Kann ChatGPT Datenanalysten ersetzen? Mit ChatGPT mühelos komplexe SQL-Abfragen generieren

- Runcell Science: Open-Source-Alternative zu Claude Science für Forschungsteams
- Mac Ruhezustand verhindern: Codex, Claude Code und KI-Agenten weiterlaufen lassen
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: Welchen KI-Agenten-Stack sollten Sie 2026 wählen?
- Wie Claude Code Jupyter Notebooks analysiert: Data Science, Grenzen und die bessere Alternative
- Claude Code Routines: KI-Cronjobs für Agenten
- Claude Code Desktop: Bypass permissions aktivieren
- Schritt-für-Schritt-Anleitung zur Erstellung von zwei Python-Agenten mit Googles A2A-Protokoll
- Die Top 10 wachsenden Data Visualization Libraries in Python im Jahr 2025
Einführung
SQL (Structured Query Language) ist eine weit verbreitete Programmiersprache zur Verwaltung und Manipulation von Daten in relationalen Datenbanken. Unternehmen und Organisationen müssen Daten speichern, abrufen und analysieren. Das Schreiben von SQL-Abfragen kann jedoch für Menschen, insbesondere bei komplexen Abfragen oder großen Datenbanken, zeitaufwendig und fehleranfällig sein.
In diesem Artikel werden wir die Möglichkeiten von ChatGPT, einem großen Sprachmodell von OpenAI, bei der Generierung effizienter SQL-Abfragen untersuchen. Wir werden zeigen, wie ChatGPT schnell komplexe Abfragen generieren, Daten mit hoher Präzision und Recall filtern und bestehende Abfragen optimieren kann.
Generieren einer Beispieldatenbank
Um die Dinge klar zu machen, verwenden wir folgende Beispieldatenbank:
Tabelle 1: Bücher
Diese Tabelle enthält Informationen über alle Bücher im Buchladen, einschließlich ihrer Titel, Autoren, Verlage und ISBNs.
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255),
publisher VARCHAR(255),
isbn VARCHAR(13)
);Tabelle 2: Kunden Diese Tabelle speichert Informationen über die Kunden, die sich im Buchladen registriert haben, einschließlich ihres Namens, ihrer E-Mail-Adressen und Telefonnummern.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
phone VARCHAR(20)
);Tabelle 3: Bestellungen
Diese Tabelle speichert Informationen über alle Bestellungen, die von Kunden aufgegeben wurden, einschließlich des Kunden, der die Bestellung aufgegeben hat, des/den bestellten Buch(s), des Bestelldatums und des Bestellstatus.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
book_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);Tabelle 4: Lagerbestand
Diese Tabelle verfolgt die aktuellen Lagerbestände jedes Buches im Laden.
CREATE TABLE inventory (
book_id INT PRIMARY KEY,
quantity INT,
FOREIGN KEY (book_id) REFERENCES books(book_id)
);Dies sind nur die grundlegenden Tabellen, die Sie für den Einstieg in eine Buchhandelsdatenbank benötigen. Je nach Ihren spezifischen Anforderungen können Sie weitere Tabellen oder Spalten hinzufügen.
ChatGPT-Aufforderung zur Datenaggregation
Eine der häufigsten Aufgaben bei der Arbeit mit Datenbanken ist die Datenaggregation. Dabei geht es darum, Daten basierend auf bestimmten Bedingungen zusammenzufassen. Zum Beispiel die Berechnung des Gesamtumsatzes für eine bestimmte Produktkategorie oder des Durchschnittsgehalts der Mitarbeiter in einer bestimmten Abteilung. Aggregationsabfragen können komplex sein und für Menschen viel Zeit in Anspruch nehmen.
ChatGPT kann jedoch diese Abfragen schnell und genau generieren. Es kann die Struktur der Daten und die gewünschte Ausgabe verstehen und eine effiziente Abfrage generieren, die die erforderlichen Informationen mit minimalem Aufwand abrufen kann. Dadurch wird das Risiko von Fehlern reduziert und Zeit für den Benutzer gespart.
Hier ist ein Beispiel für eine von ChatGPT generierte Datenaggregationsabfrage mit folgender Aufforderung:
"Finden Sie die 5 meistverkauften Bücher des letzten Quartals zusammen mit ihren Autoren und dem Gesamtumsatz."
Um diese Aggregation durchzuführen, müssen Sie die Tabellen Bücher, Bestellungen und Lagerbestand verknüpfen, die Ergebnisse nach Buch und Autor gruppieren, nach den Bestellungen des letzten Quartals filtern und den Gesamtumsatz für jedes Buch berechnen. Schließlich müssen Sie die Ergebnisse nach Umsatz sortieren und die Ausgabe auf die Top 5 Bücher beschränken.
ChatGPT generiert den folgenden SQL-Code, um dies zu erreichen:
SELECT books.title, books.author, SUM(inventory.quantity * orders.price) AS revenue
FROM books
JOIN inventory ON books.book_id = inventory.book_id
JOIN orders ON inventory.book_id = orders.book_id
WHERE orders.order_date >= DATEADD(QUARTER, -1, GETDATE())
GROUP BY books.title, books.author
ORDER BY revenue DESC
LIMIT 5;Datenfilterung
Eine weitere wichtige Aufgabe bei der Arbeit mit Datenbanken ist die Datenfilterung. Dabei geht es darum, bestimmte Daten aus einer Datenbank auf der Grundlage bestimmter Kriterien herauszufiltern. Zum Beispiel das Extrahieren aller Transaktionen, die von Kunden an einem bestimmten Standort getätigt wurden, oder aller Mitarbeiter, die seit mehr als fünf Jahren bei der Firma sind. Filterabfragen können ebenfalls komplex sein und für Menschen viel Zeit in Anspruch nehmen.
ChatGPT kann diese Abfragen mit hoher Präzision und Recall generieren. Es kann die Struktur der Daten und die gewünschte Ausgabe verstehen und eine Abfrage generieren, die die relevantesten Daten abrufen kann. Dadurch erhalten Sie genauere Daten für die Analyse und Entscheidungsfindung. Hier ist ein Beispiel für eine von ChatGPT generierte Datenfilterungsabfrage mit folgender Aufforderung:
"Finden Sie alle Bücher, die von 'Penguin Random House' veröffentlicht wurden und derzeit auf Lager sind, sortiert nach Autorenname in aufsteigender Reihenfolge."
Um dies zu filtern, müssen Sie die Tabellen Bücher und Lagerbestand verknüpfen, nach Büchern filtern, die von 'Penguin Random House' veröffentlicht wurden, und nur die Bücher auswählen, die derzeit auf Lager sind. Schließlich müssen Sie die Ergebnisse nach Autorenname in aufsteigender Reihenfolge sortieren.
ChatGPT generiert den folgenden SQL-Code, um diese Anforderung zu erfüllen:
SELECT books.title, books.author, books.publisher, inventory.quantity
FROM books
JOIN inventory ON books.book_id = inventory.book_idWHERE Bücher.Herausgeber = 'Penguin Random House' AND Bestand.Anzahl > 0 ORDER BY Bücher.Autor ASC;
## Query-Optimierung
Neben der Generierung neuer SQL-Abfragen kann ChatGPT auch bei der Optimierung bestehender Abfragen unterstützen. Durch Analyse der Struktur und Leistung einer Abfrage kann ChatGPT Verbesserungsvorschläge machen, um die Abfrage schneller und effizienter auszuführen. Zum Beispiel kann ChatGPT vorschlagen, Indizes zu verwenden oder die Abfrage umzuschreiben, um die Möglichkeiten der Datenbank besser auszunutzen.
Die Optimierung von Abfragen kann für Menschen eine schwierige Aufgabe sein, insbesondere bei großen und komplexen Datenbanken. ChatGPT kann diese Aufgabe vereinfachen und zur Leistungsverbesserung der Datenbank beitragen. Hier ist ein Beispiel für eine durch diese ChatGPT-Vorlage generierte Abfrageoptimierung:
> "Finde die 10 Kunden, die im letzten Jahr am meisten für Bücher ausgegeben haben, sowie ihre Gesamtausgaben und durchschnittlichen Ausgaben pro Bestellung."
