DropNA を超えて: Null 値を処理するための包括的なガイド

データ アナリストが遭遇する最も一般的で重要なタスクの 1 つは、データ クリーニングです。 null 値の処理は、このプロセスの重要な部分です。 この記事では、PySpark DropNA、R の DropNA などの手法を調べて、SQL、JavaScript、Databricks などのさまざまなプログラミング言語やプラットフォームで null 値を管理できるようにします。 また、自動データ分析の副操縦士である RATH がこの取り組みをどのように支援できるかについても説明します。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
ワンクリックで Null 値を削除する方法
Kanaries RATH (opens in a new tab) はデータクリーニングの味方です。 その強力な データ準備ツール により、コードなしでデータ変換ワークフローを強化できます。 RATH を使用して null 値を削除する手順は次のとおりです。
ステップ1。 RATH Online Demo (opens in a new tab) で RATH を起動します。 [データ接続] ページで、[ファイル] オプションを選択し、Excel または CSV データ ファイルをアップロードします。
ステップ2。 [データ ソース] タブには、データの概要が表示されます。
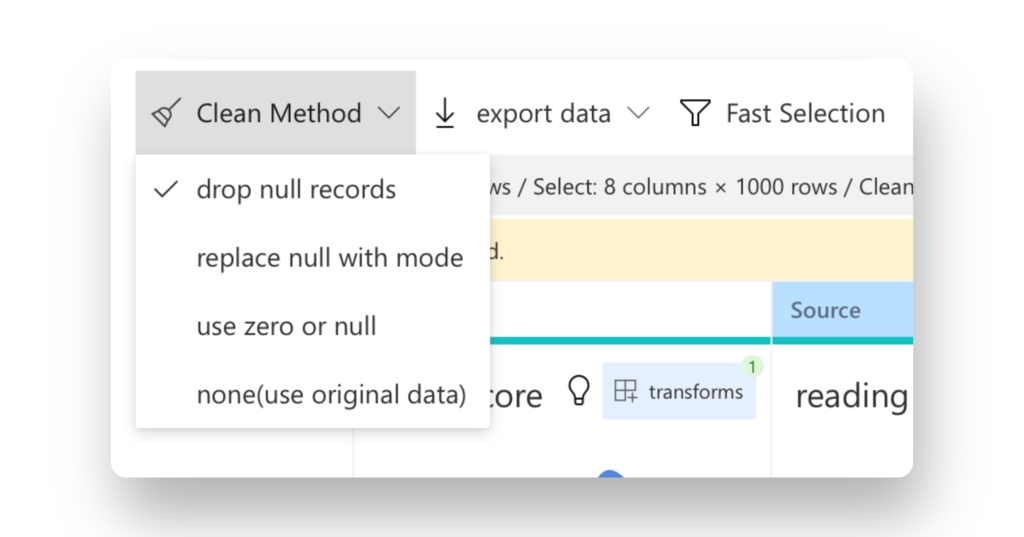
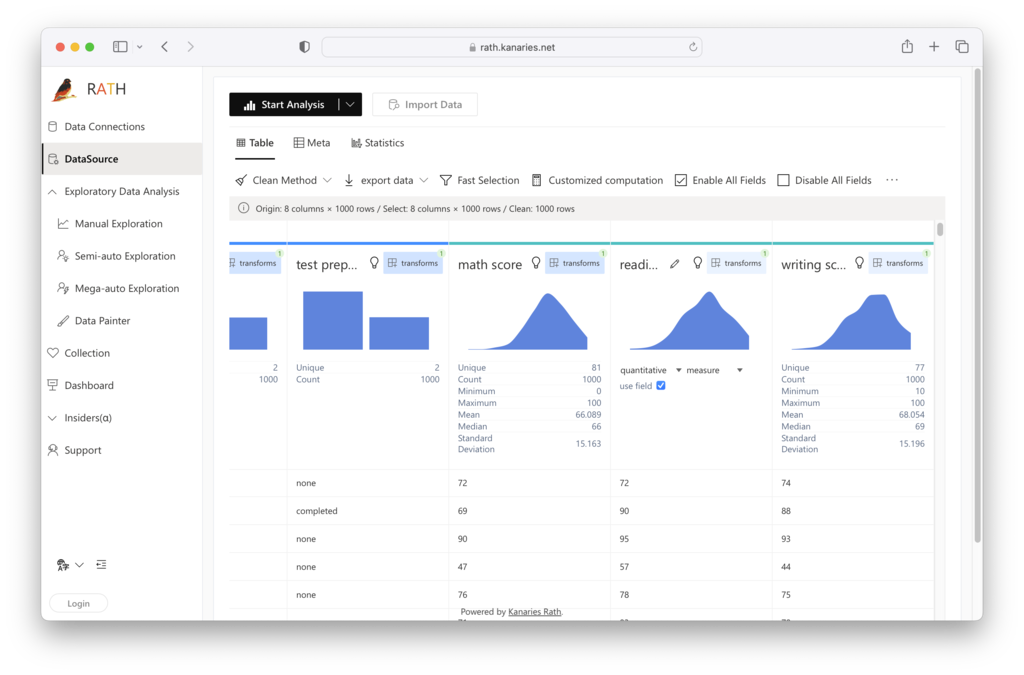 *Clean Method を選択します * タブバーのオプション。 次のいずれかのオプションを使用して、null 値を削除できます。
*Clean Method を選択します * タブバーのオプション。 次のいずれかのオプションを使用して、null 値を削除できます。
- null レコードを削除 -モードでヌル値を埋める
- ゼロまたはヌルを使用
- オリジナルデータを使用します。
データクリーニングに必要な前提条件はこれだけです。 RATH オンライン デモ (opens in a new tab) で今すぐ試すことができます。

Null 値を削除するその他のオプション
Databricks: プラットフォームでの Null 値への取り組み
Databricks は、データ エンジニアリングと分析に広く使用されているプラットフォームであり、PySpark と R 言語の両方をサポートしています。 そのため、R で PySpark DropNA または DropNA を利用して、Databricks での null 値の管理を行うことができます。 必要なライブラリとランタイム環境を使用して Databricks クラスターを構成してください。
JSON Null 値と SQL 除外の処理
SQL では、null 値を除外するのは、クエリに WHERE 句を追加するのと同じくらい簡単です。
SELECT * FROM employees WHERE age IS NOT NULL;JSON データの場合、次の Python の例のように、好みの言語で簡単なスクリプトを使用して null 値を除外できます。
import json
data = '[{"name": "Alice", "age": null}, {"name": "Bob", "age": 35}]'
json_data = json.loads(data)
clean_data = [item for item in json_data if item["age"] is not None]
print(clean_data)この Python スクリプトは、JSON データを読み取ってリストに読み込み、リスト内包表記を使用して年齢が null のオブジェクトを除外します。
PySpark ドロップNA
Apache PySpark は、大規模なデータセットを簡単に操作できる強力なデータ処理ライブラリです。 null 値の処理に関して言えば、PySpark DropNA は、これらの厄介な要素を DataFrame から削除するのに役立つ便利な関数です。 説明のために、次の例を考えてみましょう。
