Las 9 principales bibliotecas de DataFrame de código abierto para Python

Python se ha consolidado como el lenguaje preferido por desarrolladores y entusiastas de los datos. Una de las razones clave de su popularidad en el procesamiento de datos es su amplio ecosistema de bibliotecas, especialmente aquellas enfocadas en DataFrames. Estas potentes estructuras similares a tablas facilitan la manipulación y análisis de datos estructurados, convirtiéndose en herramientas indispensables para quienes trabajan con conjuntos de datos.
Si alguna vez has utilizado Python para análisis de datos, probablemente te hayas encontrado con Pandas, la biblioteca de DataFrame más conocida y querida. Pero a medida que los datos crecen en tamaño y complejidad, han surgido nuevas bibliotecas para afrontar los desafíos de escalabilidad, velocidad y rendimiento. En este artículo, haremos un recorrido por algunas de las bibliotecas de DataFrame de código abierto más populares en Python, cada una de ellas ofreciendo características únicas para ayudarte a sacar el máximo provecho de tus datos.
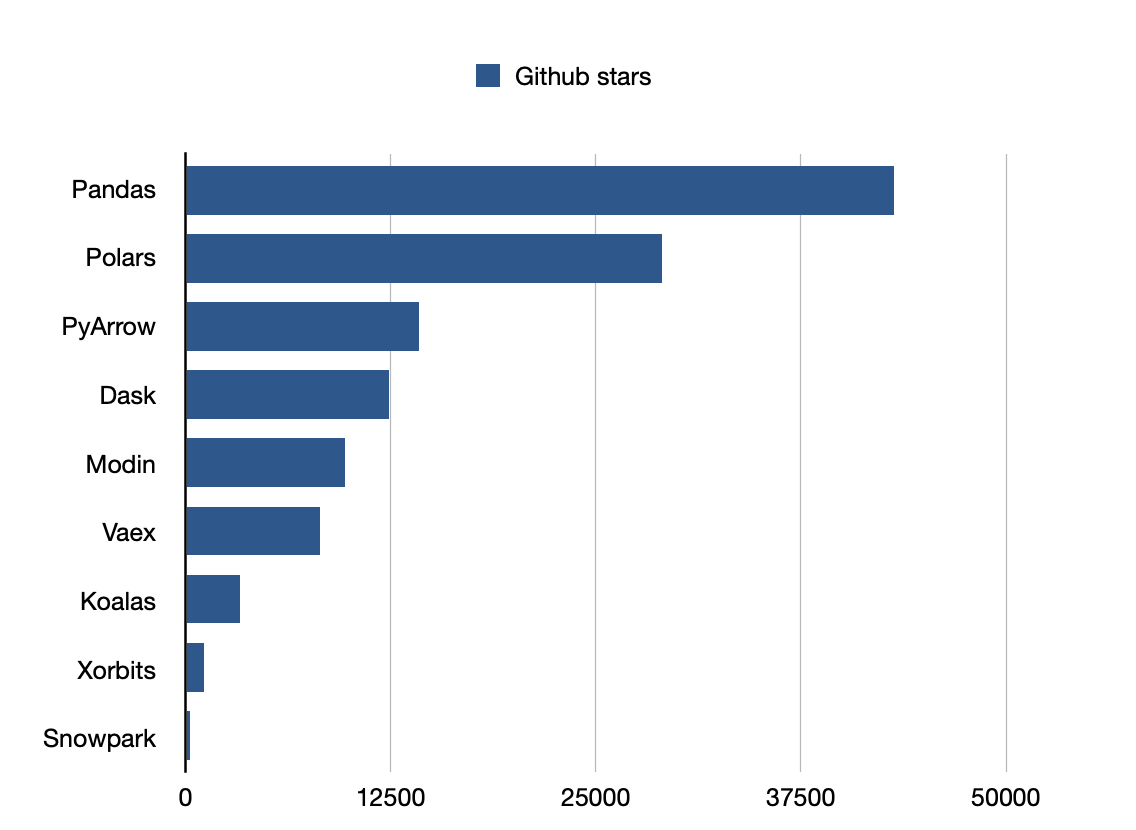
Pandas es la biblioteca más popular.