Um diese Abfrage zu optimieren, müssen Sie die Anzahl der Operationen minimieren, die die Datenbank für die Ergebnisgenerierung durchführen muss. Hier sind einige Optimierungstechniken, die Sie in Betracht ziehen könnten:
1. Verwenden Sie Indizes: Fügen Sie den relevanten Spalten in den Tabellen Kunden und Bestellungen Indizes hinzu, um die Verknüpfungen und Filteroperationen zu beschleunigen.
2. Aggregieren Sie vor der Verknüpfung: Anstatt die Tabellen Kunden und Bestellungen zu verknüpfen und dann die Ergebnisse zu aggregieren, können Sie zuerst die Bestellungen nach Kunden aggregieren und dann die resultierende Tabelle mit der Kunden-Tabelle verknüpfen.
3. Verwenden Sie Unterabfragen: Anstatt die Tabellen Kunden und Bestellungen direkt zu verknüpfen, können Sie Unterabfragen verwenden, um die Bestellungen nach Datumsbereich zu filtern und die Gesamtausgaben und durchschnittlichen Ausgaben pro Bestellung für jeden Kunden zu berechnen.
Hier ist ein Beispiel für eine SQL-Abfrage, die diese Optimierungen umsetzt, die von ChatGPT generiert wurden:
```sql copy
SELECT Kunden.name,
gesamtausgaben,
gesamtausgaben / bestellungsanzahl AS durchschnittliche_ausgaben_pro_bestellung
FROM (
SELECT kunden_id,
SUM(preis * menge) AS gesamtausgaben,
COUNT(*) AS bestellungsanzahl
FROM bestellungen
WHERE bestelldatum >= DATEADD(JAHR, -1, GETDATUM())
GROUP BY kunden_id
) AS bestellungsdaten
JOIN Kunden ON bestellungsdaten.kunden_id = Kunden.kunden_id
ORDER BY gesamtausgaben DESC
