Visualización de Pandas: Un tutorial paso a paso
- Name
- Rajiv Chandra
Actualizado el
La biblioteca Pandas de Python es una herramienta poderosa que los científicos de datos y analistas de todo el mundo utilizan a diario. Una de sus características más convincentes es su capacidad de visualización de datos robusta. Este artículo te guiará a través del proceso de creación de gráficos convincentes utilizando Pandas, brindándote las habilidades necesarias para convertir datos en bruto en gráficos perspicaces.
La visualización de Pandas no se trata solo de hacer que tus datos se vean bonitos. Se trata de desbloquear las historias ocultas dentro de los números. Ya sea que estés explorando un nuevo conjunto de datos o preparándote para compartir tus últimos hallazgos, las visualizaciones son clave para comunicar conocimientos impulsados por datos.
Absolutamente, profundicemos en cada segmento con explicaciones más detalladas y ejemplos de código de muestra.
Usa la función plot para la visualización de Pandas
Pandas proporciona una estructura de datos de alto nivel, flexible y eficiente llamada DataFrame, que es extremadamente propicia para la visualización. Con la función .plot(), puedes generar una variedad de gráficos como líneas, barras, dispersión y más. Esta función es un envoltorio sobre la versátil biblioteca Matplotlib, lo que facilita la creación de visualizaciones complejas.
Por ejemplo, si estás comenzando tu camino con Pandas, pronto estarás creando gráficos de líneas básicos que pueden revelar tendencias valiosas en tus datos. Los gráficos de líneas son excelentes para mostrar datos a lo largo del tiempo, lo que los hace perfectos para el análisis de series de tiempo.
Aquí tienes un ejemplo sencillo de cómo crear un gráfico de líneas con Pandas:
import pandas as pd
import numpy as np