1. Pandas: El Veterano de la Ciencia de Datos
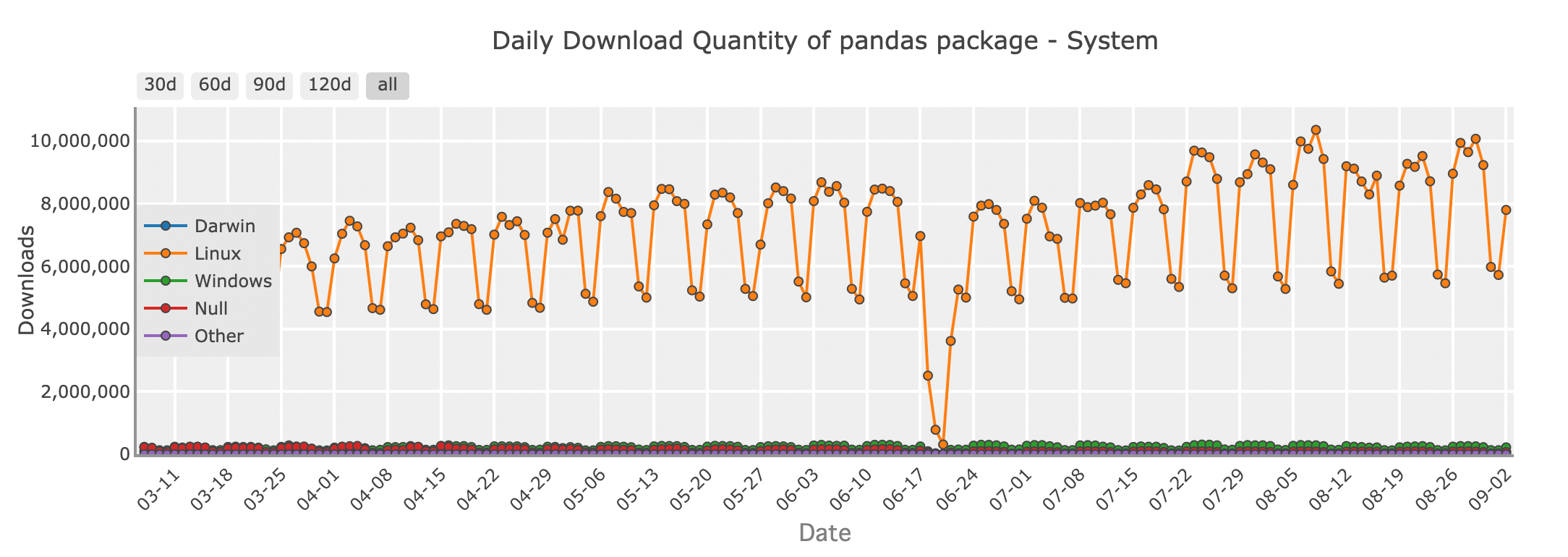
Cantidad de descargas diarias del paquete Pandas - sistema
Para muchos desarrolladores de Python, Pandas es la primera biblioteca que viene a la mente al trabajar con DataFrames. Su conjunto de características y API intuitiva hacen que sea fácil cargar, manipular y analizar datos. Ya sea que estés limpiando un conjunto de datos desordenado, fusionando datos de múltiples fuentes o realizando análisis estadísticos, Pandas proporciona todas las herramientas necesarias en un formato familiar parecido a una hoja de cálculo.
import pandas as pd
# Creando un DataFrame
data = {
'Name': ['Amy', 'Bob', 'Cat', 'Dog'],
'Age': [31,27,16,28],
'Department': ['HR', 'Engineering', 'Marketing', 'Sales'],
'Salary': [70000, 80000, 60000, 75000]
}
df = pd.DataFrame(data)
# Mostrando el DataFrame
print(df)Pandas sobresale en el manejo de conjuntos de datos pequeños a medianos que caben cómodamente en la memoria de tu computadora. Es perfecto para tareas diarias de datos, desde explorar datos en cuadernos de Jupyter hasta construir pipelines más complejos en producción. Sin embargo, a medida que tus conjuntos de datos crecen en tamaño, Pandas puede comenzar a mostrar sus limitaciones. Es ahí donde entran en juego otras bibliotecas de DataFrame.
