自動データ分析のための Python ライブラリ トップ 10

- Runcell Science:Claude Scienceのオープンソース代替となるAI研究ワークスペース
- Macをスリープさせない方法:Codex・Claude Codeを止めずに動かす
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: 2026年に選ぶべきAIエージェントスタックは?
- Claude CodeでJupyterノートブックを分析する方法|Data Science向けの実践ポイントと限界
- Claude Code Routinesとは?AIエージェントの定期実行と自動化を理解する
- Claude Code DesktopでBypass permissionsを有効にする方法
- GoogleのA2Aプロトコルで2つのPythonエージェントを構築する方法 - ステップバイステップチュートリアル
- 2025年のPythonで人気のあるトップ10のデータ可視化ライブラリ
序章
自動データ分析は、今日のデータ駆動型の世界でますます重要になっています。 毎日大量のデータが生成されるため、大規模なデータ セットを手動で分析および処理すると、時間がかかり、エラーが発生しやすくなります。 幸いなことに、Python にはデータ分析タスクを自動化できる幅広いライブラリが用意されているため、大規模なデータ セットを簡単に操作して意味のある洞察を引き出すことができます。
この記事では、データ分析の自動化に使用できる 10 個の Python ライブラリについて説明します。 これらのライブラリは、Pandas、NumPy、Matplotlib、Seaborn、Scikit-learn、TensorFlow、Keras、NLTK、およびその他の組み込みたい関連ライブラリです。
