La puissance de ChatGPT Code Interpreter (ADA) : créer des visualisations de données sans écrire une seule ligne de code

Pendant longtemps, savoir coder était le principal frein entre des données brutes et des insights exploitables. Avec ChatGPT Code Interpreter, désormais appelé Advanced Data Analysis (ADA), ce frein a beaucoup diminué.
L’intérêt d’ADA est simple : vous importez un fichier, vous décrivez l’analyse ou le graphique que vous voulez obtenir, puis ChatGPT exécute le travail Python derrière l’interface.
Autrement dit, vous disposez dans ChatGPT d’un petit environnement d’analyse avec Python, bibliothèques de visualisation, gestion de fichiers et outils de préparation des données.
À retenir rapidement : ADA est excellent pour des analyses rapides et ponctuelles dans ChatGPT. Mais si votre vrai workflow vit déjà dans Jupyter notebooks, avec un kernel actif, des fichiers locaux et des sessions longues, il est souvent plus naturel d’amener l’agent IA dans cet environnement natif.
- Runcell Science : l'alternative open source à Claude Science pour la recherche
- Empêcher un Mac de se mettre en veille : capot fermé, Codex et Claude Code
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot : quelle stack d’agents IA choisir en 2026 ?
- Comment Claude Code analyse un notebook Jupyter en Data Science : capacités réelles et limites
- Claude Code routines : triggers, cron jobs et automatisation d’agents IA
- Claude Code Desktop : activer le mode Bypass permissions
- Comment Créer Deux Agents Python avec le Protocole A2A de Google - Tutoriel Étape par Étape
- Top 10 bibliothèques de visualisation de données en Python en pleine croissance en 2025
Simplifier la visualisation de données avec ChatGPT Code Interpreter
Dans presque toutes les équipes, transformer les données en visualisations utiles est devenu essentiel. Le workflow classique demandait pourtant :
- d’exporter les données
- d’écrire du Python ou du SQL
- de déboguer des scripts
- de configurer des bibliothèques de graphiques
Pour un profil non technique, cela crée beaucoup de friction avant même d’obtenir un premier graphique exploitable.
C’est là qu’ADA change réellement les choses. Il peut :
- lire des fichiers CSV, Excel, JSON, PDF et d’autres formats courants
- nettoyer et préparer les données automatiquement
- exécuter du Python dans un environnement sandboxé
- générer des graphiques avec Matplotlib, Seaborn ou Plotly
- exporter les résultats en image ou en fichier téléchargeable
Tout cela peut partir d’un simple prompt en langage naturel.
Exemple :
Vous voulez visualiser le chiffre d’affaires par produit sur une période donnée. Habituellement, vous écririez du SQL ou du Python.
Avec ADA, il suffit de demander :
« Crée un diagramme en barres montrant le revenu par produit pour le T1 2024 à partir du fichier que j’ai importé. »
ChatGPT peut alors lire le fichier, préparer les données, créer le graphique, mettre en forme les axes, ajouter les labels et exporter le résultat.

Cela fonctionne non seulement pour les diagrammes en barres, mais aussi pour :
- les courbes
- les nuages de points
- les heatmaps
- les visualisations interactives
- les graphiques statistiques comme les histogrammes, boxplots et courbes de régression
On se rapproche d’un analyste de données personnel disponible à la demande. Pour replacer ChatGPT dans un contexte analytics plus large, vous pouvez aussi lire ce que GPT-4 change pour l’analyse de données.
Si vous aimez ADA, mais voulez ce workflow directement dans Jupyter
ADA réduit une boucle utile à une seule conversation : vous décrivez la tâche, le modèle écrit le code, l’exécute, vous regardez le résultat, puis vous continuez. C’est précisément ce qui plaît dans l’outil.
Mais pour beaucoup d’analystes, de chercheurs et de data scientists, le vrai travail ne se passe pas dans un sandbox cloud séparé. Il se passe dans des notebooks existants, avec un kernel actif, des dépendances projet, des fichiers locaux et parfois des jeux de données sensibles déjà présents dans l’environnement Jupyter.
