Dominando a Visualização de Dataframes em Python com Pandas
- Name
- Rajiv Chandra
Atualizado em
A visualização de dataframes é uma ferramenta poderosa no arsenal de qualquer cientista de dados ou analista de dados. Ela nos permite entender conjuntos de dados complexos e extrair insights que podem não ser imediatamente aparentes a partir dos dados brutos. Este artigo irá guiá-lo através do processo de visualização de dataframes usando Python, com um foco especial na biblioteca pandas. Abordaremos desde o básico até técnicas mais avançadas, fornecendo muitos exemplos de código ao longo do caminho.
Por que Visualizar Dataframes?
A visualização de dados é um aspecto essencial da análise exploratória de dados. Ela ajuda você a identificar tendências, padrões e valores discrepantes em seus dados de forma rápida. Além disso, a visualização de dados apresenta seus resultados de análise de forma mais eficaz, o que impulsiona as discussões em torno desses resultados, em vez de apresentar apenas os números.
Por exemplo, imagine que você está trabalhando com um grande conjunto de dados contendo informações sobre a população de uma cidade ao longo de vários anos. Embora você possa analisar os dados linha por linha, seria muito mais eficiente e intuitivo criar um gráfico de linha mostrando as mudanças na população ao longo do tempo. É aqui que a visualização de dataframes entra em jogo.
PyGWalker: Visualização de Dataframes por Arrastar e Soltar
Se você está procurando uma ferramenta poderosa e amigável para visualização interativa de dados em Python, não precisa procurar mais do que o PyGWalker. Pronunciado como "Pig Walker", o PyGWalker significa "Python binding of Graphic Walker". Ele integra o Jupyter Notebook com o Graphic Walker, uma alternativa de código aberto ao Tableau, permitindo que cientistas de dados analisem dados e visualizem padrões com operações simples de arrastar e soltar.

Para começar com o PyGWalker, você precisa instalá-lo primeiro. Você pode fazer isso através do pip ou conda:
# Usando o pip
pip install pygwalker
# Usando o conda
conda install -c conda-forge pygwalkerDepois de instalado, você pode importar o PyGWalker e o pandas no seu Jupyter Notebook:
import pandas as pd
import pygwalker as pygCom o PyGWalker, você pode transformar seu dataframe pandas em uma interface do usuário no estilo do Tableau para exploração visual. Por exemplo, se você tiver
um dataframe carregado no pandas, você pode chamar o Graphic Walker com o dataframe desta forma:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Isso criará uma interface do usuário semelhante ao Tableau, onde você pode analisar e visualizar dados arrastando e soltando variáveis. Você pode alterar o tipo de marca para criar gráficos diferentes, criar uma visualização concatenada para comparar diferentes medidas e até mesmo salvar o resultado da exploração dos seus dados em um arquivo local.
