ChatGPT Code Interpreter (ADA) の力: 1 行もコードを書かずにデータ可視化を作る

長いあいだ、生データを意味のあるインサイトに変える最大の壁は「コードを書けるかどうか」でした。ChatGPT Code Interpreter、現在の名称である Advanced Data Analysis (ADA) によって、その壁は大きく下がりました。
ADA の魅力はとても分かりやすいです。ファイルをアップロードし、見たい指標やグラフ、分析内容を自然言語で伝えるだけで、ChatGPT が内部の Python 環境で処理を進めてくれます。
つまり、Python、可視化ライブラリ、ファイル処理、データ整形機能を備えた分析環境が、ChatGPT の中にそのまま入っているようなものです。
要点だけ先に言うと、ADA は ChatGPT 内で素早く 1 回限りの分析をするのに向いています。一方で、実際の仕事が Jupyter notebook、既存の kernel、ローカルファイル、継続中の notebook セッションの中で進むなら、AI agent をそのネイティブな環境に入れた方が自然です。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
ChatGPT Code Interpreter でデータ可視化をシンプルにする
いまや多くのチームにとって、データを可視化して素早く理解することは必須です。従来のワークフローでは、まず次のような作業が必要でした。
- データをエクスポートする
- Python や SQL を書く
- スクリプトをデバッグする
- グラフライブラリを設定する
非エンジニアにとっては、最初のグラフにたどり着くまでの摩擦がかなり大きい流れです。
そこで意味を持つのが ChatGPT Code Interpreter (ADA) です。ADA は次のことを行えます。
- CSV、Excel、JSON、PDF などの一般的な形式を読み込む
- データを自動でクリーニングし前処理する
- サンドボックス環境で Python を実行する
- Matplotlib、Seaborn、Plotly などでグラフを生成する
- 生成結果を画像やダウンロード可能なファイルとして出力する
しかも出発点は自然言語のプロンプトだけです。
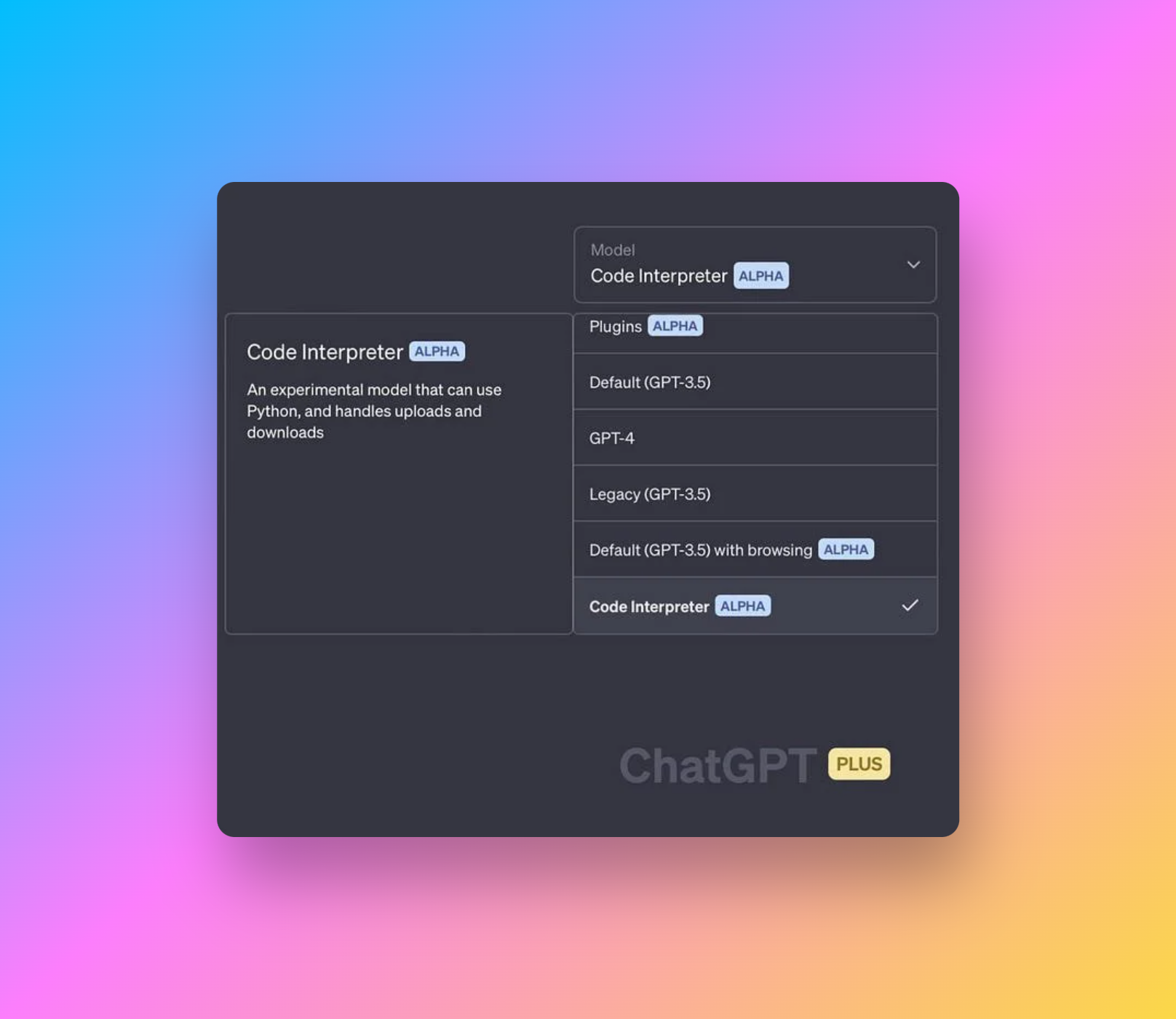
例:
ある期間の製品別売上を可視化したいとします。従来なら SQL や Python を書く場面です。
ADA なら、次のように伝えるだけで始められます。
