Explorar datos de Netflix con PyGWalker
Netflix se destaca como una plataforma principal de películas y programas de televisión. Con una biblioteca en constante crecimiento, comprender las tendencias y patrones de su contenido se vuelve crucial para los analistas, cineastas e incluso los espectadores. En este cuaderno, profundizaremos en el conjunto de datos de Netflix utilizando la biblioteca PyGWalker, una poderosa herramienta para la visualización y exploración de datos.
¿Qué es PyGWalker?
PyGWalker (opens in a new tab) es una biblioteca de Python diseñada para simplificar el proceso de visualización de datos. Permite a los usuarios crear gráficos interactivos con un código mínimo, facilitando así la obtención de información y patrones en los conjuntos de datos.

Usando PyGWalker, podemos generar visualizaciones informativas que proporcionan una comprensión más clara del panorama de contenido de Netflix.
Pasos para explorar datos de Netflix con PyGWalker
Configuración del entorno
Para comenzar, debemos asegurarnos de que nuestro entorno esté listo para el análisis. Esto implica instalar la biblioteca PyGWalker e importar los paquetes de Python necesarios.
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Cargar conjunto de datos de Netflix y preprocesamiento
Nuestra primera tarea es cargar el conjunto de datos de Netflix. Una vez cargado, lo preprocesaremos para que nuestro análisis posterior sea más fluido. Este preprocesamiento implica:
- Convertir la columna date_added a formato de fecha y hora.
- Extraer el año y el mes de la columna date_added.
- Limpiar la columna duration para representar la duración total en minutos para películas o el número de temporadas para programas de televisión.
- Filtrar datos posteriores a 2019.
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df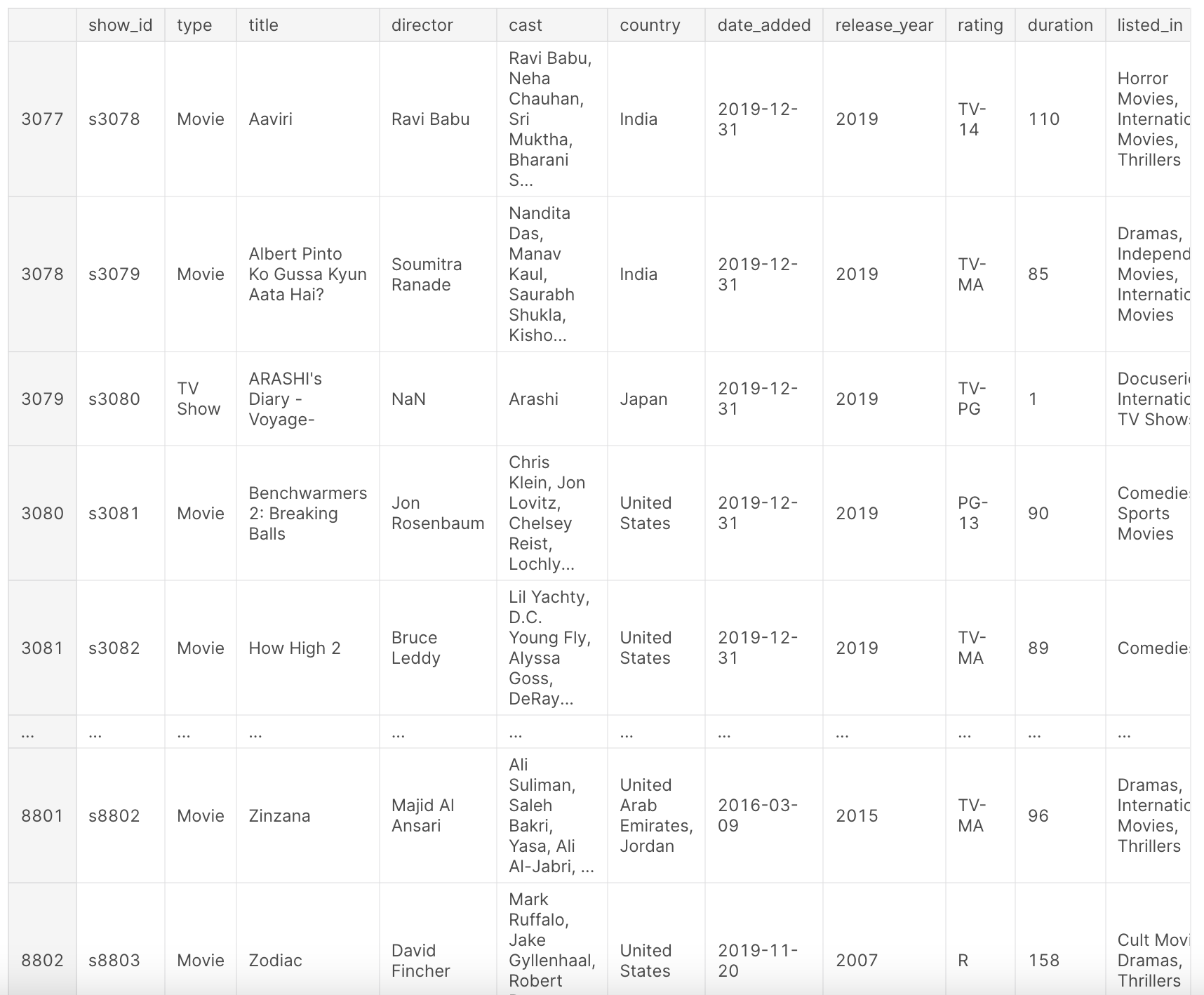