Agora que você configurou o PyGWalker, pode usá-lo para uma visualização poderosa de dados. Altere o tipo de marca para criar diferentes tipos de gráficos, como um gráfico de linha:

Compare diferentes medidas criando uma visualização concatenada com várias medidas em linhas/colunas:

Crie uma visualização facetada com várias subvisualizações divididas por um valor de dimensão:
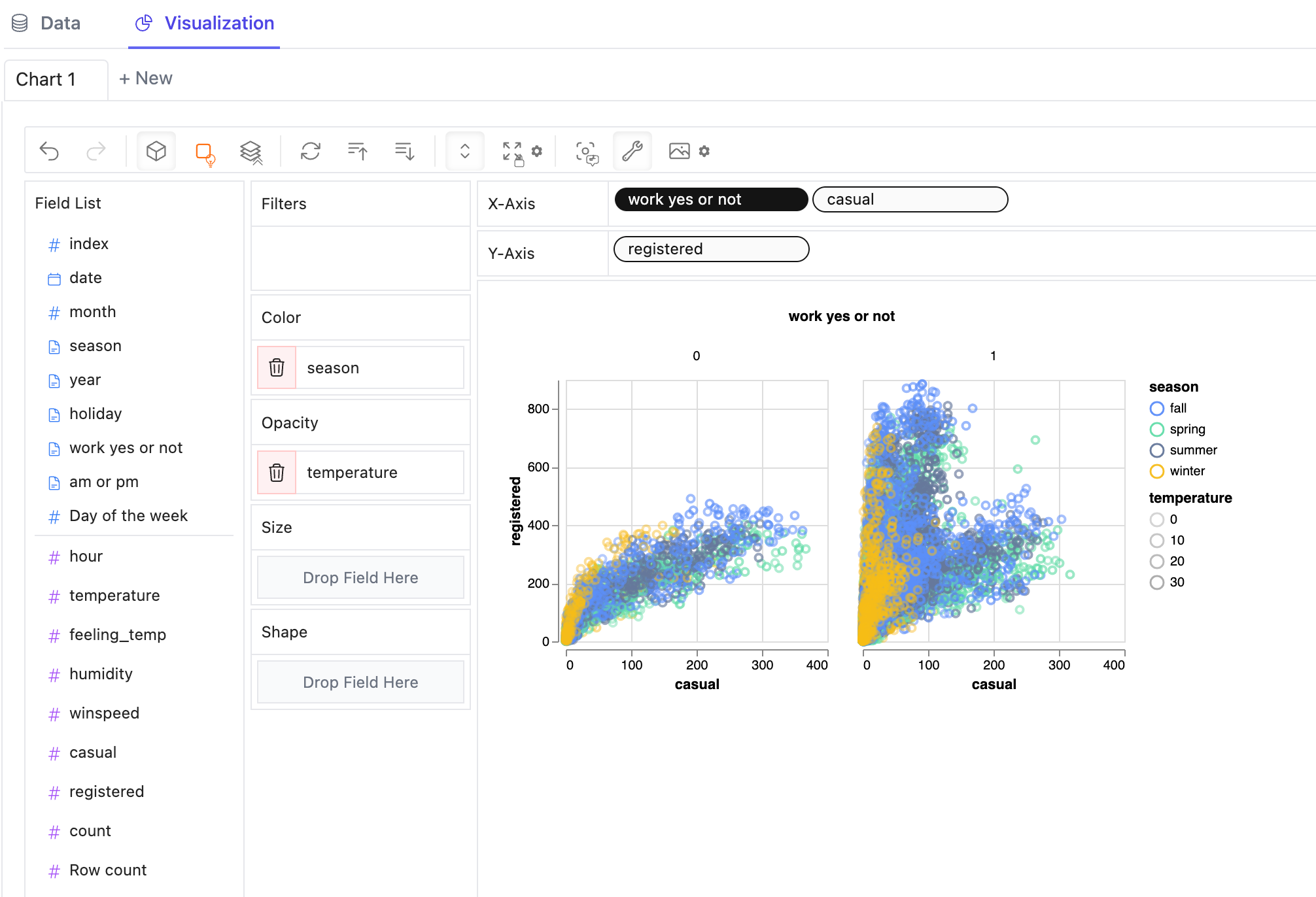
Visualize seu dataframe em uma tabela e configure tipos analíticos e tipos semânticos:

O PyGWalker não é apenas simples de usar, mas também poderoso. Ele pode lidar com conjuntos de dados grandes e visualizações complexas. Seja trabalhando com um conjunto de dados pequeno ou grande, o PyGWalker pode ajudá-lo a explorar e analisar seus dados de forma eficaz.
Se você está trabalhando com dataframes em Python e precisa de uma ferramenta para visualização de dados, o PyGWalker é uma ótima escolha. É fácil de usar, poderoso e se integra perfeitamente ao Jupyter Notebook e ao pandas. Então, por que não experimentar e ver como ele pode aprimorar seu fluxo de análise e visualização de dados?