# Crear un DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
df.plot(kind='line')En este código, primero importamos las bibliotecas necesarias. Luego creamos un DataFrame con dos columnas, cada una llena de números aleatorios. Finalmente, utilizamos la función .plot() para crear un gráfico de líneas.
Pero, ¿qué pasa si quieres usar una interfaz de usuario visual para trazar Dataframes de Pandas sin código? Bueno, afortunadamente hay un Dataframe de Pandas que puede ayudarte a resolver el problema:
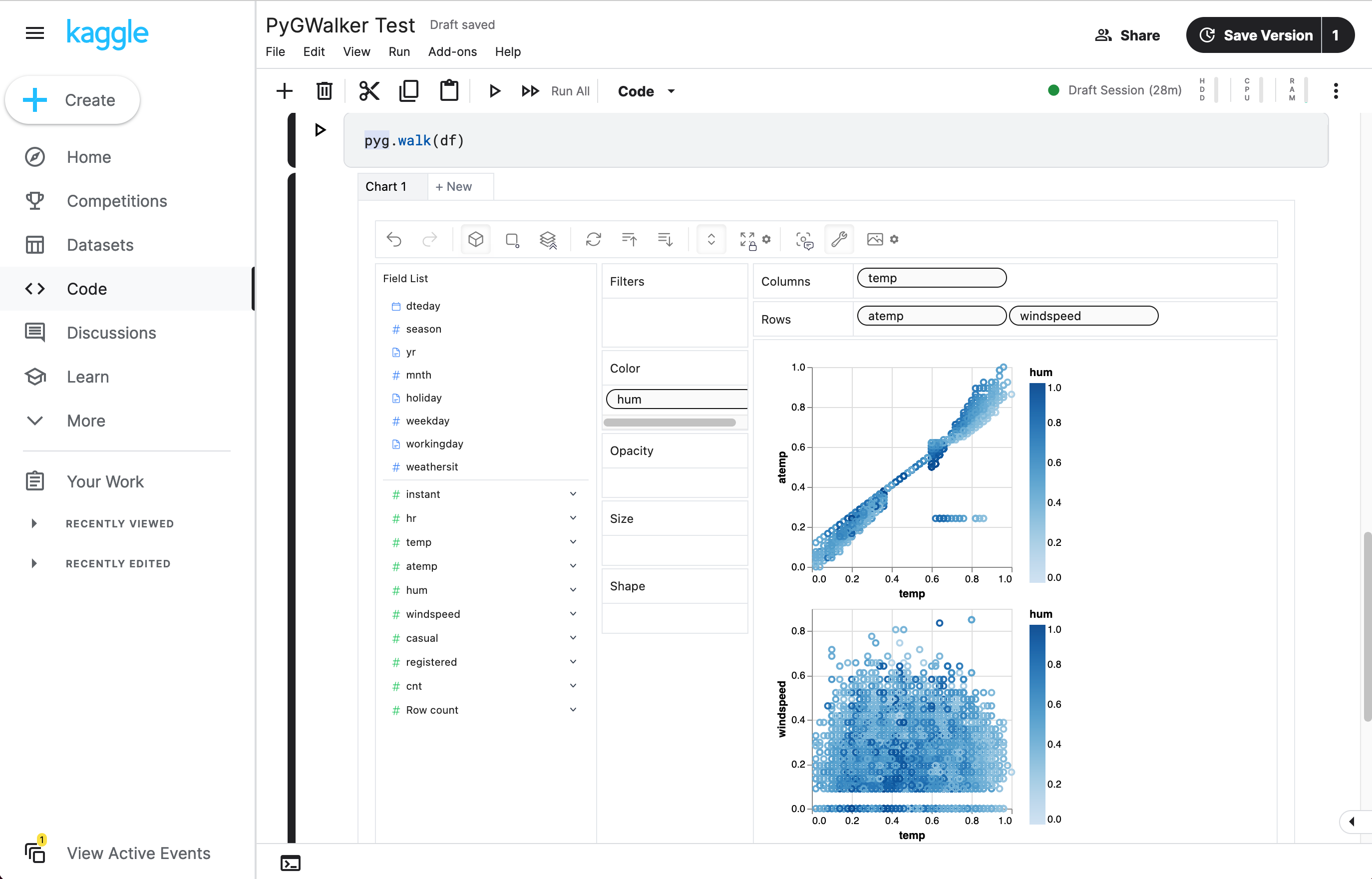
Usa PyGWalker para la visualización de Pandas
