異常値検出のマスター: データ アナリスト向けの総合ガイド

外れ値は、残りのデータと大きく異なるデータ ポイントであり、多くの場合、分析の精度が損なわれます。 外れ値を特定して処理することは、データ分析ワークフローの重要なステップです。 この記事では、R で 外れ値を特定する方法 と、ワンクリックで外れ値を特定できる視覚的で直感的なツールについて説明します: RATH
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
外れ値を検出する最良の方法: RATH の使用
Kanaries RATH (opens in a new tab) を使用すると、コーディングの知識がなくても簡単に外れ値を検出できます。 以下の手順に従います。
ステップ1。 RATH Online Demo (opens in a new tab) で RATH を起動します。 [データ接続] ページで、ファイル オプションを選択し、Excel または CSV データ ファイルをアップロードします。
ヒント: ClickHouse、BigQuery、SQL などのオンライン データベースからデータをインポートする場合は、データベース オプションを選択し、RATH をデータに接続します。
ステップ2。 [データ ソース] タブには、データの概要が表示されます。
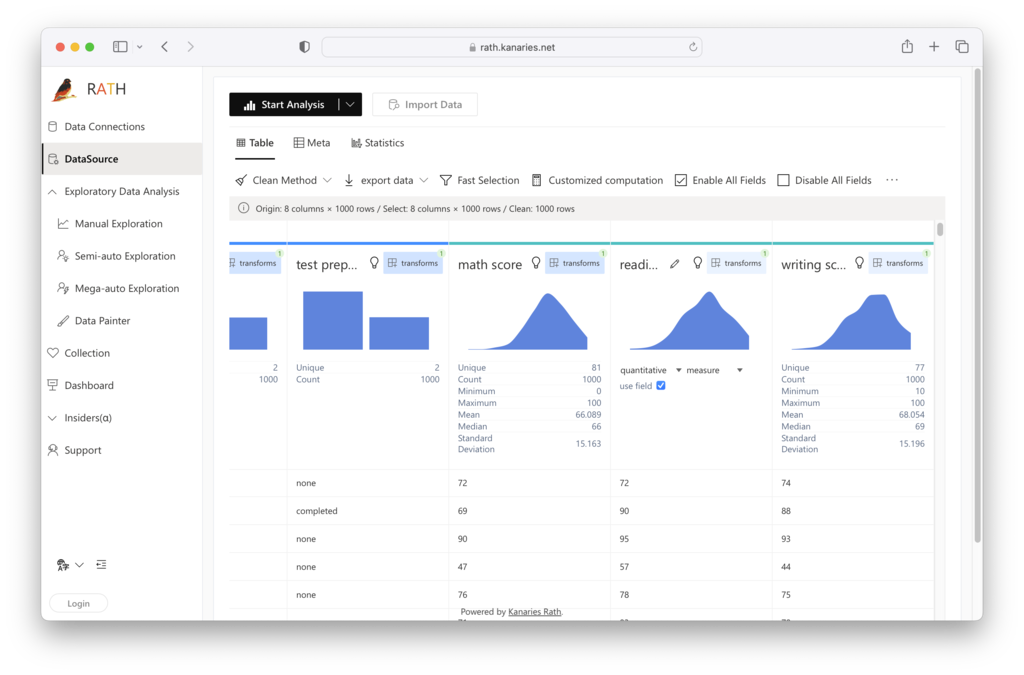 RATH は、どの変数が異常値であるかを自動的に検出し、再グループ化に Isolation Forest アルゴリズムを使用することを提案できます。
RATH は、どの変数が異常値であるかを自動的に検出し、再グループ化に Isolation Forest アルゴリズムを使用することを提案できます。
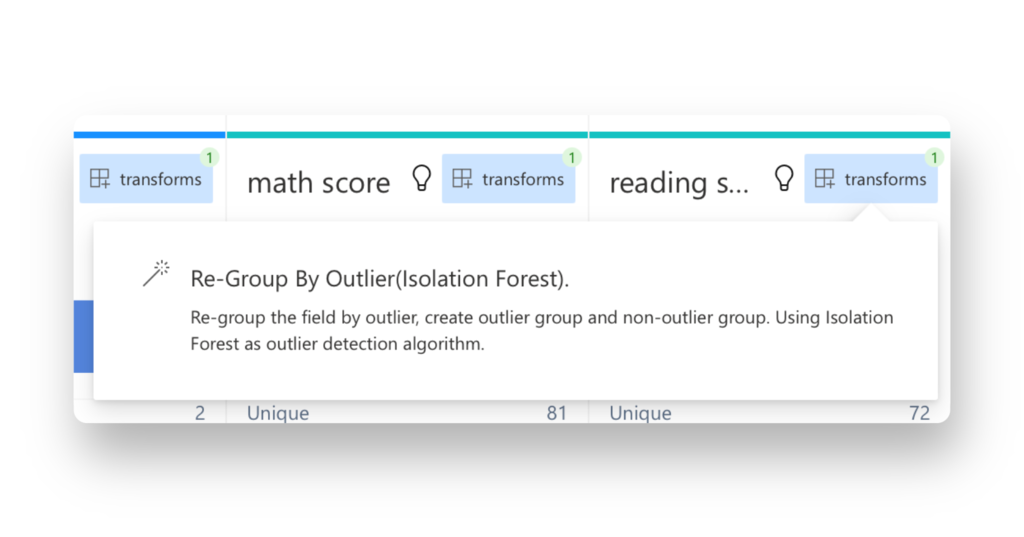
オプションをクリックして、Isolation Forest アルゴリズムを外れ値に適用します。
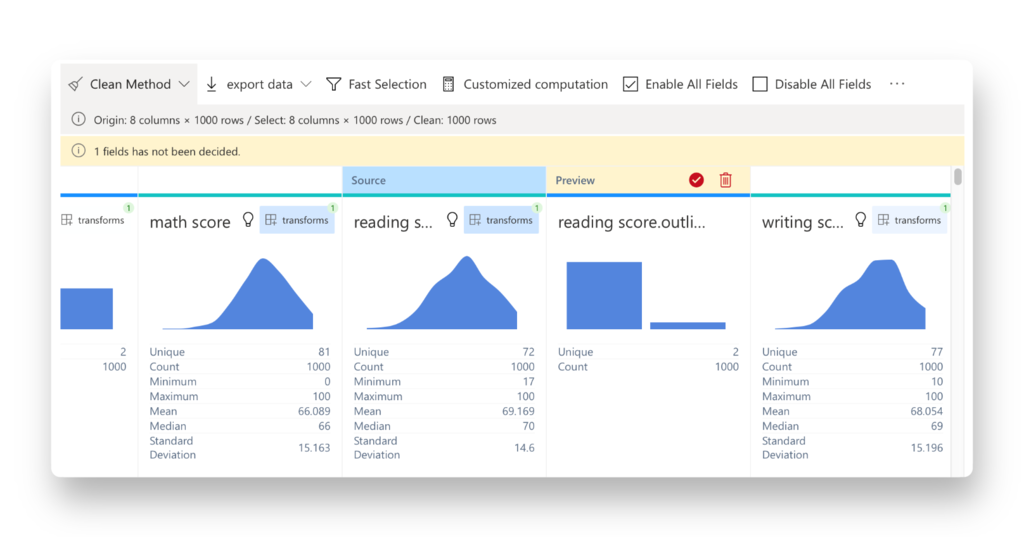