LIMIT 10;Eine weitere automatisierte Datenanalyseoption: RATH
Neben den Fähigkeiten von ChatGPT bei der Generierung effizienter SQL-Abfragen gibt es auch RATH (opens in a new tab), eine Open-Source-Alternative zu Datenanalyse- und Visualisierungstools wie Tableau. RATH bringt die Datenanalyse auf die nächste Stufe, indem es den Workflow der Exploratory Data Analysis (EDA) mit einer Augmented Analytic Engine automatisiert.
RATH unterstützt eine Vielzahl von Datenquellen. Hier sind einige der wichtigsten Datenbanklösungen, die Sie mit RATH verbinden können: MySQL, ClickHouse, Amazon Athena, Amazon Redshift, Apache Spark SQL, Apache Doris, Apache Hive, Apache Impala, Apache Kylin, Oracle und PostgreSQL.
RATH (opens in a new tab) ist Open Source. Besuchen Sie das RATH GitHub und erleben Sie das Next-Generation Auto-EDA Tool. Sie können auch die RATH Online-Demo als Ihren Data Analysis Playground ausprobieren!

Hervorzuhebende Funktionen von RATH sind:
| Funktion | Beschreibung | Vorschau |
|---|---|---|
| AutoEda | Augmented Analytic Engine zur Entdeckung von Mustern, Erkenntnissen und Kausalitäten. Eine vollständig automatisierte Möglichkeit, Ihren Datensatz zu untersuchen und Ihre Daten mit einem Klick zu visualisieren. | 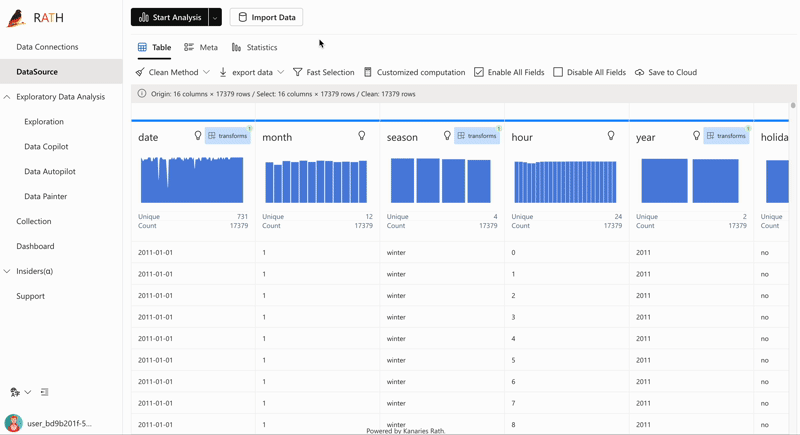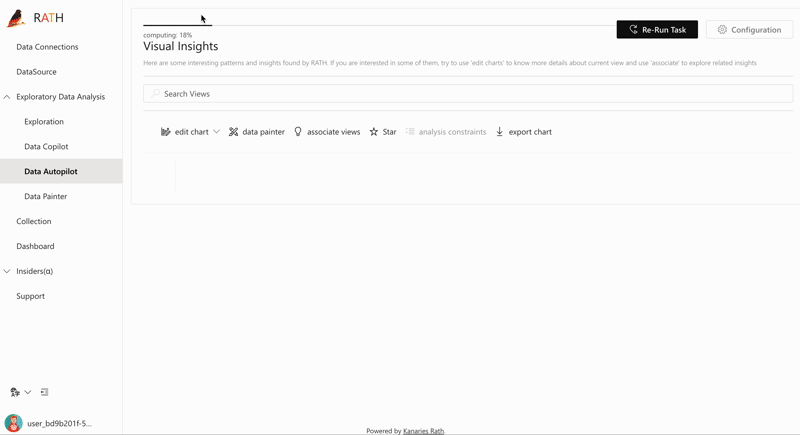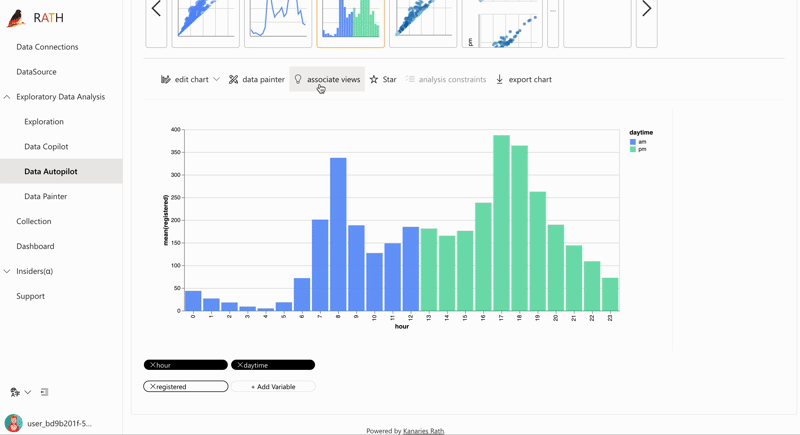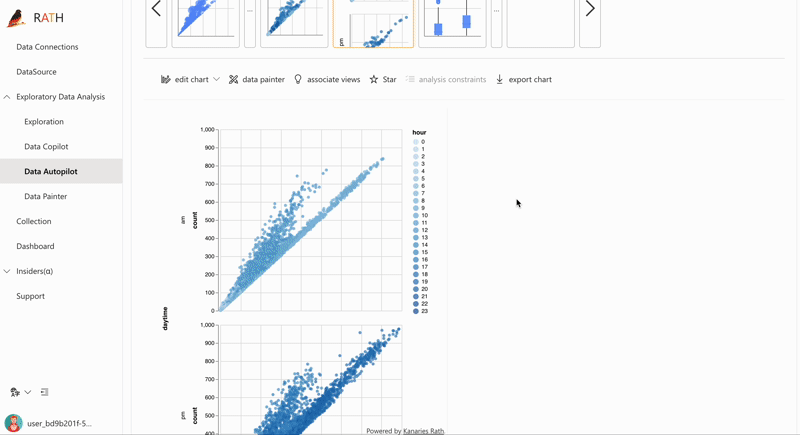 |
| Datenvisualisierung | Erstellen Sie multidimensionale Datenvisualisierungen basierend auf der Effektivität. | 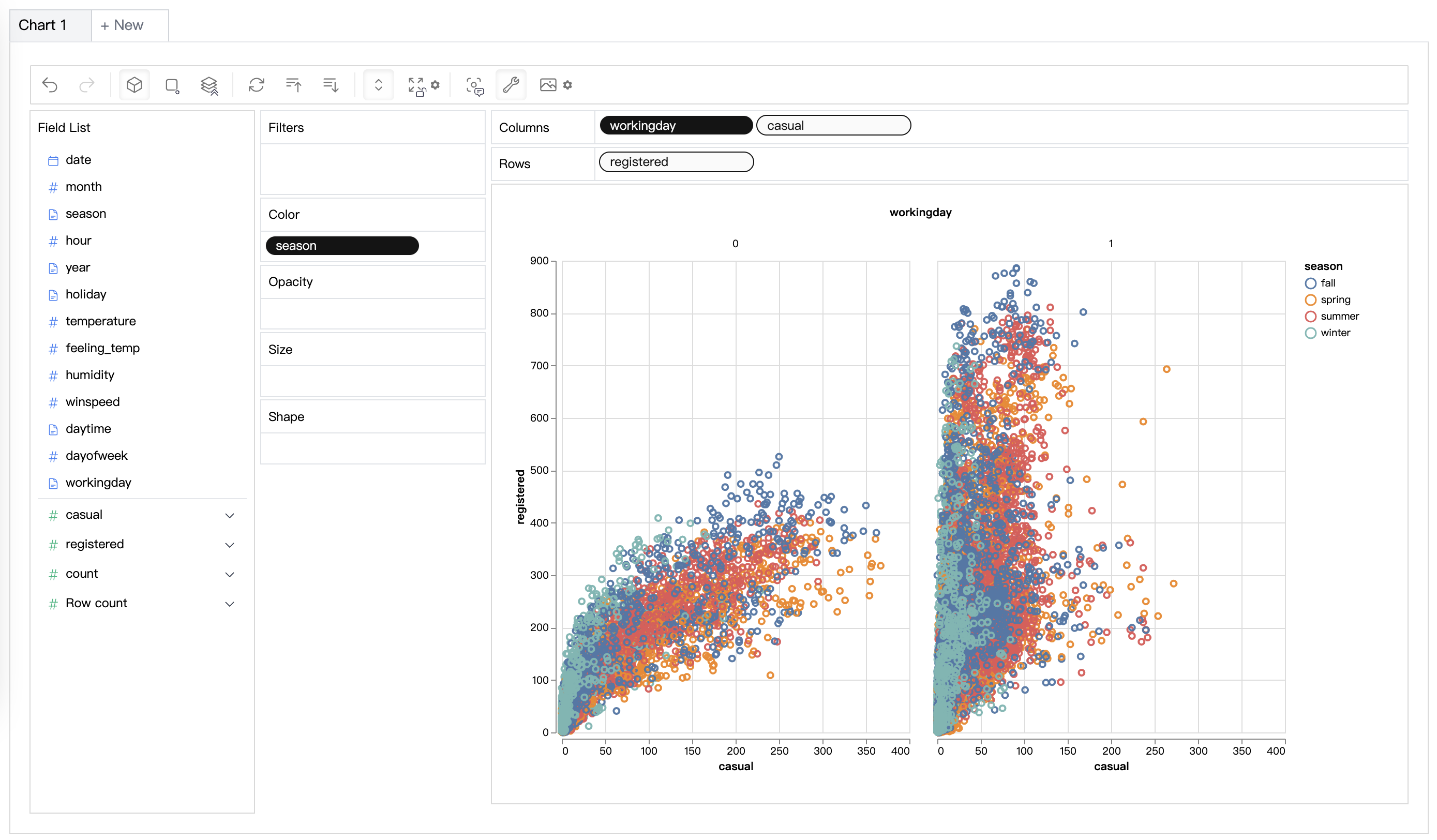 |