「アップロードしたファイルを使って、2024 年 Q1 の製品別売上の棒グラフを作ってください。」
すると ChatGPT がデータの読み込み、整形、プロット、軸の調整、ラベル付け、エクスポートまで処理できます。

棒グラフだけでなく、次のような可視化にも対応できます。
- 折れ線グラフ
- 散布図
- ヒートマップ
- インタラクティブな可視化
- ヒストグラム、箱ひげ図、回帰グラフなどの統計可視化
必要なときに 専属のデータアナリスト がいる感覚に近いです。ChatGPT と分析の関係をもう少し広く見たいなら、GPT-4 がデータ分析に意味すること も参考になります。
ADA の体験が好きでも、Jupyter の中で続けたいなら
ADA が好まれる理由は明快です。やりたいことを説明し、モデルにコードを書かせて実行し、結果を見て、そのまま次の指示に進めます。このループが 1 つの会話の中でまとまっています。
ただし、多くのアナリストや研究者、データサイエンティストにとって、実際の仕事は別のクラウド sandbox の中ではなく、既存の notebook、依存関係、ローカルファイル、Jupyter のセッション状態の中で進みます。
だからこそ RunCell (opens in a new tab) はこのテーマと相性がよいです。RunCell は Jupyter 向けの AI agent であり、notebook の文脈、DataFrame、前の cell、現在の実行状態を理解できます。つまり、ADA に近い自然言語ベースの体験を、よりネイティブな notebook ワークフローに持ち込めます。
RunCell: AI agent を Jupyter notebook に直接入れる→実務では、違いはだいたい次のように表れます。
| ニーズ | ADA | RunCell |
|---|---|---|
| ファイルを 1 つアップロードして素早く単発分析する | 向いている | 可能だが主戦場ではない |
| 既存の notebook、kernel、メモリ上の変数をそのまま使う | 制限がある | 向いている |
| Jupyter 内で DataFrame、グラフ、cell を繰り返し更新する | 間接的 | より強い |
| ローカル寄りの notebook 環境で自然に作業を続けたい | やや不向き | より自然 |
もし日常の作業がすでに notebook 中心なら、Jupyter 向け RunCell ガイド を読むとつながりやすいです。より広く AI コーディングツールを比較したいなら、2026 年のおすすめ AI コーディングツール もあります。
ChatGPT Code Interpreter がコーディング体験をどう変えたか
