Wie man Pandas DataFrames in Python leicht zusammenführt, verbindet und konkateniert

Zusammenführen, Verbinden und Konkatenieren von DataFrames in Pandas sind wichtige Techniken, mit denen Sie mehrere Datensätze zu einem einzigen DataFrame kombinieren können. Diese Techniken sind essenziell für das Bereinigen, Transformieren und Analysieren von Daten. Zusammenführen, Verbinden und Konkatenieren werden oft synonym verwendet, beziehen sich jedoch auf verschiedene Methoden der Datenkombination. In diesem Beitrag werden wir diese drei wichtigen Techniken im Detail besprechen und Beispiele dafür geben, wie man sie in Python verwendet.
- Runcell Science: Open-Source-Alternative zu Claude Science für Forschungsteams
- Mac Ruhezustand verhindern: Codex, Claude Code und KI-Agenten weiterlaufen lassen
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: Welchen KI-Agenten-Stack sollten Sie 2026 wählen?
- Wie Claude Code Jupyter Notebooks analysiert: Data Science, Grenzen und die bessere Alternative
- Claude Code Routines: KI-Cronjobs für Agenten
- Claude Code Desktop: Bypass permissions aktivieren
- Schritt-für-Schritt-Anleitung zur Erstellung von zwei Python-Agenten mit Googles A2A-Protokoll
- Die Top 10 wachsenden Data Visualization Libraries in Python im Jahr 2025
Zusammenführen von DataFrames in Pandas
Zusammenführen ist der Prozess, bei dem zwei oder mehr DataFrames zu einem einzigen DataFrame kombiniert werden, indem Zeilen anhand eines oder mehrerer gemeinsamer Schlüssel verknüpft werden. Die gemeinsamen Schlüssel können eine oder mehrere Spalten sein, deren Werte in den zu verschmelzenden DataFrames übereinstimmen.
Unterschiedliche Arten von Zusammenführungen
Es gibt vier Arten von Zusammenführungen in Pandas: innere, äußere, linke und rechte.
- Innere Zusammenführung: Gibt nur die Zeilen zurück, die in beiden DataFrames übereinstimmende Werte haben.
- Äußere Zusammenführung: Gibt alle Zeilen aus beiden DataFrames zurück und füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
- Linke Zusammenführung: Gibt alle Zeilen aus dem linken DataFrame und die übereinstimmenden Zeilen aus dem rechten DataFrame zurück. Füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
- Rechte Zusammenführung: Gibt alle Zeilen aus dem rechten DataFrame und die übereinstimmenden Zeilen aus dem linken DataFrame zurück. Füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
Beispiele für verschiedene Arten von Zusammenführungen
Schauen wir uns einige Beispiele für verschiedene Arten von Zusammenführungen mit Pandas an.
Beispiel 1: Innere Zusammenführung
import pandas as pd
# Zwei DataFrames erstellen
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Innere Zusammenführung
merged_inner = pd.merge(df1, df2, on='key')
print(merged_inner)Ausgabe:
key value_x value_y
0 B 2 5
1 D 4 6Beispiel 2: Äußere Zusammenführung
import pandas as pd
# Zwei DataFrames erstellen
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Äußere Zusammenführung
merged_outer = pd.merge(df1, df2, on='key', how='outer')
print(merged_outer)Ausgabe:
key value_x value_y
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0Beispiel 3: Linke Zusammenführung
Eine linke Zusammenführung gibt alle Zeilen aus dem linken DataFrame und die übereinstimmenden Zeilen aus dem rechten DataFrame zurück. Zeilen aus dem linken DataFrame, die keine Übereinstimmung im rechten DataFrame haben, werden mit NaN-Werten in den Spalten des rechten DataFrames gefüllt.
import pandas as pd
# Zwei DataFrames erstellen
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# Linke Zusammenführung durchführen
left_merged_df = pd.merge(df1, df2, on='key', how='left')
# Den zusammengeführten DataFrame ausgeben
print(left_merged_df)Ausgabe:
key value_x value_y
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0Beispiel 4: Rechte Zusammenführung
Eine rechte Zusammenführung gibt alle Zeilen aus dem rechten DataFrame und die übereinstimmenden Zeilen aus dem linken DataFrame zurück. Zeilen aus dem rechten DataFrame, die keine Übereinstimmung im linken DataFrame haben, werden mit NaN-Werten in den Spalten des linken DataFrames gefüllt.
