Análise Exploratória de Dados com Python Pandas: Um Guia Completo
- Name
- Omar C. Williams
Atualizado em
A Análise Exploratória de Dados (AED) é um passo crítico em qualquer projeto de ciência de dados. Isso envolve o entendimento dos dados, a identificação de padrões e a realização de observações iniciais. Este artigo o guiará pelo processo de AED usando a biblioteca Pandas do Python, uma ferramenta poderosa para manipulação e análise de dados. Vamos cobrir tudo, desde o tratamento de valores ausentes até a criação de visualizações esclarecedoras.
Use Pandas para Análise Exploratória de Dados
Tratamento de Valores Ausentes
Ao trabalhar com dados do mundo real, é comum encontrar valores ausentes. Isso pode ocorrer por vários motivos, como erros de entrada de dados ou dados não coletados para determinadas observações. O tratamento de valores ausentes é crucial, pois eles podem levar a análises imprecisas se não forem tratados adequadamente.
No Pandas, você pode verificar valores ausentes usando a função isnull(). Essa função retorna um DataFrame em que cada célula é True (se a célula original continha um valor ausente) ou False (se a célula não estava ausente de um valor). Para obter o número total de valores ausentes em cada coluna, você pode encadear a função sum():
valores_ausentes = df.isnull().sum()Isso retornará uma série com os nomes das colunas como índice e o número total de valores ausentes em cada coluna como valores. Dependendo da natureza dos seus dados e da análise que você planeja realizar, você pode decidir preencher os valores ausentes com um determinado valor (como a mediana ou a média da coluna), ou pode decidir descartar as linhas ou colunas que contêm valores ausentes.
Explorando Valores Únicos
Outra etapa importante na AED é a exploração dos valores únicos em seus dados. Isso pode ajudá-lo a entender a diversidade de seus dados. Por exemplo, se você tiver uma coluna que represente categorias de um certo recurso, verificar os valores únicos pode dar uma ideia de quantas categorias existem.
No Pandas, você pode usar a função nunique() para verificar o número de valores únicos em cada coluna:
valores_unicos = df.nunique()Isso retornará uma série com os nomes das colunas como índice e o número de valores únicos em cada coluna como valores.
Classificação de Valores
Classificar seus dados de acordo com uma determinada coluna também pode ser útil na AED. Por exemplo, você pode querer classificar seus dados por uma coluna de 'população' para ver quais países têm as maiores populações. No Pandas, você pode usar a função sort_values() para classificar seu DataFrame:
df_classificado = df.sort_values(by='população', ascending=False)Isso retornará um novo DataFrame classificado pela coluna 'população' em ordem descendente. O argumento ascending=False classifica a coluna em ordem decrescente. Se você deseja classificar em ordem crescente, pode omitir esse argumento, já que True é o valor padrão.
Visualizando correlações com mapas de calor
As visualizações podem fornecer informações valiosas sobre seus dados que podem não ser aparentes apenas olhando para os dados brutos. Uma visualização útil é um mapa de calor de correlações entre diferentes recursos em seus dados.
No Pandas, você pode calcular uma matriz de correlação usando a função corr():
matriz_correlação = df.corr()Este código retornará um DataFrame onde a célula na intersecção da linha i e da coluna j contém o coeficiente de correlação entre a i-ésima e a j-ésima característica. O coeficiente de correlação é um valor entre -1 e 1 que indica a força e direção da relação entre as duas características. Um valor próximo de 1 indica uma forte relação positiva, um valor próximo de -1 indica uma forte relação negativa e um valor próximo de 0 indica nenhuma relação.
Para visualizar esta matriz de correlação, você pode utilizar a função heatmap() da biblioteca Seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 7))
sns.heatmap(matriz_correlação, annot=True)
plt.show()Isto irá criar uma mapa de calor onde a cor de cada célula representa o coeficiente de correlação entre as características correspondentes. O argumento annot=True adiciona os coeficientes de correlação às células no mapa de calor.
