Pandas Plot によるデータの視覚化: 美しく洞察に満ちたプロットを簡単に作成する方法

データ サイエンスの世界では、データの視覚化は、複雑なデータ セットへの洞察を提供する上で重要な役割を果たします。 データ視覚化のための最も強力なツールの 1 つは、Python の Pandas Plot ライブラリです。これを使用すると、ユーザーはわずか数行のコードで見事なインタラクティブな視覚化を作成できます。
この記事では、Pandas Plot を使用して、棒グラフ、散布図、円グラフなど、さまざまな種類の視覚化を作成する方法について説明します。 また、Pandas Plot を強化する基盤となるライブラリである Matplotlib をインストールする方法についても説明します。 最後に、Python Pandas と統合するオープン ソースのデータ視覚化ツール PyGWalker について簡単に説明します。
- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
Pandas プロットでデータを視覚化する
Matplotlib のインストール
Pandas Plot でビジュアライゼーションを作成する前に、Matplotlib が Python 環境にインストールされていることを確認する必要があります。 Matplotlib は、Pandas Plot が視覚化を作成するために使用するデータ視覚化ライブラリです。
Matplotlib をインストールするには、pip パッケージ マネージャーを使用できます。
pip install matplotlib次に、matplotlib をインポートします。
import matplotlib.pyplot as pltPandas プロットで棒グラフを作成する
Pandas Plot を使用して単純な棒グラフを作成することから始めましょう。 架空の会社の月間売上高のサンプル データセットを使用します。
sales = {'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Sales': [10000, 20000, 30000, 25000, 15000, 18000]}
df = pd.DataFrame(sales)
df.plot(kind='bar', x='Month', y='Sales')
plt.show()上記のコードでは、まず月間売上高の辞書を作成し、それを Pandas DataFrame に変換します。 次に、DataFrame の plot メソッドを使用して棒グラフを作成し、x 軸と y 軸を指定します。
結果の棒グラフには、月ごとの売上高が棒として表示されます。x 軸には月のラベルが付けられ、y 軸には売上高のラベルが付けられます。
Pandas Plot で散布図を作成する
次に、Pandas Plot を使用して散布図を作成しましょう。 学生の試験スコアのサンプル データセットを使用します。
students = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emma', 'Frank'],
'Math': [70, 80, 90, 60, 75, 85],
'Science': [80, 70, 85, 65, 90, 75]}
df = pd.DataFrame(students)
df.plot(kind='scatter', x='Math', y='Science')
plt.show()上記のコードでは、まず学生の試験スコアのディクショナリを作成し、それを Pandas DataFrame に変換します。 次に、DataFrame の plot メソッドを使用して散布図を作成し、x 軸と y 軸を指定します。
結果の散布図は、生徒の数学と科学の得点の関係を示します。
Pandas プロットで棒グラフを作成する
棒グラフは、長方形のグラフ形式でデータを視覚化するのに役立ちます。 このセクションでは、Web サイト トラフィック ソースの同じサンプル データセットを使用して、Pandas Plot を使用して棒グラフを作成します。
# Create bar chart
df['source'].value_counts().plot(kind='bar')
# Add title and axis labels
plt.title('Website Traffic Sources')
plt.xlabel('Traffic Source')
plt.ylabel('Number of Visits')上記のコードでは、value_counts() 関数を使用して、各 Web サイト トラフィック ソースの発生回数をカウントしています。 次に、kind='bar' パラメータを plot() 関数に渡して棒グラフを作成します。
plt.title() を使用してタイトルを追加し、plt.xlabel() を使用して x 軸ラベルを追加し、plt.ylabel() を使用して y 軸ラベルを追加して、プロットをカスタマイズします。
Pandas Plot で円グラフを作成する
最後に、Pandas Plot を使用して円グラフを作成しましょう。 ウェブサイトのトラフィック ソースのサンプル データセットを使用します。
traffic = {'Source': ['Search Engines', 'Direct Traffic', 'Referral Traffic', 'Social Media'],
'Traffic': [40, 20, 30, 10]}
df = pd.DataFrame(traffic)
df.set_index('Source', inplace=True)
df.plot(kind='pie', y='Traffic', autopct='%1.1f%%')
plt.show()色、サイズ、ラベルなどのパラメーターを使用してプロットをカスタマイズする方法
Pandas Plot は、プロットの外観をカスタマイズするためのさまざまなパラメーターを提供します。 これらのパラメーターのいくつかを調べてみましょう。
color: プロットの色を変更します fontsize: プロットのフォント サイズを変更します title: プロットにタイトルを追加します xlabel と ylabel: x 軸と y 軸にラベルを追加します 凡例: プロットに凡例を追加します grid: プロットにグリッド線を追加します たとえば、前に作成した棒グラフの色を赤に変更するには、color='red' パラメータを plot() 関数に追加します。
df['source'].value_counts().plot(kind='bar', color='red')凡例をプロットに追加するには、legend=True パラメータを plot() 関数に追加します。
df['source'].value_counts().plot(kind='bar', legend=True)Pandas Plot の代替: Jupyter Notebook で PyGWalker を使用する
PyGWalker (opens in a new tab) は、pandas データフレーム (および polars データフレーム) を Tableau スタイルのユーザー インターフェイスに変換して視覚的な探索を行うことで、データ分析とデータ視覚化のワークフローを簡素化します。 . Jupyter Notebook (またはその他の jupyter ベースのノートブック) を Graphic Walker と統合します。これは、Tableau に代わるオープンソースの別のタイプです。 データ サイエンティストは、簡単なドラッグ アンド ドロップ操作でデータを分析し、パターンを視覚化できます。
| Kaggle で実行 (opens in a new tab) | Colab で実行 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
PyGWalker はオープン ソースです。 PyGWalker GitHub (opens in a new tab) をチェックして ⭐️ を残すことを忘れないでください!
