Análise Causal
RATH oferece um fluxo de trabalho visual e sem código para encontrar e explorar relações causais nos seus dados. Em vez de parar em correlações simples, você pode descobrir causas potenciais, testar hipóteses e construir modelos de machine learning melhores — tudo a partir de um grafo causal interativo.
Neste guia, você vai:
- Entender o que é análise causal e quando utilizá-la.
- Aprender o fluxo de trabalho passo a passo para executar análise causal no RATH.
- Acompanhar um exemplo concreto usando o dataset “Diabetes” do Kaggle.
- Explorar ferramentas avançadas como análise comparativa, inspeção mútua, testes de predição e edição manual de modelos causais.
O que é análise causal?
Análise causal é o processo de examinar relações entre variáveis para determinar se mudanças em uma variável causam mudanças em outra — e não apenas se elas variam juntas.
Na prática, isso significa:
- Identificar variáveis que podem influenciar um desfecho de interesse.
- Construir um modelo causal (geralmente um grafo direcionado) que codifica suposições ou relações aprendidas.
- Utilizar técnicas estatísticas e algoritmos para estimar a força e a direção desses efeitos.
- Testar e refinar hipóteses, em vez de depender apenas de correlação ou importância de atributos.
Como a maior parte dos dados do mundo real é observacional (não coletada em experimentos controlados), a análise causal não garante “causalidade verdadeira”, mas ajuda a gerar e validar hipóteses muito mais fortes e interpretáveis do que a correlação isoladamente.
Como realizar análise causal com o RATH
RATH encapsula técnicas complexas de descoberta causal em um fluxo de trabalho interativo. Em alto nível, você:
-
Conecta e prepara seus dados
- Importa seu dataset para o RATH.
- Limpa registros inválidos e garante que campos-chave estejam corretamente tipados (numéricos, categóricos etc.).
-
Configura campos e dependências opcionais
- Escolhe os campos que devem ser incluídos no modelo causal.
- Opcionalmente declara dependências funcionais conhecidas (por exemplo, campos derivativos, fórmulas) para que o RATH as respeite durante a descoberta.
-
Executa a descoberta causal
- Inicia o fluxo de trabalho Causal Analysis e deixa o RATH inferir um grafo causal a partir dos seus dados.
-
Explora e valida relações
- Usa ferramentas como Field Insights, Manual Exploration e Mutual Inspection para verificar e refinar o modelo descoberto com base no conhecimento de domínio.
-
Constrói e testa modelos preditivos
- Usa Prediction Test para criar modelos de machine learning baseados no grafo causal e compará-los com conjuntos de atributos alternativos.
-
Edita e finaliza o modelo causal
- Ajusta manualmente o modelo quando você tem conhecimento adicional, dados ruidosos ou fatores ausentes.
As seções seguintes percorrem esse fluxo de trabalho com um exemplo real.
Estudo de caso: análise causal do "Diabetes Database" do Kaggle
Como exemplo concreto, vamos explorar o “Diabetes Database” do Kaggle (opens in a new tab) usando o RATH. Nosso objetivo é entender quais fatores afetam mais fortemente o Outcome (diagnóstico de diabetes) e como eles interagem.
Preparar e limpar o dataset
- Importe o dataset para o RATH.
- Remova registros inválidos em que
BMI,BloodPressuresouSkinThicknesssejam iguais a0.
Na aba DataSource:- Clique em Clean Method.
- Escolha drop null records para filtrar linhas com valores inválidos.
Quando os dados estiverem limpos, abra o menu suspenso à direita do botão Start Analysis e escolha Causal Analysis para iniciar o fluxo de trabalho.
Etapa 1: Configuração dos Dados
Em Data Configuration, escolha quais campos serão incluídos na análise causal.
- Selecione todas as variáveis relevantes (por exemplo,
Pregnancies,Glucose,BloodPressure,SkinThickness,Insulin,BMI,DiabetesPedigreeFunction,AgeeOutcome). - Opcionalmente exclua campos que você sabe serem irrelevantes ou muito ruidosos.
Quando terminar, clique em Next para prosseguir.
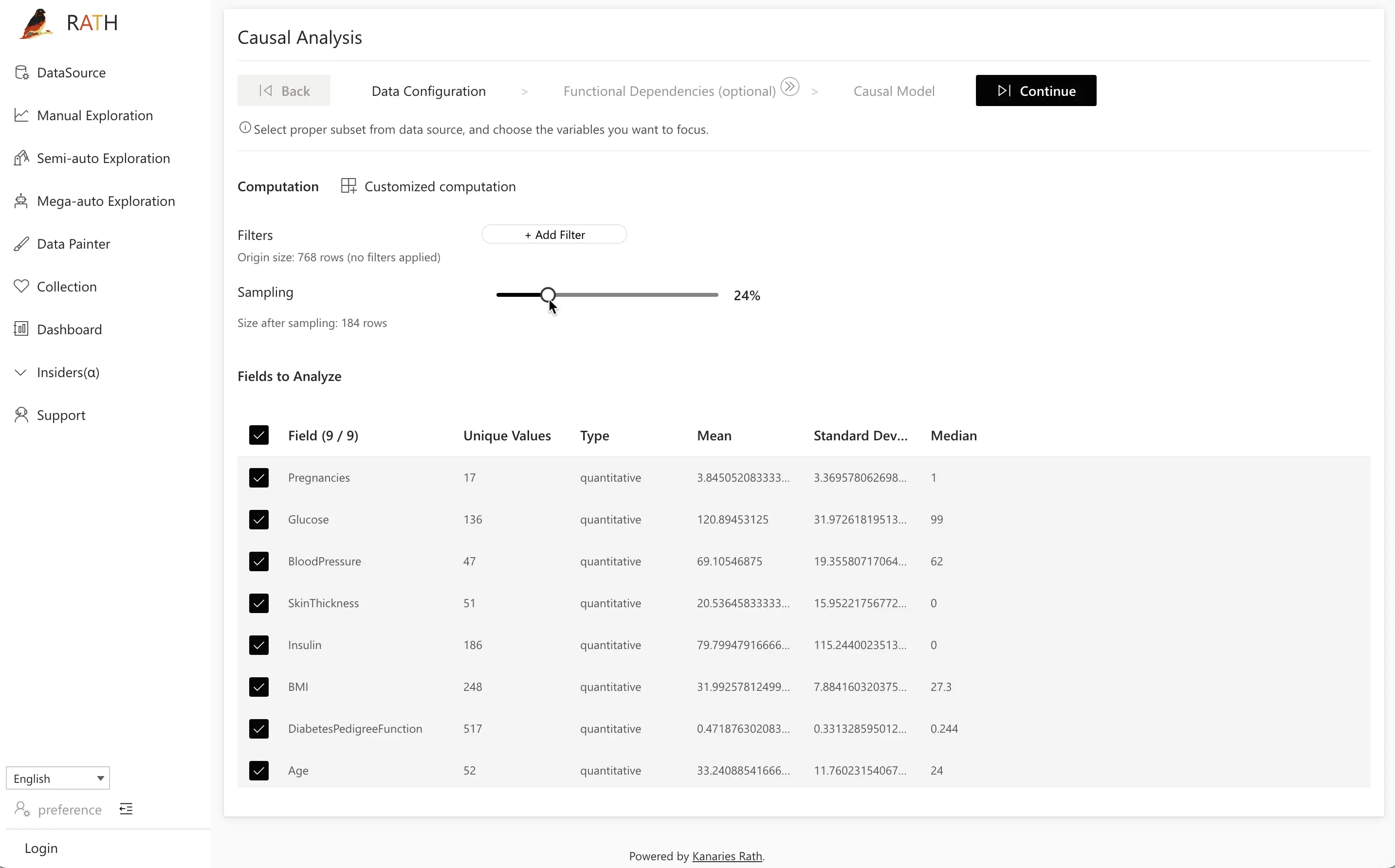
Dica: Comece com todas as variáveis potencialmente relevantes e depois refine com base no seu modelo causal e nos resultados de predição.
Etapa 2: (Opcional) Dependências Funcionais
Em muitos datasets, alguns campos são derivados de outros (por exemplo, razões calculadas, IDs formatados ou campos gerados por fórmulas SQL). Declarar essas relações antecipadamente ajuda o RATH a evitar aprender ligações causais enganosas.
Na etapa Functional Dependencies, você pode:
- Deixar o RATH analisar automaticamente seus dados e sugerir dependências.
- Especificar manualmente relações quando você já as conhece (por exemplo,
TotalAmount = Quantity × UnitPrice).
