Explorando os Dados da Netflix com PyGWalker
A Netflix se destaca como uma plataforma de destaque para filmes e programas de TV. Com uma biblioteca em constante crescimento, entender as tendências e padrões do seu conteúdo se torna crucial para analistas, cineastas e até mesmo espectadores. Neste notebook, vamos mergulhar fundo no conjunto de dados da Netflix usando a biblioteca PyGWalker, uma ferramenta poderosa para visualização e exploração de dados.
O que é o PyGWalker?
PyGWalker (opens in a new tab) é uma biblioteca em Python projetada para simplificar o processo de visualização de dados. Ele permite que os usuários criem gráficos interativos com código mínimo, facilitando a descoberta de insights e padrões em conjuntos de dados.

Usando o PyGWalker, podemos gerar visualizações perspicazes que proporcionam uma compreensão mais clara do cenário de conteúdo da Netflix.
Etapas para Explorar os Dados da Netflix com PyGWalker
Configurando o Ambiente
Para começar, precisamos garantir que nosso ambiente esteja configurado para a análise. Isso envolve a instalação da biblioteca PyGWalker e a importação dos pacotes Python necessários.
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Carregando o Conjunto de Dados da Netflix e Preparação
A nossa primeira tarefa é carregar o conjunto de dados da Netflix. Uma vez carregado, vamos prepará-lo para tornar nossa análise subsequente mais fácil. Isso envolve:
- Convertendo a coluna date_added para um formato de data e hora.
- Extraindo o ano e o mês da coluna date_added.
- Limpeza da coluna duration para representar tanto os minutos totais para filmes quanto o número de temporadas para programas de TV.
- Filtrando os dados a partir de 2019.
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df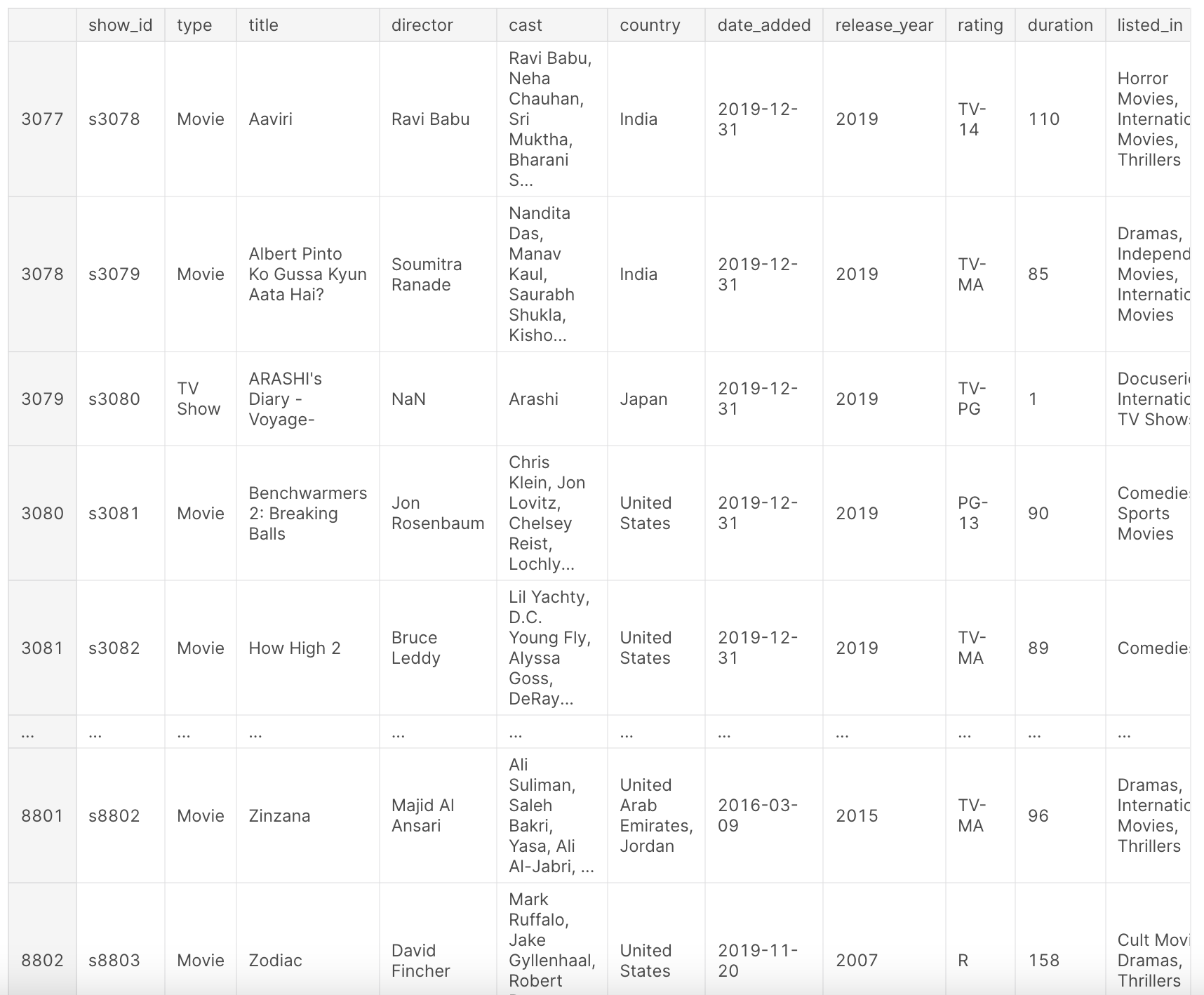
Visão Geral do Conjunto de Dados da Netflix
Após a preparação acima, nosso conjunto de dados df fornece uma visão abrangente dos títulos da Netflix. Ele contém informações como o tipo de conteúdo (filme ou programa de TV), título, diretor, elenco, país de produção, data de adição à Netflix, ano de lançamento, classificação, duração, gênero e uma breve descrição.
