Top 10 Cahiers de Science des Données en 2024
Les logiciels de science des données basés sur des cahiers gagnent en popularité ces jours-ci. Ils sont plus légers et flexibles pour les équipes de science des données que les outils de BI traditionnels. Ceci est particulièrement bénéfique pour les startups en phase initiale et les équipes dynamiques, car les cahiers de science des données sont mieux adaptés pour gérer des données brutes désordonnées et non organisées.
Dans cet article, nous explorerons les 10 meilleurs cahiers de science des données en 2024, en considérant leurs fonctionnalités, limitations et offres uniques.
1. Jupyter Notebook/Lab
Jupyter Notebook est un incontournable dans la communauté de la science des données depuis des années, et son évolution en JupyterLab a encore amélioré son utilité.
- Application web open-source: Jupyter est un projet open-source, ce qui le rend accessible à tous.
- Supporte plusieurs langages de programmation: Bien qu'il soit principalement utilisé pour Python, Jupyter supporte d'autres langages comme R et Julia à travers divers noyaux.
- Largement utilisé dans la communauté de la science des données: Sa simplicité et son extensibilité en font un choix incontournable pour les scientifiques des données.
- Tous les packages peuvent être utilisés sans limitation: Avec un contrôle total sur votre environnement, vous pouvez installer et utiliser n'importe quel package Python.
Jupyter reste un choix solide pour ceux qui ont besoin d'un environnement robuste et personnalisable qui s'intègre bien avec une variété d'outils et de sources de données.
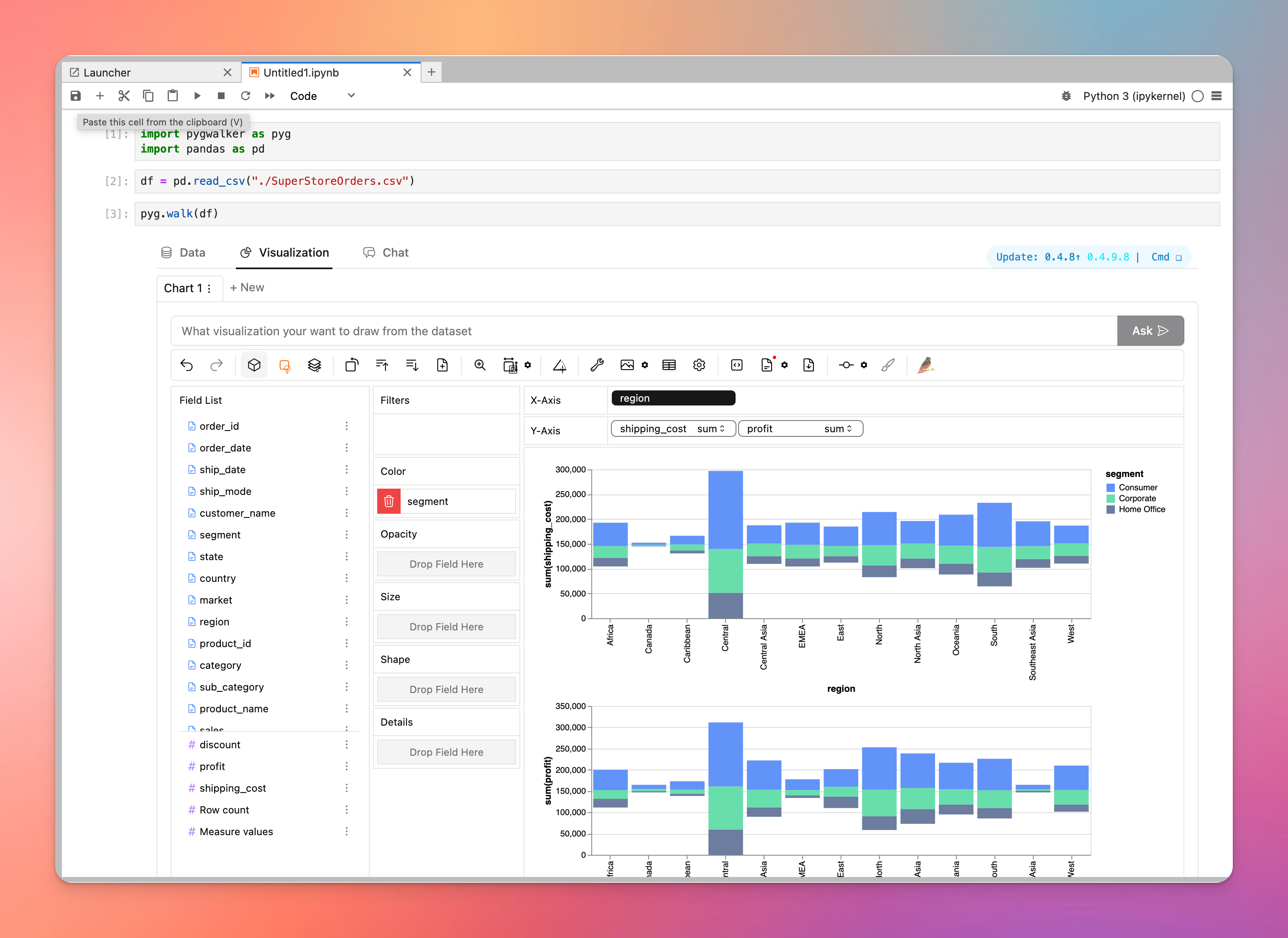
jupyter with pygwalker for visualization
Bien que la visualisation des données dans Python et Jupyter reste complexe, de nouvelles bibliothèques open-source comme PyGWalker ont simplifié le processus. PyGWalker permet la création facile de visualisations de données par des opérations simples de glisser-déposer. Cette capacité puissante fait de Jupyter un choix de premier ordre pour la visualisation interactive, surpassant les cahiers commerciaux avec leurs cellules de graphique.
2. Google Colab
Google Colab a révolutionné le travail des scientifiques des données en offrant un environnement de cahier Jupyter basé sur le cloud, avec des avantages supplémentaires.
- Environnement de cahier Jupyter basé sur le cloud: Aucune installation n'est requise; tout fonctionne dans le cloud.
- Accès gratuit au GPU et TPU: Google offre un accès gratuit à des ressources de calcul puissantes, facilitant ainsi l'entraînement de grands modèles.
