PyGWalkerとStreamlitを使ったデータの探索と情報共有
この記事では、PyGWalkerとStreamlitを使用してデータを分析し、視覚化する方法について説明します。楽しくインタラクティブな旅になるので、さっそく始めましょう!
PyGWalkerとは?
PyGWalker (opens in a new tab)は、データを視覚化するためのビジュアルインターフェースを提供するPythonライブラリです。PyGWalkerは、Pandas/Polars/Modinのデータフレームを使って、コーディングのスキルを必要とせずに、データの視覚的な探索を行うためのノーコードのユーザーインターフェースに変換することで、Jupyter Notebookのデータ分析とデータ可視化のフローを簡略化します。
PyGWalkerを使うと、わずかなドラッグアンドドロップ操作で、散布図、折れ線グラフ、棒グラフ、ヒストグラムなどを簡単に生成することができます。データサイエンティストやアナリストのために特別に設計された強力なツールであり、データの探索と視覚化を迅速かつ楽に行いたい方に最適です。
PyGWalkerの詳細な情報については、Coding is FunのSvenさんが制作した素晴らしい動画 (opens in a new tab)をご覧ください。
PyGWalkerコミュニティへのSvenさんと彼の素晴らしい貢献 (opens in a new tab)に感謝します!
さらに、PyGWalkerの例については、PyGWalkerのGitHubページ (opens in a new tab)をチェックしてください。
Streamlitとは?
Streamlitは、データアプリケーションの作成と共有において人気のあるPythonライブラリです。これにより、データスクリプトを数分でウェブアプリに変換できます。Streamlitを使用すると、複雑なウェブ開発や無限の時間をコーディングに費やす必要はありません。Pythonを使用してインタラクティブで共有可能なデータアプリケーションを簡単かつ無料で作成できる、高速かつオープンソースの方法です。
では、パワフルな視覚分析機能を持つPyGWalkerと共に、視覚的探索アプリを作成し、Streamlitでデータアプリケーションとして公開する方法を見ていきましょう!
StreamlitでPyGWalkerを使う準備
PyGWalkerをStreamlitで実行する前に、Python環境(バージョン3.6以上)が設定されていることを確認しましょう。それが完了したら、次のシンプルな手順に従ってください:
必要な依存関係のインストール
始める前に、コマンドプロンプトまたはターミナルを開き、次のコマンドを実行して必要な依存関係をインストールします:
pip install pandas
pip install pygwalker
pip install streamlitStreamlitアプリケーションにPyGWalkerを埋め込む
依存関係が整ったので、PyGWalkerを組み込んだStreamlitアプリケーションを作成しましょう。pygwalker_demo.pyという新しいPythonスクリプトを作成し、以下のコードをコピーして貼り付けてください:
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Import your data
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
pyg_app = StreamlitRenderer(df)
pyg_app.explorer()
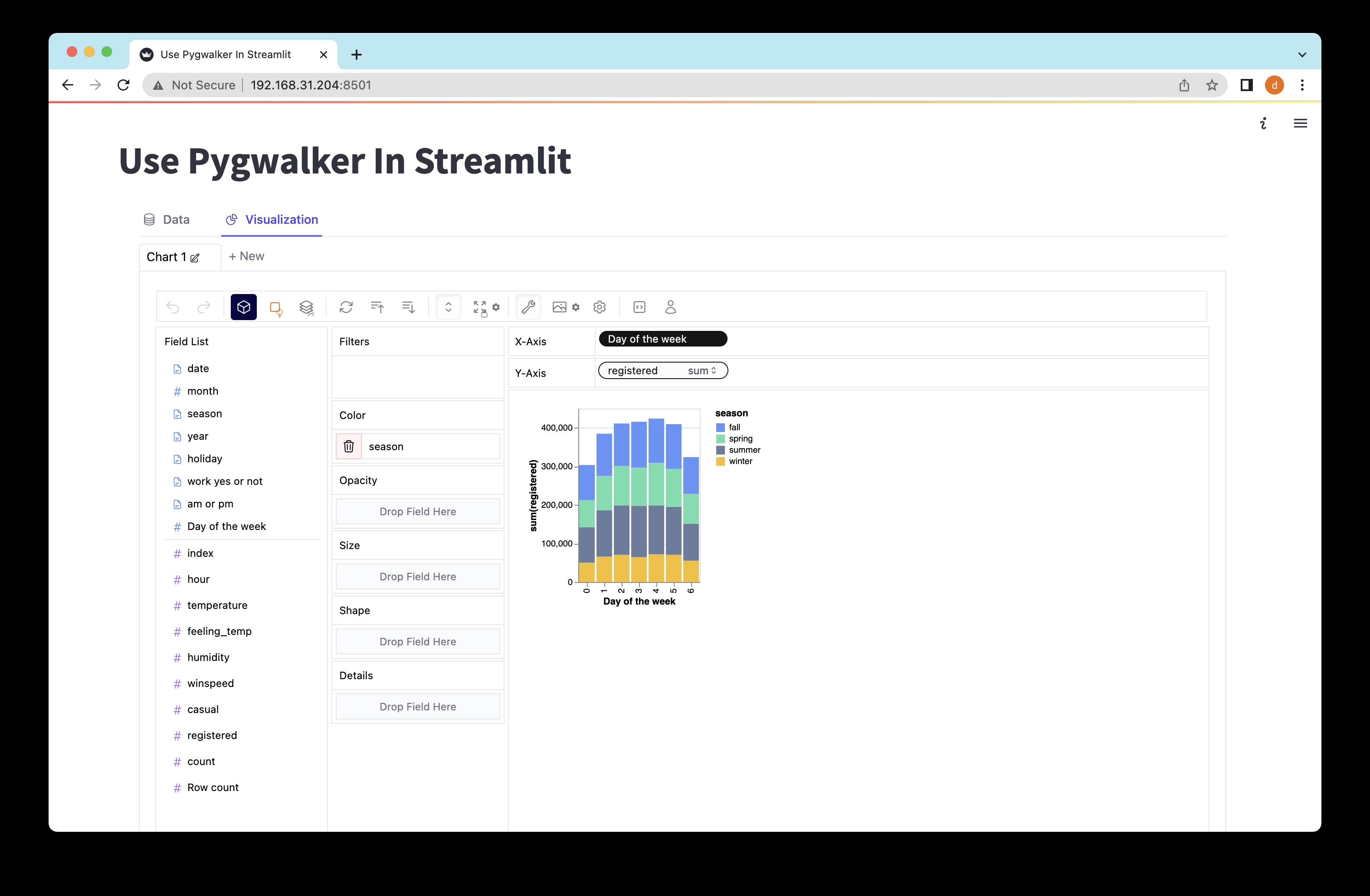
StreamlitでPyGWalkerを使ってデータを探索する
Streamlitアプリケーションを起動し、データを探索するために次のコマンドをコマンドプロンプトまたはターミナルで実行します:
streamlit run pygwalker_demo.py以下の情報が表示されるはずです:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://xxx.xxx.xxx.xxx:8501提供されたURL (http://localhost:8501) をウェブブラウザで開いてください!PyGWalkerの直感的なドラッグアンドドロップ操作を使ってデータと対話し、視覚化することができます。
PyGWalkerチャートの状態の保存
PyGWalkerチャートの状態を保存したい場合は、次の手順に従うだけです:
- チャートのエクスポートボタンをクリックします。
- コードをコピーするボタンをクリックします。
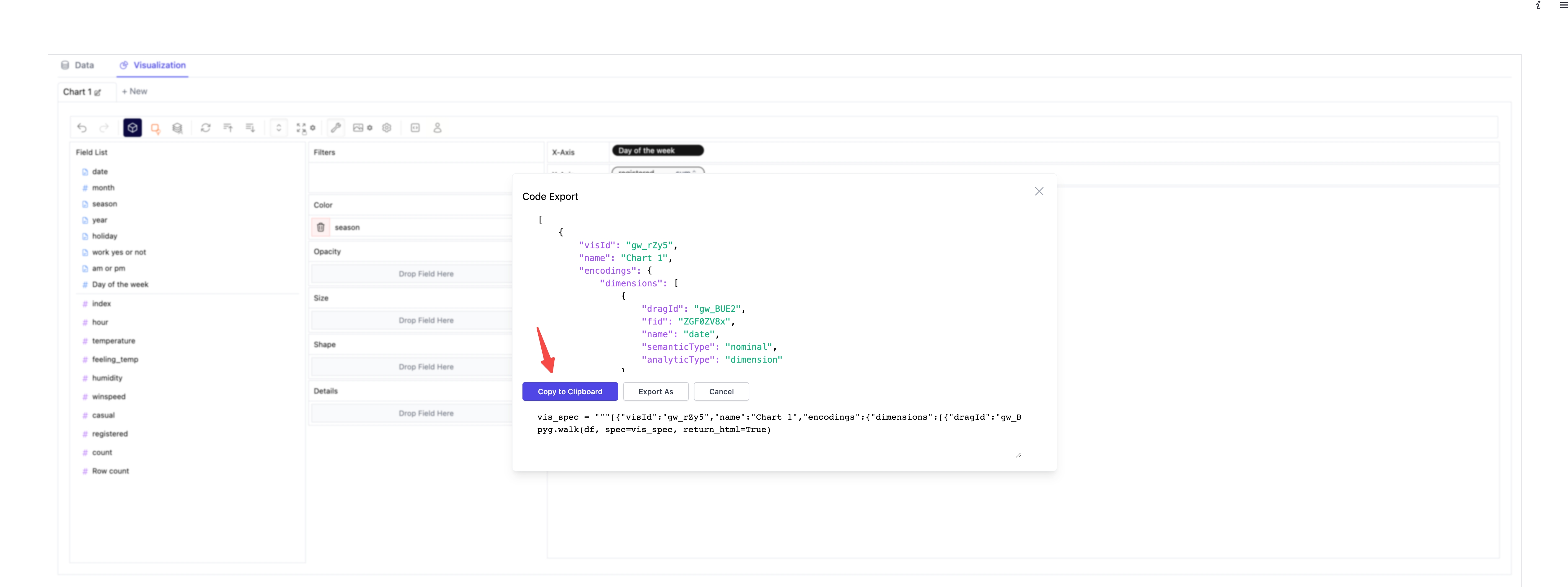
- コピーしたコードを必要な場所に貼り付けます。
import pygwalker as pyg
import pandas as pd
