Wie Claude Code Jupyter Notebooks analysiert: Data Science, Grenzen und die bessere Alternative

Claude Code kann ein Jupyter Notebook lesen, zusammenfassen und umschreiben. Aber es arbeitet dabei nicht wie ein Jupyter-nativer Agent mit Zugriff auf den aktiven Kernel, aktuelle Variablen oder den echten Laufzeitstatus. Praktisch behandelt Claude Code ein .ipynb vor allem als strukturierte Datei.
Für Softwareentwicklung reicht das oft. Für Data Science reicht es häufig nicht. In Notebook-Workflows zählen Ausführungsreihenfolge, DataFrames, Diagramme und Experimentzustand. Wer nur die Datei versteht, versteht nur einen Teil des eigentlichen Arbeitsablaufs.
Hilfreiche Ergänzungen zu diesem Thema sind Python Notebook, JupyterLab vs Notebook und Jupyter AI mit RunCell.
Kurzantwort
| Frage | Antwort |
|---|---|
| Kann Claude Code ein Jupyter Notebook öffnen? | Ja |
| Kann es Zellen und gespeicherte Outputs zusammenfassen? | Ja |
| Kann es Zellen bearbeiten? | Ja |
| Kann es Zellen ausführen oder den Kernel steuern? | Nein |
| Sieht es Live-Variablen und aktuelle DataFrames? | Nicht als echtes Runtime-Tool |
| Reicht das für vollständige Data-Science-Notebook-Arbeit? | Meistens nein |
Was Claude Code in Jupyter gut kann
Claude Code ist nützlich, wenn du das Notebook wie ein Artefakt prüfen oder aufräumen willst.
- Notebook-Struktur zusammenfassen
- den Zweck einzelner Zellen erklären
- unübersichtlichen pandas-Code umschreiben
- Markdown-Text verbessern
- redundante oder zu lange Zellen bereinigen
Das ist gut für Review, Cleanup und Dokumentation. Es ist deutlich weniger geeignet, wenn der Agent den Live-Workflow im Notebook fortsetzen soll.
Wie Claude Code technisch mit Notebooks arbeitet
Claude Code hat zwei relevante Notebook-Fähigkeiten:
- notebook-bewusstes Lesen von
.ipynb - zellorientiertes Bearbeiten über eine eigene Notebook-Edit-Funktion
Die Grenze bleibt trotzdem dateibasiert.
1. Es liest Notebook-JSON, nicht den Live-Kernel
Claude Code parst die .ipynb-Datei, extrahiert Zellen und gespeicherte Outputs und formt das Ergebnis für das Modell um.
Es macht aber nicht das, was viele Data-Science-Nutzer erwarten:
- kein Kernel-Control
- kein Jupyter-Server-Orchestrieren
- keine Live-Variableninspektion
- keine Zellausführung
- kein echtes Rerun-Verhalten
2. Es bearbeitet Zellen, schreibt aber weiterhin die Datei um
Die Notebook-Bearbeitung ist sauberer als ein roher Text-Patch. Claude Code kann Zellen einfügen, ersetzen oder löschen und alte Outputs zurücksetzen, wenn Code geändert wurde.
Das ist gutes Notebook-Datei-Handling, aber keine echte Jupyter-Runtime-Integration.
Claude Code versteht die Notebook-Datei, nicht die laufende Jupyter-Umgebung.
Warum das für Data Science wichtig ist
In Data Science ist nicht nur entscheidend, ob Python syntaktisch korrekt ist. Entscheidend ist:
- welche Zellen wann gelaufen sind
- welcher DataFrame aktuell gültig ist
- ob ein Plot auf alten oder neuen Daten basiert
- ob Upstream-Änderungen spätere Schritte unbemerkt brechen
Genau hier wirken generische Coding-Agents in Notebooks oft unvollständig.
