Entdecken Sie Netflix-Daten mit PyGWalker
Netflix zeichnet sich als führende Plattform für Filme und TV-Sendungen aus. Mit einer ständig wachsenden Bibliothek wird das Verständnis der Trends und Muster des Inhalts für Analysten, Filmemacher und sogar Zuschauer entscheidend. In diesem Notebook werden wir mit der PyGWalker-Bibliothek tief in den Netflix-Datensatz eintauchen, einem leistungsstarken Tool für die Datenvisualisierung und -exploration.
Was ist PyGWalker?
PyGWalker (opens in a new tab) ist eine Python-Bibliothek, die entwickelt wurde, um den Prozess der Datenvisualisierung zu vereinfachen. Es ermöglicht Benutzern, interaktive Diagramme mit minimalem Code zu erstellen, um Erkenntnisse und Muster in Datensätzen schneller zu entdecken.

Mit PyGWalker können wir aussagekräftige Visualisierungen generieren, die ein klareres Verständnis der Netflix-Inhaltslandschaft bieten.
Schritte zur Erkundung von Netflix-Daten mit PyGWalker
Einrichtung der Umgebung
Um loszulegen, müssen wir sicherstellen, dass unsere Umgebung für die Analyse vorbereitet ist. Dazu gehört die Installation der PyGWalker-Bibliothek und das Importieren der erforderlichen Python-Pakete.
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Netflix-Datensatz laden und vorverarbeiten
Unsere erste Aufgabe besteht darin, den Netflix-Datensatz zu laden. Nach dem Laden werden wir den Datensatz zur einfacheren Analyse vorverarbeiten. Diese Vorverarbeitung beinhaltet:
- Konvertierung der Spalte "date_added" in ein Datumsformat.
- Extrahieren des Jahres und des Monats aus der Spalte "date_added".
- Bereinigung der "duration"-Spalte, um entweder die Gesamtzahl der Minuten für Filme oder die Anzahl der Staffeln für TV-Sendungen darzustellen.
- Filtern der Daten nach 2019.
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df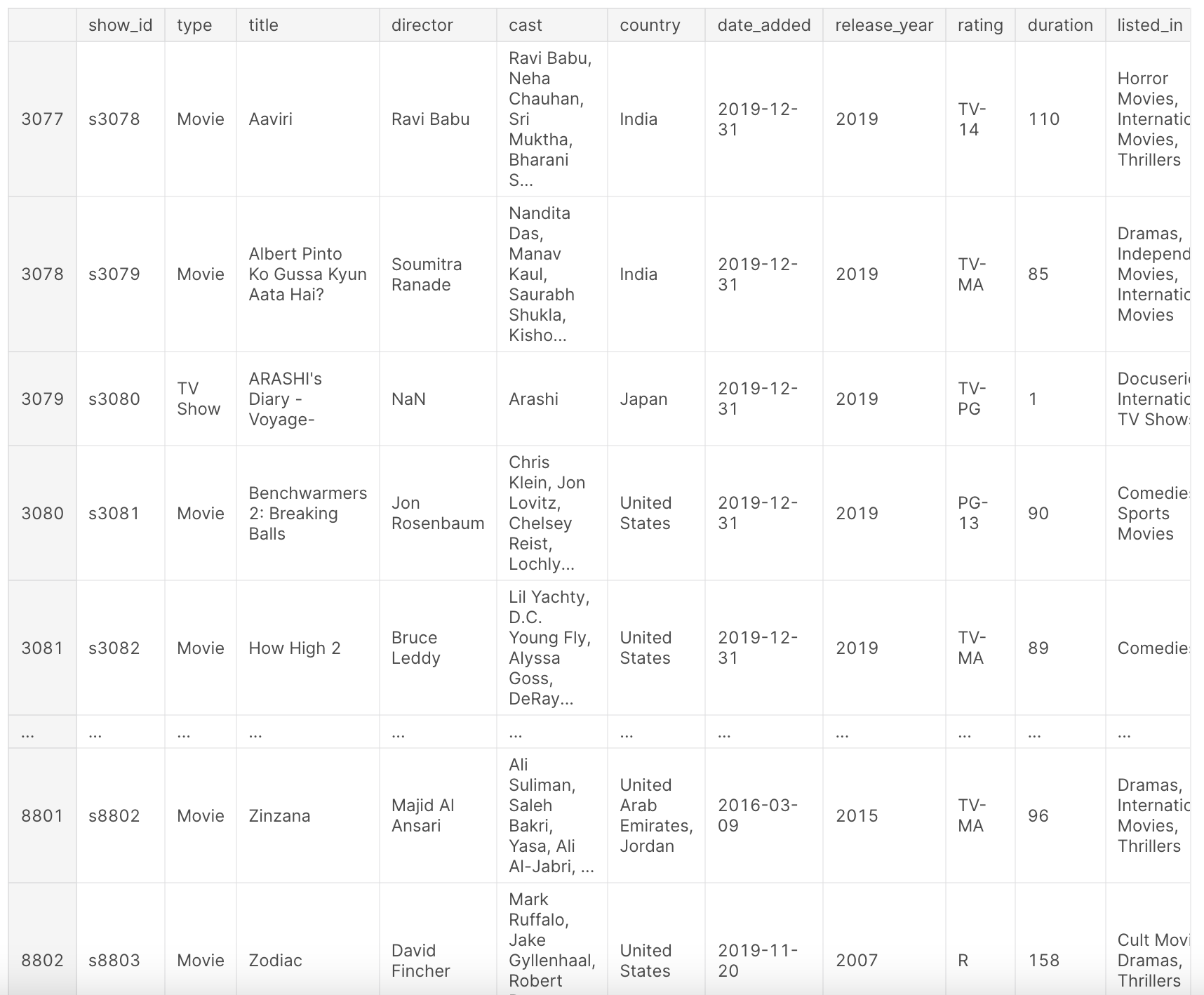
Überblick über den Netflix-Datensatz
Nach der oben genannten Vorverarbeitung bietet unser Datensatz df eine umfassende Übersicht über die Netflix-Titel. Er enthält Informationen wie den Typ des Inhalts (Film oder TV-Sendung), Titel, Regisseur, Besetzung, Produktionsland, Hinzufügedatum zu Netflix, Erscheinungsjahr, Bewertung, Dauer, Genre und eine kurze Beschreibung.
