Análisis exploratorio de datos con Python Pandas: Guía completa
- Name
- Omar C. Williams
Actualizado el
El Análisis Exploratorio de Datos (EDA) es un paso crítico en cualquier proyecto de ciencia de datos. Este proceso implica comprender los datos, identificar patrones y hacer observaciones iniciales. Este artículo te guiará a través del proceso de EDA utilizando la biblioteca Pandas de Python, una poderosa herramienta para la manipulación y análisis de datos. Cubriremos todo, desde el manejo de valores faltantes hasta la creación de visualizaciones útiles e informativas.
Usando Pandas para el Análisis Exploratorio de Datos
Manejo de valores faltantes
Al trabajar con datos del mundo real, es común encontrarse con valores faltantes. Estos pueden ocurrir por diversas razones, como errores de entrada de datos o falta de recolección de datos para ciertas observaciones. El manejo de valores faltantes es crucial ya que pueden llevar a análisis inexactos si no se tratan adecuadamente.
En Pandas, puedes revisar si hay valores faltantes utilizando la función isnull(). Esta función devuelve un DataFrame donde cada celda es True (si la celda original contenía un valor faltante) o False (si la celda no estaba faltando un valor). Para obtener el número total de valores faltantes en cada columna, puedes encadenar la función sum():
valores_faltantes = df.isnull().sum()Esto devolverá una serie con los nombres de columna como índice y el número total de valores faltantes en cada columna como valores. Dependiendo de la naturaleza de tus datos y el análisis que planeas realizar, puedes decidir llenar los valores faltantes con cierto valor (como la mediana o media de la columna), o puedes decidir eliminar las filas o columnas que contengan valores faltantes en su totalidad.
Explorando valores únicos
Otro paso importante en EDA es explorar los valores únicos en tus datos. Esto puede ayudarte a entender la diversidad de tus datos. Por ejemplo, si tienes una columna que representa categorías de cierta característica, revisar los valores únicos puede darte una idea de cuántas categorías existen.
En Pandas, puedes usar la función nunique() para revisar el número de valores únicos en cada columna:
valores_unicos = df.nunique()Esto devolverá una serie con los nombres de columna como índice y el número de valores únicos en cada columna como valores.
Ordenando valores
Ordenar tus datos según alguna columna en particular también puede ser útil en EDA. Por ejemplo, puedes querer ordenar tus datos por una columna de "población" para ver qué países tienen las poblaciones más altas. En Pandas, puedes usar la función sort_values() para ordenar tu DataFrame:
df_ordenado = df.sort_values(by='población', ascending=False)Esto devolverá un nuevo DataFrame ordenado por la columna de "población" en orden descendente. El argumento ascending=False ordena la columna en orden descendente. Si deseas ordenar en orden ascendente, puedes omitir este argumento ya que True es el valor predeterminado.
Visualización de correlaciones con mapas de calor
Las visualizaciones pueden proporcionar información valiosa sobre tus datos que quizás no sea evidente al ver los datos en bruto. Una visualización útil es un mapa de calor de las correlaciones entre diferentes características en tus datos.
En Pandas, puedes calcular una matriz de correlación utilizando la función corr():
matriz_correlación = df.corr()Este código devolverá un DataFrame en el que la celda en la intersección de la fila 'i' y la columna 'j' contiene el coeficiente de correlación entre la 'i'-ésima y la 'j'-ésima característica. El coeficiente de correlación es un valor entre -1 y 1 que indica la fuerza y la dirección de la relación entre las dos características. Un valor cercano a 1 indica una relación positiva fuerte, un valor cercano a -1 indica una relación negativa fuerte, y un valor cercano a 0 indica que no hay relación.
Para visualizar esta matriz de correlación, puedes utilizar la función heatmap() de la biblioteca seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 7))
sns.heatmap(correlation_matrix, annot=True)
plt.show()Esto creará un mapa de calor donde el color de cada celda representa el coeficiente de correlación entre las características correspondientes. El argumento annot=True añadirá los coeficientes de correlación a las celdas del mapa de calor.
