Qwen3-VL: IA Multimodal Open Source com Visão Avançada

TL;DR — Qwen acaba de lançar o Qwen3‑VL, a mais nova série vision‑language com pesos abertos. O carro‑chefe Qwen3‑VL‑235B‑A22B (Instruct + Thinking) é aberto sob Apache‑2.0, com contexto nativo de 256K (extensível a 1M), raciocínio espacial/vídeo mais forte e OCR em 32 idiomas. Mira não só reconhecimento, mas raciocínio multimodal mais profundo e controle agentic de UI. É enorme (~471 GB de weights), então a maioria das equipes começará via APIs ou inferência hospedada. (GitHub (opens in a new tab))
O que foi lançado (e por que importa)
Qwen3‑VL é a mais recente família vision‑language da equipe Qwen. O repositório e os model cards destacam upgrades em compreensão de texto, percepção/raciocínio visual, compreensão de vídeo de longo contexto e interação de agente (por exemplo, operar GUIs de PC/mobile). Arquiteturalmente, introduz Interleaved‑MRoPE para vídeo de longo horizonte, DeepStack para fusão ViT em múltiplos níveis e Text–Timestamp Alignment para modelagem temporal de vídeo precisa. (GitHub (opens in a new tab))
O primeiro release open‑weight é o modelo de ≈235B de parâmetros em MoE (A22B = ~22B experts ativos por token), disponibilizado nas edições Instruct e Thinking e licenciado sob Apache‑2.0. O modelo enfatiza STEM/raciocínio multimodal, percepção espacial/grounding 2D–3D, entendimento de vídeos longos e OCR em 32 idiomas. (Hugging Face (opens in a new tab))
Data de lançamento: a Qwen lista os weights do Qwen3‑VL‑235B‑A22B Instruct e Thinking como lançados em 23 de setembro de 2025. (GitHub (opens in a new tab))
Especificações principais em um relance
| Capacidade | Detalhe do Qwen3‑VL |
|---|---|
| Open‑weight variants | 235B A22B Instruct e Thinking (Apache‑2.0) |
| Context length | 256K nativo, expandível para 1M (orientação Qwen) |
| Vision/Video | Raciocínio espacial aprimorado, grounding temporal em vídeos longos |
| OCR | 32 idiomas, robusto a baixa luz/desfoque/inclinação |
| Agentic | Lê GUIs e planeja ações para tarefas em PC/mobile |
| Size | HF cards reportam ≈236B params; comunidade nota ~471 GB de weights |
| Framework support | Integração oficial com Transformers em meados de set/2025 |
Fontes: repo+cards para recursos/edições, comprimento de contexto e claims de agente; docs da HF para integração ao Transformers; Simon Willison para nota prática do tamanho dos weights. (GitHub (opens in a new tab))
O que há de novo vs. Qwen2.5‑VL?
- Modelagem temporal e espacial mais afiada: Interleaved‑MRoPE + Text–Timestamp Alignment visam localizar eventos ao longo de vídeos longos com mais precisão do que abordagens T‑RoPE anteriores. DeepStack melhora o alinhamento imagem–texto de grão fino. (GitHub (opens in a new tab))
- Contexto mais longo e envelope de modalidades mais amplo: 256K tokens por padrão com caminho de expansão para 1M; melhor compreensão de GUI, documentos e vídeos longos. (GitHub (opens in a new tab))
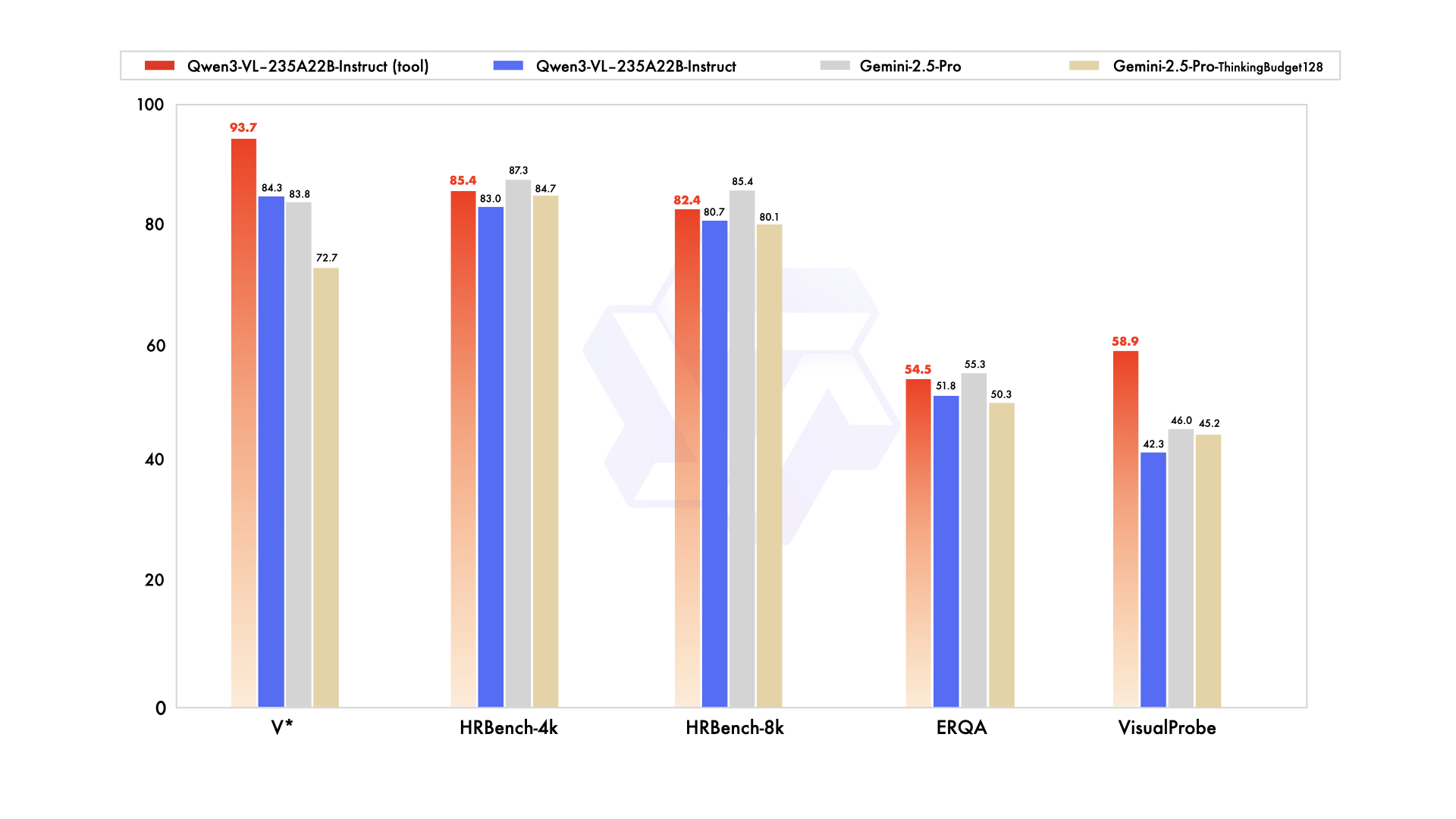
