Introdução ao PyGWalker
Início Rápido no Jupyter Notebook
Importe o pygwalker e o pandas para o seu Jupyter Notebook para começar.
import pandas as pd
import pygwalker as pygCarregue os seus dados como um dataframe e passe-o para o pygwalker.
df = pd.read_csv('./<caminho_do_seu_arquivo_csv>.csv')
walker = pyg.walk(df)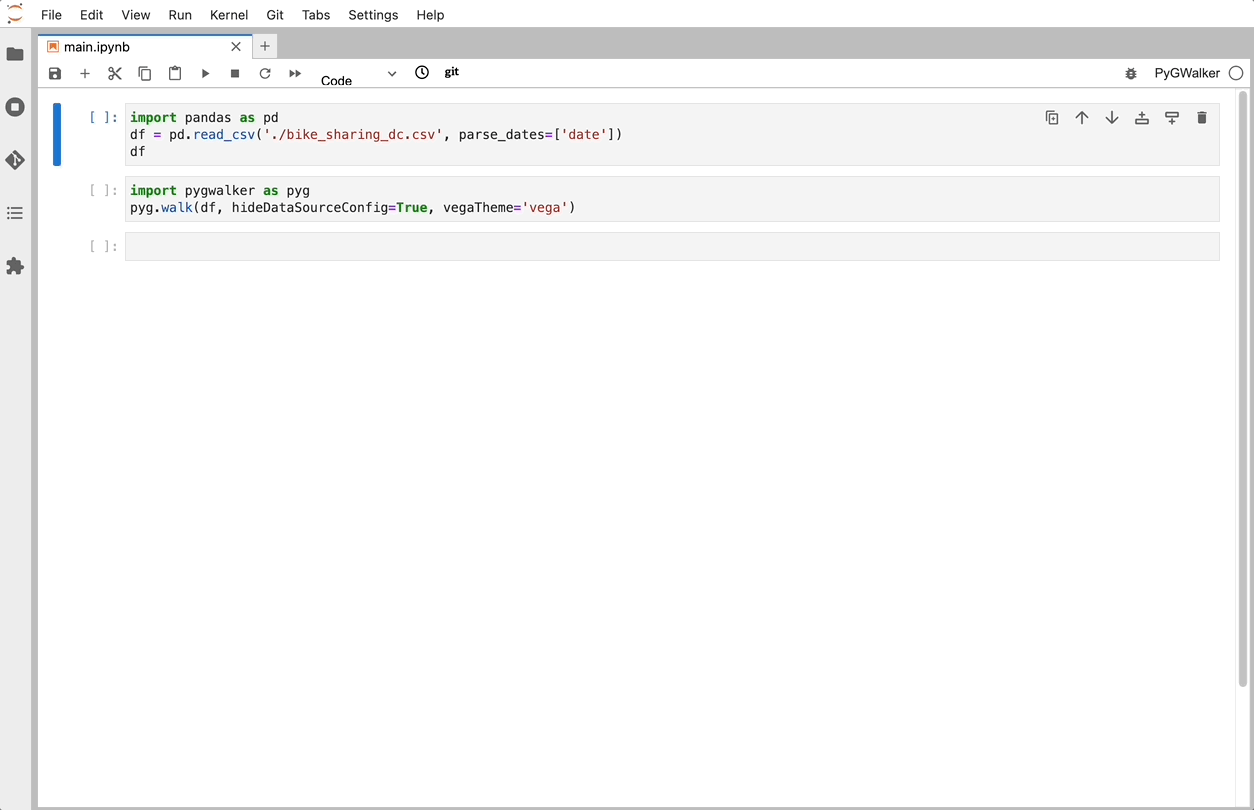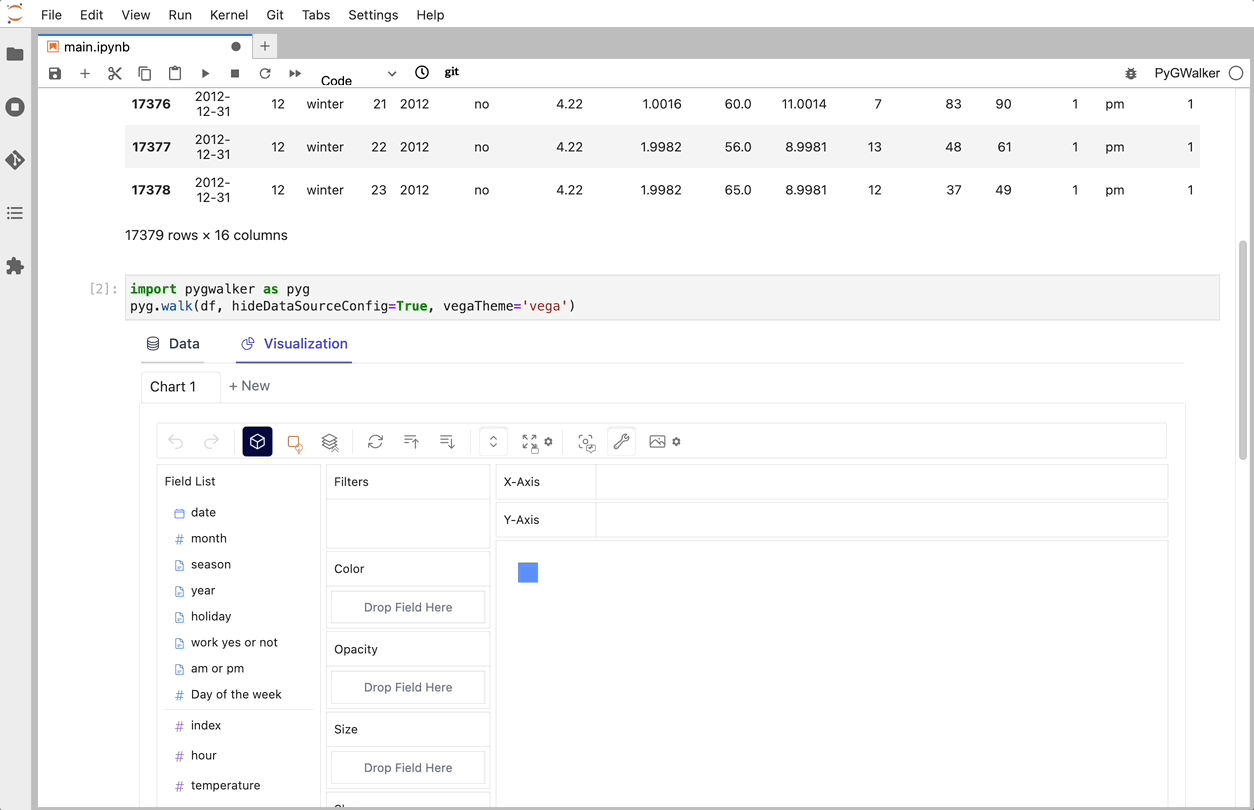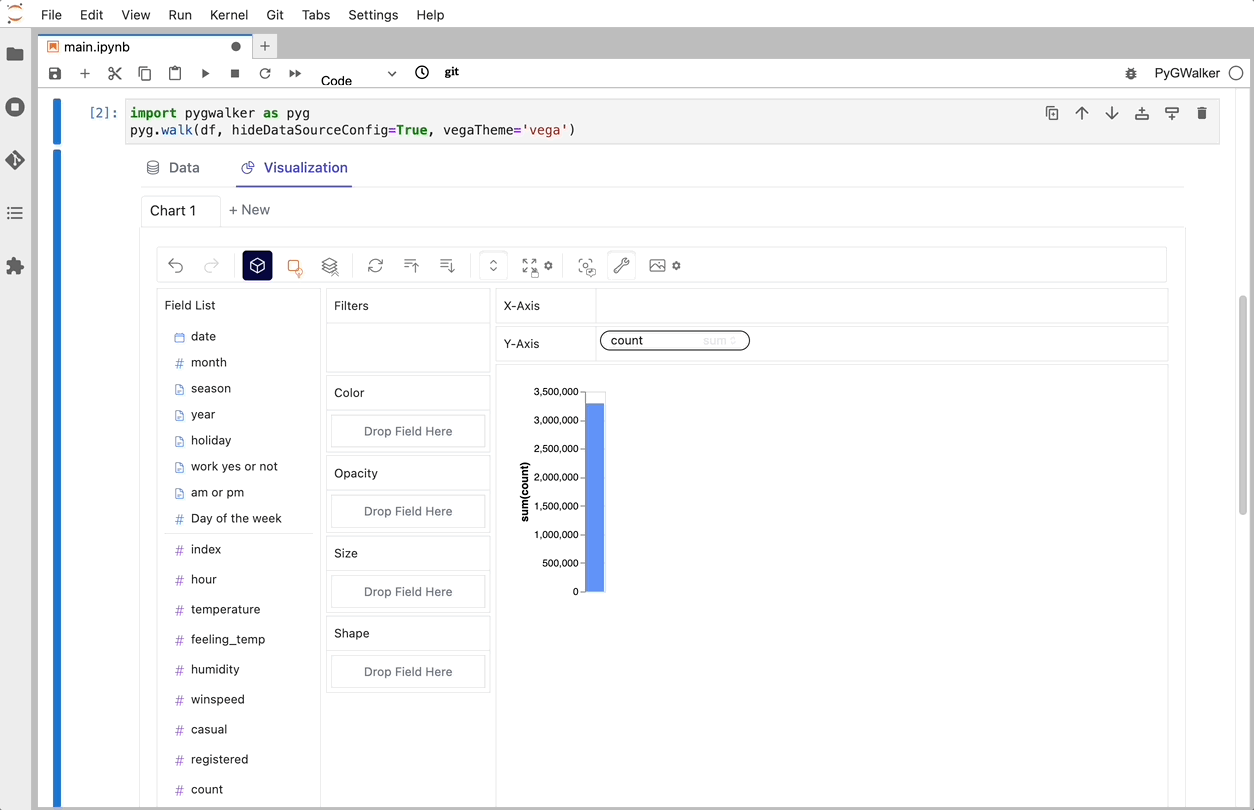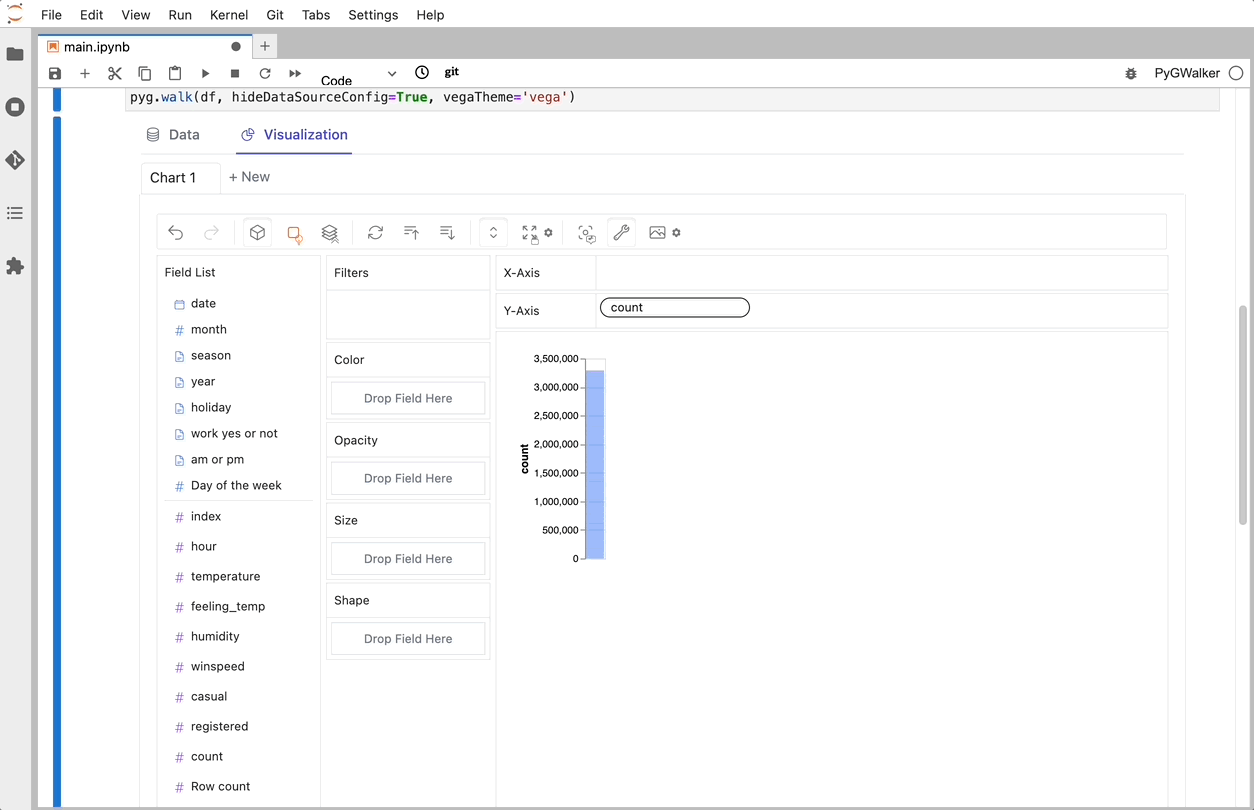
O pygwalker aceita não apenas dataframes do pandas, mas também dataframes do modin e até mesmo uma conexão de dados, como snowflake.
Aumentando o desempenho do pygwalker