Dieser Datensatz gibt einen Überblick über die Inhaltslandschaft von Netflix bis zum Jahr 2019 und ermöglicht es uns, Trends, Vorlieben und Wachstumsmuster im Laufe der Jahre zu analysieren. Werfen Sie einen Blick auf die folgenden Spalten:
show_id: Eindeutige ID für jeden Film / jede TV-Showtype: Kennzeichnung für Film oder TV-Showtitle: Titel des Films / der TV-Showdirector: Regisseur des Filmscast: Schauspieler, die am Film / an der Show beteiligt sindcountry: Land, in dem der Film / die Show produziert wurdedate_added: Datum, an dem es auf Netflix hinzugefügt wurderelease_year: Tatsächliches Erscheinungsjahr des Films / der Showrating: TV-Bewertung des Films / der Showduration: Gesamtdauer - in Minuten oder Anzahl der Staffelnlisted_in: Genredescription: Eine kurze Beschreibung des Films / der Show
Netflix-Daten mit PyGWalker visualisieren
Kommen wir jetzt zum spannenden Teil: der Visualisierung. Mit PyGWalker generieren wir interaktive Visualisierungen, um Erkenntnisse aus unserem Datensatz zu gewinnen.
1. Allgemeiner Überblick über Netflix-Daten
Hier initialisieren wir einen "walker" für unseren Hauptdatensatz. Dadurch können wir eine Reihe von Diagrammen basierend auf den in "0.json" gespeicherten Spezifikationen generieren.
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
Sie können diesen Datensatz interaktiv mit einer Online-Version von PyGWalker hier (opens in a new tab) erkunden.
walker0.display_chart("Diagramm 1", title="Inhaltstyp auf Netflix")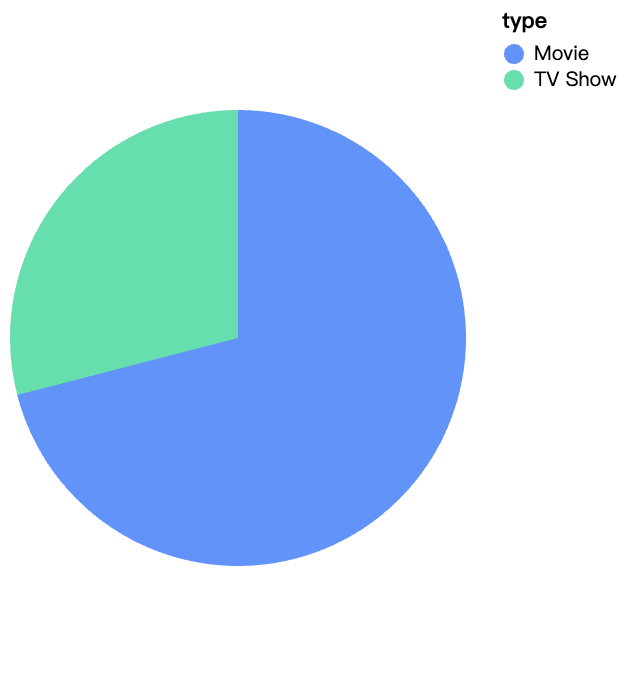
walker0.display_chart("Diagramm 2", title="Inhalt im Laufe der Jahre hinzugefügt", desc="Die Anzahl der Filme auf Netflix wächst deutlich schneller als die der TV-Shows, der Filminhalt ist nach 2016 stark angewachsen.")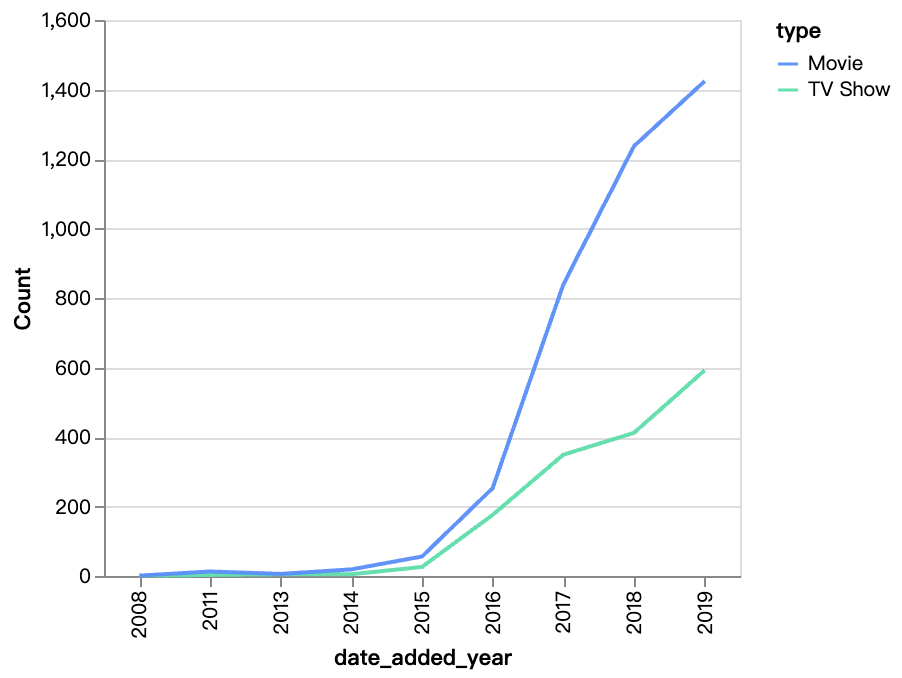