- Partage et collaboration faciles: Google Colab permet un partage facile des notebooks avec d'autres, similaire à la façon dont vous partagez un Google Doc.
- La plupart des packages peuvent être utilisés sans limitation: Les bibliothèques populaires, y compris l'outil de visualisation des données émergent
pygwalker, sont entièrement supportées.
Google Colab est idéal pour ceux qui ont besoin de ressources de calcul puissantes sans la gestion du matériel local.
3. Databricks Notebook
Databricks s'est fait un nom en intégrant Apache Spark dans son environnement de cahier, s’adressant aux praticiens du big data.
- Intégré avec Apache Spark: L’intégration étroite de Databricks avec Spark en fait une puissance pour le traitement des big data.
- Supporte le traitement des big data: Gérer d'énormes ensembles de données avec facilité, en tirant parti des capacités de calcul distribué de Spark.
- Fonctionnalités collaboratives pour les projets d'équipe: Databricks est conçu pour la collaboration, permettant aux équipes de travailler ensemble sur des projets à grande échelle.
Databricks est le cahier de choix pour les organisations traitant de vastes quantités de données, grâce à son intégration Spark et ses fonctionnalités robustes de collaboration.
4. Hex.tech
Hex.tech est un acteur relativement nouveau dans l'espace des cahiers de science des données, offrant un mélange unique de support SQL et Python avec des outils de visualisation intégrés.
- Plateforme de science des données avec interface en cahier: La plateforme d’Hex.tech est conçue pour les scientifiques des données qui doivent combiner SQL et Python dans leurs flux de travail.
- Support SQL et Python: Connexion entre les requêtes SQL et le code Python dans le même notebook.
- Outils de visualisation intégrés: Hex.tech offre des outils de visualisation simples, prêts à l'emploi, facilitant l'exploration visuelle des données.
- Bien que la fonctionnalité de cellule de graphique soit impressionnante, elle présente des limitations notables pour la visualisation, en particulier en ce qui concerne une exploration plus interactive.
Hex.tech est parfait pour les scientifiques des données qui travaillent fréquemment avec SQL et Python, offrant un environnement intégré adapté à ces besoins.
5. Deepnote
Deepnote offre une vision moderne du cahier de science des données, avec des fonctionnalités conçues pour une collaboration en temps réel et un déploiement facile.