PyGWalker es una biblioteca de Python diseñada para Análisis Exploratorio de Datos y Visualización de Datos Fácil. Piensa en ello como ejecutar un Tableau de código abierto dentro de tu Jupyter Notebook. Puedes crear fácilmente visualizaciones arrastrando y soltando variables en lugar de consultar complejos tutoriales de codificación:
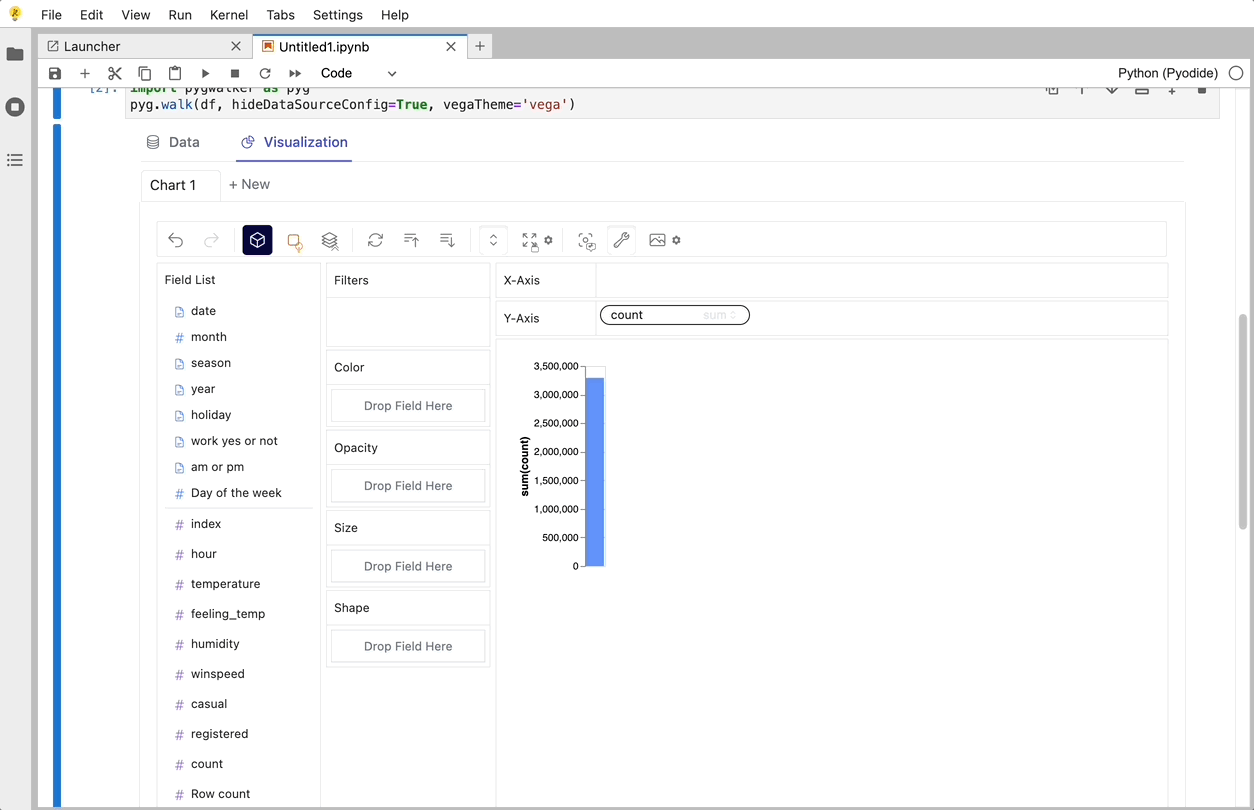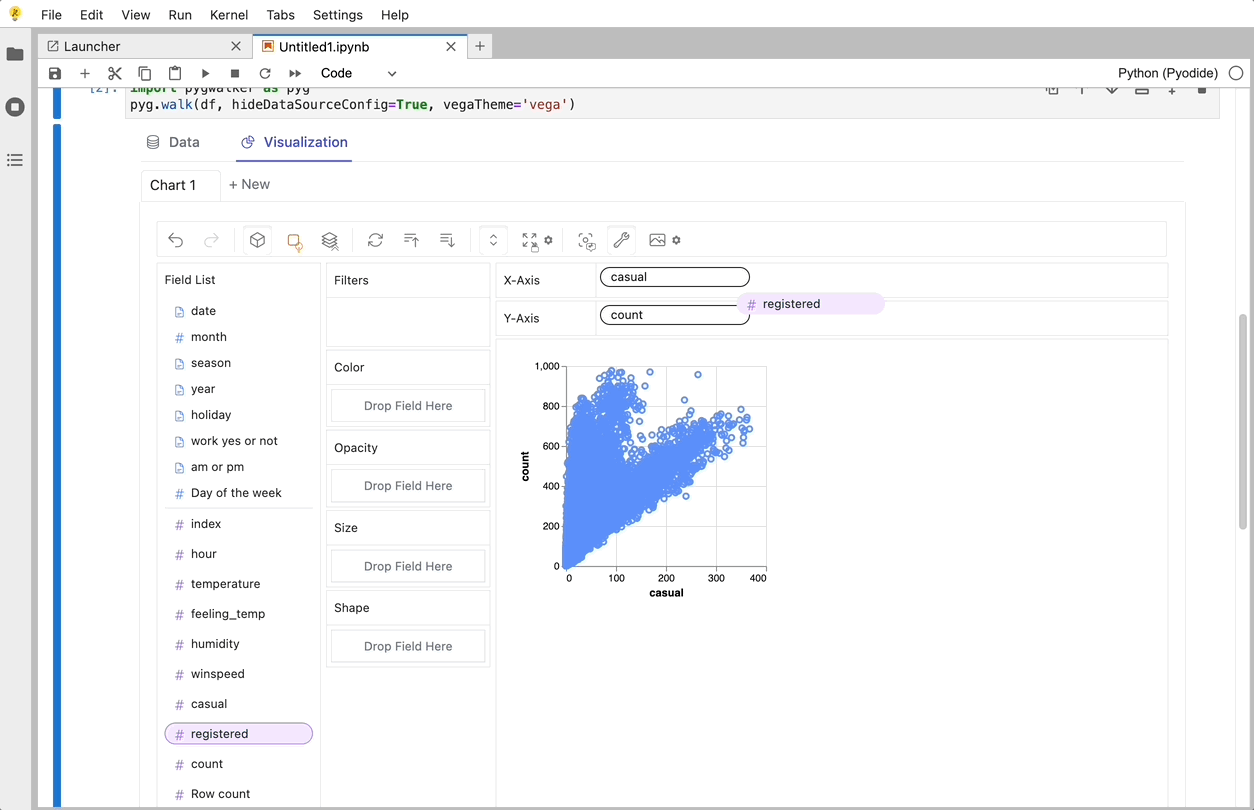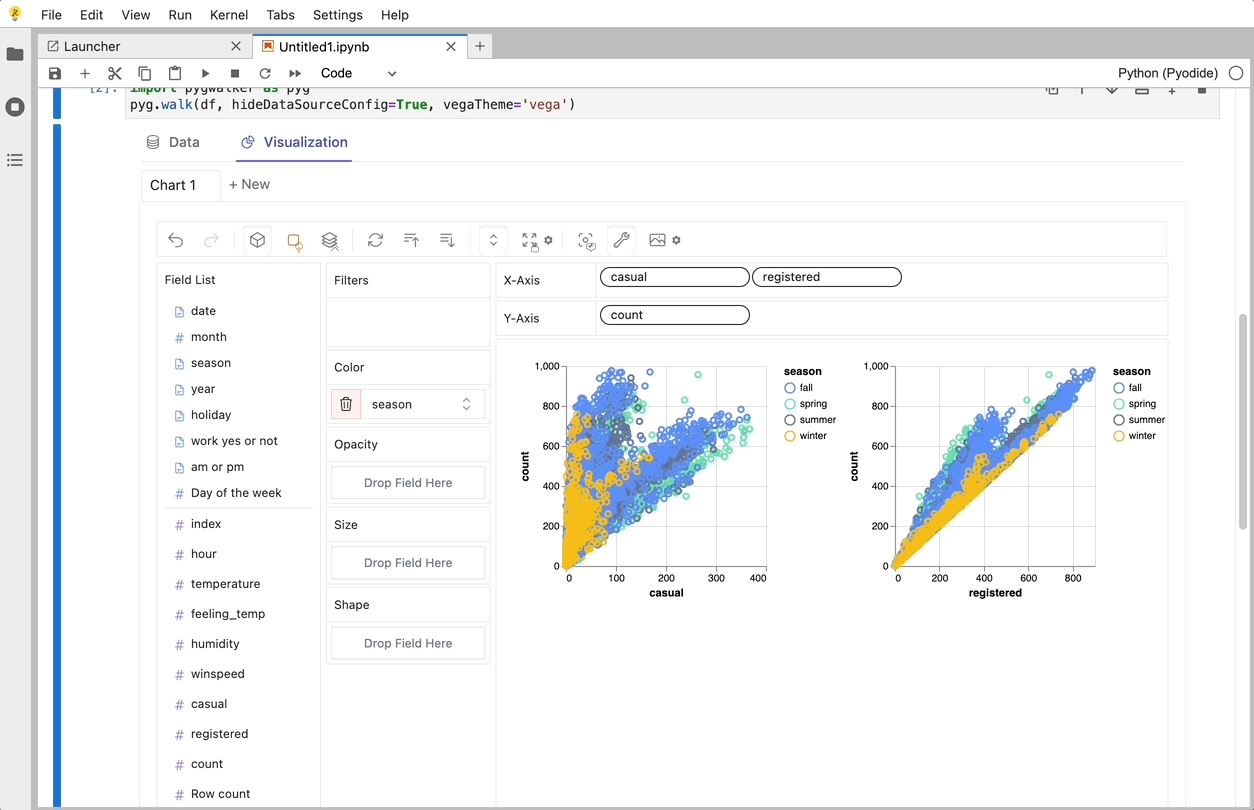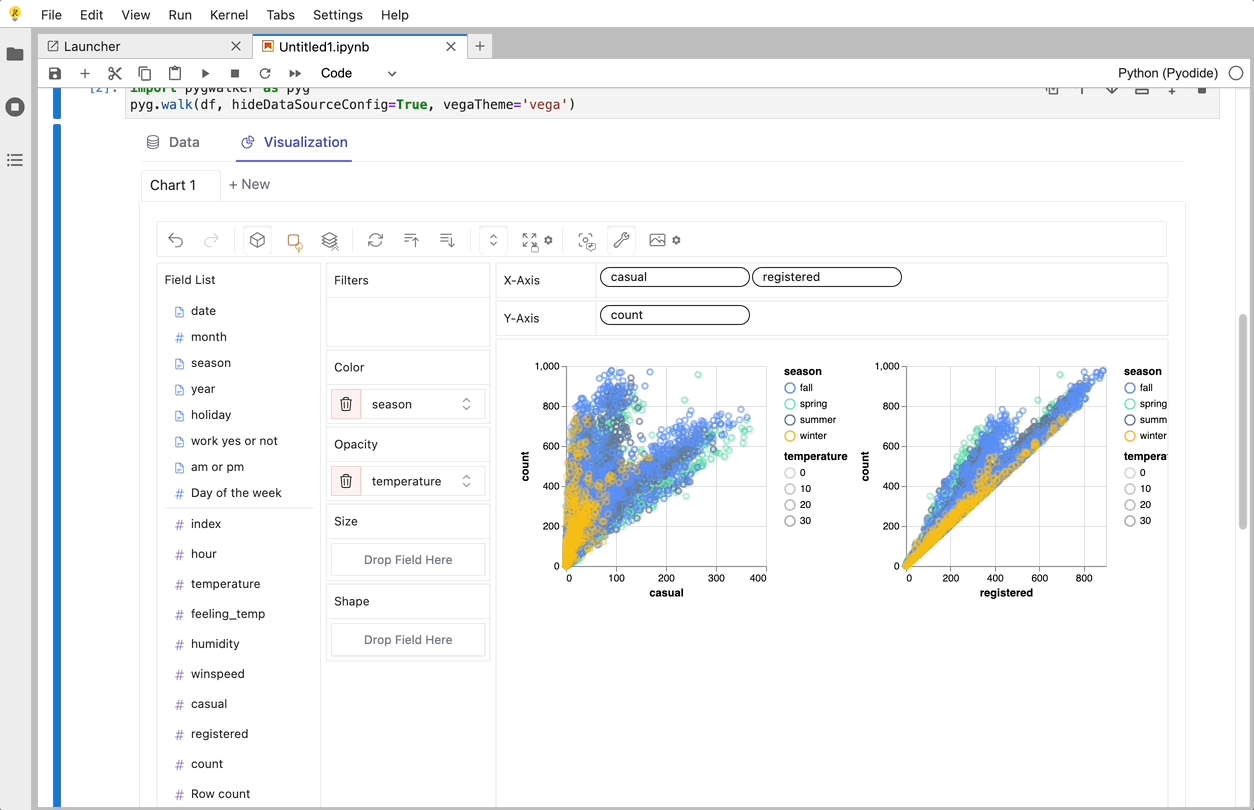
Aquí tienes cómo puedes empezar rápidamente:
Importa pandas y pygwalker a tu Jupyter Notebook para empezar.
import pandas as pd