Este conjunto de dados oferece uma visão geral do cenário de conteúdo da Netflix até o ano de 2019, permitindo-nos analisar tendências, preferências e padrões de crescimento ao longo dos anos. Dê uma olhada nas seguintes colunas:
show_id: ID único para cada filme/programa de TVtype: Identificador para Filme ou Programa de TVtitle: Título do Filme/Programa de TVdirector: Diretor do Filmecast: Atores envolvidos no filme/programacountry: País onde o filme/programa foi produzidodate_added: Data que foi adicionado na Netflixrelease_year: Ano de lançamento real do filme/programarating: Classificação de TV do filme/programaduration: Duração total - em minutos ou número de temporadaslisted_in: Gênerodescription: Uma breve descrição do filme/programa
Visualizando os Dados da Netflix com PyGWalker
Agora, vem a parte emocionante: visualizações. Com o PyGWalker, vamos gerar visualizações interativas para descobrir insights do nosso conjunto de dados.
1. Visão Geral Geral dos Dados da Netflix
Aqui, estamos inicializando um walker para o nosso conjunto de dados principal. Isso nos permitirá gerar uma série de gráficos com base nas especificações salvas em "0.json".
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
Você pode explorar este conjunto de dados interativamente com uma versão online do PyGWalker aqui (opens in a new tab).
walker0.display_chart("Gráfico 1", title="Tipo de Conteúdo na Netflix")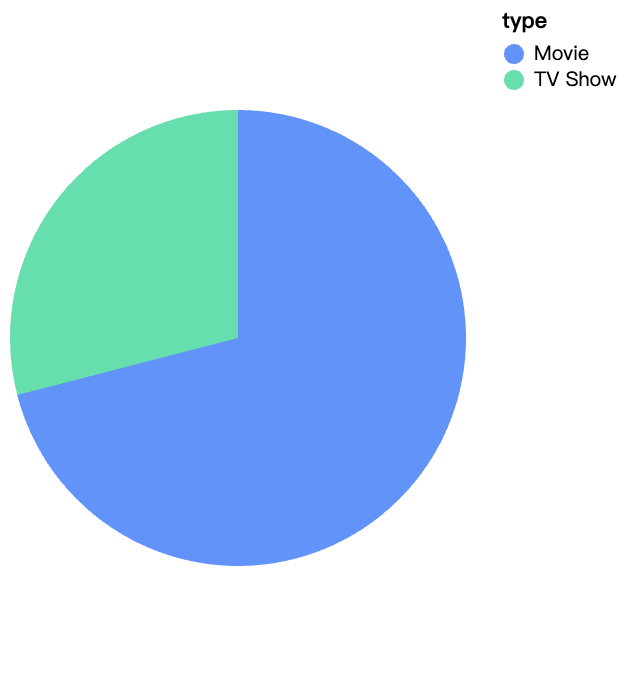
walker0.display_chart("Gráfico 2", title="Conteúdo Adicionado ao Longo dos Anos", desc="O número de filmes na Netflix está crescendo muito mais rápido do que os programas de TV, o conteúdo de filmes cresceu substancialmente depois de 2016.")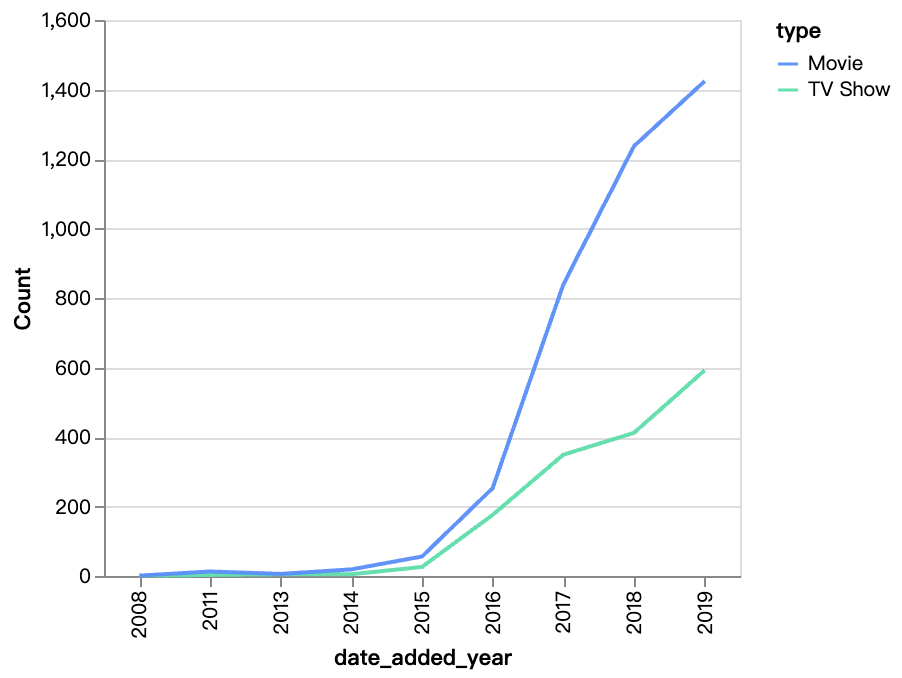