RATH analisa os valores de diferentes variáveis e computa possíveis relações funcionais. Você pode aceitar, editar ou adicionar suas próprias dependências.
Boa prática:
Se parte dos seus dados é gerada usando expressões regulares ou fórmulas SQL, declare aqui essas dependências. Se esses campos derivados forem gerados dentro do RATH, geralmente você não precisa fazer nada — o RATH lida com isso automaticamente.
Etapa 3: Modelo Causal
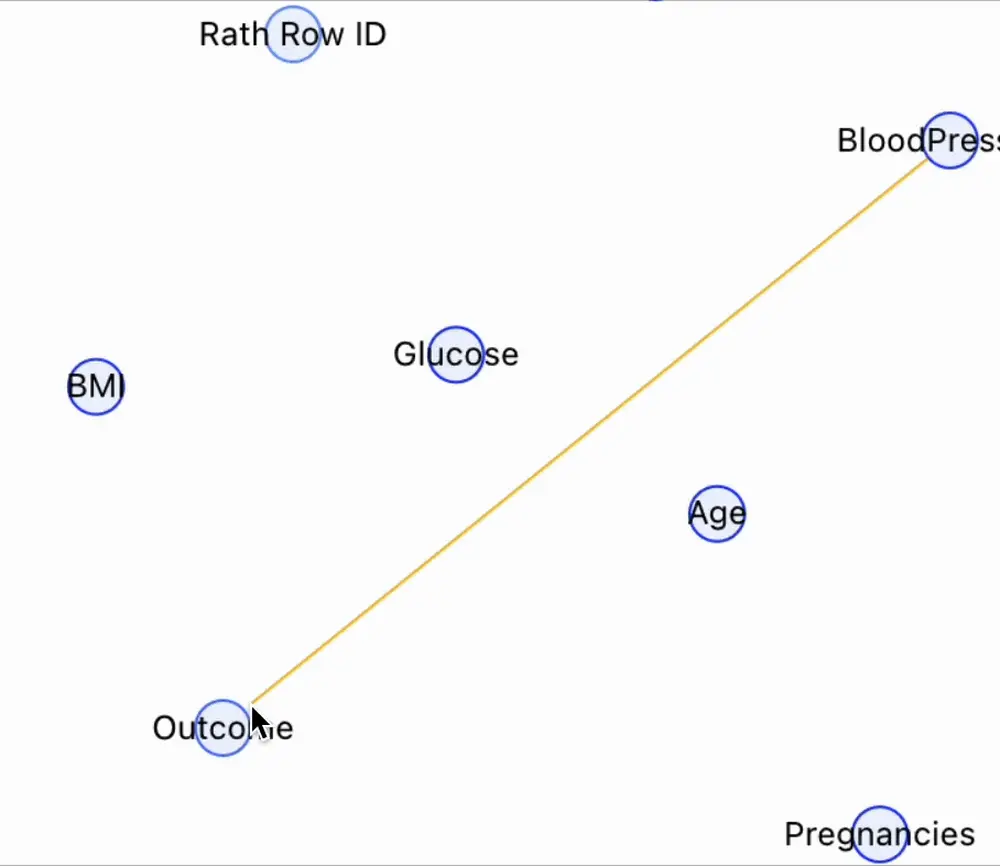
Clique em Causal Discovery para que o RATH infira um modelo causal a partir dos campos configurados.
A captura de tela abaixo mostra um resultado típico de descoberta causal para o dataset de diabetes:
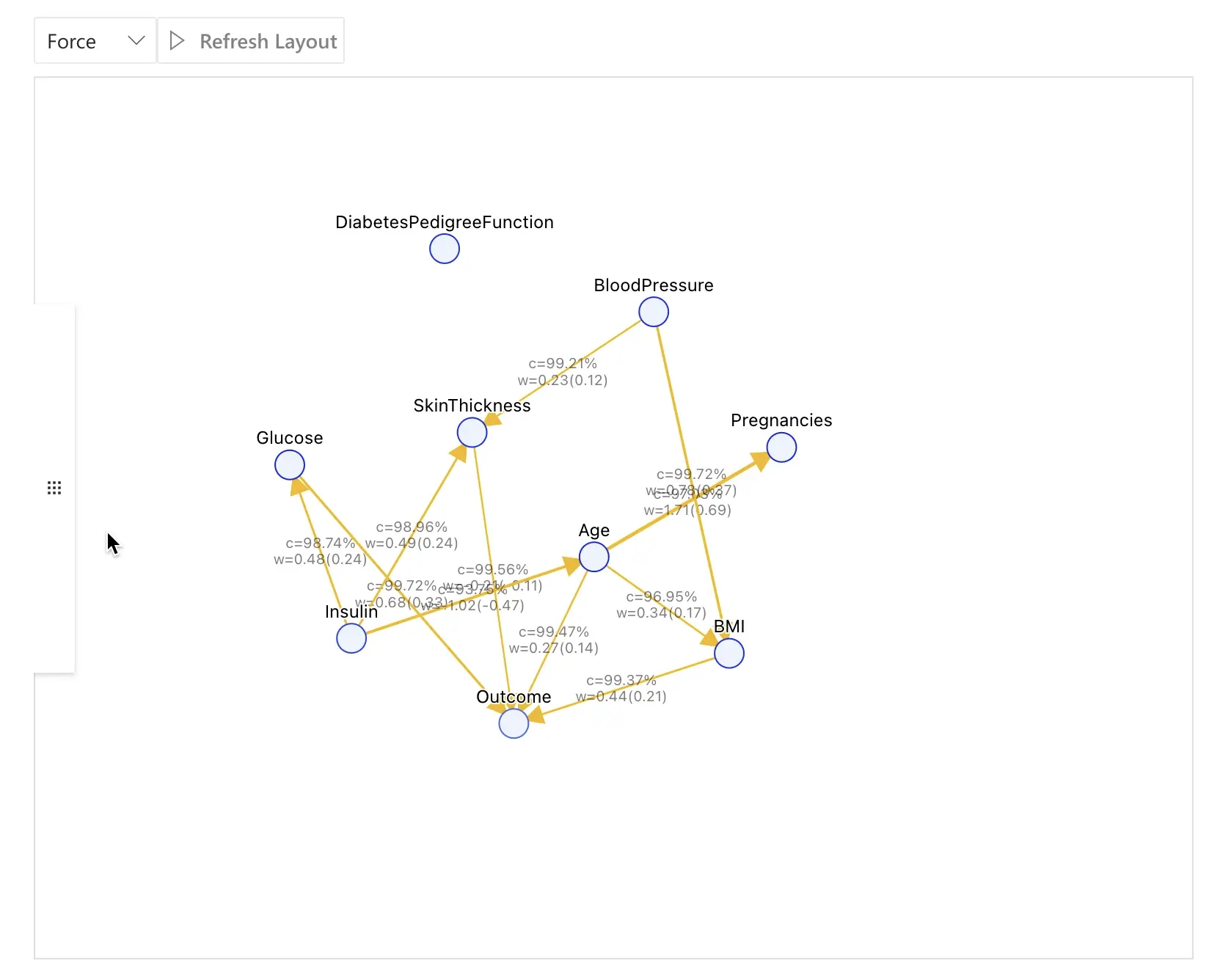
Neste exemplo, alguns dos relacionamentos principais são:
Glucose→Outcome
Níveis mais altos de glicose aumentam a probabilidade de um diagnóstico positivo de diabetes.Insulin→Glucose→Outcome
Insulina afeta glicose, que por sua vez afeta o desfecho de diabetes.Age→Outcome(e às vezes influenciada por fatores de saúde relacionados)
Idade contribui para a probabilidade de ter diabetes.
O grafo interativo é o seu espaço de trabalho central:
- Clique em um nó para destacar suas causas e efeitos diretos.
- Examine a espessura da aresta ou o indicador de força para entender o quão forte é uma relação.
- Use o painel à direita para acessar diferentes ferramentas (Field Insights, Manual Exploration, Mutual Inspection, Prediction Test) focadas na variável selecionada.