import pygwalker as pygPuedes usar pygwalker sin interrumpir tu flujo de trabajo actual. Por ejemplo, puedes llamar a Graphic Walker con el dataframe cargado de esta manera:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Y puedes usar pygwalker con polars (desde pygwalker>=0.1.4.7a0):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Ahora has cargado tu Pandas Dataframe para visualización.
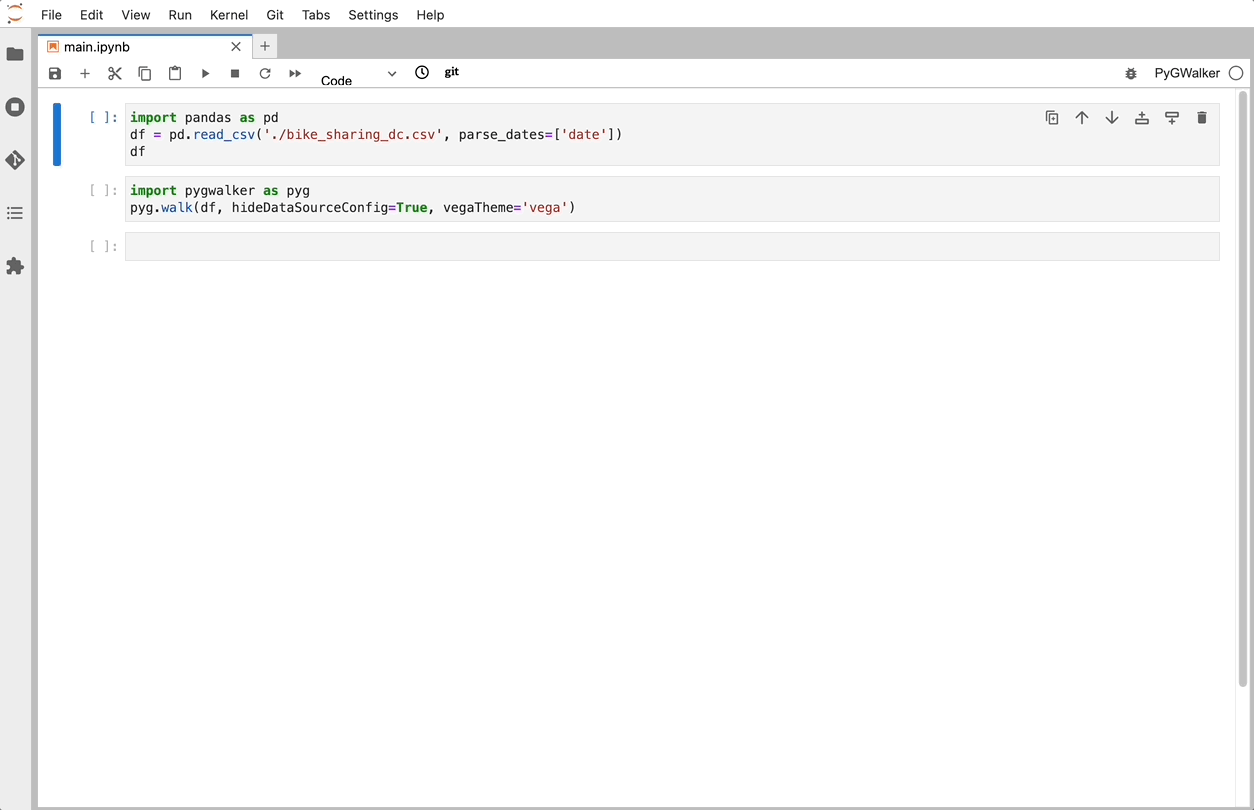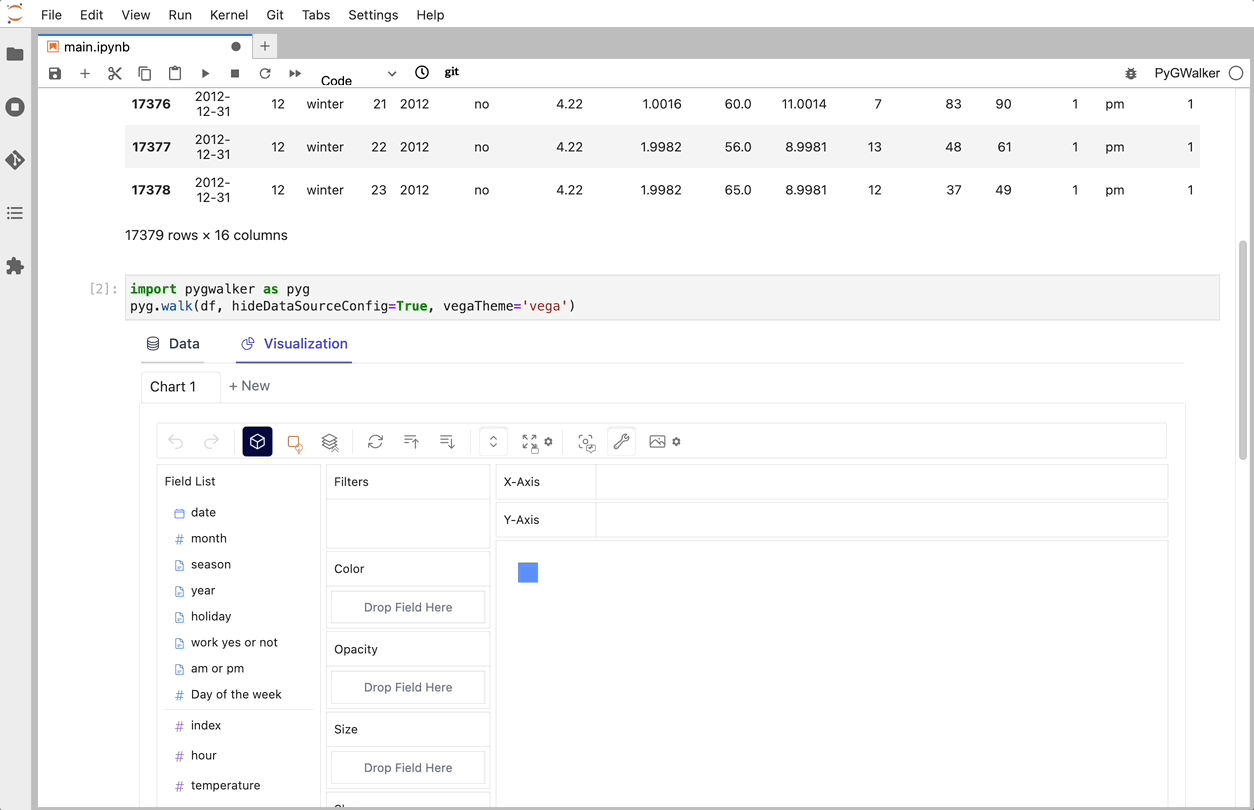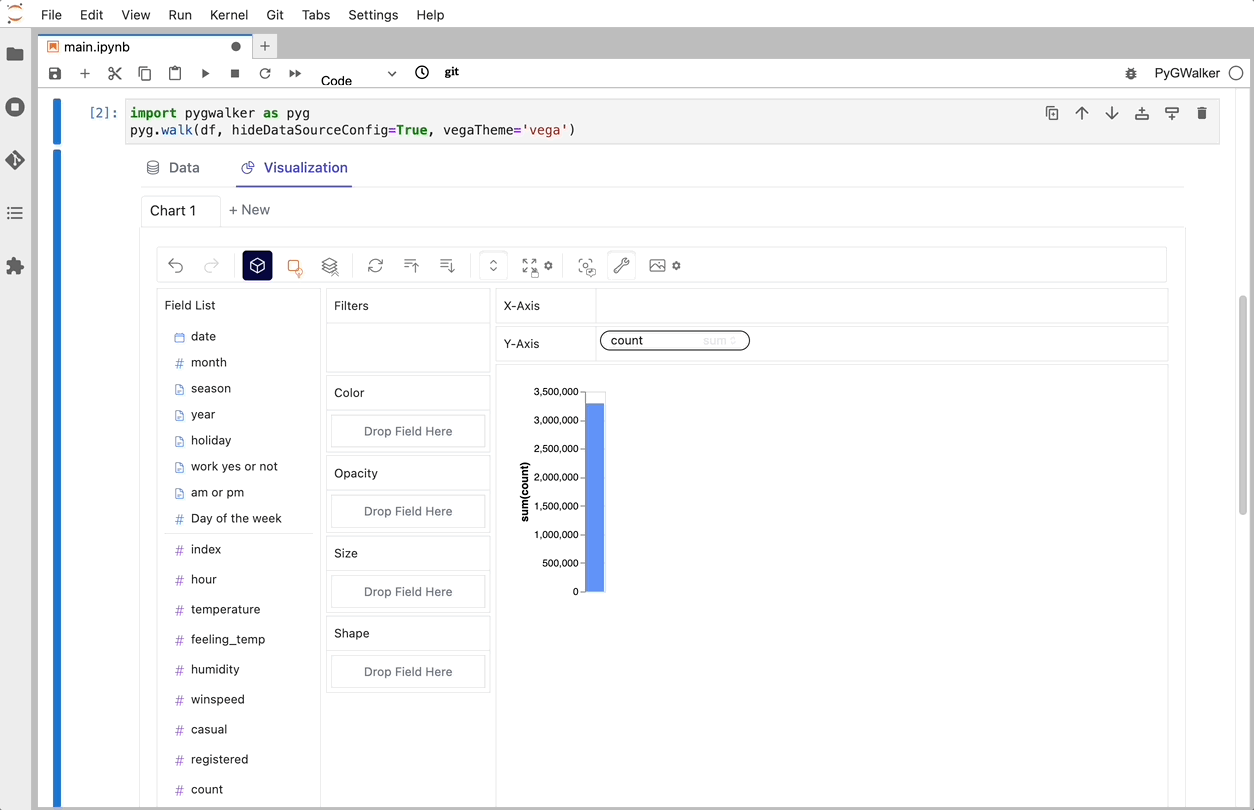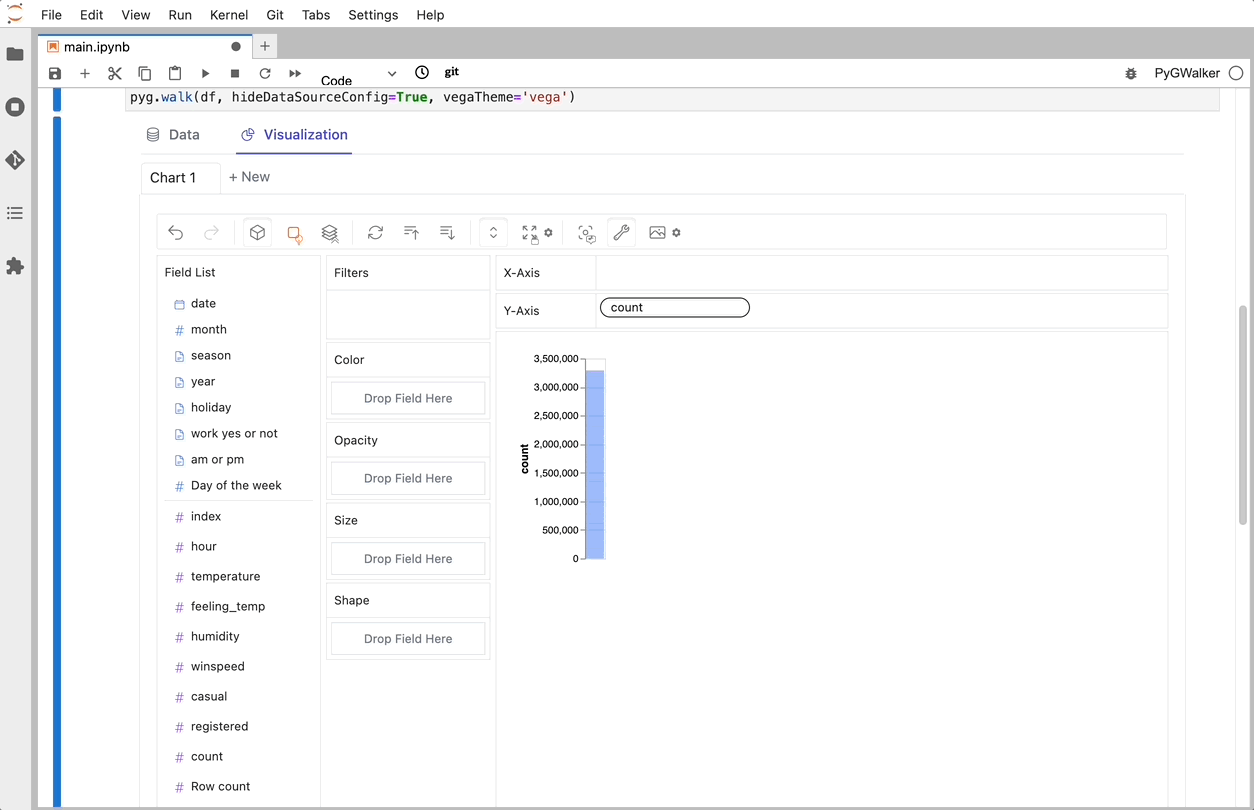
Eso es todo. Ahora tienes una interfaz de usuario similar a Tableau para analizar y visualizar datos arrastrando y soltando variables.