import pandas as pd
# Zwei DataFrames erstellen
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# Rechte Zusammenführung durchführen
right_merged_df = pd.merge(df1, df2, on='key', how='right')
# Den zusammengeführten DataFrame ausgeben
print(right_merged_df)Ausgabe:
key value_x value_y
0 B 2.0 5
1 D NaN 6
2 E NaN 7Verbinden von DataFrames in Pandas
Verbinden ist eine Methode, um zwei DataFrames basierend auf ihren Index- oder Spaltenwerten zu einem einzigen DataFrame zusammenzuführen.
In Pandas gibt es vier Arten von Verbindungen: innere, äußere, linke und rechte.
- Innere Verbindung: Gibt nur die Zeilen zurück, die übereinstimmende Index- oder Spaltenwerte in beiden DataFrames haben.
- Äußere Verbindung: Gibt alle Zeilen aus beiden DataFrames zurück und füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
- Linke Verbindung: Gibt alle Zeilen aus dem linken DataFrame und die übereinstimmenden Zeilen aus dem rechten DataFrame zurück. Füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
- Rechte Verbindung: Gibt alle Zeilen aus dem rechten DataFrame und die übereinstimmenden Zeilen aus dem linken DataFrame zurück. Füllt fehlende Werte mit NaN auf, wo keine Übereinstimmung besteht.
Konkatenieren von DataFrames in Pandas
Konkatenieren ist der Prozess des Zusammenfügens von zwei oder mehr DataFrames vertikal oder horizontal. In Pandas kann dies mit der Funktion concat() erreicht werden. Mit der Funktion concat() können Sie zwei oder mehr DataFrames zu einem einzigen DataFrame kombinieren, indem Sie sie entweder vertikal oder horizontal stapeln.
Beispiele zum Konkatenieren von zwei oder mehr DataFrames mit Pandas
Um zwei oder mehr DataFrames vertikal zu verketten, können Sie den folgenden Code verwenden:
import pandas as pd
# Erstellen Sie zwei Beispieldatenframes
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
# Verketten Sie die DataFrames vertikal
result = pd.concat([df1, df2])
print(result)Ausgabe:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7Um zwei oder mehr DataFrames horizontal zu verketten, können Sie den folgenden Code verwenden:
import pandas as pd
# Erstellen Sie zwei Beispieldatenframes
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'E': ['E0', 'E1', 'E2', 'E3'],
'F': ['F0', 'F1', 'F2', 'F3'],
'G': ['G0', 'G1', 'G2', 'G3'],
'H': ['H0', 'H1', 'H2', 'H3']})
# Verketten Sie die DataFrames horizontal
result = pd.concat([df1, df2], axis=1)
print(result)Ausgabe:
A B C D E F G H
0 A0 B0 C0 D0 E0 F0 G0 H0
1 A1 B1 C1 D1 E1 F1 G1 H1
2 A2 B2 C2 D2 E2 F2 G2 H2Erstellen Sie eine Concat View für Panda-Dataframes
Zur Erstellung von Concat Views in Python gibt es ein Open Source Data Analysis & Data Visualization-Paket, mit dem Sie gut arbeiten können: PyGWalker.
