Dominando la Visualización de Dataframes en Python con Pandas
- Name
- Rajiv Chandra
Updated on
La visualización de dataframes es una herramienta poderosa en el arsenal de cualquier científico de datos o analista de datos. Nos permite entender conjuntos de datos complejos y extraer información que puede no ser evidente de los datos en bruto. En este artículo, te guiaré a través del proceso de visualizar dataframes utilizando Python, con un enfoque particular en la biblioteca pandas. Cubriremos todo, desde lo básico hasta técnicas más avanzadas, proporcionando muchos ejemplos de código en el camino.
¿Por qué visualizar dataframes?
La visualización de datos es un aspecto esencial del análisis exploratorio de datos. Nos ayuda a identificar tendencias, patrones y valores atípicos en los datos de forma rápida. Además, la visualización de datos presenta los resultados de nuestro análisis de una manera más efectiva, lo que fomenta la discusión en torno a estos resultados, en lugar de presentar solo los números.
Por ejemplo, imagina que estás trabajando con un conjunto de datos grande que contiene información sobre la población de una ciudad a lo largo de varios años. Si bien podrías revisar los datos línea por línea, sería mucho más eficiente e intuitivo crear un gráfico de línea que muestre los cambios en la población a lo largo del tiempo. Aquí es donde entra en juego la visualización de dataframes.
PyGWalker: Visualización de Dataframes mediante Arrastrar y Soltar
Si estás buscando una herramienta poderosa e intuitiva de visualización de datos interactiva para Python, no busques más allá de PyGWalker. Pronunciado como "Pig Walker", PyGWalker significa "Python binding of Graphic Walker". Integra Jupyter Notebook con Graphic Walker, una alternativa de código abierto a Tableau, lo que permite a los científicos de datos analizar datos y visualizar patrones mediante operaciones sencillas de arrastrar y soltar.

Para comenzar con PyGWalker, primero debes instalarlo. Puedes hacerlo a través de pip o conda:
# Usando pip
pip install pygwalker
# Usando conda
conda install -c conda-forge pygwalkerUna vez instalado, puedes importar PyGWalker y pandas en tu Jupyter Notebook:
import pandas as pd
import pygwalker as pygCon PyGWalker, puedes convertir tu dataframe de pandas en una interfaz de usuario similar a Tableau para la exploración visual. Por ejemplo, si tienes un dataframe cargado en pandas, puedes llamar a Graphic Walker con el dataframe de esta manera:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Esto creará una interfaz de usuario similar a Tableau donde puedes analizar y visualizar datos arrastrando y soltando variables. Puedes cambiar el tipo de marca para crear diferentes gráficos, crear una vista de concatenación para comparar diferentes medidas e incluso guardar el resultado de tu exploración de datos en un archivo local.
Ahora que has configurado PyGWalker, puedes utilizarlo para una potente visualización de datos. Cambia el tipo de marca para crear diferentes tipos de gráficos, como un gráfico de líneas:

Compara diferentes medidas creando una vista de concatenación con múltiples medidas en filas/columnas:

Crea una vista de facetas con múltiples subvistas divididas por un valor de dimensión:
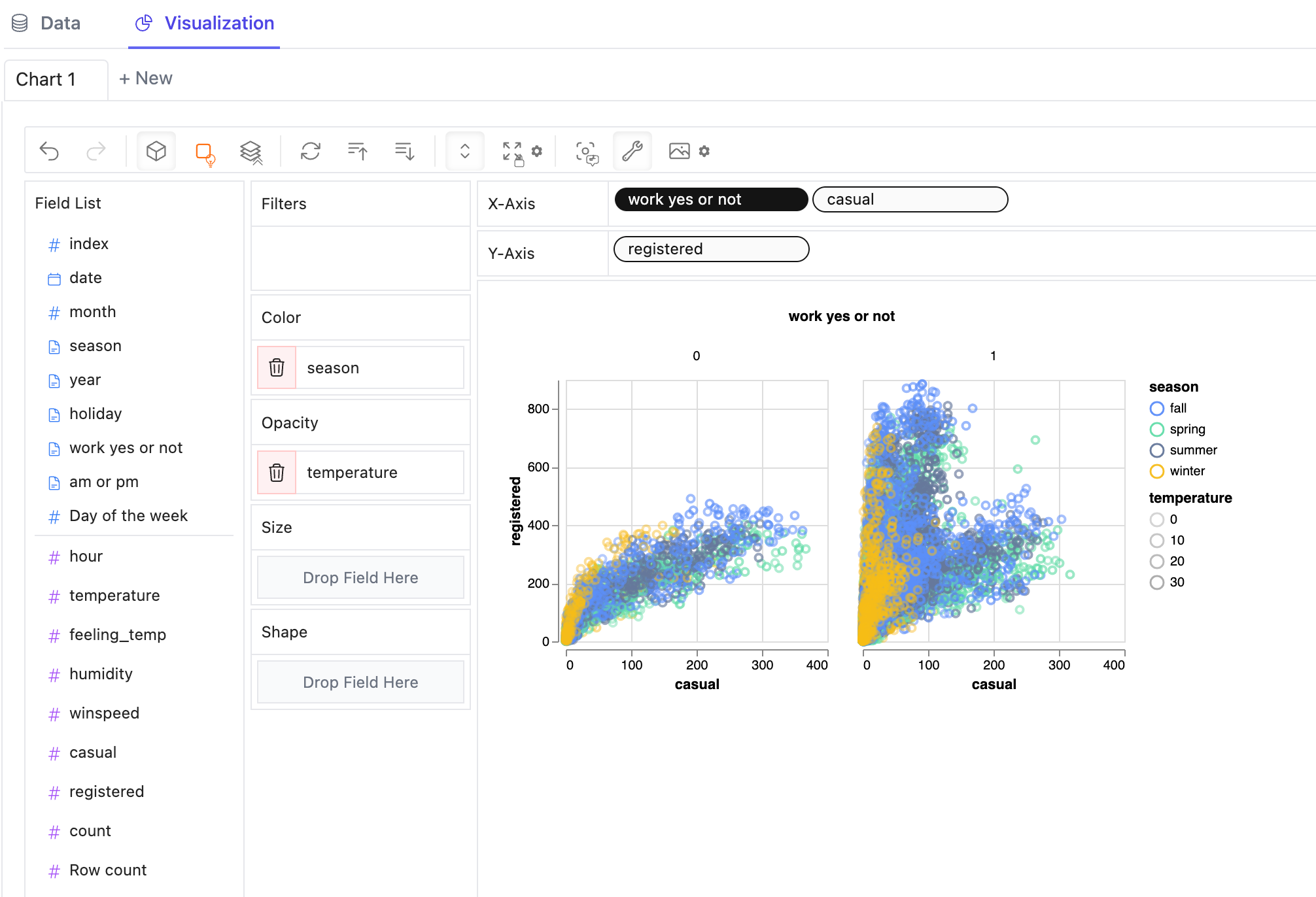
Visualiza tu dataframe en una tabla y configura tipos analíticos y tipos semánticos:

PyGWalker no solo es fácil de usar, sino también poderoso. Puede manejar conjuntos de datos grandes y visualizaciones complejas. Ya sea que estés trabajando con un conjunto de datos pequeño o grande, PyGWalker puede ayudarte a explorar y analizar tus datos de manera efectiva.
Si estás trabajando con dataframes en Python y necesitas una herramienta para la visualización de datos, PyGWalker es una excelente opción. Es fácil de usar, potente e se integra perfectamente con Jupyter Notebook y pandas. Entonces, ¿por qué no probarlo y ver cómo puede mejorar tu flujo de análisis y visualización de datos?
Echa un vistazo a la página de Github de PyGWalker (opens in a new tab).
Primeros Pasos con Pandas para la Visualización de Dataframes
La popular biblioteca de análisis de datos en Python, pandas, ofrece varias opciones diferentes para visualizar tus datos. Incluso si estás al principio de tu camino con pandas, pronto estarás creando gráficos básicos que te proporcionarán información valiosa sobre tus datos.
Para comenzar con pandas, primero debes importarlo. Así es cómo puedes hacerlo:
import pandas as pdUna vez que hayas importado pandas, puedes comenzar a utilizarlo para crear gráficos. Por ejemplo, si tienes un dataframe df con dos columnas A y B, puedes crear un gráfico de línea de A frente a B de la siguiente manera:
df.plot(x='A', y='B',
kind='line')Esto creará un gráfico de línea con 'A' en el eje x y 'B' en el eje y. El parámetro kind determina el tipo de gráfico a producir. En este caso, estamos creando un gráfico de línea, pero también podrías crear un gráfico de barras, un histograma, un gráfico de dispersión y más.
Diferentes Formas de Visualizar Dataframes en Pandas
Pandas proporciona una variedad de formas de visualizar dataframes, cada una adecuada para diferentes tipos de datos y diferentes tipos de preguntas. Veamos algunos de los tipos más comunes de gráficos que puedes crear con pandas.
Gráficos de Línea
Los gráficos de línea son ideales para visualizar cambios a lo largo del tiempo. Por ejemplo, si tienes un dataframe con una columna de fecha y una columna numérica, puedes usar un gráfico de línea para visualizar cómo cambia el valor numérico a lo largo del tiempo.
Aquí tienes un ejemplo:
df.plot(x='date', y='value', kind='line')Esto creará un gráfico de línea con 'date' en el eje x y 'value' en el eje y.
Gráficos de Barras
Los gráficos de barras son útiles para comparar cantidades entre diferentes categorías. Por ejemplo, si tienes un dataframe con una columna categórica y una columna numérica, puedes usar un gráfico de barras para comparar los valores numéricos entre diferentes categorías.
Así es cómo puedes crear un gráfico de barras:
df.plot(x='category', y='value', kind='bar')Esto creará un gráfico de barras con 'category' en el eje x y 'value' en el eje y.