Jupyter Notebook で PyGWalker を使用する
PyGWalker と pandas を Jupyter Notebook にインポートして開始します。
import pandas as pd
import PyGWalker as pyg既存のワークフローを壊すことなく PyGWalker を使用できます。 たとえば、Pandas データフレームをビジュアル UI に読み込むことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)また、PyGWalker を極座標で使用できます (PyGWalker>=0.1.4.7a0 から):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Binder (opens in a new tab)、Google Colab (opens in a new tab) or Kaggle Code (opens in a new tab). または Kaggle コード (opens in a new tab)。
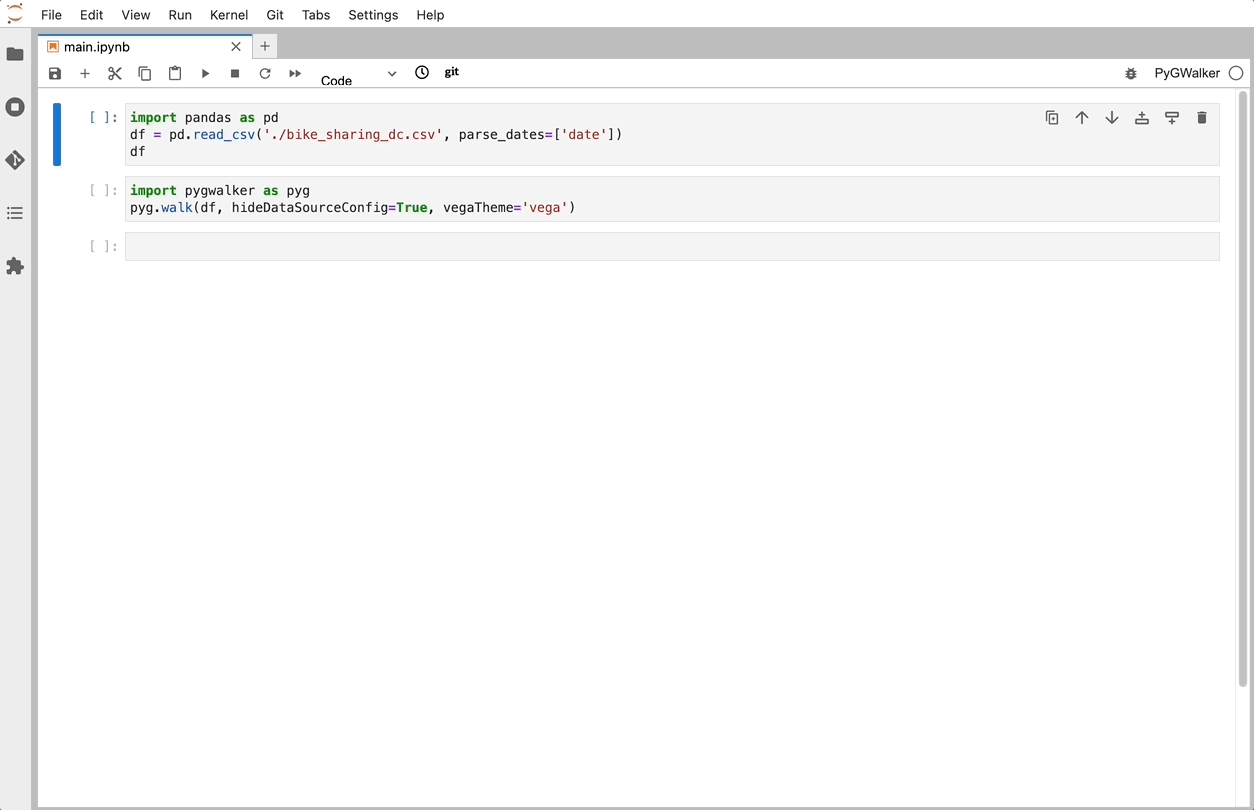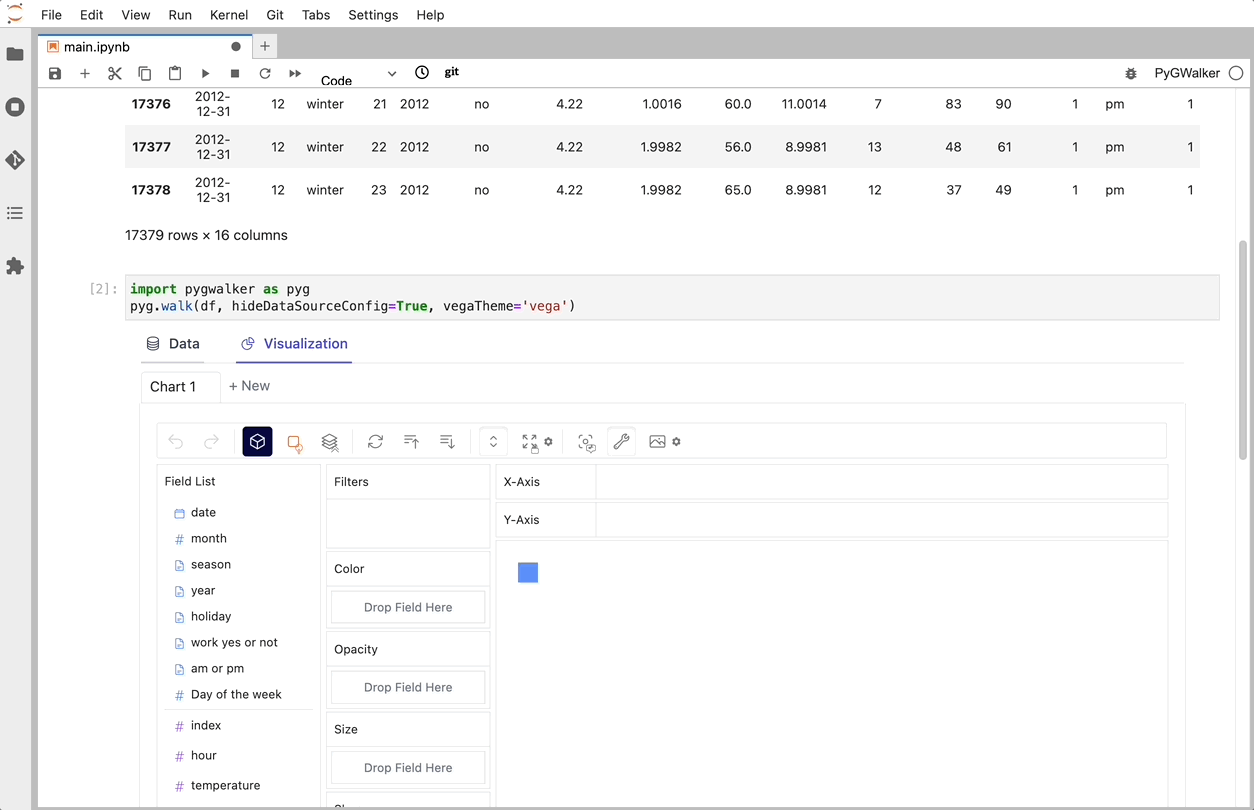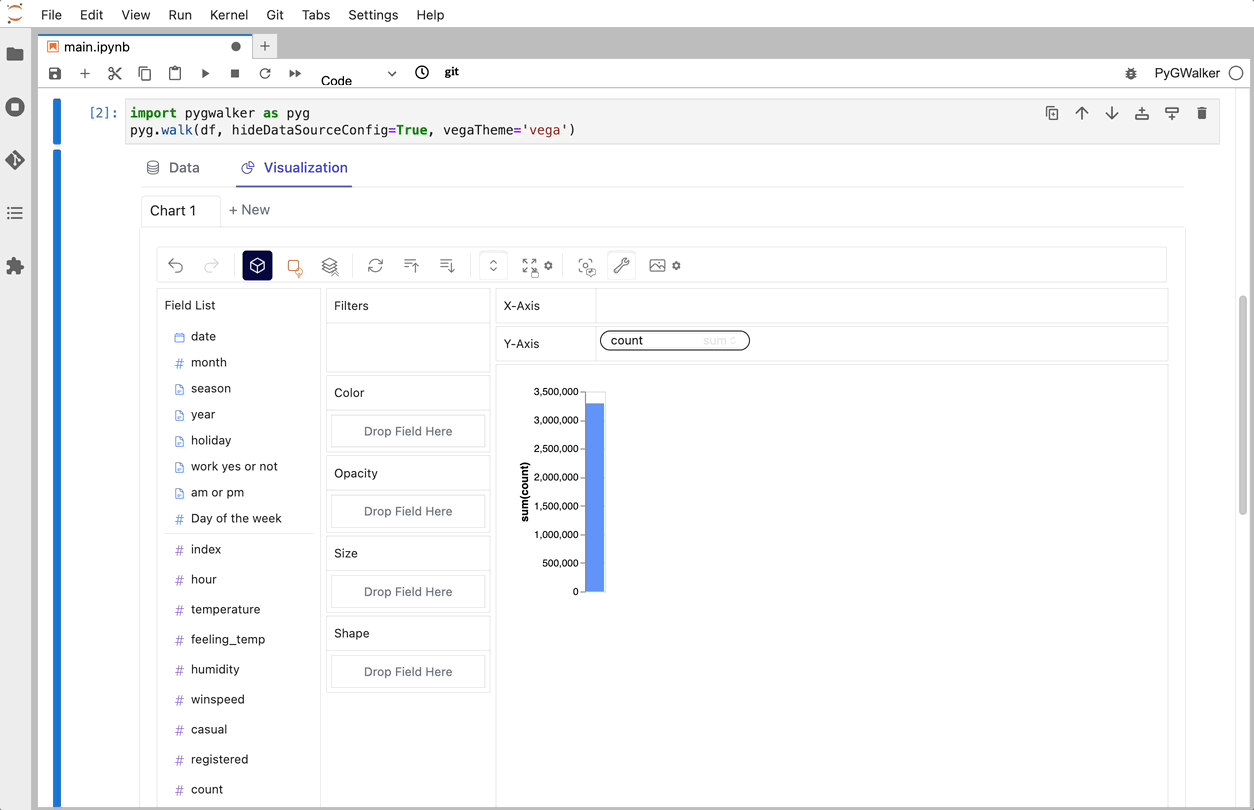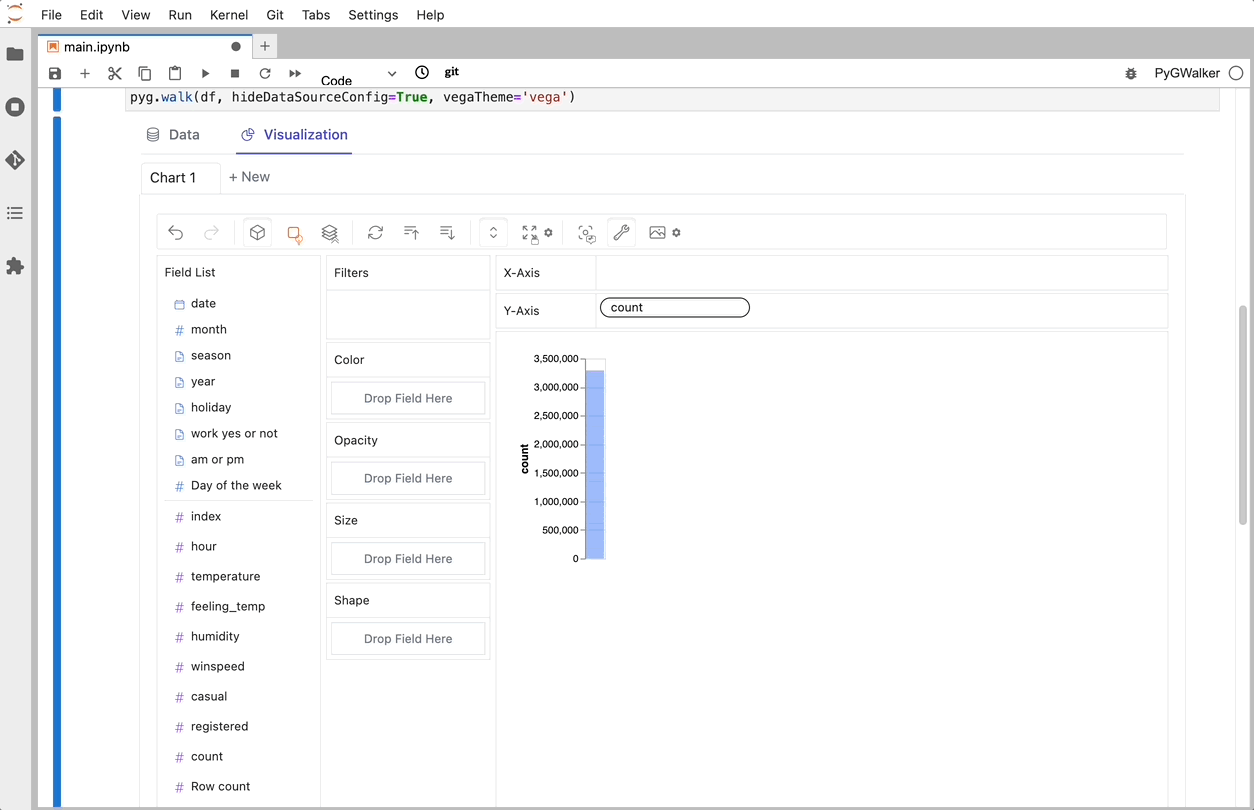
それでおしまい。 これで、Tableau に似たユーザー インターフェイスを使用して、変数をドラッグ アンド ドロップしてデータを分析および視覚化できます。
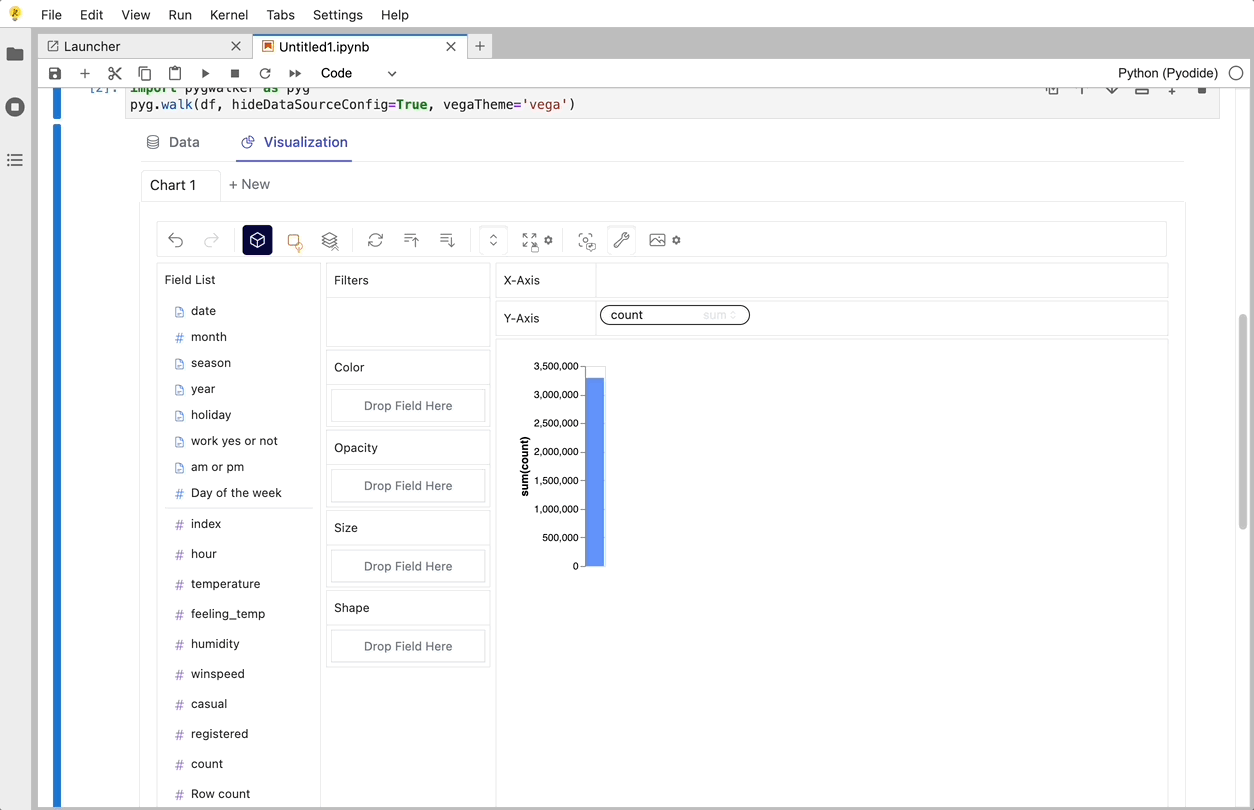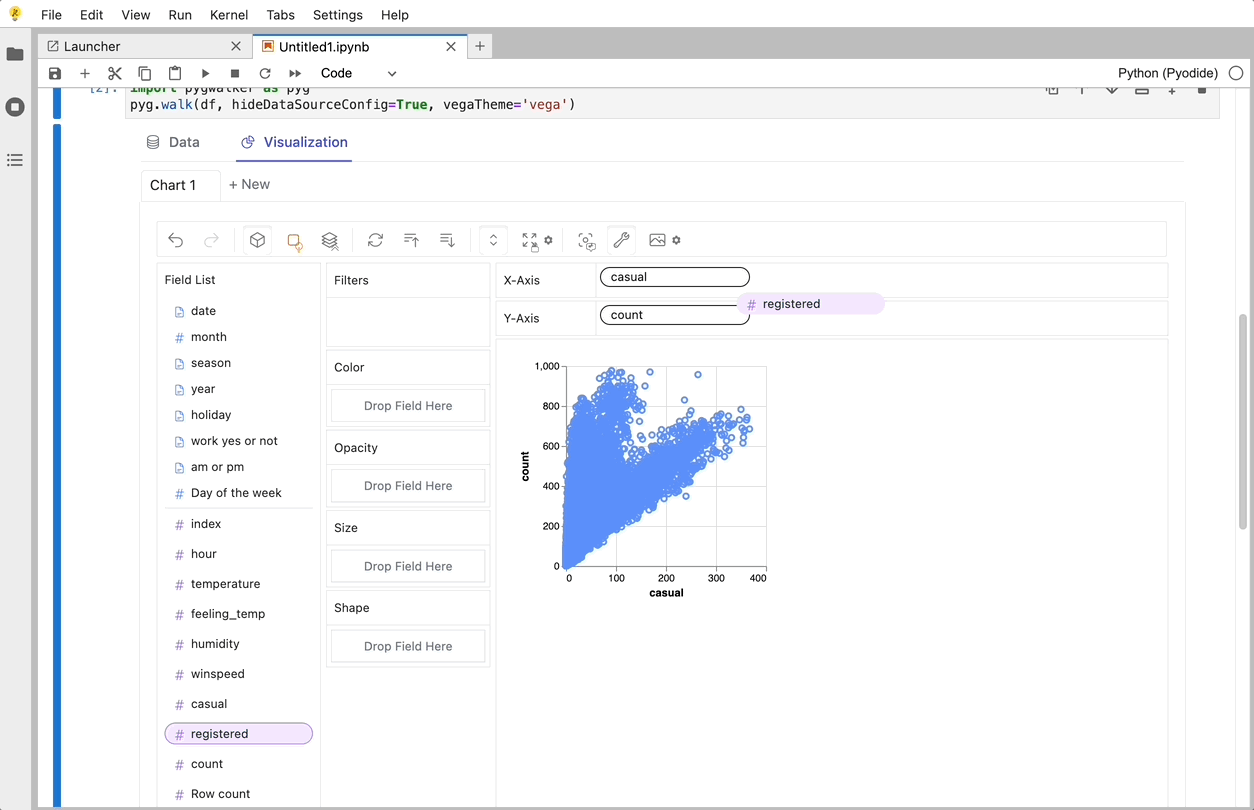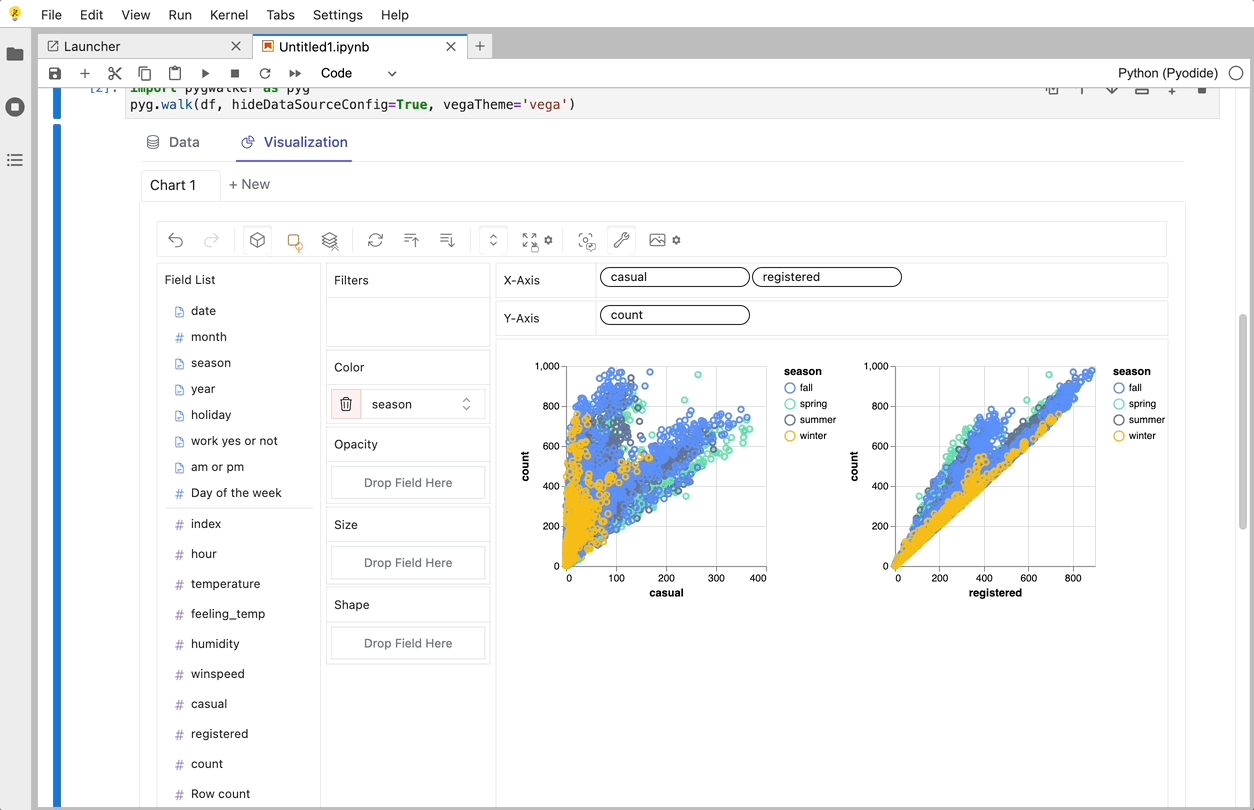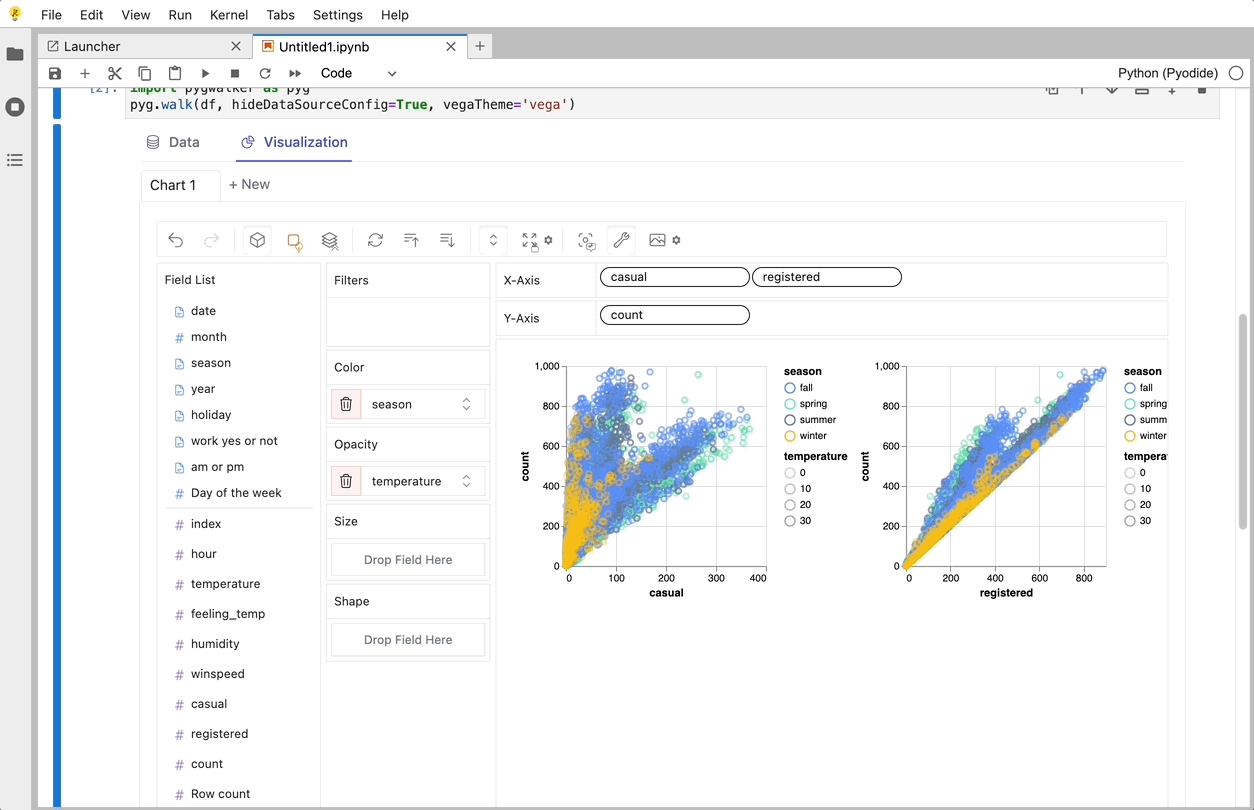
PyGWalker でデータの視覚化を作成する
棒グラフ  | 折れ線グラフ  | 面積グラフ  |
|---|---|---|
トレイル  | 散布図  | サークル  |
ティックプロット  | 長方形  | アーク図  |
箱ひげ図  | ヒートマップ  |
より多くの例については、データ可視化ギャラリーをご覧ください。
Pandas Plot による高度なプロット
