Qwen3‑VL: 高度なビジョンを備えたオープンソースのマルチモーダルAI

TL;DR — Qwen が最新のオープンウェイト視覚言語シリーズである Qwen3‑VL を公開。フラッグシップの Qwen3‑VL‑235B‑A22B(Instruct + Thinking)は Apache‑2.0 でオープン、ネイティブ256K(最大1Mまで拡張可能)のコンテキスト、より強力な空間/動画推論、32言語のOCRを搭載。単なる認識にとどまらず、より深いマルチモーダル推論とエージェント型のUI制御を狙う大型モデル(重み約471GB)。多くのチームはまずAPIやホスティング推論から着手するだろう。(GitHub (opens in a new tab))
何が公開されたのか(そして、なぜ重要か)
Qwen3‑VL は Qwen チームの最新の視覚言語モデルファミリー。リポジトリとモデルカードでは、テキスト理解、視覚知覚/推論、長コンテキストの動画理解、そしてエージェント的なインタラクション(PC/モバイルのGUI操作など)にわたる強化が示されている。アーキテクチャとしては、長期動画に向けた Interleaved‑MRoPE、マルチレベルViT融合のための DeepStack、精密な動画の時間的モデリングのための Text–Timestamp Alignment を導入。(GitHub (opens in a new tab))
最初のオープンウェイト公開は約235Bパラメータの MoE モデル(A22B = トークンあたり約22Bがアクティブ)。Instruct と Thinking 版が Apache‑2.0 で提供。重点領域は STEM/マルチモーダル推論、空間知覚/2D–3Dグラウンディング、長尺動画理解、32言語のOCR。(Hugging Face (opens in a new tab))
リリース日: Qwen は Qwen3‑VL‑235B‑A22B の Instruct と Thinking の重みを 2025年9月23日 にリリースと記載。(GitHub (opens in a new tab))
主な仕様の早見表
| 機能 | Qwen3‑VL の詳細 |
|---|---|
| オープンウェイトのバリアント | 235B A22B の Instruct と Thinking(Apache‑2.0) |
| コンテキスト長 | ネイティブ 256K、1M まで拡張可能(Qwen のガイダンス) |
| Vision/Video | 空間推論を強化、長尺動画の時間的グラウンディング |
| OCR | 32言語、低照度/ブレ/傾きに頑健 |
| Agentic | GUIを読み取り、PC/モバイルのタスクで行動計画が可能 |
| サイズ | HFカードは約236Bパラメータ、コミュニティ報告では重み約471GB |
| フレームワーク対応 | 2025年9月中旬時点で公式に Transformers に対応 |
出典: リポジトリ/モデルカードの機能・エディション、コンテキスト長やエージェント機能の記述;Transformers 対応は HF ドキュメント;実用上の重みサイズは Simon Willison のノート。(GitHub (opens in a new tab))
Qwen2.5‑VL からの主な進化点は?
- 時間/空間モデリングの精度向上: Interleaved‑MRoPE と Text–Timestamp Alignment により、従来の T‑RoPE 手法よりも長尺動画におけるイベント局在化の精度向上を狙う。DeepStack は画像‑テキストの細粒度アラインメントを強化。(GitHub (opens in a new tab))
- より長いコンテキストと広いモダリティ対応: デフォルトで 256K トークン、1M への拡張パス。GUI、ドキュメント、長尺動画の理解が強化。(GitHub (opens in a new tab))
- より大型で推論特化のエディション: Thinking 版はマルチモーダル推論タスクを狙う。選定ベンチマークでは一部でクローズドモデルと競合/凌駕するとの自己報告。(Simon Willison’s Weblog (opens in a new tab))
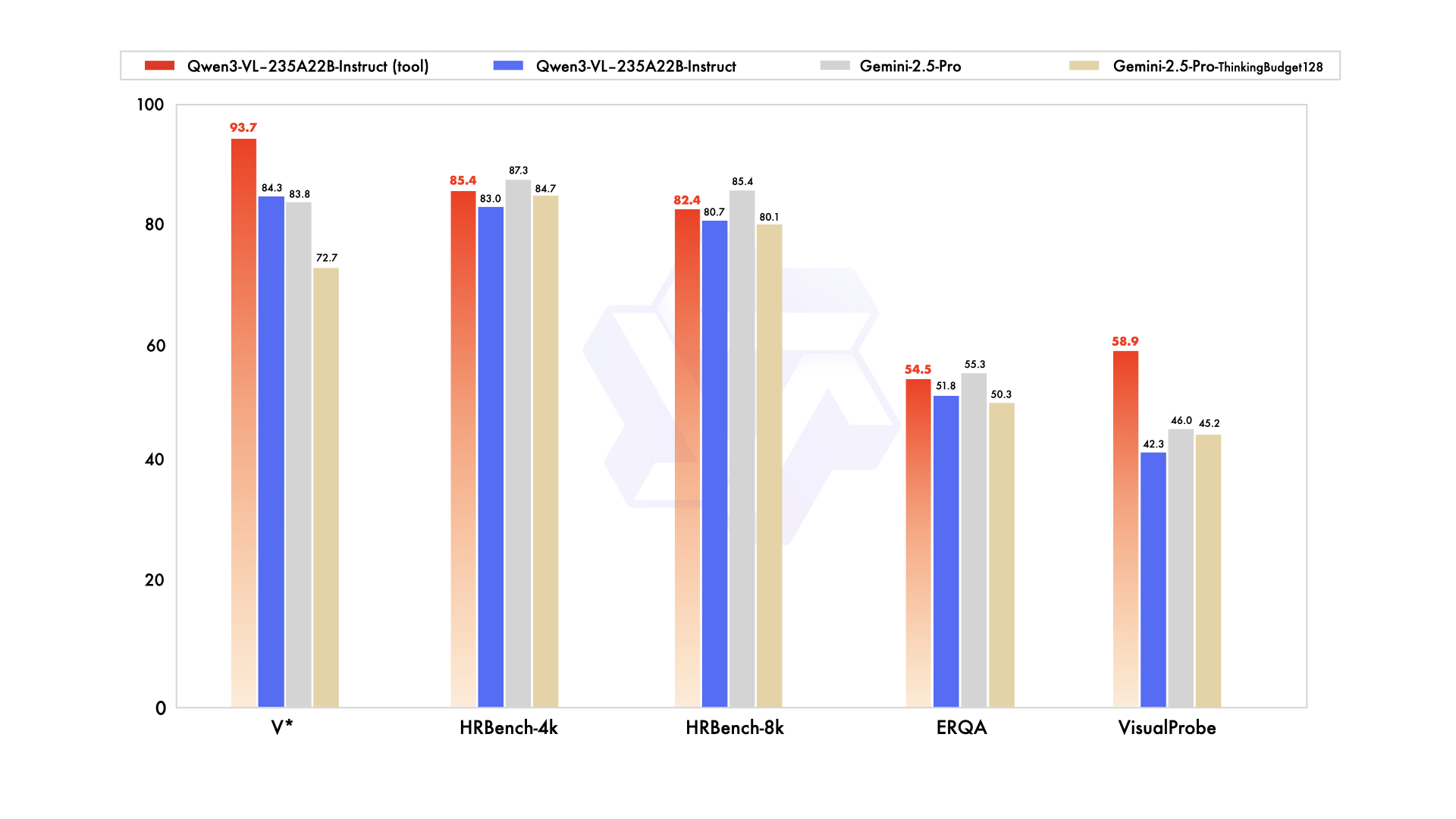
