2026 年 Hermes Agent vs OpenClaw:关于运行时、记忆系统与 Agent 设计的深度分析

如果只想先记住一句话,可以先记这个版本:Hermes Agent 不是一个“又一个 agent CLI”,OpenClaw 也不是一个“又一个开源 bot 壳”。它们都属于更大的 personal AI agent 类别,但真正想占据的系统边界并不一样。Hermes 更像是在把 agent 本身做成一个可持续积累能力的运行时;OpenClaw 更像是在把 assistant 做成一个以 gateway、routing、session 和 delivery 为中心的 control plane。
这也是为什么这个对比现在变得更重要了。今天的 agent 竞争,已经不只是“谁能 demo 一个更酷的 tool call”,而是“哪套 runtime 假设在真实运维、真实计费和真实产品策略变化之下仍然成立”。
- Runcell Science:面向科研的开源 Claude Science 替代方案
- Mac 怎么不休眠:合盖继续运行 Codex、Claude Code 和本地 AI Agent
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot:2026 年该选哪个 AI Agent 技术栈?
- Claude Code 能分析 Jupyter Notebook 吗?Data Science 场景下它到底做了什么
- Claude Code Routines 是什么?AI Agent 定时任务与自动触发指南
- Claude Code Desktop 绕过权限:如何开启 Bypass permissions
- 如何用 Google 的 A2A 协议构建两个 Python Agent:一步步教程
- 2025 年 Python 增长最快的 10 个数据可视化库
快速答案:Hermes Agent 和 OpenClaw 到底该看谁?
如果你只看一节,看这里就够了。
| 如果你更看重... | 更应该先看谁 | 原因 |
|---|---|---|
| 一个覆盖终端、消息平台、编辑器集成、记忆、技能和自动化的统一运行时 | Hermes Agent | Hermes 建立在一个共享 runner 和统一 runtime 模型之上 |
| 一个围绕 channel、session、routing 和平台行为来组织的 personal assistant 平台 | OpenClaw | OpenClaw 的架构重心明显落在 gateway 和会话路由上 |
| 训练、trajectory 生成和 RL / data generation 的相邻能力 | Hermes Agent | Hermes 官方文档明确把环境框架、benchmark 和 rollout 基础设施作为一等能力 |
| 一个已经有巨大生态体量和高公共可见度的 assistant 项目 | OpenClaw | OpenClaw 目前仍然是更大、更成熟的公共项目 |
如果你在进入这篇文章之前还想看更宽一点的背景,2026 年最佳 Vibe Coding 工具 是更适合的市场总览。如果你的真实工作发生在 Jupyter notebook,而不是通用 agent 框架里,Jupyter AI RunCell 会更直接。
为什么现在再看这个对比,比几个月前重要得多
Hermes Agent 本身的热度就足够高。到 2026-04-15 为止,官方 NousResearch/hermes-agent 仓库大约有 87.5k GitHub stars、11.9k forks,v0.9.0 刚在 2026-04-13 发布。这已经足够让它成为一个值得研究的项目。
但 Hermes 的上升并不是在真空中发生的。OpenClaw 最近也经历了几件足够改变市场判断的事情。
第一件,是组织层面的变化。Peter Steinberger 在 2026 年 2 月 14 日 发布文章,明确表示自己将加入 OpenAI,同时 OpenClaw 会转入 foundation 结构,并继续保持开源和独立。这件事立刻改变了很多人看 OpenClaw 的方式。它不再只是一个爆红的开源 assistant,也成了“大模型公司如何进入 personal agents”这个更大叙事的一部分。
第二件,是经济和运维层面的不确定性。Anthropic 当前帮助中心的公开表述很清楚:付费 Claude 订阅主要面向 Anthropic 自家的原生应用,包括 Claude 网页端、桌面端、移动端以及 Claude Code;如果你要通过第三方工具访问 Anthropic 服务,更推荐的路径是 API key 或受支持的云平台认证。Anthropic 还保留把某些第三方工具流量计入 Extra Usage,而不是订阅额度的权利。
这件事为什么重要?因为很多 OpenClaw 用户过去默认把 Claude 订阅当成驱动第三方 agent 工作流的一条现实路径。到了 2026-04 前后,这条路径明显变得更不稳定。OpenClaw 自己现在的 Anthropic 和 OAuth 文档也反映了这种变化:一方面它把 Anthropic API key 描述成最清晰、最可预测的生产路径;另一方面它又写到 Anthropic staff 后来告诉他们 OpenClaw 风格的 Claude CLI 使用“又被允许了”。这不是一个简单粗暴的“彻底封禁”故事。更准确的结论是:
通过第三方 agent 框架稳定、低成本地使用 Claude,这件事在运营上和计费上都变得更不确定了。
