PyGWalker: inicio rápido
Inicio rápido en Jupyter Notebook
Importa pygwalker y pandas a tu Jupyter Notebook para comenzar.
import pandas as pd
import pygwalker as pygCarga tus datos como un dataframe y luego pásalo a pygwalker.
df = pd.read_csv('./<ruta_del_archivo_csv>.csv')
walker = pyg.walk(df)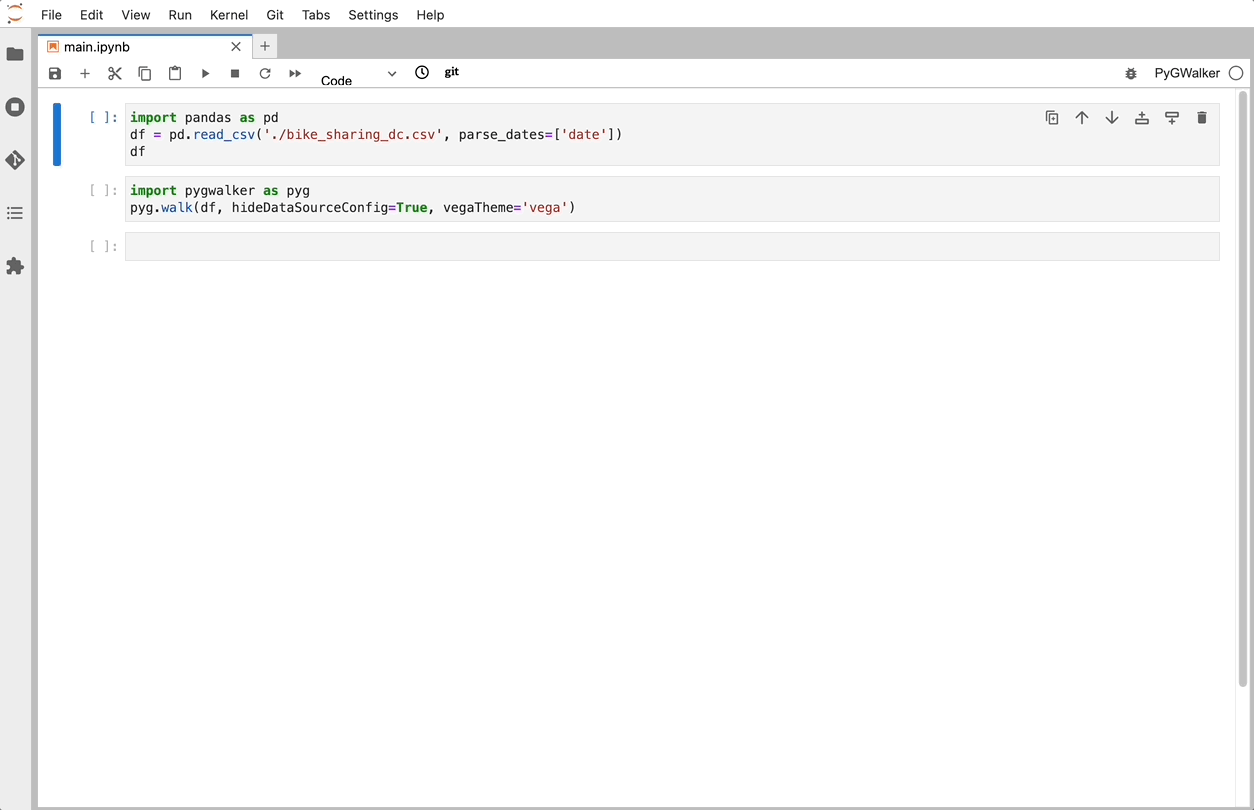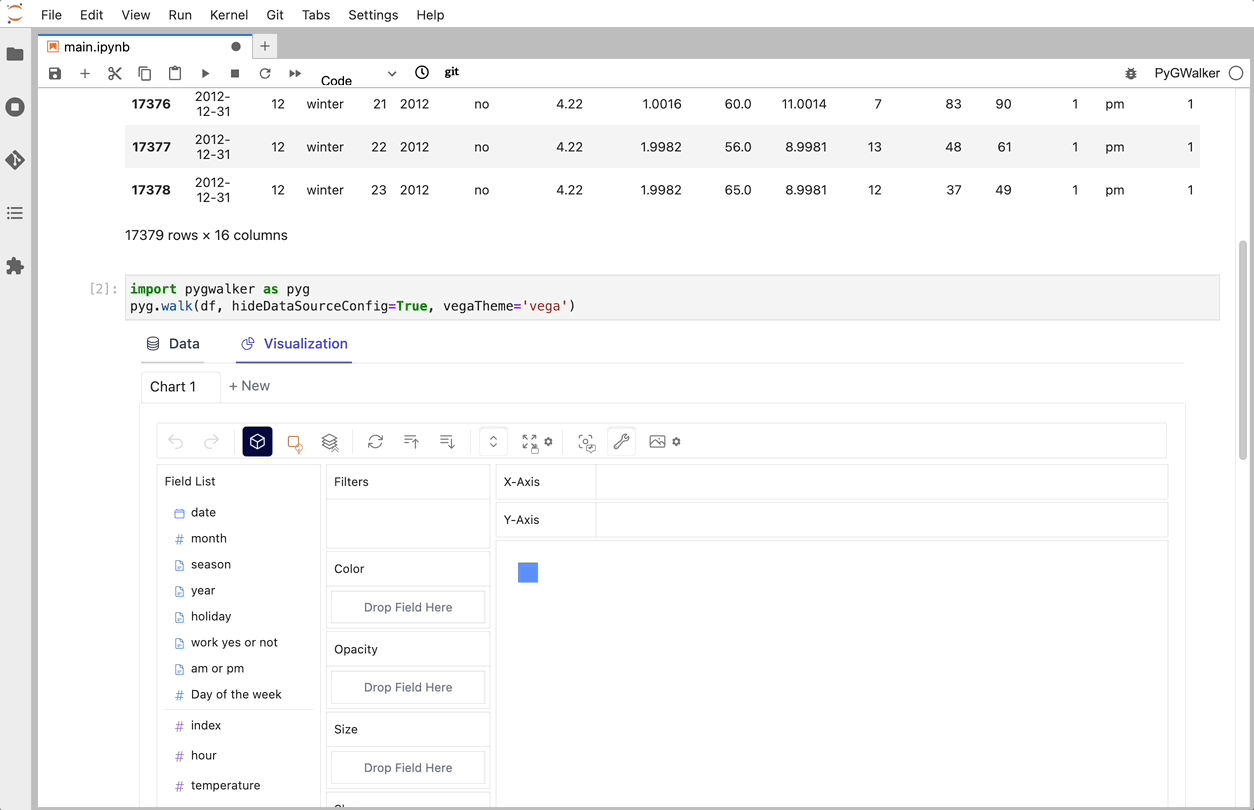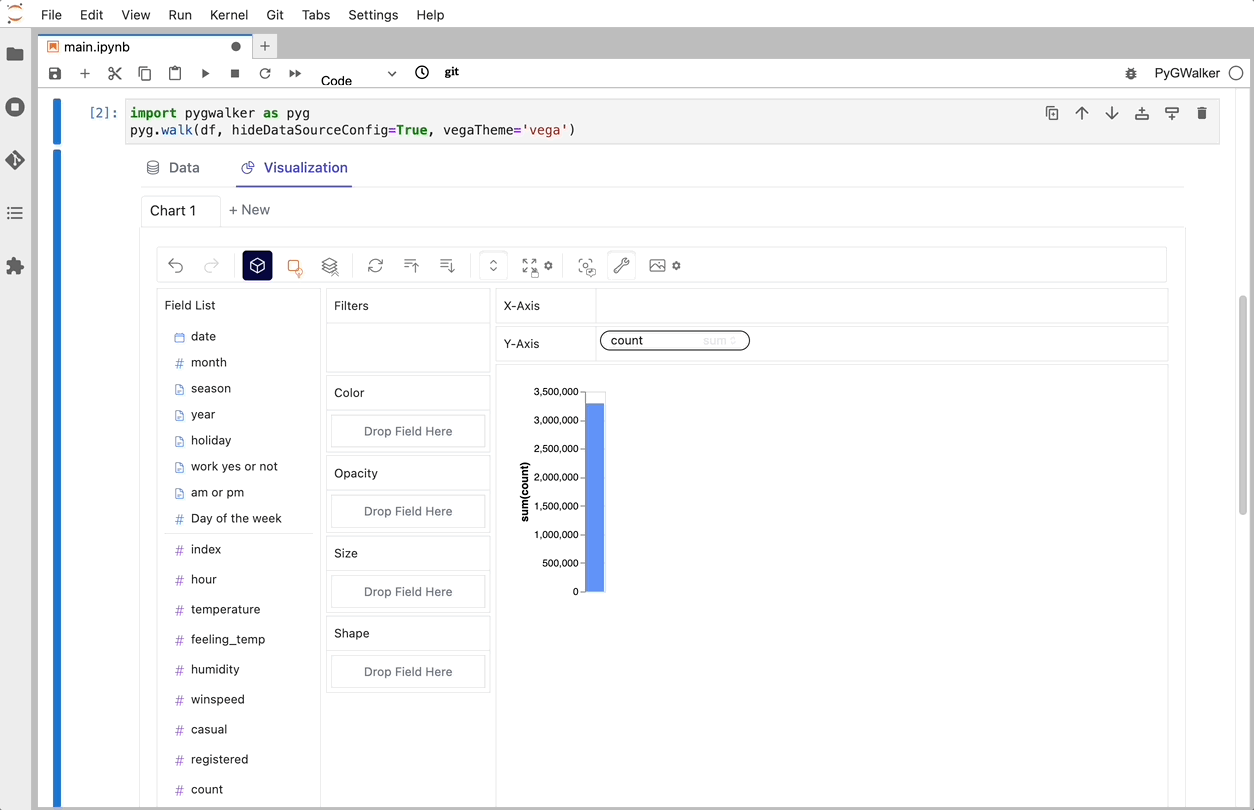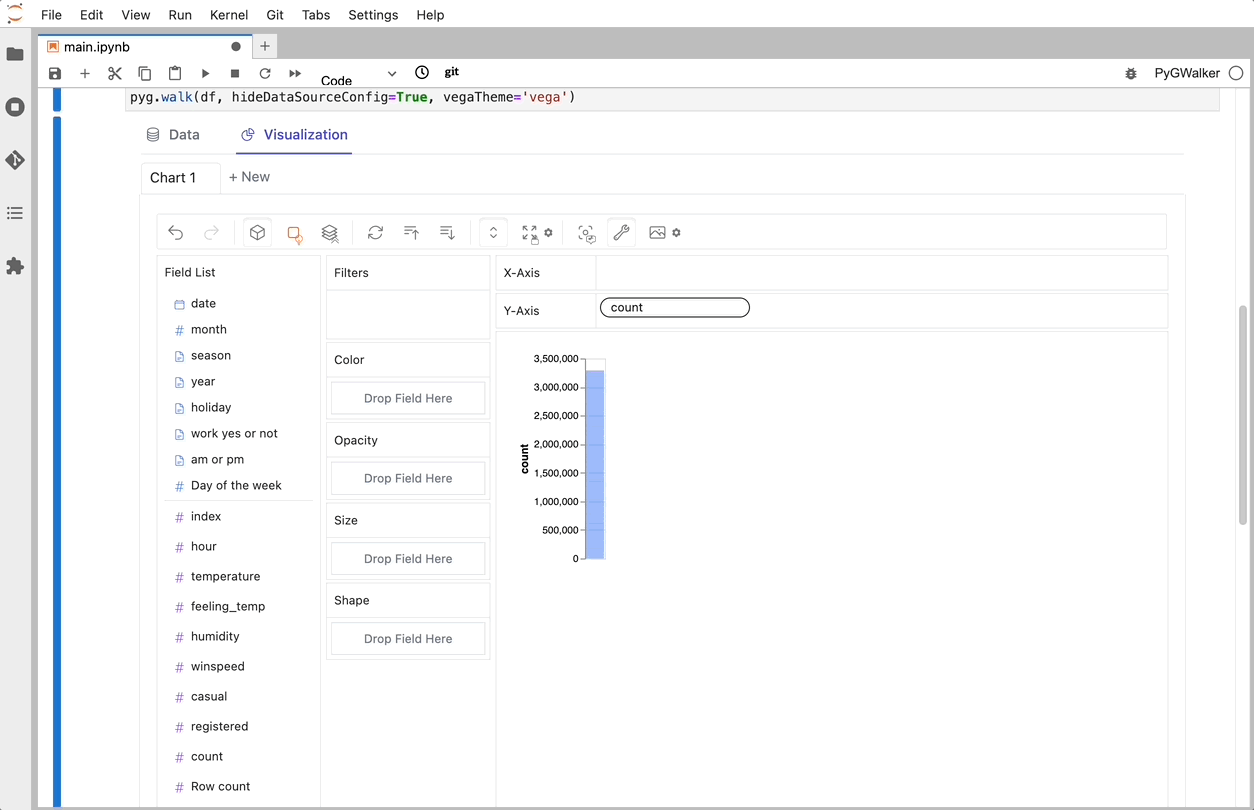
pygwalker acepta no solo un dataframe de pandas, sino también un dataframe de modin e incluso una conexión de datos, como snowflake.
Aumentar el rendimiento de pygwalker