C’est pour cela que RunCell (opens in a new tab) est particulièrement pertinent ici. RunCell est un agent IA conçu pour Jupyter. Il comprend le contexte du notebook, les DataFrames, les cellules précédentes et l’état d’exécution actuel, ce qui permet de retrouver une expérience proche d’ADA dans un workflow notebook beaucoup plus natif.
RunCell : intégrer un agent IA directement dans votre notebook Jupyter→Dans la pratique, la différence ressemble souvent à ceci :
| Besoin | ADA | RunCell |
|---|---|---|
| Importer un fichier et faire une analyse ponctuelle rapide | Très adapté | Possible, mais ce n’est pas son avantage principal |
| Continuer à travailler avec un notebook, un kernel et des variables déjà chargées | Limité | Mieux adapté |
| Itérer sur des DataFrames, graphiques et cellules dans Jupyter | Indirect | Plus fort |
| Garder le workflow proche d’un environnement notebook local et natif | Moins direct | Plus naturel |
Si votre travail se déroule déjà surtout dans les notebooks, poursuivez avec RunCell pour les workflows Jupyter IA. Si vous comparez des outils plus larges, voyez aussi les 15 meilleurs outils de code IA en 2026.
Comment ChatGPT Code Interpreter a changé l’expérience du code
Avant ADA, il fallait généralement :
- connaître Python
- installer des bibliothèques
- gérer des environnements
- déboguer les erreurs à la main
Désormais, il suffit de décrire le résultat voulu.
ADA peut transformer le langage naturel en code exécutable et gérer :
- le nettoyage de données
- la transformation
- la modélisation statistique
- la régression
- le clustering
- la visualisation
Le tout avec beaucoup moins de configuration manuelle.
Cela réduit l’écart entre compétence technique et intention analytique. Une fois cet écart plus faible, la vraie question devient : voulez-vous tout faire dans ChatGPT, ou amener cette même interface conversationnelle dans l’environnement notebook où votre travail existe déjà ?
Exemples concrets d’usage de ChatGPT Code Interpreter pour la visualisation
Exemple 1 : analyse descriptive et visualisations
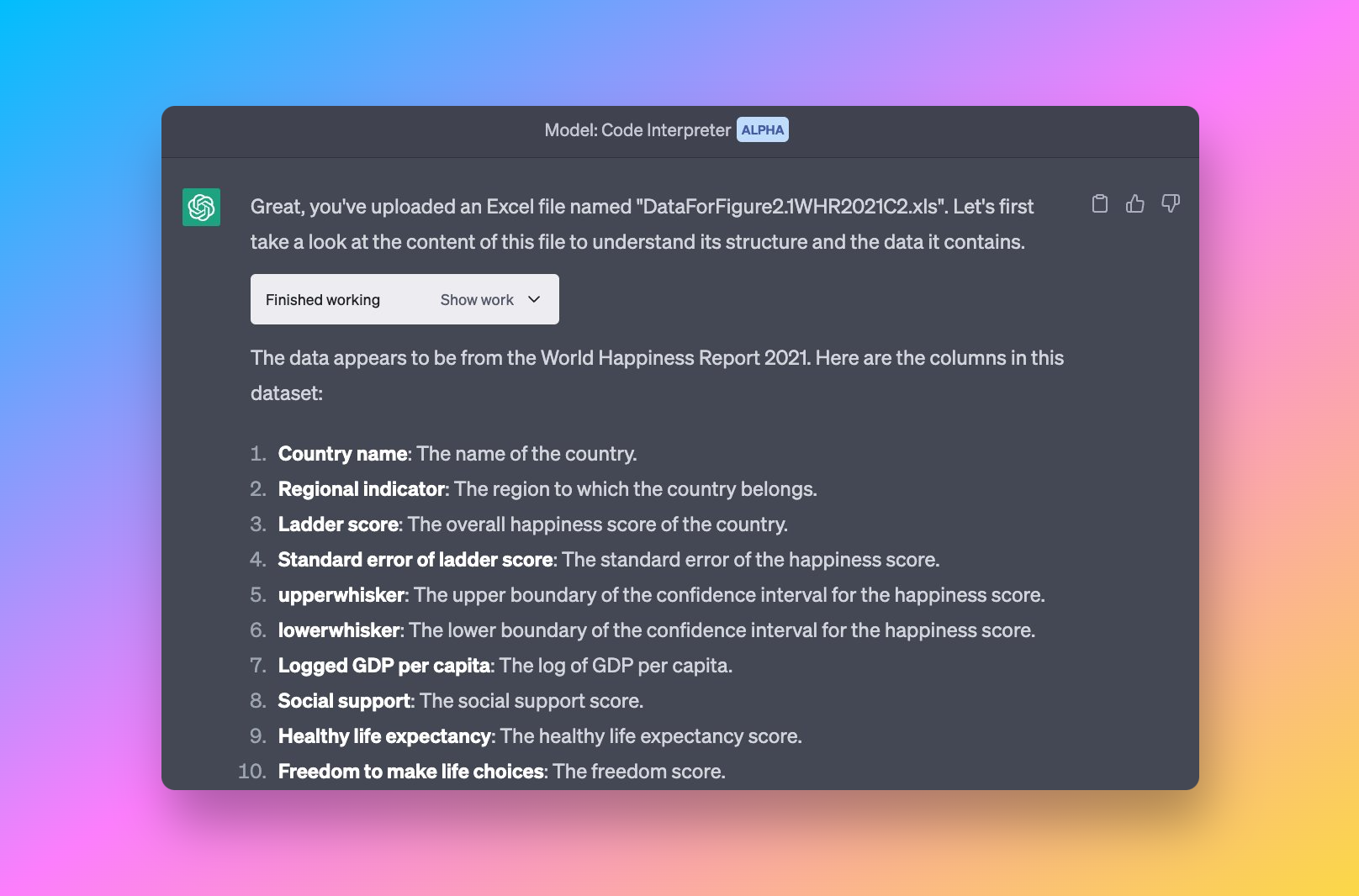
Ethan Mollick a importé un fichier XLS et demandé à ADA :