walker0.display_chart("Diagramm 3", title="Inhalt im Laufe der Jahre veröffentlicht")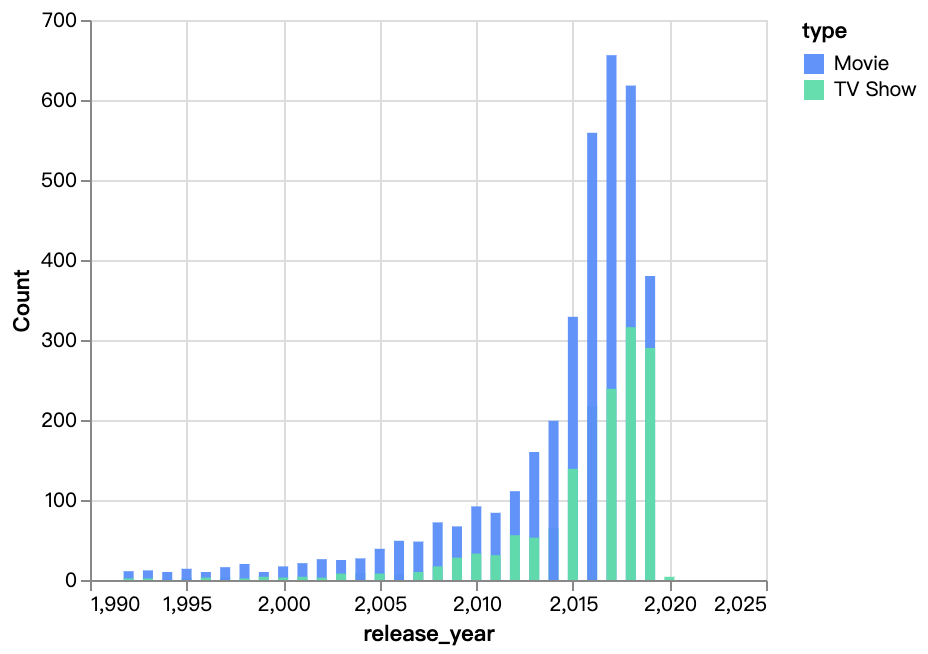
walker0.display_chart("Diagramm 4", title="Inhalt im Laufe der Monate hinzugefügt", desc="")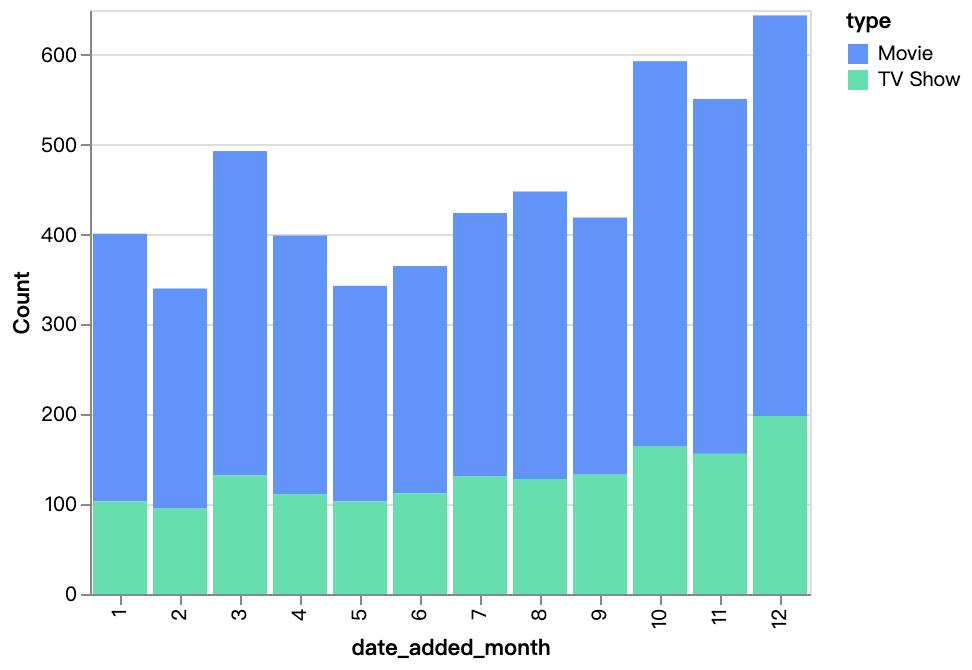
walker0.display_chart("Diagramm 5", title="Inhalt im Laufe der Jahre hinzugefügt nach Bewertung", desc="TV-MA, TV-14 sind die Bewertungen für den Großteil des Netflix-Inhalts, und R-Inhalte nehmen ebenfalls von Jahr zu Jahr zu")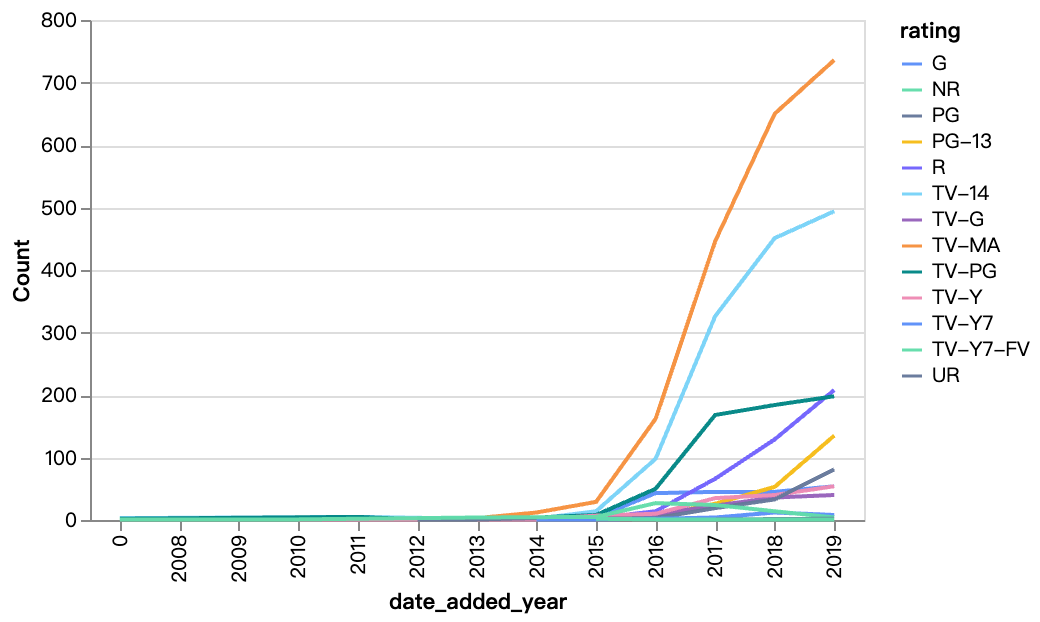
walker0.display_chart("Diagramm 6", title="Filmdauerverteilung", desc="Hauptsächlich konzentriert zwischen 90 und 110 Minuten")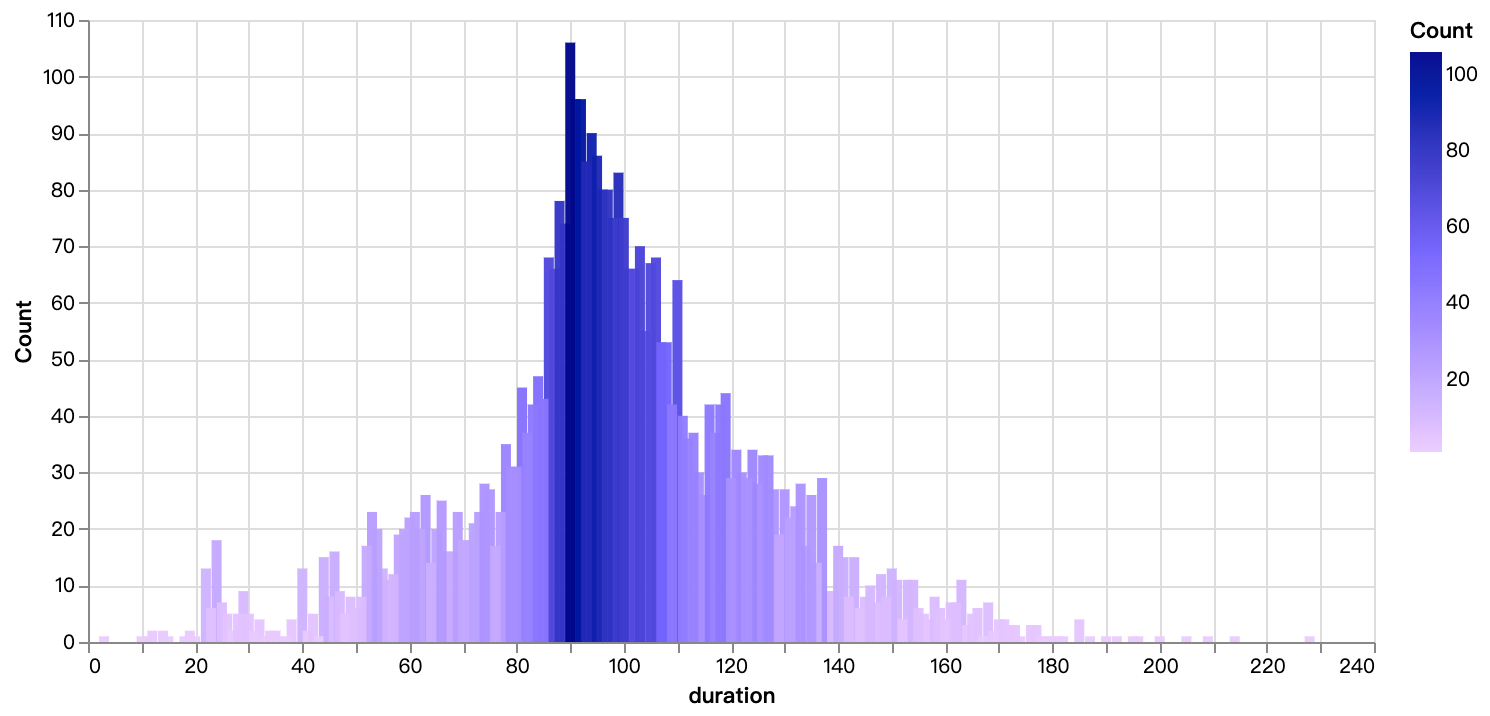
walker0.display_chart("Diagramm 7", title="TV-Show Staffelverteilung")
