因果分析
RATH は、データの中から因果関係を見つけて探索するための ビジュアルかつノーコードのワークフロー を提供します。単純な相関で止まるのではなく、潜在的な原因を発見し、仮説を検証し、より良い機械学習モデルを構築できます — すべてインタラクティブな因果グラフから行えます。
このガイドでは次のことを扱います。
- 因果分析とは何か、いつ使うべきかを理解する。
- RATH で因果分析を実行するステップバイステップのワークフローを学ぶ。
- Kaggle の “Diabetes” データセットを使った具体例を一緒にたどる。
- 比較分析、相互インスペクション、予測テスト、手動でのモデル編集といった高度なツールを探索する。
因果分析とは?
因果分析 は、変数間の関係を調べて、一方の変数の変化がもう一方の変数の変化を 引き起こしているのか を検討するプロセスです。単に一緒に動いているか(相関があるか)を見るだけではありません。
実務的には、次のようなことを意味します。
- 関心のあるアウトカムに影響を与える可能性のある変数を特定する。
- 仮定や学習された関係を符号化した 因果モデル(しばしば有向グラフ)を構築する。
- 統計的・アルゴリズム的手法を用いて、その効果の強さと向きを推定する。
- 相関や特徴量重要度だけに頼るのではなく、仮説を検証・洗練していく。
多くの現実世界のデータは 観測データ(制御された実験からではない)であるため、因果分析を行っても「真の因果関係」が保証されるわけではありません。ただし、単なる相関に比べて、より強く解釈しやすい仮説を生成し、検証する助けになります。
RATH で因果分析を行うには
RATH は複雑な因果発見手法をインタラクティブなワークフローでラップしています。大まかな流れは次の通りです。
-
データを接続し、準備する
- データセットを RATH にインポートする。
- 不正なレコードをクレンジングし、主要なフィールドの型(数値、カテゴリなど)が正しいことを確認する。
-
フィールドとオプションの依存関係を設定する
