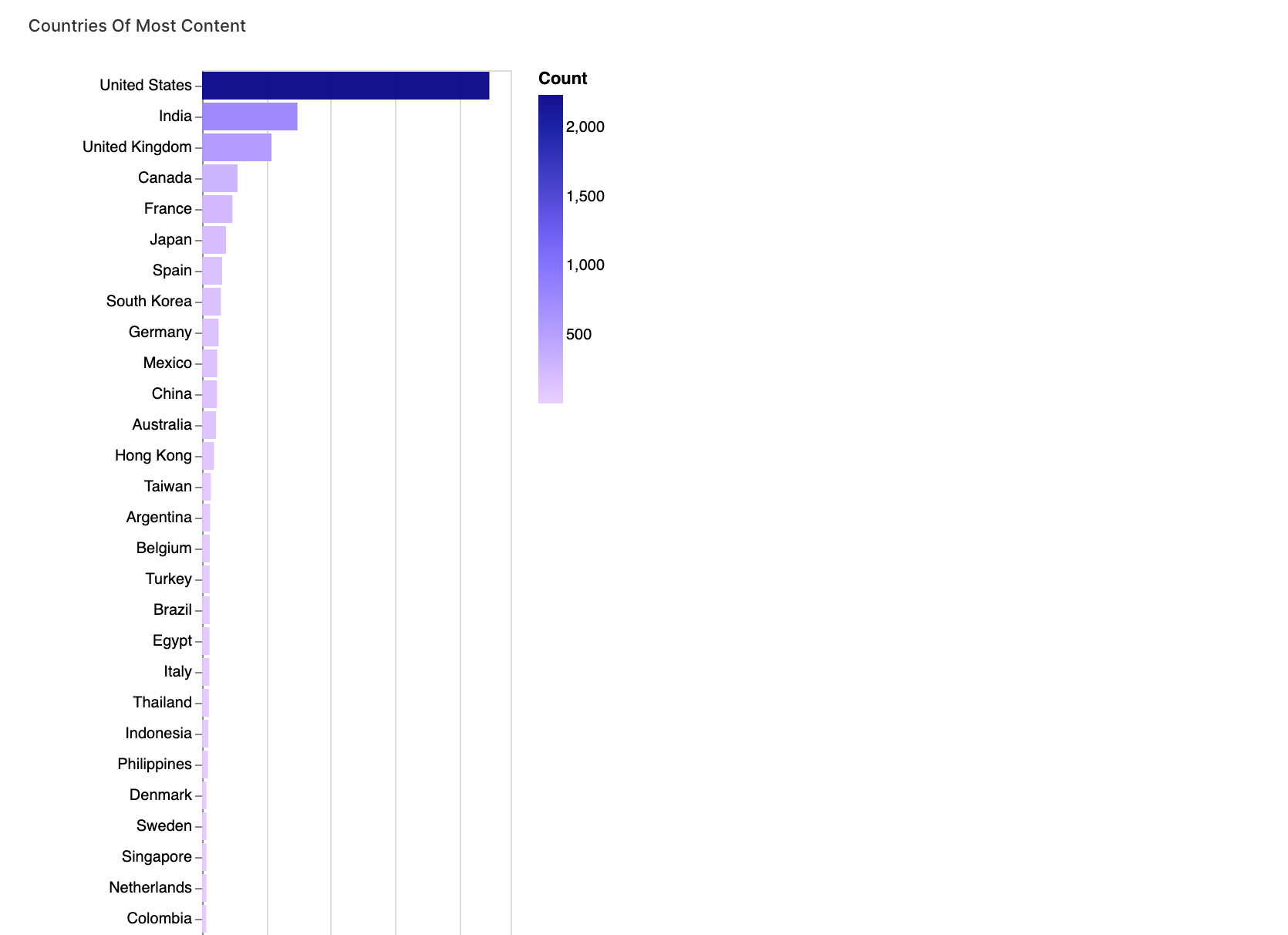
3. カテゴリーと評価の分析
最後に、カテゴリーと評価に焦点を当てます。このセクションでは、ジャンルごとのコンテンツの配信状況やそのジャンル内での評価のバリエーションを理解することができます。
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)こちら (opens in a new tab)でPyGWalkerユーザーインターフェースを試すことができます。
walker2.display_chart("TVカテゴリー", title="TV番組のカテゴリー分布")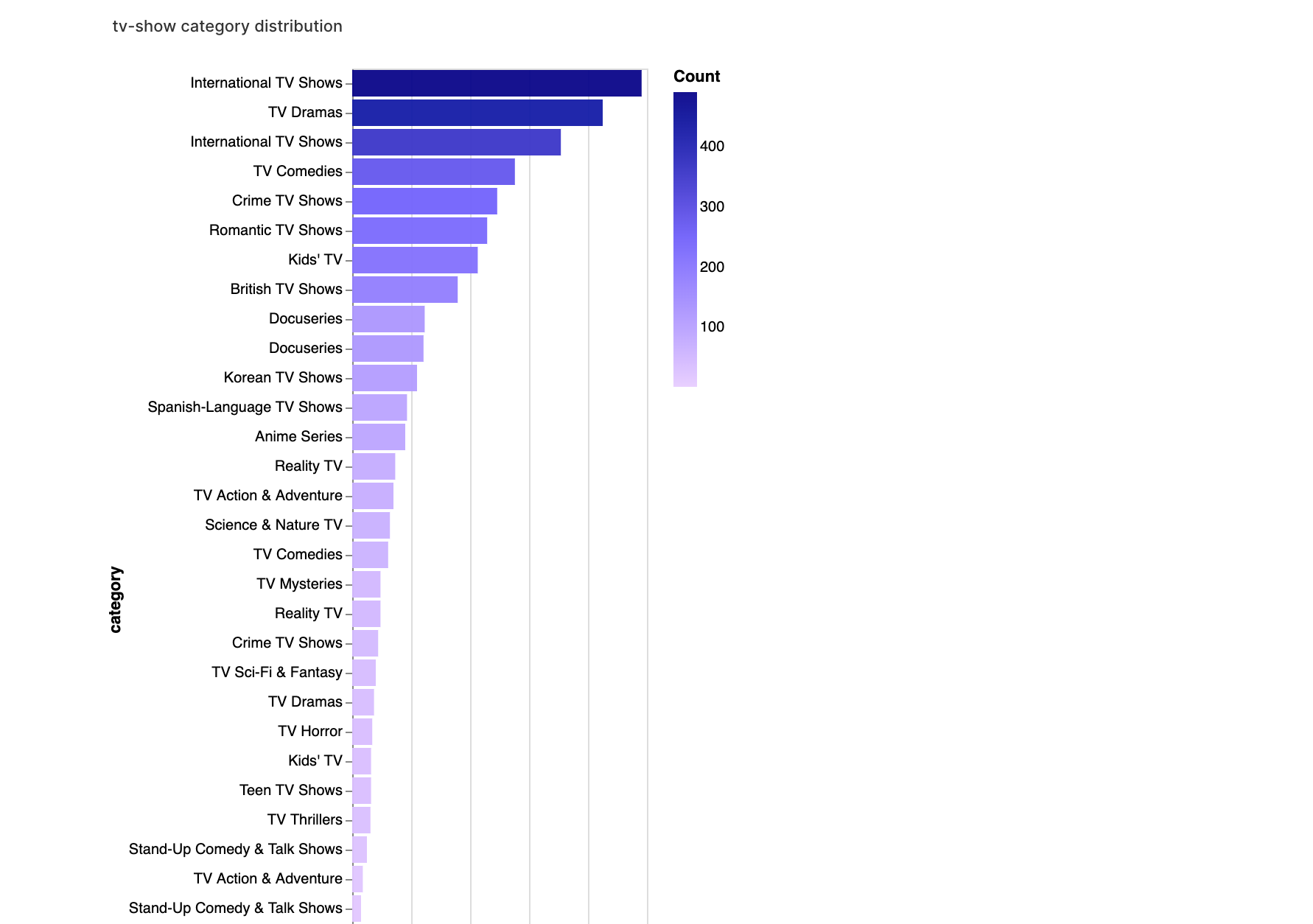
walker2.display_chart("映画カテゴリー", title="映画のカテゴリー分布")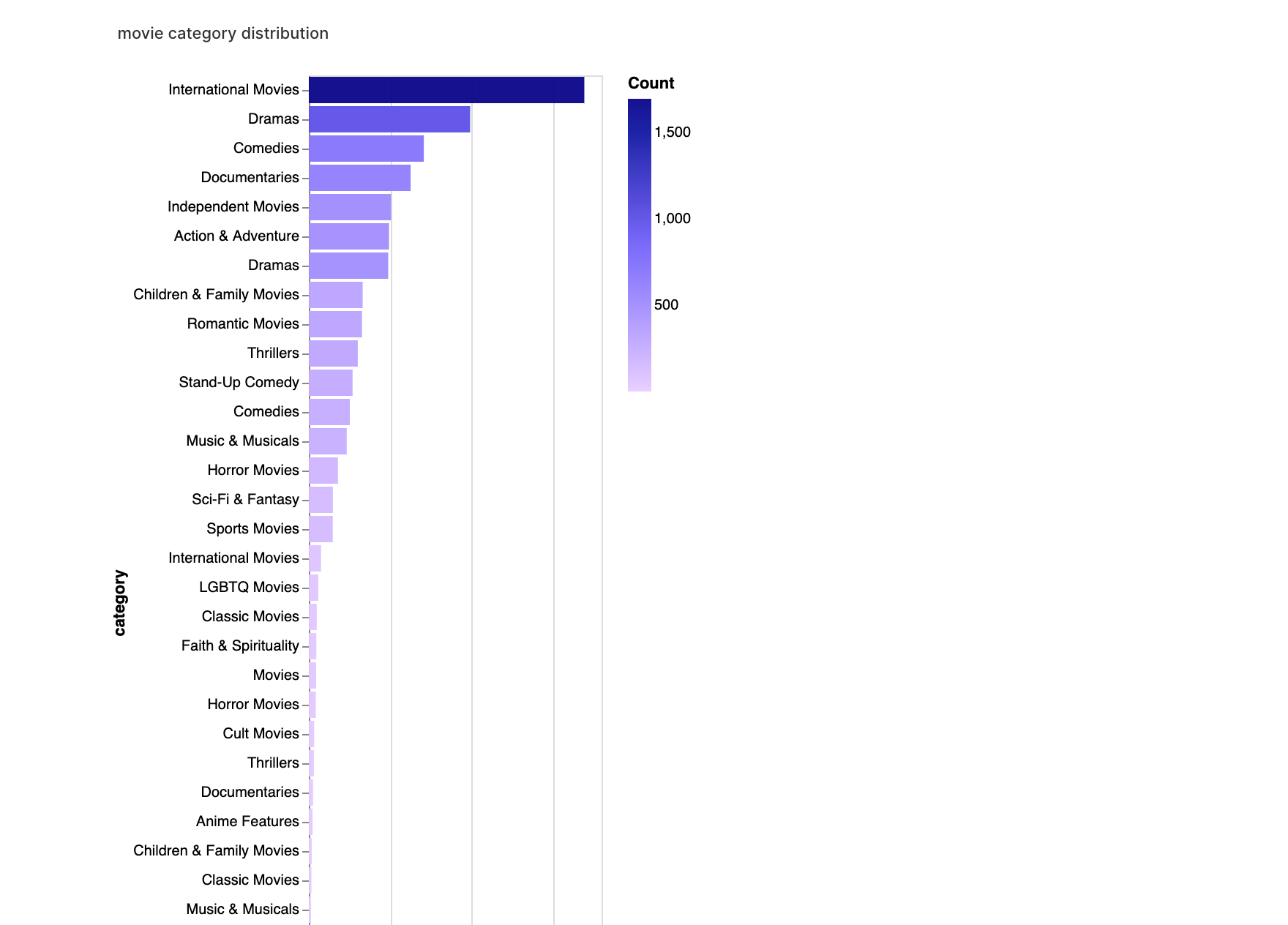