パート 1. 次世代の自動データ分析: RATH
RATH (opens in a new tab) は、Tableau などのデータ分析および視覚化ツールに代わるオープンソースのツールではありません。 パターン、洞察、因果関係を発見することにより、拡張分析エンジンを使用して探索的データ分析ワークフローを自動化し、これらの洞察を強力な自動生成された多次元データ視覚化で提示します。
| 機能 | 説明 | プレビュー |
|---|---|---|
| AutoEda | パターン、洞察、因果関係を発見するための拡張分析エンジン。 ワンクリックでデータ セットを探索し、データを視覚化する完全自動化された方法。 | 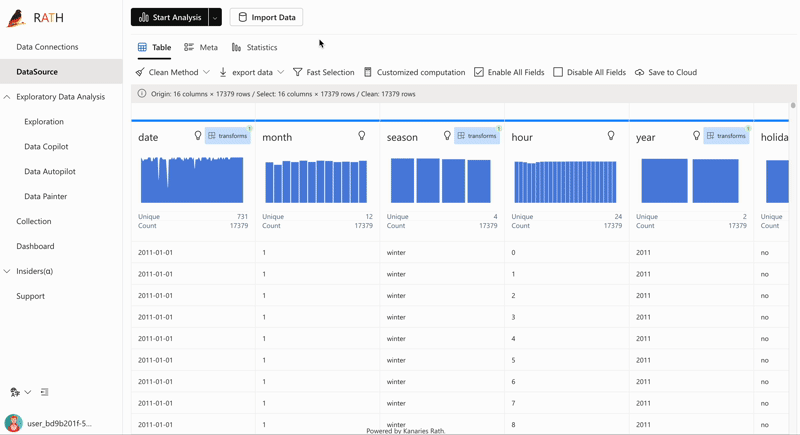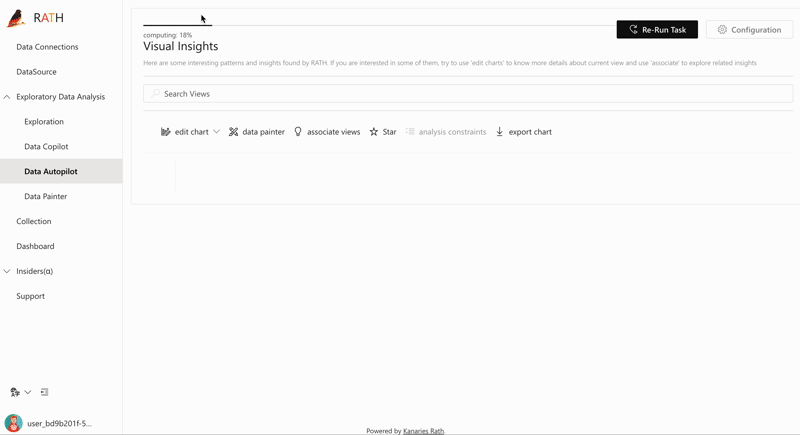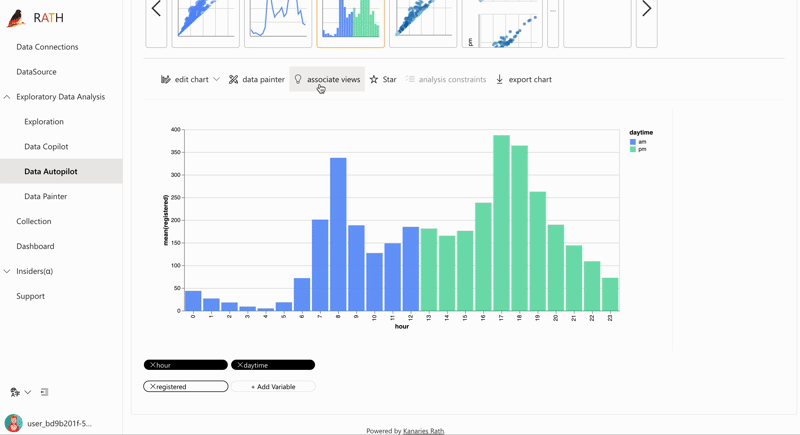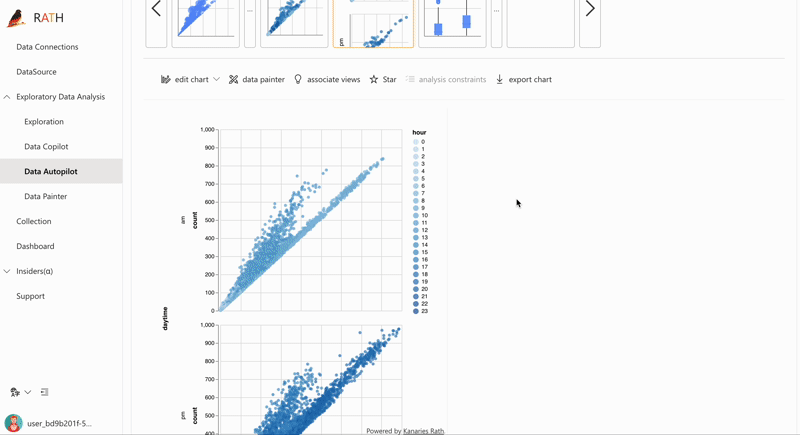 |
| データの可視化 | 有効性スコアに基づいて多次元データの視覚化を作成します。 | 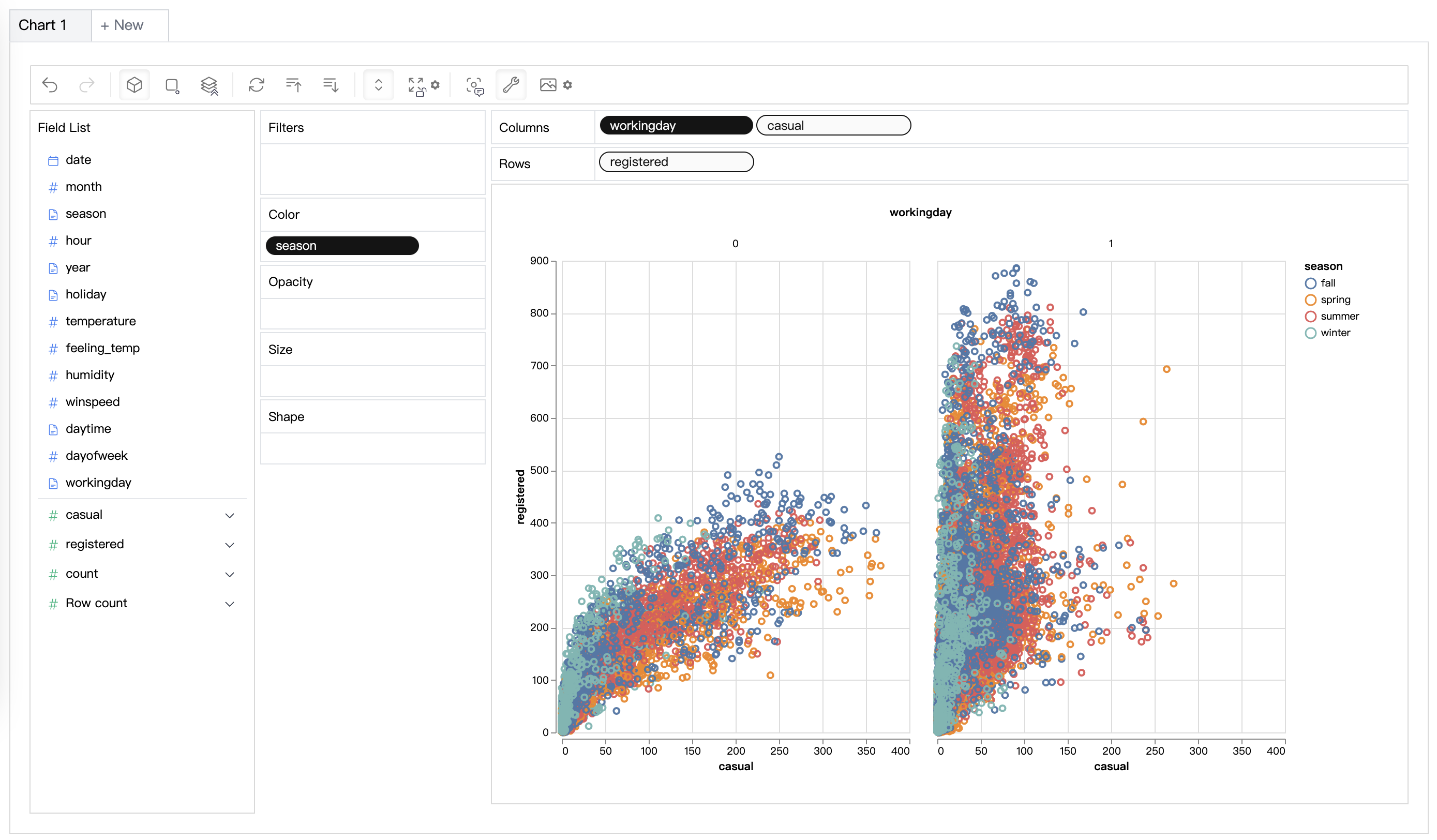 |
| Data Wrangler | データとデータ変換の概要を生成するための自動化されたデータ ラングラー。 | 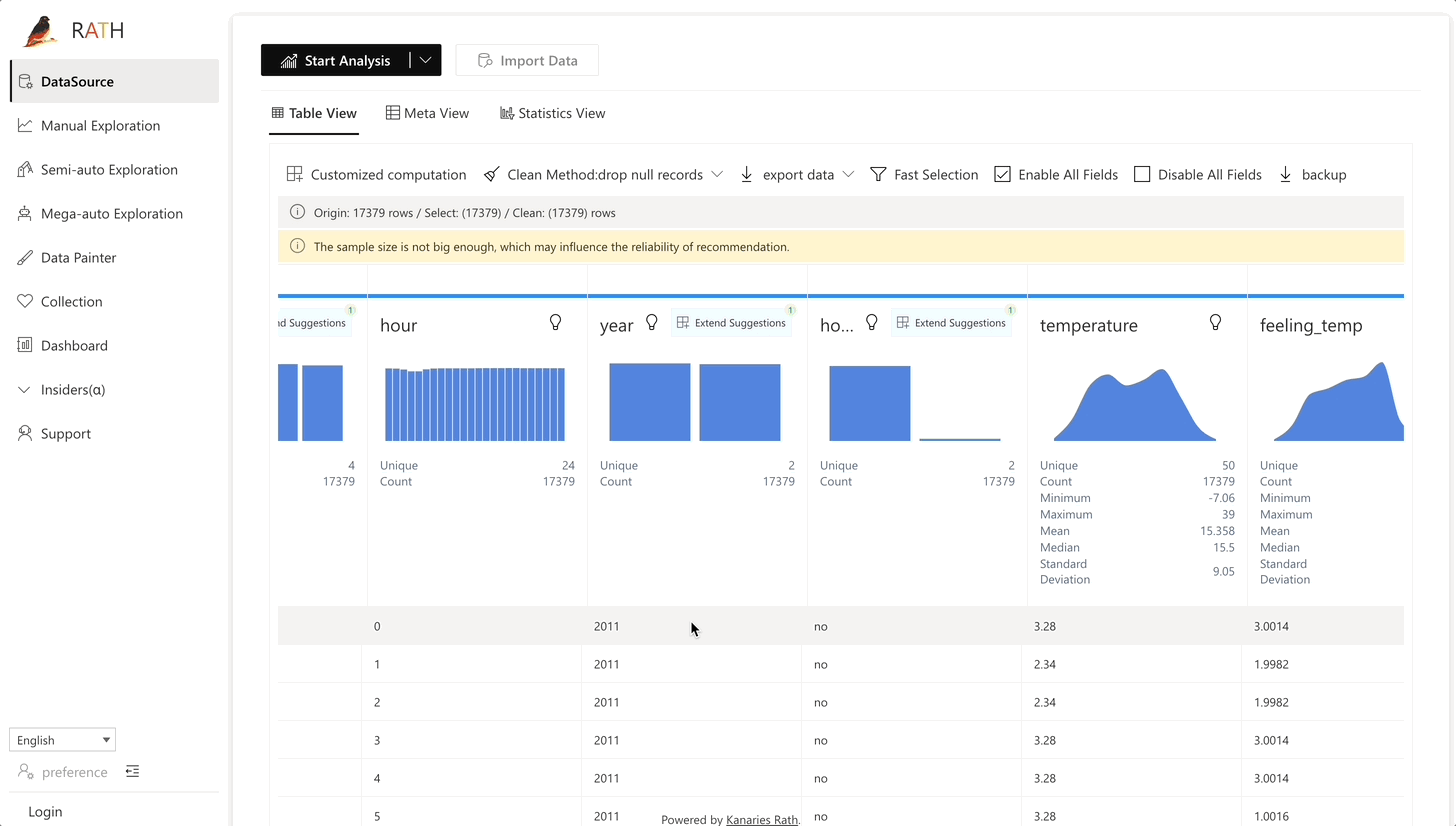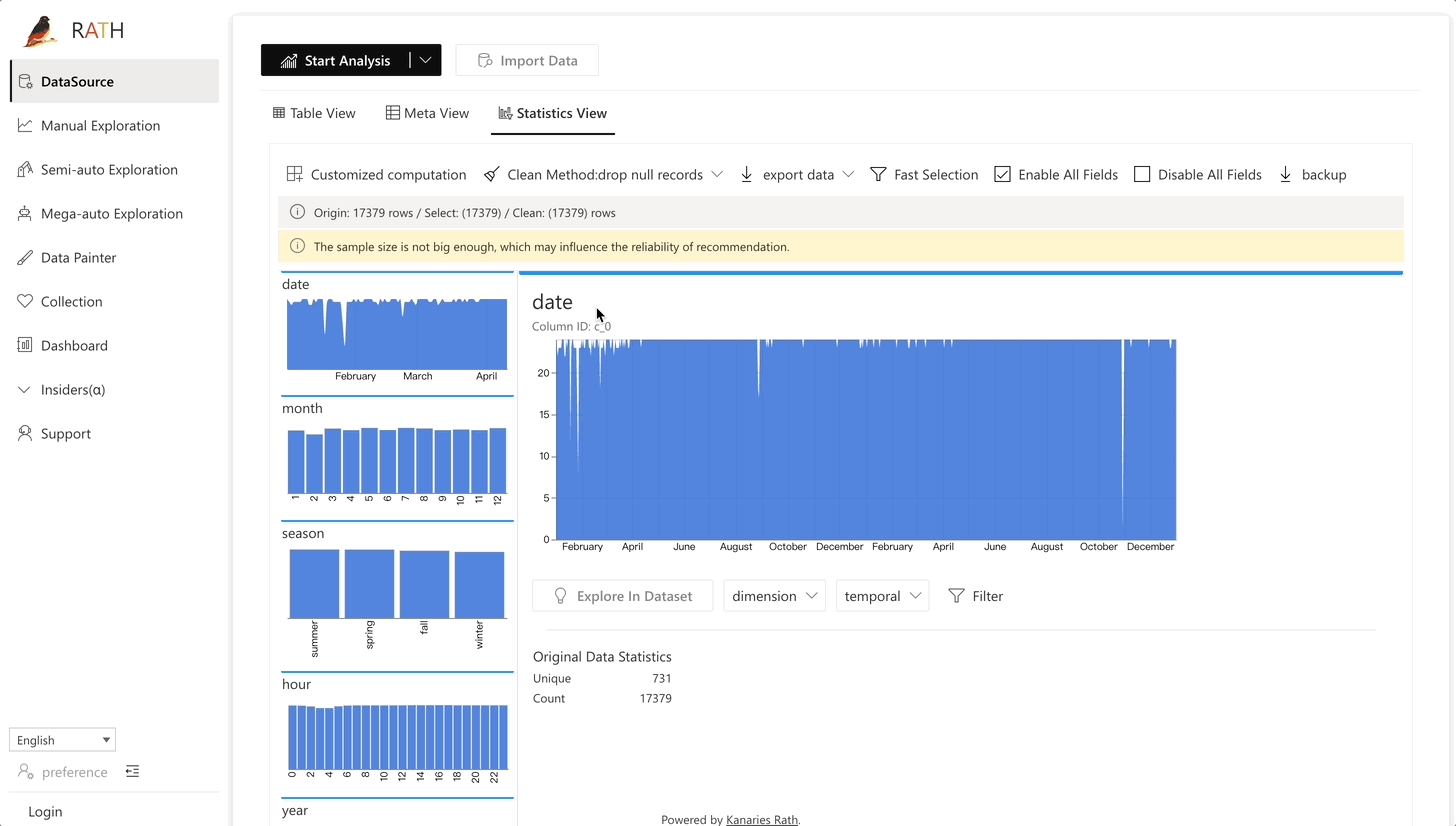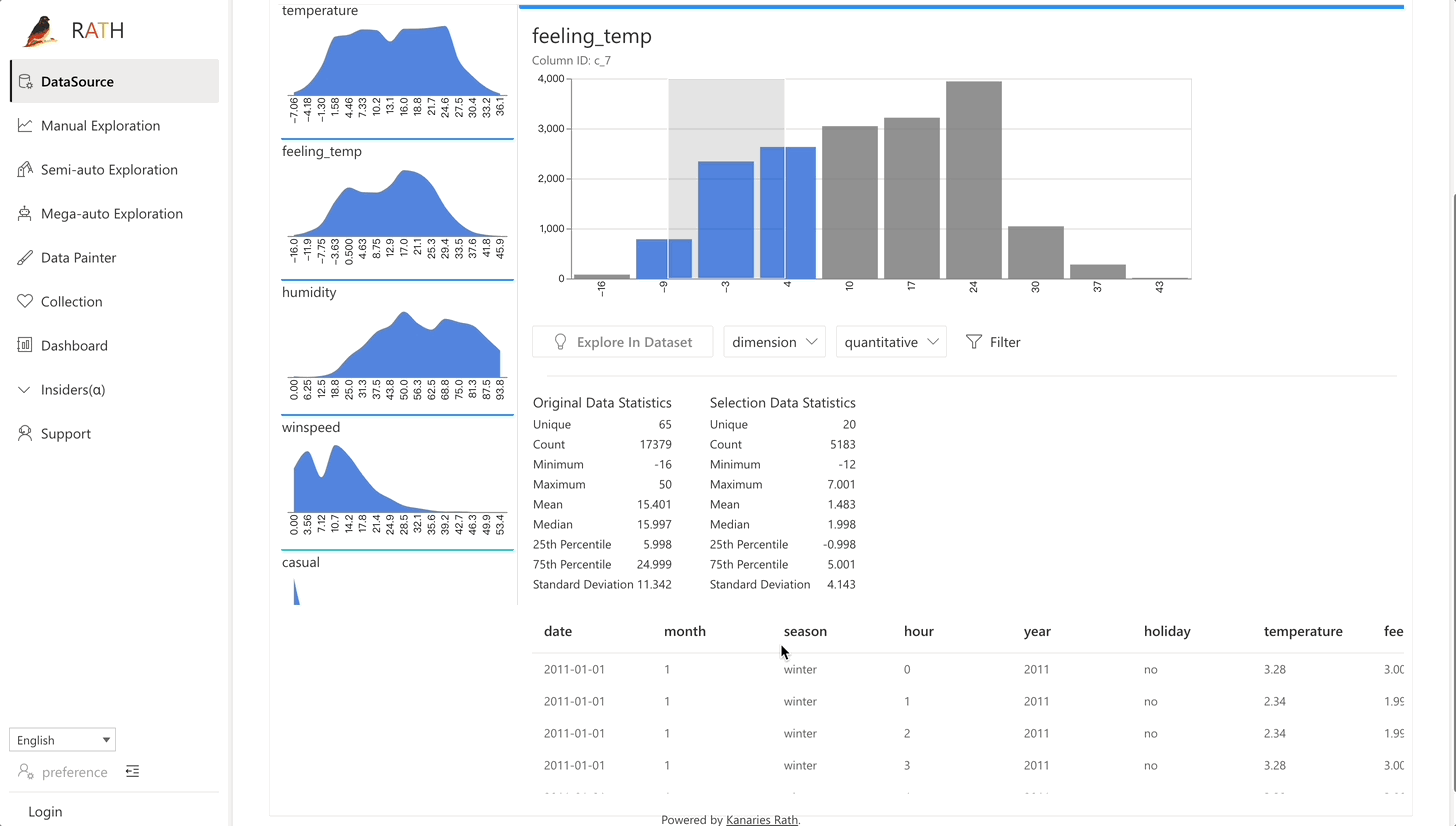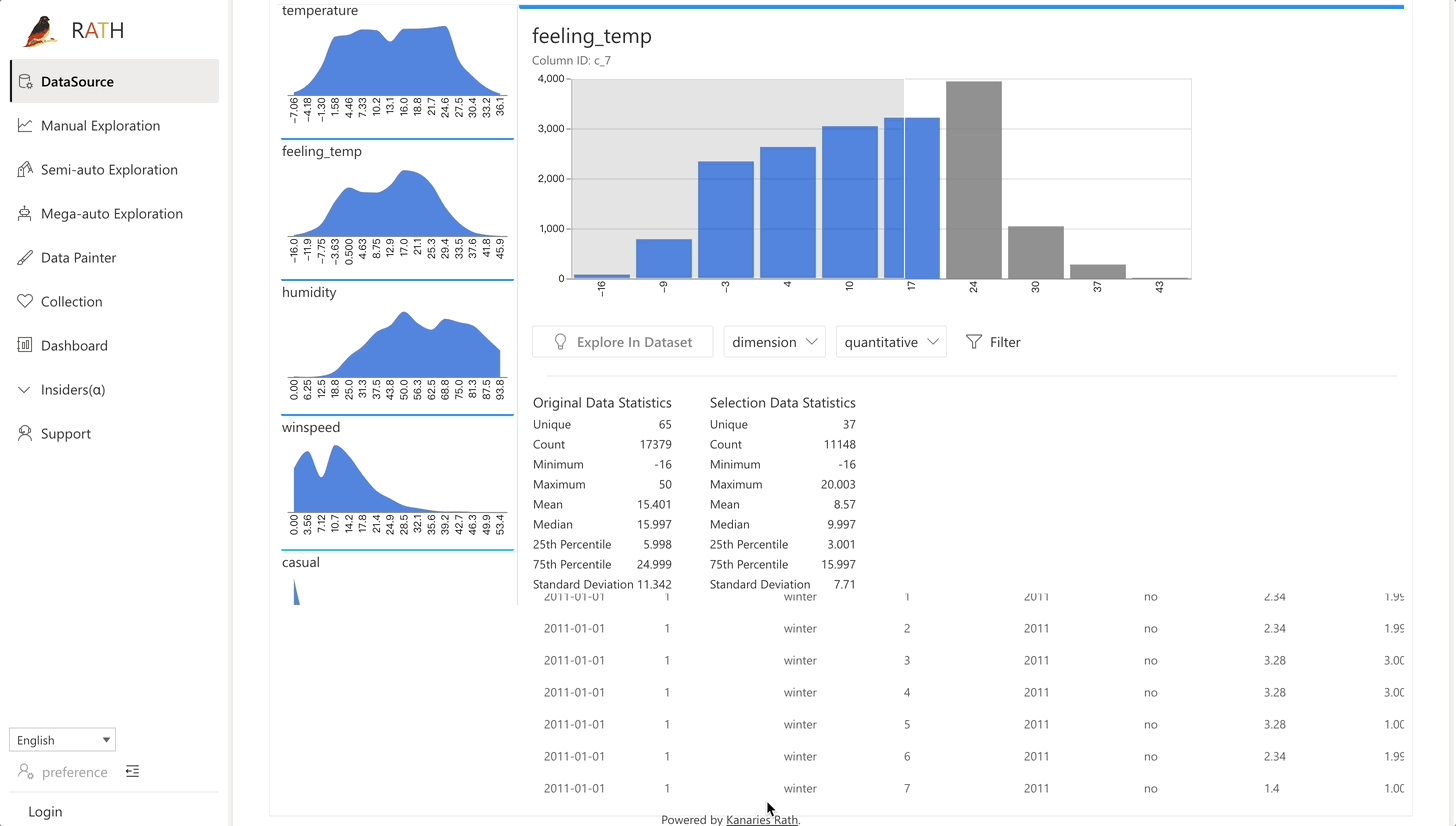 |