RATH は、外れ値検出のプロセスを非常に簡単かつシンプルにします。 さらに、RATH は高度なデータ分析自動化ツールでもあり、データ内のパターンと因果関係を見つけるプロセスを簡素化します。 Tableau のようなドラッグ アンド ドロップ インターフェイスを使用すると、コーディングの知識がなくても 多次元データの視覚化を作成 でき、高度な拡張分析エンジンで自動化された洞察を得ることができます。
RATH を使い始めるには、GitHub リポジトリ (opens in a new tab) にアクセスし、オンライン デモ (opens in a new tab) を試してください。

R の外れ値検出手法
箱ひげ図による外れ値の特定
箱ひげ図は、データの分布を視覚化し、外れ値を特定するためのシンプルかつ強力なツールです。 R では、次のコードを使用してボックス プロットを作成できます。
boxplot(dataset$column_name, main="Box Plot", xlab="Column Name", ylab="Values")データセットをデータセットの名前に置き換え、column_name を分析する特定の列に置き換えます。 箱ひげ図には、データの四分位範囲 (IQR)、中央値、および潜在的な外れ値が表示されます。 外れ値は、通常、箱ひげ図のひげを越えた個々の点としてプロットされます。
Z スコア法
Z スコア法は、データ ポイントが分布の平均からどれだけ離れているかを測定する統計手法であり、標準偏差で表されます。 R では、次のコードを使用して Z スコアを計算し、外れ値を特定できます。
z_scores <- scale(dataset$column_name)
outliers <- which(abs(z_scores) > 2.5)2.5 のしきい値は任意であり、特定のニーズに応じて調整できます。 Z スコアが 2.5 より大きいか -2.5 より小さいデータ ポイントは外れ値と見なされます。
テューキーのフェンス
Tukey のフェンスは、IQR に基づいて外れ値を検出する堅牢な方法です。 次の式を使用して、外れ値の下限と上限を定義します。
- 下限: Q1 - 1.5 × IQR
- 上限: Q3 + 1.5 × IQR R では、次のコードを使用して Tukey のフェンスを適用できます。
iqr <- IQR(dataset$column_name)