Bitte geben Sie die deutsche Übersetzung für diese Markdown-Datei an. Wenn ein Frontmatter vorhanden ist, stellen Sie sicher, dass Sie den Sprachparameter auch auf de übersetzen. Hier ist die Datei: 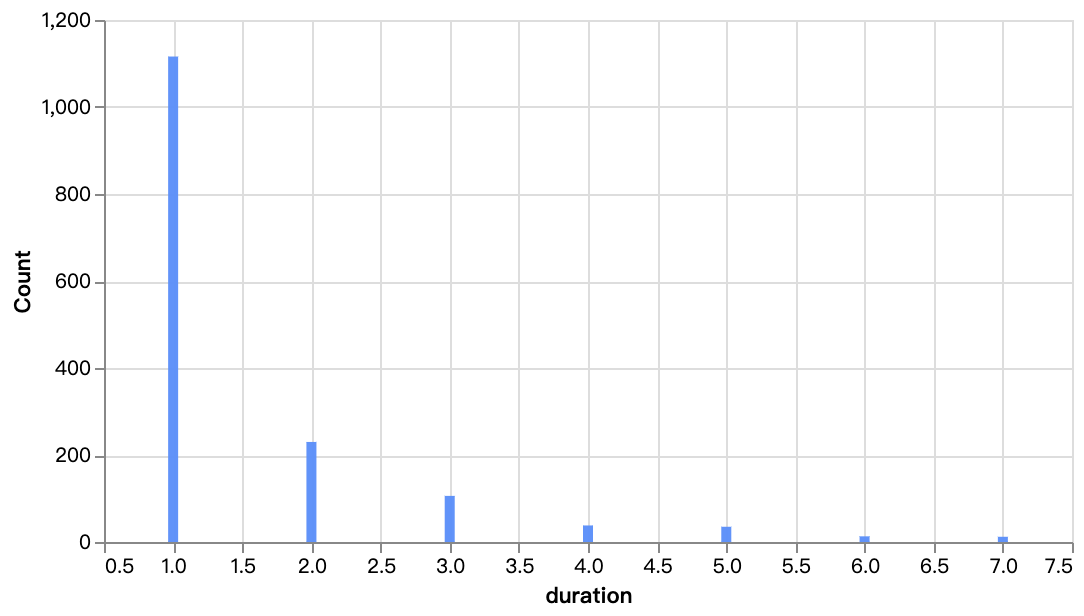
2. Länderbezogene Analyse der Netflix-Daten
In diesem Abschnitt analysieren wir die Inhalte nach Ländern. Durch Aufsplitten und Neuordnen der Spalte "country" können wir die Verteilung der Inhalte in verschiedenen Ländern analysieren.
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)Sie können PyGWalker User Interface hier (opens in a new tab) ausprobieren.
walker1.display_chart("Diagramm 1", title="Länder mit den meisten Inhalten")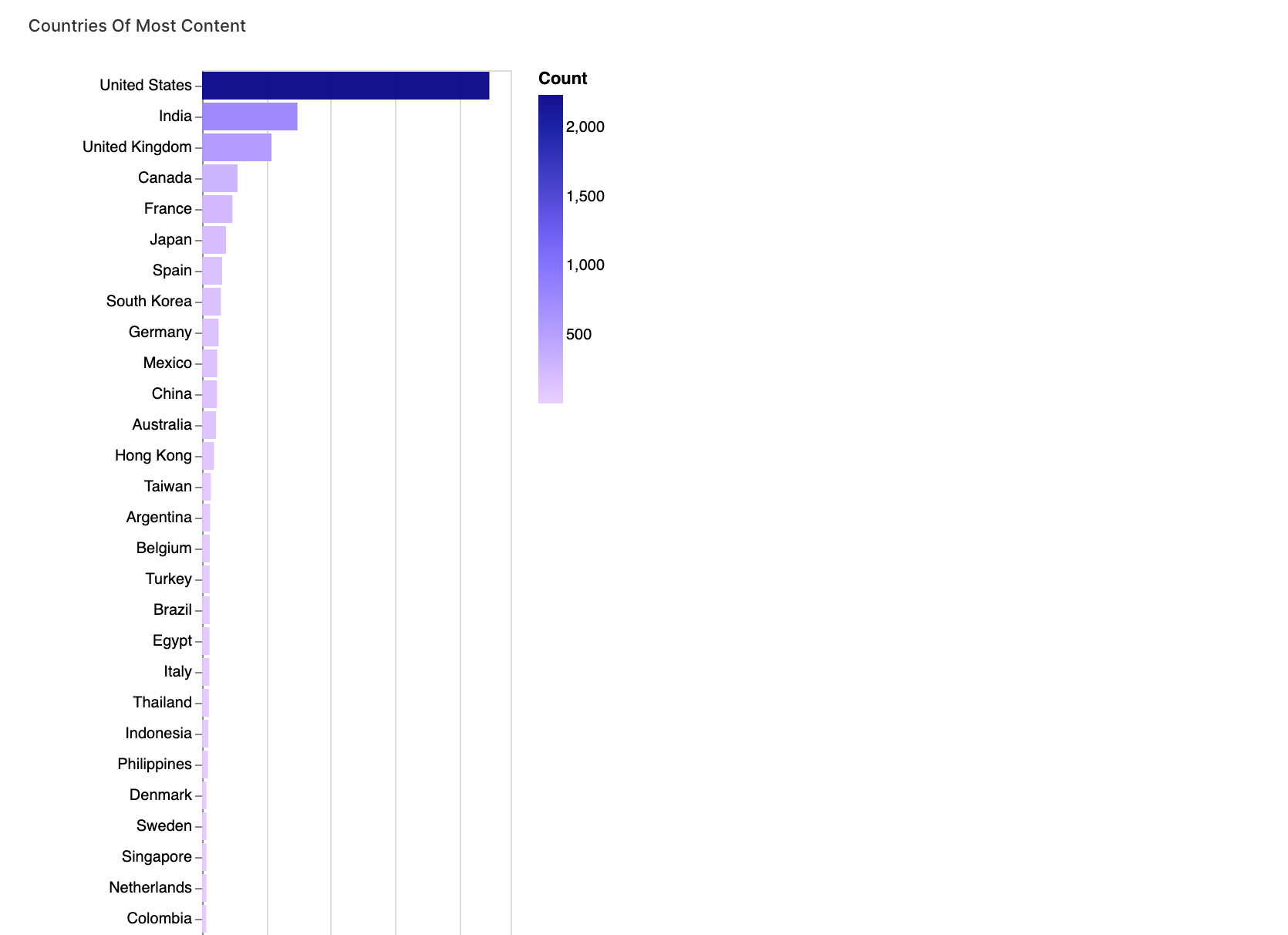
3. Kategorie- und Bewertungsanalyse
Zuletzt konzentrieren wir uns auf Kategorien und Bewertungen. Dieser Abschnitt ermöglicht es uns, die Verteilung der Inhalte in den Genres zu verstehen und wie sich die Bewertungen innerhalb dieser Genres unterscheiden.