Github stars: 43200
2. Modin: Escalando Pandas a Nuevas Alturas
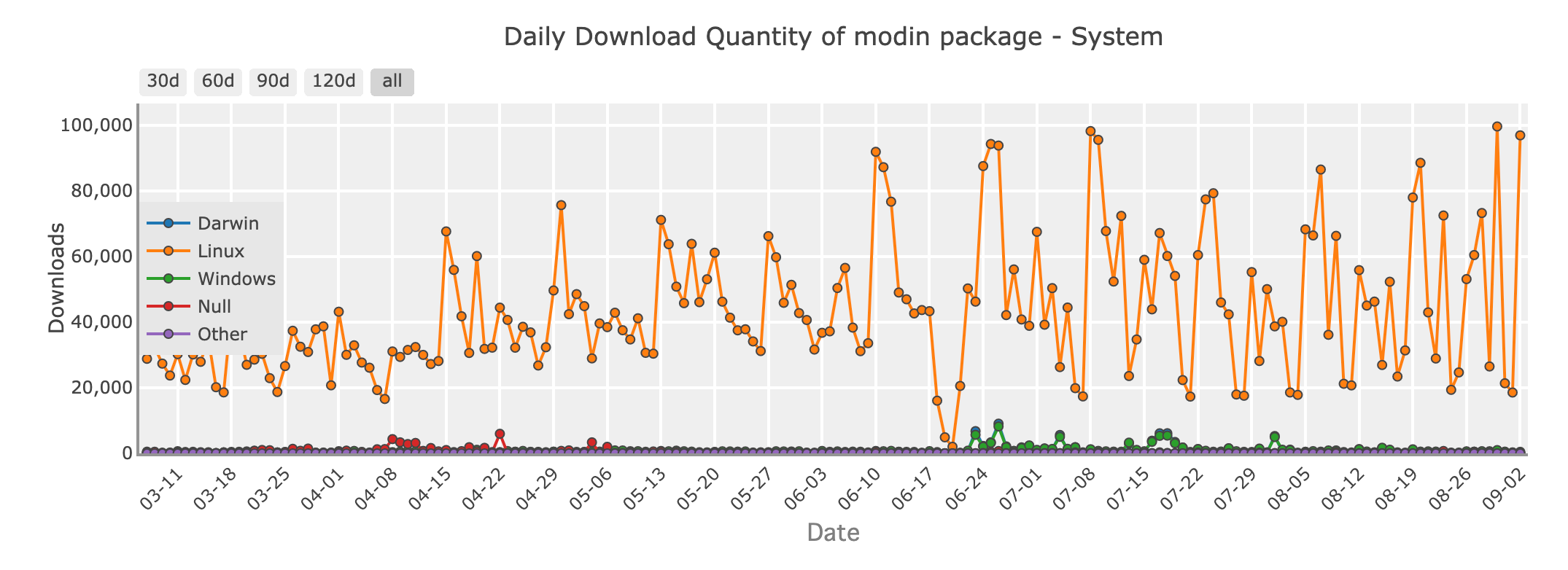
Cantidad de descargas diarias del paquete Modin - sistema
Imagina trabajar con un conjunto de datos demasiado grande para que Pandas lo maneje eficientemente. No quieres reescribir toda tu base de código, pero necesitas más velocidad y escalabilidad. Entra Modin, una biblioteca diseñada para hacer que tu código de Pandas se ejecute más rápido, sin requerir cambios importantes.
Modin es un reemplazo directo para Pandas, lo que significa que puedes tomar tu código existente de Pandas y paralelizarlo simplemente cambiando la declaración de importación. Detrás de escena, Modin utiliza potentes frameworks como Ray o Dask para distribuir tus cálculos en múltiples núcleos o incluso en un clúster de máquinas. Trae tiempos de procesamiento más rápidos para tus operaciones de datos.
Con Modin, obtienes la API familiar de Pandas que conoces y amas, pero con la capacidad de manejar conjuntos de datos más grandes y aprovechar al máximo tu hardware.