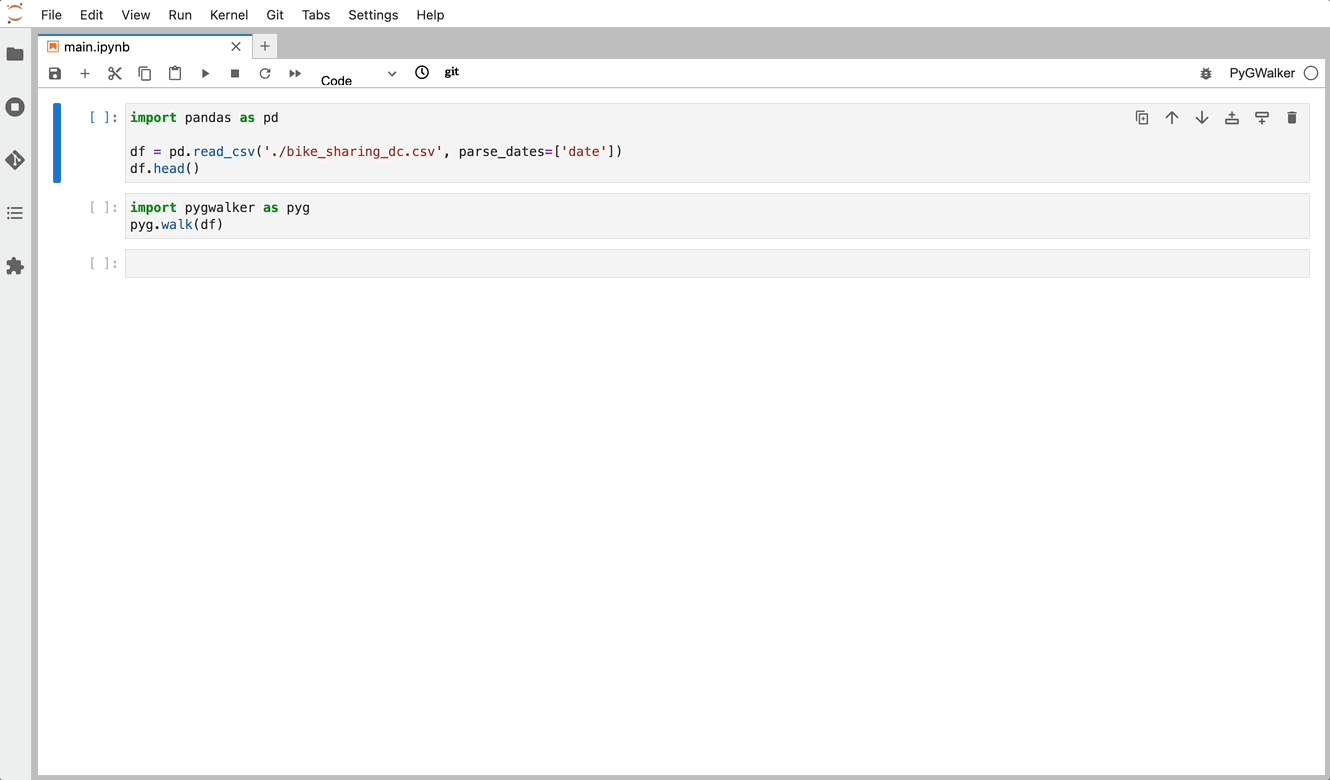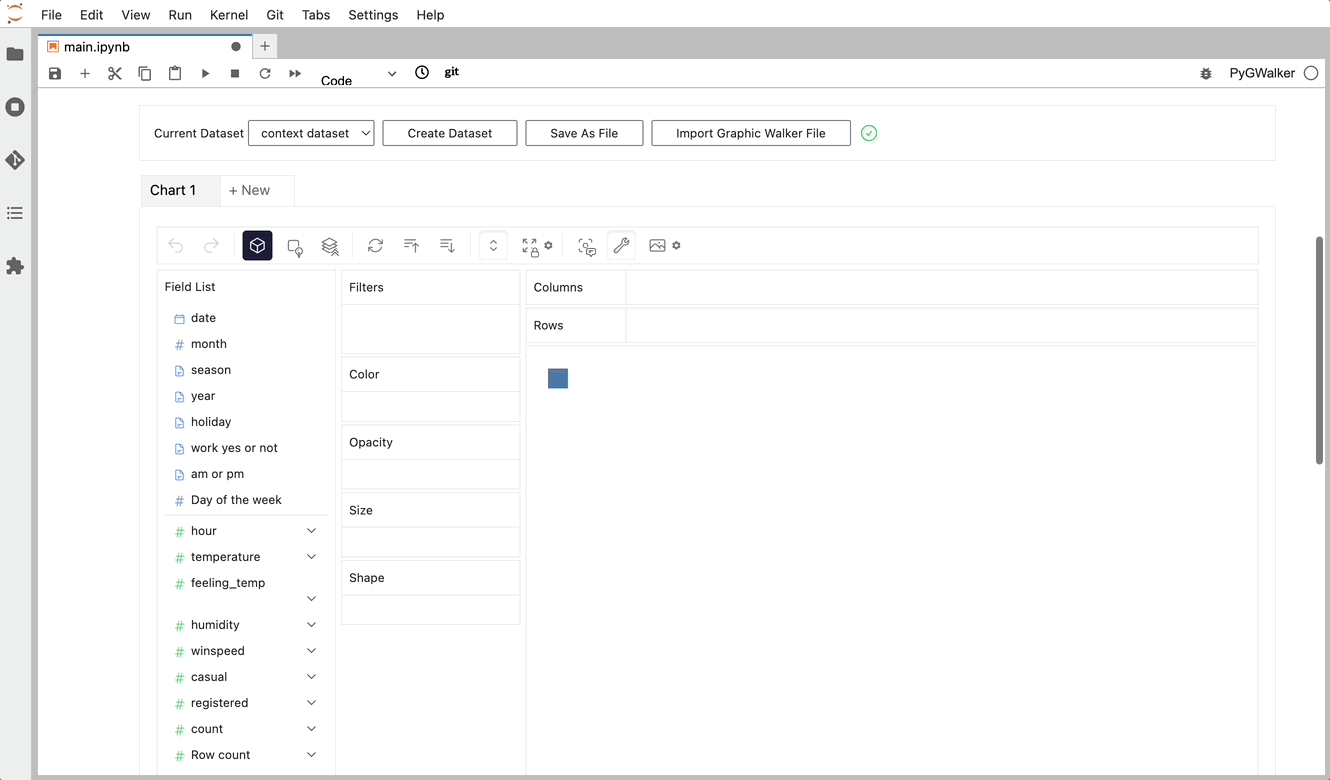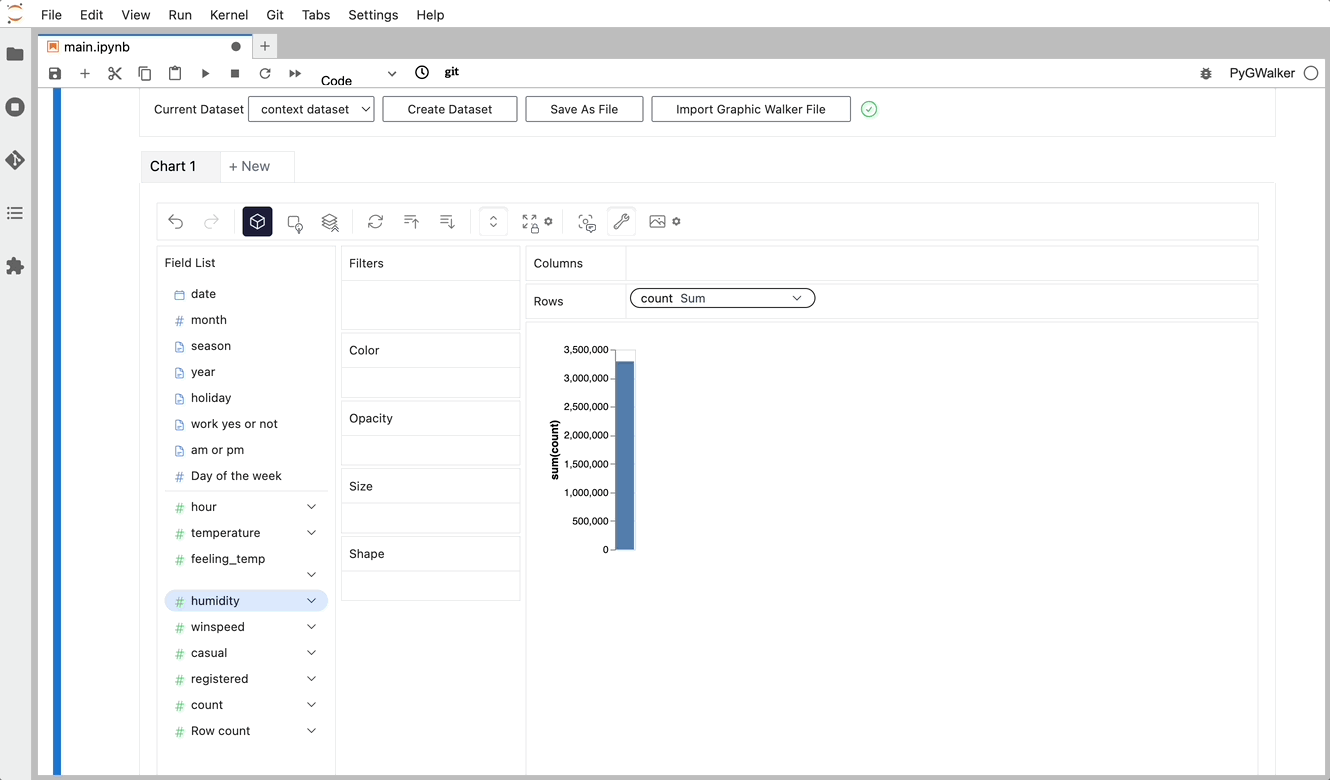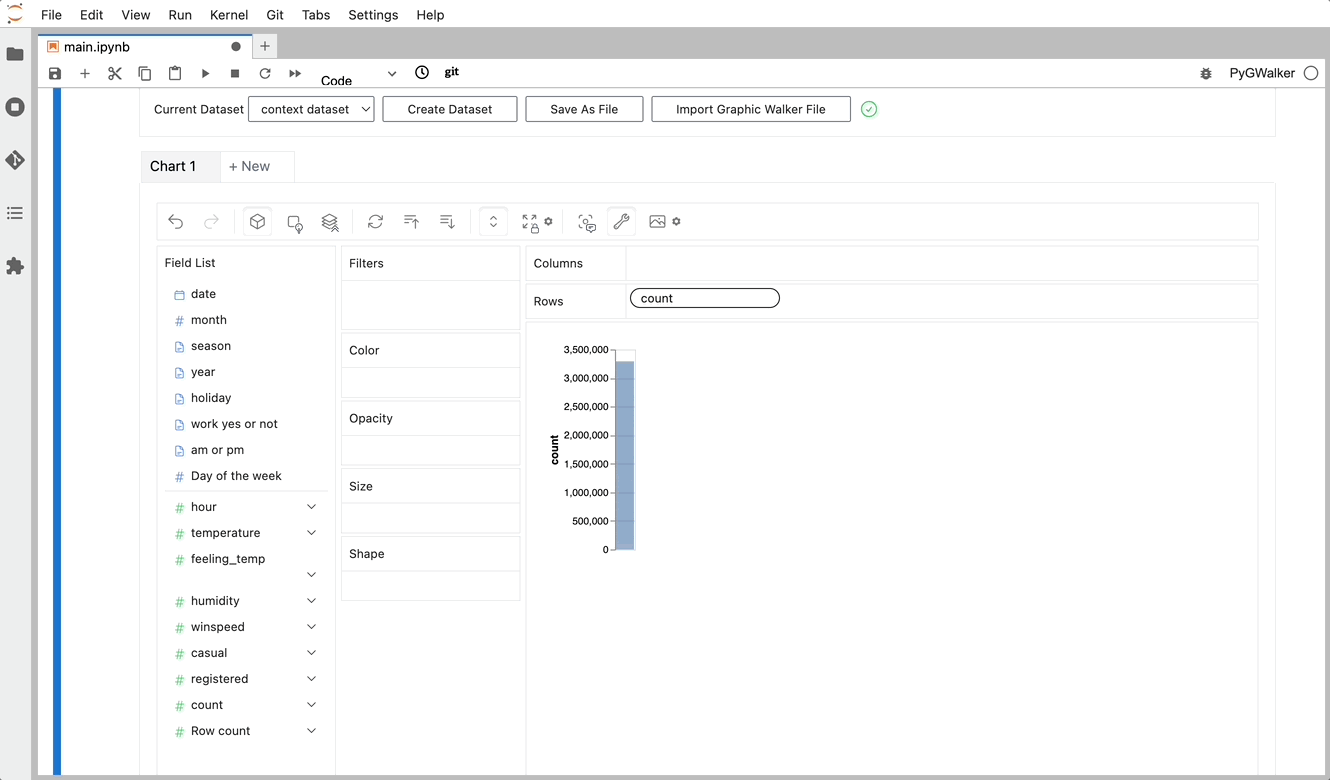
PyGWalker kann Ihren Jupyter Notebook-Workflow für Datenanalyse und Datenvisualisierung vereinfachen. Es bietet eine leichte, benutzerfreundliche Oberfläche anstelle der Analyse von Daten mit Python. Die Schritte sind einfach:
Importieren Sie pygwalker und pandas in Ihr Jupyter Notebook, um zu beginnen.
import pandas as pd
import pygwalker as pygSie können pygwalker verwenden, ohne Ihren bestehenden Workflow zu ändern. Sie können beispielsweise Graphic Walker mit dem geladenen Dataframe aufrufen:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Jetzt können Sie Ihr Pandas Dataframe mit einer benutzerfreundlichen Benutzeroberfläche visualisieren!