Pandas Plot は、サブプロット、グループ棒グラフ、積み上げ棒グラフなど、より高度なプロット機能を提供します。 これらの機能のいくつかを見てみましょう。
サブプロット
サブプロットは、1 つの図に複数のプロットを表示する強力な方法です。 Pandas Plot でサブプロットを作成するには、subplots 関数を使用できます。 この関数は Figure を作成し、目的のプロットの作成に使用できる一連のサブプロットを返します。 たとえば、並べてプロットしたい 2 つのデータセットがあるとします。 次のコードを使用して、2 つのサブプロットを持つ図を作成できます。
import pandas as pd
import matplotlib.pyplot as plt
data1 = pd.read_csv('data1.csv')
data2 = pd.read_csv('data2.csv')
fig, axs = plt.subplots(1, 2, figsize=(10, 5))
data1.plot(ax=axs[0])
data2.plot(ax=axs[1])このコードでは、最初に 2 つのデータセット (data1 と data2) を読み込みます。 次に、関数 subplots を使用して 2 つのサブプロットを含む Figure を作成します。 1 と 2 の引数は、1 行のサブプロットと 2 列のサブプロットが必要であることを指定します。 figsize 引数は、Figure のサイズを指定します。
次に、最初のサブプロット (axs[0]) に data1 をプロットし、2 番目のサブプロット (axs[1]) に data2 をプロットします。
グループ化された棒グラフ
グループ化された棒グラフは、複数のデータ セットを比較するのに便利な方法です。 Pandas Plot でグループ化された棒グラフを作成するには、幅引数を 1 未満の値に設定して bar 関数を使用できます。 たとえば、グループ化された棒グラフを使用して比較したい 2 つのデータ セットがあるとします。 次のコードを使用してチャートを作成できます。
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('data.csv')
fig, ax = plt.subplots()