- Edições maiores e ajustadas para raciocínio: versões Thinking miram tarefas de raciocínio multimodal; a Qwen afirma desempenho competitivo ou superior a bases multimodais proprietárias em benchmarks selecionados (auto‑relatado). (Simon Willison’s Weblog (opens in a new tab))
O blog e as postagens sociais da Qwen afirmam paridade/superioridade sobre Gemini 2.5 Pro em benchmarks de percepção e SOTA em vários conjuntos de raciocínio multimodal — vale verificação independente. (Simon Willison’s Weblog (opens in a new tab))

Artefatos de lançamento e onde executá‑lo
-
GitHub: trechos de código (Transformers), cookbooks (OCR, grounding, vídeo, agents). O paper está “a caminho”. (GitHub (opens in a new tab))
-
Hugging Face:
- Qwen3‑VL‑235B‑A22B‑Instruct (Apache‑2.0) (Hugging Face (opens in a new tab))
- Qwen3‑VL‑235B‑A22B‑Thinking (Apache‑2.0) (Hugging Face (opens in a new tab))
-
Suporte em Transformers: Qwen3‑VL entrou na documentação do Transformers em meados de setembro de 2025. (Hugging Face (opens in a new tab))
-
Opções hospedadas: OpenRouter lista Qwen3‑VL 235B para uso via API; o Model Studio da Alibaba Cloud oferece SKUs de API Qwen‑Plus/Qwen3‑VL‑Plus com modos thinking vs non‑thinking e faixas de preço. (OpenRouter (opens in a new tab))
Nota sobre nomenclatura: leitores do HN apontam que Qwen3‑VL‑Plus (API) e Qwen‑VL‑Plus (série mais antiga) são diferentes, e que o snapshot naming qwen‑plus‑2025‑09‑11 pode confundir quem está chegando agora. Você não está só. (Hacker News (opens in a new tab))
Benchmarks (leia com cuidado)
Os canais de anúncio da Qwen afirmam que Instruct “igualou/superou” Gemini 2.5 Pro em testes com foco em percepção e que Thinking atingiu SOTA em diversas suítes de raciocínio multimodal. Esses números são auto‑relatados; avaliações independentes serão importantes, especialmente para compreensão de gráficos/tabelas, raciocínio com diagramas e vídeo QA, onde a curadoria de dados pode deslocar resultados. (Simon Willison’s Weblog (opens in a new tab))
Dito isso, notas iniciais da comunidade comparam Qwen3‑Omni → Qwen3‑VL‑235B em conjuntos compartilhados (por exemplo, HallusionBench, MMMU‑Pro, MathVision) e sugerem ganhos significativos — novamente, ainda não revisados por pares. (Reddit (opens in a new tab))
Por que a academia continua escolhendo Qwen (e provavelmente adotará Qwen3‑VL rapidamente)
Enquanto muitos apps de negócios padronizam em GPT/Claude/Gemini por conveniência e SLAs, grupos de pesquisa frequentemente precisam de weights abertos para reprodutibilidade, auditoria, ablação e fine‑tuning por domínio. O catálogo da Qwen facilita isso:
- Weights abertos em diversas escalas (de sub‑2B a 235B+ em MoE), permitindo experimentos que cabem nas GPUs de laboratório e escalam depois. (Qwen (opens in a new tab))
- Licenciamento permissivo (Apache‑2.0 em muitos checkpoints) reduz atritos para colaboração academia/indústria. (Hugging Face (opens in a new tab))
- Uso demonstrado em papers: por exemplo, BioQwen em biomédico bilíngue; RCP‑Merging que usa bases Qwen2.5 para estudar long CoT/domain merging; vários trabalhos de RL‑tuning em VLMs médicos partem do Qwen2.5. (ciblab.net (opens in a new tab))