| Daten Wrangler | Automatisierter Daten Wrangler zur Generierung einer Zusammenfassung der Daten und zur Datenverarbeitung. | 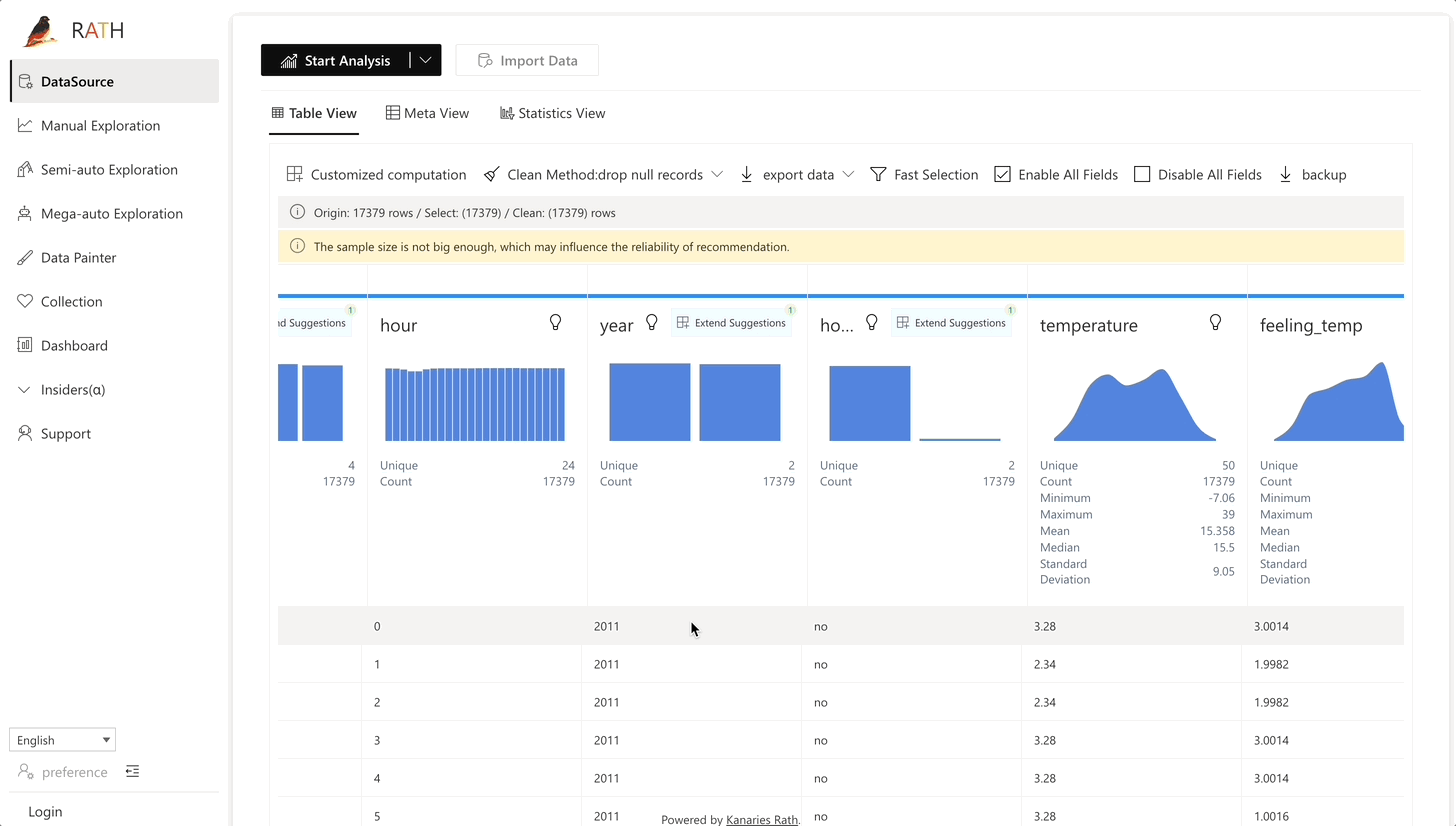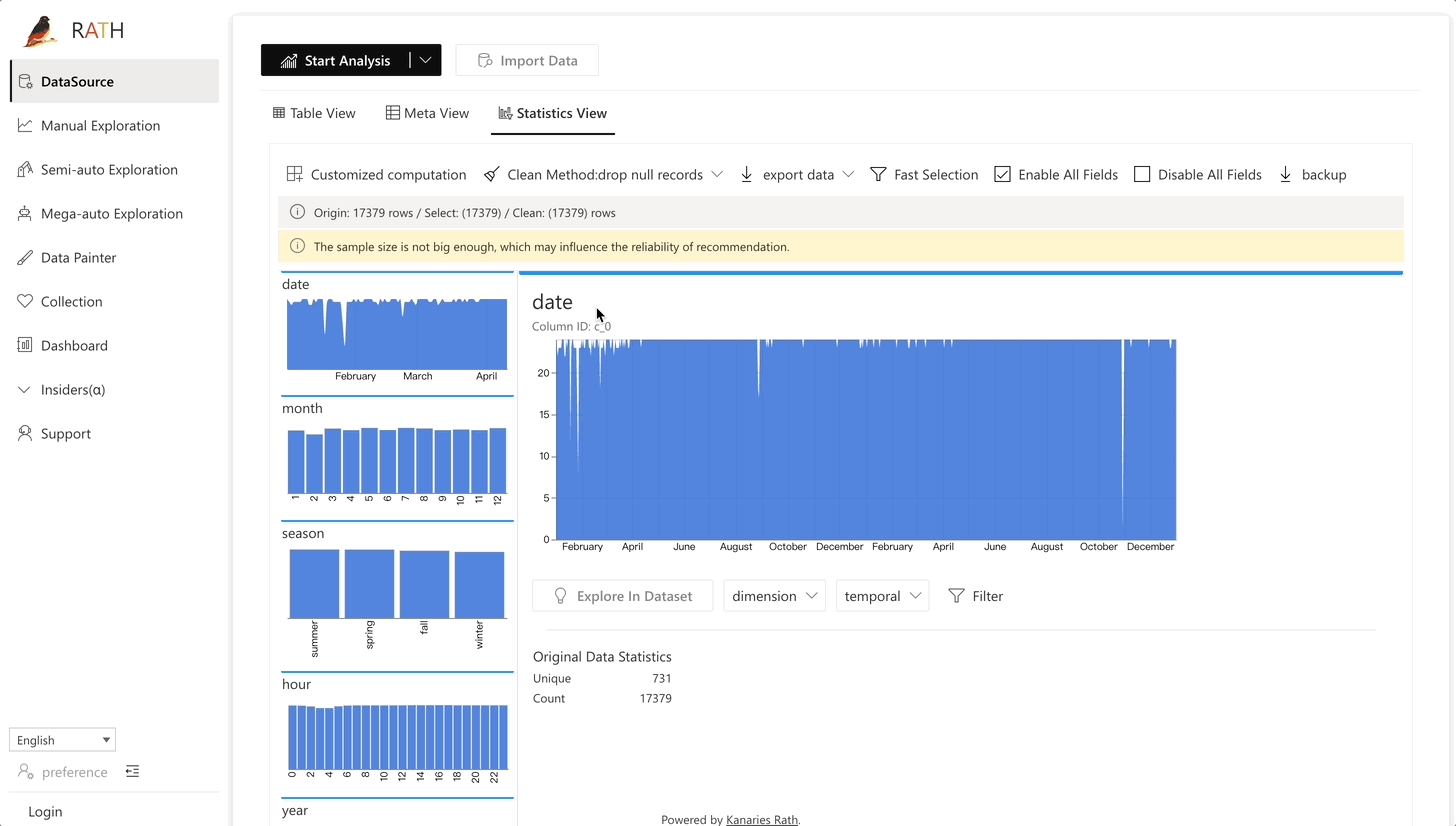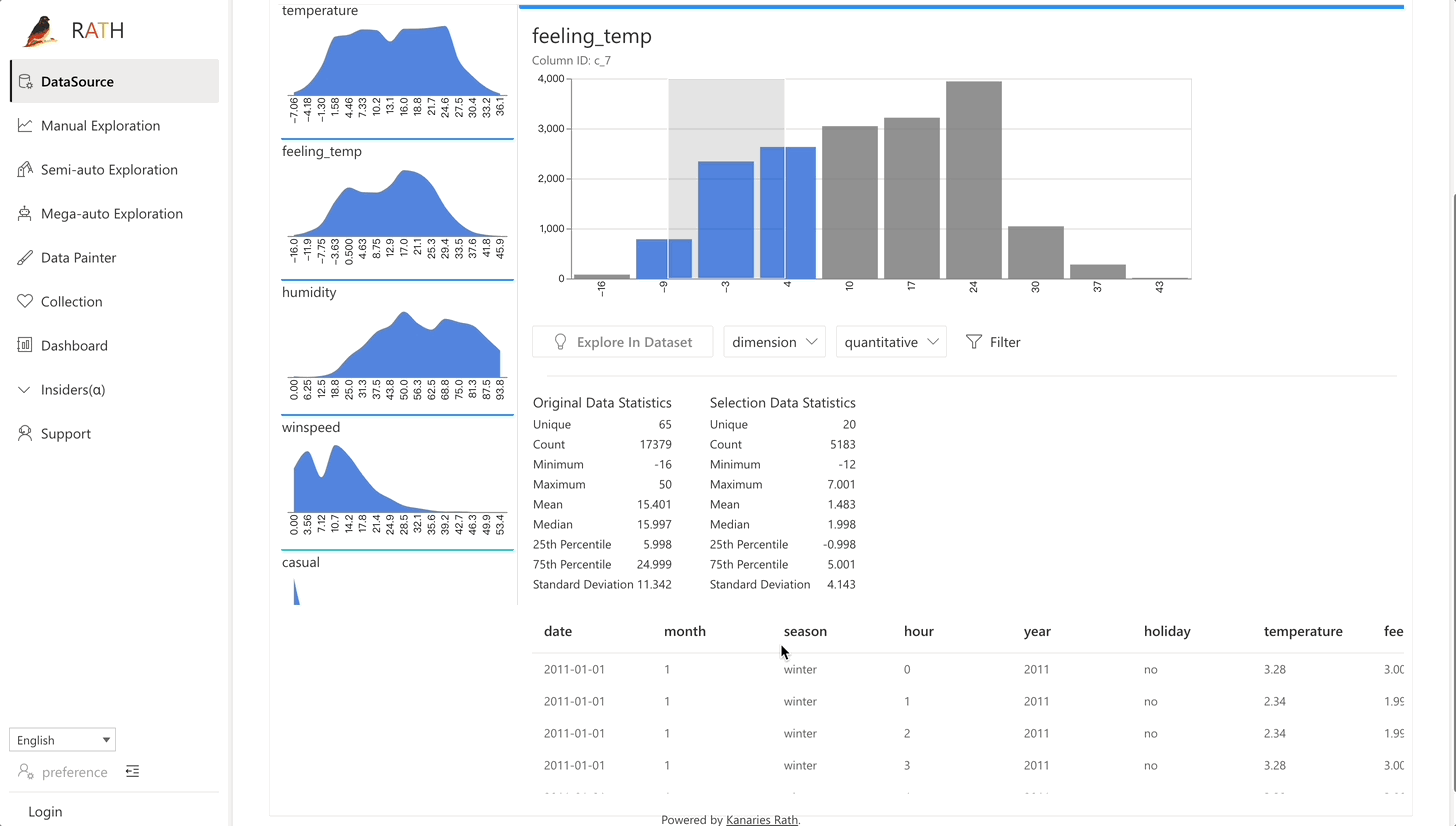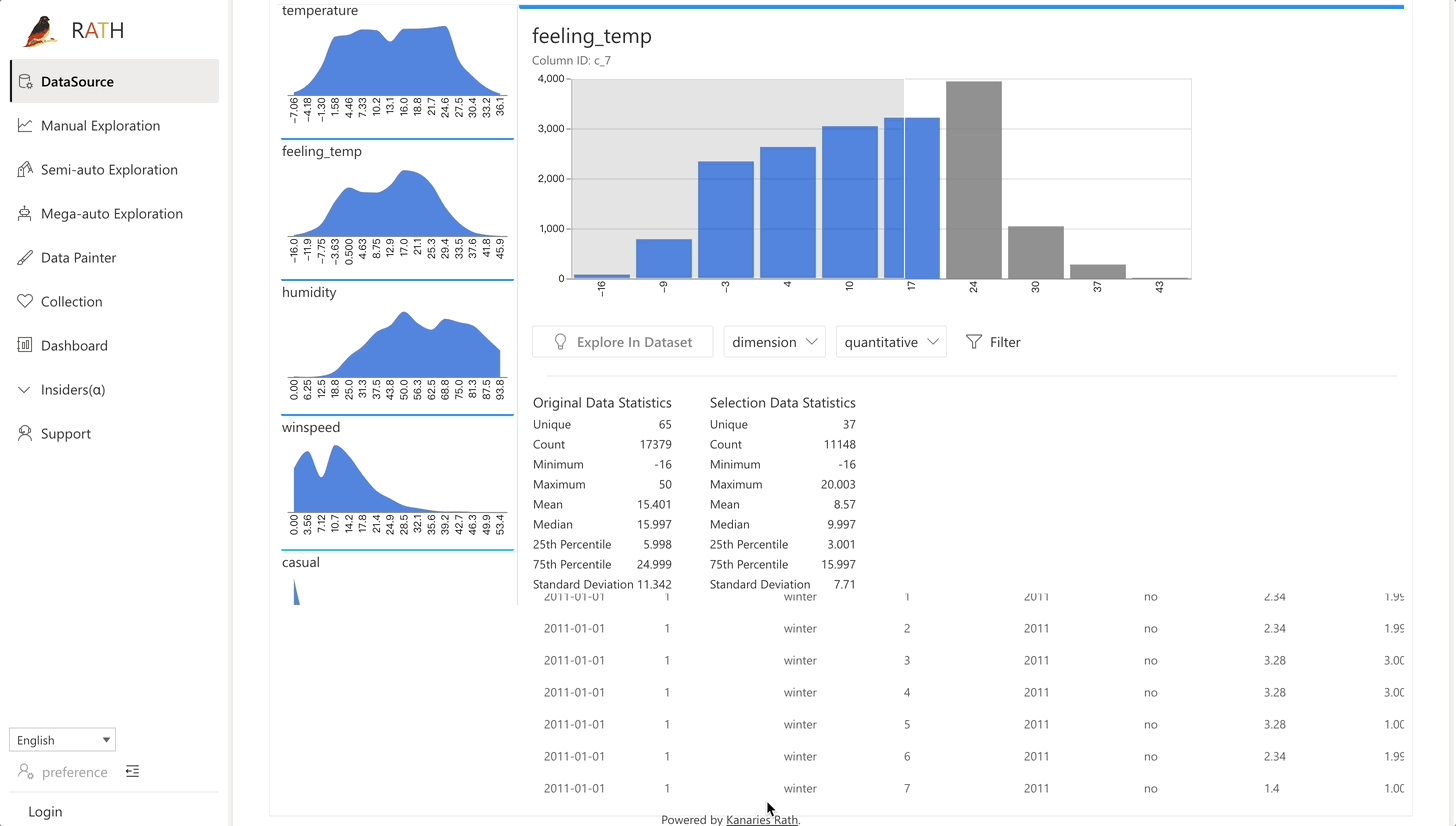 |
| Data Exploration Copilot | Kombiniert automatisierte Datenexploration und manuelle Exploration. RATH unterstützt Sie als Copilot in der Datenanalyse, lernt Ihre Interessen und generiert relevante Empfehlungen für Sie mithilfe der Augmented Analytic Engine. | 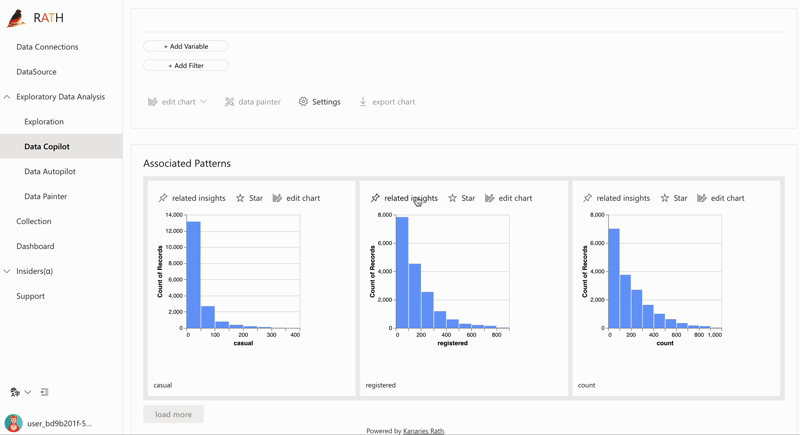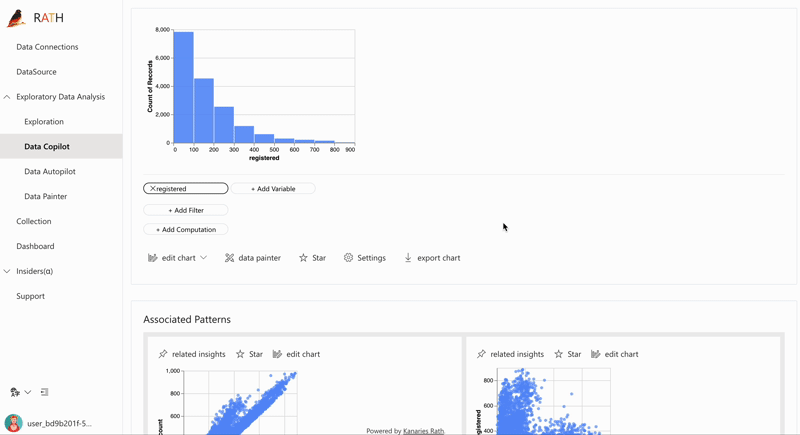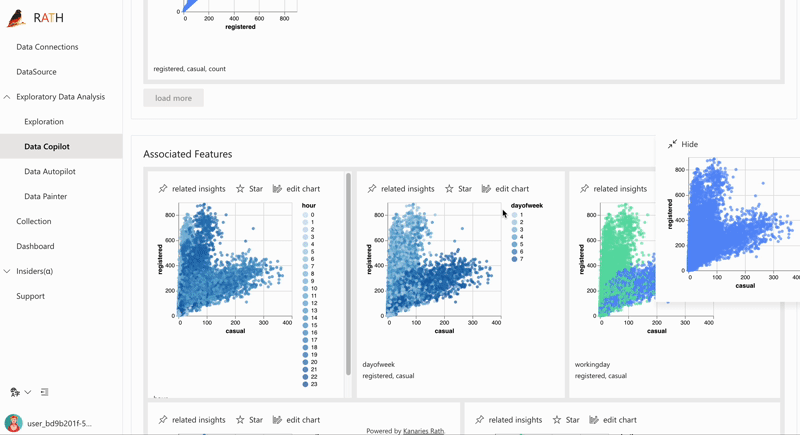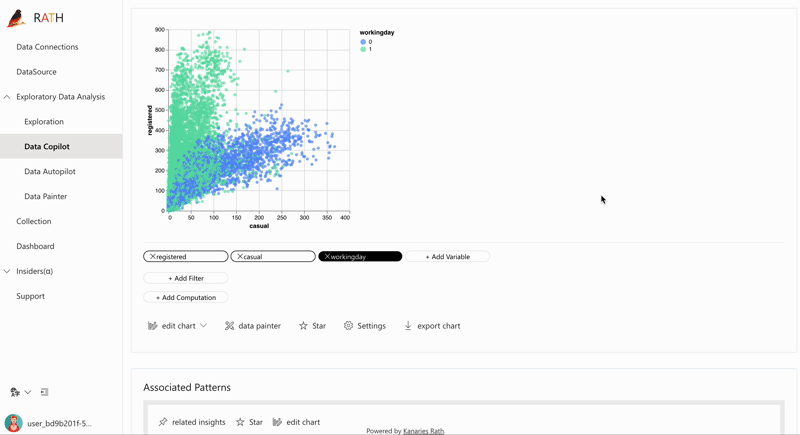 |