from pygwalker.api.streamlit import StreamlitRenderer
import streamlit as st
# Streamlitページの幅を調整する
st.set_page_config(
page_title="StreamlitでPygwalkerを使う",
layout="wide"
)
# タイトルを追加
st.title("StreamlitでPygwalkerを使う")
# データをインポートする
df = pd.read_csv("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/public-datasets/bike_sharing_dc.csv")
# コピーしたPygwalkerチャートのコードをここに貼り付ける
vis_spec = """<PASTE_COPIED_CODE_HERE>"""
pyg_app = StreamlitRenderer(df, spec=vis_spec)
pyg_app.explorer()- ページを再読み込みして、保存されたPyGWalkerチャートの状態を表示するのを忘れないでください。
PyGWalkerはgraphic-walkerに基づいており、ExcelやAirtableなどの他のプラットフォームに埋め込むことができます。したがって、PyGWalkerアプリもこの機能を利用して、graphic-walker/pygwalkerを含む他のプラットフォームのユーザーとの協力を実現できます。
結論
PyGWalkerとStreamlitは、データ探索と共有をより簡単にする素晴らしいツールです。
PyGWalkerの直感的なインターフェースと幅広い視覚化オプション、Streamlitのデータアプリケーションの構築と共有のプロセスを簡素化する能力を組み合わせることで、データの視覚化と探索のための視覚的なUIを持つデータアプリケーションを素早く構築することができます。
初心者から経験豊富なデータサイエンティストまで、PyGWalkerとStreamlitはデータ分析のワークフローを向上させ、見つけたインサイトを効果的に伝えるのに役立ちます。ですので、データを探索し、素晴らしいインサイトを世界と共有してください!
lab2.dev - Turn your ideas to python apps with AI. Build Streamlit apps with simple text prompts.→