而这正是用户会重新认真看 Hermes 这类替代方案的原因。
Hermes Agent 到底是什么
理解 Hermes 最有用的方法,不是把它看成一个界面,也不是把它看成一个 bot。
更准确的说法是:Hermes 是一个 Python 写成的 agent runtime,而它的多个入口都坐落在同一个核心循环之上。
这件事为什么重要?因为它解释了 Hermes 为什么会给人一种“整体性”很强的感觉。很多 agent 项目也会同时做 CLI、做 bot、做插件,但这些入口背后往往不是同一套 runtime。Hermes 明显是在尽量维持同一种 session 观、同一种 memory 观、同一种 tool runtime 观。
它真正想提供的是:
- 一个 CLI
- 一个消息网关
- ACP 编辑器集成
- 记忆与召回
- 技能系统
- cron 式自动化
但这些东西不是松散拼起来的,而是围绕一个共享运行时组织起来的。
第一个关键机制:runner 才是系统中心
如果把 Hermes 的架构压缩成一个最重要的设计决策,那就是:runner 是中心。
整个 conversation loop 把 prompt 组装、provider 选择、tool dispatch、context compression、重试和持久化都当成同一个 runtime 问题来处理。这样做的结果是,Hermes 可以在不同表面上尽量维持统一的语义:什么叫 session,什么叫 memory,什么叫 tool,什么叫一个 turn 的完成。
这也是为什么 Hermes 和很多“看起来有很多功能”的 agent 仓库给人的感觉不一样。它不是每个入口各长各的,而是更像一个有中心的系统。
Hermes 里的 memory 不是装饰功能,而是运行时原语
Hermes 很喜欢讲 memory 和 self-improving,但真正重要的不是这些词本身,而是 memory 在系统中的位置。
在 Hermes 里,memory 参与的不是某一个角落功能,而是很多关键环节:
- prompt 构建时的记忆注入
- turn 前的 prefetch
- turn 后的同步
- memory-aware 的工具 schema
- delegation 观察
- 压缩前的 hook
这意味着 Hermes 的 memory 不是“记住你喜欢什么”的附属特性,而是系统如何延续状态、如何提升下一次表现、如何控制长程上下文的一部分基础设施。
“自我改进”真正指的是什么
这里非常值得澄清,因为这是最容易被误读的地方。
Hermes 看起来并不是在用户会话中实时更新模型权重,也不是某种神奇的在线训练系统。
它的“自我改进”如果说得更准确一点,应该理解成:
- 它会存储并召回有价值的上下文
- 它会沉淀可复用的技能
- 它会在后续工作中重用这些技能
- 它会生成有助于后续训练和评测的 trajectory
这当然仍然很有意义。只是它属于 runtime learning 和 workflow accumulation,而不是“模型一边对话一边自我训练”的神话。
Hermes 对热路径是有意识的
Hermes 的另一个突出点,是它明显不只是为了堆功能,而是对 runtime 行为本身有工程意识。
这里至少有两个值得讲的模式:
第一,system prompt 的组织方式强调 cache stability。identity、memory、skills、context files、模型相关指导这些层,会尽量围绕稳定前缀组织,而不是每一轮都暴力重拼。
第二,memory 和 dialectic 一类的上下文检索可以通过 prefetch 移出当前 turn 的热路径,而不是总是在模型调用前硬阻塞。这个设计非常有信号量。它说明 Hermes 考虑的问题不只是“模型会不会做”,而是“昂贵的上下文工作应该在哪个阶段发生,才能让真实响应路径保持可用”。
这类决策通常只会出现在把 agent 当成基础设施来设计的团队里。
Hermes 的 tool system 也更像 runtime,而不是函数袋子
很多 agent 项目一旦工具变多,工具层就会失控:schema 漂移、入口各自理解、命名冲突、执行逻辑越来越难以推断。
Hermes 在这点上显得更克制。它把工具纳入一个更受控的系统里:
- 有中心化 registry
- 用共享 schema 和 handler 管理工具
- 在统一位置做 availability check
- 对冲突和覆盖有明确处理
执行层面也一样。Hermes 不是天真地“所有都并发”。安全的 batch 可以并发跑,但有破坏性或路径重叠风险的操作会回退到串行路径。这种取舍本身就是 runtime discipline 的体现。
很多人会忽略的一点:Hermes 也是研究基础设施
从外部看,很多人会把 Hermes 理解成“一个更完整的 assistant 项目”。这不算错,但不完整。
Hermes 的官方开发者文档明确把环境框架和 Atropos 风格的 RL 训练、评测工作流连接起来,而且直接列出了三种用途:
- RL training
- benchmarks
- 基于 agent rollout 的 SFT 数据生成
这会明显改变我们理解 Hermes 的方式。它不只是想成为一个“能用的 agent 产品”,也想成为一个“可用于 agent 研究、评测和数据生成的底座”。
这种双重身份,是 Hermes 在最近几个月里变得特别有意思的一个关键原因。
那它和 OpenClaw 的差异到底在哪里?