Github stars: 9700
3. Polars: Velocidad y Eficiencia Redefinidas
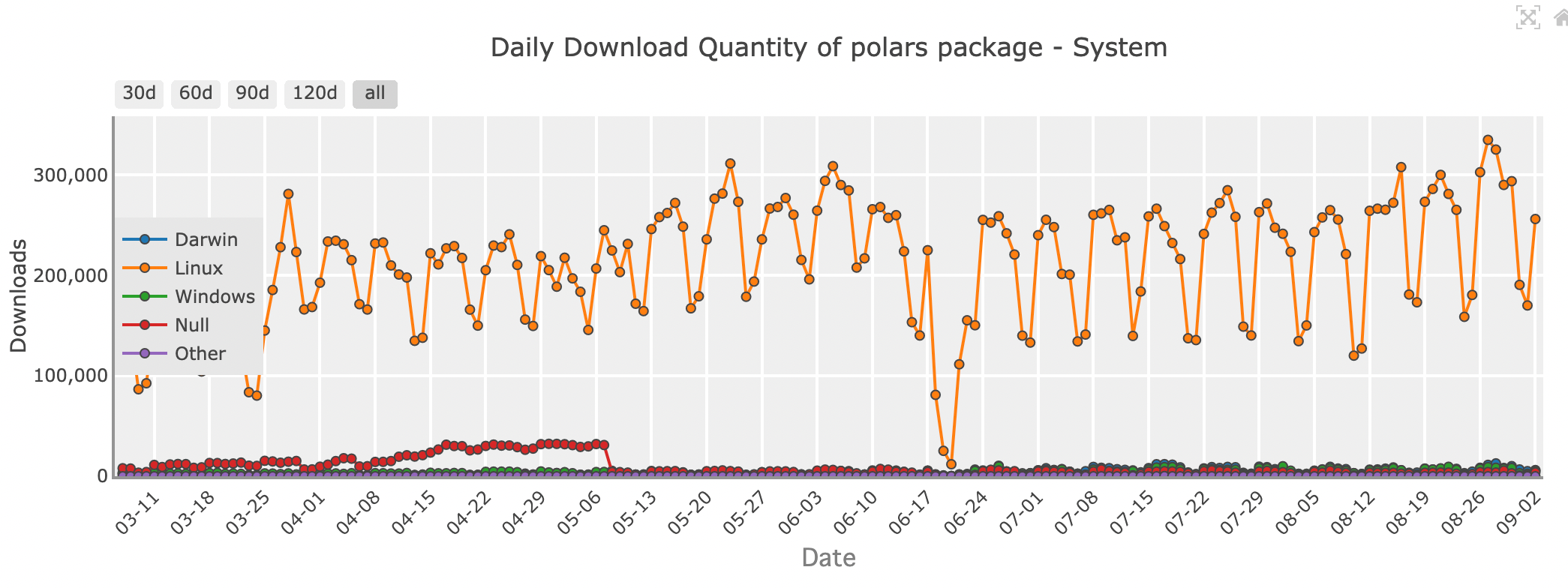
Cantidad de descargas diarias del paquete Polars - sistema
Cuando se trata de velocidad y eficiencia bruta, Polars está causando sensación en la comunidad de ciencia de datos. Escrito en Rust, un lenguaje de programación conocido por su rendimiento y seguridad, Polars está diseñado para ser rápido, muy rápido. Si estás manejando grandes conjuntos de datos o necesitas realizar operaciones complejas rápidamente, Polars podría ser la biblioteca adecuada para ti.
Polars utiliza una técnica llamada evaluación perezosa, donde las operaciones solo se ejecutan cuando es absolutamente necesario. Esto le permite optimizar toda la pipeline de cálculo, minimizando el tiempo y los recursos necesarios. Además, Polars está construido pensando en la multitarea, por lo que puede usar eficientemente todos los núcleos de tu máquina, lo que lo convierte en una elección ideal para tareas críticas de rendimiento.
Aunque Polars presume de una velocidad impresionante, viene con una curva de aprendizaje. Su API es diferente de la de Pandas, por lo que puede llevar tiempo acostumbrarse. Sin embargo, para aquellos dispuestos a invertir el tiempo, Polars ofrece un rendimiento sin igual y la capacidad de manejar conjuntos de datos que simplemente no serían viables con otras bibliotecas.