| Data Painter | Ein interaktives, intuitives und leistungsstarkes Werkzeug für die explorative Datenanalyse, bei dem Sie Ihre Daten direkt einfärben und weitere analytische Funktionen nutzen können. | 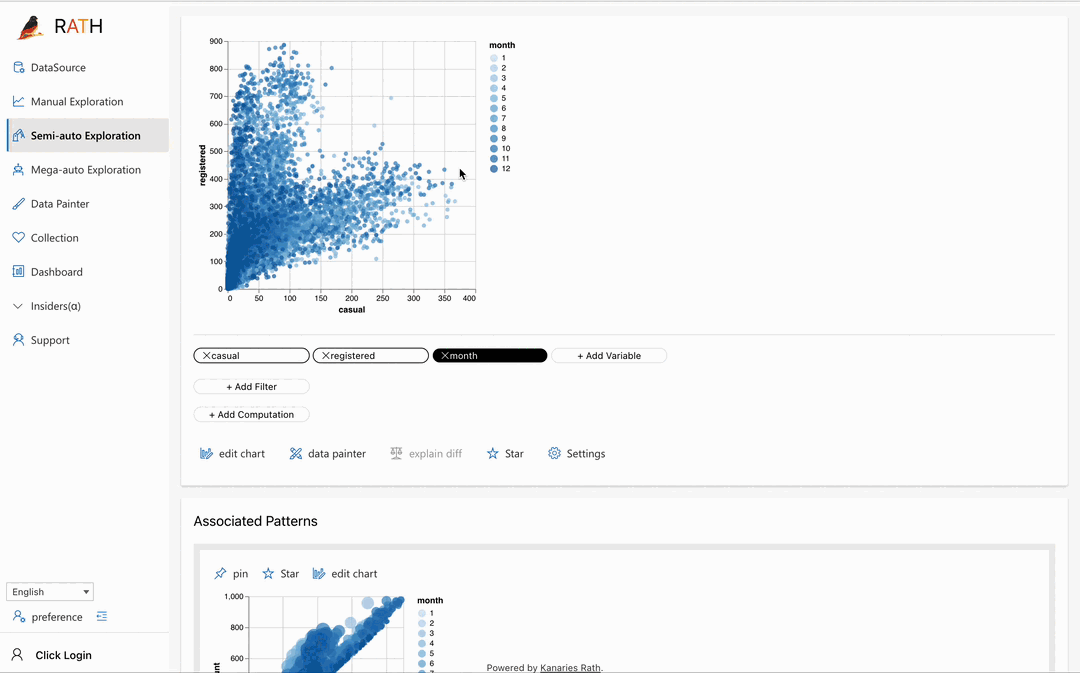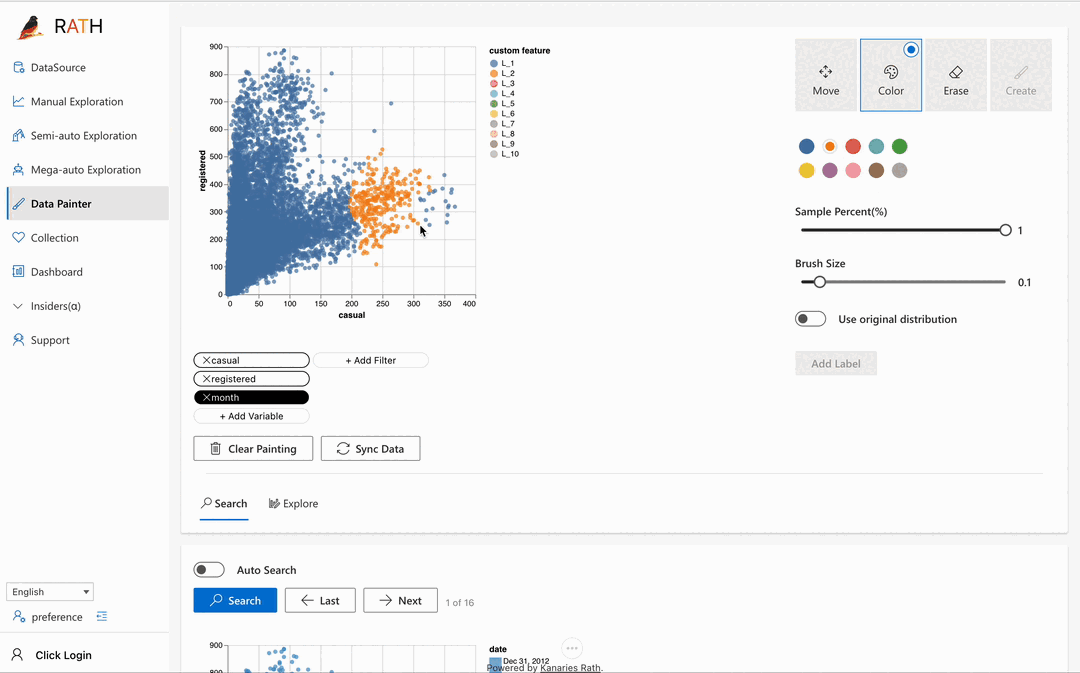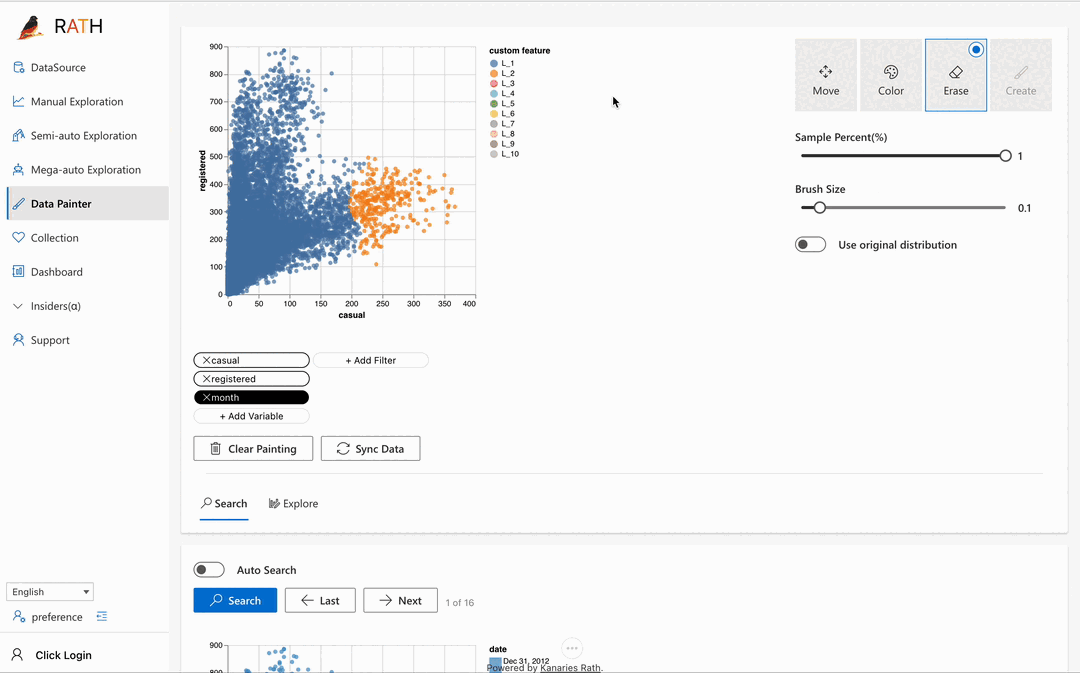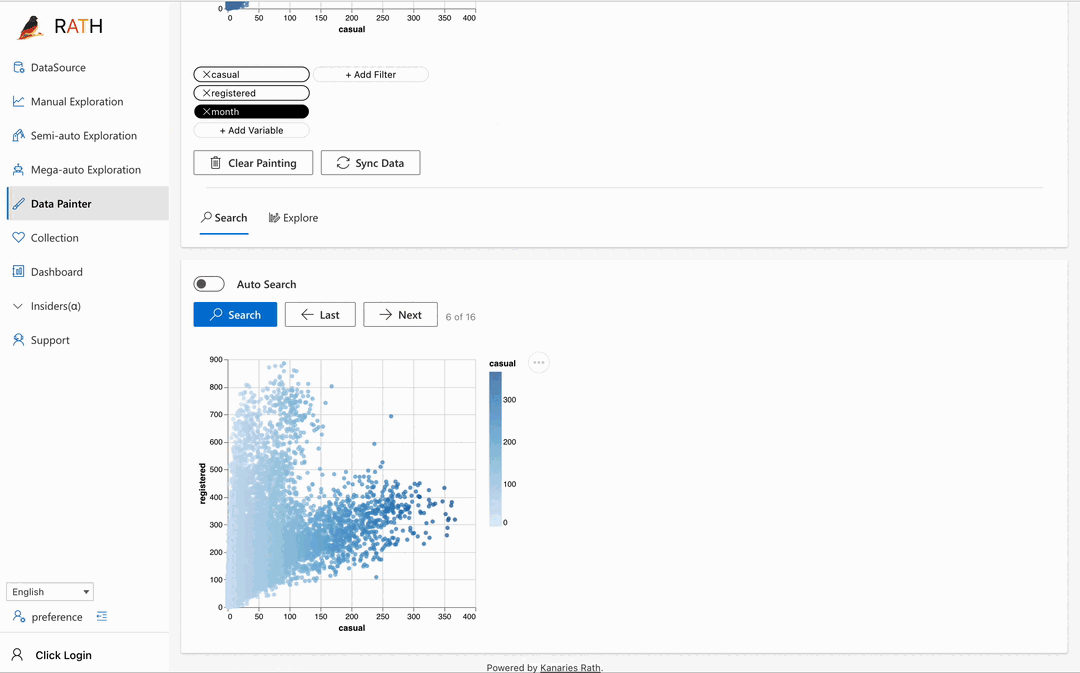 |
| Dashboard | Erstellen Sie ein schönes interaktives Daten-Dashboard (einschließlich eines automatisierten Dashboard-Designers, der Vorschläge für Ihr Dashboard machen kann). | 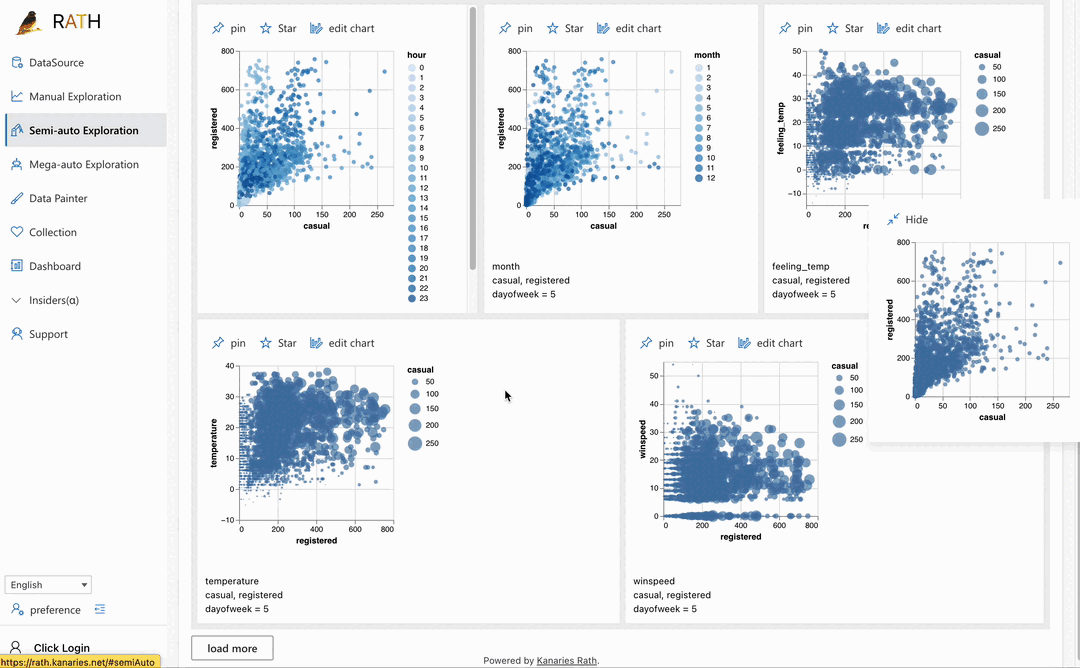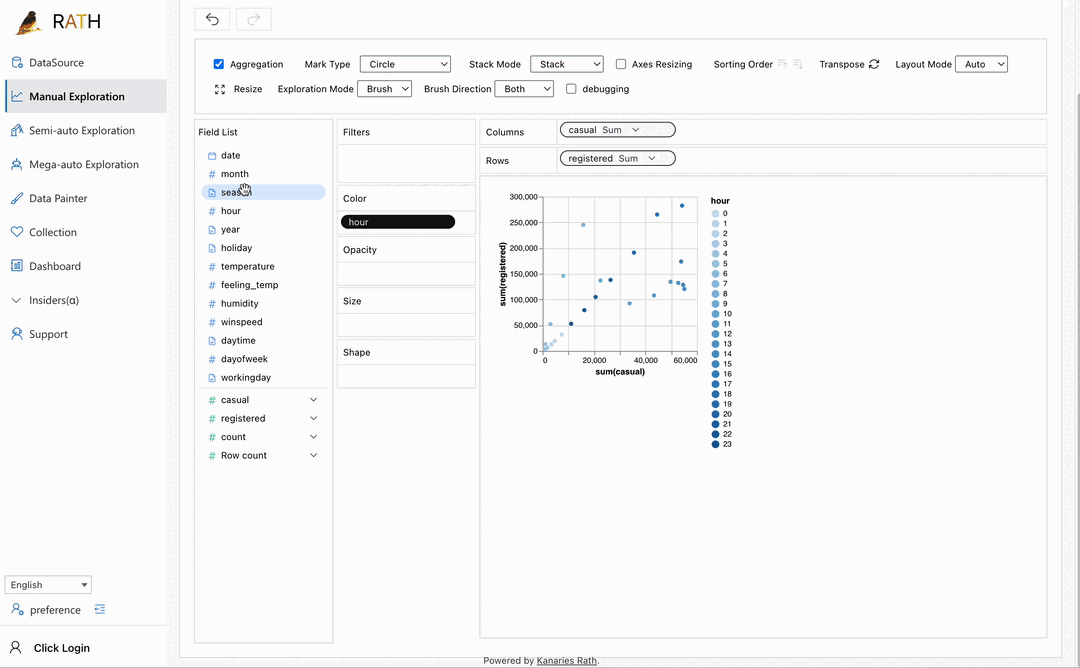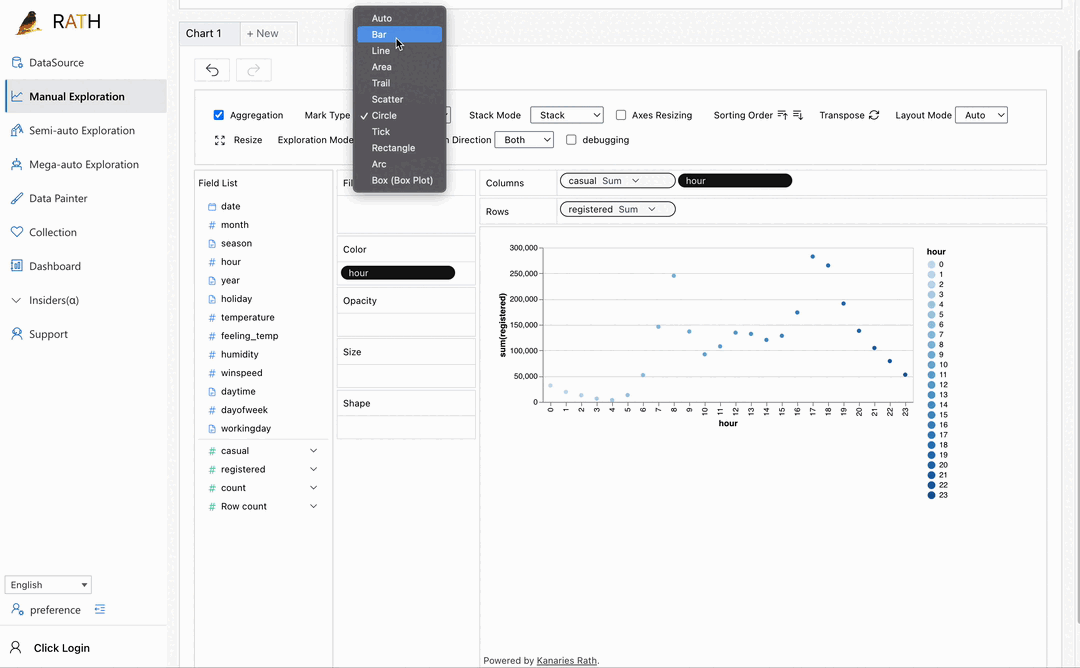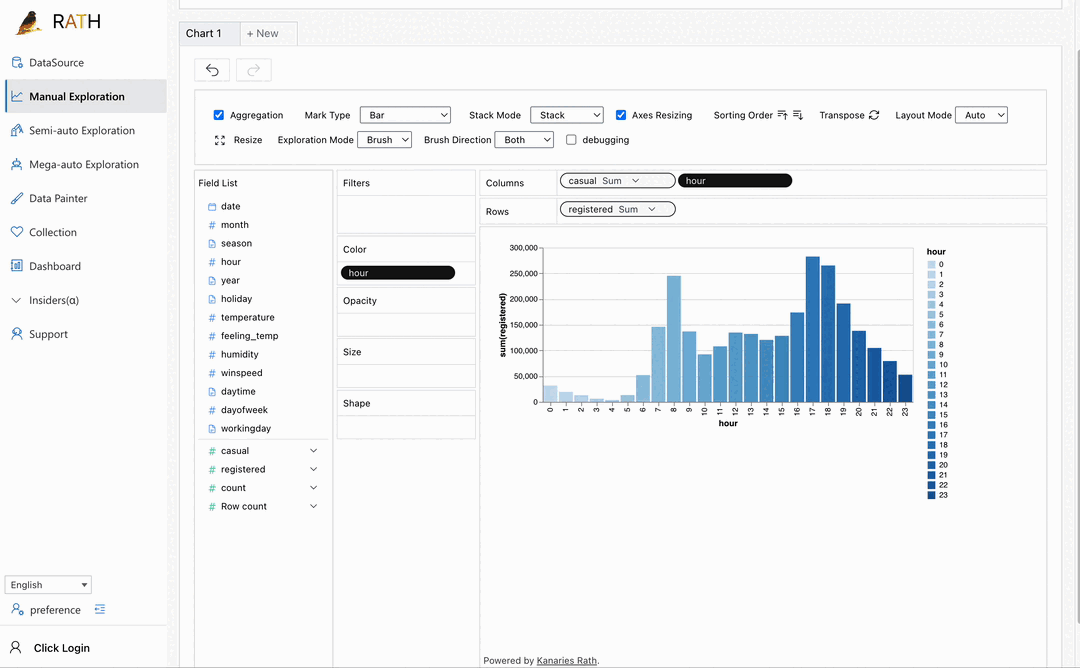 |