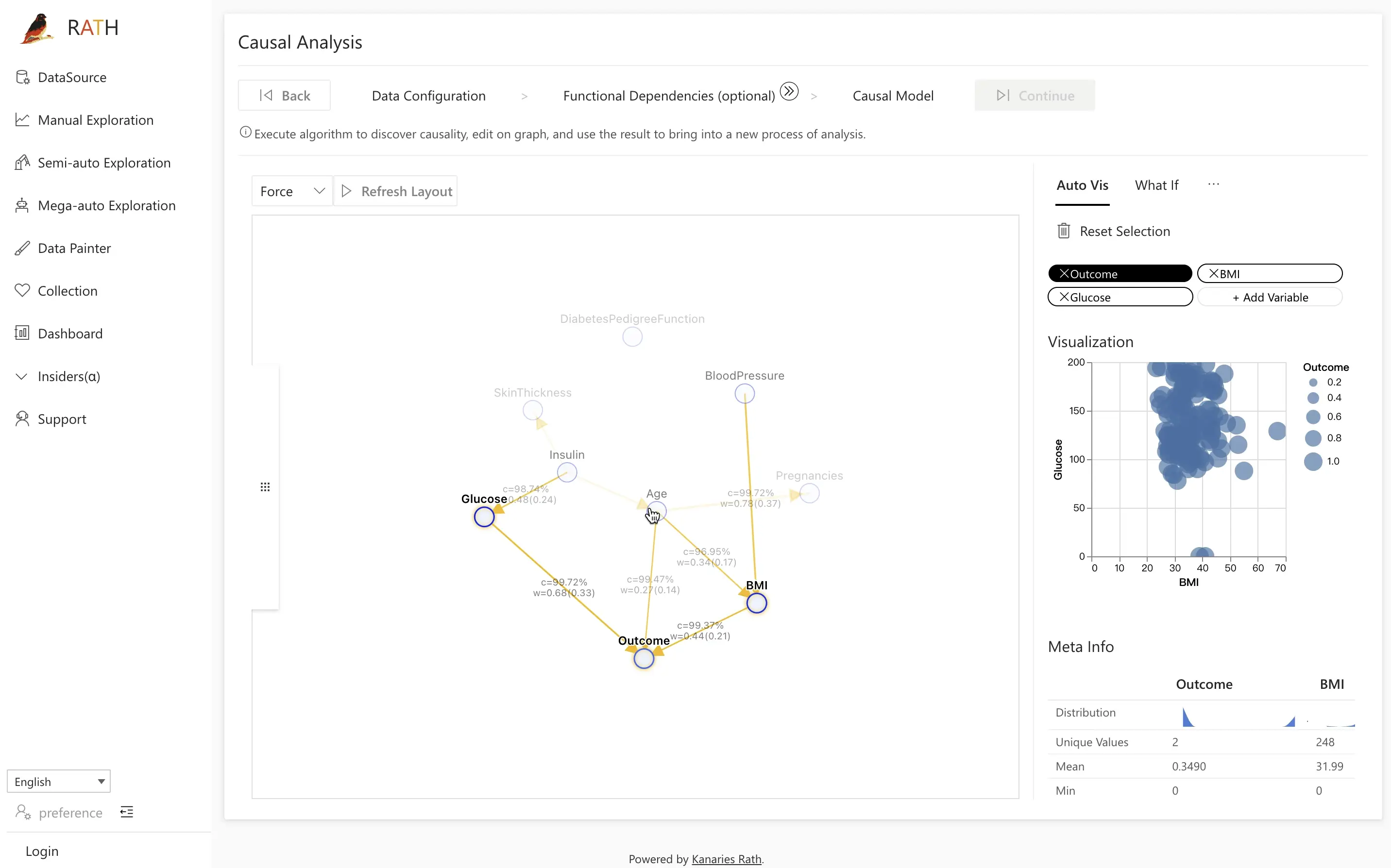
Etapa 3.1: Análise Comparativa com Field Insights
A análise comparativa permite comparar dois grupos — por exemplo, pacientes com e sem diabetes — e explicar as diferenças usando o seu modelo causal.
O RATH oferece vários modos de comparação:
- Subset vs. Whole
(por exemplo, janeiro vs. o ano inteiro) - Subset vs. Complement
(janeiro vs. “todo o resto exceto janeiro”) - Subset vs. Another Subset
(janeiro vs. junho)
Você pode usar essas comparações para:
- Investigar fatores causais potenciais por trás de anomalias ou outliers.
- Verificar e refinar hipóteses causais usando distribuições reais.
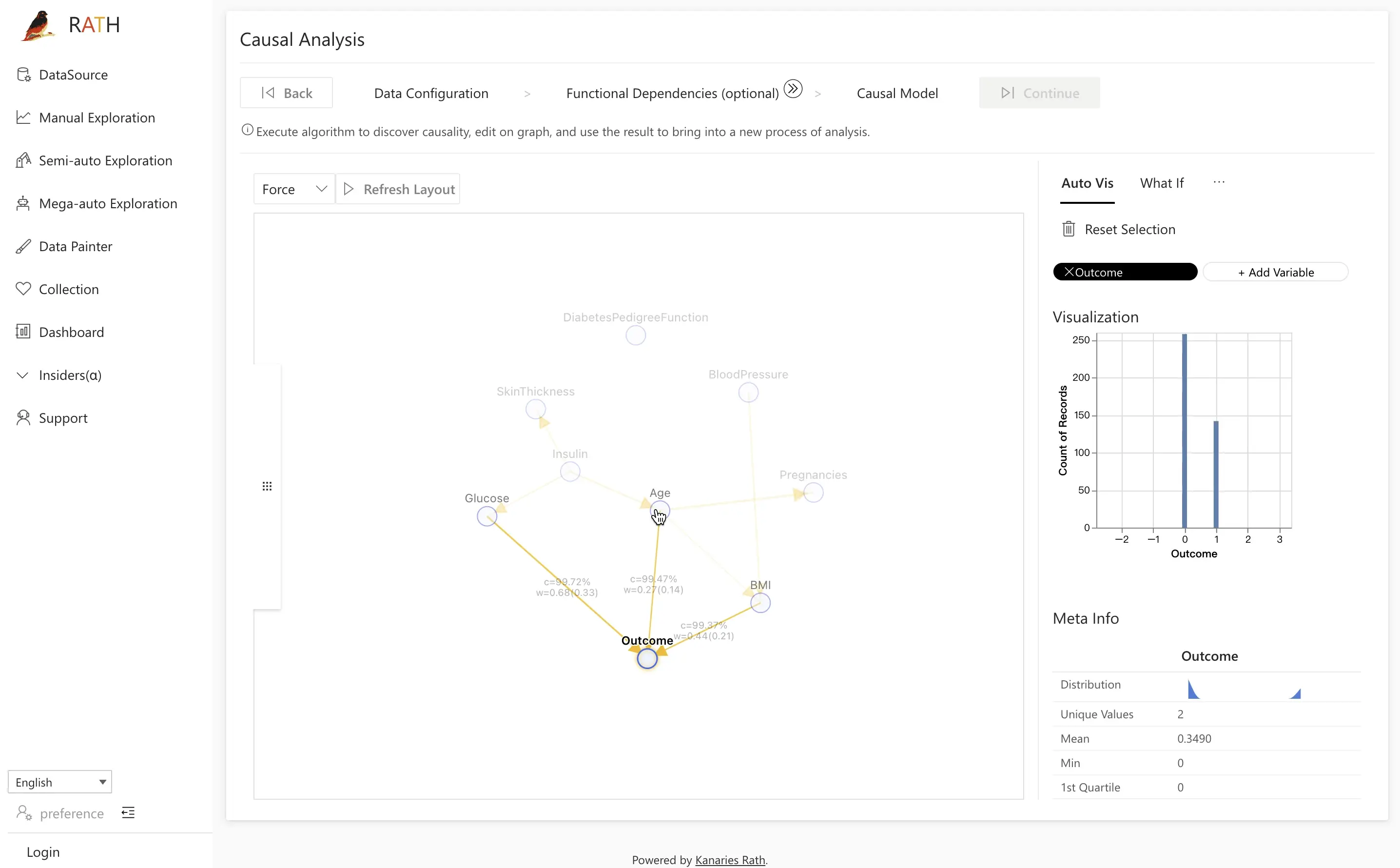
Exemplo: analisando Outcome
- Abra a aba Field Insight.
- Clique no nó
Outcomeà esquerda. - À direita, visualize as distribuições de indivíduos com e sem diabetes.
- Clique em uma das distribuições (por exemplo, resultados positivos) para executar uma análise comparativa.
Em seguida, escolha o grupo de controle e a variável-chave de interesse, como Glucose, e clique em Causal Discovery para que o RATH analise causas subjacentes potenciais. O RATH utiliza diagramas de causa e efeito para sugerir explicações para as diferenças observadas.