ADA 以前は、次のことを自分でこなす必要がありました。
- Python を知っている
- ライブラリをインストールする
- 環境を管理する
- エラーを手でデバッグする
今は、欲しい結果を 説明する ところから始められます。
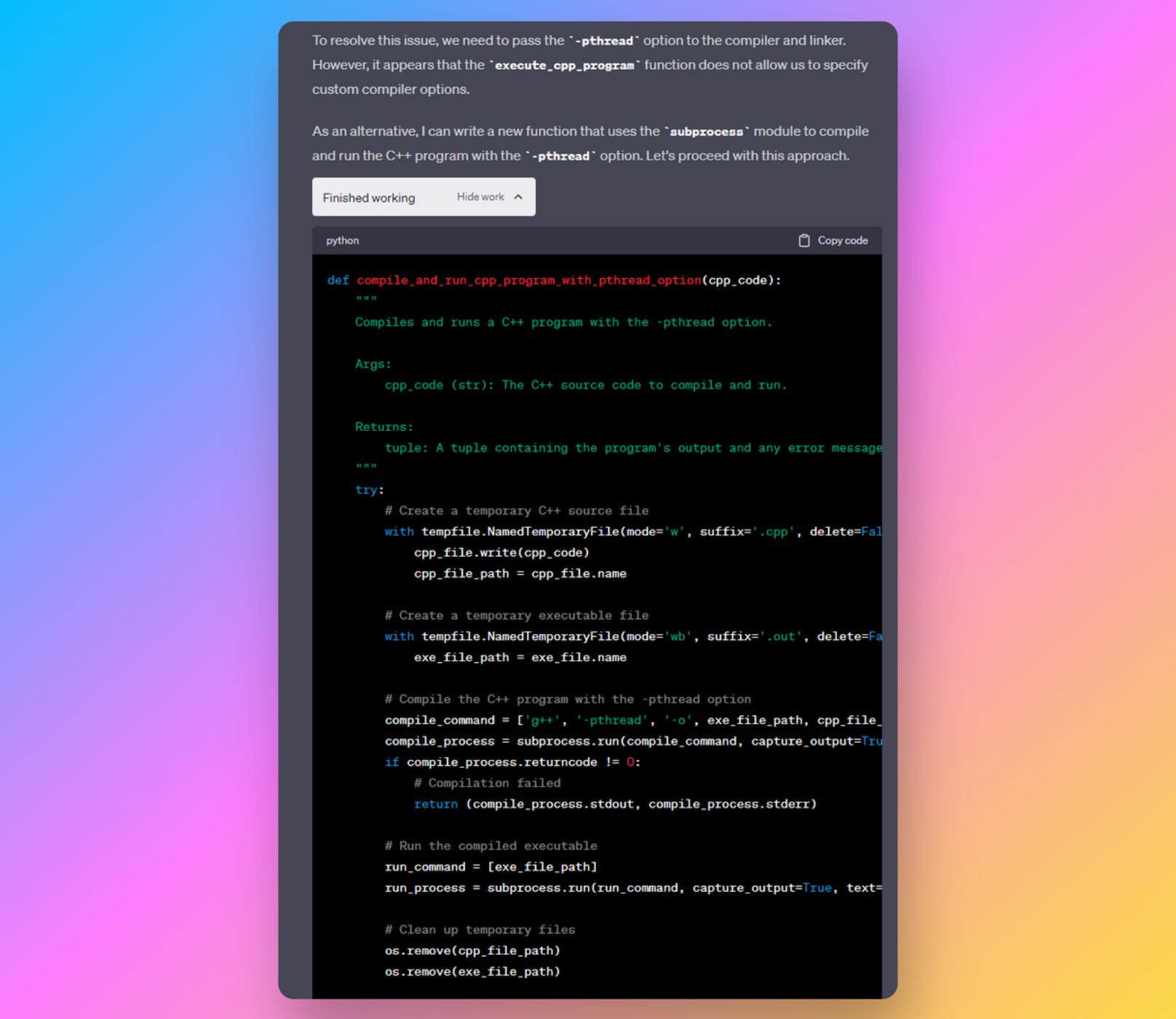
ADA は自然言語を実行可能なコードに変え、次のような処理を支援します。
- データクリーニング
- データ変換
- 統計モデリング
- 回帰
- クラスタリング
- 可視化
しかも、手作業のセットアップをかなり減らせます。
これにより 技術力 と 分析意図 のあいだのギャップが小さくなります。そこまで来ると、次に大事になるのは「ChatGPT の中で完結させるか」「実際に使っている notebook 環境へ同じ対話体験を持ち込むか」です。
ChatGPT Code Interpreter を使ったデータ可視化の実例
例 1: 記述分析と可視化
Ethan Mollick 氏は XLS ファイルをアップロードし、ADA に次のように依頼しました。
- 「記述統計を出して」
- 「主要なパターンを可視化して」
- 「回帰と診断を実行して」
するとモデルは自動的に次を生成しました。
- サマリーテーブル
- ヒストグラム
- 散布図
- 回帰結果
- 結果の解説
これは、自然言語だけで複数ステップの分析が回ることを示しています。
例 2: 感度分析と適応的な問題解決
セッション状態が乱れた場面でも、ADA は分析ロジックを復元して続行できました。これは次の能力を示します。
- 不足した文脈を推論する
- 中間ステップを復元する
- 最初からやり直さずに分析を続ける
実務の messy な分析ではかなり重要な強みです。
例 3: UFO 目撃情報のヒートマップ
ノイズの多い元データを渡しても、ADA はデータを整形し、次を生成できました。
- ヒートマップ
- 地理可視化
- 外れ値検出の結果
これらが 1 回の指示から進む点が重要です。
こうした例を見ると、ADA が複雑な分析手順を会話型ワークフローへ変えていることが分かります。
ChatGPT Code Interpreter を使ってデータ可視化を始める方法
始め方はシンプルです。
- CSV、Excel、JSON、TSV、PDF テーブル、ZIP などのデータセットをアップロードする。
- 見たいものを自然言語で伝える。
「カテゴリごとに price と quantity の散布図を作って」
- ADA にデータ解析、グラフ生成、エクスポートを任せる。
- 会話を続けながら結果を調整する。