- 因果モデルに含めるフィールドを選択する。
- 必要に応じて、既知の関数従属性(派生フィールド、計算式など)を宣言し、RATH が発見時にそれらを尊重できるようにする。
-
因果発見を実行する
- Causal Analysis ワークフローを開始し、RATH にデータから因果グラフを推定させる。
-
関係を探索し、妥当性を検証する
- Field Insights、Manual Exploration、Mutual Inspection などのツールを使い、発見されたモデルをドメイン知識と照らし合わせながら検証・調整する。
-
予測モデルを構築・テストする
- Prediction Test を使って、因果グラフに基づく機械学習モデルを作成し、別の特徴量セットで構築したモデルと比較する。
-
因果モデルを編集し、確定させる
- 追加の知見がある場合や、データノイズ・欠落要因などがある場合には、モデルを手動で調整する。
次のセクションでは、このワークフローを具体例を用いて順に説明します。
ケーススタディ: Kaggle の "Diabetes Database" の因果分析
具体例として、RATH を使って Kaggle の “Diabetes Database” (opens in a new tab) を分析してみましょう。目標は、どの要因が Outcome(糖尿病診断)に最も強く影響し、どのように相互作用しているか を理解することです。
データセットの準備とクレンジング
- データセットを RATH にインポートします。
BMI、BloodPressures、SkinThicknessが0となっている不正なレコードを削除します。
DataSource タブで:- Clean Method をクリック。
- drop null records を選択し、不正な値を含む行をフィルタリングします。
データクレンジングが完了したら、Start Analysis ボタンの右側にあるドロップダウンメニューを開き、Causal Analysis を選択してワークフローを開始します。