PyGWalker cuenta con el apoyo de una comunidad activa de desarrolladores y científicos de datos. Visita PyGWalker GitHub (opens in a new tab) ¡y dale una ⭐️!
Puedes probar PyGWalker con Google Colab o un Notebook de Kaggle ahora mismo:
| Ejecutar en Kaggle (opens in a new tab) | Ejecutar en Colab (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 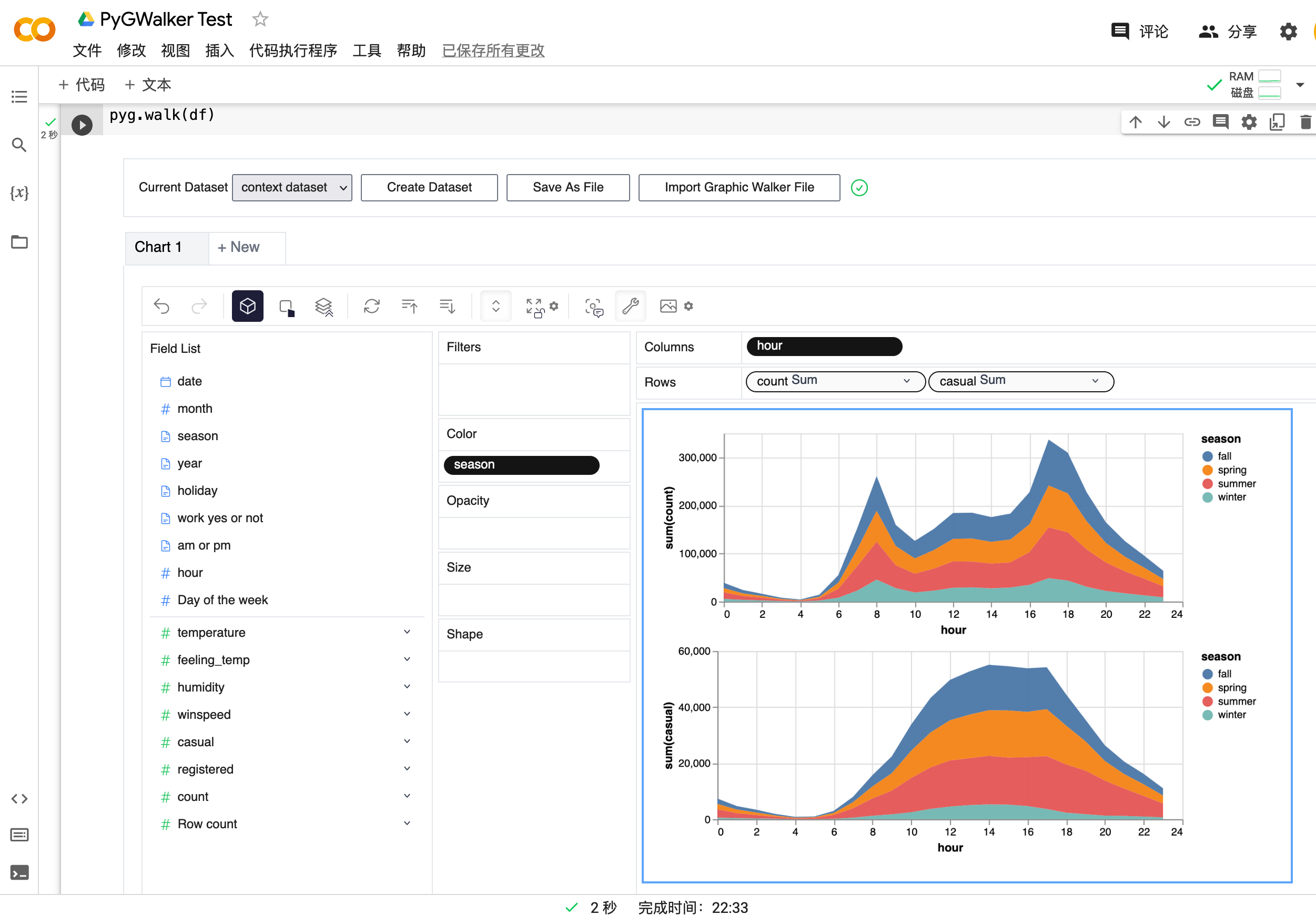 (opens in a new tab) (opens in a new tab) |
Sumergirse en diferentes tipos de gráficos
Pandas ofrece una variedad de tipos de gráficos, cada uno de ellos adecuado para diferentes tipos de datos y preguntas. Por ejemplo, los histogramas son ideales para obtener una visión general de la distribución de tus datos, mientras que los gráficos de dispersión pueden ayudarte a descubrir correlaciones entre diferentes puntos de datos.
Cada tipo de gráfico en Pandas viene con un conjunto de parámetros que puedes ajustar para personalizar tu visualización. Comprender estos parámetros y cuándo usarlos puede mejorar enormemente tu capacidad para crear visualizaciones significativas.
Así es como puedes crear un histograma y un gráfico de dispersión:
# Histograma
df['A'].plot(kind='hist')
# Gráfico de dispersión
df.plot(kind='scatter', x='A', y='B')En el primer gráfico, estamos creando un histograma de la columna 'A'. En el segundo gráfico, estamos creando un gráfico de dispersión con 'A' en el eje x y 'B' en el eje y.
Manejo de datos categóricos con Pandas
Los datos categóricos son un tipo de datos común que encontrarás en muchos conjuntos de datos. Pandas proporciona varias herramientas potentes para visualizar este tipo de datos. Por ejemplo, los gráficos de barras pueden ayudarte a comparar diferentes categorías, mientras que los gráficos de sectores son excelentes para visualizar las proporciones entre categorías.