walker2.display_chart("評価カテゴリー(TV)", title="評価カテゴリーのヒートマップ(TV番組)")
walker2.display_chart("評価カテゴリー(映画)", title="評価カテゴリーのヒートマップ(映画)")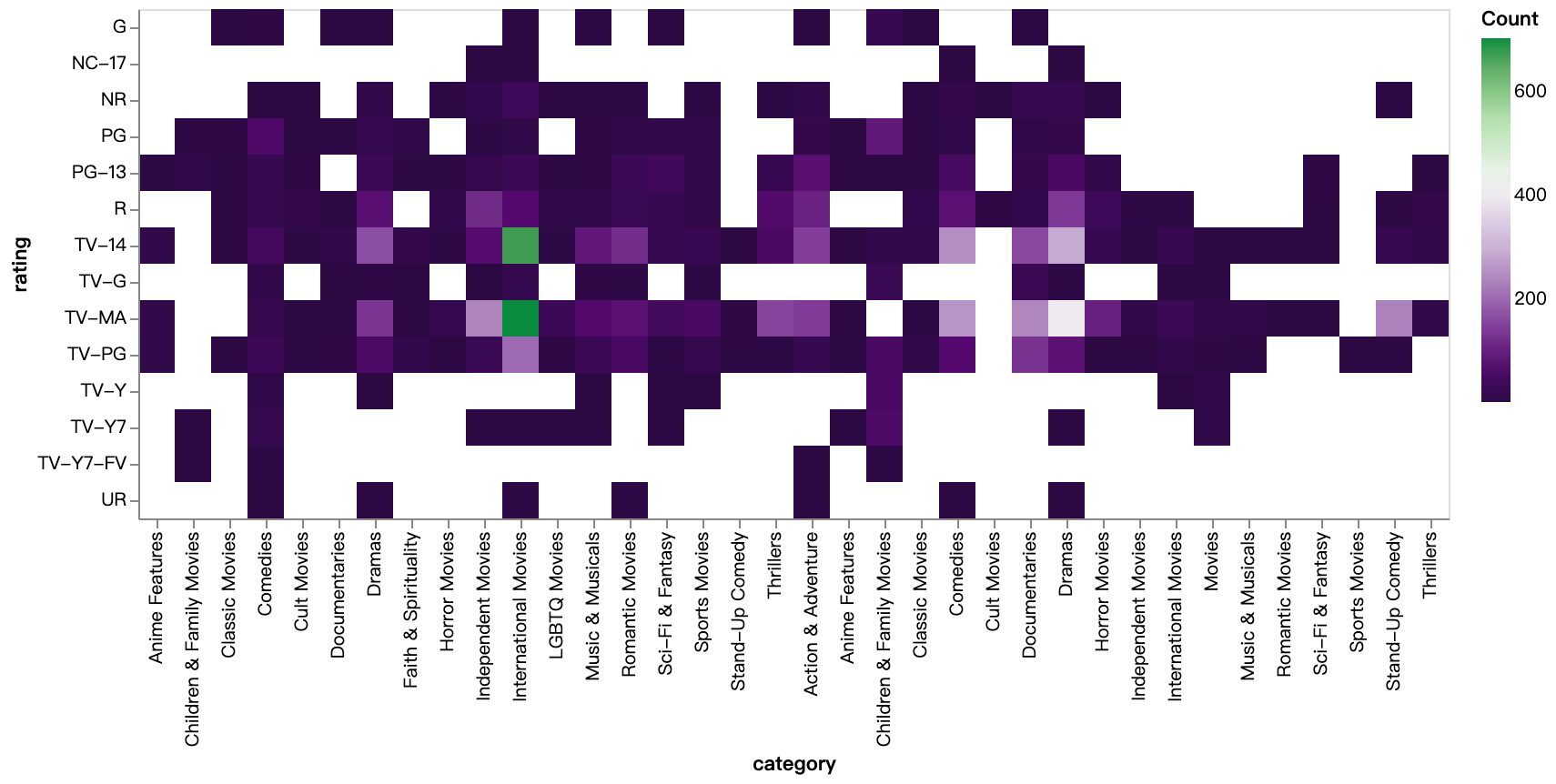
結論
PyGWalkerライブラリを使用してNetflixデータセットを包括的に探索した結果、Netflixコンテンツの多様な側面に深く入り込むことができました。PyGWalkerはビジュアライゼーションプロセスを簡素化し、必要なトレンドを明らかにするための強力なツールでした。分析は、成長パターン、好み、傾向についての明確さを提供しました。カテゴリーと評価についての詳細な分析により、映画とTV番組のジャンルの多様性と分布、およびそのジャンル内での評価のバリエーションが明らかになりました。