| データ探索コパイロット | 自動データ探索と手動探索を組み合わせます。 RATH はデータ サイエンスの副操縦士として働き、あなたの興味を学習し、拡張分析エンジンを使用して関連する推奨事項を生成します。 | 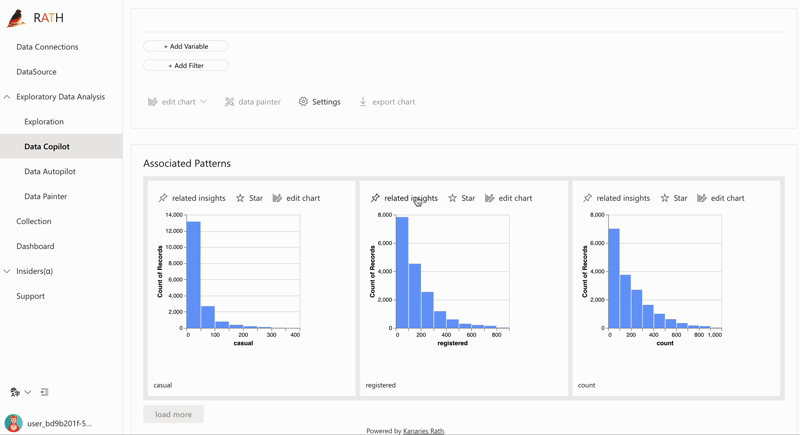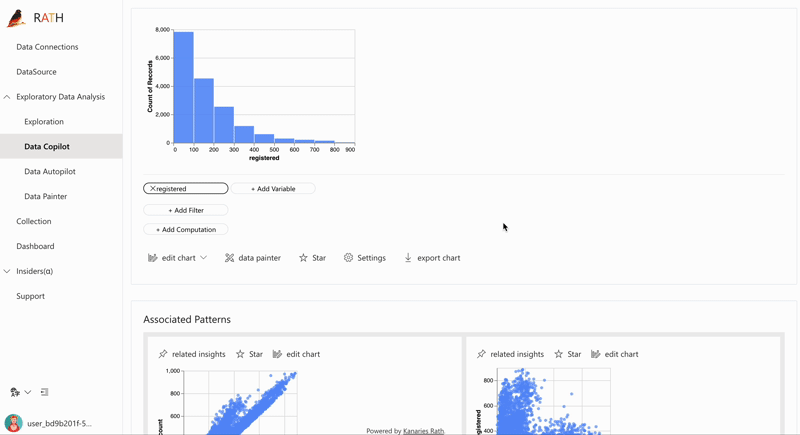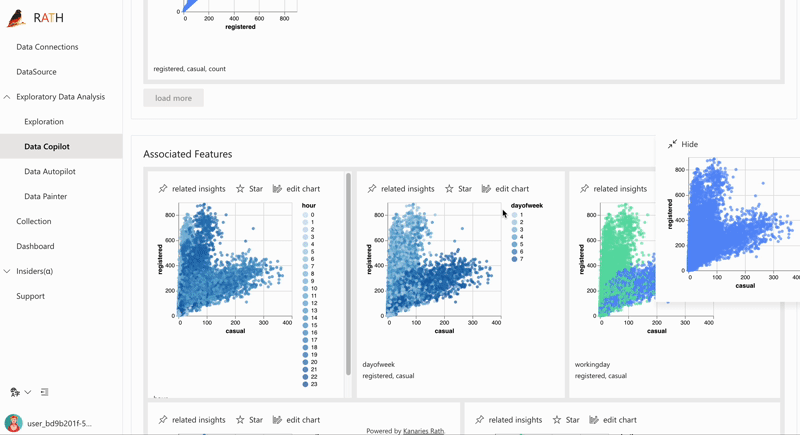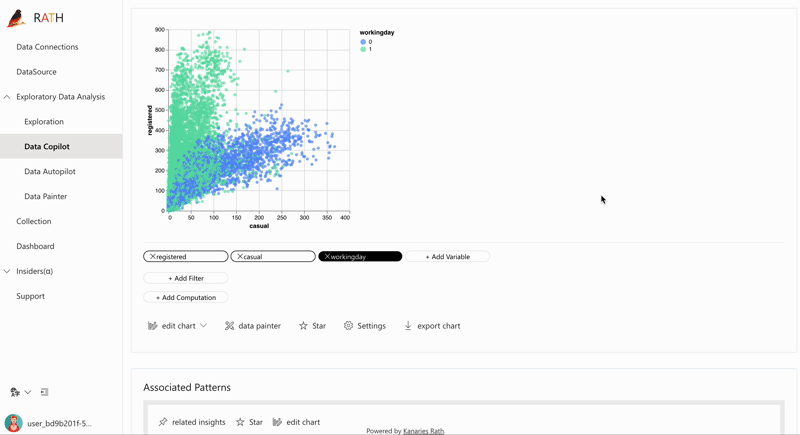 |
| Data Painter | さらなる分析機能を使用して、データを直接色付けすることで探索的データ分析を行うためのインタラクティブで直感的かつ強力なツールです。 | 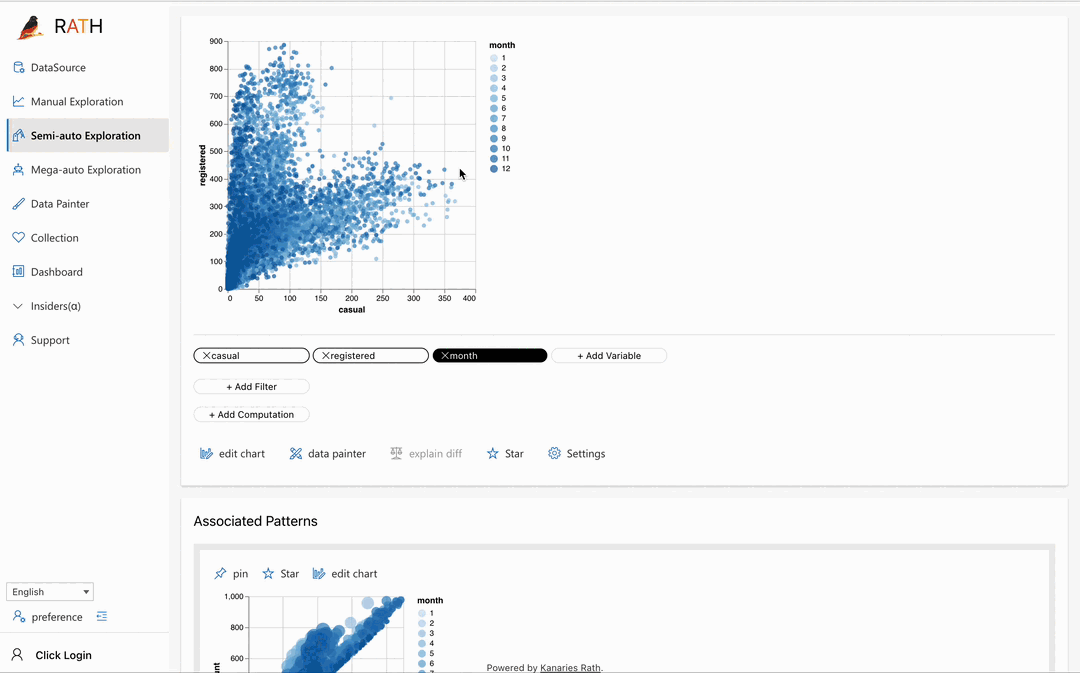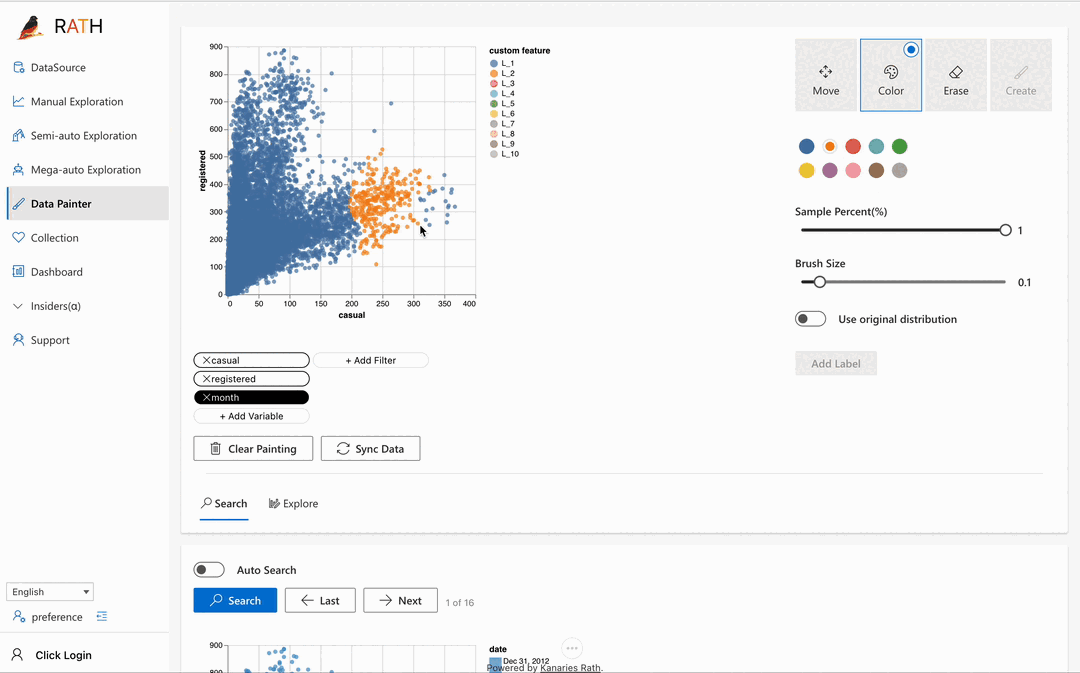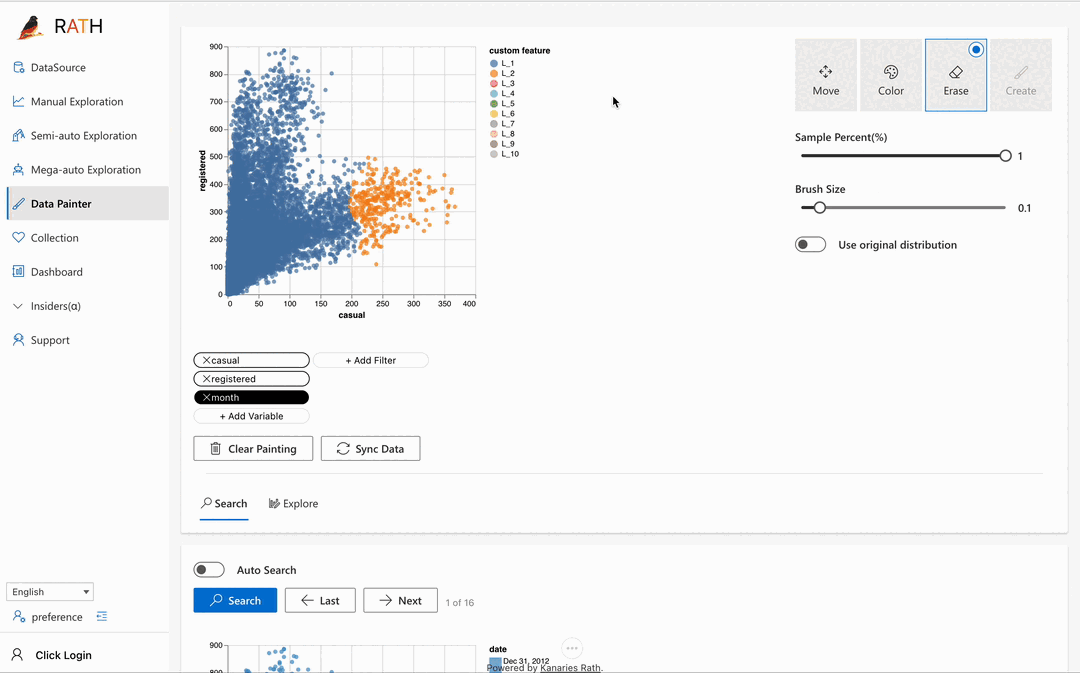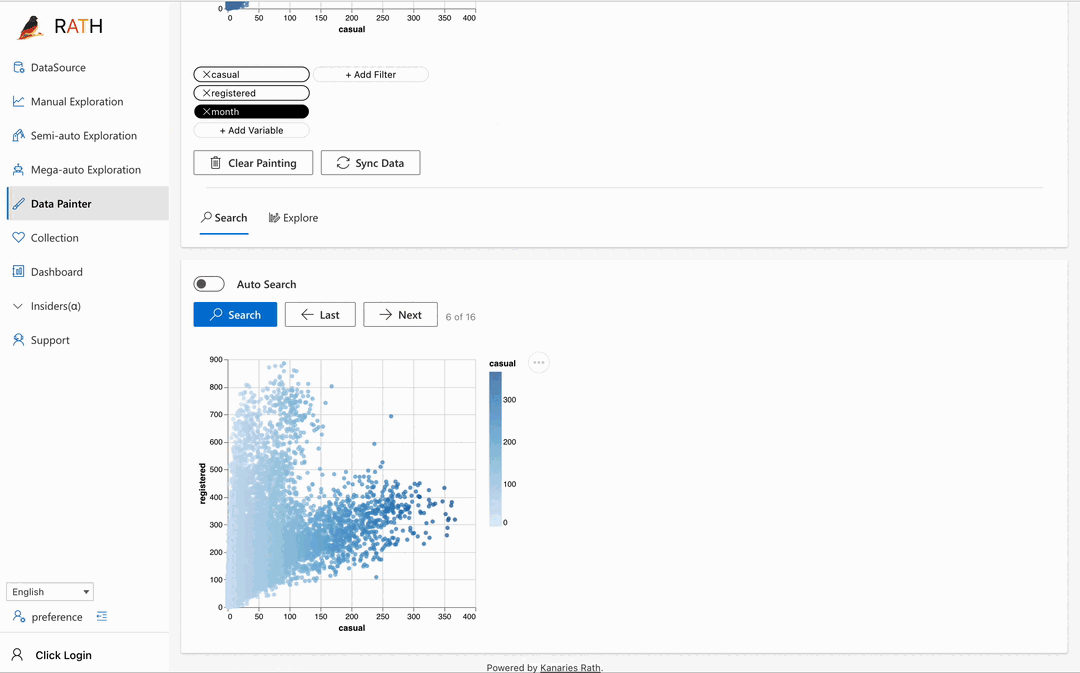 |
| ダッシュボード | 美しいインタラクティブなデータ ダッシュボードを構築します (ダッシュボードに提案を提供できる自動ダッシュボード デザイナーを含む) |  |
| 因果分析 | 複雑な関係分析の因果関係の発見と説明を提供します。 | 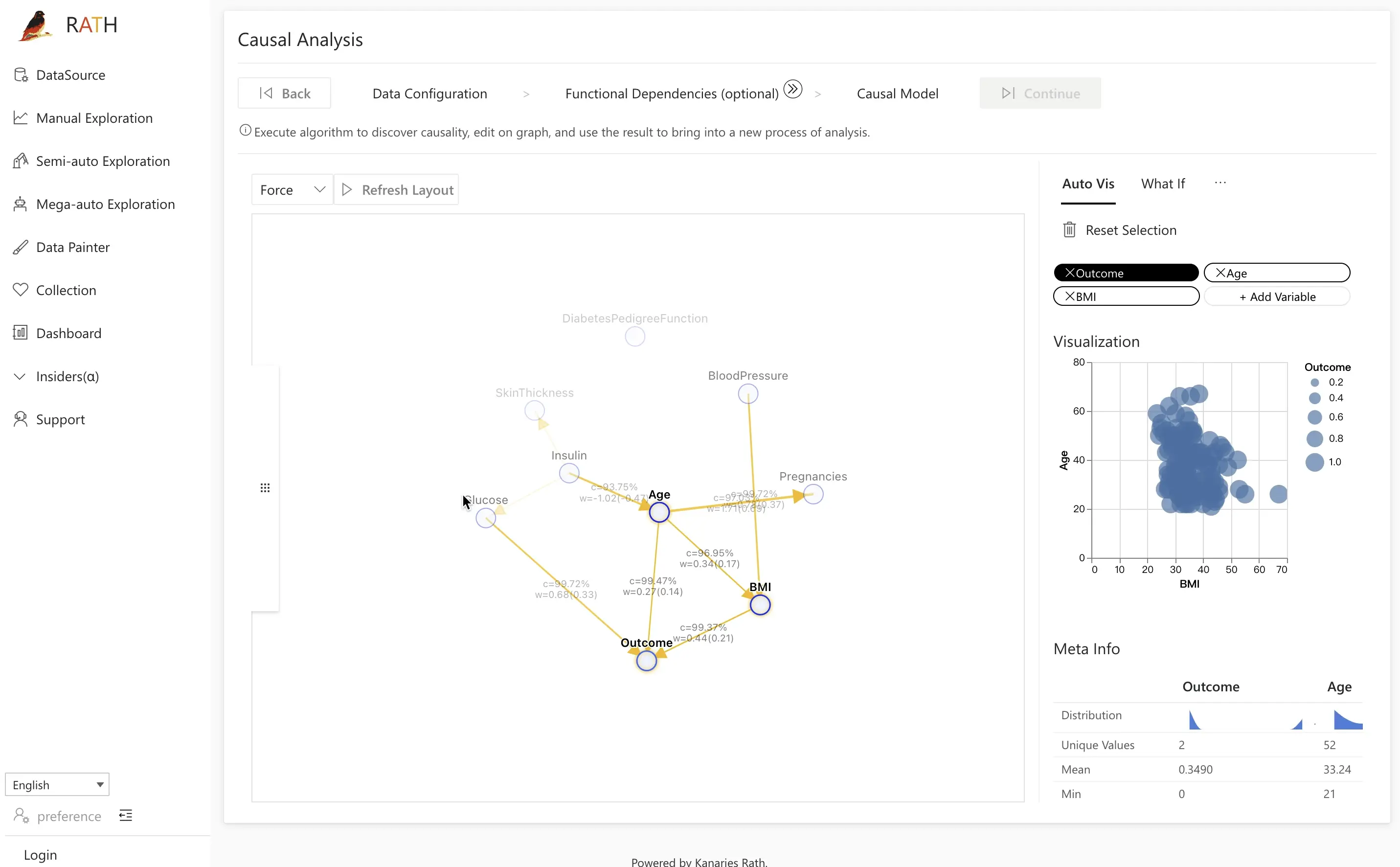 |
RATH は幅広いデータ ソースをサポートしています。 RATH に接続できる主要なデータベース ソリューションの一部を以下に示します: MySQL、ClickHouse、Amazon Athena、Amazon Redshift、Apache Spark SQL、Apache Doris、Apache Hive、Apache Impala、Apache Kylin、Oracle、および PostgreSQL。