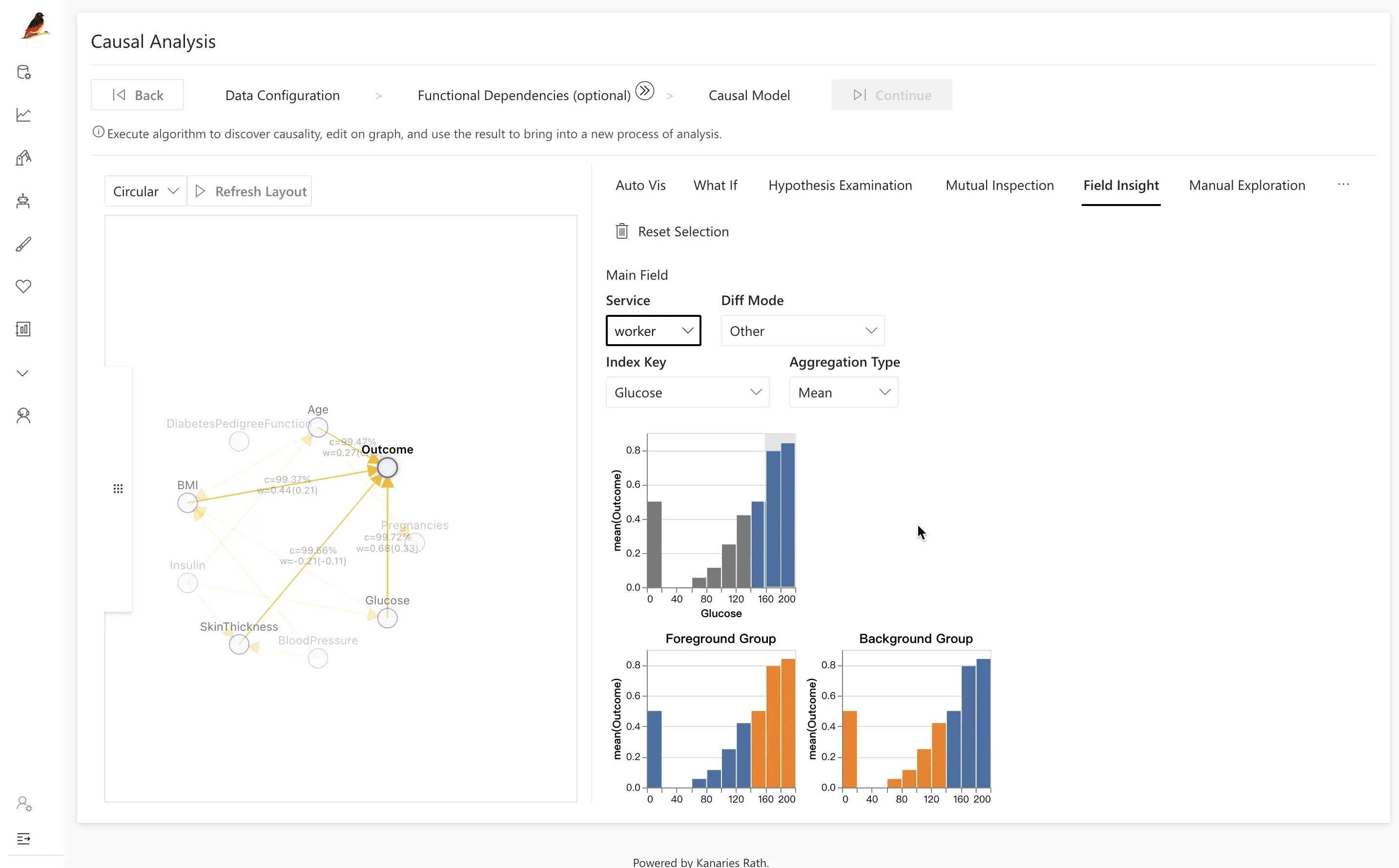
No exemplo de diabetes, comparar pacientes diabéticos e não diabéticos frequentemente revela que as diferenças são impulsionadas por:
BMIAgeGlucose
Ao clicar no fator latente Glucose, você pode ver que as distribuições de glicose são significativamente maiores para o grupo diabético (destacado em laranja).
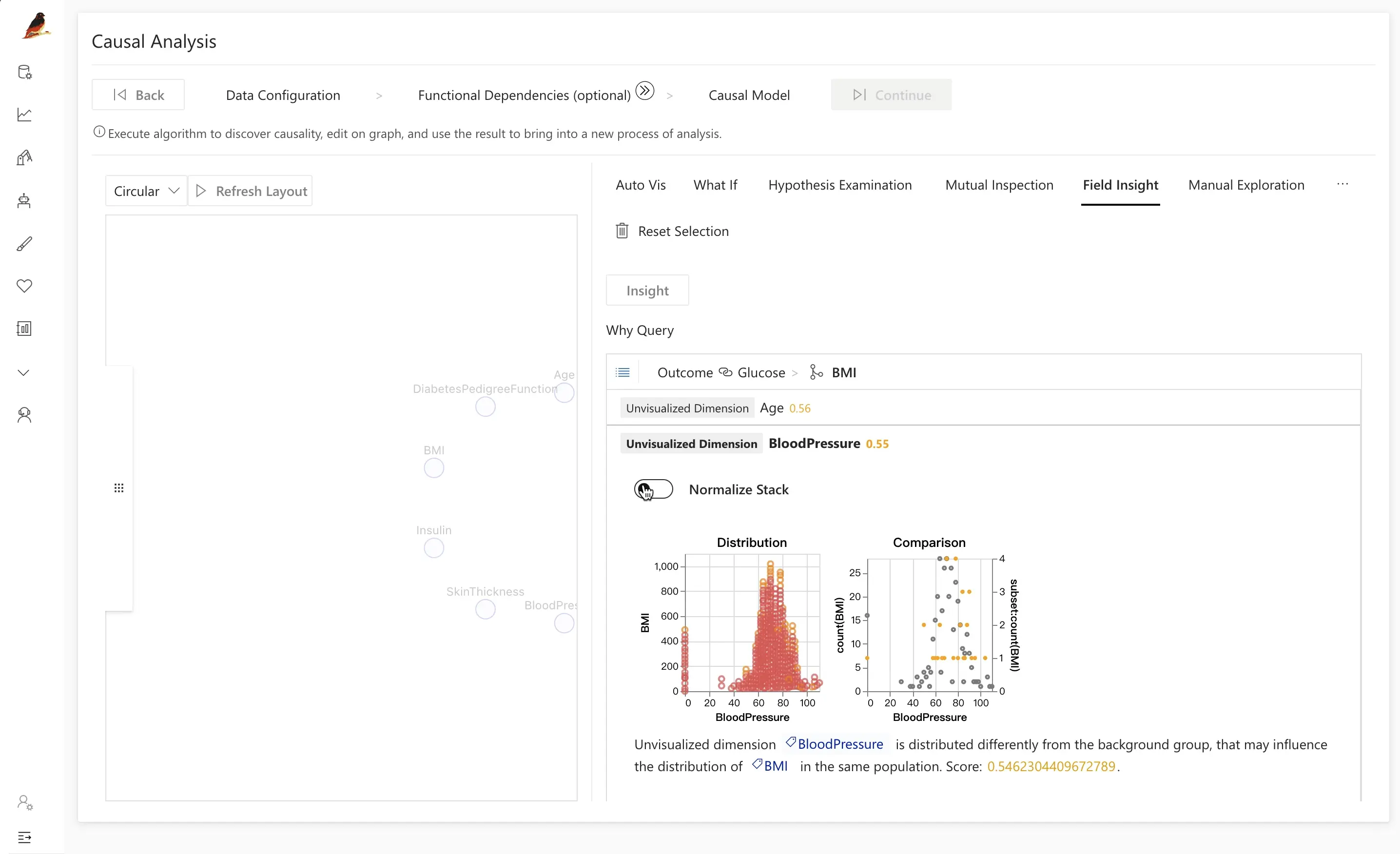
Etapa 3.2: Exploração Manual
A exploração manual permite testar visualmente suposições causais específicas.
Para o dataset de diabetes, você pode querer verificar:
- Se
Insuliné uma causa direta deOutcome. - Como a relação entre
GlucoseeOutcomemuda quando você controla porInsulin.
Usando a exploração manual, você pode:
- Plotar
Outcomevs.Glucosee comparar distribuições entre grupos doentes e saudáveis. - Adicionar
Insulincomo variável de condicionamento (por exemplo, fatiar os dados em intervalos de níveis de insulina).