Histogramas
Los histogramas son útiles para visualizar la distribución de una variable numérica. Dividen la variable en bins, cuentan la cantidad de observaciones en cada bin y representan estas cuentas con barras.
Así es cómo puedes crear un histograma de una columna numérica:
df['value'].plot(kind='hist')Esto creará un histograma de la columna 'value'.
Estrategias Avanzadas para la Visualización de Dataframes
Si bien las capacidades básicas de trazado de pandas son poderosas, también existen estrategias más avanzadas que pueden ayudarte a crear visualizaciones aún más informativas. Veamos algunas de estas técnicas.
Subplots
Los subplots te permiten crear múltiples gráficos en una única figura. Esto puede ser especialmente útil cuando deseas comparar varias distribuciones o tendencias al mismo tiempo. Aquí tienes un ejemplo de cómo puedes crear subplots en pandas:
df[['A', 'B', 'C']].plot(subplots=True)Esto creará tres subplots, uno para cada una de las columnas 'A', 'B' y 'C'.
Matriz de Dispersión
Una matriz de dispersión es un gráfico de dispersión par a par de varias variables presentado en un formato de matriz. Se puede utilizar para determinar si las variables están correlacionadas y si la correlación es positiva o negativa. En pandas, puedes crear una matriz de dispersión utilizando la función scatter_matrix del módulo pandas.plotting:
from pandas.plotting import scatter_matrix
scatter_matrix(df[['A
', 'B', 'C']])Esto creará una matriz de dispersión para las columnas 'A', 'B' y 'C'.
Visualización Interactiva de Dataframes con Pandas
Si bien los gráficos estáticos son útiles, los gráficos interactivos pueden proporcionar una comprensión más profunda de los datos al permitirte hacer zoom en áreas de interés, pasar el mouse sobre puntos para ver sus valores y más. Hay varias herramientas que pueden ayudarte a crear visualizaciones interactivas con pandas, como Qgrid y Lux.
Qgrid
Qgrid es un widget de Jupyter Notebook que utiliza el componente SlickGrid para agregar interactividad a tu dataframe. Te permite ordenar, filtrar y editar dataframes en Jupyter notebooks. Aquí tienes un ejemplo de cómo puedes usar Qgrid:
import qgrid
qgrid_widget = qgrid.show_grid(df, show_toolbar=True)
qgrid_widgetEsto creará una cuadrícula interactiva para el dataframe df.
Lux
Lux es una herramienta de visualización ligera que facilita la exploración de tus datos al recomendar automáticamente visualizaciones útiles y relevantes a medida que trabajas con tu dataframe de pandas. Así es cómo puedes usar Lux:
import lux
df.intent = ['A', 'B']
dfEsto generará automáticamente visualizaciones para las columnas 'A' y 'B' en el dataframe df.
Visualizando Datos Agrupados de un Dataframe
A menudo, es posible que desees agrupar tus datos por ciertas variables y visualizar los datos agrupados. Por ejemplo, es posible que desees agrupar un conjunto de datos de poblaciones de ciudades por año y visualizar el cambio de población a lo largo del tiempo. Así es cómo puedes hacerlo en pandas:
grouped = df.groupby('year')['population'].sum()
grouped.plot(kind='line')Esto creará un gráfico de línea de la población total para cada año.
Conclusión
En conclusión, la visualización de dataframes es una herramienta poderosa para el análisis de datos y la ciencia de datos. Con Python y pandas, puedes crear una amplia variedad de visualizaciones, desde gráficos básicos hasta visualizaciones más avanzadas e interactivas. Así que comienza a visualizar tus dataframes hoy mismo y descubre las ideas ocultas en tus datos.
Preguntas Frecuentes
-
¿Qué es la visualización de dataframes? La visualización de dataframes es el proceso de representar datos de un dataframe en un formato visual, como un gráfico o un diagrama. Esto ayuda a comprender los patrones, tendencias y correlaciones en los datos.
-
¿Cómo puedo visualizar un dataframe en Python? Python ofrece varias bibliotecas para visualizar dataframes, incluyendo pandas, matplotlib, seaborn y PyGWalker. Estas bibliotecas proporcionan funciones para crear varios tipos de gráficos, como gráficos de línea, gráficos de barras, histogramas y más.
-
¿Qué es la visualización de dataframes en pandas? La visualización de dataframes en pandas implica el uso de la biblioteca pandas en Python para crear representaciones visuales de datos almacenados en dataframes de pandas. Pandas proporciona una
función .plot() que se puede utilizar para crear varios tipos de gráficos.
-
¿Cuáles son algunas herramientas para la visualización de dataframes en pandas? Algunas herramientas populares para la visualización de dataframes en pandas incluyen pandas en sí, matplotlib, seaborn y herramientas interactivas como PyGWalker y Qgrid.
-
¿Se puede visualizar un dataframe de pandas con Plotly? Sí, Plotly es otra biblioteca en Python que se puede utilizar para crear gráficos interactivos para dataframes de pandas. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.