Github stars: 29000
| Característica/Aspecto | Pandas | Modin | Polars |
|---|---|---|---|
| Arquitectura | Monohilo, Python/Cython | Multihilo, distribuido (Ray/Dask) | Multihilo, escrito en Rust |
| Rendimiento | Bueno para conjuntos de datos pequeños a medianos | Escalable en múltiples núcleos o clústeres | Extremadamente rápido, maneja grandes conjuntos de datos |
| Uso de Memoria | Alto uso de memoria | Similar a Pandas | Bajo uso de memoria, soporte fuera de núcleo |
| Facilidad de Uso | Muy fácil, soporte comunitario extenso | Transición fácil desde Pandas | Intuitivo pero diferente API |
| Ecosistema | Maduro, bien integrado con otras bibliotecas | Compatible con el ecosistema de Pandas | Ecosistema más pequeño, pero en crecimiento |
| Casos de Uso | Conjuntos de datos pequeños a medianos, manipulación de datos | Conjuntos de datos más grandes, escalando operaciones de Pandas | Computación de alto rendimiento, grandes conjuntos de datos |
| Instalación | pip install pandas | pip install modin[all] | pip install polars |
4. Dask: Un DataFrame Distribuido para Big Data
Cantidad de descargas diarias del paquete Dask - sistema
Cuando tus datos crecen tanto que ya no caben en la memoria, Dask puede servir como un asistente poderoso. Dask es una biblioteca de computación paralela que extiende la API de Pandas para manejar conjuntos de datos que son demasiado grandes para una sola máquina.
Dask funciona dividiendo tu gran DataFrame en fragmentos más pequeños y procesándolos en paralelo, ya sea en tu máquina local o en un clúster. Esto te permite escalar tus cálculos sin preocuparte por quedarse sin memoria. Ya sea que estés trabajando con big data o construyendo pipelines de datos que necesitan escalar a miles de tareas, Dask proporciona la flexibilidad y el poder que necesitas.
Github stars: 12400
5. PyArrow: Intercambio de Datos Rápido con Apache Arrow
Cantidad de descargas diarias del paquete PyArrow - sistema
En el ámbito de la ingeniería de datos, PyArrow brilla como una biblioteca crucial para el intercambio eficiente de datos entre diferentes sistemas. Construido sobre el formato Apache Arrow, PyArrow proporciona un maravilloso formato de memoria columnar que permite lecturas sin copia para grandes conjuntos de datos. Esto lo convierte en una elección perfecta para escenarios donde el rendimiento y la interoperabilidad son clave.
PyArrow se utiliza ampliamente para habilitar transferencias de datos rápidas entre lenguajes como Python, R y Java, y juega un papel fundamental en muchos frameworks de procesamiento de big data. Si estás trabajando con grandes pipelines de datos, especialmente donde los datos necesitan ser compartidos entre diferentes herramientas o plataformas, PyArrow es una herramienta valiosa en tu arsenal.
Github stars: 14200
6. Snowpark: DataFrames en la Nube con Snowflake
Cantidad de descargas diarias del paquete Snowpark - sistema
A medida que más organizaciones trasladan sus operaciones de datos a la nube, Snowpark emerge como una solución innovadora para los desarrolladores de Python. Snowpark es una característica de Snowflake, un almacén de datos en la nube, que te permite usar operaciones estilo DataFrame directamente dentro del entorno de Snowflake. Esto significa que puedes operar transformaciones y análisis de datos complejos sin mover tus datos fuera de Snowflake, reduciendo la latencia y aumentando la eficiencia.
Con Snowpark, puedes escribir código Python que se ejecute nativamente en la infraestructura de Snowflake, aprovechando el poder de la nube para procesar conjuntos de datos masivos fácilmente. Es una excelente opción para equipos que ya utilizan Snowflake y buscan agilizar sus flujos de trabajo de procesamiento de datos.
Github stars: 253
7. Xorbits: Una Solución Unificada para Escalar Data Science
Cantidad de descargas diarias del paquete Xorbits - sistema
Xorbits es un potente framework diseñado para escalar las operaciones de ciencia de datos en entornos distribuidos. Ofrece una API unificada que abstrae las complejidades de la computación distribuida, permitiéndote escalar tus operaciones de DataFrame en múltiples nodos sin tener que preocuparte por la infraestructura subyacente.