Resumen del conjunto de datos de Netflix
Después del preprocesamiento anterior, nuestro conjunto de datos df proporciona una vista integral de los títulos de Netflix. Contiene información como el tipo de contenido (película o programa de televisión), título, director, reparto, país de producción, fecha de agregado a Netflix, año de lanzamiento, clasificación, duración, género y una breve descripción.
Este conjunto de datos ofrece una instantánea del panorama de contenido de Netflix hasta el año 2019, lo que nos permite analizar tendencias, preferencias y patrones de crecimiento a lo largo de los años. Eche un vistazo a las siguientes columnas:
show_id: ID único para cada película o programa de televisióntype: Identificador para película o programa de televisióntitle: Título de la película o programa de televisióndirector: Director de la películacast: Actores involucrados en la película o programacountry: País donde se produjo la película o programadate_added: Fecha en que se agregó a Netflixrelease_year: Año real de lanzamiento de la película o programarating: Clasificación de televisión de la película o programaduration: Duración total, en minutos o número de temporadaslisted_in: Génerodescription: Una breve descripción de la película o programa
Visualizar datos de Netflix con PyGWalker
Ahora, para la parte emocionante: visualizaciones. Con PyGWalker, generaremos visualizaciones interactivas para descubrir información en nuestro conjunto de datos.
1. Resumen general de datos de Netflix
Aquí, estamos inicializando un walker para nuestro conjunto de datos principal. Esto nos permitirá generar una serie de gráficos basados en las especificaciones guardadas en "0.json".
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
Puedes explorar este conjunto de datos de forma interactiva con una versión en línea de PyGWalker aquí (opens in a new tab).