Agrupando Dados
Agrupar seus dados com base em determinados critérios pode fornecer informações valiosas. Por exemplo, você pode querer agrupar seus dados por 'continente' para analisar os dados em nível de continente. No Pandas, você pode utilizar a função groupby() para agrupar seus dados:
grupo_df = df.groupby('continente').mean()Isto irá retornar um novo DataFrame onde os dados estão agrupados pela coluna 'continente' e os valores em cada grupo são os valores médios dos dados originais nesse grupo.
Visualizando Dados ao Longo do Tempo
Visualizar seus dados ao longo do tempo pode ajudá-lo a identificar tendências e padrões. Por exemplo, você pode querer visualizar a população de cada continente ao longo do tempo. No Pandas, você pode criar um gráfico de linha para este propósito:
df.groupby('continente').mean().transpose().plot(figsize=(20, 10))
plt.show()Isto irá criar um gráfico de linha onde o eixo x representa o tempo e o eixo y representa a média da população. Cada linha no gráfico representa um continente diferente.
Identificando Outliers com Box Plots
Os gráficos de caixa são uma ótima maneira de identificar outliers em seus dados. Um outlier é um valor que é significativamente diferente dos outros valores. Outliers podem ser causados por vários fatores, como erros de medição ou variabilidade genuína em seus dados.
No Pandas, você pode criar um gráfico de caixa utilizando a função boxplot():
df.boxplot(figsize=(20, 10))
plt.show()Isto irá criar um gráfico de caixa para cada coluna em seu DataFrame. A caixa em cada gráfico de caixa representa o intervalo interquartil (o intervalo entre os percentis 25 e 75), a linha dentro da caixa representa a mediana e os pontos fora da caixa representam outliers.
Entendendo os Tipos de Dados
Entender os tipos de dados em seu DataFrame é outro aspecto crucial da EDA. Diferentes tipos de dados requerem diferentes técnicas de tratamento e podem suportar diferentes tipos de operações. Por exemplo, operações numéricas não podem ser realizadas em dados de string e vice-versa.
No Pandas, você pode verificar os tipos de dados de todas as colunas em seu DataFrame utilizando o atributo dtypes:
df.dtypesEste retornará uma Series com os nomes das colunas como índice e os tipos de dados das colunas como valores.
Filtrando dados com base nos tipos de dados
Às vezes, você pode querer executar operações apenas em colunas de um determinado tipo de dados. Por exemplo, você pode querer calcular medidas estatísticas como média, mediana, etc., apenas em colunas numéricas. Nestes casos, você pode filtrar as colunas com base em seus tipos de dados.
No Pandas, você pode usar a função select_dtypes() para selecionar colunas de um tipo de dados específico:
numeric_df = df.select_dtypes(include='number')Isso retornará um novo DataFrame contendo apenas as colunas com dados numéricos. Da mesma forma, você pode selecionar colunas com tipo de dados objeto (string) da seguinte maneira:
object_df = df.select_dtypes(include='object')Visualizando Distribuições de Dados com Histogramas
Histogramas são uma ótima maneira de visualizar a distribuição de seus dados. Eles podem fornecer insights sobre a tendência central, variabilidade e assimetria de seus dados.
No Pandas, você pode criar um histograma usando a função hist():
df['population'].hist(bins=30)
plt.show()Isso criará um histograma para a coluna 'população'. O parâmetro bins determina o número de intervalos para dividir os dados.
Combine PyGWalker e Pandas para Análise Exploratória de Dados
No mundo da ciência de dados e análise, muitas vezes nos encontramos mergulhando profundamente na exploração e análise de dados usando ferramentas como pandas, matplotlib e seaborn. Embora essas ferramentas sejam incrivelmente poderosas, às vezes podem deixar a desejar quando se trata de exploração e visualização de dados interativos. É aqui que entra o PyGWalker.

PyGWalker, pronunciado como "Pig Walker", é uma biblioteca Python que se integra perfeitamente com o Jupyter Notebook (ou outros notebooks baseados em jupyter) e o Graphic Walker, uma alternativa de código aberto ao Tableau. O PyGWalker transforma seu dataframe pandas em uma interface de usuário estilo Tableau para exploração visual, tornando seu fluxo de trabalho de análise de dados mais interativo e intuitivo.