Agrupación de datos
Agrupar tus datos en función de ciertos criterios puede proporcionar información valiosa. Por ejemplo, podrías querer agrupar tus datos por 'continente' para analizar los datos a nivel de continente. En Pandas, puedes utilizar la función groupby() para agrupar tus datos:
grouped_df = df.groupby('continente').mean()Esto devolverá un nuevo DataFrame en el que los datos están agrupados por la columna 'continente', y los valores en cada grupo son los valores medios de los datos originales en ese grupo.
Visualización de datos a lo largo del tiempo
Visualizar tus datos a lo largo del tiempo puede ayudarte a identificar tendencias y patrones. Por ejemplo, podrías querer visualizar la población de cada continente a lo largo del tiempo. En Pandas, puedes crear un gráfico de líneas para este propósito:
df.groupby('continente').mean().transpose().plot(figsize=(20, 10))
plt.show()Esto creará un gráfico de líneas en el que el eje x representa el tiempo y el eje y representa la población media. Cada línea en el gráfico representa un continente diferente.
Identificación de valores atípicos con diagramas de caja
Los diagramas de caja son una excelente manera de identificar valores atípicos en tus datos. Un valor atípico es un valor que es significativamente diferente de los demás valores. Los valores atípicos pueden ser causados por diversos factores, como errores de medición o variabilidad genuina en tus datos.
En Pandas, puedes crear un diagrama de caja utilizando la función boxplot():
df.boxplot(figsize=(20, 10))
plt.show()Esto creará un diagrama de caja para cada columna en tu DataFrame. La caja en cada diagrama de caja representa el rango intercuartílico (el rango entre el percentil 25 y el percentil 75), la línea dentro de la caja representa la mediana, y los puntos fuera de la caja representan los valores atípicos.
Comprensión de los tipos de datos
Comprender los tipos de datos en tu DataFrame es otro aspecto crucial del AED. Diferentes tipos de datos requieren diferentes técnicas de manejo y pueden admitir diferentes tipos de operaciones. Por ejemplo, no se pueden realizar operaciones numéricas en datos de texto, y viceversa.
En Pandas, puedes comprobar los tipos de datos de todas las columnas en tu DataFrame utilizando el atributo dtypes:
df.dtypesEste devolverá una Serie con los nombres de columna como índice y los tipos de datos de las columnas como valores.
Filtrado de datos basado en tipos de datos
A veces, es posible que desee realizar operaciones solo en columnas de un cierto tipo de datos. Por ejemplo, es posible que desee calcular medidas estadísticas como la media, la mediana, etc., solo en columnas numéricas. En tales casos, puede filtrar las columnas según sus tipos de datos.
En Pandas, puede utilizar la función select_dtypes() para seleccionar columnas de un tipo de datos específico:
numeric_df = df.select_dtypes(include = 'number')Esto devolverá un nuevo DataFrame que contiene solo las columnas con datos numéricos. De manera similar, puede seleccionar columnas con el tipo de datos de objeto (cadena) de la siguiente manera:
object_df = df.select_dtypes(include = 'object')Visualización de distribuciones de datos con histogramas
Los histogramas son una excelente manera de visualizar la distribución de sus datos. Pueden proporcionar información sobre la tendencia central, la variabilidad y la asimetría de sus datos.
En Pandas, puede crear un histograma utilizando la función hist():
df['population'].hist(bins = 30)
plt.show()Esto creará un histograma para la columna 'población'. El parámetro bins determina la cantidad de intervalos para dividir los datos.
Combine PyGWalker y Pandas para el análisis exploratorio de datos
En el ámbito de la ciencia de datos y el análisis, a menudo nos encontramos profundizando en la exploración y el análisis de datos utilizando herramientas como pandas, matplotlib y seaborn. Si bien estas herramientas son increíblemente potentes, a veces pueden quedarse cortas en cuanto a exploración y visualización de datos interactivos. Aquí es donde entra PyGWalker.

PyGWalker, pronunciado como "Pig Walker", es una biblioteca de Python que se integra perfectamente con Jupyter Notebook (u otros notebooks basados en Jupyter) y Graphic Walker, una alternativa de código abierto a Tableau. PyGWalker transforma su marco de datos de pandas en una interfaz de usuario estilo Tableau para la exploración visual, lo que hace que su flujo de trabajo de análisis de datos sea más interactivo e intuitivo.