Qwen のブログやSNSでは、知覚系ベンチでの Gemini 2.5 Pro に対する同等/優位や、複数のマルチモーダル推論セットでのSOTAを主張。独立検証が必要。(Simon Willison’s Weblog (opens in a new tab))

公開物と実行場所
-
GitHub: コードスニペット(Transformers)、クックブック(OCR、グラウンディング、動画、エージェント)。論文は「近日」。(GitHub (opens in a new tab))
-
Hugging Face:
- Qwen3‑VL‑235B‑A22B‑Instruct(Apache‑2.0)(Hugging Face (opens in a new tab))
- Qwen3‑VL‑235B‑A22B‑Thinking(Apache‑2.0)(Hugging Face (opens in a new tab))
-
Transformers 対応: Qwen3‑VL は 2025年9月中旬に Transformers ドキュメントへ掲載。(Hugging Face (opens in a new tab))
-
ホスティング/API オプション: OpenRouter が Qwen3‑VL 235B のAPIを提供。Alibaba Cloud の Model Studio では Qwen‑Plus / Qwen3‑VL‑Plus の API SKU があり、thinking / non‑thinking モードや料金階層を用意。(OpenRouter (opens in a new tab))
命名に関する注意: HN では、Qwen3‑VL‑Plus(API)と Qwen‑VL‑Plus(旧シリーズ)は別物であること、また qwen‑plus‑2025‑09‑11 のようなスナップショット名が混乱を招くとの指摘。心配無用。(Hacker News (opens in a new tab))
ベンチマーク(要注意)
Qwen の発表では、Instruct が知覚寄りのテストで Gemini 2.5 Pro に「同等/優位」、Thinking は複数のマルチモーダル推論スイートで SOTA と主張。これらは自己申告であり、特にチャート/テーブル理解、図表推論、動画QAのようにデータ設計が結果を左右しがちな領域では、独立評価が重要。(Simon Willison’s Weblog (opens in a new tab))
とはいえ、コミュニティの初期ノートでは、Qwen3‑Omni → Qwen3‑VL‑235B の比較(例: HallusionBench, MMMU‑Pro, MathVision 等)で有意な伸びが示唆されている——ただし未査読。(Reddit (opens in a new tab))
なぜ学術界は Qwen を選び続けるのか(そして Qwen3‑VL の採用が速い理由)
多くのビジネス用途が利便性やSLAから GPT/Claude/Gemini を選ぶ一方で、研究グループは再現性、監査、アブレーション、領域特化の微調整のためにオープンウェイトを求めることが多い。Qwen はそれを後押ししてきた。
- 規模を跨ぐオープンウェイト(サブ2Bから 235B+ MoE まで)。研究室のGPUに合うサイズから始め、必要に応じてスケールアップ可能。(Qwen (opens in a new tab))
- 寛容なライセンス(多くのチェックポイントが Apache‑2.0)により、学術/産業の協業で摩擦が少ない。(Hugging Face (opens in a new tab))
- 論文での実績: 例として BioQwen(バイオメディカル双語モデル)、RCP‑Merging による Qwen2.5 ベースの長CoT/領域マージ研究、複数の医療VLMのRLチューニングが Qwen2.5 を起点に。(ciblab.net (opens in a new tab))
Qwen3‑VL は長尺動画と空間グラウンディングを強化しつつオープンウェイトを維持しているため、特にドキュメントインテリジェンス、科学図表、医療VQA、エンボディド/エージェント研究で「標準ベースライン」として迅速に採用されるだろう。
プロダクトチーム向け: 実践的な指針