RATH (opens in a new tab) はオープンソースです。 RATH GitHub にアクセスして、次世代の Auto-EDA ツールを体験してください。 また、データ分析のプレイグラウンドとして RATH オンライン デモをチェックすることもできます。

パート 2. トップ Python 自動データ分析ライブラリ
- パンダ
Pandas は、Python でのデータ分析用の最も人気のあるライブラリの 1 つです。 大量のデータを簡単に処理できる強力なデータ構造とデータ操作ツールを提供します。 Pandas を使用すると、さらなる分析のためにデータを簡単にロード、クリーニング、および準備できます。 また、データのフィルタリング、グループ化、結合などのデータ操作タスクを実行することもできます。
Pandas を使用してデータを DataFrame にロードし、欠損値を処理する方法の例を次に示します。
import pandas as pd
# データを DataFrame に読み込む
df = pd.read_csv('data.csv')
# 欠損値の処理
df.fillna(0, inplace=True)2.NumPy
NumPy は、数値計算とデータ操作のための強力なライブラリです。 幅広い数学関数を提供し、データの配列に対して操作を実行できます。 NumPy を使用すると、データの平均、標準偏差、相関などの統計を簡単に計算できます。
以下は、NumPy を使用してデータ配列の平均と標準偏差を計算する方法の例です。