PyGWalker está construido por una colectividad apasionada de colaboradores de código abierto. ¡No olvides revisar PyGWalker GitHub (opens in a new tab) y dar una estrella!
Empezando con PyGWalker
La instalación de PyGWalker es muy fácil. Simplemente abra su cuaderno de Jupyter y escriba:
!pip install pygwalkerExploración interactiva de datos con PyGWalker
Una vez que tenga PyGWalker instalado, puede comenzar a explorar sus datos de manera interactiva. Para hacer esto, simplemente necesita llamar a la función walk() en su marco de datos:
import pygwalker as pyg
pyg.walk(datos)Este lanzará una herramienta de visualización de datos interactiva que se parece mucho a Tableau. El lado izquierdo de la interfaz muestra las variables en su marco de datos. El área central está reservada para sus visualizaciones, donde puede arrastrar y soltar variables a las cajas de eje X e Y. PyGWalker también ofrece varias opciones de personalización, como filtros, color, opacidad, tamaño y forma, lo que le permite adaptar sus visualizaciones a sus necesidades específicas.
Creando visualizaciones con PyGWalker
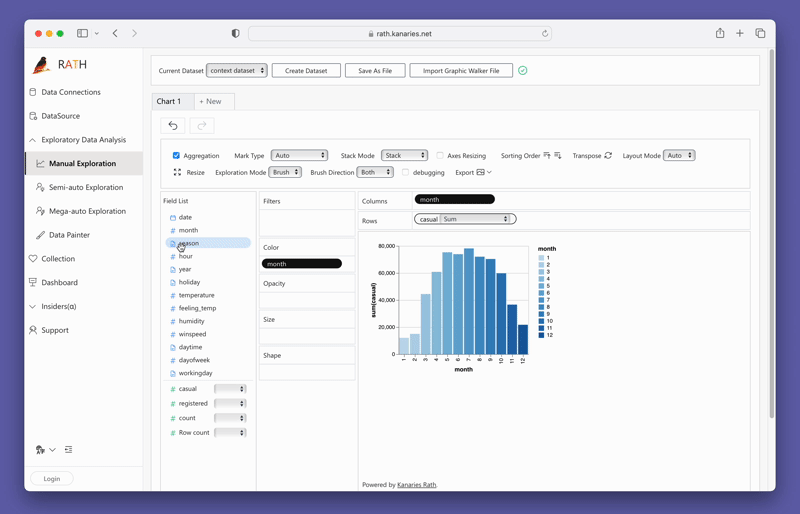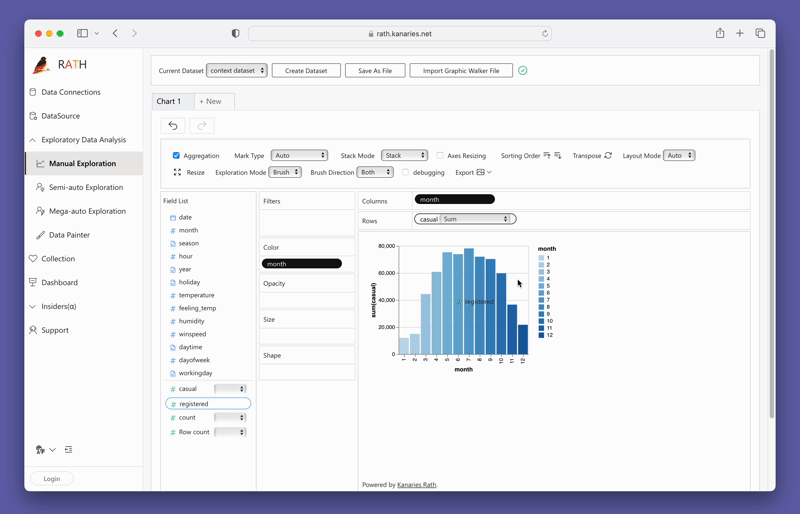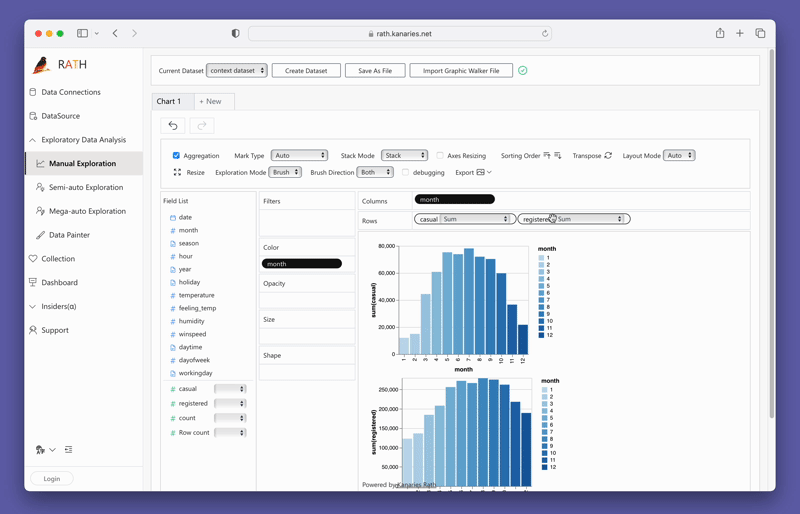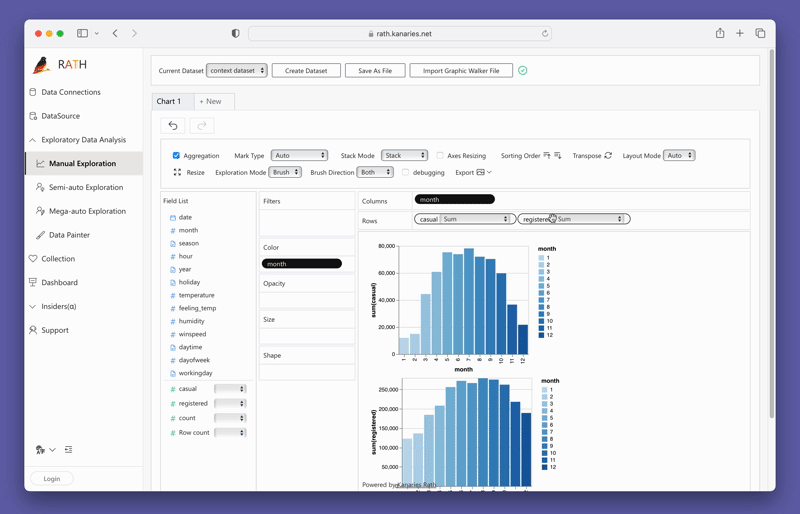
Crear visualizaciones con PyGWalker es tan simple como arrastrar y soltar sus variables. Por ejemplo, para crear un gráfico de barras de ventas por región, arrastraría la columna "Ventas" al eje X y la columna "Región" al eje Y. PyGWalker también le permite seleccionar el tipo de marca deseado o dejarlo en modo automático para que la herramienta pueda seleccionar el tipo de gráfico más adecuado para usted.
Para obtener más detalles sobre la creación de todos los tipos de visualizaciones de datos, consulte la Documentación.