walker0.display_chart("Gráfico 3", title="Lançamento de Conteúdo ao Longo dos Anos")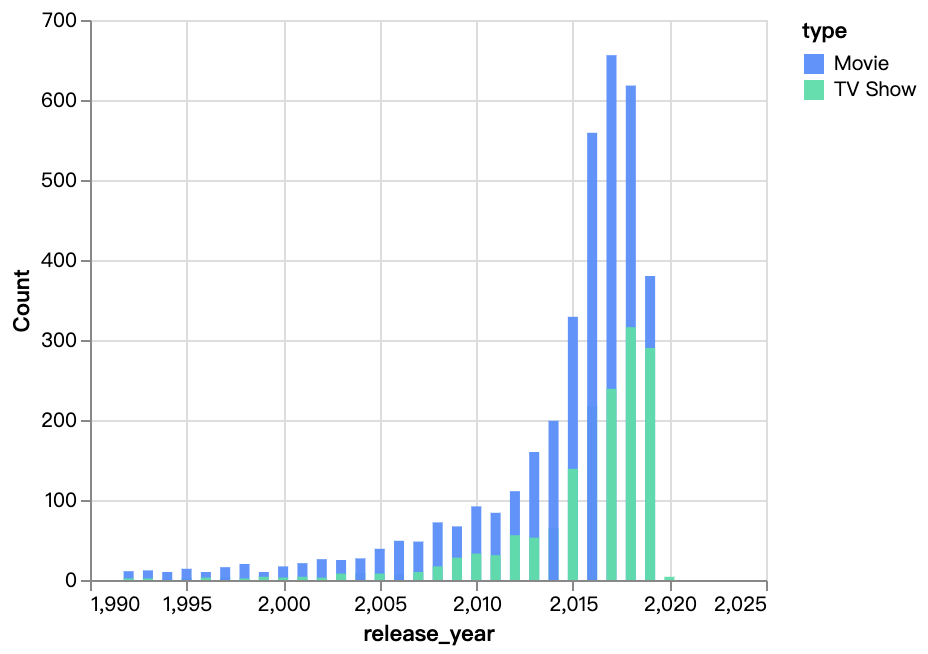
walker0.display_chart("Gráfico 4", title="Conteúdo Adicionado ao Longo dos Meses", desc="")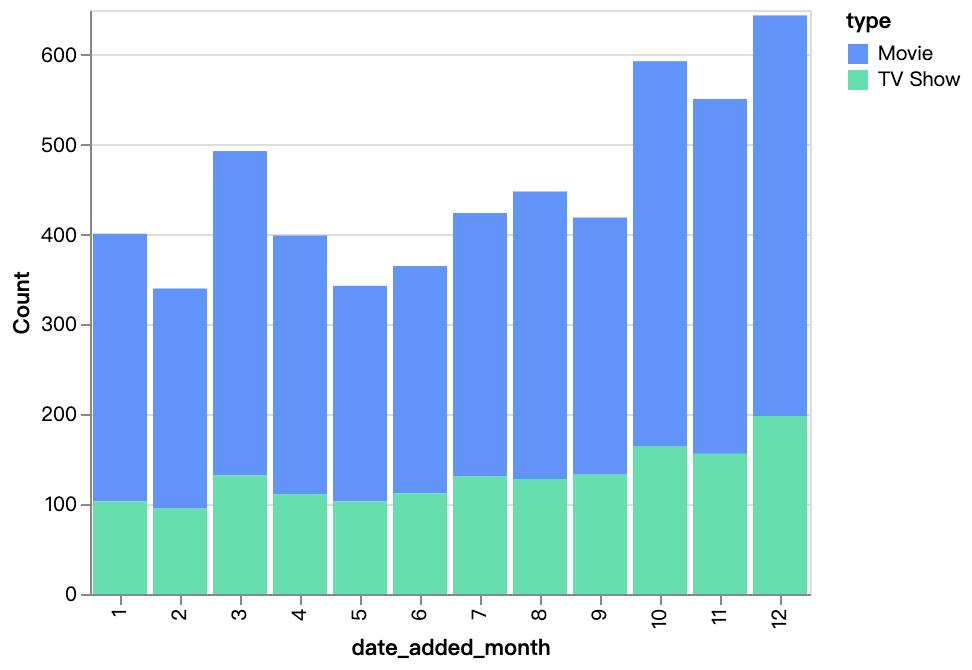
walker0.display_chart("Gráfico 5", title="Conteúdo Adicionado ao Longo dos Anos com Base na Classificação", desc="TV-MA, TV-14 são as classificações para a maioria dos conteúdos da Netflix, e o conteúdo R também está aumentando ano a ano")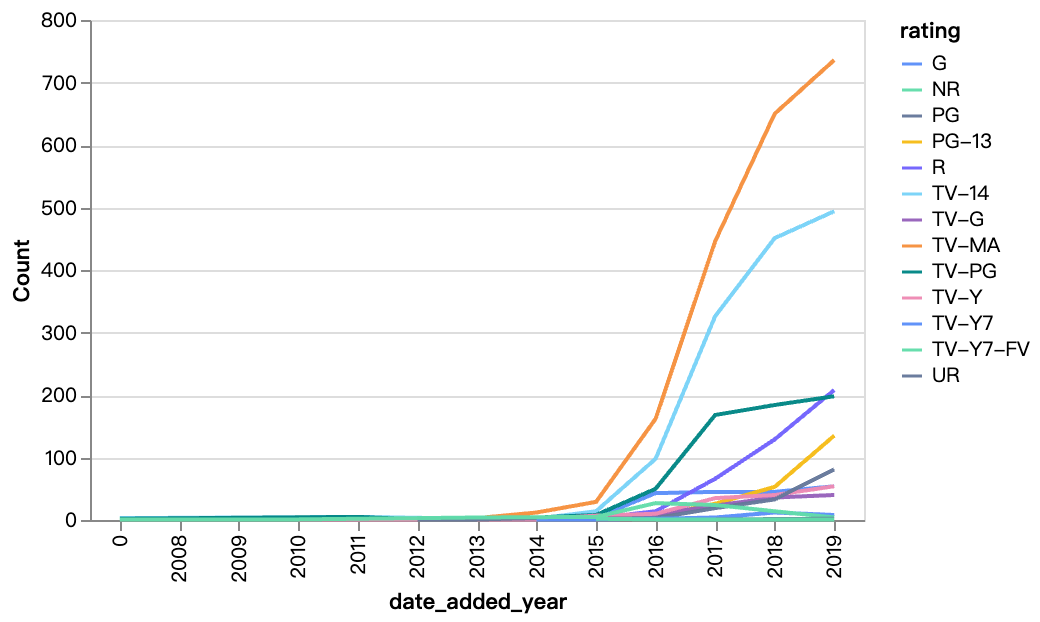
walker0.display_chart("Gráfico 6", title="Distribuição do Tempo do Filme", desc="Principalmente concentrado entre 90 e 110 minutos")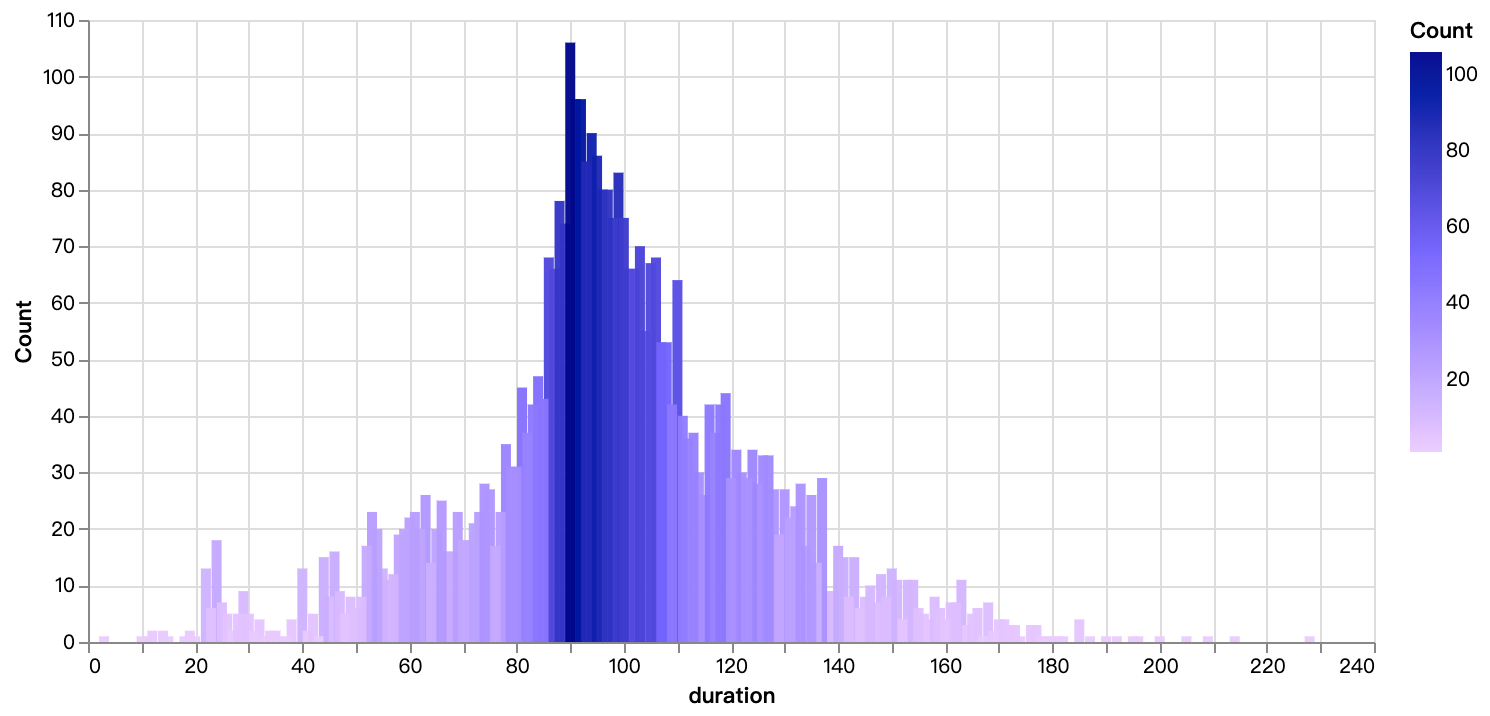