Además, Pandas te permite agrupar tus datos en función de categorías, lo cual puede ser increíblemente útil cuando quieres agregar tus datos y obtener información a nivel de categoría.
Aquí tienes un ejemplo de cómo crear un gráfico de barras y un gráfico de sectores:
# Crear un DataFrame con datos categóricos
df = pd.DataFrame({
'Fruit': ['Manzana', 'Plátano', 'Cereza', 'Manzana', 'Cereza', 'Plátano', 'Manzana', 'Cereza', 'Plátano', 'Manzana'],
'Cantidad': np.random.randint(1, 10, 10)
})
# Gráfico de barras
df.groupby('Fruit')['Cantidad'].sum().plot(kind='bar')
# Gráfico de torta
df.groupby('Fruit')['Cantidad'].sum().plot(kind='pie')En este código, primero creamos un DataFrame con datos categóricos. Luego agrupamos los datos por la columna 'Fruit' y sumamos la 'Cantidad' para cada fruta. Finalmente, creamos un gráfico de barras y un gráfico de torta de las cantidades sumadas.
Personalización de tus gráficos
Una de las características más poderosas de la visualización de Pandas es la capacidad de personalizar tus gráficos. Esto incluye cambiar el color y el estilo de tus gráficos, agregar etiquetas y títulos, y mucho más.
Aquí tienes un ejemplo de cómo personalizar un gráfico de línea:
# Crear un DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
# Crear un gráfico de línea con personalizaciones
df.plot(kind='line',
color=['rojo', 'azul'],
style=['-', '--'],
title='Mi Gráfico de Línea',
xlabel='Índice',
ylabel='Valor')En este código, primero creamos un DataFrame con dos columnas, cada una llena de números aleatorios. Luego creamos un gráfico de línea y lo personalizamos configurando el color y el estilo de las líneas, y agregando un título y etiquetas para los ejes x e y.
Manejo de estructuras de datos más complejas
Pandas no se limita a manejar estructuras de datos simples. También puede manejar estructuras de datos más complejas como DataFrames con múltiples índices y datos de series temporales.
Aquí tienes un ejemplo de cómo crear un gráfico de línea a partir de un DataFrame con múltiples índices:
# Crear un DataFrame con múltiples índices
index = pd.MultiIndex.from_tuples([(i,j) for i in range(5) for j in range(5)])
df = pd.DataFrame({
'A': np.random.rand(25),
'B': np.random.rand(25)
}, index=index)
# Crear un gráfico de línea
df.plot(kind='line')En este código, primero creamos un DataFrame con múltiples índices con dos columnas, cada una llena de números aleatorios. Luego creamos un gráfico de línea a partir de este DataFrame.
Visualización avanzada con Seaborn
Si bien Pandas proporciona una base sólida para la visualización de datos, a veces es posible que necesites herramientas más avanzadas. Seaborn es una biblioteca de visualización de datos de Python basada en Matplotlib que proporciona una interfaz de alto nivel para crear visualizaciones hermosas e informativas.
Aquí tienes un ejemplo de cómo crear un gráfico de Seaborn a partir de un DataFrame de Pandas:
import seaborn as sns
# Cargar tu DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Crear un gráfico de Seaborn
sns.lineplot(data=df, x='date', y='count')En este código, primero importamos la biblioteca Seaborn. Luego cargamos un DataFrame y creamos un gráfico de línea con la columna 'date' en el eje x y la columna 'count' en el eje y.
Visualización interactiva con Plotly
Para visualizaciones interactivas, Plotly es una excelente opción. Plotly es una biblioteca de gráficos de Python que crea gráficos interactivos de calidad de publicación.
Aquí tienes un ejemplo de cómo crear un gráfico de Plotly a partir de un DataFrame de Pandas:
import plotly.express as px
# Cargar tu DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Crear un gráfico de Plotly
fig = px.line(df, x='date', y='count')
fig.show()En este código, primero importamos el módulo Plotly Express. Luego cargamos un DataFrame y creamos un gráfico de línea con la columna 'date' en el eje x y la columna 'count' en el eje y. El comando fig.show() muestra el gráfico interactivo.
Conclusión
Pandas es una herramienta poderosa para el análisis y la visualización de datos en Python. Con sus robustas capacidades de visualización y compatibilidad con otras bibliotecas de visualización como Matplotlib, Seaborn, Plotly y PyGWalker, puedes crear una amplia gama de visualizaciones para obtener información de tus datos. Ya seas un principiante que recién comienza o un científico de datos experimentado, dominar la visualización de Pandas es una habilidad valiosa que mejorará tu flujo de trabajo de análisis de datos.
Preguntas frecuentes
-
¿Qué es Pandas en Python?
- Pandas es una biblioteca de software escrita para el lenguaje de programación Python para la manipulación y análisis de datos. Proporciona estructuras de datos y funciones necesarias para manipular datos estructurados.
-
¿Cómo se utiliza Pandas para la visualización de datos?
- Pandas proporciona visualización de datos permitiendo el uso de su función plot() y varios métodos de trazado para trazar datos directamente de los objetos DataFrame y Series.
-
¿Cuáles son algunas de las bibliotecas de visualización de Pandas más populares?
- Algunas de las bibliotecas más populares para la visualización de datos en Pandas incluyen Matplotlib, Seaborn, Plotly y PyGWalker. Estas bibliotecas proporcionan una variedad de herramientas y funcionalidades para crear gráficos estáticos, animados e interactivos en Python.