import numpy as np
data = [1, 2, 3, 4, 5]
# 平均を計算する
mean = np.mean(data)
print(mean) # 3.0
# 標準偏差を計算する
std = np.std(data)
print(std) # 1.5811388300841898- Matplotlib
Matplotlib は Python のプロット ライブラリで、静的、アニメーション、インタラクティブな視覚化を作成できます。 これはデータを視覚化するための強力なツールであり、折れ線グラフ、散布図、ヒストグラムなどのさまざまなプロットを作成するために使用できます。
Matplotlib を使用して単純な折れ線グラフを作成する方法の例を次に示します。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
plt.plot(x, y)
plt.xlabel('x-axis')
plt.ylabel('y-axis')
plt.title('Line Plot')
plt.show()- Seaborn
Seaborn は、Matplotlib の上に構築されたライブラリであり、より高度な視覚化を作成できます。 Pandas によるデータ視覚化のサポートが組み込まれており、ヒートマップ、ボックス プロット、バイオリン プロットの作成に使用できます。
以下は、Seaborn を使用してヒートマップを作成する方法の例です。
import seaborn as sns
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
sns.heatmap(data)
plt.title('Heatmap')
plt.show()- Scikit-learn
scikit-learn は、Python で機械学習を行うための強力なライブラリです。 分類、回帰、クラスタリングなどの幅広いアルゴリズムを提供します。 また、NumPy や Pandas などの他のライブラリとも互換性があるため、データ分析ワークフローと簡単に統合できます。
以下は、scikit-learn を使用して線形回帰モデルを構築する方法の例です。
from sklearn.linear_model import LinearRegression
x = [[1], [2], [3], [4], [5]]
y = [2, 4, 6, 8, 10]
model = LinearRegression()
model.fit(x, y)
print(model.coef_) # [2.0]
print(model.intercept_) # 0.0- TensorFlow
TensorFlow は、Python でディープ ラーニングを行うための強力なライブラリです。 これにより、機械学習モデル、特に深層学習モデルを構築、トレーニング、デプロイできます。 TensorFlow を使用すると、ニューラル ネットワークを簡単に構築し、画像分類や自然言語処理などのタスクを実行できます。
TensorFlow を使用して単純なフィードフォワード ニューラル ネットワークを構築する方法の例を次に示します。
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(10, input_dim=8, activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='adam')- Keras