walker0.display_chart("Gráfico 7", title="Distribuição de Temporadas de Programas de TV")
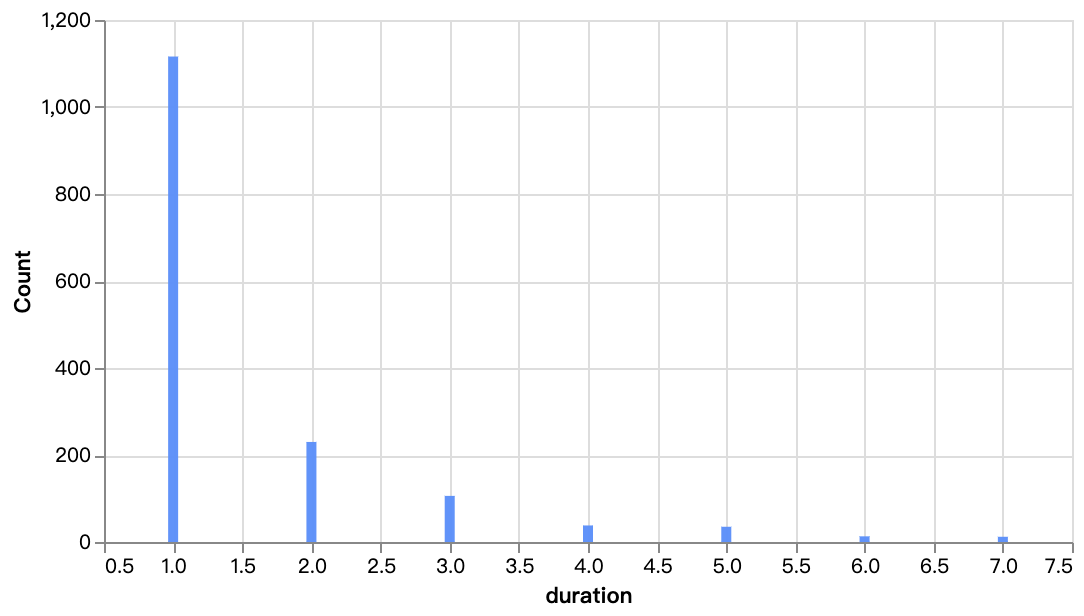
### 2. Análise específica por país nos dados da Netflix
Neste segmento, estamos analisando o conteúdo por país. Ao dividir e reestruturar a coluna de país, podemos analisar a distribuição de conteúdo em diferentes países.
```python copy
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)Você pode experimentar o PyGWalker User Interface aqui (opens in a new tab)
walker1.display_chart("Gráfico 1", title="Países com Mais Conteúdo")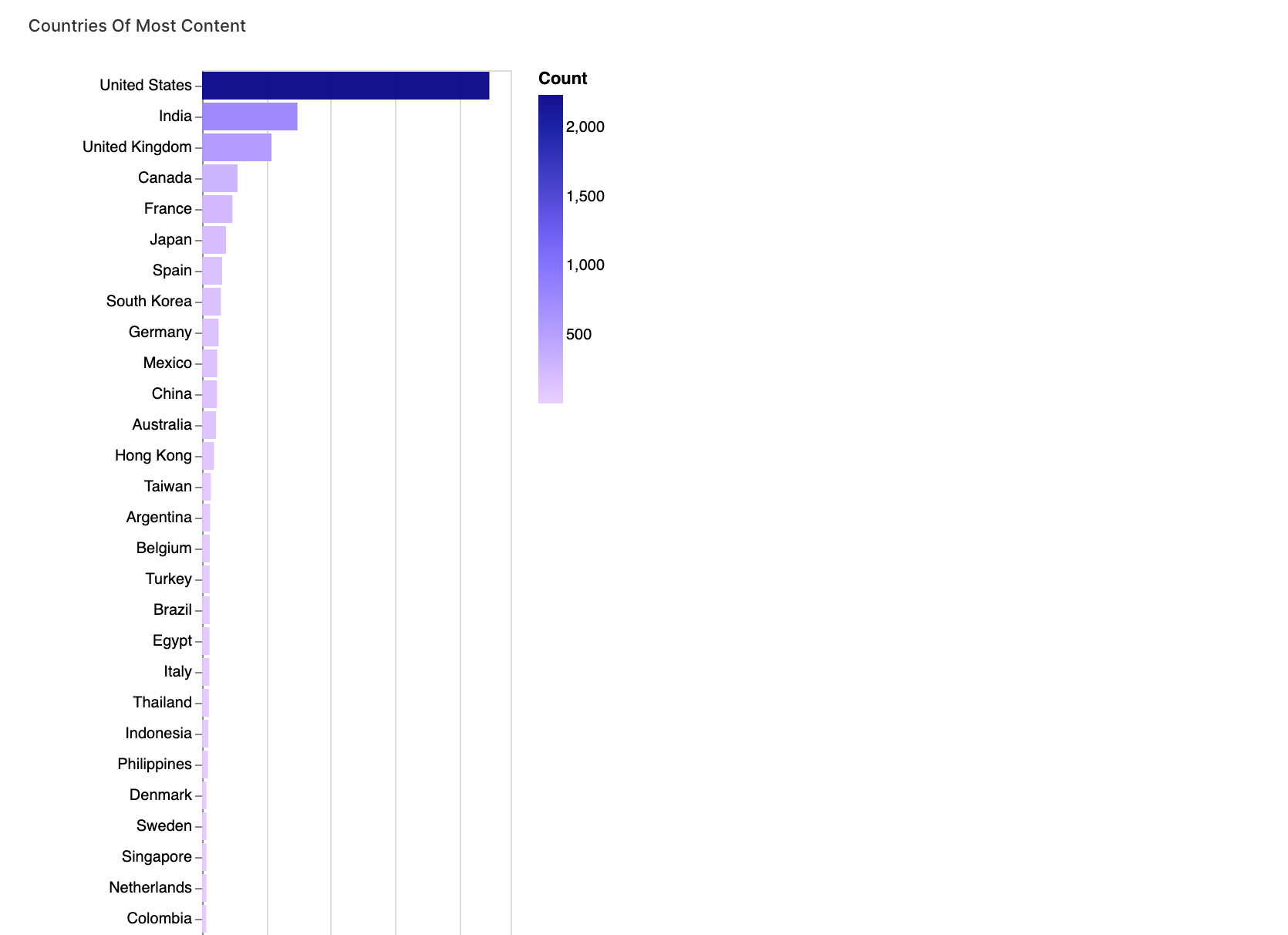
3. Análise de Categoria e Classificação
Por fim, estamos focando em categorias e classificações. Esta seção nos permitirá entender a distribuição de conteúdo por gêneros e como as classificações variam dentro desses gêneros.
