PyGWalker Dokumentation
Eine Python-Bibliothek für explorative Datenanalyse mit Visualisierung - PyGWalker
PyGWalker (opens in a new tab) kann Ihren Workflow zur Datenanalyse und Datenvisualisierung in Jupyter Notebook vereinfachen, indem es Ihr Pandas-Dataframe in eine interaktive Benutzeroberfläche für visuelle Exploration umwandelt.
PyGWalker (ausgesprochen wie "Pig Walker", einfach zum Spaß) wurde als Abkürzung von "Python binding of Graphic Walker" benannt. Es integriert Jupyter Notebook mit Graphic Walker (opens in a new tab), einer Open-Source-Alternative zu Tableau. Es ermöglicht Datenwissenschaftlern, die Daten mit einfachen Drag-and-Drop-Operationen und sogar natürlichen Sprachabfragen zu visualisieren, zu bereinigen und zu annotieren.
AI Agent In Jupyter Notebook
Let runcell AI take control of your notebook — automatically executing cells and completing complex data workflows while you focus on insights.
Besuchen Sie Google Colab (opens in a new tab), Kaggle Code (opens in a new tab) oder Graphic Walker Online Demo (opens in a new tab), um es auszuprobieren!
Wenn Sie lieber R verwenden, überprüfen Sie GWalkR (opens in a new tab), den R-Wrapper von Graphic Walker.
Erste Schritte
| In Kaggle ausführen (opens in a new tab) | In Colab ausführen (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 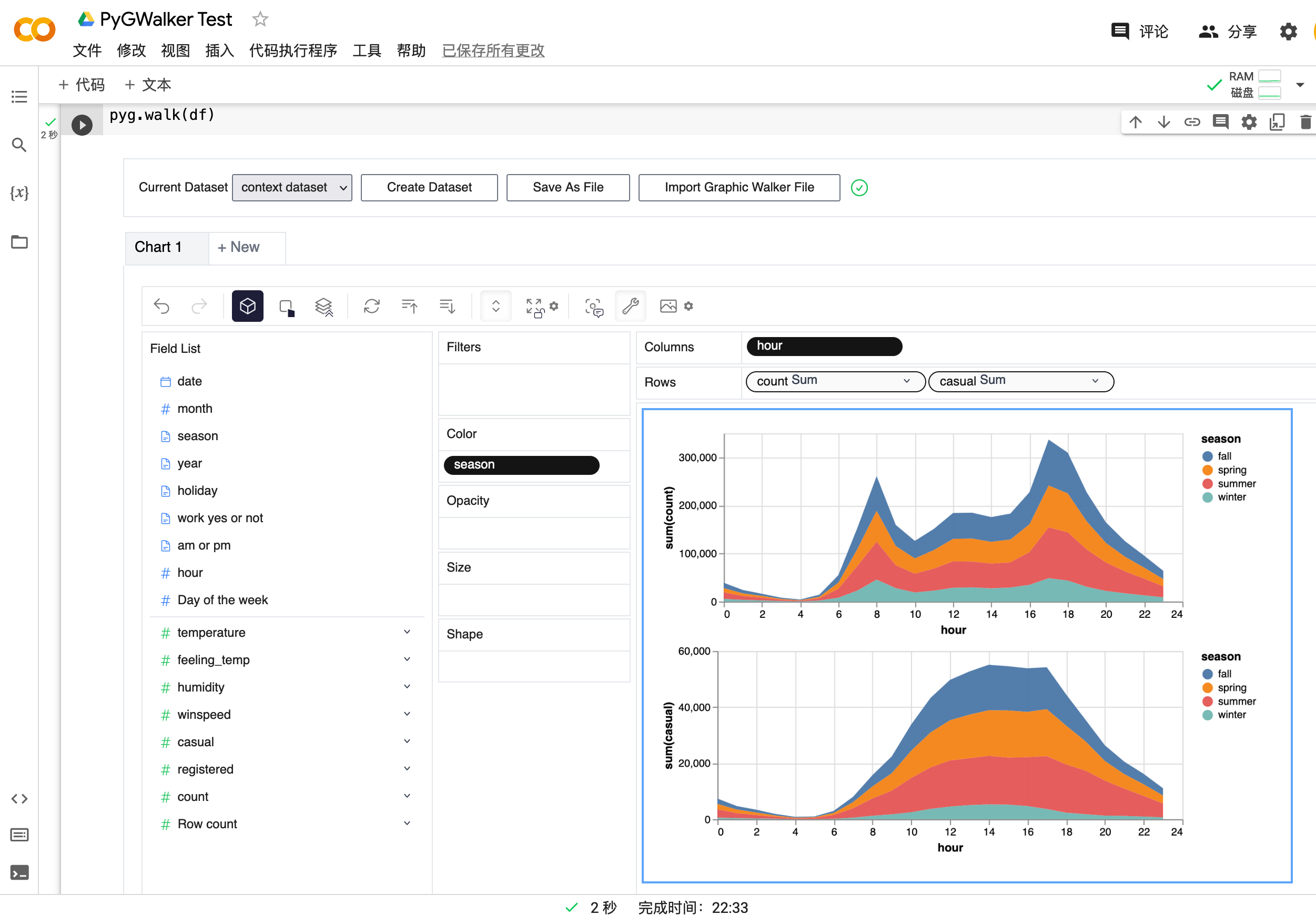 (opens in a new tab) (opens in a new tab) |
PyGWalker einrichten
Bevor Sie PyGWalker verwenden, stellen Sie sicher, dass Sie die Pakete über die Befehlszeile mit pip oder conda installieren.
pip
pip install pygwalkerHinweis
Für einen frühen Test können Sie mit
pip install pygwalker --upgradeinstallieren, um Ihre Version auf dem neuesten Stand mit dem neuesten Release zu halten, oder sogarpip install pygwaler --upgrade --pre, um die neuesten Funktionen und Fehlerkorrekturen zu erhalten.
Conda-forge
conda install -c conda-forge pygwalkeroder