Confira a página do Github do PyGWalker (opens in a new tab).
Primeiros Passos com Pandas para Visualização de Dataframes
A popular biblioteca de análise de dados em Python, pandas, oferece várias opções diferentes para visualizar seus dados. Mesmo que você esteja no início de sua jornada com o pandas, em breve estará criando plots básicos que proporcionarão insights valiosos sobre seus dados.
Para começar com o pandas, você precisa importá-lo. Veja como fazer isso:
import pandas as pdDepois de importar o pandas, você pode começar a usá-lo para criar plots. Por exemplo, se você tiver um dataframe df com duas colunas A e B, você pode criar um gráfico de linha de
A em relação a B desta forma:
df.plot(x='A', y='B', kind='line')Isso criará um gráfico de linha com 'A' no eixo x e 'B' no eixo y. O parâmetro kind determina o tipo de gráfico a ser criado. Neste caso, estamos criando um gráfico de linha, mas você também pode criar um gráfico de barras, um histograma, um gráfico de dispersão e outros.
Diferentes Formas de Visualizar Dataframes no Pandas
O pandas oferece uma variedade de formas de visualizar dataframes, cada uma adequada a diferentes tipos de dados e diferentes tipos de perguntas. Vamos explorar alguns dos tipos de plots mais comuns que você pode criar com o pandas.
Gráficos de Linha
Os gráficos de linha são ótimos para visualizar mudanças ao longo do tempo. Por exemplo, se você tiver um dataframe com uma coluna de data e uma coluna numérica, você pode usar um gráfico de linha para visualizar como o valor numérico muda ao longo do tempo.
Aqui está um exemplo:
df.plot(x='date', y='value', kind='line')Isso criará um gráfico de linha com 'date' no eixo x e 'value' no eixo y.
Gráficos de Barras
Os gráficos de barras são úteis para comparar quantidades entre diferentes categorias. Por exemplo, se você tiver um dataframe com uma coluna categórica e uma coluna numérica, você pode usar um gráfico de barras para comparar os valores numéricos entre diferentes categorias.
Veja como você pode criar um gráfico de barras:
df.plot(x='category', y='value', kind='bar')Isso criará um gráfico de barras com 'category' no eixo x e 'value' no eixo y.
Histogramas
Histogramas são úteis para visualizar a distribuição de uma variável numérica. Eles dividem a variável em bins, contam o número de observações em cada bin e representam essas contagens com barras.
Veja como você pode criar um histograma de uma coluna numérica:
df['value'].plot(kind='hist')Isso criará um histograma da coluna 'value'.
Estratégias Avançadas para Visualização de Dataframes
Embora as capacidades básicas de plotagem do pandas sejam poderosas, também existem estratégias mais avançadas que podem ajudar você a criar visualizações ainda mais informativas. Vamos explorar algumas dessas técnicas.
Subplots
Subplots permitem que você crie vários plots em uma única figura. Isso pode ser particularmente útil quando você deseja comparar várias distribuições ou tendências ao mesmo tempo. Aqui está um exemplo de como você pode criar subplots no pandas:
df[['A', 'B', 'C']].plot(subplots=True)Isso criará três subplots, um para cada uma das colunas 'A', 'B' e 'C'.
Scatter Matrix
Uma scatter matrix é um gráfico de dispersão par a par de várias variáveis apresentado em um formato de matriz. Ele pode ser usado para determinar se as variáveis estão correlacionadas e se a correlação é positiva ou
negativa. No pandas, você pode criar uma scatter matrix usando a função scatter_matrix do módulo pandas.plotting:
from pandas.plotting import scatter_matrix
scatter_matrix(df[['A', 'B', 'C']])Isso criará uma scatter matrix para as colunas 'A', 'B' e 'C'.