Às vezes, o seu dataframe pode ser bastante grande e causar um desempenho lento do pygwalker. Agora, fornecemos uma maneira simples de aumentar o desempenho com um parâmetro extra kernel_computation.
pyg.walk(df, kernel_computation=True)Ao definir kernel_computation=True, você habilitará o novo mecanismo de computação no pygwalker alimentado pelo DuckDB.
Usando o pygwalker com Snowflake
Às vezes, os seus dados podem ser extremamente grandes e você não deseja carregá-los na memória local. O PyGWalker permite enviar todos os seus cálculos para serviços OLAP remotos, como o Snowflake.
pip install --upgrade --pre pygwalker
pip install --upgrade --pre "pygwalker[snowflake]"
Aqui está um exemplo de código de uso do pygwalker com o Snowflake.
import pygwalker as pyg
from pygwalker.data_parsers.database_parser import Connector
conn = Connector(
"snowflake://nome_de_usuario:senha@identificador_da_conta/banco_de_dados/esquema",
"""
SELECT
*
FROM
SNOWFLAKE_SAMPLE_DATA.TPCH_SF1.ORDERS
"""
)
walker = pyg.walk(conn)Rápido no Streamlit
O PyGWalker é poderoso para exploração de dados localmente e pode ser ótimo se puder ser executado em um aplicativo da web. Basicamente, há várias maneiras de implementar isso:
- Use o Streamlit (opens in a new tab) para criar um aplicativo da web.
O Streamlit é uma ótima ferramenta para criar aplicativos de dados com Python, especialmente para cientistas de dados que não estão familiarizados com o desenvolvimento web. Aqui está um exemplo rápido de uso do PyGWalker com o Streamlit.
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# Adjust the width of the Streamlit page
st.set_page_config(
page_title="Use Pygwalker In Streamlit",
layout="wide"
)
# Add Title
st.title("Use Pygwalker In Streamlit")
# You should cache your pygwalker renderer, if you don't want your memory to explode
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# If you want to use feature of saving chart config, set `spec_io_mode="rw"`
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()Confira este artigo da comunidade para aprender mais sobre como usar o PyGWalker com o Streamlit: pygwalker streamlit api