A veces tu dataframe puede ser bastante grande y causar un rendimiento lento de pygwalker. Ahora te proporcionamos una forma sencilla de aumentar su rendimiento con un parámetro adicional kernel_computation.
pyg.walk(df, kernel_computation=True)Al establecer kernel_computation=True se habilitará el nuevo motor de cálculo en pygwalker impulsado por DuckDB.
Usar pygwalker con Snowflake
A veces tus datos pueden ser extremadamente grandes y no deseas cargarlos en tu memoria local. PyGWalker permite enviar todas sus computaciones a un servicio OLAP remoto, como Snowflake.
pip install --upgrade --pre pygwalker
pip install --upgrade --pre "pygwalker[snowflake]"
Aquí tienes un ejemplo de código sobre cómo usar pygwalker con Snowflake.
import pygwalker as pyg
from pygwalker.data_parsers.database_parser import Connector
conn = Connector(
"snowflake://user_name:password@account_identifier/database/schema",
"""
SELECT
*
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
"""
)
walker = pyg.walk(conn)Inicio rápido en Streamlit
PyGWalker es potente para la exploración de datos localmente, y puede ser genial si se puede ejecutar en una aplicación web. Básicamente, hay muchas formas de implementarlo:
- Usar Streamlit (opens in a new tab) para construir una aplicación web.
Streamlit es una excelente herramienta para construir aplicaciones de datos con Python, especialmente para los científicos de datos que no están familiarizados con el desarrollo web. Aquí tienes un ejemplo rápido de cómo usar PyGWalker con Streamlit.
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Add Title
st.title("Use Pygwalker In Streamlit")
# You should cache your pygwalker renderer, if you don't want your memory to explode
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# If you want to use feature of saving chart config, set `spec_io_mode="rw"`
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()Consulta este artículo de la comunidad para obtener más información sobre cómo usar PyGWalker con Streamlit: pygwalker streamlit api