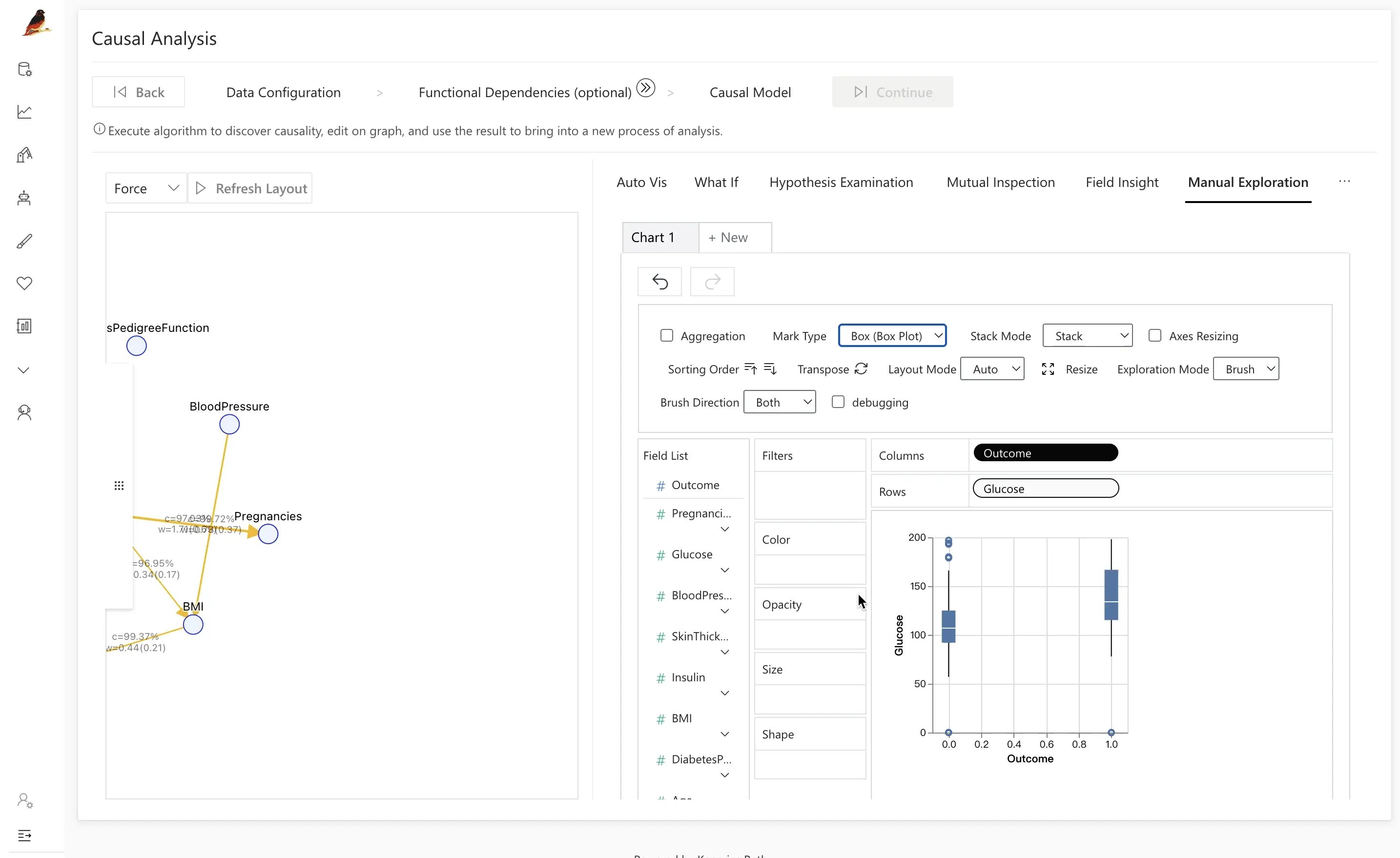
Análises tradicionais costumam parar em correlação ou importância de atributos, o que pode não capturar como uma variável exerce sua influência. Ao incorporar Análise Causal, o RATH ajuda a revelar esses mecanismos e a mostrar quando um efeito aparente é parcialmente explicado por outra variável.
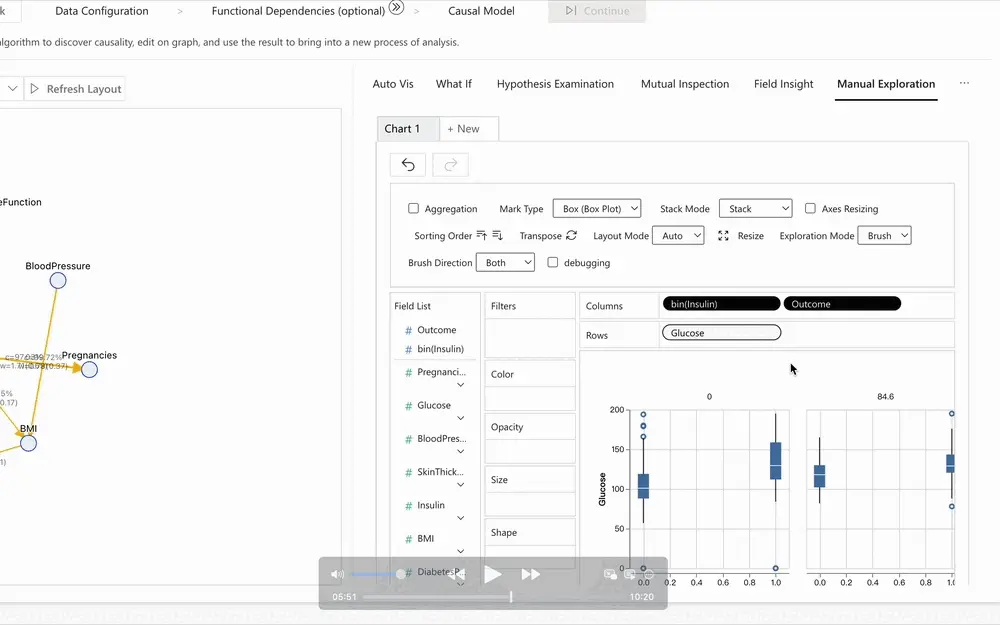
Por exemplo, após introduzir Insulin entre Outcome e Glucose:
- Ao controlar por diferentes intervalos de
Insulin, a diferença de insulina entre grupos doentes e saudáveis pode desaparecer. - Isso sugere que a relação direta entre
OutcomeeGlucoseé mais fraca do que parece inicialmente, uma vez que a influência deInsuliné levada em conta.
Etapa 3.3: Mutual Inspection
A ferramenta Mutual Inspection oferece outra forma de inspecionar relações causais e verificar suposições.
Como funciona:
- Clique em um nó no grafo causal para adicionar sua distribuição ao módulo de verificação à direita.
- Por exemplo, para explorar a relação entre
GlucoseeOutcome, adicione ambas as variáveis. - Selecione um intervalo de
Glucose, arraste o intervalo e observe como a distribuição deOutcomemuda.