ステップ 1: Data Configuration
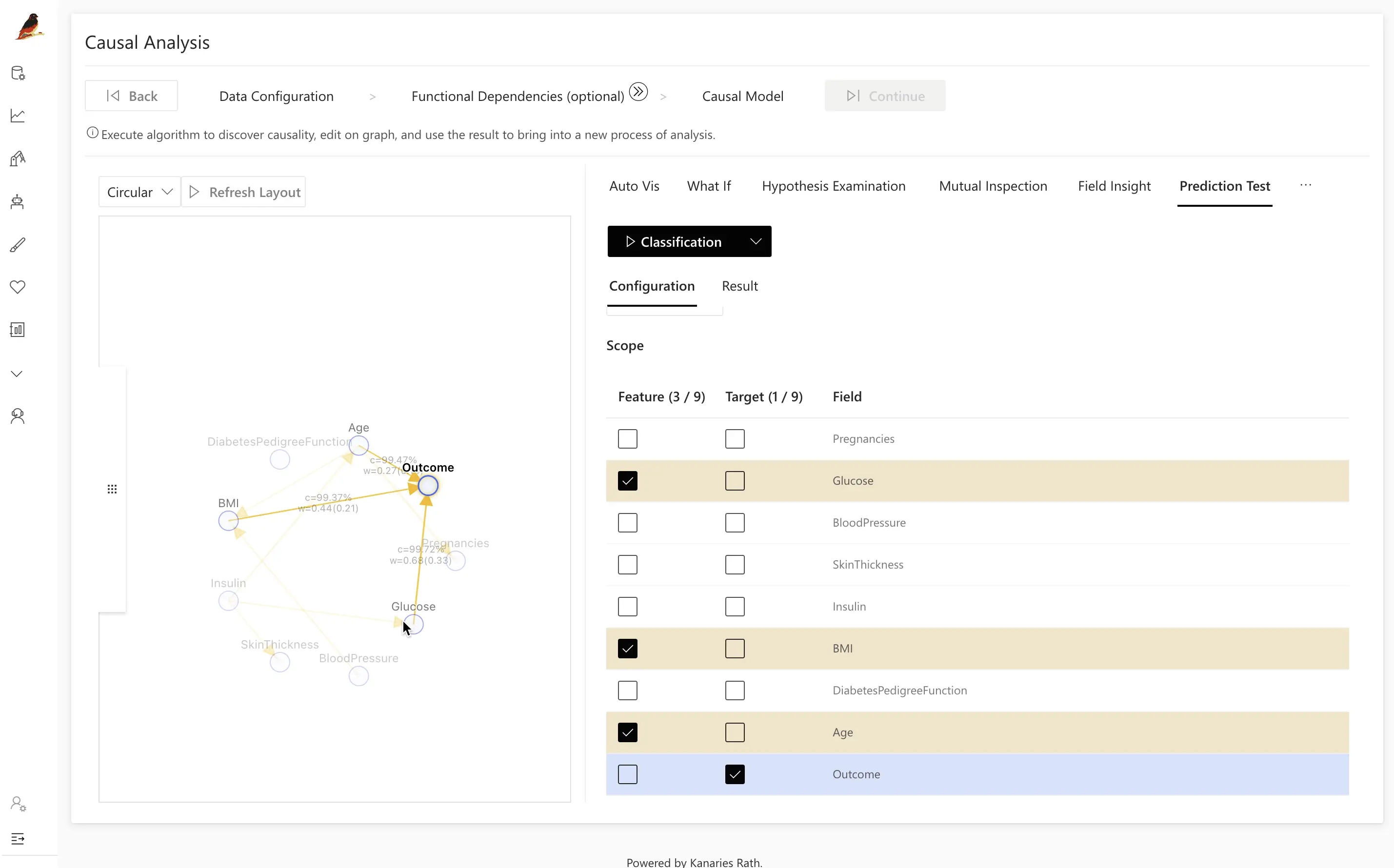
Data Configuration では、因果分析に含めるフィールドを選択します。
- たとえば
Pregnancies、Glucose、BloodPressure、SkinThickness、Insulin、BMI、DiabetesPedigreeFunction、Age、Outcomeなど、関連する変数をすべて選びます。 - 関係ない、あるいはノイズが大きすぎると分かっているフィールドは除外しても構いません。
選択が終わったら Next をクリックして次に進みます。
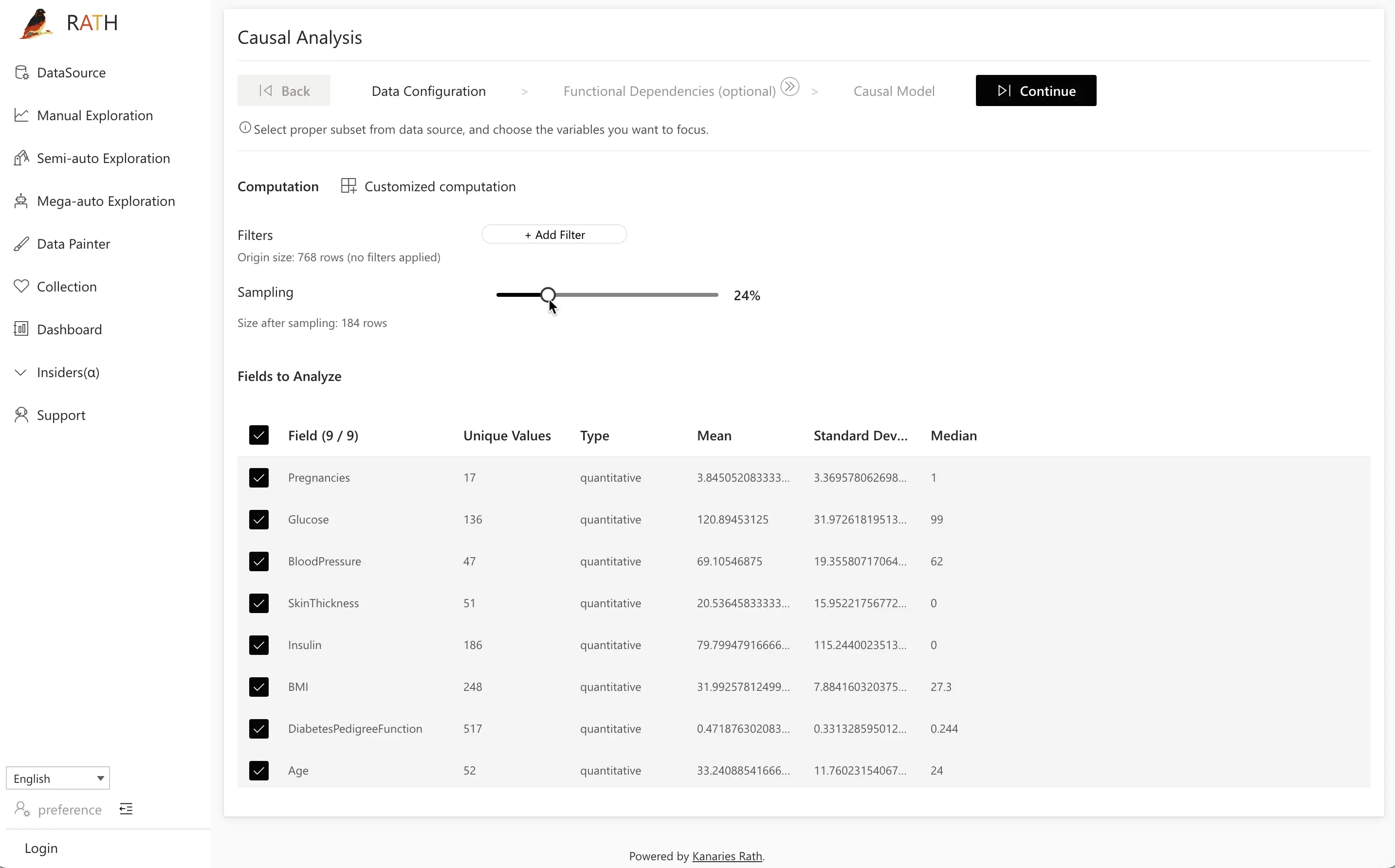
Tip: まずは関係がありそうな変数を広めに含め、因果モデルや予測結果が見えてきた段階で徐々に絞り込んでいくとよいでしょう。
ステップ 2:(任意)Functional Dependencies
多くのデータセットでは、あるフィールドが他のフィールドから 導出 されています(例: 比率の計算、フォーマット済み ID、SQL の計算式で生成された値など)。これらの関係を事前に宣言しておくと、RATH が誤解を生む因果リンクを学習するのを防げます。
Functional Dependencies ステップでは次のことができます。
- RATH にデータを自動解析させ、候補となる従属性を提案させる。
- 既に分かっている関係(例:
TotalAmount = Quantity × UnitPrice)を手動で指定する。
RATH は変数間の値を解析し、あり得る関数的関係を計算します。提案された依存関係をそのまま受け入れてもよいですし、編集したり独自に追加したりすることもできます。
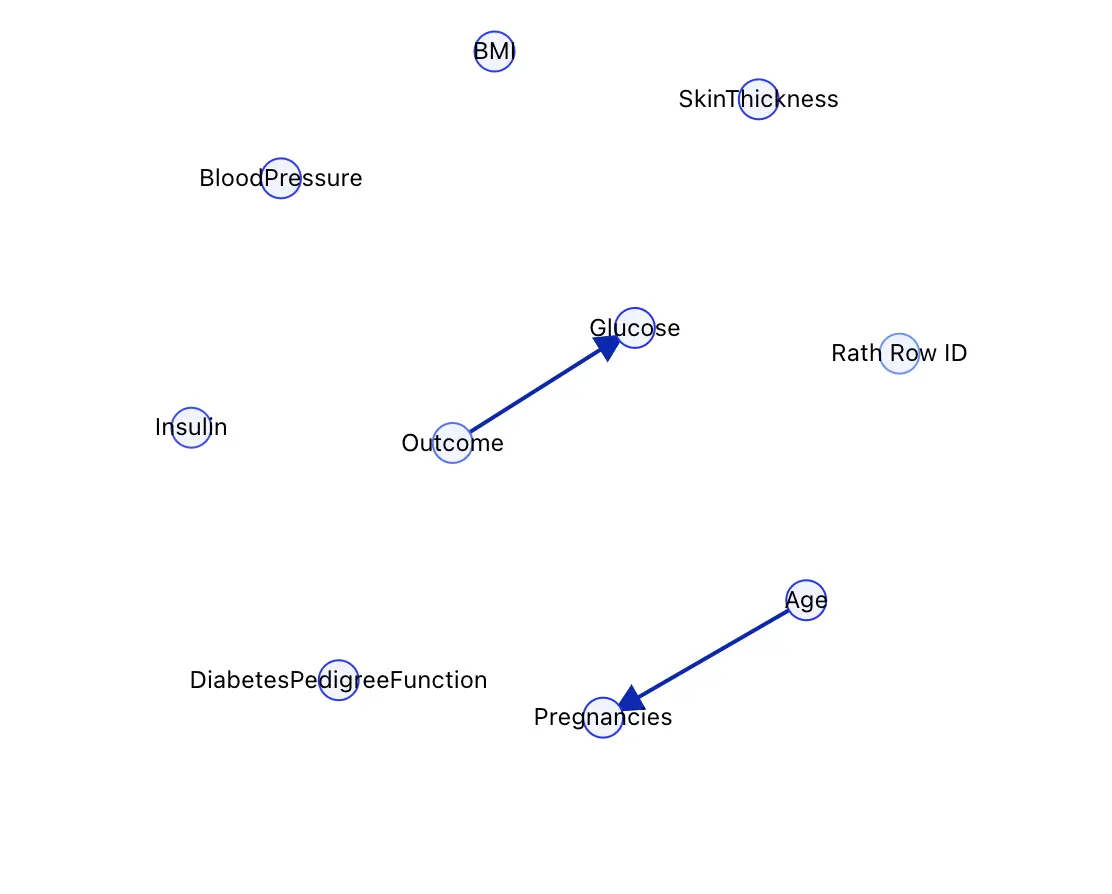
ベストプラクティス:
正規表現や SQL の計算式で生成したフィールドがある場合は、その依存関係をここで宣言しておきましょう。これらの派生フィールドが RATH 内で生成されたものであれば、多くの場合は何もする必要はなく、RATH が自動的に扱ってくれます。
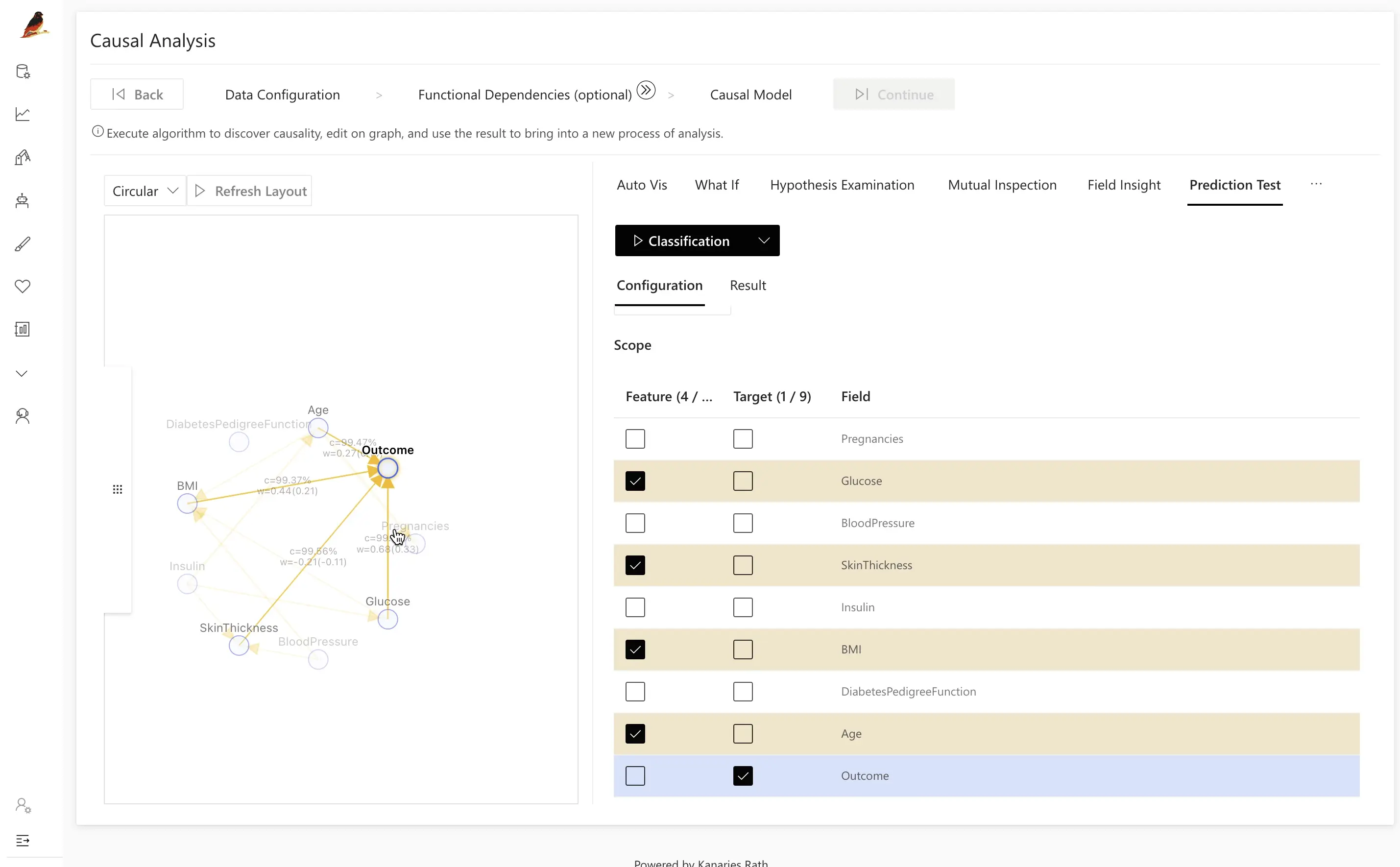
ステップ 3: Causal Model
Causal Discovery をクリックすると、設定したフィールドに基づいて RATH が因果モデルを推定します。
次のスクリーンショットは、Diabetes データセットに対する典型的な因果発見の結果例です。
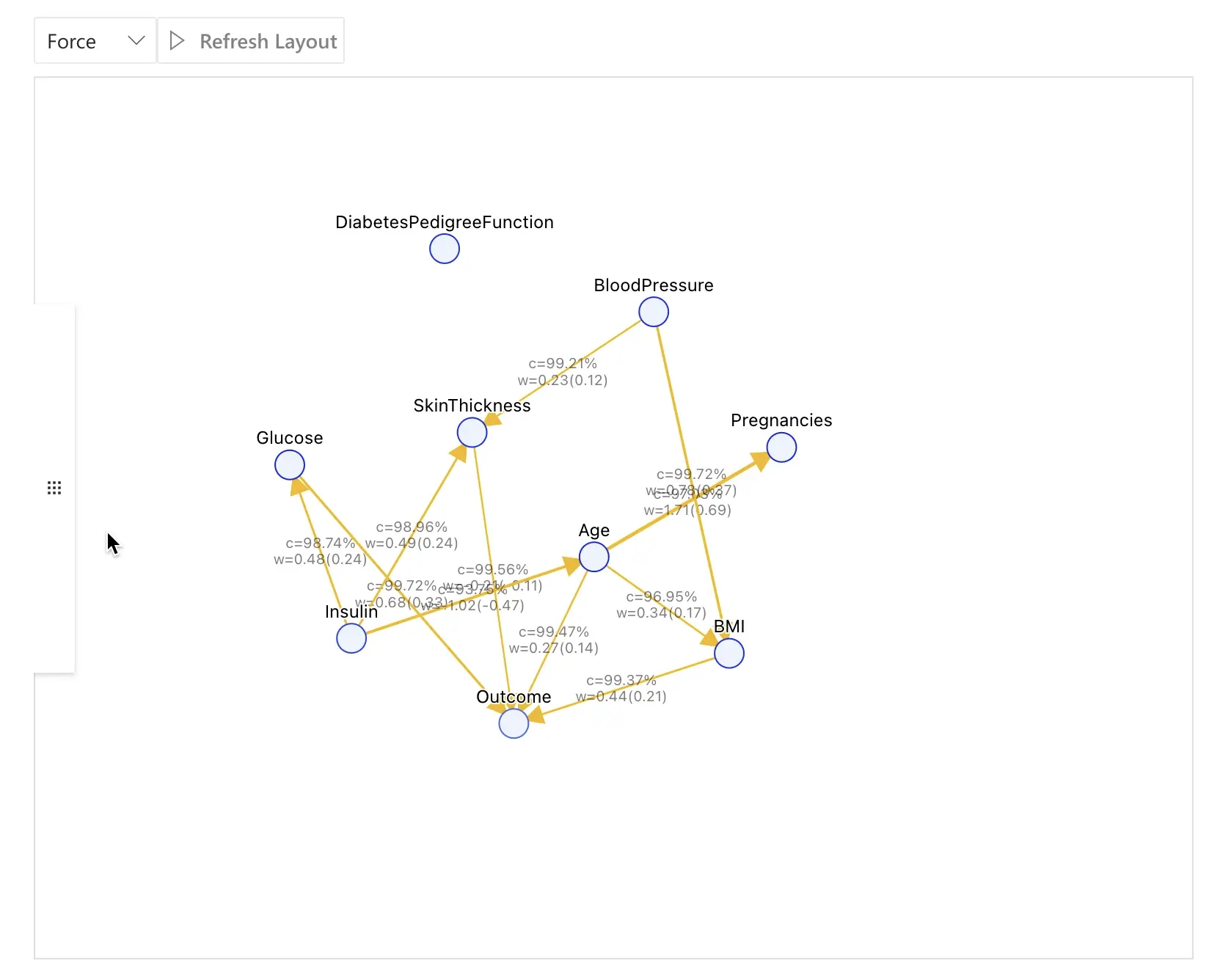
この例では、主要な関係として次のようなものが見られます。
Glucose→Outcome
血糖値が高いほど、糖尿病診断が陽性となる可能性が高まります。Insulin→Glucose→Outcome
インスリンが血糖値に影響し、その血糖値が糖尿病のアウトカムに影響します。Age→Outcome(関連する健康状態とともに影響する場合もある)
年齢も糖尿病である確率に寄与します。
インタラクティブなグラフが、作業の中心となるワークスペースです。
- ノードをクリックすると、その直接の原因と結果がハイライトされます。
- エッジの太さや強さのインジケーターを見ることで、関係の強さを把握できます。
- 右側のパネルから、選択した変数にフォーカスした各種ツール(Field Insights、Manual Exploration、Mutual Inspection、Prediction Test)にアクセスできます。
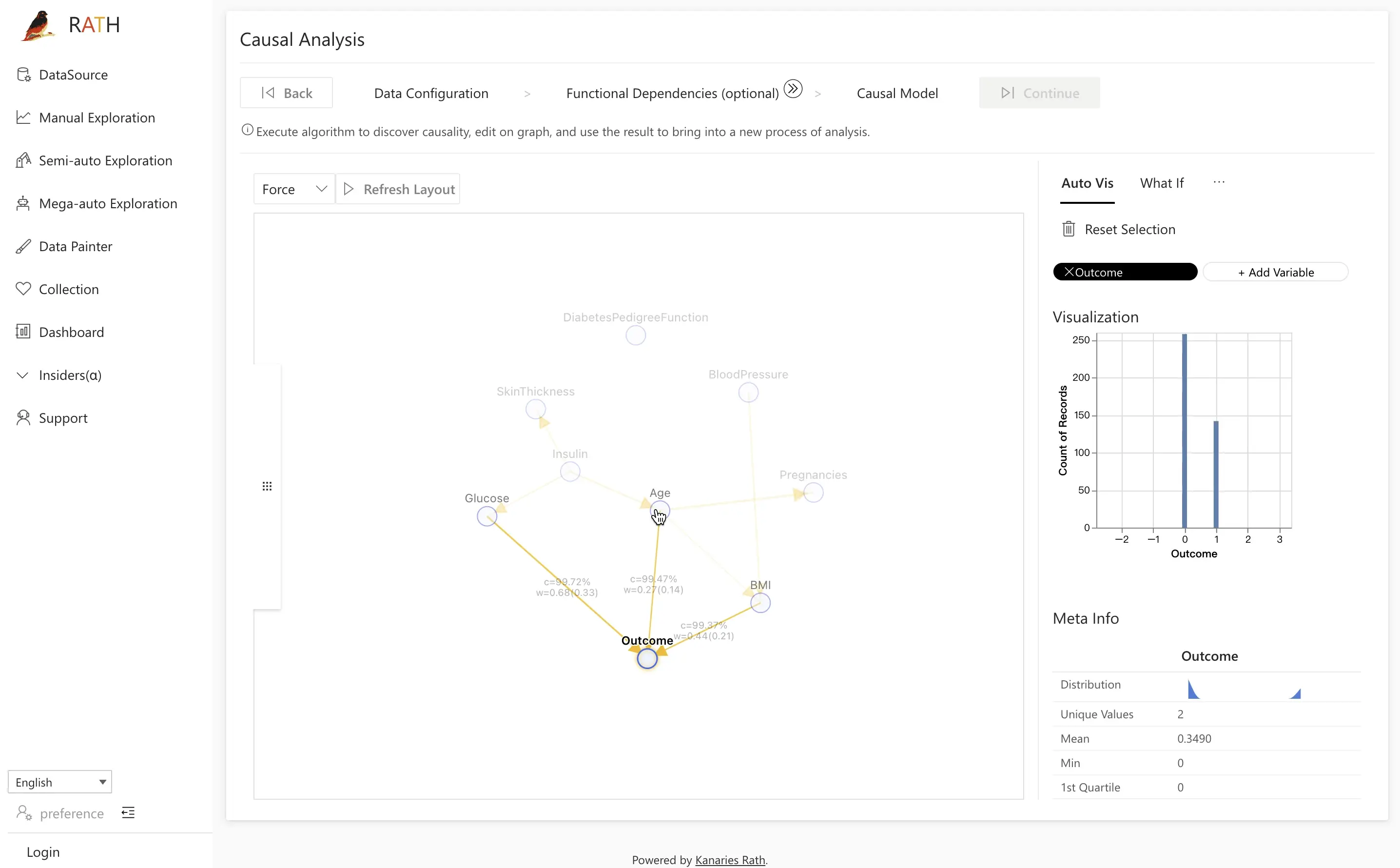
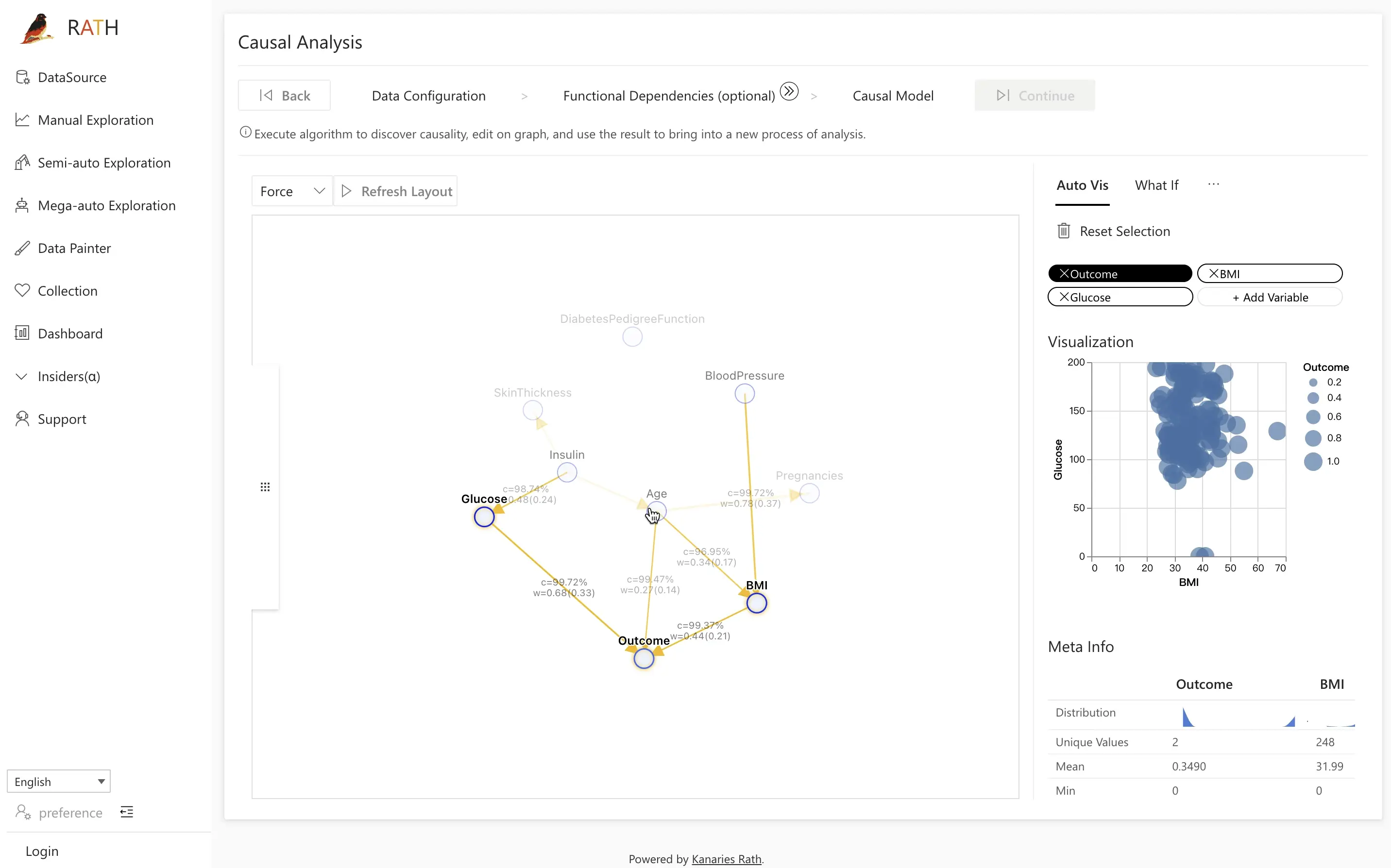
ステップ 3.1: Field Insights を使った比較分析
Comparative analysis(比較分析) では、たとえば糖尿病のある患者とない患者のように、2 つのグループを比較し、その違いを因果モデルを使って説明できます。