mamba install -c conda-forge pygwalkerSehen Sie das Conda-Forge-Feedstock (opens in a new tab) für weitere Hilfe.
Verwendung von PyGWalker in Jupyter Notebook
Schnellstart
Importieren Sie pygwalker und Pandas in Ihr Jupyter Notebook, um loszulegen.
import pandas as pd
import pygwalker as pygSie können PyGWalker verwenden, ohne Ihren bestehenden Workflow zu unterbrechen. Sie können beispielsweise PyGWalker mit dem geladenen Dataframe aufrufen:
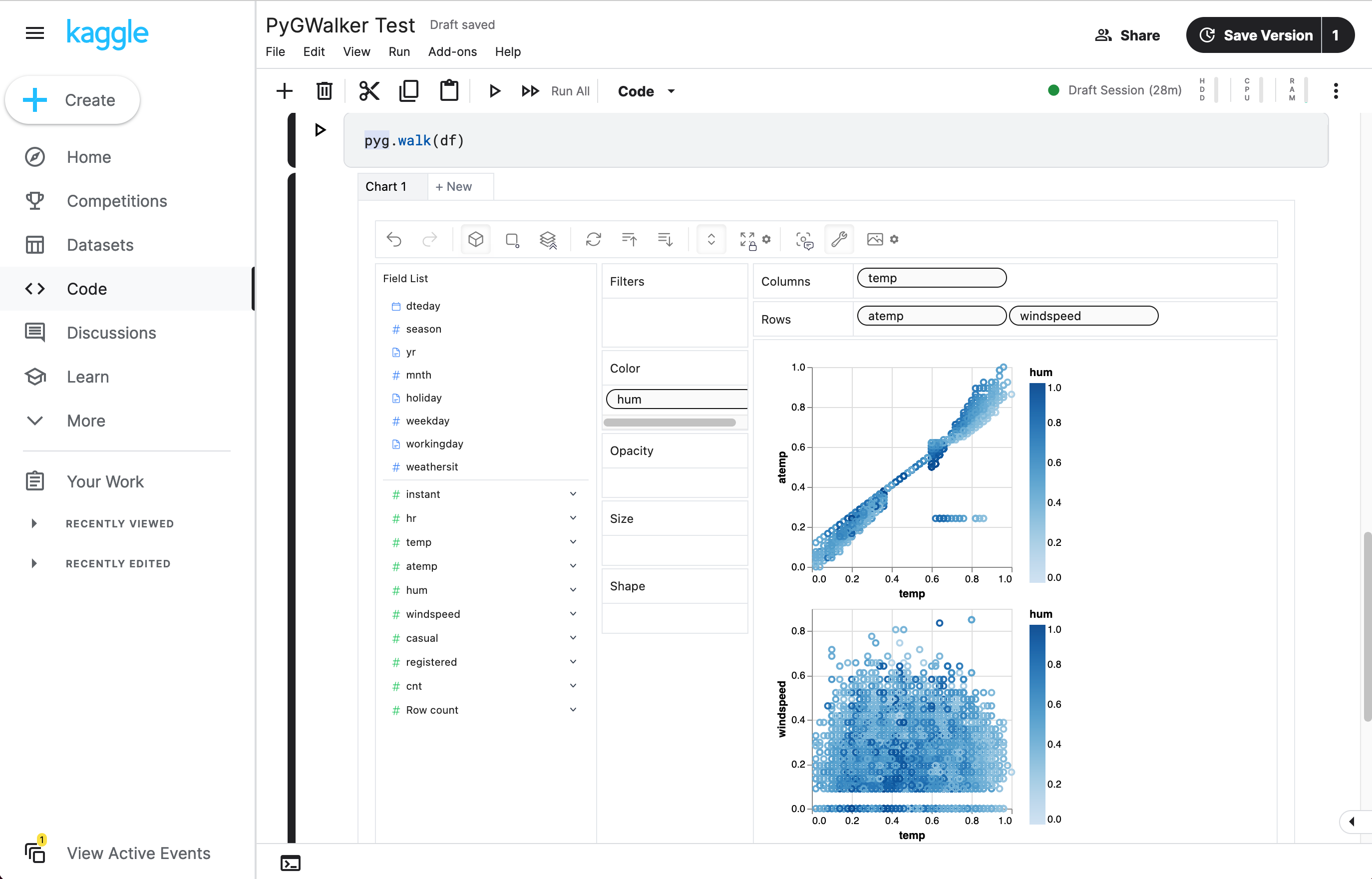
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(df)So haben Sie nun eine interaktive Benutzeroberfläche, um Daten mit einfachen Drag-and-Drop-Operationen zu analysieren und visualisieren.
Cool Dinge, die Sie mit PyGWalker tun können:
-
Sie können den Markentyp in andere ändern, um verschiedene Diagramme zu erstellen, zum Beispiel ein Liniendiagramm:

-
Um verschiedene Maße zu vergleichen, können Sie eine Konkatinierung in Ansichten erstellen, indem Sie mehr als ein Maß in Zeilen/Spalten hinzufügen.