PyGWalker é construído por uma coleção apaixonada de contribuidores de código aberto. Não se esqueça de conferir PyGWalker GitHub (opens in a new tab) e dar uma estrela!
Começando com o PyGWalker
Instalar o PyGWalker é muito fácil. Basta abrir seu caderno Jupyter e digitar:
!pip install pygwalkerExploração de Dados Interativa com PyGWalker
Depois de instalar o PyGWalker, você pode começar a explorar seus dados de forma interativa. Para fazer isso, você simplesmente precisa chamar a função walk() no seu dataframe:
import pygwalker as pyg
pyg.walk(data)Este arquivo markdown abrirá uma ferramenta interativa de visualização de dados que se parece muito com o Tableau. A parte esquerda da interface exibe as variáveis em seu conjunto de dados. A área central é reservada para suas visualizações onde você pode arrastar e soltar suas variáveis nas caixas do eixo X e Y. O PyGWalker também oferece várias opções de personalização, como filtros, cor, opacidade, tamanho e forma, permitindo que você adapte suas visualizações às suas necessidades específicas.
Criando Visualizações com PyGWalker
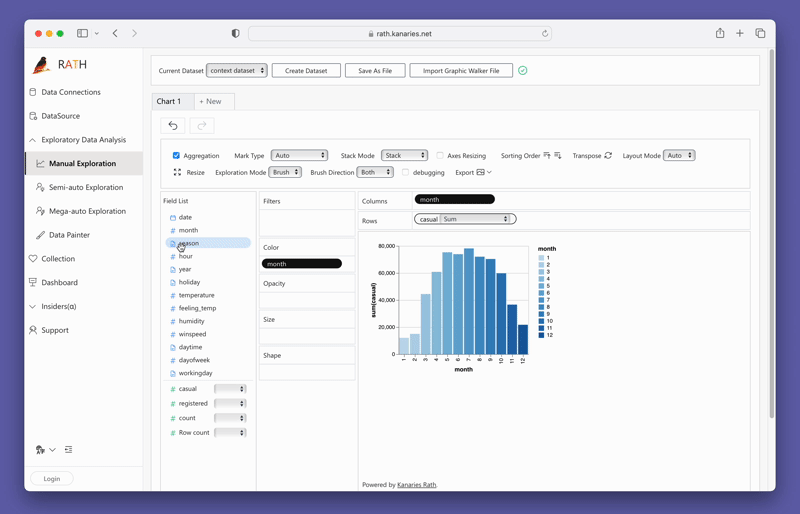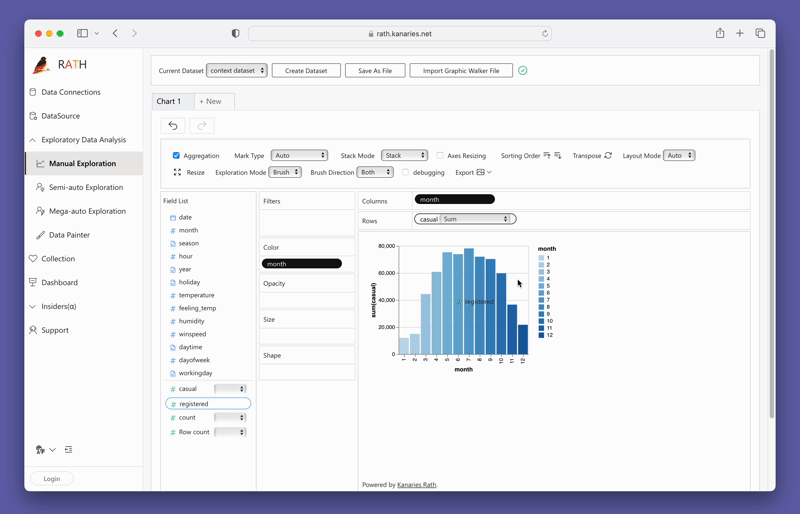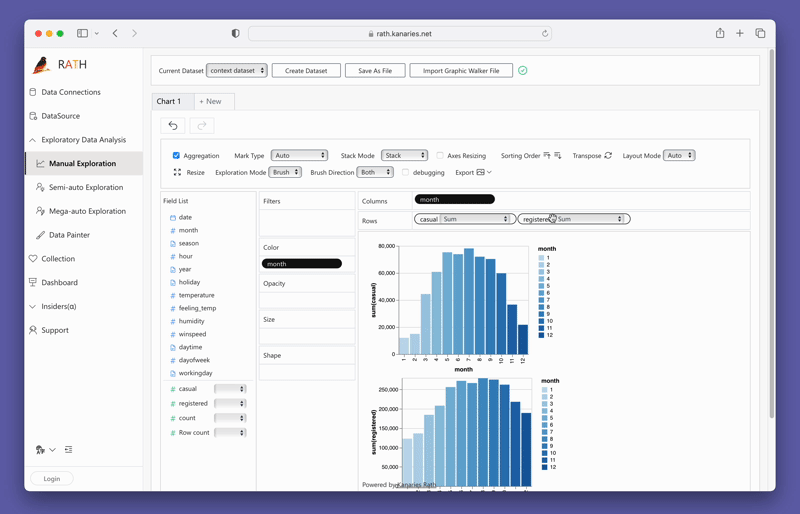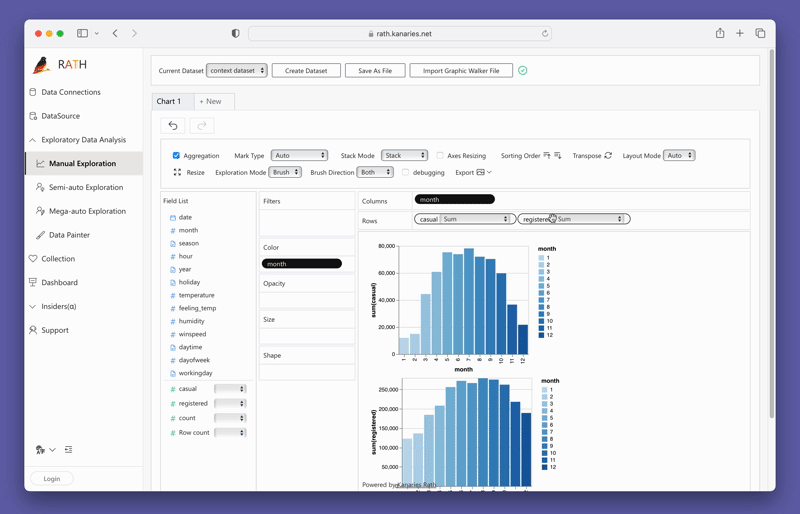
Criar visualizações com o PyGWalker é tão simples quanto arrastar e soltar suas variáveis. Por exemplo, para criar um gráfico de barras de vendas por região, você arrastaria a coluna "Vendas" para o eixo X e a coluna "Região" para o eixo Y. O PyGWalker também permite que você selecione o tipo de marca desejado ou deixe-o em modo automático para que a ferramenta possa selecionar o tipo de gráfico mais adequado para você.
Para obter mais detalhes sobre a criação de todos os tipos de visualizações de dados, consulte a Documentação.