Keras は、Python で記述された高レベルのニューラル ネットワーク API です。 これは、ニューラル ネットワーク モデルを簡単に構築、トレーニング、およびテストできる使いやすい API です。 TensorFlow の上に構築されており、最小限のコードで複雑なニューラル ネットワークを構築するために使用できます。
Keras を使用して単純なフィードフォワード ニューラル ネットワークを構築する方法の例を次に示します。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(10, input_dim=8, activation='relu'))
model.add(Dense(1, activation='linear'))
model.compile(loss='mean_squared_error', optimizer='adam')- NLTK
NLTK (Natural Language Toolkit) は、自然言語処理 (NLP) 用のツールを提供する Python のライブラリです。 トークン化、ステミング、品詞のタグ付けなどのタスクを実行するために使用できます。 NLTK を使用すると、テキスト データを簡単に分析して理解することができます。
NLTK を使用して文をトークン化する方法の例を次に示します。
import nltk
sentence = "This is a sample sentence."
tokens = nltk.word_tokenize(sentence)
print(tokens) # ['This', 'is', 'a', 'sample', 'sentence', '.']- Scipy
SciPy は Python のライブラリで、NumPy の上に構築され、幅広い数学および科学関数を提供します。 最適化、統合、補間、信号および画像処理などに使用できます。 これは、科学計算とデータ分析のための強力なライブラリです。