-
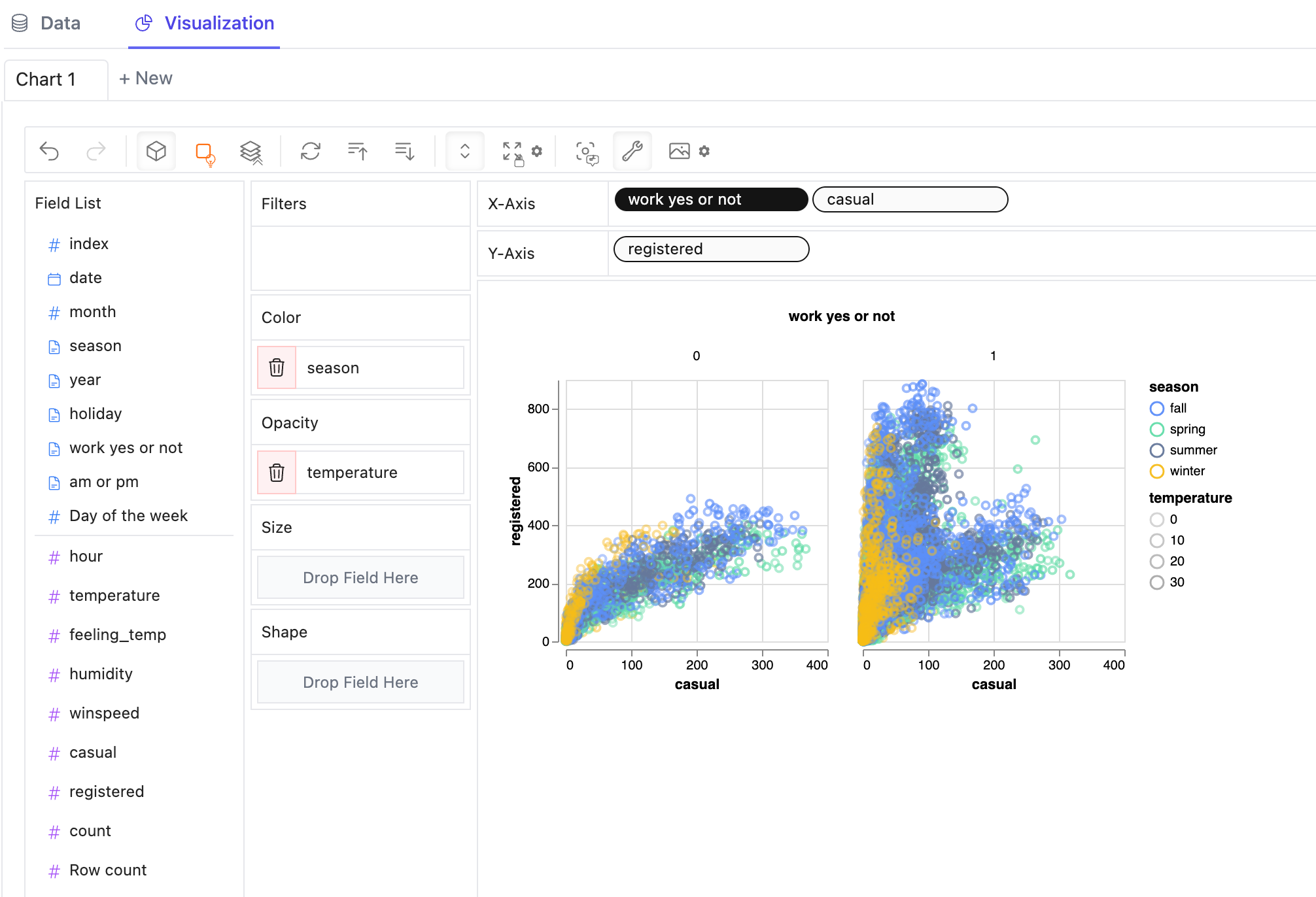
Um eine Facettenansicht von mehreren Unteransichten zu erstellen, die durch den Wert in der Dimension unterteilt sind, setzen Sie Dimensionen in Zeilen oder Spalten, um eine Facettenansicht zu erstellen.
-
PyGWalker enthält eine leistungsstarke Daten-Tabelle, die einen schnellen Überblick über Daten und deren Verteilung, Profilierung bietet. Sie können auch Filter hinzufügen oder die Datentypen in der Tabelle ändern.
- Sie können das Ergebnis der Datenexploration in einer lokalen Datei speichern
Beste Praktiken
Es gibt einige wichtige Parameter, die Sie kennen sollten, wenn Sie pygwalker verwenden:
spec: für Speichern/Laden von Diagrammkonfigurationen (JSON-Zeichenfolge oder Dateipfad)kernel_computation: für die Verwendung von DuckDB als Rechenmotor, der es Ihnen ermöglicht, größere Datensätze schneller auf Ihrem lokalen Rechner zu verarbeiten.kernel_computation: Veraltet, verwenden Sie stattdessenkernel_computation.