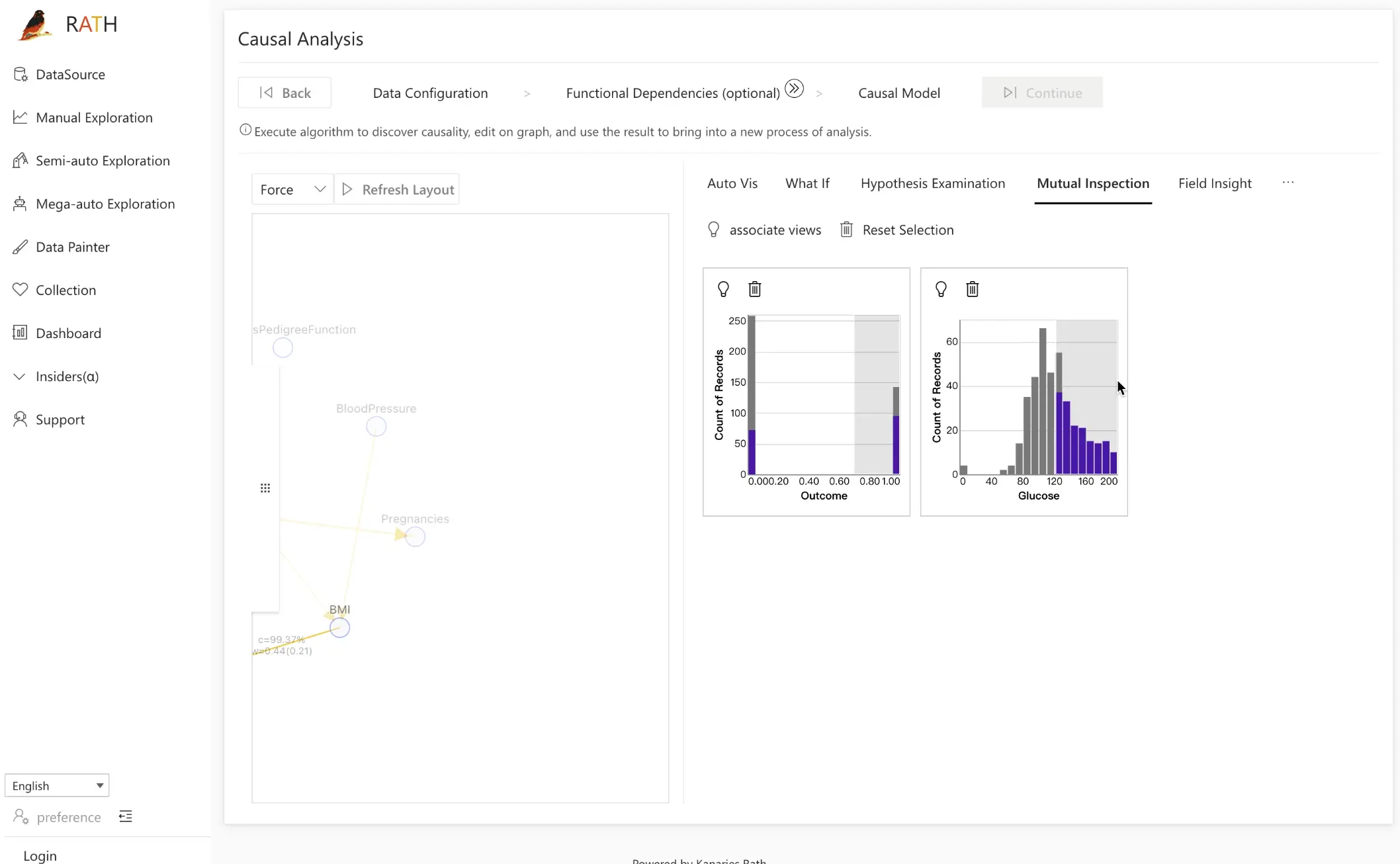
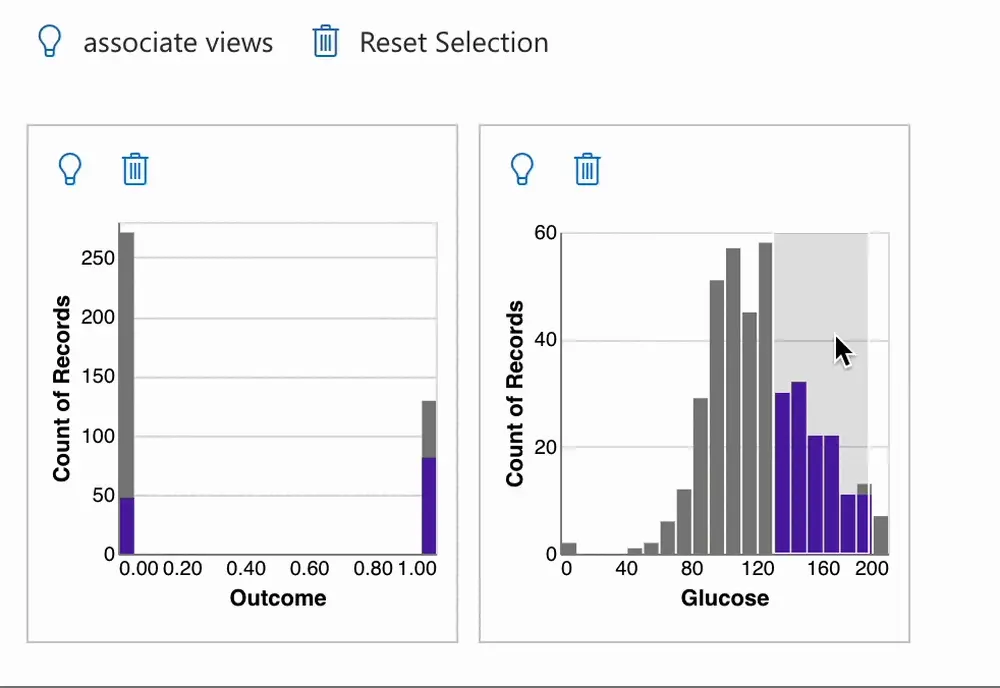
Ao percorrer diferentes níveis de glicose e observar a resposta da distribuição de desfechos, você pode confirmar visualmente uma correlação positiva e quão forte ela se mantém ao longo dos dados.
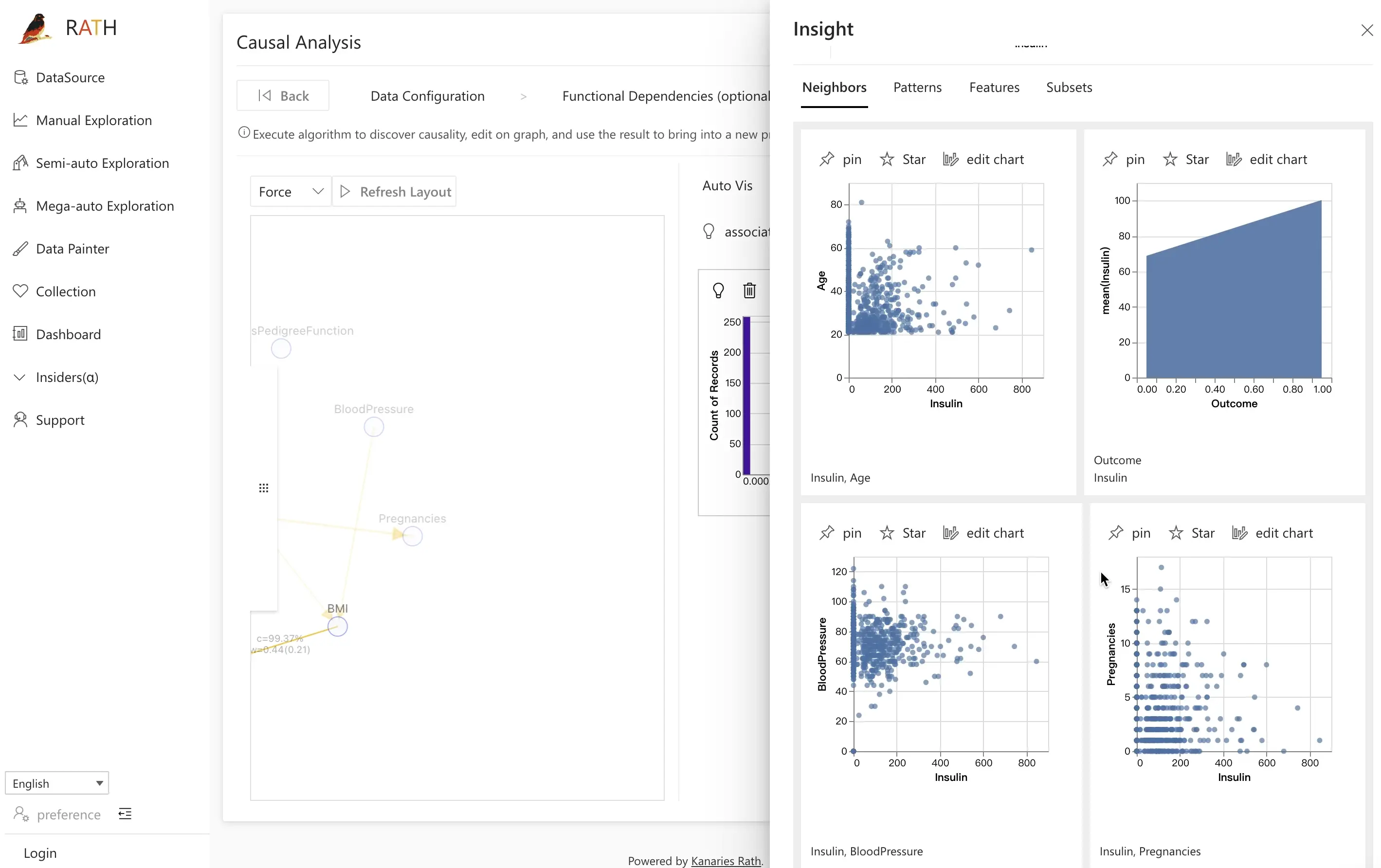
Para ir além, clique em associate views para habilitar a Semi-auto Exploration. O RATH recomendará gráficos de dispersão e outras visualizações que destacam possíveis relações entre as variáveis selecionadas, ajudando você a descobrir padrões adicionais mais rapidamente.