- « Donne-moi des statistiques descriptives. »
- « Visualise les principaux schémas. »
- « Lance des régressions et diagnostics. »
Le modèle a automatiquement généré :
- des tableaux de synthèse
- des histogrammes
- des nuages de points
- des résultats de régression
- des explications sur les résultats
Cela montre qu’ADA peut gérer un workflow d’analyse en plusieurs étapes à partir du seul langage naturel.
Exemple 2 : analyse de sensibilité et résolution adaptative
Même lorsque l’état de session est perturbé, ADA peut reconstruire la logique de l’analyse. Cela montre sa capacité à :
- raisonner malgré un contexte incomplet
- retrouver des étapes intermédiaires
- continuer l’analyse sans tout recommencer
Cette robustesse compte beaucoup dans les analyses réelles, rarement parfaitement propres.
Exemple 3 : heatmap d’observations d’OVNI
À partir d’un jeu de données brut et désordonné, ADA a pu produire :
- une heatmap
- une visualisation géographique
- une détection des valeurs aberrantes
Le tout à partir d’une seule instruction.
Ensemble, ces exemples montrent comment ADA transforme un workflow analytique complexe en workflow conversationnel.
Comment utiliser ChatGPT Code Interpreter pour la visualisation de données
La prise en main est simple :
- Importez votre dataset : CSV, Excel, JSON, TSV, tableaux PDF ou ZIP.
- Décrivez ce que vous voulez voir.
« Crée un nuage de points prix vs quantité pour chaque catégorie. »
- Laissez ADA parser les données, créer le graphique et exporter le résultat.
- Continuez avec des questions de suivi pour affiner.
Pas de code. Pas de configuration d’environnement. Pas d’allers-retours entre plusieurs outils.
ADA est donc particulièrement utile pour :
- les marketeurs qui examinent des campagnes
- les journalistes qui explorent des données publiques
- les étudiants qui travaillent sur un mémoire ou un projet
- les équipes métier qui passent en revue des indicateurs
- les analystes qui veulent produire des graphiques et rapports plus vite
Si votre travail est davantage orienté reporting ou BI, AWS data visualization et Airtable charts peuvent aussi compléter la lecture.