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(
df,
spec="./chart_meta_0.json", # Diese JSON-Datei speichert Ihren Diagrammzustand. Sie müssen auf die Schaltfläche Speichern in der Benutzeroberfläche klicken, wenn Sie ein Diagramm fertigstellen. 'Automatisches Speichern' wird in Zukunft unterstützt.
kernel_computation=True, # Setzen Sie `kernel_computation=True`, verwendet pygwalker DuckDB als Rechenmotor. Es ermöglicht Ihnen, größere Datensätze zu erkunden (<=100GB).
)Beispiel im lokalen Notebook
- Notebook-Code: Klicken Sie hier (opens in a new tab)
- Vorschau des Notebook-Html: Klicken Sie hier (opens in a new tab)
Beispiel im Cloud-Notebook
- Verwenden von PyGWalker in Kaggle (opens in a new tab)
- Verwenden von PyGWalker in Google Colab (opens in a new tab)
Verwendung von PyGWalker in Streamlit
Streamlit ermöglicht es Ihnen, eine Webversion von PyGWalker zu hosten, ohne sich mit den Details der Funktionsweise von Webanwendungen beschäftigen zu müssen.
Hier sind einige App-Beispiele, die mit PyGWalker und Streamlit erstellt wurden:
- PyGWalker + Streamlit für das Bike-Sharing-Datenset (opens in a new tab)
- Erdbeben-Dashboard (opens in a new tab)

from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Passen Sie die Breite der Streamlit-Seite an
st.set_page_config(
page_title="Pygwalker in Streamlit verwenden",
layout="wide"
)
# Titel hinzufügen
st.title("Pygwalker in Streamlit verwenden")
# Sie sollten Ihren pygwalker-Renderer zwischenspeichern, wenn Sie nicht möchten, dass Ihr Speicher explodiert
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# Wenn Sie die Funktion zum Speichern der Diagrammkonfiguration verwenden möchten, setzen Sie `spec_io_mode="rw"`
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()API-Referenz (opens in a new tab)
pygwalker.walk (opens in a new tab)
| Parameter | Typ | Standardwert | Beschreibung |
|---|---|---|---|
| dataset | Union[DataFrame, Connector] | - | Der Dataframe oder Connector, der verwendet werden soll. |
| gid | Union[int, str] | None | ID für das GraphicWalker-Container-Div, im Format gwalker-\{gid\}. |
| env | Literal['Jupyter', 'JupyterWidget'] | 'JupyterWidget' | Umgebung, die pygwalker verwendet. |
| field_specs | Optional[Dict[str, FieldSpec]] | None | Spezifikationen von Feldern. Wird automatisch aus dataset abgeleitet, wenn nicht angegeben. |
| hide_data_source_config | bool | True | Wenn True, werden die Schaltfläche zum Importieren und Exportieren von Datenquellen ausgeblendet. |
| theme_key | Literal['vega', 'g2'] | 'g2' | Thementyp für den GraphicWalker. |
| appearance | Literal['media', 'light', 'dark'] | 'media' | Themeneinstellung. 'media' erkennt das Betriebssystem-Theme automatisch. |
| spec | str | "" | Konfigurationsdaten des Diagramms. Kann eine Konfigurations-ID, JSON oder eine URL zu einer Remote-Datei sein. |
| use_preview | bool | True | Wenn True, wird die Vorschau-Funktion verwendet. |
| kernel_computation | bool | False | Wenn True, wird die Kernel-Berechnung für Daten verwendet. |
| **kwargs | Any | - | Zusätzliche Schlüsselwortargumente. |
Getestete Umgebungen
- Jupyter Notebook
- Google Colab
- Kaggle Code
- Jupyter Lab
- Jupyter Lite
- Databricks Notebook (Seit Version
0.1.4a0) - Jupyter-Erweiterung für Visual Studio Code (Seit Version
0.1.4a0) - Die meisten Webanwendungen, die mit IPython-Kernels kompatibel sind. (Seit Version
0.1.4a0) - Streamlit (Seit Version
0.1.4.9), aktiviert mitpyg.walk(df, env='Streamlit') - DataCamp-Arbeitsbereich (Seit Version
0.1.4a0) - Hex-Projekte
- ...fühlen Sie sich frei, eine Anfrage für weitere Umgebungen zu stellen.