- まずはホスティング、その後最適化: フラッグシップは非常に大きい(コミュニティ報告: 重み約471GB)。マルチGPU(A100/H100/MI300)環境がないなら、まず API(OpenRouter, Alibaba Model Studio)で利用し、Qwen2.5‑VL と同様に小型版の Qwen3‑VL が出揃ったタイミングでローカル/エッジ展開を再検討。(Simon Willison’s Weblog (opens in a new tab))
- 「Thinking」=常に優位 ではない: API は thinking / non‑thinking を提供し、トークン予算や料金が異なる。長尺/曖昧なマルチモーダル課題などに絞って thinking を使い分ける。(AlibabaCloud (opens in a new tab))
- コンテキスト費用に注意: 256K–1M のコンテキストは強力だがコスト高。ドキュメント/動画の分割戦略、事前パース(OCR/レイアウト)や RAG を活用し、プロンプトの肥大化を抑制。(GitHub (opens in a new tab))
- エージェント的UX: スクリーンショットや画面ストリームからの UI 自動化が必要なら、Qwen3‑VL のビジュアルエージェント機能を試す価値あり。ただし堅牢なツールAPIとガードレールの実装に投資を。(GitHub (opens in a new tab))
クイックスタート(Transformers)
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor # HF >= 4.57
model_id = "Qwen/Qwen3-VL-235B-A22B-Instruct" # or ...-Thinking
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(model_id, dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [{"role": "user", "content": [
{"type": "image", "image": "https://.../app-screenshot.png"},
{"type": "text", "text": "What button should I tap to turn on dark mode? Explain briefly."}
]}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])これは Qwen のモデルカード例に準拠(利用可能なら FlashAttention‑2 を有効化)。マルチ画像や動画の場合は、複数の {"type": "image"} エントリ、またはフレーム/画素制御を含む {"type": "video"} をリポジトリの例に従って渡す。(Hugging Face (opens in a new tab))
よくある落とし穴と注意点
- 命名の揺れ: 「Qwen3‑VL‑Plus」(API)と「Qwen‑VL‑Plus」(旧オープンウェイト系)は別物。読み込んでいる Model Studio のドキュメントと HF のページを要確認。(Hacker News (opens in a new tab))
- メモリの錯覚: 235B の MoE はオープンウェイトだが、MoE でも推論が小さくなるわけではない。メモリと帯域を十分に見積もること。重みはコミュニティでは約471GBとされる。(Simon Willison’s Weblog (opens in a new tab))
- 自己申告リーダーボード: マーケ資料は仮説と捉える。特にチャート/テーブル、ドキュメント、動画QAは自前で再評価を。
FAQ
Q: Qwen3‑VL‑235B‑A22B の「A22B」は何を意味する? A: Mixture‑of‑Experts モデルで、総パラメータは約235B、トークンあたりアクティブなのは約22B。計算効率と容量のトレードオフ。(Qwen (opens in a new tab))
Q: Instruct と Thinking はどう使い分ける? A: Instruct は汎用に整列され、概ね高速/低コスト。Thinking は内部で思考トレース(APIの「thinking mode」)を伴い、合成性の高い課題や長期依存で効く可能性がある一方、トークンコストは増える。手元の評価セットで両方を試すとよい。(Hugging Face (opens in a new tab))