表面上看,Hermes 和 OpenClaw 都像是 broad personal-agent stacks。它们都关心消息平台、session、tools,也都在试图超出单一聊天框的能力边界。
但它们的中心引力不同。
OpenClaw 更容易被理解成一个 gateway-first 的 assistant architecture。它的文档把 routing、session key、channel 行为、真实平台交付和 gateway 行为放在非常核心的位置。连测试体系也在强调:
- unit / integration / e2e / live
- gateway smoke
- channel behavior
- WebSocket / HTTP surfaces
- agent reliability evals
Hermes 则更像一个统一 runtime,同时再向外暴露 gateway。runner、prompt system、memory manager、tool registry、ACP adapter 和 research environments 全都指向同一个方向:Hermes 想拥有的是完整的 runtime boundary,而不仅仅是 communication layer。
把这个差异压缩成表格,会更清楚:
| 维度 | Hermes Agent | OpenClaw |
|---|---|---|
| 核心抽象 | 一体化 agent runtime | 以 gateway 为中心的 assistant 平台 |
| 架构重心 | runner + memory + tool runtime | gateway + routing + session control |
| 表面模型 | CLI、gateway、ACP、cron 和 skills 共用一套 runtime | assistant 行为围绕 gateway 和 channel / session 模型展开 |
| 学习叙事 | memory、skills、持久化、rollout 和 eval 相邻性 | 产品行为、路由和运行可靠性 |
| 最适合的技术理解方式 | runtime design | control-plane design |
这不是“谁更高级”的问题,而是“它们分别想占哪一层”的问题。
这里真正创新的地方是什么?
这类文章最容易犯的错误,就是只写 feature list。
更有用的问题其实是:每个项目真正创新的对象到底是什么?
对 Hermes 来说,最有辨识度的不是某一个界面细节,而是它试图把 agent 本身变成一个一致的 runtime boundary:
- 一套 loop
- 一套 memory story
- 一套 tool runtime
- 多个 surface
- 在同一个体系里同时服务产品使用和研究使用
对 OpenClaw 来说,最有辨识度的创新对象则不同。它更像是在解决:一个 assistant 怎样跨越真实 channels、真实 routing 规则、真实 delivery surface 和真实 operator constraints 稳定工作。
所以这不是一篇“谁功能更多”的对比文,而是一篇关于设计哲学的对比文。
一些很容易出现的误读
如果只是快速扫一眼两个项目,读者很容易犯下面几个错误。
1. 把 Hermes 当成另一个 coding-agent CLI
不对。CLI 只是它的一个入口,不是它的全部。
2. 以为 Hermes 的自我改进等于实时在线训练
也不对。它更接近 memory、skills 和 rollout 层面的积累。
3. 以为 Hermes 只是 Python 版 OpenClaw
这也不对。Hermes 确实有 OpenClaw 迁移路径,但它的 runtime 架构中心和系统边界并不一样。
4. 以为 OpenClaw 只是一个 bot wrapper
同样不对。OpenClaw 的 gateway、session routing、channel model 和测试体系都比这个说法深得多。
这些澄清很重要,因为只有纠正了这些误读,读者才能站在正确层面比较这两个系统。
如果你的真实工作场景在 Jupyter 里,那更值得看的其实可能是 RunCell
这里还有一个非常实际、但也很容易被忽略的分叉。
很多人在比较 Hermes Agent 和 OpenClaw 这类通用 agent 框架时,表面上是在选“哪一个 agent 更强”,但他们真实要解决的问题,其实是:
- 我怎么在 notebook 里更快完成分析?