Explorar datos con PyGWalker
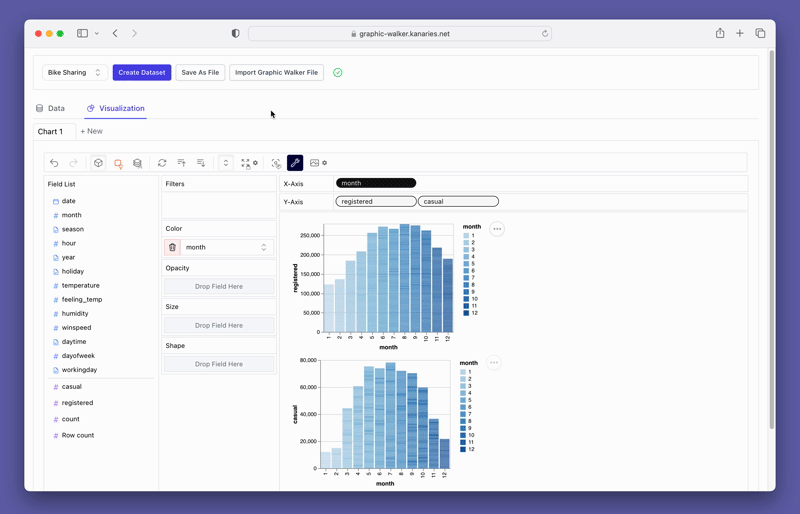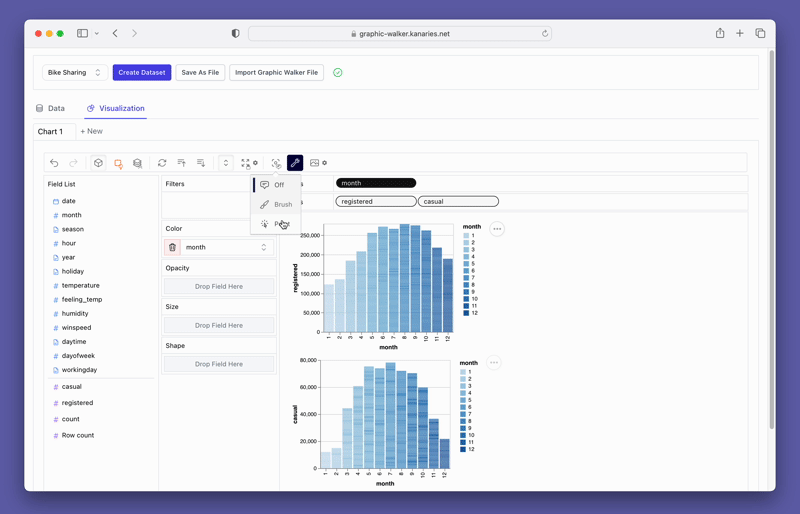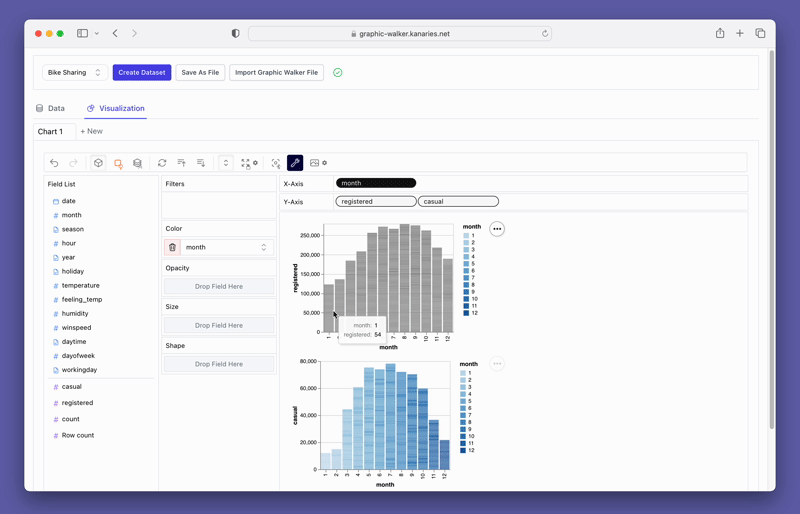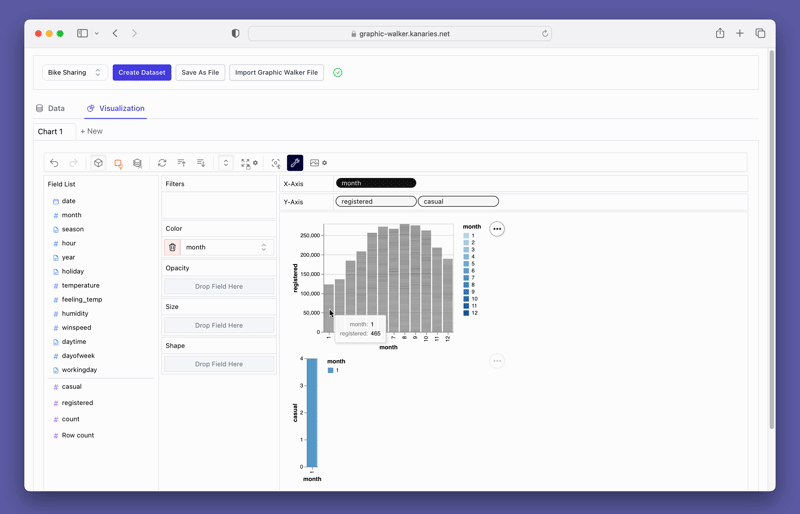
PyGWalker también proporciona opciones de filtrado y agregación fáciles de usar. Puede filtrar sus datos en función de cualquier columna arrastrando la columna a la caja de filtro. De manera similar, puede agregar sus columnas numéricas seleccionando la función de agregación de las opciones disponibles.