| Kausalanalyse | Ermittlung und Erklärung von kausalen Zusammenhängen für komplexe relationale Analysen. | 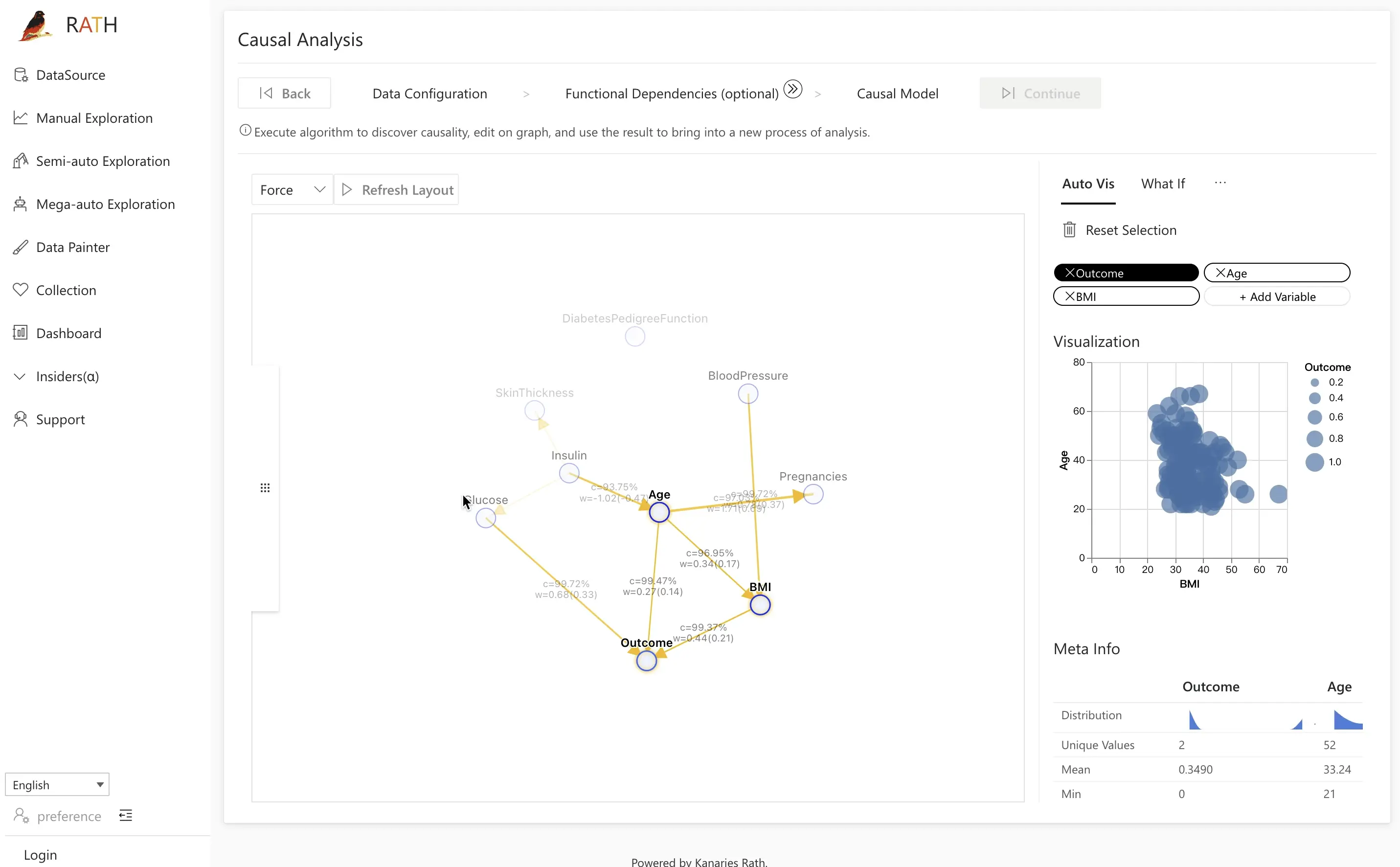 |
Fazit
Zusammenfassend ist ChatGPT ein leistungsstarkes Tool zur Generierung effizienter SQL-Abfragen. Es kann schnell komplexe Abfragen für die Datenaggregation, -filterung und -optimierung generieren und so das Risiko von Fehlern verringern und Zeit für den Benutzer sparen.
Neben den Fähigkeiten von ChatGPT zur Generierung effizienter SQL-Abfragen gibt es auch RATH, ein Open-Source-Tool, das den Workflow der Exploratory Data Analysis (EDA) automatisiert und automatisierte Datenexploration, Visualisierung und halbautomatische Exploration bietet, um die Datenanalyse effizienter und effektiver zu gestalten.