Cómo fusionar, unir y concatenar DataFrames de Pandas en Python

Fusionar, unir y concatenar DataFrames en pandas son técnicas importantes que te permiten combinar múltiples conjuntos de datos en uno solo. Estas técnicas son esenciales para limpiar, transformar y analizar datos. Fusionar, unir y concatenar se utilizan a menudo indistintamente, pero se refieren a diferentes métodos de combinación de datos. En esta publicación, discutiremos estas tres técnicas importantes en detalle y proporcionaremos ejemplos de cómo usarlas en Python.
- Runcell Science: alternativa open source a Claude Science para investigación
- Cómo evitar que Mac se duerma: mantener Codex, Claude Code y agentes de IA corriendo
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: ¿Qué stack de agentes de IA deberías elegir en 2026?
- Cómo Claude Code analiza notebooks de Jupyter en Data Science: lo que sí hace y lo que no
- Claude Code routines: qué son y por qué importan los cron jobs de agentes de IA
- Claude Code Desktop Bypass Permissions: cómo activarlo
- Cómo Construir Dos Agentes en Python con el Protocolo A2A de Google - Tutorial Paso a Paso
- Las 10 principales bibliotecas de visualización de datos en Python que crecen en 2025
Fusionar DataFrames en pandas
Fusionar es el proceso de combinar dos o más DataFrames en un solo DataFrame, vinculando filas en función de una o más claves comunes. Las claves comunes pueden ser una o más columnas que tengan valores coincidentes en los DataFrames que se fusionan.
Diferentes tipos de fusiones
Existen cuatro tipos de fusiones en pandas: interna, externa, izquierda y derecha.
- Fusión interna: Devuelve solo las filas que tienen valores coincidentes en ambos DataFrames.
- Fusión externa: Devuelve todas las filas de ambos DataFrames y completa los valores faltantes con NaN donde no hay una coincidencia.
- Fusión izquierda: Devuelve todas las filas del DataFrame izquierdo y las filas coincidentes del DataFrame derecho. Completa los valores faltantes con NaN donde no hay una coincidencia.
- Fusión derecha: Devuelve todas las filas del DataFrame derecho y las filas coincidentes del DataFrame izquierdo. Completa los valores faltantes con NaN donde no hay una coincidencia.
Ejemplos de cómo realizar diferentes tipos de fusiones
Veamos algunos ejemplos de cómo realizar diferentes tipos de fusiones utilizando Pandas.
Ejemplo 1: Fusión interna
import pandas as pd
# Crear dos DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Fusión interna
fusion_inner = pd.merge(df1, df2, on='key')
print(fusion_inner)Salida:
key value_x value_y
0 B 2 5
1 D 4 6Ejemplo 2: Fusión externa
import pandas as pd
# Crear dos DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# Fusión externa
fusion_outer = pd.merge(df1, df2, on='key', how='outer')
print(fusion_outer)Salida:
key value_x value_y
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0Ejemplo 3: Fusión izquierda
Una fusión izquierda devuelve todas las filas del DataFrame izquierdo y las filas coincidentes del DataFrame derecho. Cualquier fila del DataFrame izquierdo que no tenga una coincidencia en el DataFrame derecho tendrá valores NaN en las columnas del DataFrame derecho.
import pandas as pd
# Crear dos DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# Realizar una fusión izquierda
df_fusion_izquierda = pd.merge(df1, df2, on='key', how='left')
# Imprimir el DataFrame fusionado
print(df_fusion_izquierda)Salida:
key value_x value_y
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0Ejemplo 4: Fusión derecha
Una fusión derecha devuelve todas las filas del DataFrame derecho y las filas coincidentes del DataFrame izquierdo. Cualquier fila del DataFrame derecho que no tenga una coincidencia en el DataFrame izquierdo tendrá valores NaN en las columnas del DataFrame izquierdo.
import pandas as pd
# Crear dos DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# Realizar una fusión derecha
df_fusion_derecha = pd.merge(df1, df2, on='key', how='right')
# Imprimir el DataFrame fusionado
print(df_fusion_derecha)Salida:
key value_x value_y
0 B 2.0 5
1 D NaN 6
2 E NaN 7Unir DataFrames en pandas
Unir es un método para combinar dos DataFrames en uno solo en función de sus índices o valores de columna.