Com o Qwen3‑VL adicionando melhorias em vídeo longo e grounding espacial enquanto permanece open‑weight, é de esperar que vire baseline padrão para projetos acadêmicos multimodais, particularmente em inteligência de documentos, diagramas científicos, medical VQA e pesquisa embodied/agentic.
Para equipes de produto: orientações práticas
- Comece hospedado, depois otimize: o modelo carro‑chefe é enorme (nota da comunidade: ~471 GB de weights). A menos que você tenha clusters multi‑GPU (A100/H100/MI300), comece via API (por exemplo, OpenRouter, Alibaba Model Studio) e reavalie implantação local/edge quando chegarem tamanhos menores do Qwen3‑VL (como aconteceu com Qwen2.5‑VL 72B/32B/7B/3B). (Simon Willison’s Weblog (opens in a new tab))
- “Thinking” ≠ sempre melhor: as APIs da Qwen expõem modos thinking vs non‑thinking com orçamentos de tokens e preços diferentes. Use thinking seletivamente (por exemplo, tarefas multimodais longas/ambíguas). (AlibabaCloud (opens in a new tab))
- Atenção aos custos de contexto: contextos de 256K–1M são poderosos, mas caros. Divida documentos/vídeos de forma inteligente; use pré‑parsing (OCR/layout) e RAG para minimizar inchaço do prompt. (GitHub (opens in a new tab))
- Agentic UX: se você precisa de automação de UI a partir de screenshots ou streams de tela, os recursos de agente visual do Qwen3‑VL valem um piloto — mas invista em APIs de ferramentas robustas e guardrails. (GitHub (opens in a new tab))
Início rápido (Transformers)
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor # HF >= 4.57
model_id = "Qwen/Qwen3-VL-235B-A22B-Instruct" # or ...-Thinking
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(model_id, dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [{"role": "user", "content": [
{"type": "image", "image": "https://.../app-screenshot.png"},
{"type": "text", "text": "What button should I tap to turn on dark mode? Explain briefly."}
]}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])Isto espelha o exemplo do model card da Qwen (ative FlashAttention‑2 se disponível). Para multi‑imagem ou vídeo, passe múltiplas entradas {"type": "image"} ou um item {"type": "video"} com controles de frame/pixel conforme mostrado no repositório. (Hugging Face (opens in a new tab))
Armadilhas e pegadinhas comuns
- Naming drift: “Qwen3‑VL‑Plus” (API) vs. “Qwen‑VL‑Plus” (linha open‑weight mais antiga) não são a mesma coisa. Confira a documentação do Model Studio e a página da HF que você está carregando. (Hacker News (opens in a new tab))
- Ilusões de memória: o 235B em MoE tem weights abertos, mas “MoE” não o torna pequeno para inferência. Planeje memória e banda de acordo. Notas da comunidade colocam os weights em cerca de 471 GB. (Simon Willison’s Weblog (opens in a new tab))
- Leaderboards auto‑relatados: trate gráficos de marketing como hipóteses. Rode suas próprias avaliações — especialmente para charts/tables, documentos e vídeo QA.