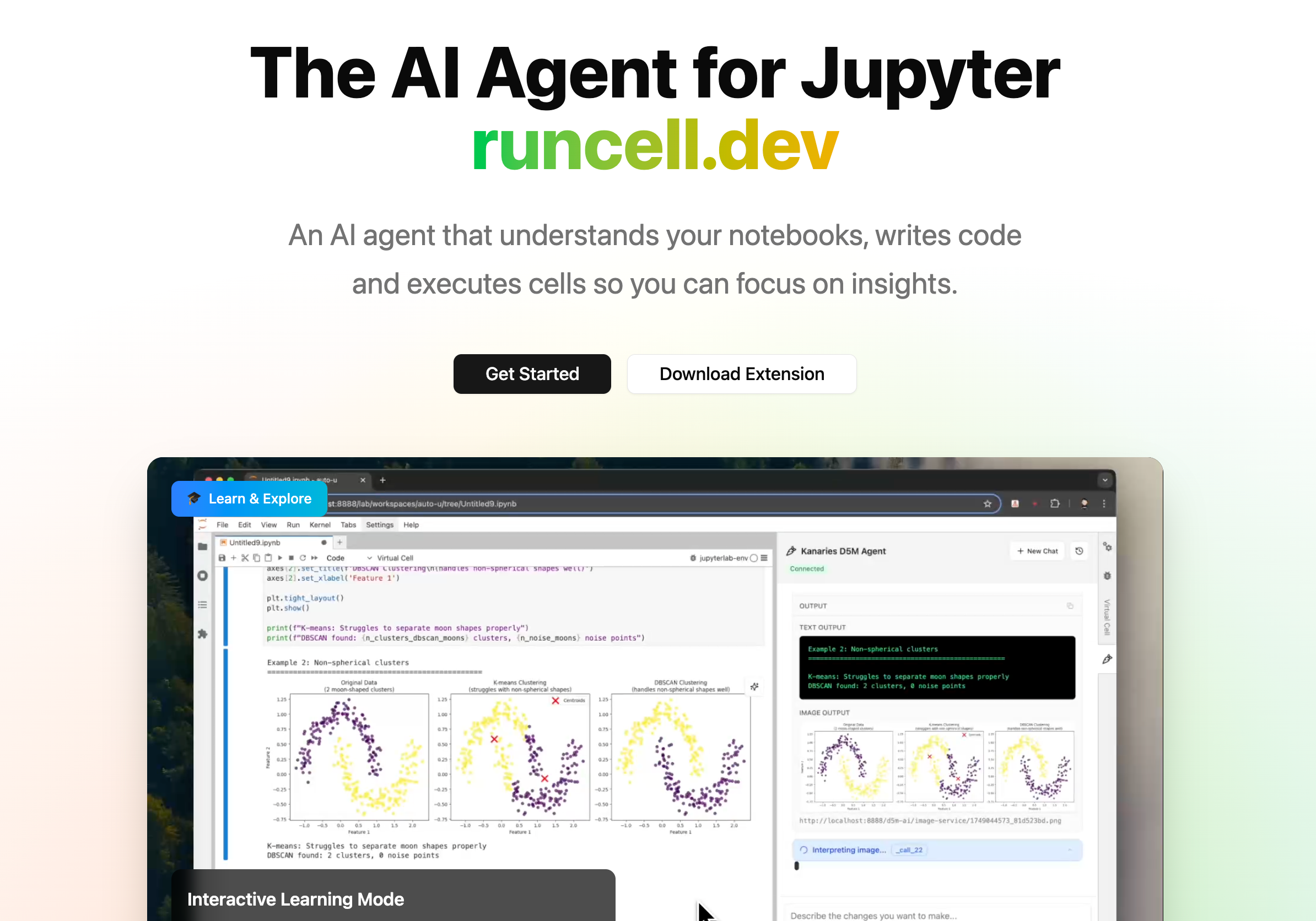
Warum RunCell besser zu Jupyter-Workflows passt
RunCell (opens in a new tab) ist hier interessant, weil das Problem für viele Notebook-Nutzer nie nur war: "Kann die KI den Code ändern?"
Der eigentliche Frust sieht oft so aus:
- das Notebook ist schon halb durchgelaufen und man muss erst wieder verstehen, welche Zellen noch gültig sind
- der Plot auf dem Bildschirm sieht richtig aus, aber niemand weiß sofort, ob er wirklich auf den neuesten Daten basiert
- eine kleine Schema-Änderung weiter oben kann viele spätere Zellen mitreißen
- der Agent schreibt Code um, weiß aber nicht unbedingt, an welchem Punkt der Analyse du gerade wirklich stehst
Genau deshalb wirken generische Coding-Agents in Jupyter oft fast richtig, aber nicht ganz. Sie lesen die Datei, aber nicht immer die reale Situation im Notebook.
RunCell ist kein allgemeines KI-Coding-Tool, das nebenbei .ipynb öffnen kann. Es ist ein JupyterLab-KI-Agent für Data Science und Notebook-Arbeit. Praktisch heißt das: weniger Hin-und-her zwischen Ansichten, weniger manuelles Zurückspringen durch Zellen und weniger Rätselraten, ob der aktuelle Output überhaupt noch zum aktuellen Stand der Analyse passt.
| Bedarf | Claude Code | RunCell |
|---|---|---|
| Notebook-Dateien lesen und ändern | Ja | Ja |
| Mit Notebook-Status arbeiten | Begrenzt | Nativ |
| DataFrames und Zellen als Kernsignal nutzen | Begrenzt | Stärker |
| Analysen direkt aus Outputs weiterführen | Indirekt | Direkt |
| Für Data-Science-Notebooks gebaut | Eher allgemein | Klar spezialisiert |
Wenn du Notebooks vor allem prüfen und umstrukturieren willst, reicht Claude Code oft aus.
Wenn dein Alltag aber eher so aussieht:
- EDA
- Datenbereinigung
- Feature Engineering
- Modell-Tuning
- Diagramme prüfen und Notebook-Fehler Schritt für Schritt ausräumen
dann fühlt sich RunCell meist natürlicher an. Das Ziel ist nicht nur, "den Code richtig zu machen", sondern die Analyse ohne Reibung weiterzuführen.
Wenn du das kennst, ist der Unterschied schnell greifbar: Der Agent kann die .ipynb bearbeiten, aber danach musst du trotzdem selbst Outputs prüfen, Variablen kontrollieren und Zellen neu ausführen, bevor du dem Ergebnis traust. Genau an diesem Punkt ist RunCell (opens in a new tab) meist der natürlichere nächste Schritt.