このドキュメントはKaggleノートブック (opens in a new tab)でも利用できます。
よくある質問
1. Netflixデータセットとは何ですか?
- Netflixデータセットは、Netflixプラットフォームで利用可能なコンテンツの詳細情報を提供するデータの集合です。このデータには、コンテンツのタイプ(映画またはTV番組)、タイトル、監督、キャスト、製作国、Netflixへの追加日、リリース年、評価、時間、ジャンル、簡単な説明などの要素が通常含まれています。これらのデータセットを使用することで、研究者やアナリストはプラットフォームのコンテンツの構造をより深く理解することができます。
2. Netflixデータセットはどのように活用できますか?
- Netflixデータセットはさまざまな方法で活用することができます:
- トレンド分析: 年ごとの成長パターン、好み、トレンドを理解します。
- 国別分析: 最も多くのコンテンツを提供している国や、さまざまな地域で人気のあるコンテンツのタイプを特定します。
- ジャンルの分布: 最も人気のあるジャンルや、映画とTV番組の間でどのように異なるかを探索します。
- 評価に関する洞察: さまざまなコンテンツのタイプにわたる評価の分布を分析し、視聴者の好みを特定します。
- データの可視化: PyGWalkerなどのツールを使用して、より深い洞察を得るためのインタラクティブな視覚化を作成します。
3. PyGWalkerとは何か、データの探索にどのような利点がありますか?
- PyGWalkerは、データの視覚化プロセスを効率化するために特に設計されたPythonライブラリです。ユーザーは最小限のコードでインタラクティブなチャートを生成できるため、データセットのパターンや洞察を簡単に発見することができます。Netflixのような大規模なデータセットを持つプラットフォームでは、PyGWalkerはデータの探索を簡素化し、わかりやすい視覚化を生成するために非常に便利なツールとなります。