Konfiguration und Datenschutzrichtlinie (PyGWalker >= 0.3.10)
Sie können pygwalker config verwenden, um Ihre Datenschutzeinstellungen zu konfigurieren.
$ pygwalker config --help
Verwendung: pygwalker config [-h] [--set [Schlüssel=Wert ...]] [--reset [Schlüssel ...]] [--reset-all] [--list]
Konfigurationsdatei ändern. (Standard: ~/Library/Application Support/pygwalker/config.json)
Verfügbare Konfigurationen:
- privacy ['offline', 'update-only', 'events'] (Standard: events).
"offline": vollständig offline, es werden keine Daten gesendet oder APIs angefordert
"update-only": nur Überprüfung, ob dies eine neue Version von PyGWalker zum Aktualisieren ist
"events": Teilen von Ereignissen, welche Funktionen in PyGWalker verwendet werden, enthält nur Ereignisdaten darüber, welche Funktion Sie für die Produktoptimierung verwenden. Es werden keine von Ihnen analysierten DATEN gesendet. Ereignisdaten werden mit einer eindeutigen ID verbunden, die von PyGWalker generiert wird, wenn es basierend auf dem Zeitstempel installiert wird. Wir werden keine anderen Informationen über Sie sammeln.
- kanaries_token ['Ihr kanaries token'] (Standard: Leere Zeichenfolge).
Ihr Kanaries-Token, das Sie von https://kanaries.net erhalten können.
Siehe: https://space.kanaries.net/t/how-to-get-api-key-of-kanaries.
Mit dem Kanaries-Token können Sie den Kanaries-Service in PyGWalker verwenden, z. B. Diagramm teilen, Konfiguration teilen.
Optionen:
-h, --help Diese Hilfe anzeigen und beenden
--set [Schlüssel=Wert ...]
Konfiguration setzen, z. B. "pygwalker config --set privacy=update-only"
--reset [Schlüssel ...] Benutzerkonfiguration zurücksetzen und Standardwerte verwenden, z. B. "pygwalker config --reset privacy"
--reset-all Alle Benutzerkonfigurationen zurücksetzen und Standardwerte verwenden, z. B. "pygwalker config --reset-all"
--list Liste der aktuellen verwendeten Konfiguration anzeigen.Weitere Einzelheiten finden Sie hier: So setzen Sie Ihre Datenschutzeinstellungen? (opens in a new tab)
Lizenz
Apache License 2.0 (opens in a new tab)
Ressourcen
PyGWalker Cloud ist veröffentlicht! Sie können jetzt Ihre Charts in der Cloud speichern, die interaktive Zelle als Web-App veröffentlichen und fortgeschrittene, auf GPT basierende Funktionen nutzen. Schauen Sie sich die PyGWalker Cloud (opens in a new tab) für weitere Details an.
- PyGWalker Paper PyGWalker: On-the-fly Assistant for Exploratory Visual Data Analysis (opens in a new tab)
- Weitere Ressourcen zu PyGWalker finden Sie unter Kanaries PyGWalker (opens in a new tab)
- Wir arbeiten auch an RATH (opens in a new tab): einer Open-Source-Software zur automatisierten explorativen Datenanalyse, die den Workflow der Datenaufbereitung, Exploration und Visualisierung mit KI-gestützter Automatisierung neu definiert. Besuchen Sie die Kanaries-Website (opens in a new tab) und RATH GitHub (opens in a new tab) für mehr Informationen!
- Verwenden von pygwalker zum Erstellen von visuellen Analyse-Apps in Streamlit (opens in a new tab)
- Wenn Sie auf Probleme stoßen und Unterstützung benötigen, treten Sie unserem Discord (opens in a new tab) bei oder stellen Sie ein Problem auf GitHub.