RATH は次のような比較モードをサポートしています。
- Subset vs. Whole
(例: 1 月 vs. 通年) - Subset vs. Complement
(例: 1 月 vs. 「1 月以外のすべて」) - Subset vs. Another Subset
(例: 1 月 vs. 6 月)
これらの比較を使って次のような分析が可能です。
- 異常値やアウトライヤーの背後にある潜在的な因果要因を調べる。
- 実際の分布を見ながら因果仮説を検証・洗練する。
例: Outcome の分析
- Field Insight タブを開きます。
- 左側で
Outcomeノードをクリックします。 - 右側で、糖尿病 あり と なし の個体の分布を確認します。
- いずれかの分布(例: 陽性アウトカム)をクリックして、比較分析を実行します。
次に、対照群や注目する主な変数(例: Glucose)を選び、Causal Discovery をクリックすると、RATH が潜在的な原因を分析します。RATH は原因と結果のダイアグラムを使って、観測された違いに対する説明を提示します。
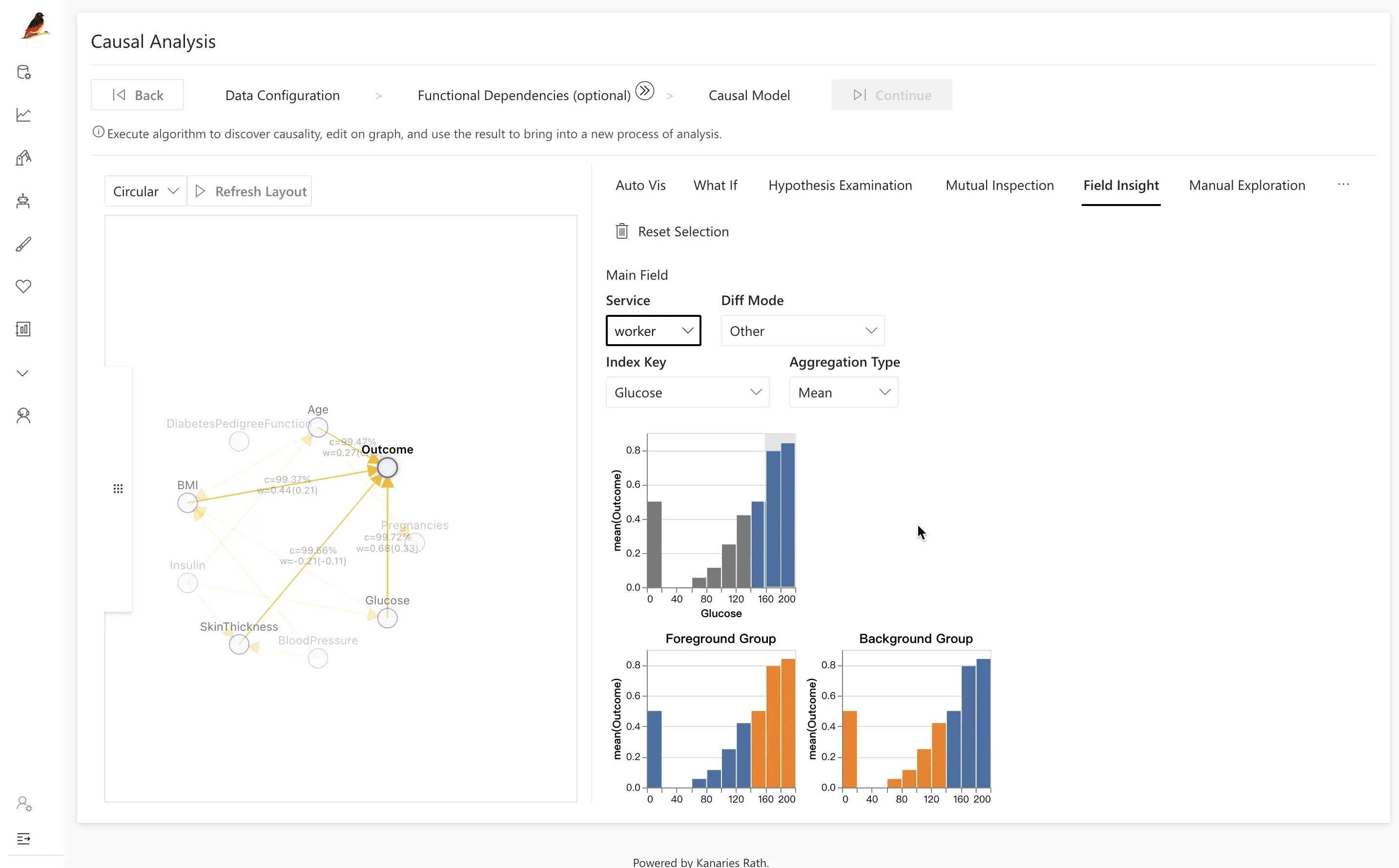
Diabetes データセットの例では、糖尿病あり・なしを比較すると、違いは主に次の変数によって生じていることが多く分かります。
BMIAgeGlucose
潜在要因としての Glucose をクリックすると、糖尿病群(オレンジでハイライト)の方が血糖値の分布が有意に高くなっていることを確認できます。
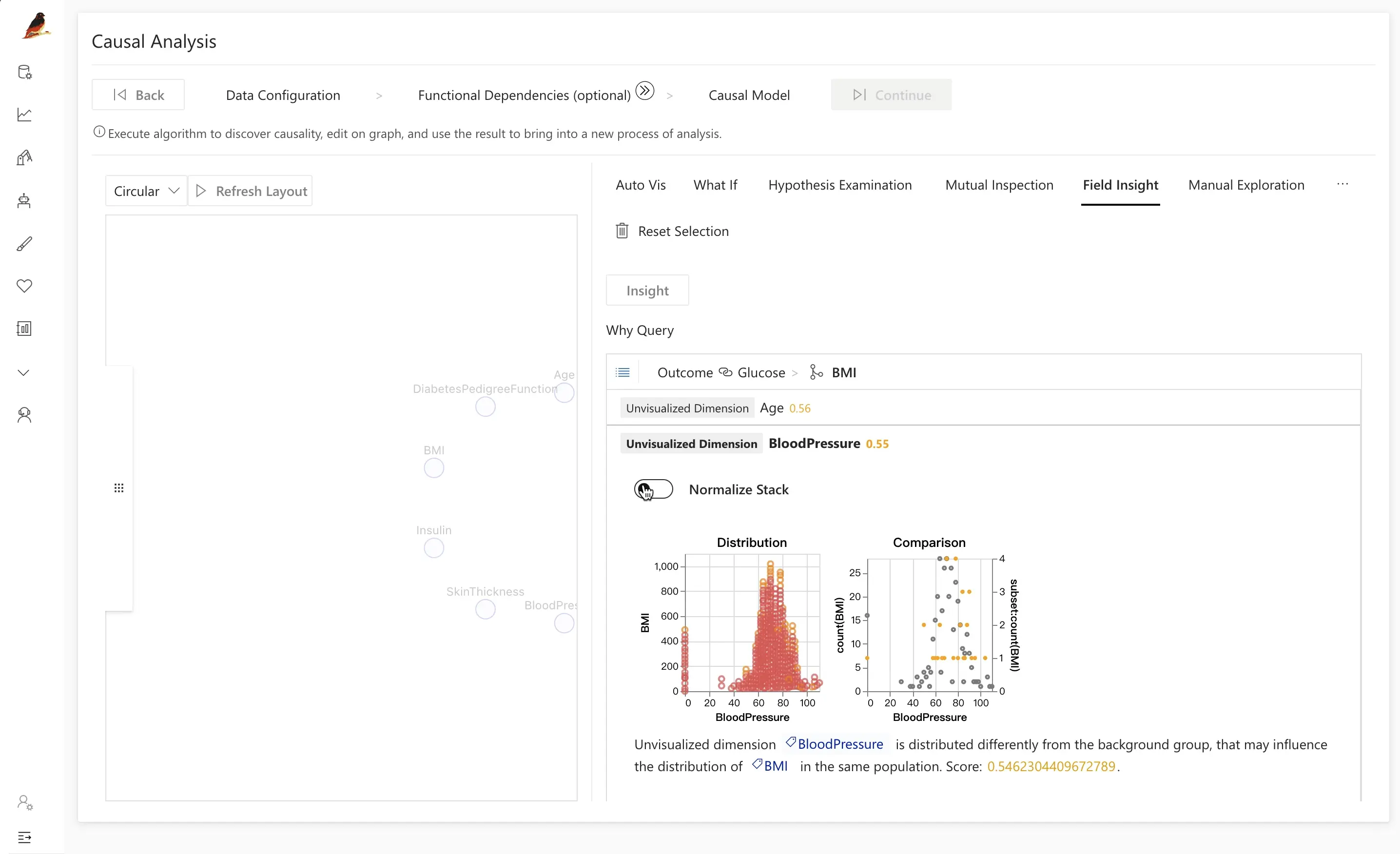
ステップ 3.2: Manual Exploration
Manual exploration は、特定の因果仮定を視覚的に検証するための機能です。
Diabetes データセットでは、たとえば次のような点を検証したくなるかもしれません。