Cas d’usage fréquents de ChatGPT Code Interpreter
ADA peut aider sur :
✔ Analyse exploratoire de données
- statistiques descriptives
- détection des valeurs manquantes
- heatmaps de corrélation
✔ Visualisation de données
- graphiques avec Matplotlib, Seaborn, Plotly et Altair
- graphiques statistiques
- séries temporelles
✔ Nettoyage de données
- déduplication
- correction des types
- détection des outliers
✔ Tâches de data science
- régression
- clustering
- forecasting
- feature engineering
✔ Automatisation de fichiers
- conversion CSV vers Excel
- fusion de fichiers
- extraction de tableaux depuis des PDF
En pratique, c’est une boîte à outils légère de data science, pilotable en langage naturel.
ChatGPT Code Interpreter et le machine learning
ADA repose sur des modèles capables de :
- interpréter l’intention utilisateur
- générer du code Python
- inspecter les sorties
- corriger des erreurs
- itérer vers un meilleur résultat
Cela crée une boucle de feedback assez proche de la manière dont un analyste humain travaille.
Pour mieux comprendre le contexte technique d’ADA, lisez ce rapport de Nature (opens in a new tab).
La prochaine étape de l’analyse conversationnelle : du sandbox cloud au workflow natif
Des outils comme ADA réunissent plusieurs idées :
- no-code
- low-code
- programmation traditionnelle
- raisonnement assisté par IA
Au lieu d’écrire le code manuellement, on décrit la tâche et le modèle écrit puis exécute le code.
Cette évolution accélère le mouvement plus large du no-code et de l’analytics assisté par IA.
Mais le changement le plus intéressant aujourd’hui, c’est que beaucoup d’utilisateurs ne veulent plus que l’analyse IA reste enfermée dans une session cloud séparée. Ils veulent l’agent là où le vrai travail existe déjà : notebooks Jupyter, fichiers projet, répertoires de données locaux et sessions notebook en cours.
C’est là que les outils notebook-native comme RunCell deviennent particulièrement convaincants. ADA a montré que l’interface “langage naturel + exécution de code” fonctionne. RunCell pousse cette interface dans un workflow Jupyter plus natif, souvent mieux adapté à l’analyse itérative, au développement local et aux données sensibles.
Si vous comparez surtout les outils notebook, consultez aussi Top 10 data science notebooks.
Related Guides
- RunCell pour les workflows Jupyter IA
- Les 15 meilleurs outils de code IA en 2026
- Ce que GPT-4 change pour l’analyse de données
- AWS data visualization
- Top 10 data science notebooks
FAQs
Qu’est-ce que ChatGPT Code Interpreter (ADA) ?
C’est un environnement d’exécution Python dans ChatGPT qui permet d’analyser des fichiers, d’effectuer des calculs et de générer des visualisations à partir de prompts en langage naturel.
Comment l’utiliser ?
Importez un fichier, décrivez l’analyse souhaitée, puis ChatGPT peut renvoyer graphiques, résumés et résultats d’exécution.
Quels langages sont pris en charge ?
Principalement Python, avec les bibliothèques usuelles comme Pandas, Matplotlib, Seaborn, Plotly, NumPy et Scikit-Learn.
Est-ce gratuit ?
Généralement non. Advanced Data Analysis est en général inclus dans des offres payantes de ChatGPT prenant en charge l’analyse de fichiers. Vérifiez les conditions actuelles d’OpenAI pour le détail exact.
Que faire si ADA n’est pas disponible pour moi ?
Si vous voulez surtout une analyse ponctuelle rapide dans ChatGPT, ADA reste l’option la plus directe. Mais si vous voulez un agent IA dans votre workflow Jupyter existant, RunCell (opens in a new tab) est l’alternative la plus pertinente, car il travaille directement avec le contexte du notebook, les cellules et l’état local du workflow.
Conclusion
ChatGPT Code Interpreter (ADA) a changé la manière dont beaucoup de personnes abordent l’analyse de données. En combinant langage naturel et exécution Python, il rend la visualisation et l’analyse beaucoup plus accessibles.
Pour des analyses rapides dans ChatGPT, cela reste l’un des outils les plus simples à prendre en main. Mais si votre workflow central vit déjà dans Jupyter, un agent IA notebook-native comme RunCell sera souvent l’étape suivante la plus naturelle.