FAQ
Q: O que significa “A22B” em Qwen3‑VL‑235B‑A22B? A: É um modelo Mixture‑of‑Experts com ~235B de parâmetros totais e ~22B ativos por token — trocando eficiência de compute por capacidade. (Qwen (opens in a new tab))
Q: Instruct vs Thinking — quando escolher cada um? A: Instruct é alinhado para uso geral e tende a ser mais rápido/barato. Thinking adiciona traces de raciocínio internamente (a API expõe “thinking mode”), o que pode ajudar em tarefas composicionais ou de longo horizonte, mas custa mais tokens. Teste ambos no seu conjunto de avaliação. (Hugging Face (opens in a new tab))
Q: É mesmo “melhor que o Gemini 2.5 Pro”? A: A Qwen alega vitórias em benchmarks de percepção selecionados e SOTA em várias tarefas multimodais, mas são números auto‑relatados. Comparações independentes levarão tempo — acompanhe as avaliações da comunidade e seus testes específicos de domínio. (Simon Willison’s Weblog (opens in a new tab))
Q: Posso rodar localmente? A: Só se você tiver hardware sério (multi‑GPU com muita RAM). A maioria das equipes usará inferência hospedada primeiro (por exemplo, OpenRouter, Model Studio). Para testes locais menores, considere tamanhos anteriores do Qwen2.5‑VL (72B/32B/7B/3B) até chegarem variantes menores do Qwen3‑VL. (OpenRouter (opens in a new tab))
Q: Como fica a licença? A: Os weights lançados do Qwen3‑VL‑235B‑A22B estão sob Apache‑2.0 conforme os model cards na HF. Sempre confirme a licença do checkpoint específico. (Hugging Face (opens in a new tab))
Q: Por que pesquisadores continuam escolhendo Qwen? A: Weights abertos em vários tamanhos, licenciamento permissivo e forte capacidade multilíngue — além de muitos exemplos de fine‑tunes baseados em Qwen na literatura (por exemplo, BioQwen, long‑CoT model merging, medical VQA com RL‑tuning partindo do Qwen2.5). (ciblab.net (opens in a new tab))
Reação da comunidade e discussão
O tópico no Hacker News rapidamente trouxe à tona confusão de nomenclatura (Qwen3‑VL‑Plus vs snapshots como qwen-plus-2025-09-11) e questões práticas de implantação, mas também entusiasmo com o ritmo dos lançamentos open‑weight. É uma boa janela para o sentimento dos early adopters. (Hacker News (opens in a new tab))
Para um resumo conciso da comunidade dev, veja a nota do Simon Willison — útil para uma checagem de sanidade sobre o tamanho do modelo e a provável cadência de variantes menores. (Simon Willison’s Weblog (opens in a new tab))
Considerações finais
Qwen3‑VL eleva o patamar dos modelos multimodais open‑weight ao ir além de “reconhecer esta imagem” rumo a “raciocinar‑e‑agir” em imagens, documentos e vídeos — e chega em um stack aberto familiar (Transformers). Para pesquisa, é um novo baseline óbvio. Para equipes de produto, o carro‑chefe é grande demais para a maioria dos self‑hostings hoje, mas é imediatamente valioso via APIs — especialmente para inteligência de documentos, entendimento de telas e vídeo QA. Espere a inflexão real quando tamanhos menores do Qwen3‑VL seguirem o padrão do Qwen2.5.
Referências e leituras adicionais
- Repo: QwenLM/Qwen3‑VL — recursos, notas de arquitetura, cookbooks, log de release. (GitHub (opens in a new tab))
- Model cards: Instruct e Thinking (Apache‑2.0), com quickstarts e gráficos de desempenho. (Hugging Face (opens in a new tab))
- Transformers docs: integração do Qwen3‑VL. (Hugging Face (opens in a new tab))
- Qwen3 overview & MoE sizes (explicação de A22B, line‑up open‑weighted). (Qwen (opens in a new tab))
- Discussão no HN: impressões da comunidade e confusão de nomes. (Hacker News (opens in a new tab))
- API/preços: Alibaba Cloud Model Studio (thinking vs non‑thinking, orçamentos de tokens). (AlibabaCloud (opens in a new tab))
- Exemplos de pesquisa usando Qwen: BioQwen; RCP‑Merging; medical VQA com RL‑tuning em bases Qwen2.5. (ciblab.net (opens in a new tab))