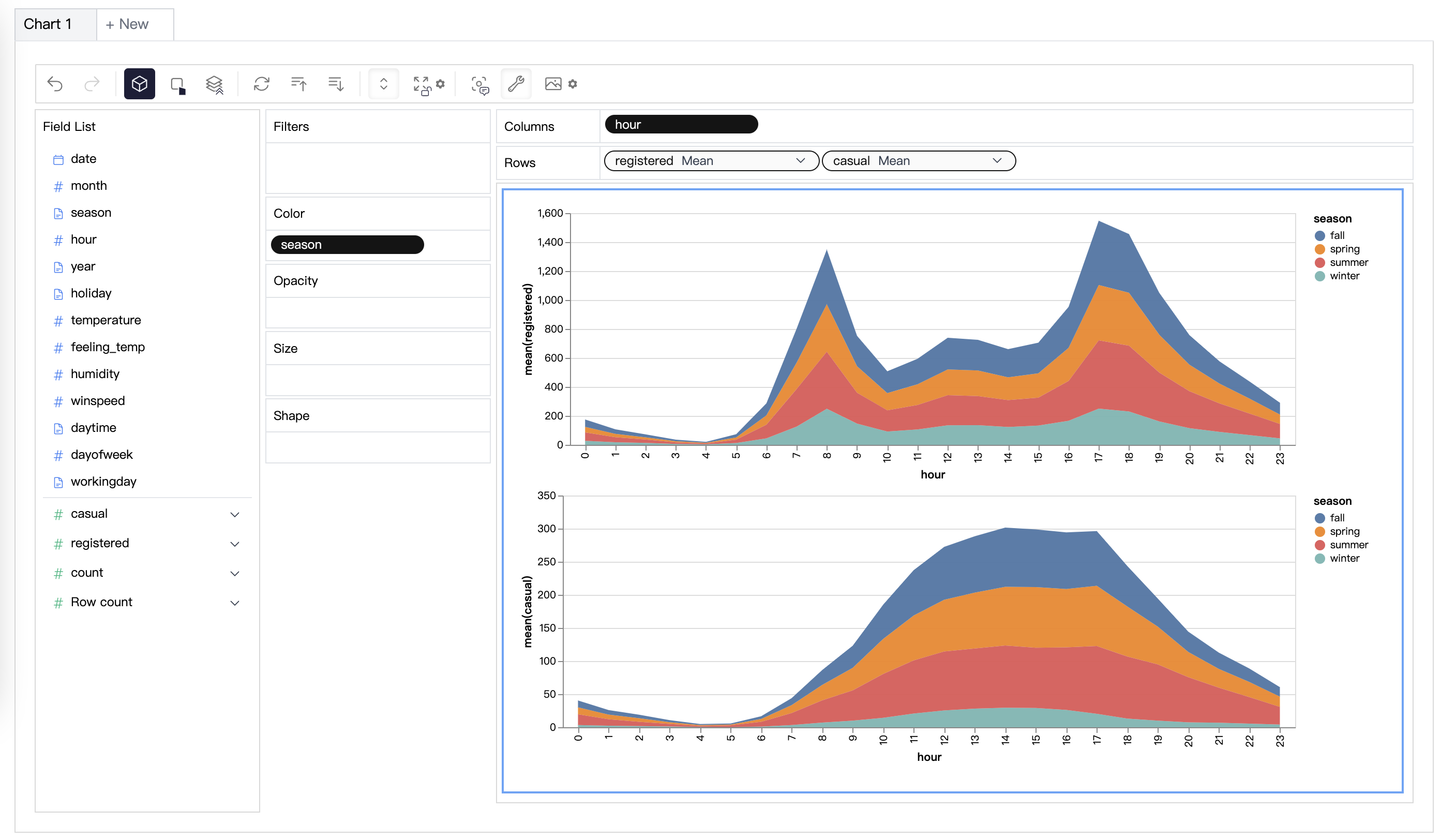
Sie können ganz einfach eine Concat View erstellen, indem Sie Variablen per Drag & Drop ziehen und ablegen:
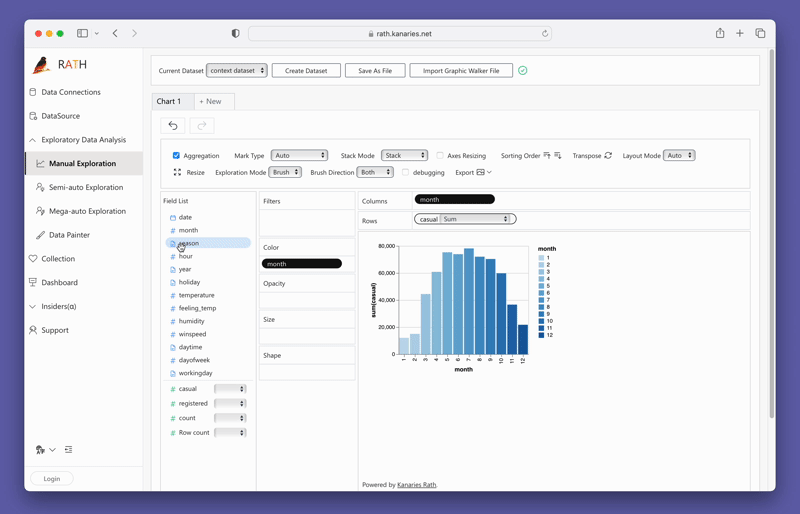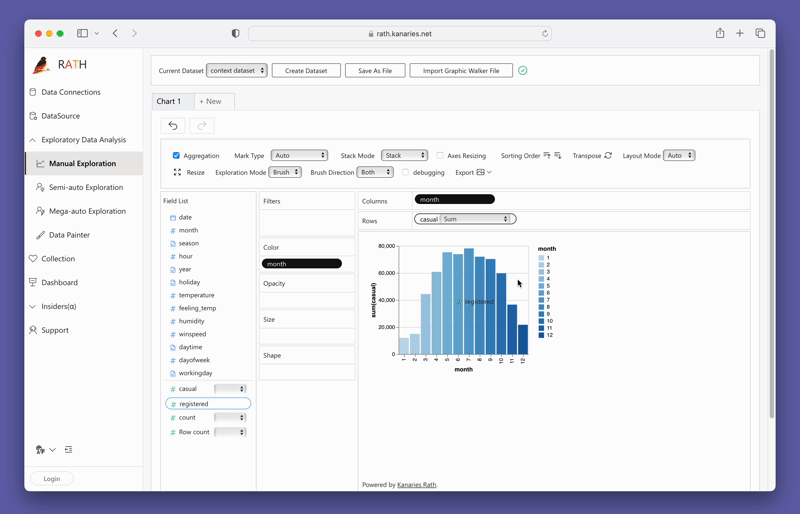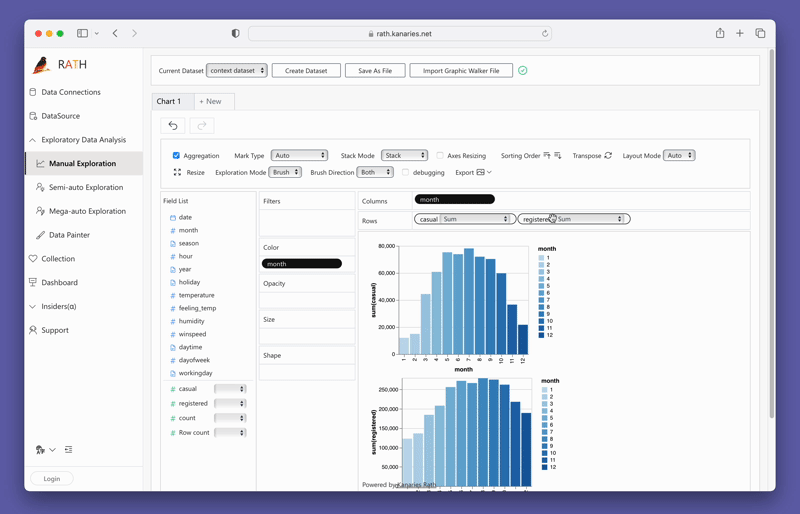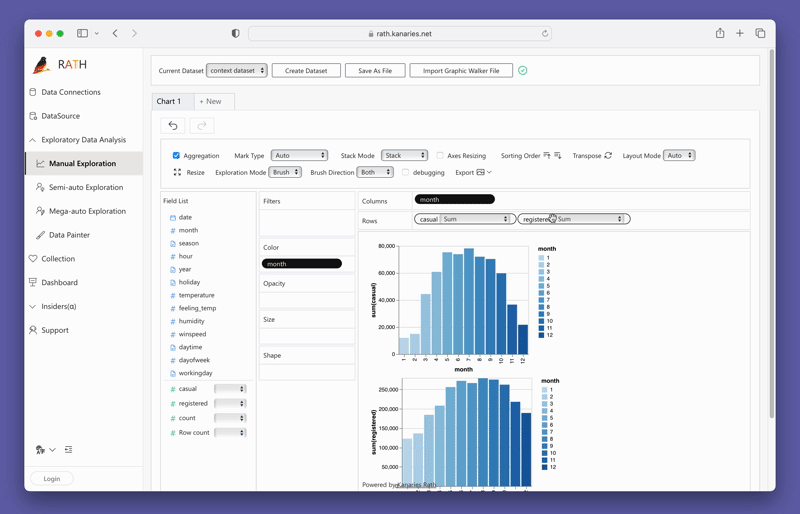
Um PyGWalker jetzt zu testen, können Sie PyGWalker in Google Colab (opens in a new tab), Binder (opens in a new tab) oder Kaggle (opens in a new tab) ausführen.
PyGWalker ist Open Source. Sie können die PyGWalker GitHub-Seite (opens in a new tab) überprüfen und den Towards Data Science-Artikel (opens in a new tab) dazu lesen.
Vergessen Sie nicht, auch ein fortgeschrittenes, KI-unterstütztes automatisiertes Datenanalyse-Tool auszuprobieren: RATH (opens in a new tab). RATH ist ebenfalls Open Source und hat seinen Quellcode auf GitHub (opens in a new tab) gehostet.
FAQ