Existen cuatro tipos de uniones en pandas: interna, externa, izquierda y derecha.
- Unión interna: Devuelve solo las filas que tienen valores de índice o columna coincidentes en ambos DataFrames.
- Unión externa: Devuelve todas las filas de ambos DataFrames y completa los valores faltantes con NaN donde no hay una coincidencia.
- Unión izquierda: Devuelve todas las filas del DataFrame izquierdo y las filas coincidentes del DataFrame derecho. Completa los valores faltantes con NaN donde no hay una coincidencia.
- Unión derecha: Devuelve todas las filas del DataFrame derecho y las filas coincidentes del DataFrame izquierdo. Completa los valores faltantes con NaN donde no hay una coincidencia.
Concatenar DataFrames en pandas
Concatenar es el proceso de unir dos o más DataFrames ya sea vertical u horizontalmente. En pandas, esto se puede lograr utilizando la función concat(). La función concat() te permite combinar dos o más DataFrames en un solo DataFrame apilándolos ya sea vertical u horizontalmente.
Ejemplos de cómo concatenar dos o más DataFrames utilizando pandas
Para concatenar dos o más DataFrames verticalmente, puedes usar el siguiente código:
import pandas as pd
# Crear dos DataFrames de muestra
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
# Concatenar los DataFrames verticalmente
result = pd.concat([df1, df2])
print(result)Output:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D7Para concatenar dos o más DataFrames horizontalmente, puedes usar el siguiente código:
import pandas as pd
# Crear dos DataFrames de muestra
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'E': ['E0', 'E1', 'E2', 'E3'],
'F': ['F0', 'F1', 'F2', 'F3'],
'G': ['G0', 'G1', 'G2', 'G3'],
'H': ['H0', 'H1', 'H2', 'H3']})
# Concatenar los DataFrames horizontalmente
result = pd.concat([df1, df2], axis=1)