Consulte la documentación para más ejemplos y herramientas para Análisis exploratorio de datos en PyGWalker.
Una vez que esté satisfecho con sus visualizaciones, puede exportarlas y guardarlas como archivos PNG o SVG para su uso posterior. En la actualización PyGWalker 0.1.6, también puede exportar visualizaciones a la cadena de código.
Conclusión
El análisis exploratorio de datos (EDA) es un paso fundamental en cualquier proyecto de ciencia de datos. Le permite comprender sus datos, descubrir patrones y tomar decisiones informadas sobre el proceso de modelado. La biblioteca Pandas de Python ofrece una amplia variedad de funciones para realizar EDA de manera eficiente y efectiva.
En este artículo, hemos cubierto cómo manejar valores faltantes, explorar valores únicos, ordenar valores, visualizar correlaciones, agrupar datos, visualizar datos a lo largo del tiempo, identificar valores atípicos, comprender los tipos de datos, filtrar datos en función de los tipos de datos y visualizar distribuciones de datos. Con estas técnicas en su kit de herramientas de ciencia de datos, está bien equipado para sumergirse en sus propios datos y extraer información valiosa.
Recuerde, el EDA es más un arte que una ciencia. Requiere curiosidad, intuición y un ojo agudo para los detalles. Por lo tanto, no tenga miedo de sumergirse profundamente en sus datos y explorarlos desde diferentes ángulos. ¡Feliz análisis!
- Runcell Science: alternativa open source a Claude Science para investigación
- Cómo evitar que Mac se duerma: mantener Codex, Claude Code y agentes de IA corriendo
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: ¿Qué stack de agentes de IA deberías elegir en 2026?
- Cómo Claude Code analiza notebooks de Jupyter en Data Science: lo que sí hace y lo que no
- Claude Code routines: qué son y por qué importan los cron jobs de agentes de IA
- Claude Code Desktop Bypass Permissions: cómo activarlo
- Cómo Construir Dos Agentes en Python con el Protocolo A2A de Google - Tutorial Paso a Paso
- Las 10 principales bibliotecas de visualización de datos en Python que crecen en 2025
Preguntas frecuentes
-
¿Qué es el análisis exploratorio de datos?
El análisis exploratorio de datos es el proceso de analizar y visualizar datos para descubrir patrones, relaciones e información. Implica técnicas como limpieza de datos, transformación de datos y visualización de datos.
-
¿Por qué es importante el análisis exploratorio de datos?
El análisis exploratorio de datos es importante porque ayuda a comprender los datos, identificar tendencias y patrones, y tomar decisiones informadas sobre el análisis posterior. Permite a los científicos de datos obtener información y descubrir patrones ocultos que pueden impulsar las decisiones comerciales.
-
¿Cuáles son algunas técnicas comunes utilizadas en el análisis exploratorio de datos?
Algunas técnicas comunes utilizadas en el análisis exploratorio de datos incluyen estadísticas resumidas, visualización de datos, limpieza de datos, manejo de valores faltantes, detección de valores atípicos y análisis de correlación.
-
¿Qué herramientas se utilizan comúnmente para el análisis exploratorio de datos?
Hay varias herramientas comúnmente utilizadas para el análisis exploratorio de datos, incluidas bibliotecas de Python como Pandas, NumPy y Matplotlib, así como software como Tableau y Excel.
-
¿Cuáles son los pasos clave en el análisis exploratorio de datos?
Los pasos clave en el análisis exploratorio de datos incluyen limpieza de datos, exploración de datos, visualización de datos, análisis estadístico y sacar conclusiones de los datos. Estos pasos son iterativos e implican una exploración y refinamiento continuos de los datos.