walker0.display_chart("Gráfico 1", title="Tipo de contenido en Netflix")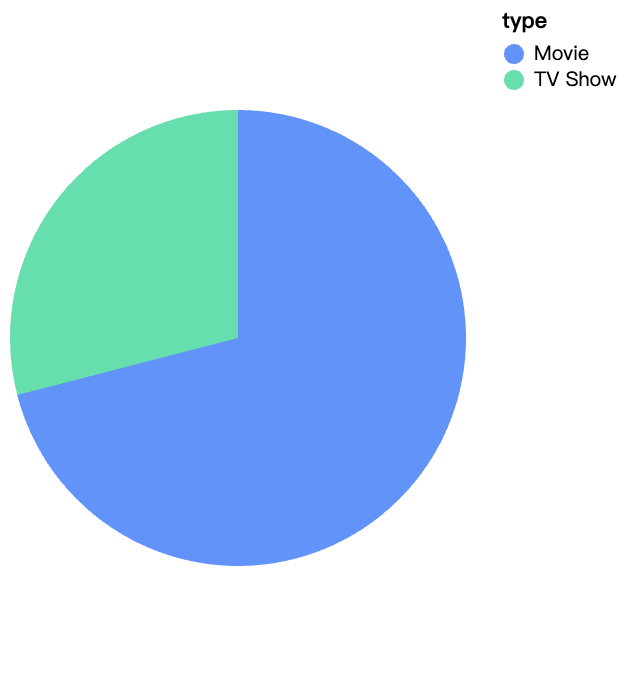
walker0.display_chart("Gráfico 2", title="Contenido agregado a lo largo de los años", desc="La cantidad de películas en Netflix está creciendo mucho más rápido que los programas de televisión, el contenido de películas ha crecido considerablemente después de 2016.")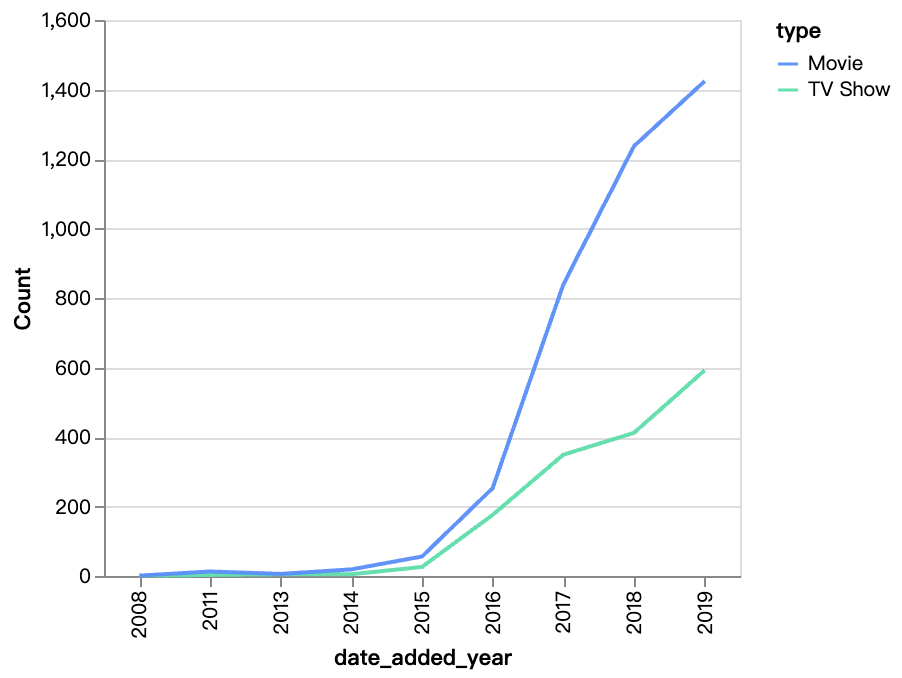
walker0.display_chart("Gráfico 3", title="Lanzamiento de contenido a lo largo de los años")
walker0.display_chart("Gráfico 4", title="Contenido agregado por mes", desc="")
walker0.display_chart("Gráfico 5", title="Contenido agregado a lo largo de los años según la clasificación", desc="TV-MA, TV-14 son las clasificaciones de la mayoría del contenido de Netflix, y el contenido R también aumenta año tras año")