コードは不要です。環境構築も不要です。複数ツールを往復する必要もありません。
そのため ADA は次のような人に向いています。
- キャンペーンデータを見るマーケター
- 公開データを調べるジャーナリスト
- 課題や研究を進める学生
- 指標を確認するビジネスチーム
- グラフやレポートを速く作りたいアナリスト
もし用途がレポーティングや BI に近いなら、AWS データ可視化 や Airtable チャート も役立ちます。
ChatGPT Code Interpreter の代表的なユースケース
ADA は次のような作業に使えます。
✔ 探索的データ分析
- 要約統計量
- 欠損値検出
- 相関ヒートマップ
✔ データ可視化
- Matplotlib、Seaborn、Plotly、Altair によるグラフ
- 統計グラフ
- 時系列チャート
✔ データクリーニング
- 重複除去
- 型修正
- 外れ値検出
✔ データサイエンス作業
- 回帰
- クラスタリング
- 予測
- 特徴量エンジニアリング
✔ ファイル自動処理
- CSV から Excel への変換
- ファイル統合
- PDF からの表抽出
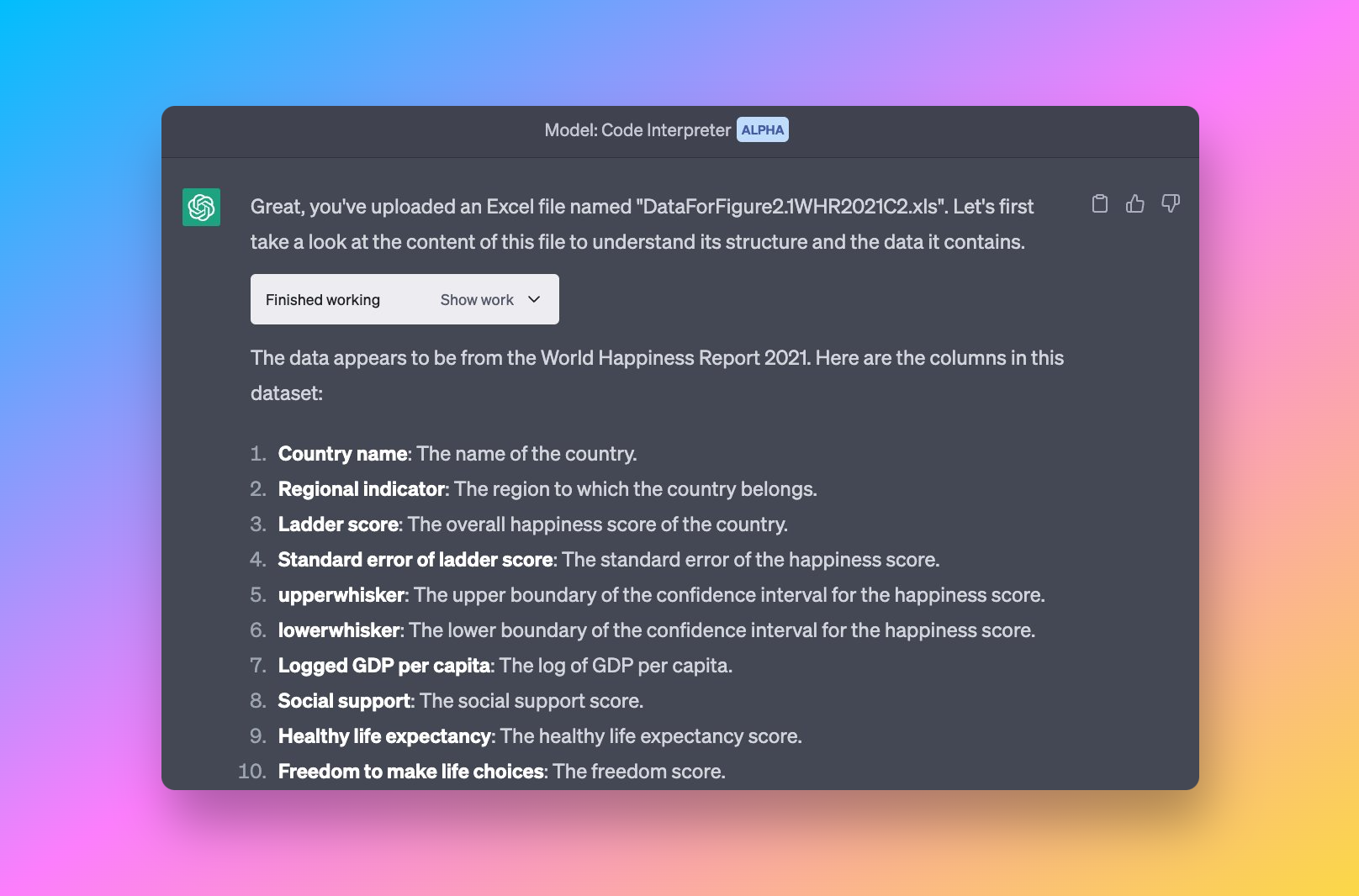
つまり、自然言語で扱える軽量なデータサイエンスツールキットです。
ChatGPT Code Interpreter と機械学習
ADA は、次のようなことができる機械学習モデルによって支えられています。
- ユーザー意図の解釈
- Python コード生成
- 出力確認
- エラー修正
- よりよい結果に向けた反復
これは、人間のアナリストがタスクを進めるときのフィードバックループにかなり近い動きです。
ADA の技術的背景をもう少し知りたい場合は、Nature のレポート (opens in a new tab) が参考になります。
会話型分析の次の段階: クラウド sandbox からネイティブなワークフローへ
ADA のようなツールは、次の考え方をまとめています。
- ノーコード
- ローコード
- 従来のプログラミング
- AI による推論補助
手でコードを書く代わりに、タスクを説明し、モデルにコードを書いて実行させるわけです。
この変化が、より広い ノーコード / AI 支援分析 の流れを加速しています。
ただし今は、「分析を別のクラウド会話に閉じ込めたくない」というニーズが強くなっています。ユーザーは Jupyter notebook、プロジェクトファイル、ローカルのデータディレクトリ、継続中の notebook セッションの中で agent を使いたいのです。