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)Sie können PyGWalker User Interface hier (opens in a new tab) ausprobieren.
walker2.display_chart("TV-Kategorie", title="Verteilung der TV-Show-Kategorien")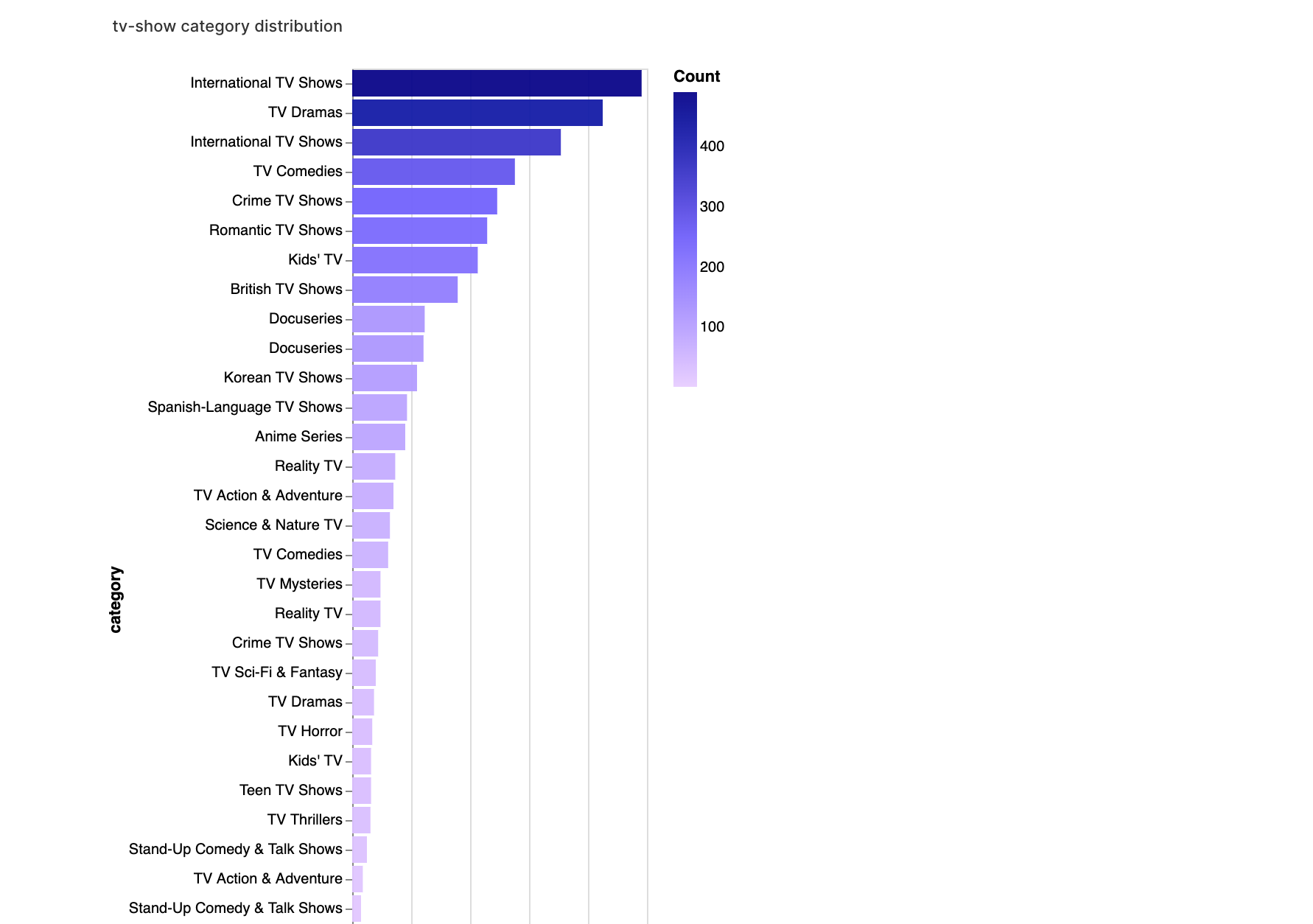
walker2.display_chart("Filmkategorie", title="Verteilung der Filmkategorien")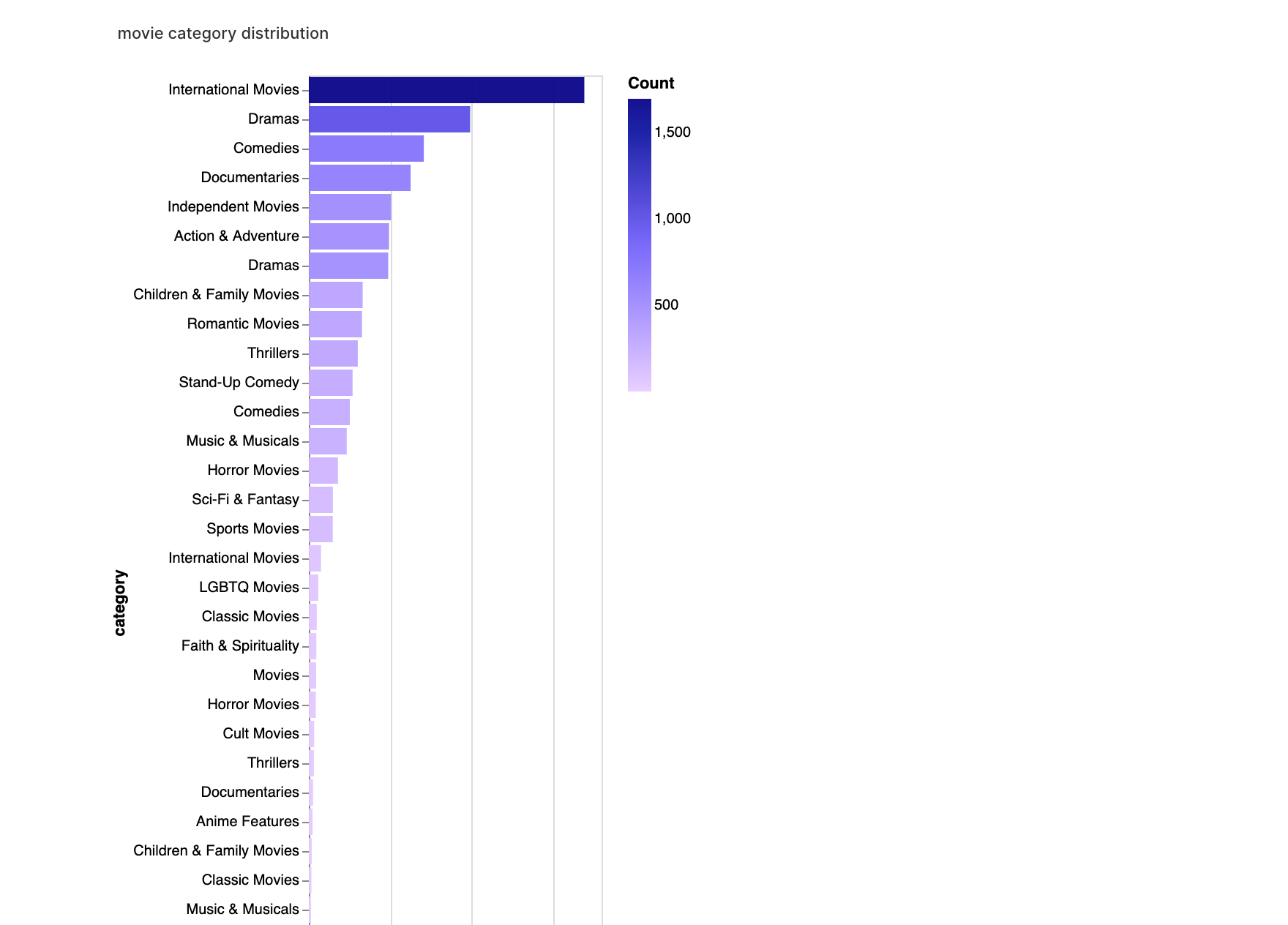
walker2.display_chart("Bewertungskategorie (TV-Show)", title="Hitzeampel der Bewertungskategorien (TV-Show)")
walker2.display_chart("Bewertungskategorie (Film)", title="Hitzeampel der Bewertungskategorien (Film)")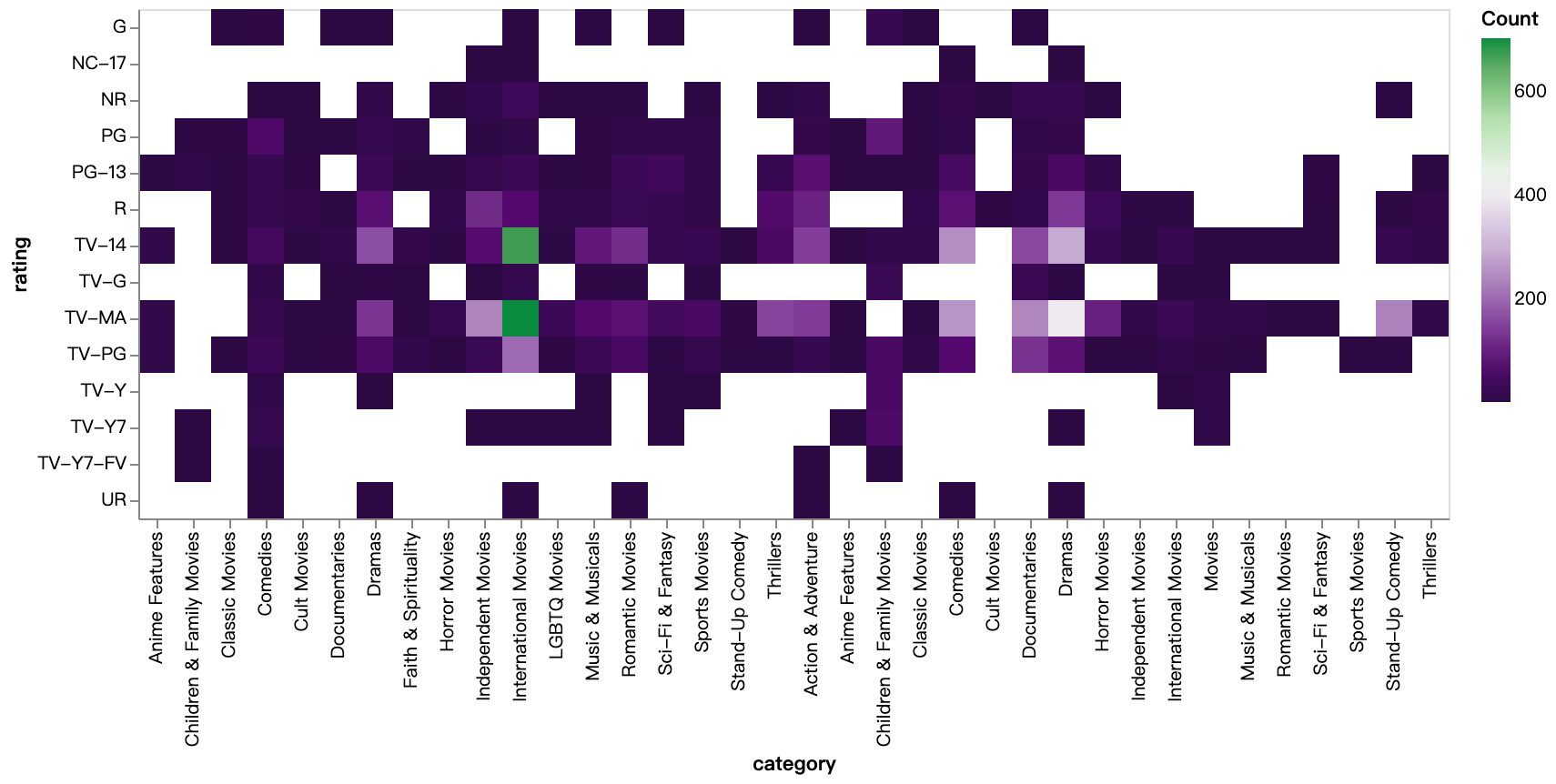
Fazit
In dieser umfassenden Erkundung des Netflix-Datensatzes mit der PyGWalker-Bibliothek haben wir uns intensiv mit den vielfältigen Facetten der Netflix-Inhaltslandschaft beschäftigt. PyGWalker erwies sich als ein effektives Werkzeug, das den Visualisierungsprozess vereinfachte und wesentliche Trends aufzeigte. Die Analyse lieferte Erkenntnisse über Wachstumsmuster, Präferenzen und Trends der Netflix-Inhalte bis 2019. Die