q1 <- quantile(dataset$column_name, 0.25)
q3 <- quantile(dataset$column_name, 0.75)
lower_boundary <- q1 - 1.5 * iqr
upper_boundary <- q3 + 1.5 * iqr
outliers <- dataset$column_name[dataset$column_name < lower_boundary | dataset$column_name > upper_boundary]R で外れ値を処理する
外れ値を特定したら、分析の目的に応じてそれらを削除または変換できます。
外れ値を取り除く
データセットから外れ値を削除するには、次のコードを使用します。
clean_data <- dataset[!(dataset$column_name %in% outliers), ]このコードは、特定された外れ値を含まない clean_data という新しいデータセットを作成します。 外れ値を削除すると、データセットの平均が変わる可能性があることに注意することが重要です。 データの分布によっては、平均値が外れ値に対して非常に敏感になる可能性があり、外れ値を削除すると、データの中心傾向がより正確に表現される可能性があります。
異常値の変換
外れ値を削除する代わりに、それらを変換して分析への影響を減らすことができます。 一般的な変換手法には次のものがあります。
- Winsorization: 極端な値を、最も近くの外れていないデータ ポイントに置き換えます。
- 対数変換: データに対数変換を適用することで、極端な値の影響を軽減できます。 R では、DescTools パッケージの winsorize 関数を使用して Winsorization を適用できます。
library(DescTools)
winsorized_data <- Winsorize(dataset$column_name, probs = c(0.01, 0.99))ログ変換を適用するには、次のコードを使用します。