そこで意味を持つのが、RunCell のような notebook-native ツールです。ADA は「自然言語 + 実行環境」という組み合わせが有効だと証明しました。RunCell はそれを、よりネイティブな Jupyter ワークフローまで押し広げます。反復的な分析やローカル開発、プライバシーに配慮したデータ作業では、この方がしっくり来ることが多いです。
notebook ツール自体を比較したいなら、Top 10 Data Science Notebooks もどうぞ。
Related Guides
- Jupyter 向け RunCell ガイド
- 2026 年のおすすめ AI コーディングツール
- GPT-4 がデータ分析に意味すること
- AWS データ可視化
- Top 10 Data Science Notebooks
FAQs
ChatGPT Code Interpreter (ADA) とは何ですか?
ChatGPT の中にある Python 実行環境で、ファイル分析、計算、グラフ生成を自然言語プロンプトから進められる機能です。
どう使えばよいですか?
ファイルをアップロードし、やりたい分析を説明すると、ChatGPT がグラフ、要約、コード実行結果を返せます。
どの言語をサポートしていますか?
主に Python と、Pandas、Matplotlib、Seaborn、Plotly、NumPy、Scikit-Learn などの主要ライブラリです。
無料ですか?
通常は無料ではありません。Advanced Data Analysis は、ファイル分析に対応した有料 ChatGPT プランに含まれることが一般的です。最新の利用条件は OpenAI のプラン情報を確認してください。
ADA が使えない場合の代替はありますか?
単発のファイル分析を ChatGPT 内で素早く済ませたいなら ADA が直接的です。ただ、既存の Jupyter ワークフロー の中で AI agent を使いたいなら、RunCell (opens in a new tab) の方が関連性は高いです。notebook の文脈、cell、ローカルな作業状態をそのまま扱えるからです。
まとめ
ChatGPT Code Interpreter (ADA) は、多くの人のデータ作業の始め方を変えました。自然言語と Python 実行を組み合わせることで、分析と可視化のハードルを大きく下げています。
ChatGPT の中で素早く分析したいなら、今でも非常に使いやすい選択肢です。一方で、中心となる作業がすでに Jupyter にあるなら、RunCell のような notebook-native AI agent の方が自然な次の一歩になりやすいです。