Untersuchung der Kategorien und Bewertungen zeigte die Vielfalt und Verteilung der Genres in Filmen und TV-Shows sowie die Variation der Bewertungen innerhalb dieser Genres.
Diese Dokumentation ist auch auf Kaggle Notebook (opens in a new tab) verfügbar.
FAQs
1. Was sind Netflix-Datensätze?
- Netflix-Datensätze sind Sammlungen von Daten, die detaillierte Informationen über die auf der Netflix-Plattform verfügbaren Inhalte liefern. Diese Daten umfassen in der Regel Aspekte wie den Typ des Inhalts (Film oder TV-Show), Titel, Regisseur, Besetzung, Produktionsland, Hinzufügedatum zu Netflix, Erscheinungsjahr, Bewertung, Dauer, Genre und eine kurze Beschreibung. Diese Datensätze ermöglichen es Forschern und Analysten, ein besseres Verständnis der Inhaltlandschaft der Plattform zu erlangen.
2. Wie können Netflix-Datensätze verwendet werden?
- Netflix-Datensätze können auf verschiedene Weise verwendet werden:
- Trendanalyse: Verstehen Sie die Wachstumsmuster, Präferenzen und Trends im Laufe der Jahre.
- Länderanalyse: Bestimmen Sie, welche Länder die meisten Inhalte produzieren und welche Art von Inhalten in verschiedenen Regionen beliebt ist.
- Genreverteilung: Erforschen Sie die beliebtesten Genres und wie sie sich zwischen Filmen und TV-Shows unterscheiden.
- Bewertungsinformationen: Analysieren Sie die Verteilung von Bewertungen in verschiedenen Arten von Inhalten und ermitteln Sie die Vorlieben des Publikums.
- Datenvisualisierung: Verwenden Sie Tools wie PyGWalker, um interaktive Visualisierungen für tiefere Einblicke zu erstellen.
3. Was ist PyGWalker und warum ist es für die Datenexploration vorteilhaft?
- PyGWalker ist eine Python-Bibliothek, die speziell entwickelt wurde, um den Prozess der Datenvisualisierung zu vereinfachen. Sie ermöglicht es Benutzern, interaktive Diagramme mit minimalem Code zu generieren und damit Muster und Erkenntnisse in Datensätzen aufzudecken. Für Plattformen wie Netflix, die umfangreiche Datensätze haben, kann PyGWalker von unschätzbarem Wert sein, um die Datenexploration zu vereinfachen und leicht verständliche Visualisierungen zu generieren.