Etapa 3.4: Prediction Test
Depois de ter um modelo causal, você pode transformá-lo em um modelo preditivo de machine learning e avaliar seu desempenho com o Prediction Test.
- Clique na variável
Outcomeno grafo causal.
O RATH constrói automaticamente um modelo simples de classificação ou regressão usando pais causais e variáveis relacionadas.
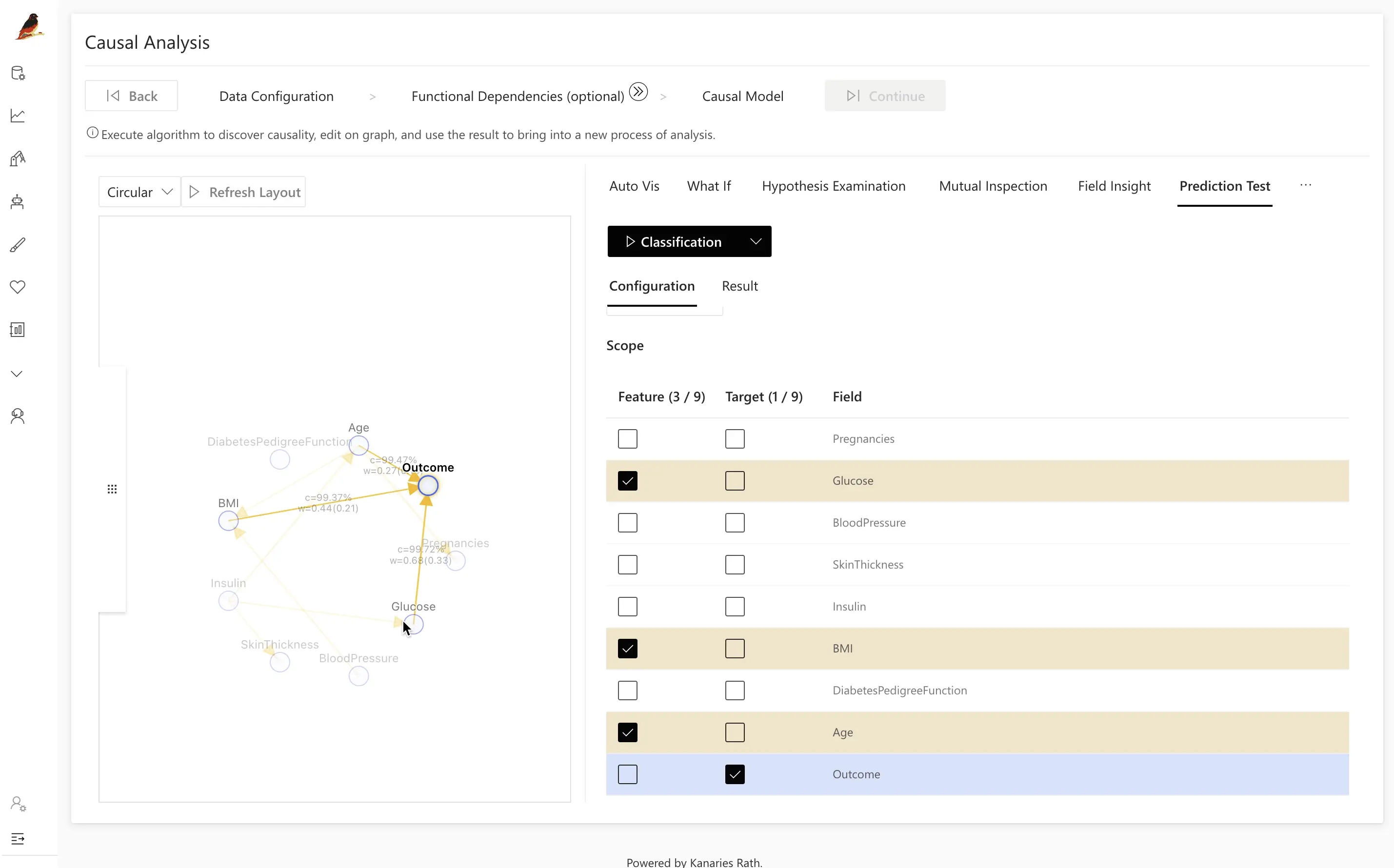
- Clique em Classification para treinar o modelo e calcular sua Accuracy (e outras métricas, dependendo da configuração).

- Ajuste sua estratégia de teste:
- Use o grafo causal para selecionar conjuntos de atributos mais eficientes ou interpretáveis.
- Compare modelos construídos a partir de atributos causais vs. subconjuntos de atributos arbitrários.
Por exemplo, você pode deliberadamente construir um modelo concorrente que evite os atributos sugeridos pela análise causal do RATH e então comparar os resultados:
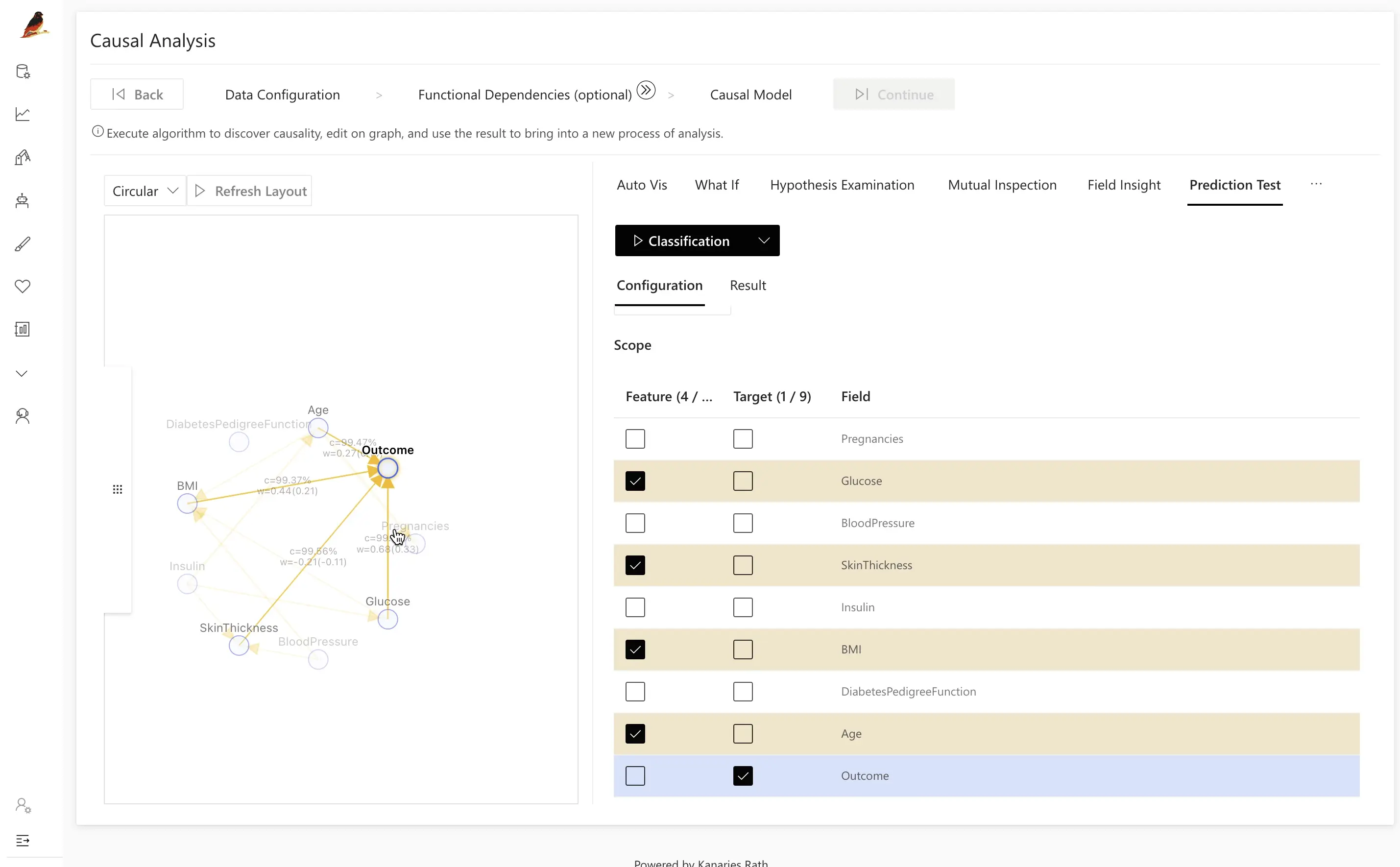
Geralmente, o modelo guiado pelo grafo causal alcança maior acurácia e melhor generalização do que uma seleção ingênua de atributos:
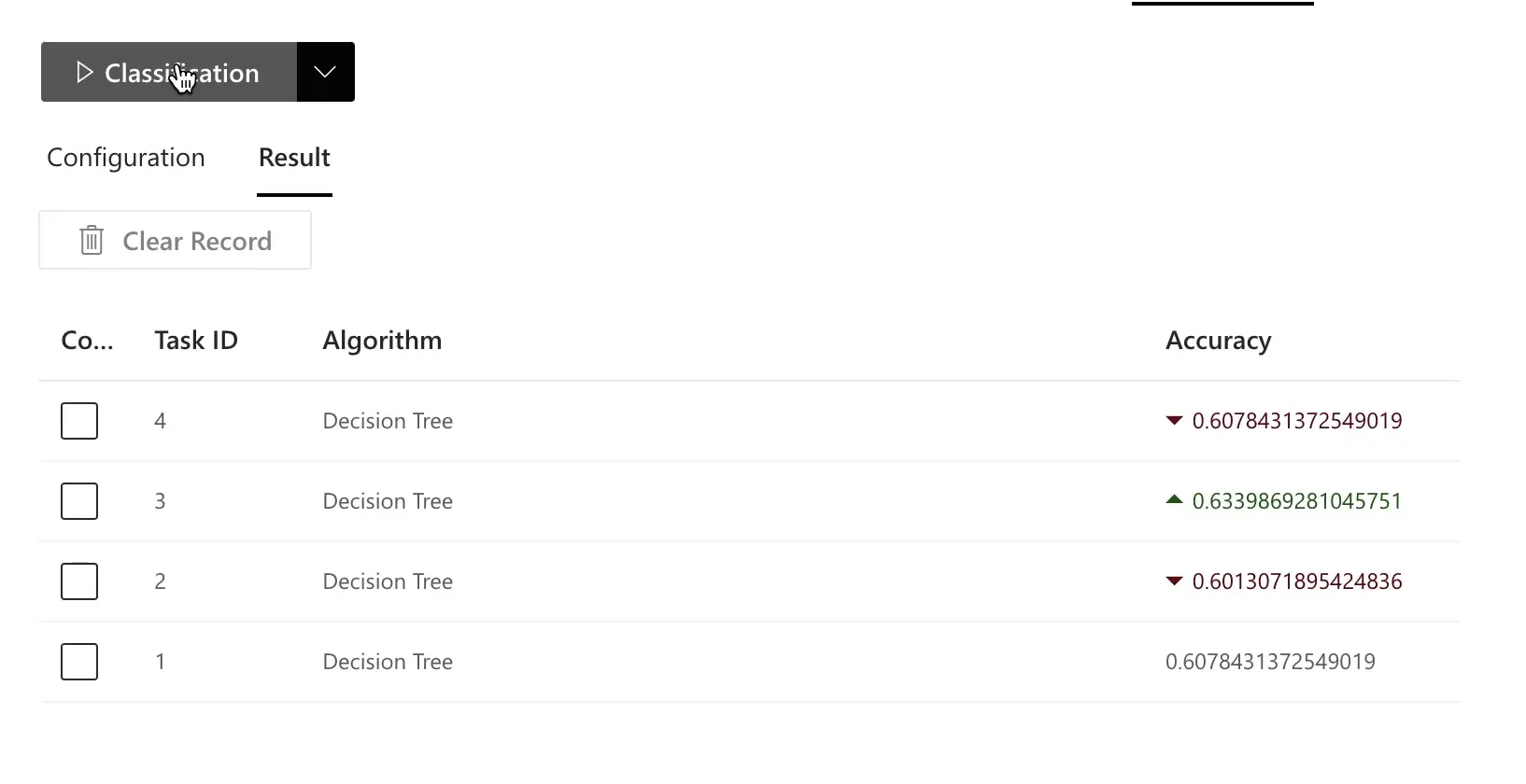
RATH é particularmente adequado para datasets grandes e de alta dimensionalidade com muitas variáveis. A análise causal ajuda a identificar automaticamente melhores atributos, levando a modelos de machine learning mais precisos e interpretáveis.
Editar o modelo causal
Dados do mundo real são bagunçados. Às vezes o grafo causal gerado automaticamente pelo RATH pode não corresponder totalmente ao seu conhecimento de domínio devido a:
- Ruído nos dados
- Tamanho de amostra insuficiente