- 我怎么让 agent 真正理解 DataFrame、变量状态和 cell 输出?
- 我怎么让它帮我调试、执行、迭代,而不是只给我一段代码片段?
如果这是你的真实问题,那么一个 notebook-native 的 agent,往往会比通用 agent runtime 更有意义。
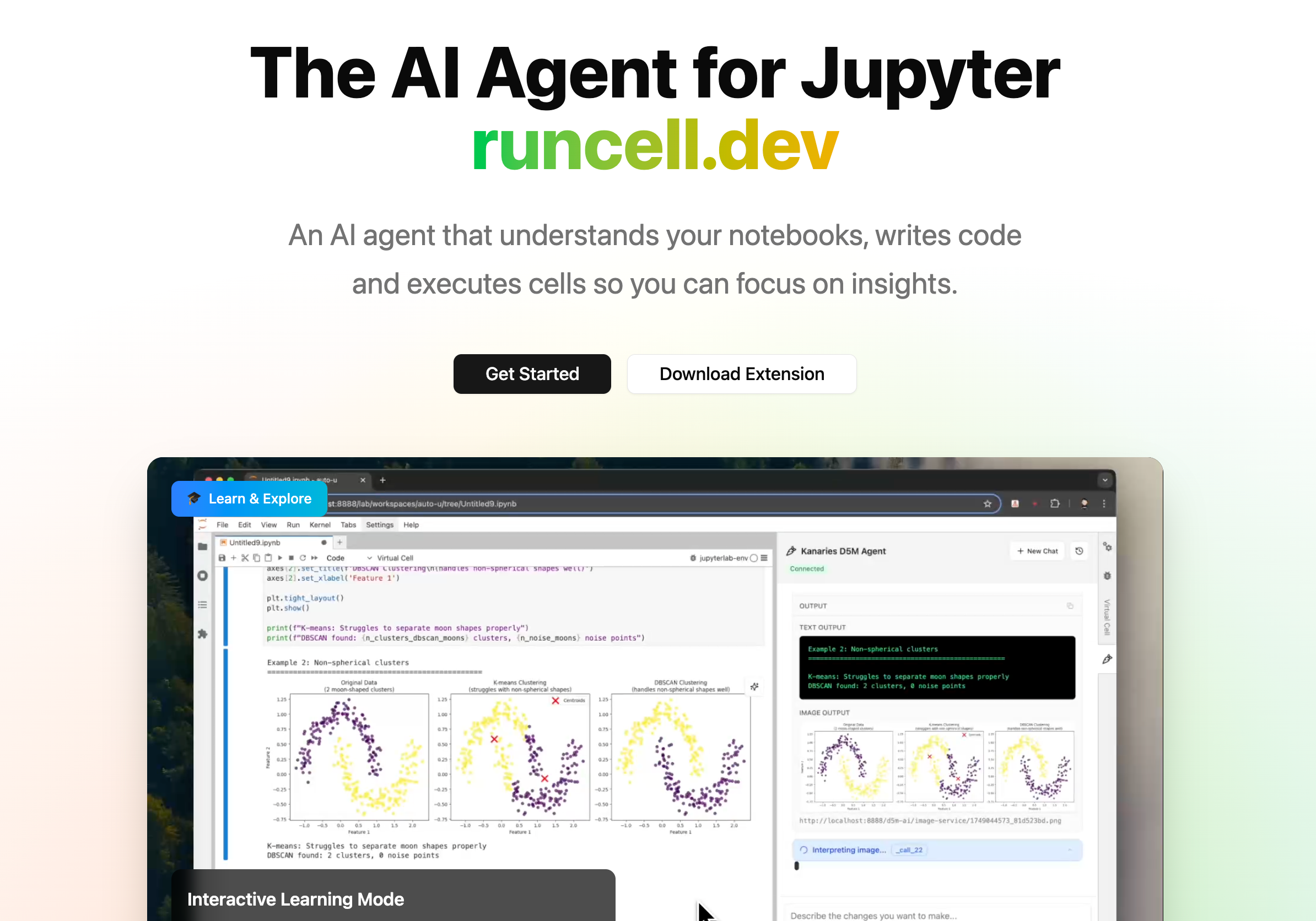
这也是 RunCell (opens in a new tab) 值得被放进这个讨论里的原因。RunCell 本质上是一个运行在 Jupyter 里的 Data Science Agent,而这恰好是很多通用 agent 非常不擅长处理的环境。它不是把 notebook 当成外部文本来理解,而是直接在 notebook 上下文里工作,所以它在下面这些事情上会自然得多:
- 理解 cell、变量、输出和 DataFrame 的状态
- 处理 Jupyter 环境里常见的执行、重跑和调试问题
- 基于数据本身做判断,而不是只生成“看起来像答案”的代码
这也是 RunCell 真正有意思的地方。它不是一个“另一个更大的通用 agent”,而是在一个非常具体、非常高价值的环境里,把问题做得更深:
- 它是 Jupyter-native,而不是 terminal-native
- 它特别擅长 notebook 场景的任务执行
- 它也特别擅长围绕数据本身做判断和分析
所以如果你脑子里的真实问题不是“我该押注哪一个通用 agent runtime”,而是“我今天在 notebook 里怎么更高效地完成数据工作”,那 RunCell 很可能比 Hermes 或 OpenClaw 更值得你马上试一下。
如果你想看更 notebook-specific 的视角,AI Agent 将 Jupyter Notebook 变成数据科学副驾驶 会更直接。如果你想看更广的编码工具市场背景,2026 年最佳 AI 编程工具 和 2026 年最佳 Vibe Coding 工具 是更好的延伸阅读。
Related Guides
- 2026 年最佳 AI 编程工具
- 2026 年最佳 Vibe Coding 工具
- Codex vs Claude Code
- 并行代码 Agent
- Jupyter AI RunCell
- OpenClaw Discord 设置指南
Sources
- Hermes Agent official repo: https://github.com/NousResearch/hermes-agent (opens in a new tab)
- Hermes Agent architecture docs: https://hermes-agent.nousresearch.com/docs/developer-guide/architecture (opens in a new tab)
- Hermes Agent environments docs: https://hermes-agent.nousresearch.com/docs/developer-guide/environments/ (opens in a new tab)
- OpenClaw official repo: https://github.com/openclaw/openclaw (opens in a new tab)
- Peter Steinberger on joining OpenAI: https://steipete.me/posts/2026/openclaw (opens in a new tab)