Xorbits se integra fácilmente con herramientas existentes como Pandas, Dask y PyTorch, lo que lo convierte en una elección ideal para aplicaciones de machine learning y ciencia de datos que requieren flexibilidad. Ya sea que estés entrenando grandes modelos o procesando grandes cantidades de datos, Xorbits proporciona la flexibilidad y el poder para manejar el trabajo.
Github stars: 1100
8. Vaex: DataFrames Fuera de Núcleo para Análisis Eficiente
Cantidad de descargas diarias del paquete Vaex - sistema
Si estás trabajando con grandes conjuntos de datos que exceden la memoria de tu sistema pero aún deseas la simplicidad de Pandas, Vaex vale la pena explorar. Vaex está diseñado para la computación fuera de núcleo, lo que significa que puede manejar conjuntos de datos más grandes que tu RAM procesando datos en fragmentos, sin cargar todo en memoria a la vez.
Vaex está optimizado para la velocidad y ofrece características como filtrado rápido, agrupación y agregación, todo mientras mantiene el uso de memoria al mínimo. Es especialmente útil para tareas como la exploración de datos, el análisis estadístico e incluso el machine learning en grandes conjuntos de datos.
Github stars: 8200
9. Koalas: Llevando Pandas a Big Data con Apache Spark
Cantidad de descargas diarias del paquete Koalas - sistema
Para los desarrolladores de Python que trabajan en el mundo de big data, Apache Spark es un nombre familiar. Koalas es una biblioteca que conecta Pandas con Spark, permitiéndote usar una sintaxis similar a la de Pandas en conjuntos de datos distribuidos gestionados por Spark. Esto significa que puedes aprovechar la escalabilidad de Spark mientras escribes código que se siente como Pandas.
Koalas es una gran opción si estás haciendo la transición de Pandas a entornos de big data, ya que minimiza la curva de aprendizaje asociada con Spark y te permite escribir código que escala sin perder la simplicidad de Pandas.
Github stars: 3300
Elegir la Herramienta Adecuada para el Trabajo
Con tantas opciones disponibles, ¿cómo eliges la biblioteca de DataFrame adecuada para tu proyecto? Aquí hay algunas pautas:
- Conjuntos de Datos Pequeños a Medianos: Si tus datos caben cómodamente en la memoria, Pandas sigue siendo la mejor opción por su facilidad de uso y rica funcionalidad.
- Escalando Pandas: Si estás enfrentando cuellos de botella en el rendimiento con Pandas, pero no quieres cambiar tu código, Modin ofrece un camino fácil hacia una ejecución más rápida.
- Tareas Críticas de Rendimiento: Para necesidades de alto rendimiento y grandes conjuntos de datos, Polars ofrece una velocidad y eficiencia impresionantes debido a su diseño ligero, lo que lo hace particularmente efectivo en dispositivos locales. Sin embargo, es importante notar que Polars no está diseñado principalmente para el procesamiento distribuido de grandes datos, donde soluciones como Modin pueden ser más apropiadas.
- Big Data y Computación Distribuida: Al trabajar con big data, Dask, Koalas y Xorbits son excelentes opciones para escalar tus cálculos en múltiples máquinas.
- Interoperabilidad y Compartición de Datos: Si necesitas un intercambio de datos eficiente entre diferentes sistemas o lenguajes, PyArrow es la biblioteca preferida.
- Operaciones Basadas en la Nube: Para aquellos que aprovechan la infraestructura de la nube, Snowpark ofrece una integración fluida con Snowflake, permitiendo potentes cálculos dentro de la base de datos.
Ya sea que estés trabajando con pequeños conjuntos de datos o abordando enormes pipelines de datos distribuidos, hay una biblioteca de Python que se adapta a tus necesidades. Al explorar estas bibliotecas de DataFrame de código abierto, estarás mejor equipado para aprovechar al máximo tus datos, sin importar su tamaño o complejidad.
Así que adelante, sumérgete en el mundo de los DataFrames y desata el poder de Python para tu próxima aventura basada en datos!