Visualização Interativa de Dataframes com Pandas
Embora os plots estáticos sejam úteis, plots interativos podem fornecer uma compreensão mais profunda dos dados, permitindo que você dê zoom em áreas de interesse, passe o mouse sobre pontos para ver seus valores e muito mais. Existem várias ferramentas que podem ajudá-lo a criar visualizações interativas com pandas, como o Qgrid e o Lux.
Qgrid
O Qgrid é um widget do Jupyter Notebook que usa o componente SlickGrid para adicionar interatividade ao seu dataframe. Ele permite classificar, filtrar e editar DataFrames no Jupyter Notebook. Veja um exemplo de como você pode usar o Qgrid:
import qgrid
qgrid_widget = qgrid.show_grid(df, show_toolbar=True)
qgrid_widgetIsso criará uma grade interativa para o dataframe df.
Lux
O Lux é uma ferramenta de visualização leve que facilita a exploração dos seus dados, recomendando automaticamente visualizações úteis e relevantes à medida que você trabalha com seu dataframe do pandas. Veja como você pode usar o Lux:
import lux
df.intent = ['A', 'B']
dfIsso irá gerar automaticamente visualizações para as colunas 'A' e 'B' no dataframe df.
Visualizando Dados Agrupados de um Dataframe
Muitas vezes, você pode querer agrupar seus dados por certas variáveis e visualizar os dados agrupados. Por exemplo, você pode querer agrupar um conjunto de dados de populações de cidades por ano e visualizar a variação populacional ao longo do tempo. Veja como você pode fazer isso no pandas:
grouped = df.groupby('year')['population'].sum()
grouped.plot(kind='line')Isso criará um gráfico de linha da população total para cada ano.
- Runcell Science: alternativa open source ao Claude Science para pesquisa com IA
- Como impedir o Mac de dormir: mantenha Codex, Claude Code e agentes de IA rodando
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: qual stack de agentes de IA você deve escolher em 2026?
- Como o Claude Code analisa notebooks Jupyter em Data Science: capacidade real, limites e alternativa melhor
- Claude Code Routines: rotinas e cron jobs para agentes de IA
- Claude Code Desktop: como ativar Bypass permissions
- Como Construir Dois Agentes Python com o Protocolo A2A do Google - Tutorial Passo a Passo
- Top 10 bibliotecas de visualização de dados em Python em 2025
Conclusão
Em conclusão, a visualização de dataframes é uma ferramenta poderosa para análise de dados e ciência de dados. Com Python e pandas, você pode criar uma grande variedade de visualizações, desde plots básicos até visualizações mais avançadas e interativas. Portanto, comece a visualizar seus dataframes hoje mesmo e descubra os insights ocultos em seus dados!
Perguntas Frequentes
-
O que é visualização de dataframe? A visualização de dataframe é o processo de representar dados de um dataframe em um formato visual, como um gráfico ou um diagrama. Isso ajuda a entender os padrões, tendências e correlações nos dados.
-
Como posso visualizar um dataframe em Python? Python oferece várias bibliotecas para visualização de dataframes, incluindo pandas, matplotlib, seaborn e PyGWalker. Essas bibliotecas fornecem funções para criar vários tipos de plots, como gráficos de linha, gráficos de barras, histogramas e outros.
-
**
O que é visualização de dataframe no pandas?**
A visualização de dataframe no pandas envolve o uso da biblioteca pandas em Python para criar representações visuais de dados armazenados em dataframes do pandas. O pandas fornece uma função .plot() que pode ser usada para criar vários tipos de plots.
-
Quais são algumas ferramentas para visualização de dataframes no pandas? Algumas ferramentas populares para visualização de dataframes no pandas incluem o próprio pandas, matplotlib, seaborn e ferramentas interativas como PyGWalker e Qgrid.
-
É possível visualizar um dataframe do pandas com o Plotly? Sim, o Plotly é outra biblioteca em Python que pode ser usada para criar plots interativos para dataframes do pandas. Ele oferece uma interface de alto nível para desenhar gráficos estatísticos atraentes e informativos.