- OpenClaw channel routing docs: https://docs.openclaw.ai/channels/channel-routing (opens in a new tab)
- OpenClaw Anthropic provider docs: https://docs.openclaw.ai/providers/anthropic (opens in a new tab)
- OpenClaw OAuth docs: https://docs.openclaw.ai/concepts/oauth (opens in a new tab)
- OpenClaw testing docs: https://docs.openclaw.ai/help/testing (opens in a new tab)
- Anthropic account login/help article: https://support.claude.com/en/articles/13189465-logging-in-to-your-claude-account (opens in a new tab)
- Anthropic Pro or Max Claude Code article: https://support.claude.com/en/articles/11145838-using-claude-code-with-your-pro-or-max-plan (opens in a new tab)
- TechCrunch on Peter Steinberger’s temporary suspension: https://techcrunch.com/2026/04/10/anthropic-temporarily-banned-openclaws-creator-from-accessing-claude/ (opens in a new tab)
FAQ
Hermes Agent 是什么?
Hermes Agent 是一个由 Nous Research 构建的一体化 agent runtime。它把共享 runner、memory、tools、messaging、ACP 集成、skills 和 automation 组织在同一个系统里。
OpenClaw 是什么?
OpenClaw 是一个 personal assistant 平台,它的架构中心是一个长期运行的 gateway,以及围绕 session routing、channel behavior 和 delivery 展开的控制面。
Hermes Agent 是 OpenClaw 的直接替代品吗?
不完全是。Hermes 和 OpenClaw 确实足够相似,值得被拿来比较,但它们优化的系统边界不同。Hermes 更 runtime-centric,OpenClaw 更 gateway-centric。
为什么这个对比在 2026 年特别重要?
因为 OpenClaw 最近经历了创始人和生态层面的变化,而 Anthropic 对第三方 Claude 使用路径的政策与计费也变得更不确定,这推动更多用户重新评估替代方案。
Hermes Agent 的“自我改进”是真的吗?
从实践意义上说是成立的,但不是通过实时改模型权重实现的。它的改进回路更多来自 memory、可复用 skills、累积上下文,以及用于后续训练和评测的 rollout 生成。
什么时候 RunCell 比 Hermes Agent 或 OpenClaw 更合适?
当你的真实工作发生在 Jupyter notebook 里时,RunCell 更合适。它是 notebook-native 的,擅长 stateful debugging、DataFrame-aware analysis 和数据科学工作流。