InsulinがOutcomeの直接の原因なのかどうか。Insulinを調整したときに、GlucoseとOutcomeの関係がどう変化するか。
Manual Exploration を使うと、次のような操作ができます。
OutcomeとGlucoseの関係をプロットし、疾患者と健常者の分布を比較する。- 条件変数として
Insulinを追加し(例: インスリン値の区間でデータを分割)、その違いを確認する。
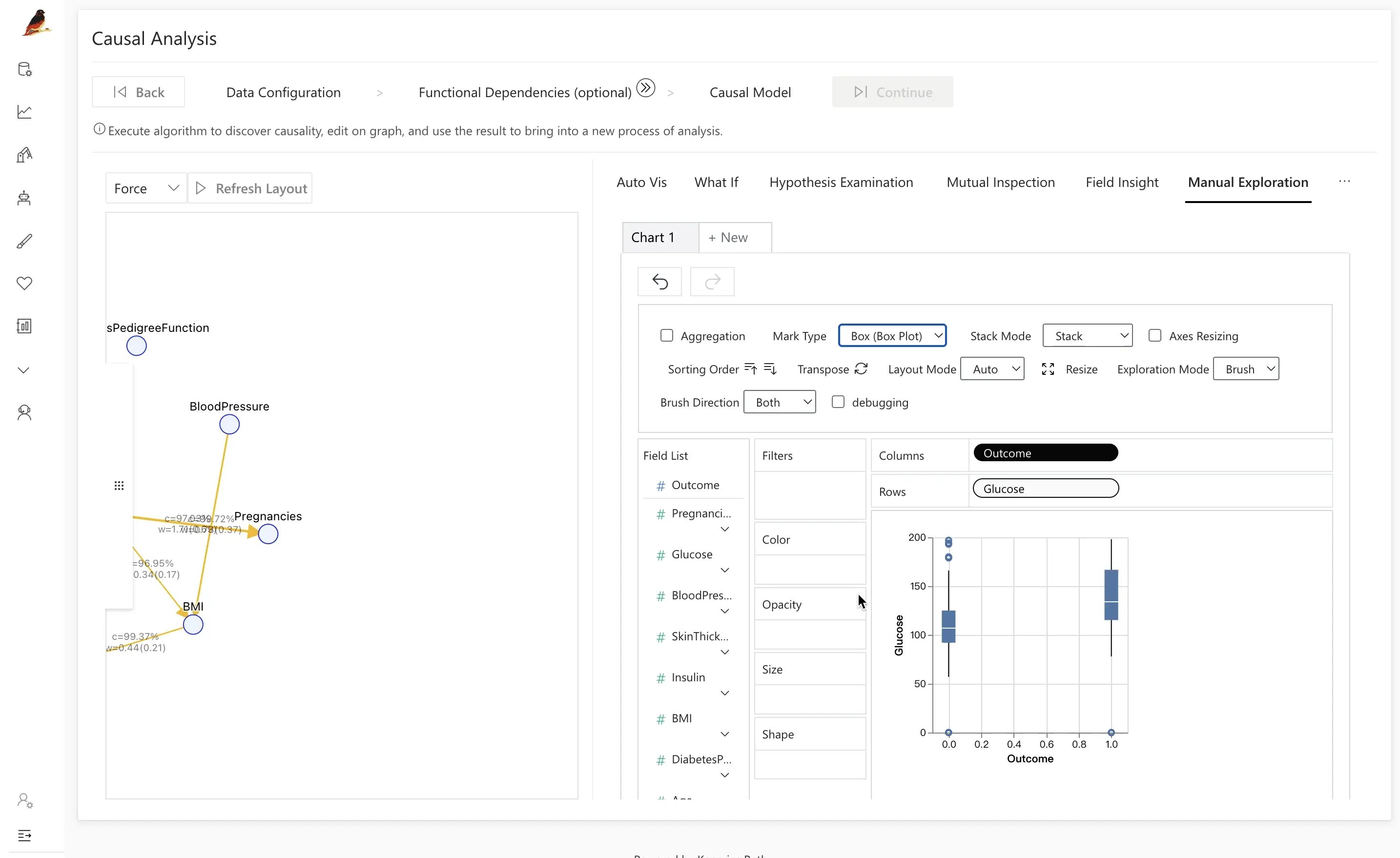
従来の分析では、相関や特徴量重要度を確認したところで終わってしまうことが多く、変数が どのように 影響を及ぼしているのかを見落としがちです。Causal Analysis を組み込むことで、RATH はそのメカニズムを明らかにし、見かけ上の効果が別の変数によって部分的に説明されている場面を把握しやすくします。
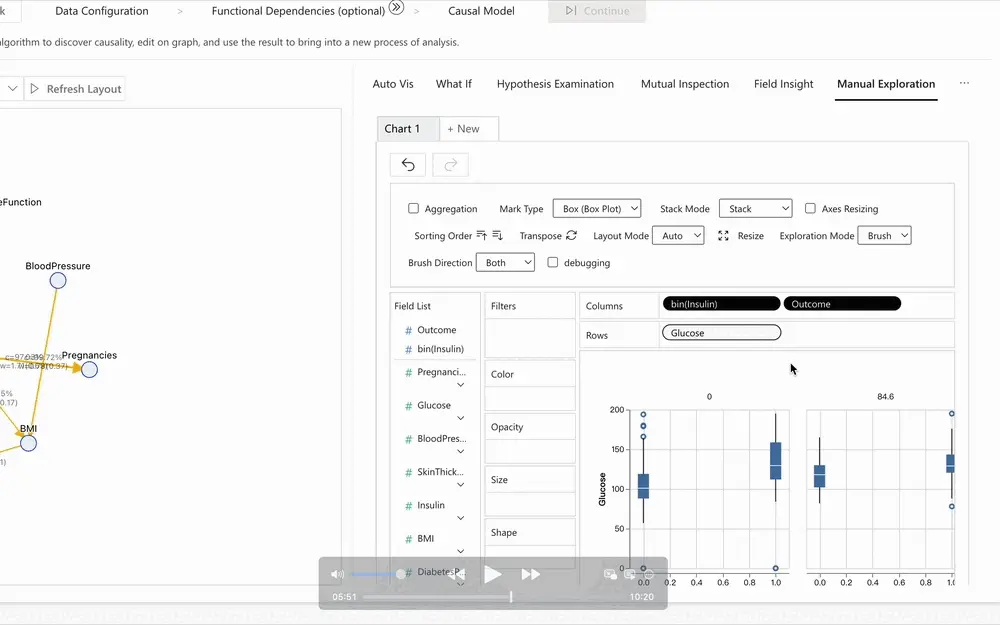
たとえば Outcome と Glucose の間に Insulin を導入した場合:
Insulinの区間ごとに条件づけて比較すると、疾患者と健常者のインスリンの違いが消えてしまうことがあります。- これは、
Insulinの影響を考慮すると、OutcomeとGlucoseの直接的な関係が 最初に見えたほど強くない ことを示唆しています。
ステップ 3.3: Mutual Inspection
Mutual Inspection ツールは、因果関係を検証し、仮定を確認するための別の手段を提供します。
動作イメージは次の通りです。
- 因果グラフ上でノードをクリックすると、その分布が右側の検証モジュールに追加されます。
- たとえば
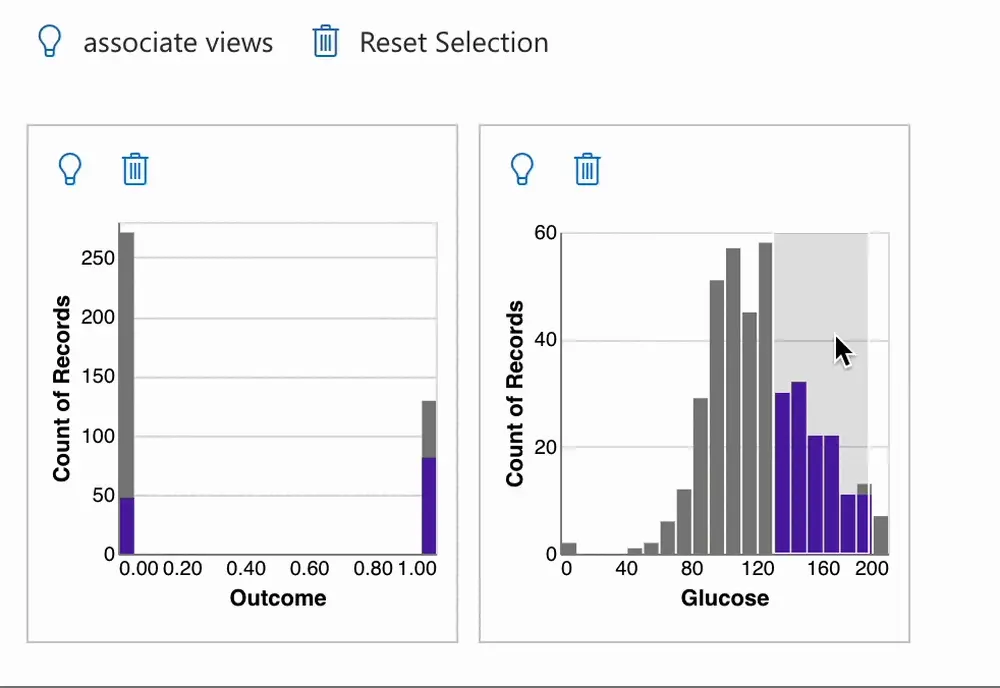
GlucoseとOutcomeの関係を調べたい場合は、この 2 つの変数を追加します。 Glucoseの範囲を選択し、その範囲をドラッグしていくと、Outcomeの分布がどのように変化するかを観察できます。