walker0.display_chart("Gráfico 6", title="Distribución del tiempo de las películas", desc="Principalmente concentrado entre 90 y 110 minutos")
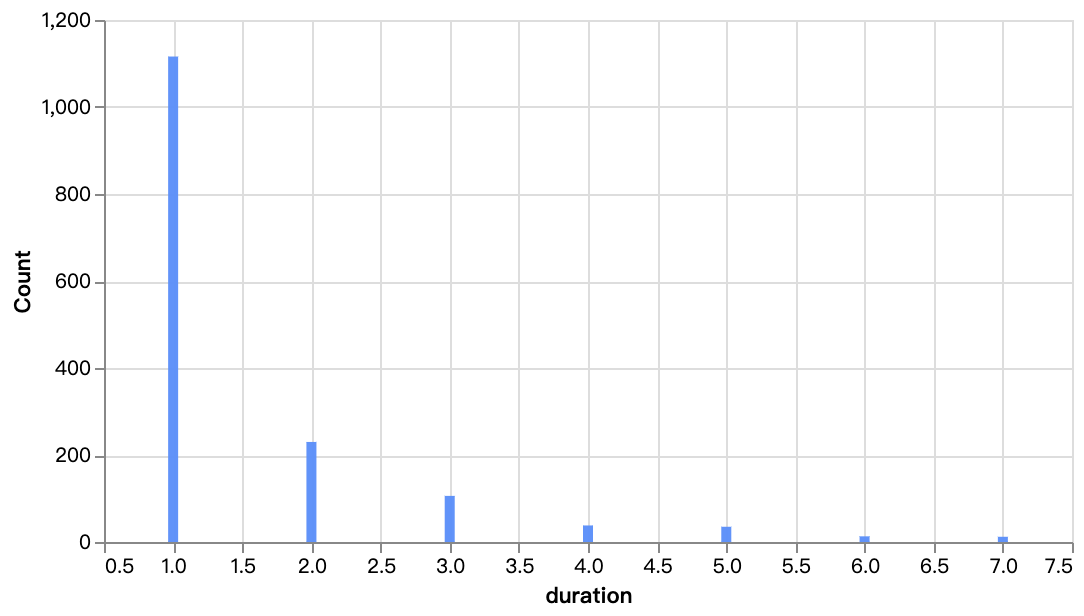
walker0.display_chart("Gráfico 7", title="Distribución de temporadas de programas de televisión")
2. Análisis específico por país en los datos de Netflix
En este segmento, estamos desglosando el contenido por país. Al dividir y reestructurar la columna de país, podemos analizar la distribución del contenido en diferentes países.
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)Puedes probar PyGWalker en la interfaz de usuario aquí (opens in a new tab)
walker1.display_chart("Gráfico 1", title="Países con más contenido")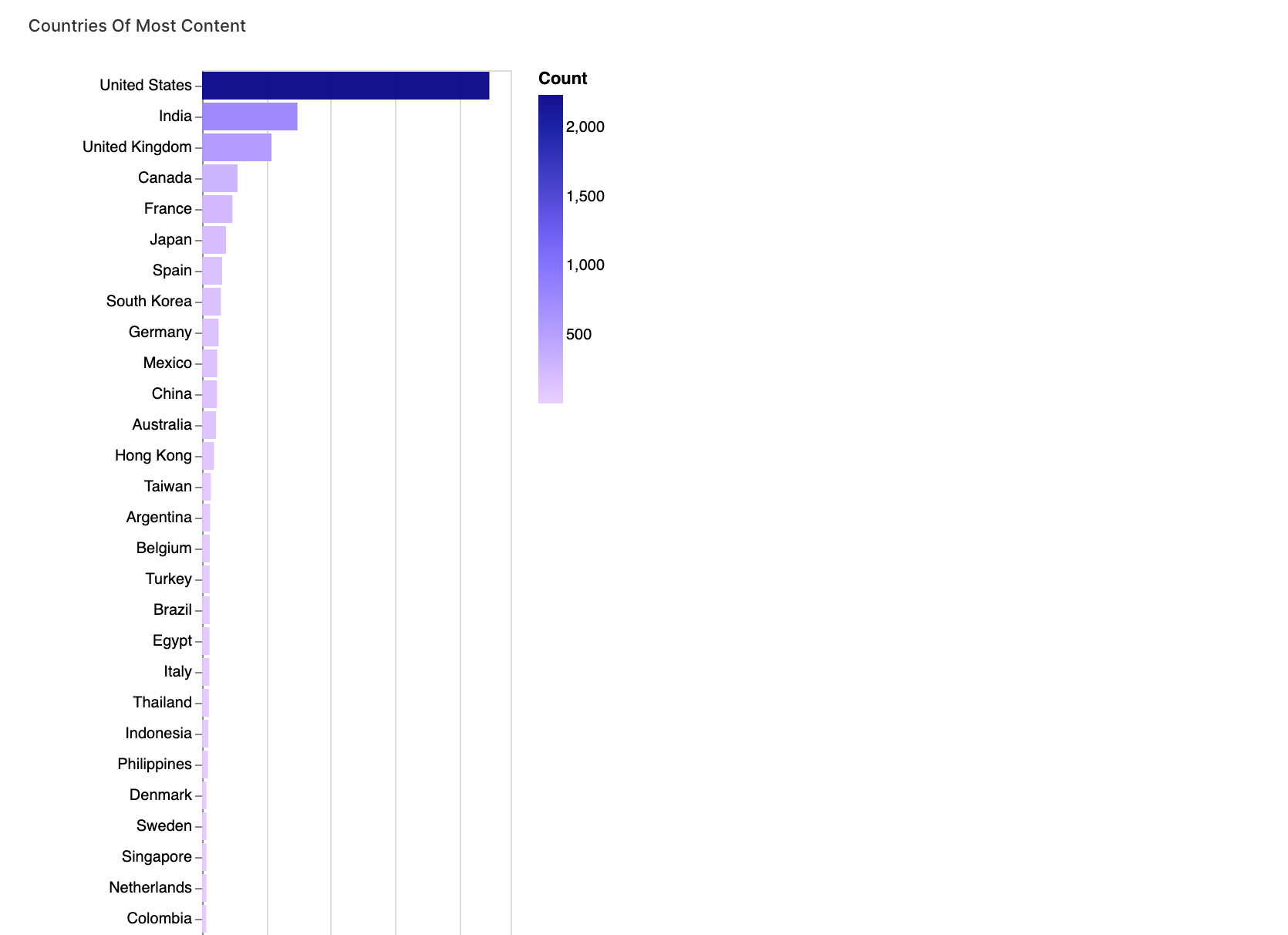
3. Análisis de categorías y calificaciones
Por último, nos enfocamos en las categorías y calificaciones. Esta sección nos permitirá entender la distribución del contenido en los géneros y cómo varían las calificaciones dentro de esos géneros.