Explorando Dados com PyGWalker
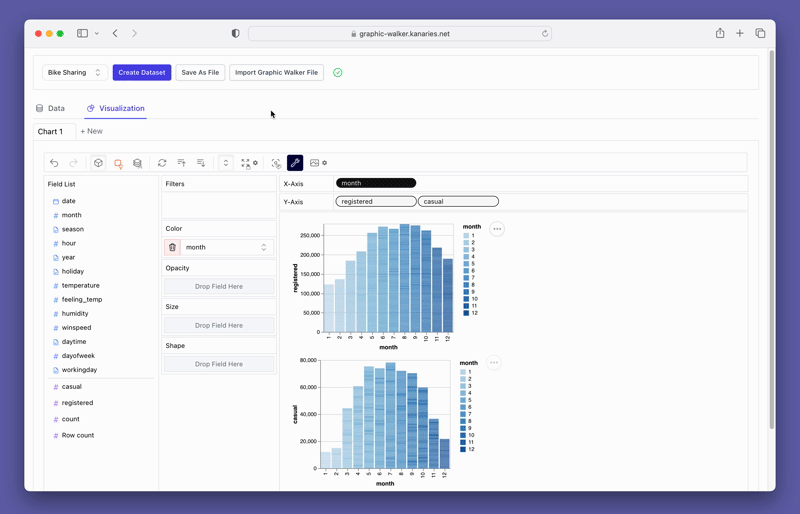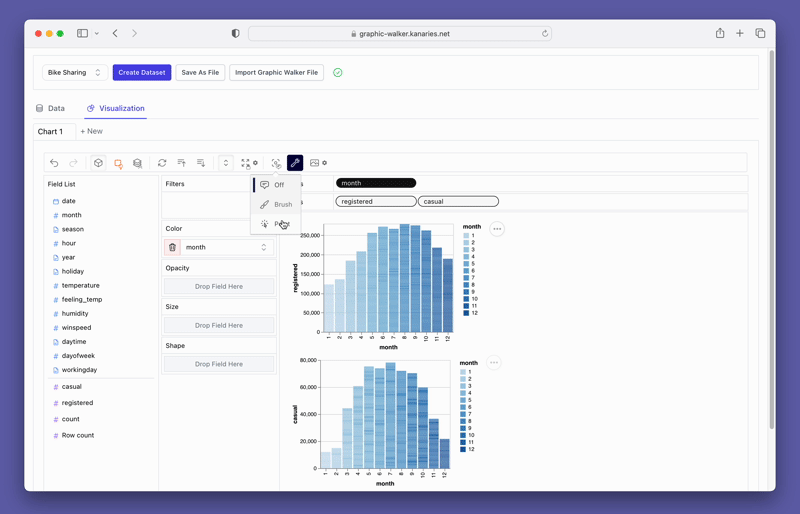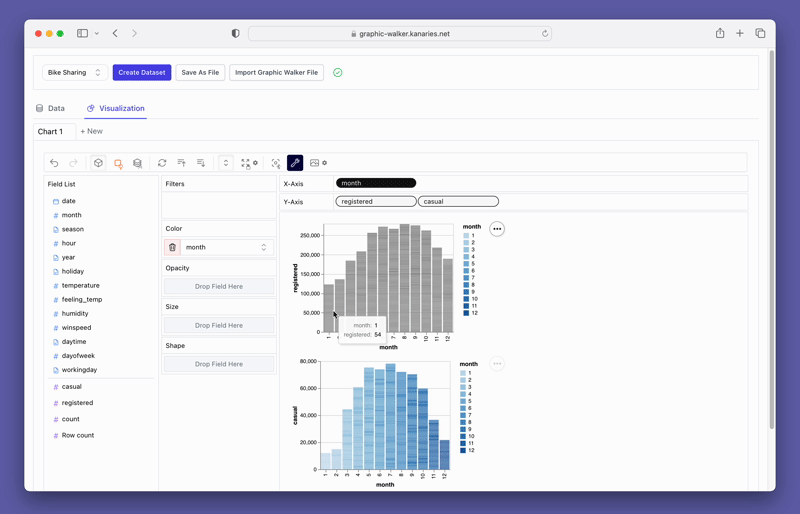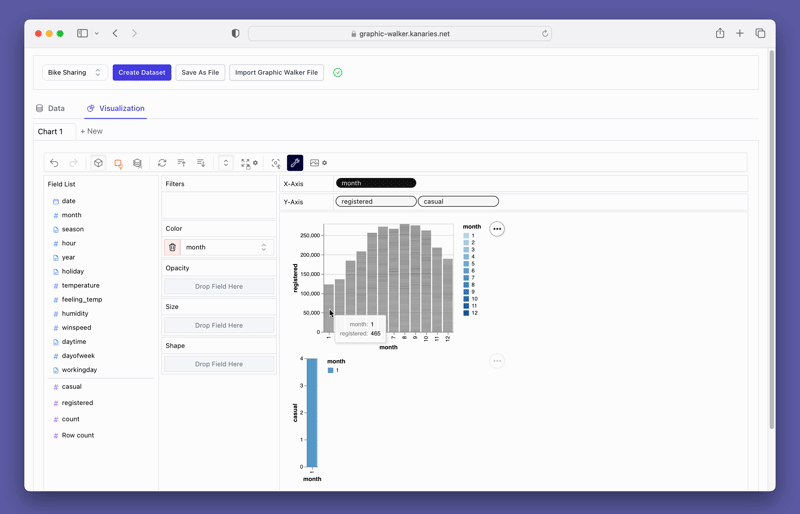
O PyGWalker também fornece opções fáceis de usar para filtragem e agregação. Você pode filtrar seus dados com base em qualquer coluna arrastando a coluna para a caixa de filtro. Da mesma forma, você pode agregar suas colunas numéricas selecionando a função de agregação entre as opções disponíveis.