data.plot(kind='bar', x='Group', y=['Data1', 'Data2'], width=0.4, ax=ax)このコードでは、最初にデータセット (data) を読み込みます。 次に、関数 subplots を使用して、単一のサブプロットを含む Figure を作成します。 関数 bar を使用して、このサブプロットにデータをプロットします。 kind 引数は、棒グラフが必要であることを指定します。 x 引数は、x 軸に使用する列 (この場合は「グループ」列) を指定します。 y 引数は、y 軸に使用する列 (この場合は "Data1" 列と "Data2" 列) を指定します。 width 引数は、各バーの幅を指定します (この場合は 0.4)。
積み上げ棒グラフ
積み上げ棒グラフは、複数のデータ セットを比較するもう 1 つの便利な方法です。 Pandas Plot で積み上げ棒グラフを作成するには、関数 bar を使用して、bottom 引数を前のデータ セットの値に設定します。 たとえば、積み上げ棒グラフを使用して比較したい 3 つのデータ セットがあるとします。 次のコードを使用してチャートを作成できます。
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('data.csv')
fig, ax = plt.subplots()
data.plot(kind='bar', x='Group', y=['Data1', 'Data2', 'Data3'], stacked=True, ax=ax)このコードでは、最初に Pandas を使用してデータ セットを読み取り、次に「groupby」関数を使用してデータを年と大陸別にグループ化します。 次に、積み上げパラメーターを True に設定して plot.bar メソッドを使用して、積み上げ棒グラフをプロットします。 これにより、各年のバーが積み上げられた棒グラフが作成され、各バーはその年の大陸別の人口の割合を表します。
効果的なデータ視覚化のためのヒントとコツ
データ ビジュアライゼーションは、データ サイエンティストやアナリストがインサイトを効果的に伝達するために不可欠なツールです。 このセクションでは、Pandas Plot を使用して効果的なデータ視覚化を作成するためのヒントとコツについて説明します。
-
分析するデータに適した視覚化の種類を選択してください: 視覚化の種類の選択は、データの種類と伝えたいメッセージによって異なります。 たとえば、連続変数の分布を表示する場合は、ヒストグラムまたは密度プロットが適切です。 一方、2 つ以上の変数を比較する場合は、散布図または折れ線グラフの方が適している場合があります。
-
適切な色、ラベル、タイトルを使用する: メッセージを効果的に伝えるには、適切な色、ラベル、タイトルを使用することが重要です。 目に優しく、データの邪魔にならない色を選択してください。 明確で簡潔なラベルを使用して、変数と測定単位を説明します。 最後に、ビジュアライゼーションのメッセージを要約した有益なタイトルを使用します。
-
よくある間違いを避ける: ビジュアライゼーションを作成するときによくある間違いがいくつかあります。 これらには、ビジュアライゼーションで使用する色や要素が多すぎる、2 次元データセットに 3D プロットを使用する、円グラフを使用して 3 つ以上の変数を比較するなどがあります。
結論
このブログ投稿では、Pandas Plot を使用したデータ視覚化の威力を探りました。 Pandas Plot の基本と、棒グラフや折れ線グラフなどの簡単な視覚化の作成方法を説明することから始めました。 読者には、Pandas Plot と PyGWalker を使用したデータ視覚化の力を探求し、さまざまな種類の視覚化を試して洞察を効果的に伝えることをお勧めします。