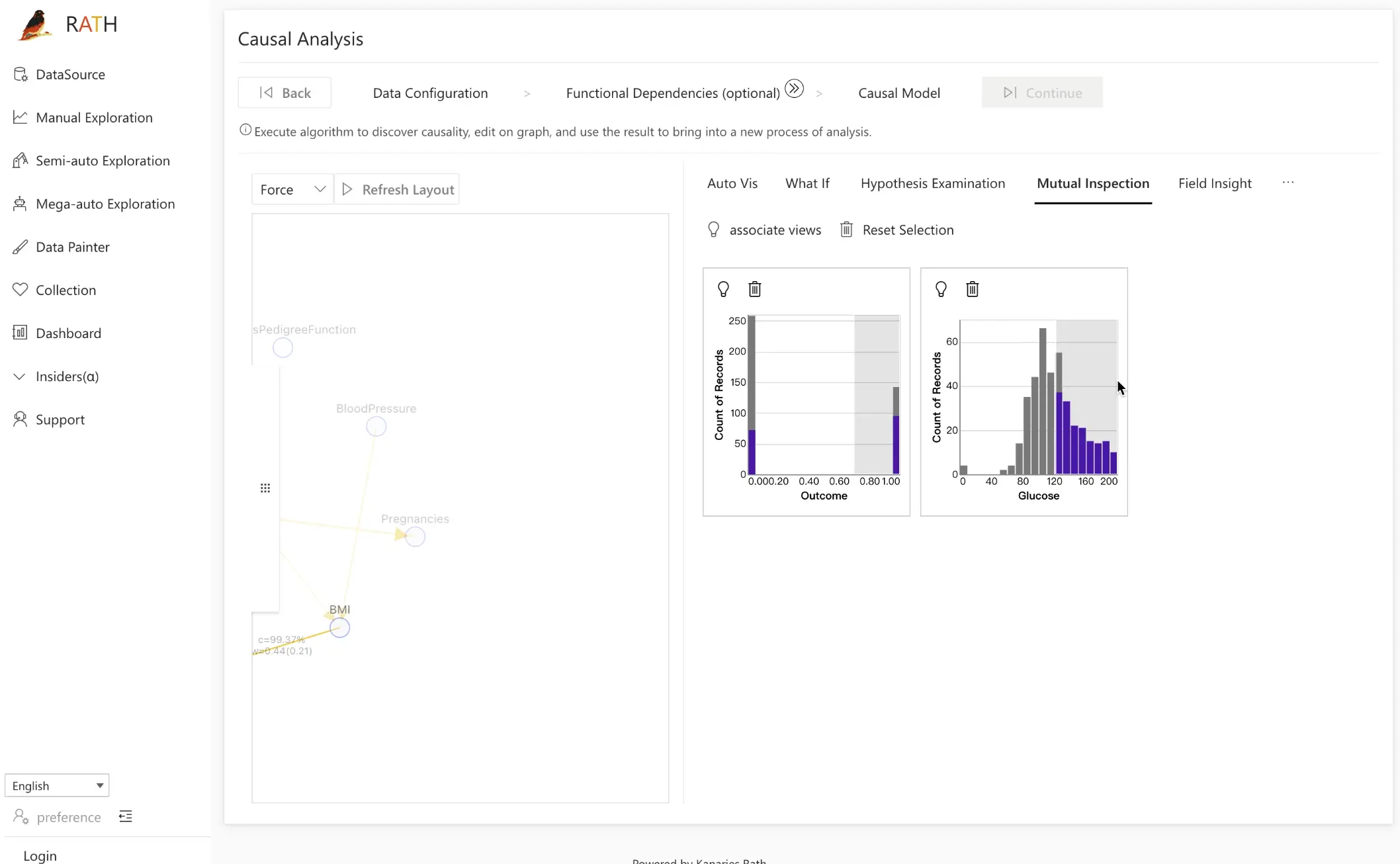
血糖値のレベルを横断的に変化させ、そのときのアウトカム分布の反応を確認することで、正の相関 がどの程度一貫して成り立っているかを視覚的に確かめられます。
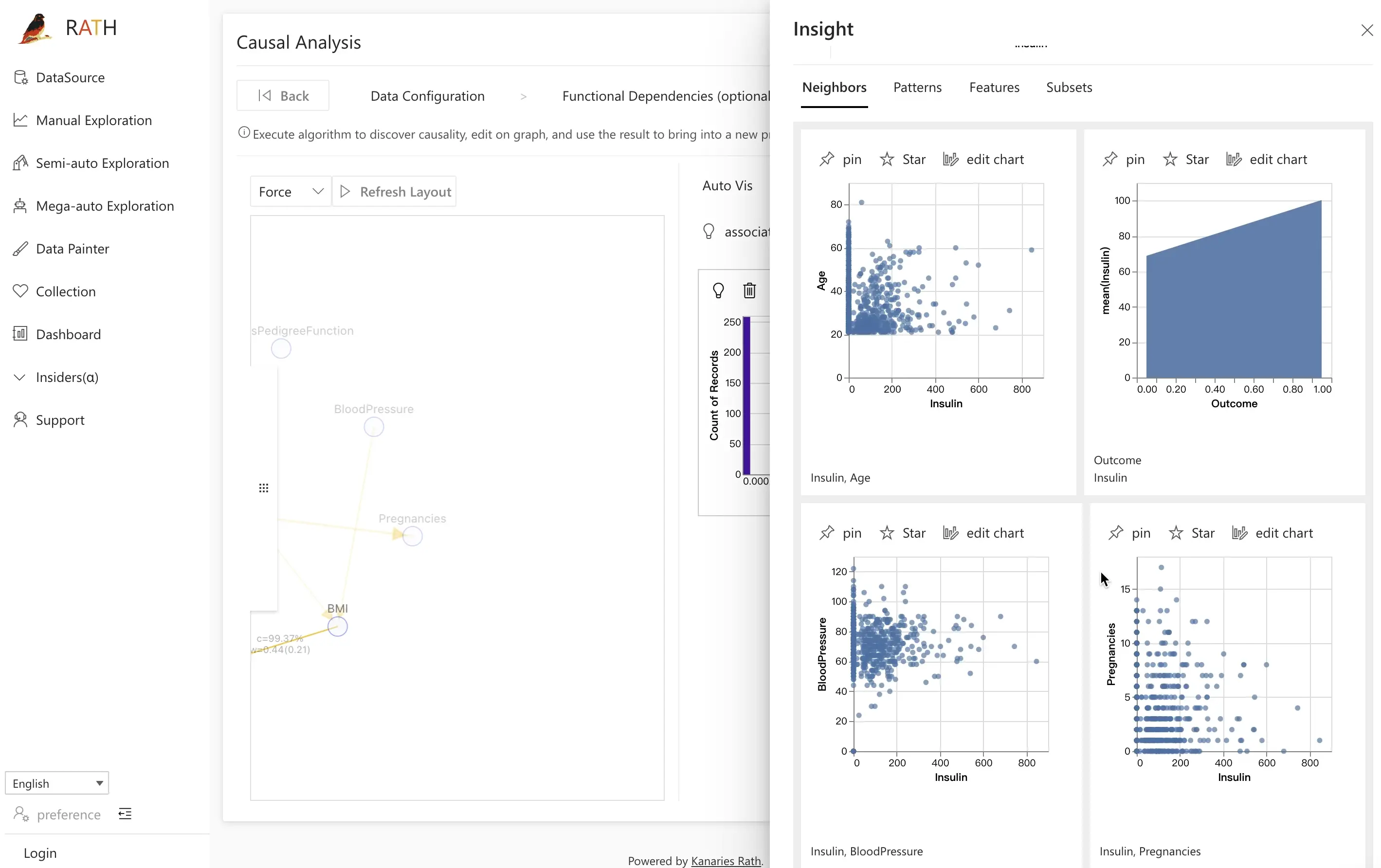
さらに踏み込むには、associate views をクリックして Semi-auto Exploration を有効にします。RATH は選択した変数間の関係を強調する散布図などのビューを自動的に推奨し、追加のパターンを素早く発見できるよう支援します。
ステップ 3.4: Prediction Test
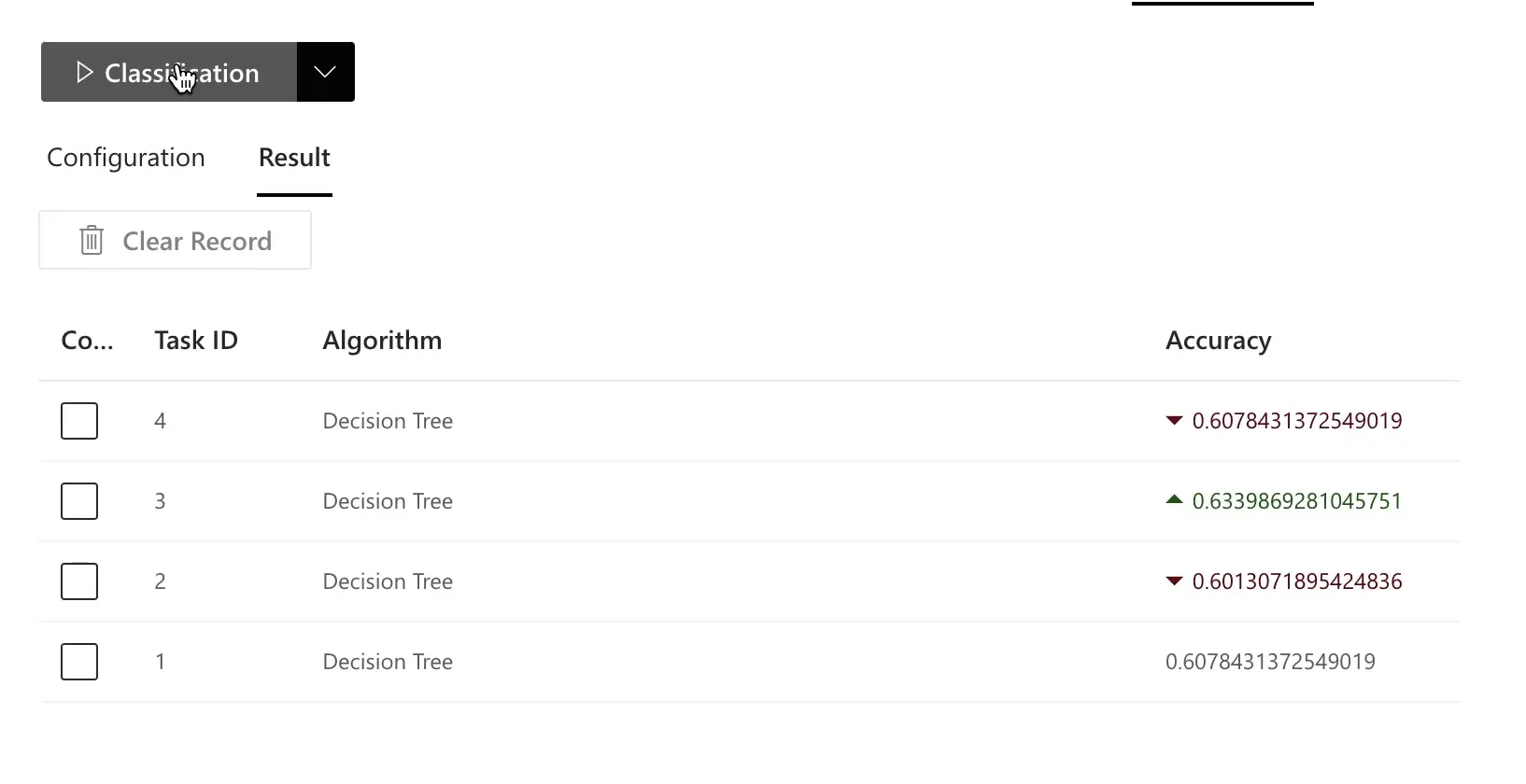
因果モデルが得られたら、それを予測用の機械学習モデルに変換し、Prediction Test で性能を評価できます。
- 因果グラフで
Outcome変数をクリックします。
RATH は、因果親や関連変数を使って、自動的にシンプルな分類/回帰モデルを構築します。
- Classification をクリックすると、モデルが学習され、Accuracy(および設定に応じた他の指標)が計算されます。

- テスト戦略を調整します。
- 因果グラフを参考に、より効率的で解釈しやすい特徴量セットを選択する。
- 因果特徴量に基づくモデルと、任意に選んだ特徴量サブセットによるモデルを比較する。
たとえば、RATH の因果分析で推奨された特徴量をあえて避けた競合モデルを構築し、その結果を比較することができます。
一般に、因果グラフに導かれたモデルの方が、精度が高く、汎化性能も優れている ことが多くのケースで確認できます。
RATH は、変数が多い 大規模・高次元データセット に特に適しています。因果分析により、より良い特徴量を自動的に特定でき、精度が高く、かつ解釈性の高い機械学習モデルにつながります。