Scipy を使用して最適化を実行する方法の例を次に示します。
from scipy.optimize import minimize
def function(x):
return x[0]**2 + x[1]**2
x0 = [2, -1]
res = minimize(function, x0)
print(res)- Statsmodels
Statsmodels は、さまざまな統計モデルを推定するためのクラスと関数を提供する Python のライブラリです。 また、さまざまな統計テストとデータ探索ツールも提供します。 NumPy および Pandas と互換性があるため、データ分析ワークフローと簡単に統合できます。
Statsmodels を使用して線形回帰を実行する方法の例を次に示します。
import statsmodels.api as sm
X = [[1, 2], [3, 4], [5, 6], [7, 8]]
y = [2, 4, 6, 8]
X = sm.add_constant(X)
model = sm.OLS(y, X)
results = model.fit()
print(results.summary())結論
結論として、これらはデータ分析タスクの自動化に使用できる Python で利用可能な多くのライブラリのほんの一例です。 これらのライブラリを使用すると、大規模なデータ セットの操作、データのクリーニングと準備の実行、意味のある洞察の抽出、および視覚化の作成を簡単に行うことができます。 より近代化されたインターフェースと、因果分析、データ探索コパイロットなどのより高度な機能を好む人にとって、RATH はあなたを支援する究極のツールです。