log_transformed_data <- log(dataset$column_name)ログ変換では、すべてのデータ ポイントが正である必要があることに注意してください。 データに負の値が含まれている場合は、変換を適用する前にデータに定数を追加する必要がある場合があります。
統計的尺度とモデルに対する外れ値の影響
外れ値は、さまざまな統計的測定およびモデルに大きな影響を与える可能性があります。
- 平均: 前述のように、平均は外れ値の影響を受けやすく、外れ値が削除されるとその値が大幅に変化する可能性があります。
- 中央値: 中央値はデータの中間値を表すため、外れ値に対してより耐性があります。
- 標準偏差: 標準偏差は、平均値周辺のデータ ポイントの分散を測定するため、異常値に敏感です。
- 相関: 異常値は変数間の相関に影響を与え、誤った関係や誤解を招く関係につながる可能性があります。
- ランダム フォレスト: ランダム フォレスト モデルは、極端な値に対してより堅牢なデシジョン ツリーに依存しているため、一般的に異常値の影響を受けません。
- 散布図: 外れ値は、通常、データのメイン クラスターから離れた孤立した点として表示されるため、散布図で簡単に識別できます。
RATH による外れ値の視覚化
RATH の強力な視覚化機能を使用すると、外れ値を特定して分析するための洞察に満ちたプロットを作成できます。 RATH の高度なデータ視覚化機能を活用することで、散布図、箱ひげ図、およびその他の視覚化を自動的に作成して、外れ値がデータに与える影響を調べることができます。
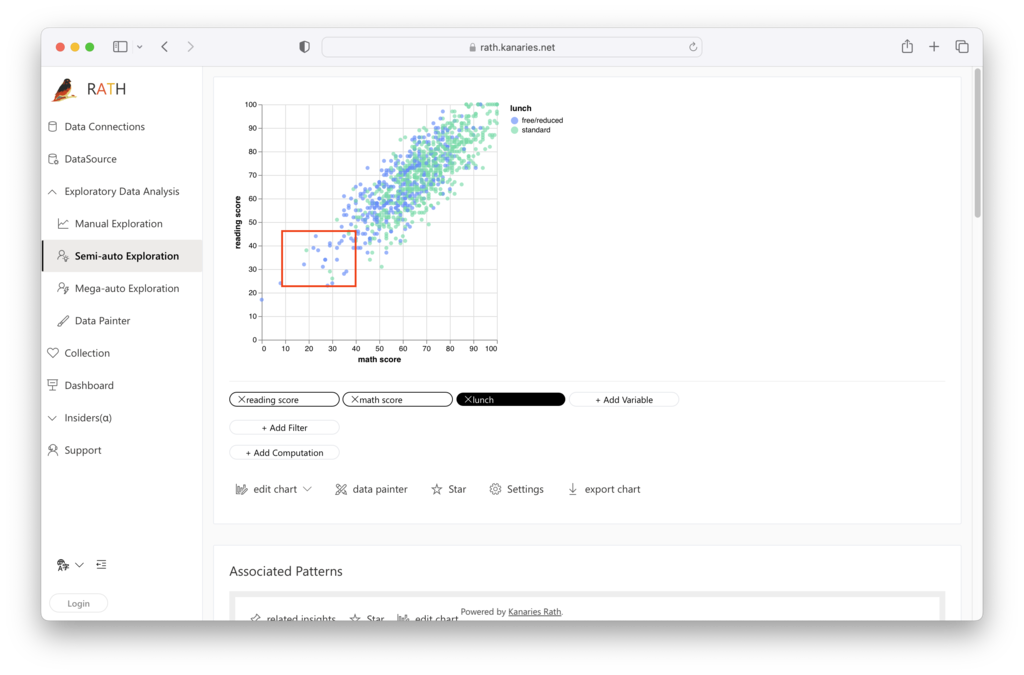
分析スキルをさらに強化するには、RATH の拡張分析エンジンを使用して探索的データ分析ワークフローを合理化し、データ内のパターンと因果関係を発見することを検討してください。
結論
外れ値の検出は、データ分析プロセスにおける重要なステップです。 この包括的なガイドでは、自動化されたデータ分析と視覚化のための強力なツールである RATH を使用して、R で外れ値を特定して処理するためのさまざまな手法について説明しました。 これらの方法を習得することで、データ分析結果の正確性と信頼性を確保できます。 ですから、今すぐ RATH でデータの探索を開始し、データ分析スキルを次のレベルに引き上げましょう!