print(result)Output:
A B C D E F G H
0 A0 B0 C0 D0 E0 F0 G0 H0
1 A1 B1 C1 D1 E1 F1 G1 H1
2 A2 B2 C2 D2 E2 F2 G2 H2Crear una vista de concatenación para DataFrames de Pandas
Para crear vistas de concatenación dentro de Python, hay un paquete de Análisis de Datos y Visualización de Datos de código abierto que puede cubrir tus necesidades: PyGWalker.
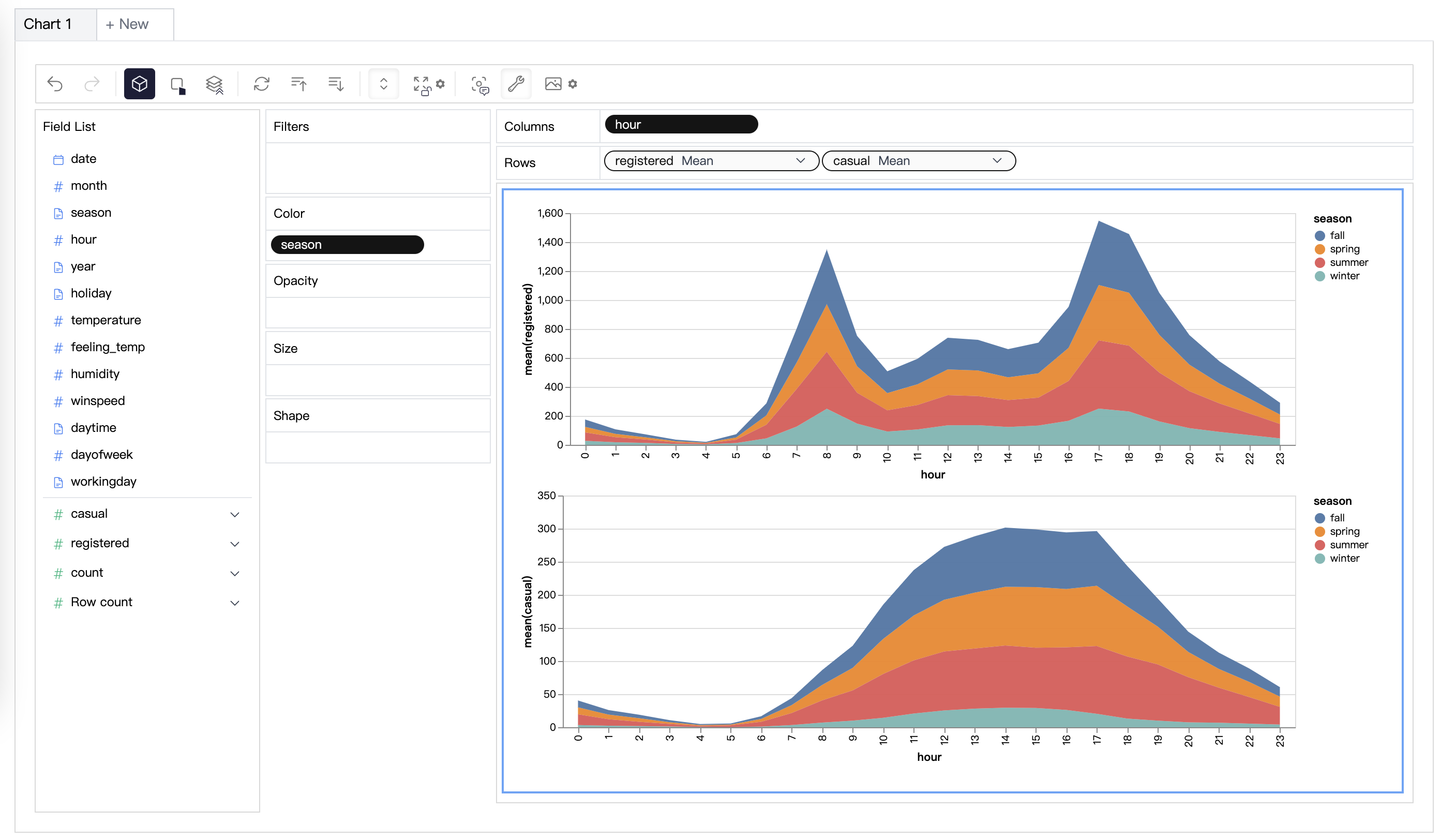
PyGWalker puede simplificar tu flujo de trabajo de análisis y visualización de datos en Jupyter Notebook. Al proporcionar una interfaz ligera y fácil de usar en lugar de analizar los datos utilizando Python. Los pasos son sencillos:
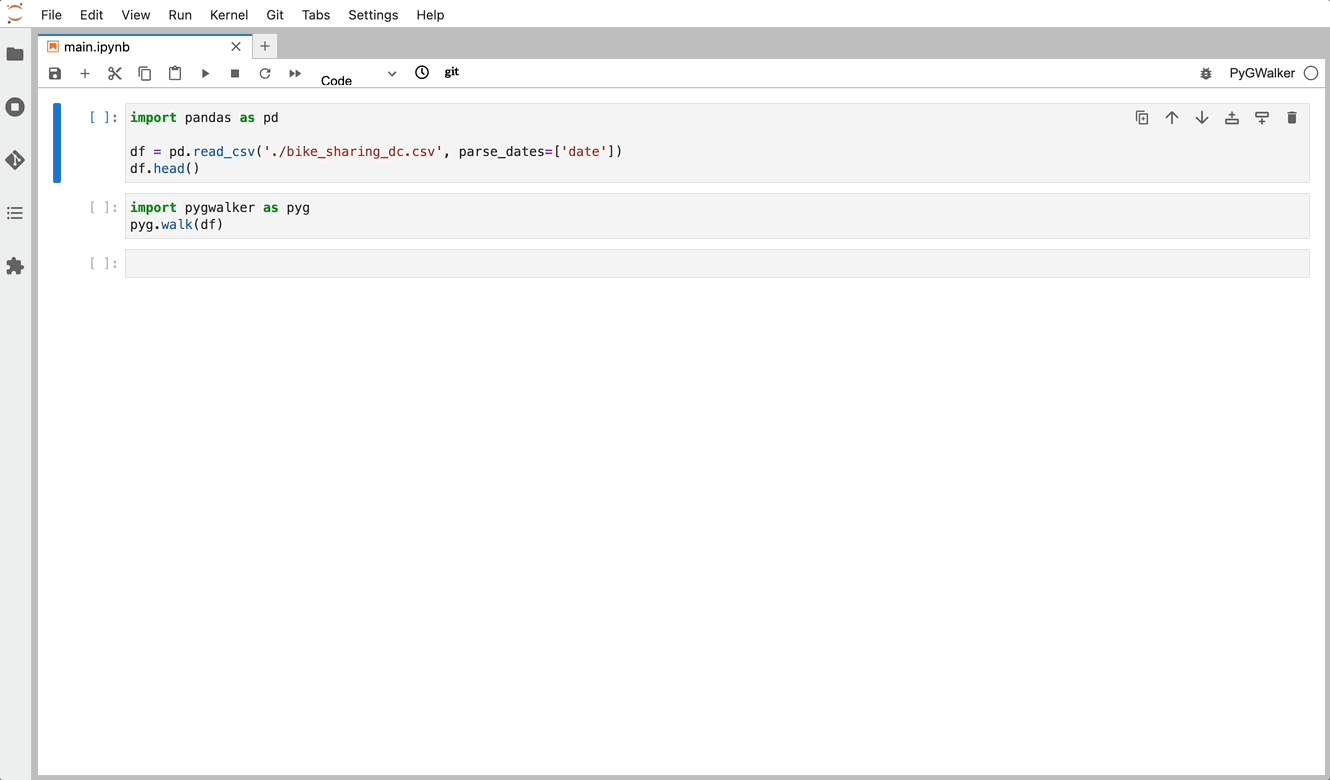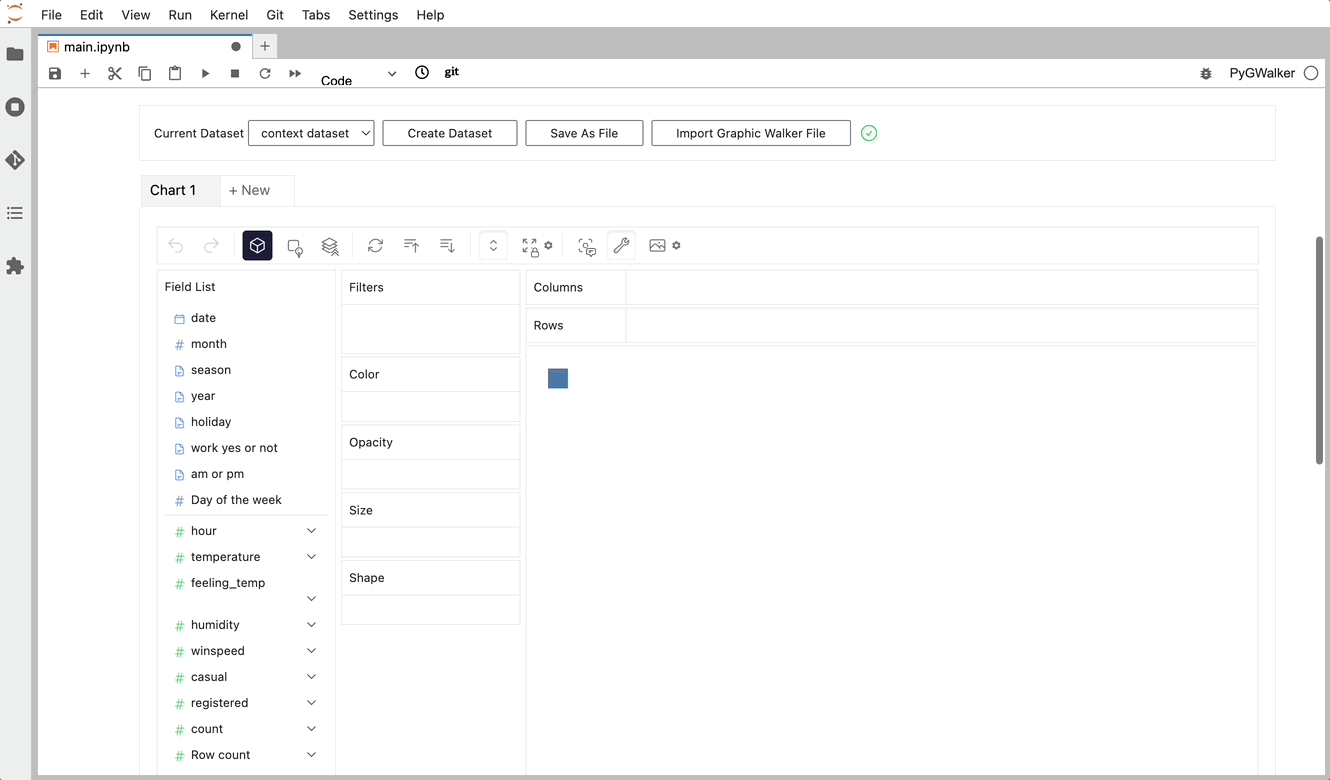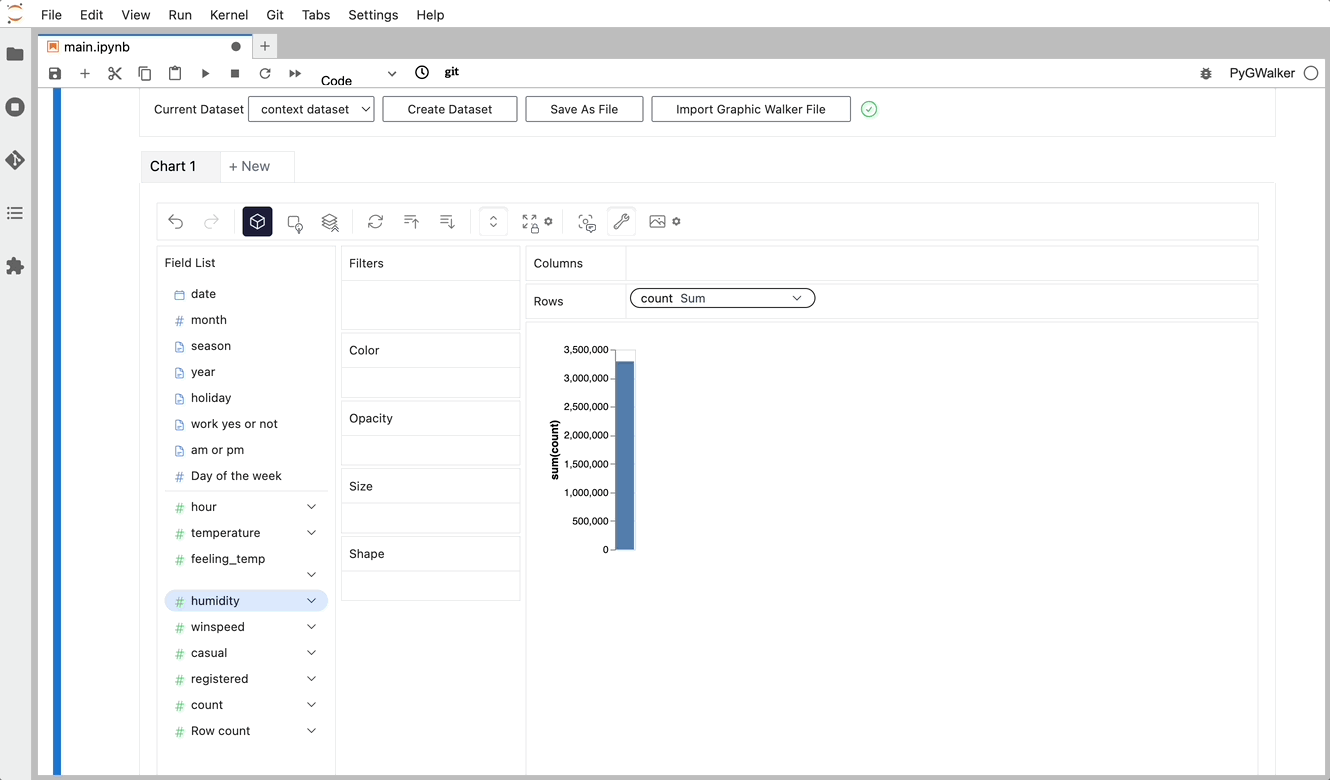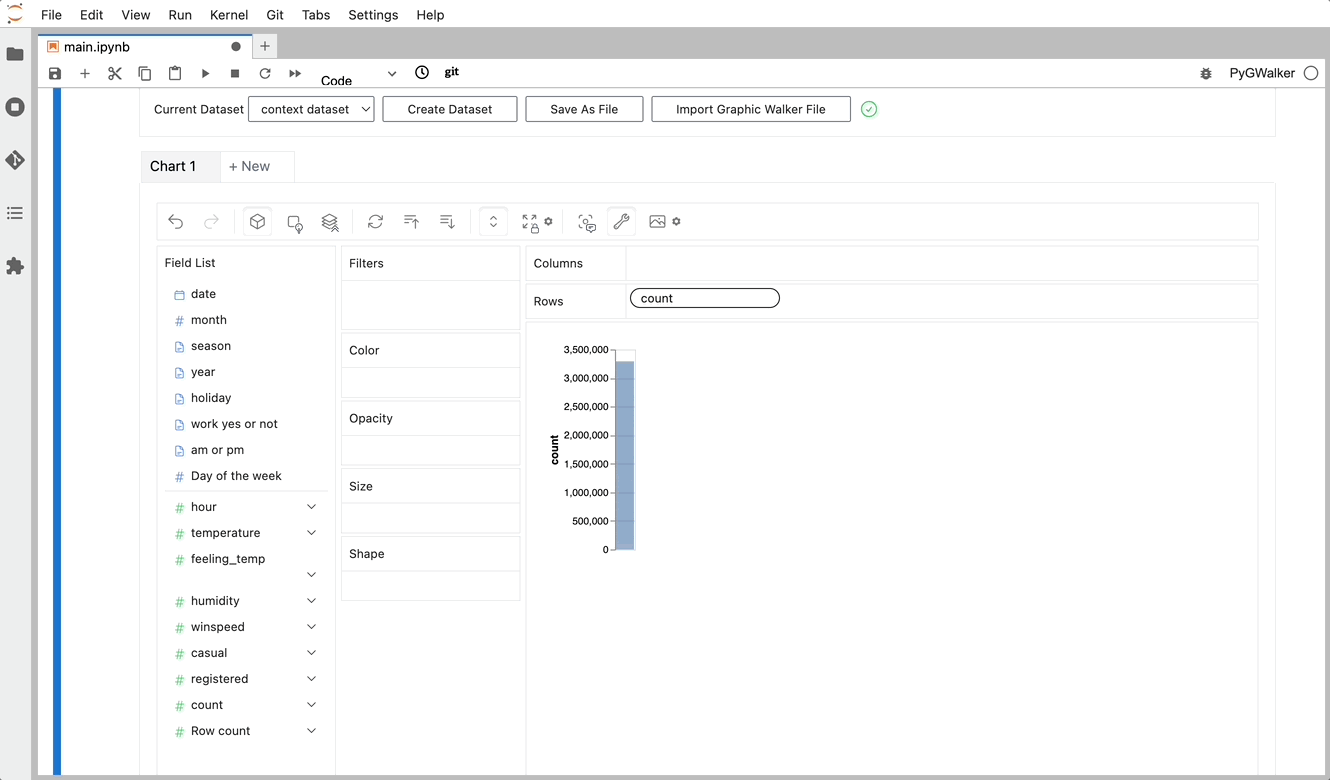
Importa pygwalker y pandas a tu Jupyter Notebook para comenzar.
import pandas as pd
import pygwalker as pygPuedes usar pygwalker sin cambiar tu flujo de trabajo existente. Por ejemplo, puedes llamar a Graphic Walker con el DataFrame cargado de esta manera:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)¡Ahora puedes visualizar tu Pandas DataFrame con una interfaz de usuario fácil de usar!