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)Puedes probar PyGWalker en la interfaz de usuario aquí (opens in a new tab)
walker2.display_chart("Categoría de TV", title="Distribución de categorías de programas de televisión")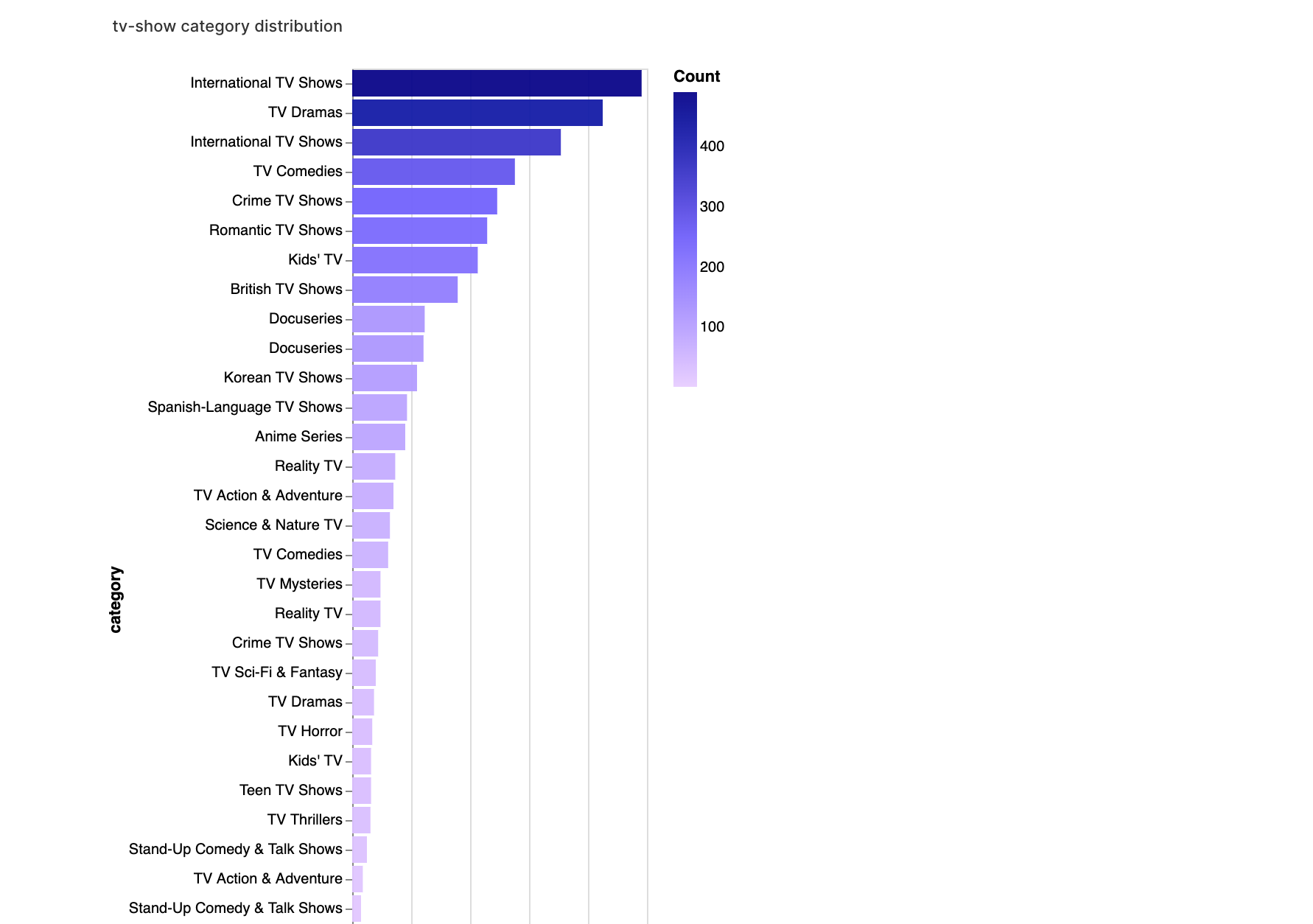
walker2.display_chart("Categoría de película", title="Distribución de categorías de películas")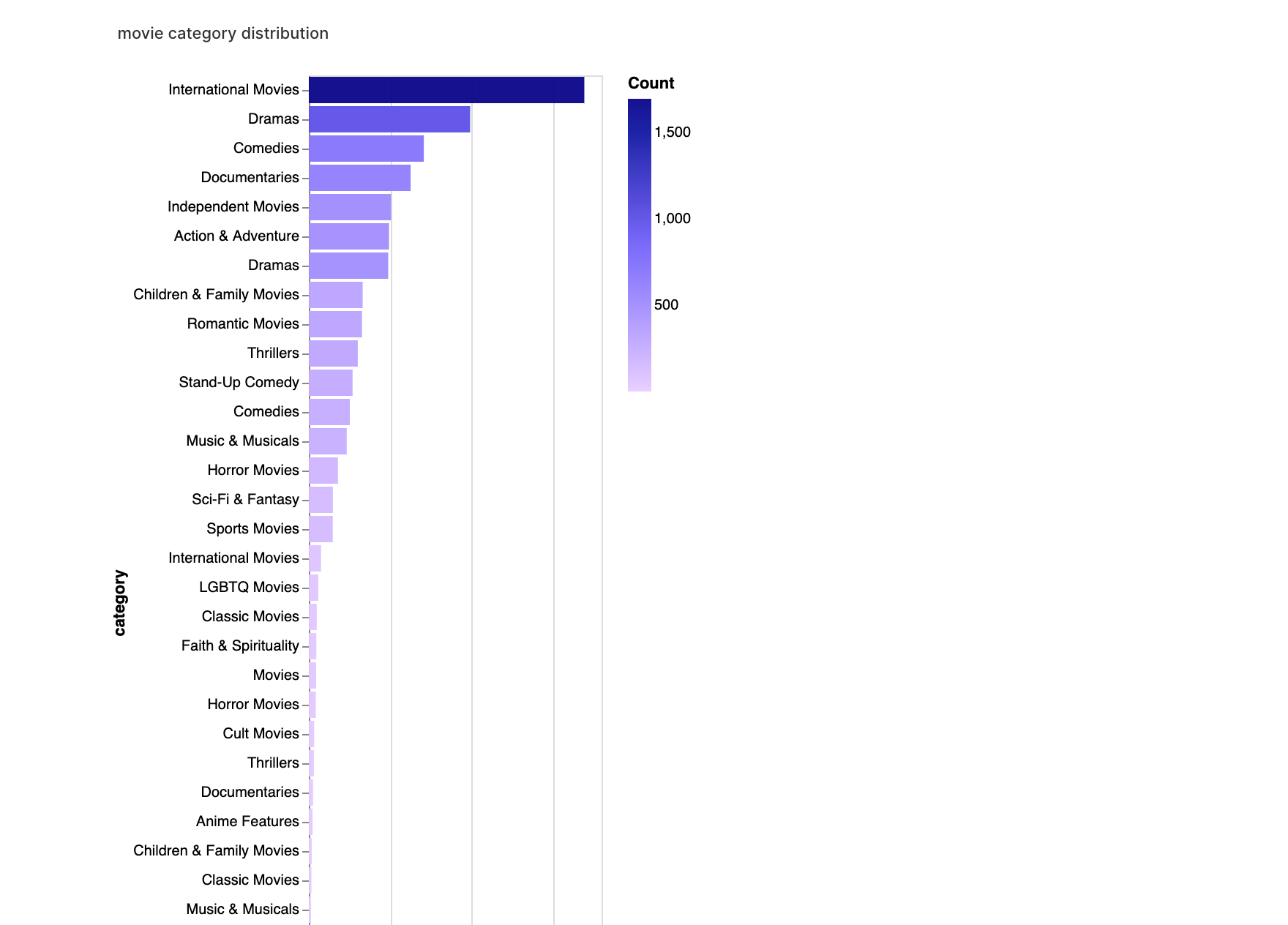
walker2.display_chart("Categoría de calificación televisiva", title="Mapa de calor de categorías de calificación (TV-Show)")
walker2.display_chart("Categoría de calificación de películas", title="Mapa de calor de categorías de calificación (películas)")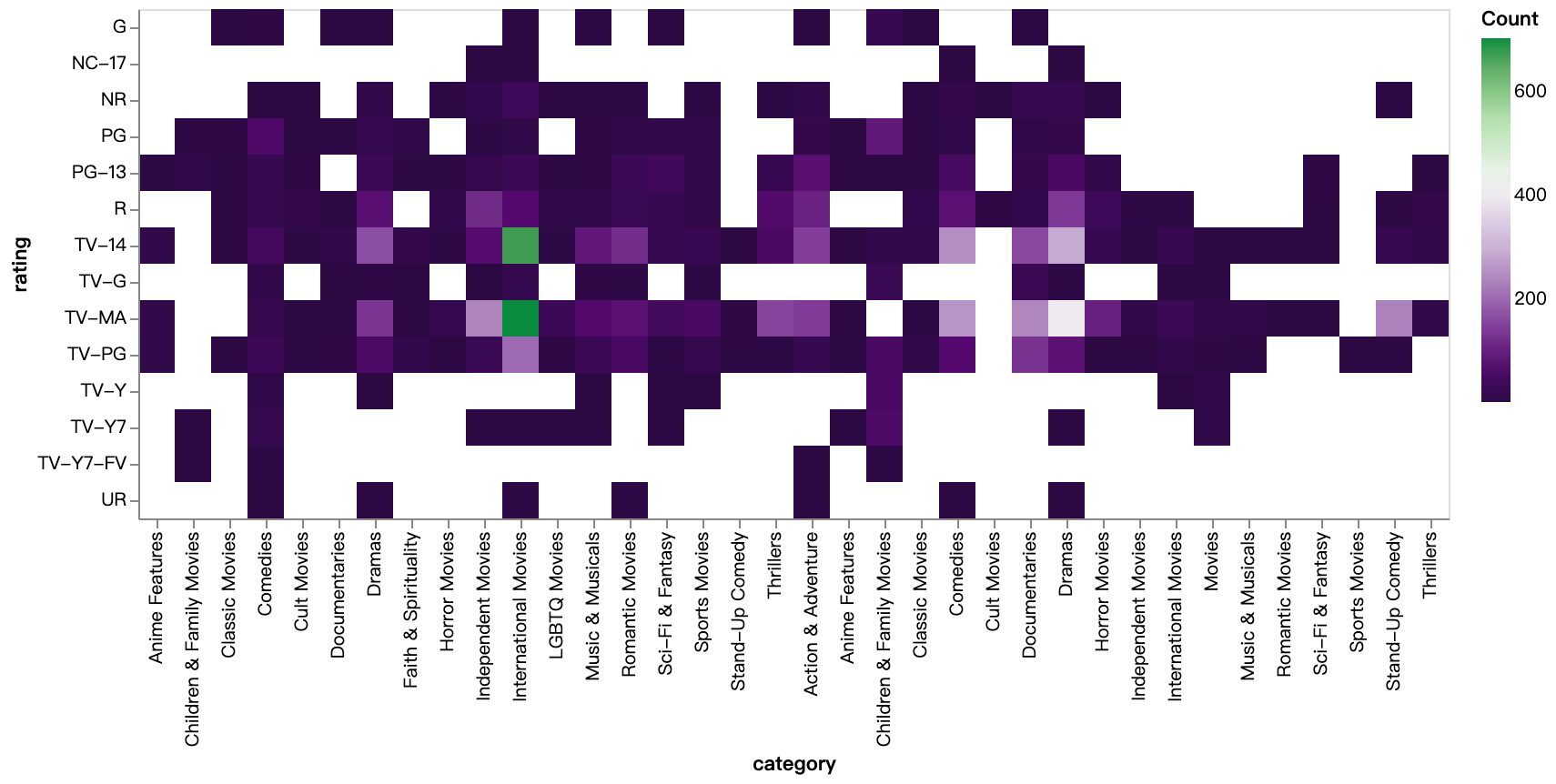
Conclusión