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)Você pode experimentar o PyGWalker User Interface aqui (opens in a new tab)
walker2.display_chart("Categoria de TV", title="Distribuição de Categorias de Séries de TV")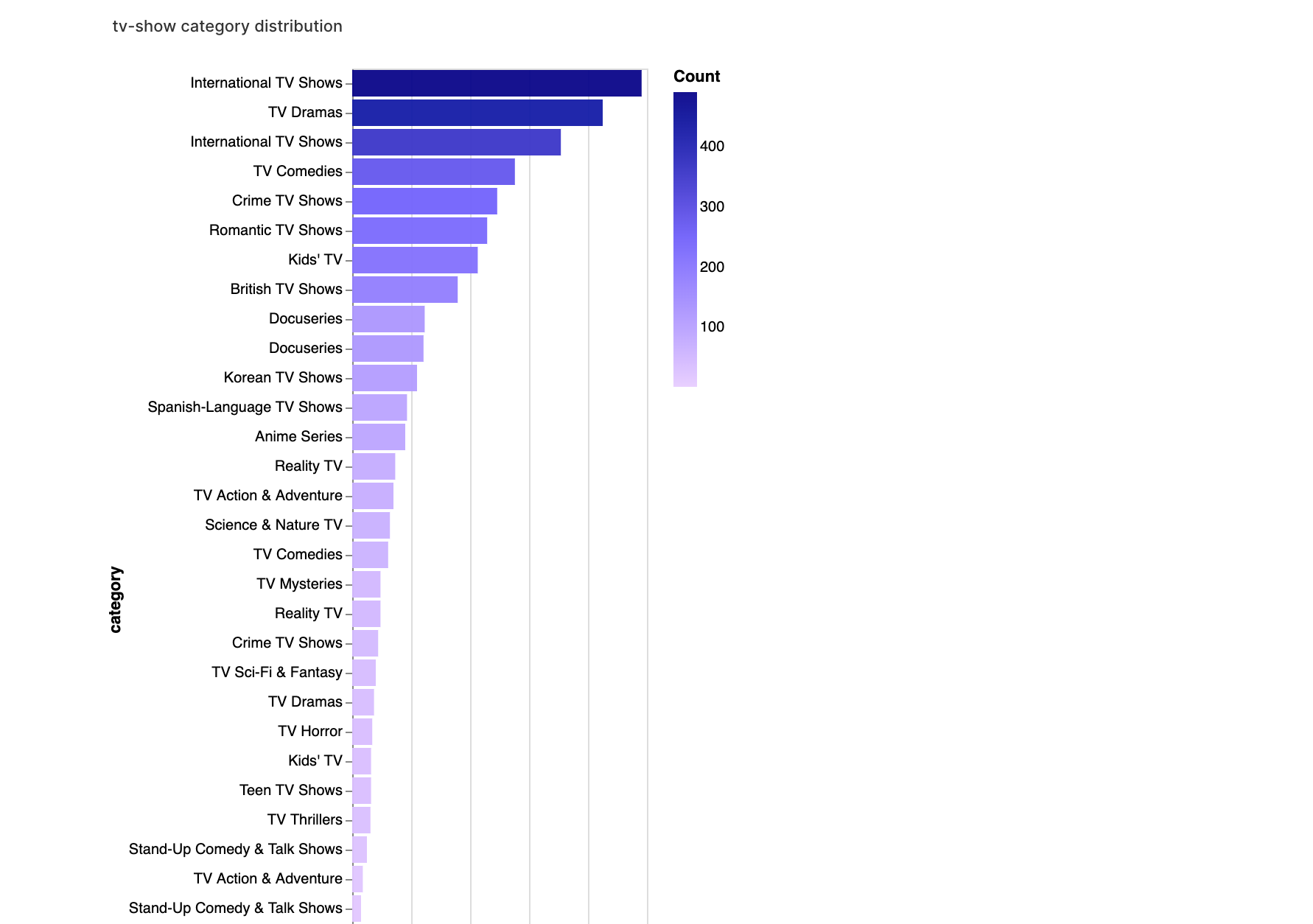
walker2.display_chart("Categoria de Filme", title="Distribuição de Categorias de Filmes")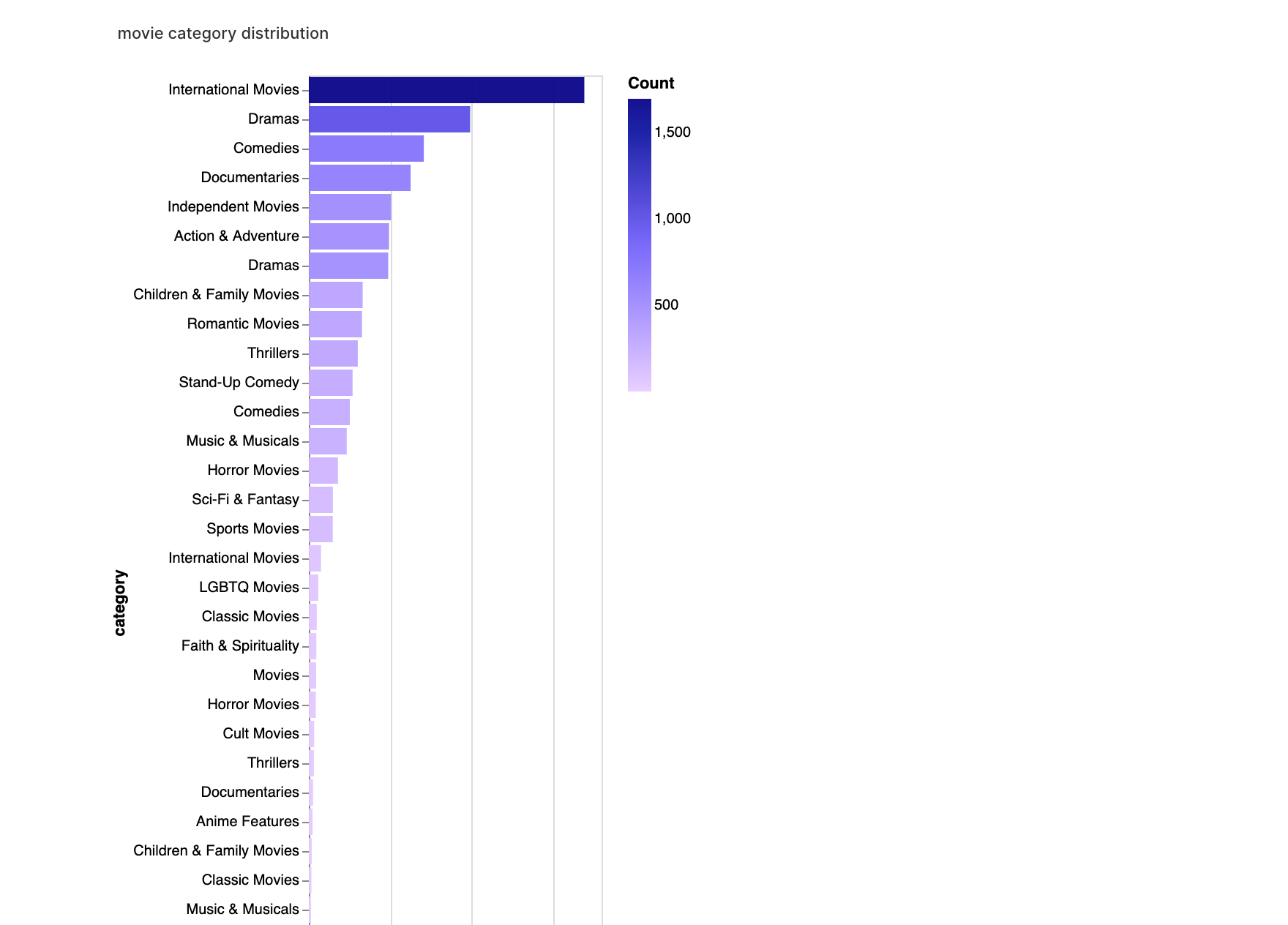
walker2.display_chart("Categoria de classificação (TV)", title="Mapa de Calor de Categoria de Classificação (Série de TV)")
walker2.display_chart("Categoria de classificação (filme)", title="Mapa de Calor de Categoria de Classificação (Filme)")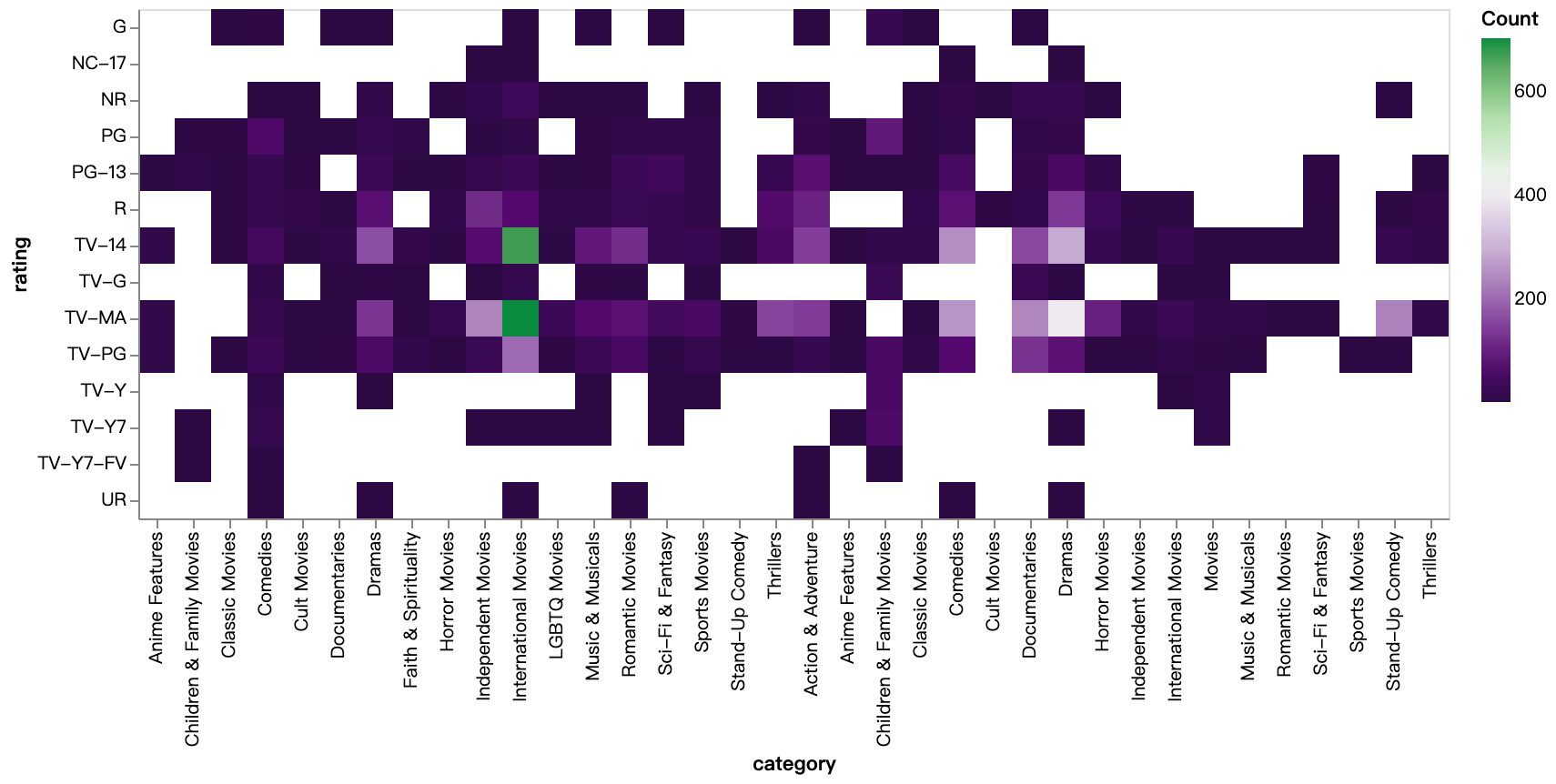
Conclusão
Nesta exploração abrangente do conjunto de dados da Netflix usando a biblioteca PyGWalker, mergulhamos fundo nas inúmeras facetas do conteúdo da Netflix. O PyGWalker se mostrou uma ferramenta poderosa, simplificando o processo de visualização para revelar tendências essenciais. A análise proporcionou clareza sobre os padrões de crescimento, preferências e tendências