Simplemente puedes crear una vista de concatenación arrastrando y soltando variables:
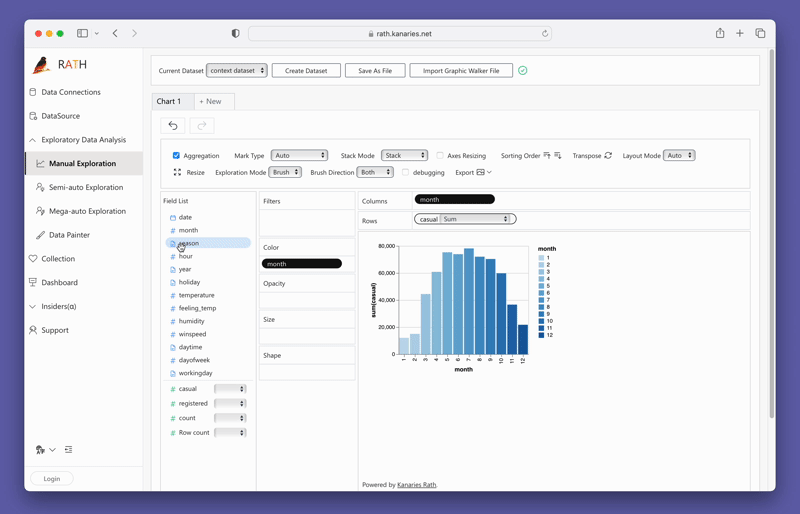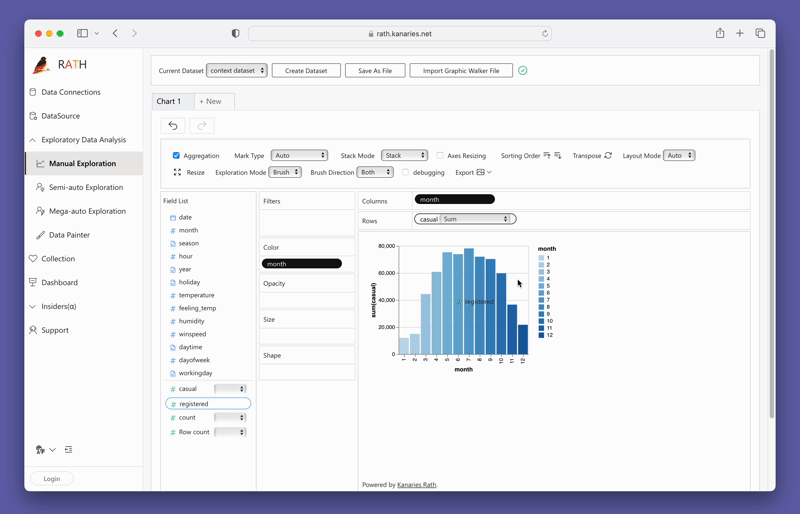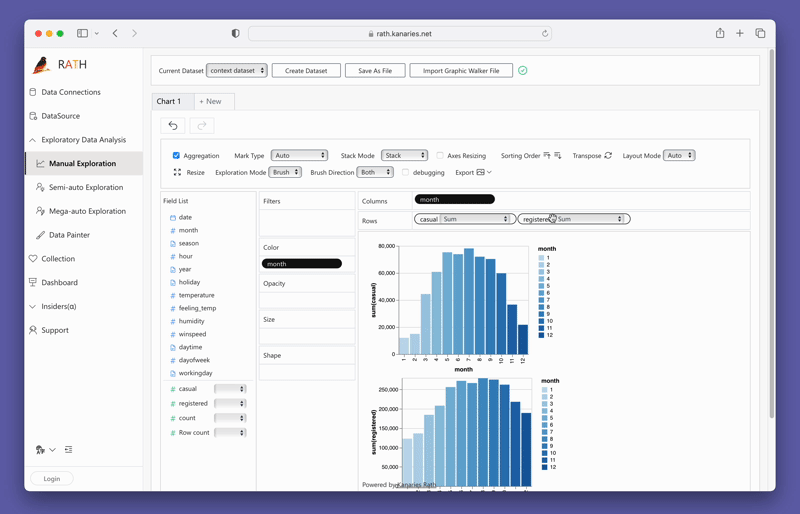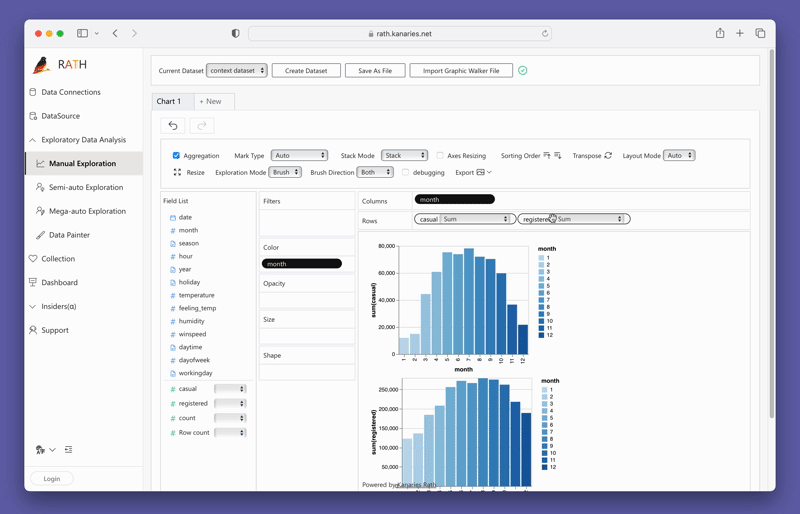
Para probar PyGWalker ahora mismo, puedes ejecutar PyGWalker en Google Colab (opens in a new tab), Binder (opens in a new tab) o Kaggle (opens in a new tab).
PyGWalker es de código abierto. Puedes consultar la página de GitHub de PyGWalker (opens in a new tab) y leer el artículo de Towards Data Science (opens in a new tab) al respecto.
No olvides consultar una herramienta de análisis de datos automatizada más avanzada y basada en IA: RATH (opens in a new tab). RATH también es de código abierto y ha alojado su código fuente en GitHub (opens in a new tab).
Preguntas frecuentes
¿Cómo puedo unir dos DataFrames usando PySpark?
PySpark es un marco de procesamiento de datos de gran tamaño de código abierto que te permite escribir aplicaciones de procesamiento de datos en Python, Java, Scala o R. Para unir dos DataFrames usando PySpark, puedes usar el método join(), que toma dos objetos DataFrame y una expresión de unión opcional. Puedes especificar el tipo de unión usando el parámetro how.
¿Cómo puedo combinar dos DataFrames usando R?
Para combinar dos DataFrames usando R, puedes usar la función merge(), que toma dos data frames y un conjunto opcional de argumentos que especifican cómo se deben combinar los datos.
¿Cómo puedo agregar dos o más DataFrames en pandas?
Para agregar dos o más DataFrames en pandas, puedes usar la función concat(), que toma una lista de DataFrames y un parámetro de eje opcional que especifica el eje a lo largo del cual se deben concatenar los DataFrames.
¿Cómo puedo unir dos DataFrames en base a una columna común usando pandas?
Para unir dos DataFrames en base a una columna común usando pandas, puedes usar la función merge(), que toma dos DataFrames y un conjunto opcional de argumentos que especifican cómo se deben combinar los datos. Puedes especificar la columna a unir usando el parámetro on.
Conclusión
En conclusión, la fusión, unión y concatenación de DataFrames son operaciones esenciales en el análisis de datos. Con la ayuda de herramientas poderosas como pandas, PySpark y R, estas operaciones se pueden realizar de manera fácil y eficiente. Ya sea que estés lidiando con conjuntos de datos grandes o pequeños, estas herramientas ofrecen formas flexibles e intuitivas de manipular tus datos.