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("PySpark DropNA Example") \
.getOrCreate()
# null 値を持つサンプル DataFrame
data = [("Alice", 30, None),
("Bob", None, 5000),
(None, 40, 6000)]
columns = ["Name", "Age", "Salary"]
df = spark.createDataFrame(data, columns)
# null 値を含む行を削除
df_clean = df.na.drop()
df_clean.show()In this example, we create a simple DataFrame with some null values and use the drop() method to remove rows containing these values. The result is a clean DataFrame without nulls.
Array Remove Null Values in JavaScript
JavaScript, a popular language for web development, also requires handling null values. To remove null values from an array, you can use the filter() method:
const data = [1, null, 3, null, 5];
const cleanData = data.filter(item => item !== null);
console.log(cleanData);This JavaScript code snippet demonstrates how to remove null values from an array using the filter() method.
DropNA in R: Null Value Management in R Language
R is another popular language for data analysts, with its rich ecosystem of packages for data manipulation and analysis. To handle null values in R, you can use the na.omit() or drop_na() functions from the base R package and the tidyverse package, respectively.
# Load the required libraries
library(tidyverse)
# Create a sample data frame
data <- tibble(Name = c("Alice", "Bob", "Cindy"),
Age = c(30, NA, 40),
Salary = c(NA, 5000, 6000))
# Remove null values using drop_na()
data_clean <- data %>% drop_na()
print(data_clean)この R コードは、tidyverse パッケージの drop_na() 関数を使用して null 値を含む行を削除する方法を示しています。
結論
null 値の処理は、すべてのデータ アナリストにとってデータ クリーニングの重要な側面です。 PySpark DropNA、R の DropNA、およびその他の言語固有のアプローチなどの手法は、null 値を効率的に管理するのに役立ちます。 さらに、RATH は、自動データ分析のための強力で使いやすいソリューションを提供し、データがクリーンで、さらなる調査の準備が整っていることを保証します。 これらの手法とツールを習得して、データ分析機能を強化することで、時代を先取りしてください。