En esta exploración exhaustiva del conjunto de datos de Netflix utilizando la biblioteca PyGWalker, nos sumergimos en los numerosos aspectos del panorama de contenido de Netflix. PyGWalker demostró ser una herramienta poderosa, simplificando el proceso de visualización para revelar tendencias esenciales. El análisis proporcionó claridad sobre los patrones de crecimiento, preferencias y tendencias del contenido de Netflix hasta 2019, analizando las categorías y calificaciones reveló la variedad y distribución de géneros en películas y programas de televisión y cómo varían las calificaciones dentro de esos géneros.
Esta documentación también está disponible en Kaggle Notebook (opens in a new tab).
Preguntas frecuentes
1. ¿Qué son los conjuntos de datos de Netflix?
- Los conjuntos de datos de Netflix son colecciones de datos que proporcionan información detallada sobre el contenido disponible en la plataforma de Netflix. Estos datos típicamente incluyen aspectos como el tipo de contenido (película o programa de televisión), título, director, elenco, país de producción, fecha de agregado a Netflix, año de lanzamiento, calificación, duración, género y una breve descripción. Estos conjuntos de datos permiten a investigadores y analistas comprender mejor el panorama de contenido de la plataforma.
2. ¿Cómo se pueden utilizar los conjuntos de datos de Netflix?
- Los conjuntos de datos de Netflix se pueden utilizar de diversas formas:
- Análisis de tendencias: Comprender los patrones de crecimiento, preferencias y tendencias a lo largo de los años.
- Análisis por país: Determinar qué países producen más contenido y qué tipo de contenido es popular en diferentes regiones.
- Distribución de géneros: Explorar los géneros más populares y cómo varían entre películas y programas de televisión.
- Información sobre calificaciones: Analizar la distribución de calificaciones en diversos tipos de contenido y determinar las preferencias del público.
- Visualización de datos: Utilizar herramientas como PyGWalker para crear visualizaciones interactivas para obtener información más detallada.
3. ¿Qué es PyGWalker y por qué es beneficioso para la exploración de datos?
- PyGWalker es una biblioteca de Python diseñada específicamente para agilizar el proceso de visualización de datos. Permite a los usuarios generar gráficos interactivos con un código mínimo, facilitando el descubrimiento de patrones e información en conjuntos de datos. Para plataformas como Netflix, que tienen conjuntos de datos vastos, PyGWalker puede ser invaluable para simplificar la exploración de datos y generar visualizaciones fácilmente comprensibles.