- Variáveis ausentes
- Restrições conhecidas que o algoritmo não consegue inferir
Nesses casos, você pode editar diretamente o modelo causal.
- Abra o painel à esquerda.
- Ative Modify Constraints.
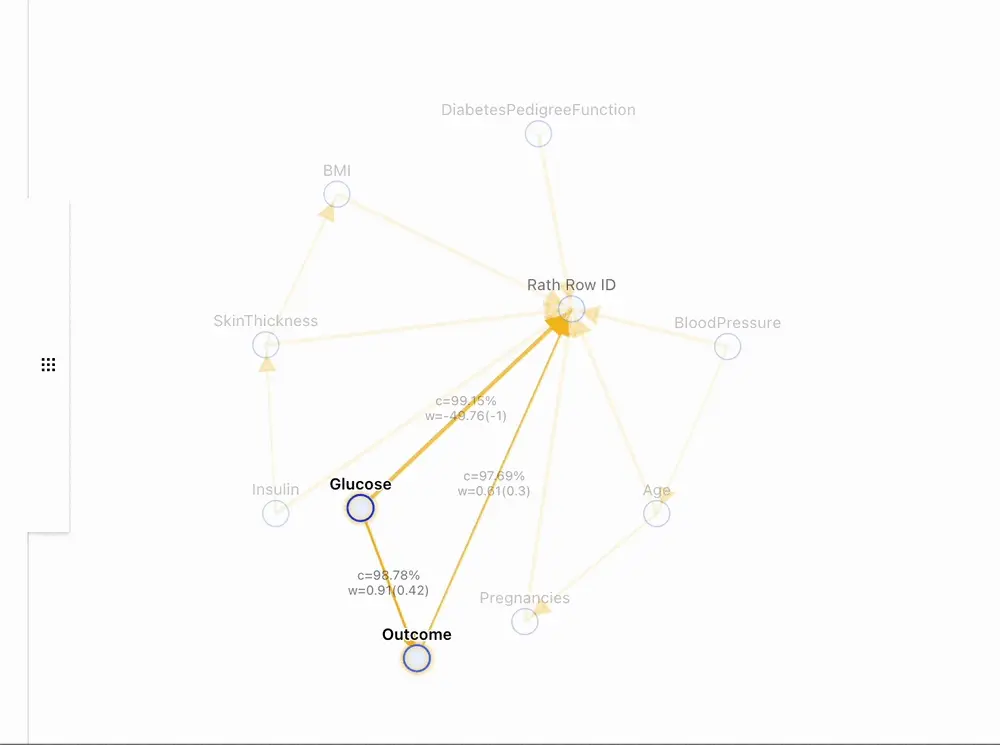
Em seguida:
- Arraste e solte nós para adicionar, remover ou reorientar arestas.
- Codifique conhecimento de domínio (por exemplo, “a variável A não pode ser causada pela variável B”).
- Deixe o RATH regenerar novos modelos causais que respeitem suas restrições.
Esse ciclo apertado entre descoberta automática e refinamento manual ajuda você a convergir para um modelo causal que seja ao mesmo tempo estatisticamente plausível e alinhado ao entendimento de especialistas.
Próximos passos
Depois de ter um modelo causal, você pode avançar ainda mais com o RATH:
- Aprenda análise causal em estilo “what-if” explorando o capítulo What-if Analysis. Você irá simular intervenções (por exemplo, “O que acontece com
Outcomese reduzirmosGlucoseem X?”) diretamente no modelo causal. - Descubra padrões em campos de texto com Text Pattern Extraction e depois alimente esses atributos extraídos de volta na análise causal.
RATH também está evoluindo em direção a explicações mais narrativas e baseadas em texto de modelos causais — gerando automaticamente insights e sugestões de decisão diretamente da estrutura e das estimativas presentes no seu grafo causal.
Ao combinar descoberta causal visual, exploração interativa e modelagem preditiva, o RATH transforma seus datasets em insights acionáveis e explicáveis — não apenas em dashboards estáticos.