因果モデルの編集
現実のデータはきれいとは限りません。次のような理由で、RATH が自動生成した因果グラフがドメイン知識と完全には一致しないことがあります。
- データのノイズ
- サンプルサイズの不足
- 欠落している変数
- アルゴリズムでは推論できない既知の制約
こうした場合には、因果モデルを直接 編集 できます。
- 左側のパネルを開きます。
- Modify Constraints をオンにします。
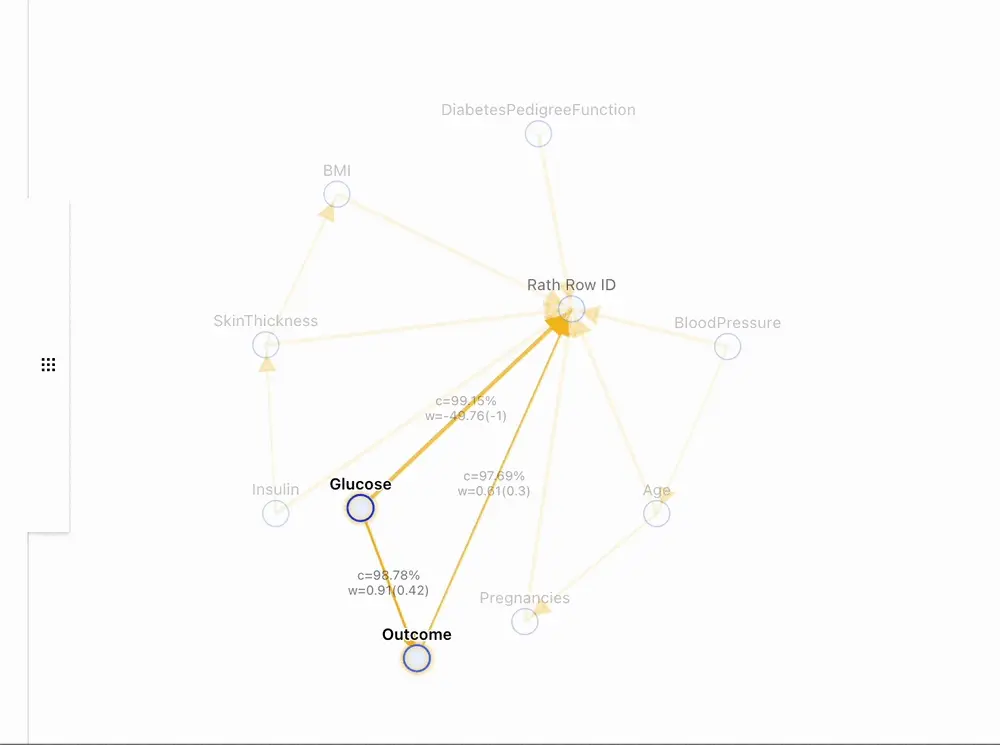
そのうえで次のような操作が可能です。
- ノードをドラッグ&ドロップして、エッジの追加・削除・向きの変更を行う。
- 「変数 A が変数 B によって引き起こされることはない」といったドメイン知識をモデルに反映する。
- 設定した制約を尊重する新しい因果モデルを RATH に再生成させる。
このように、自動発見 と 手動での洗練 を繰り返すことで、統計的に妥当であると同時に、専門家の理解とも整合した因果モデルに収束していけます。
次のステップ
因果モデルを構築したら、RATH でさらに先へ進むことができます。
- What-if Analysis の章で、what-if 型の因果分析 を学びましょう。因果モデル上で、(例: 「
Glucoseを X だけ下げたらOutcomeはどう変わるか?」)といった介入をシミュレーションできます。 - Text Pattern Extraction でテキストフィールドのパターンを抽出し、その特徴量を因果分析に再投入してパターン発見の幅を広げることもできます。
RATH は、因果モデルに基づく ナラティブなテキスト説明 にも進化しつつあります。因果グラフの構造や推定結果から、自動的にインサイトや意思決定の提案を生成する方向です。
ビジュアルな因果発見、インタラクティブな探索、予測モデリングを組み合わせることで、RATH はデータセットを単なる静的なダッシュボードではなく、行動につながる説明可能なインサイトへと変換します。