Q: 「Gemini 2.5 Pro より優れている」は本当? A: 知覚系ベンチでの優位や複数のマルチモーダルタスクでのSOTAは Qwen の自己報告。独立比較には時間を要するため、コミュニティ評価や自分のドメイン固有テストを注視。(Simon Willison’s Weblog (opens in a new tab))
Q: ローカルで動かせる? A: 大容量メモリのマルチGPUがあれば可能。多くのチームはまず OpenRouter や Model Studio などのホスティング推論から始めるだろう。小規模なローカル試行には、より小さい Qwen2.5‑VL(72B/32B/7B/3B)を検討し、Qwen3‑VL の小型版登場を待つのが現実的。(OpenRouter (opens in a new tab))
Q: ライセンスは? A: 公開されている Qwen3‑VL‑235B‑A22B の重みは HF モデルカードいわく Apache‑2.0。チェックポイントごとにライセンスの確認を。(Hugging Face (opens in a new tab))
Q: 研究者が Qwen を選び続ける理由は? A: 規模を跨ぐオープンウェイト、寛容なライセンス、強力な多言語性。さらに、BioQwen、長CoTのモデルマージ、Qwen2.5 起点の医療VQA RL‑チューニングなど、Qwenベースのファインチューニング事例が豊富。(ciblab.net (opens in a new tab))
コミュニティの反応と議論
Hacker News のスレッドでは、Qwen3‑VL‑Plus と qwen‑plus‑2025‑09‑11 のようなスナップショット名の混同、実運用のための実務的な質問が早速挙がった一方、オープンウェイト公開のペースに対する期待も大きい。初期 adopters の温度感を知る良い窓口。(Hacker News (opens in a new tab))
開発者コミュニティによる簡潔なまとめとしては Simon Willison のノートが参考——モデル「サイズ」の現実や、小型版が後追いで出る見込みの妥当性を確認するのに有用。(Simon Willison’s Weblog (opens in a new tab))
総括
Qwen3‑VL は、「この画像を認識して終わり」から一歩進み、画像・文書・動画をまたいで「推論し、行動する」方向へと、オープンウェイトのマルチモーダルモデルの水準を引き上げた。しかも馴染みのあるオープンなツーリング(Transformers)上に着地している。研究用途では新たな明白なベースライン。プロダクトチームにとっては、フラッグシップの自前ホスティングは現時点では重いが、API経由で即価値がある——特にドキュメントインテリジェンス、画面理解、動画QAで。Qwen2.5 の前例どおり小型版の Qwen3‑VL が続く局面が、本格的な普及の転換点になるはずだ。
参考文献・関連リンク
- Repo: QwenLM/Qwen3‑VL — 機能、アーキテクチャ解説、クックブック、リリースログ。(GitHub (opens in a new tab))
- モデルカード: Instruct と Thinking(Apache‑2.0)。クイックスタートと性能チャート。(Hugging Face (opens in a new tab))
- Transformers ドキュメント: Qwen3‑VL の統合。(Hugging Face (opens in a new tab))
- Qwen3 概要と MoE サイズ(A22B の説明、オープンウェイトのラインアップ)。(Qwen (opens in a new tab))
- HN 議論: コミュニティの所感と命名の混乱。(Hacker News (opens in a new tab))
- API/料金: Alibaba Cloud Model Studio(thinking / non‑thinking、トークン予算)。(AlibabaCloud (opens in a new tab))
- Qwen を用いた研究例: BioQwen、RCP‑Merging、Qwen2.5 ベースの医療VQA RL‑チューニング。(ciblab.net (opens in a new tab))