Confira a Documentação para mais exemplos e ferramentas para Análise Exploratória de Dados em PyGWalker.
Depois de satisfeito com suas visualizações, você pode exportá-las e salvá-las como arquivos PNG ou SVG para uso posterior. Na atualização 0.1.6 do PyGWalker, você também pode exportar visualizações para uma string de código.
Conclusão
A Análise Exploratória de Dados (AED) é uma etapa fundamental em qualquer projeto de ciência de dados. Ela permite que você entenda seus dados, descubra padrões e tome decisões informadas sobre o processo de modelagem. A biblioteca Pandas do Python oferece uma ampla variedade de funções para conduzir a AED de maneira eficiente e efetiva.
Neste artigo, abordamos como lidar com valores ausentes, explorar valores únicos, classificar valores, visualizar correlações, agrupar dados, visualizar dados ao longo do tempo, identificar valores discrepantes, entender tipos de dados, filtrar dados com base em tipos de dados e visualizar distribuições de dados. Com essas técnicas em seu kit de ferramentas de ciência de dados, você está bem equipado para mergulhar em seus próprios dados e extrair insights valiosos.
Lembre-se, a AED é mais uma arte do que uma ciência. Isso requer curiosidade, intuição e um olho aguçado para detalhes. Então, não tenha medo de mergulhar fundo em seus dados e explorá-los sob diferentes perspectivas. Boa análise!
- Runcell Science: alternativa open source ao Claude Science para pesquisa com IA
- Como impedir o Mac de dormir: mantenha Codex, Claude Code e agentes de IA rodando
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot: qual stack de agentes de IA você deve escolher em 2026?
- Como o Claude Code analisa notebooks Jupyter em Data Science: capacidade real, limites e alternativa melhor
- Claude Code Routines: rotinas e cron jobs para agentes de IA
- Claude Code Desktop: como ativar Bypass permissions
- Como Construir Dois Agentes Python com o Protocolo A2A do Google - Tutorial Passo a Passo
- Top 10 bibliotecas de visualização de dados em Python em 2025
Perguntas Frequentes
-
O que é análise exploratória de dados?
Análise exploratória de dados é o processo de analisar e visualizar dados para descobrir padrões, relacionamentos e insights. Envolve técnicas como limpeza de dados, transformação de dados e visualização de dados.
-
Por que a análise exploratória de dados é importante?
A análise exploratória de dados é importante porque ajuda a entender os dados, identificar tendências e padrões e tomar decisões informadas sobre análises adicionais. Permite que os cientistas de dados obtenham insights e descubram padrões ocultos que podem impulsionar decisões de negócios.
-
Quais são algumas técnicas comuns usadas na análise exploratória de dados?
Algumas técnicas comuns usadas na análise exploratória de dados incluem estatísticas de resumo, visualização de dados, limpeza de dados, tratamento de valores ausentes, detecção de valores discrepantes e análise de correlação.
-
Quais ferramentas são comumente usadas para análise exploratória de dados?
Existem várias ferramentas comumente usadas para análise exploratória de dados, incluindo bibliotecas Python como Pandas, NumPy e Matplotlib, além de software como Tableau e Excel.
-
Quais são as etapas principais na análise exploratória de dados?
As etapas principais na análise exploratória de dados incluem limpeza de dados, exploração de dados, visualização de dados, análise estatística e conclusões a partir dos dados. Essas etapas são iterativas e envolvem refinamento e exploração contínuos dos dados.