Wie kann ich zwei DataFrames mit PySpark verbinden?
PySpark ist ein Open-Source-Framework zur Verarbeitung großer Datenmengen, mit dem Sie Datenverarbeitungsanwendungen in Python, Java, Scala oder R schreiben können. Um zwei DataFrames mit PySpark zu verbinden, können Sie die Methode join() verwenden, die zwei DataFrame-Objekte und einen optionalen Join-Ausdruck annimmt. Sie können den Join-Typ mit dem Parameter how festlegen.
Wie kann ich zwei DataFrames mit R zusammenführen?
Um zwei DataFrames mit R zusammenzuführen, können Sie die Funktion merge() verwenden, die zwei Datenframes und eine optionale Reihe von Argumenten annimmt, die angeben, wie die Daten zusammengeführt werden sollen.
Wie kann ich zwei oder mehr DataFrames in pandas anhängen?
Um zwei oder mehr DataFrames in Pandas anzuhängen, können Sie die Funktion concat() verwenden, die eine Liste von DataFrames und einen optionalen Achsenparameter annimmt, der die Achse angibt, entlang der die DataFrames zusammengefügt werden sollen.
Wie kann ich zwei DataFrames basierend auf einer gemeinsamen Spalte mit pandas verbinden?
Um zwei DataFrames basierend auf einer gemeinsamen Spalte mit pandas zu verbinden, können Sie die Funktion merge() verwenden, die zwei DataFrames und eine optionale Reihe von Argumenten annimmt, die angeben, wie die Daten zusammengeführt werden sollen. Sie können die Spalte, anhand derer Sie verknüpfen möchten, mit dem on-Parameter angeben.
Fazit
Zusammenführen, Verknüpfen und Verketten von DataFrames sind wesentliche Operationen bei der Datenanalyse. Mit Hilfe leistungsstarker Tools wie pandas, PySpark und R können diese Operationen einfach und effizient durchgeführt werden. Egal ob Sie mit großen oder kleinen Datensätzen arbeiten, diese Tools bieten flexible und intuitive Möglichkeiten zur Manipulation Ihrer Daten.