do conteúdo da Netflix até 2019, aprofundando-se nas categorias e classificações revelou a variedade e distribuição de gêneros em filmes e séries de TV e como as classificações variam dentro desses gêneros.
Esta documentação também está disponível no Kaggle Notebook (opens in a new tab).
FAQs
1. O que são conjuntos de dados da Netflix?
- Conjuntos de dados da Netflix são coleções de dados que fornecem informações detalhadas sobre o conteúdo disponível na plataforma Netflix. Esses dados normalmente incluem aspectos como o tipo de conteúdo (filme ou série de TV), título, diretor, elenco, país de produção, data de adição à Netflix, ano de lançamento, classificação, duração, gênero e uma breve descrição. Esses conjuntos de dados permitem que pesquisadores e analistas compreendam melhor o cenário de conteúdo da plataforma.
2. Como os conjuntos de dados da Netflix podem ser utilizados?
- Os conjuntos de dados da Netflix podem ser utilizados de várias maneiras:
- Análise de Tendências: Compreender os padrões de crescimento, preferências e tendências ao longo dos anos.
- Análise por País: Determinar quais países produzem mais conteúdo e que tipo de conteúdo é popular em diferentes regiões.
- Distribuição de Gêneros: Explorar os gêneros mais populares e como eles variam entre filmes e séries de TV.
- Percepções de Classificação: Analisar a distribuição das classificações em diversos tipos de conteúdo e determinar as preferências do público.
- Visualização de Dados: Utilizar ferramentas como o PyGWalker para criar visualizações interativas para obter insights mais profundos.
3. O que é o PyGWalker e por que ele é benéfico para exploração de dados?
- PyGWalker é uma biblioteca em Python projetada especificamente para agilizar o processo de visualização de dados. Ela permite que os usuários gerem gráficos interativos com código mínimo, facilitando a descoberta de padrões e insights em conjuntos de dados. Para plataformas como a Netflix, que possuem conjuntos de dados vastos, o PyGWalker pode ser inestimável ao simplificar a exploração de dados e gerar visualizações facilmente compreensíveis.