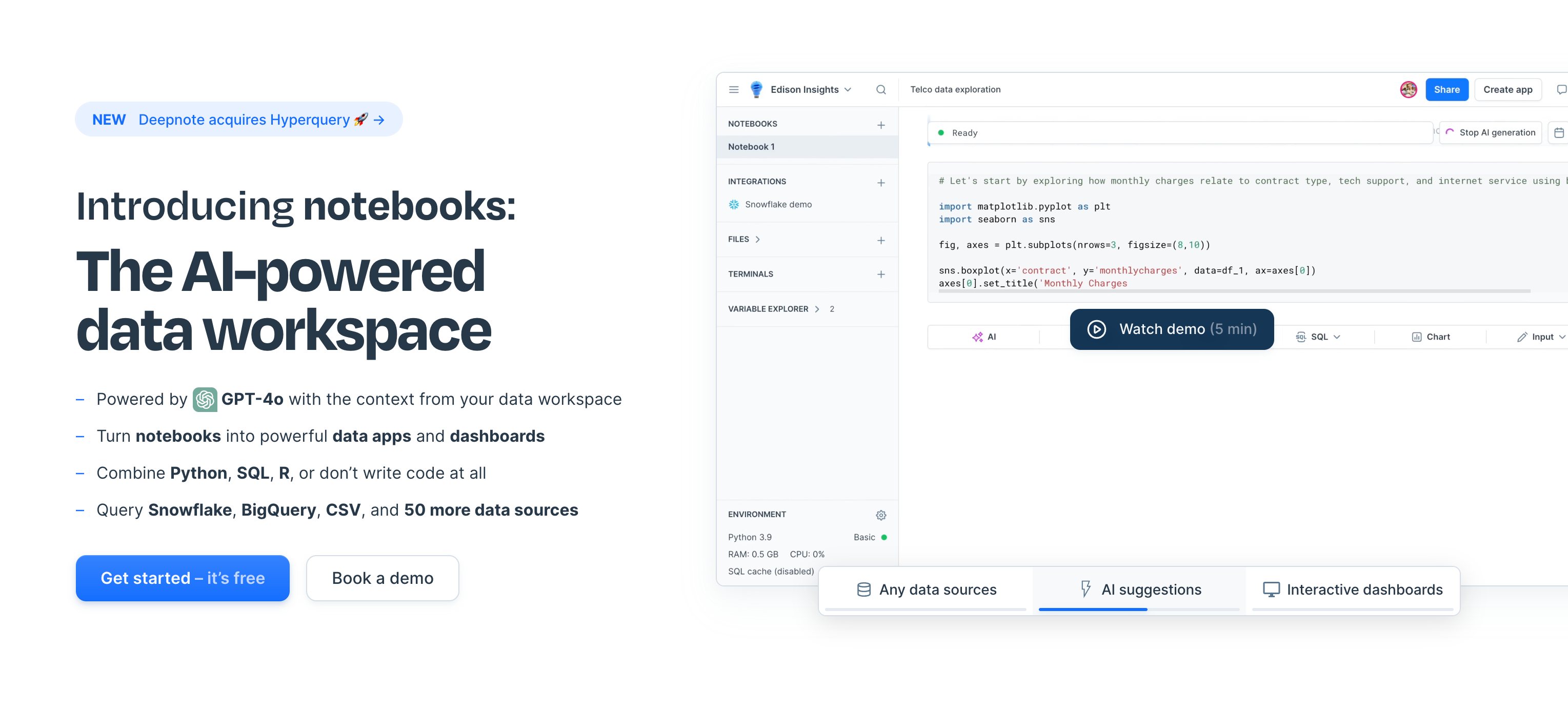
- Collaboration en temps réel: Travaillez avec votre équipe en temps réel, voyant les modifications des autres à mesure qu'elles se produisent.
- Intégration du contrôle de version: Gestionnez l'historique de votre cahier et collaborez plus efficacement avec le contrôle de version intégré.
- Déploiement facile des modèles de machine learning: Déployez des modèles directement depuis Deepnote, simplifiant la transition du développement à la production.
Deepnote est un excellent choix pour les équipes qui ont besoin de collaborer étroitement et de déployer des modèles de machine learning rapidement.
6. Kaggle Notebooks
Kaggle, connu pour ses compétitions de science des données, offre un environnement de cahiers qui est étroitement intégré à sa plateforme.
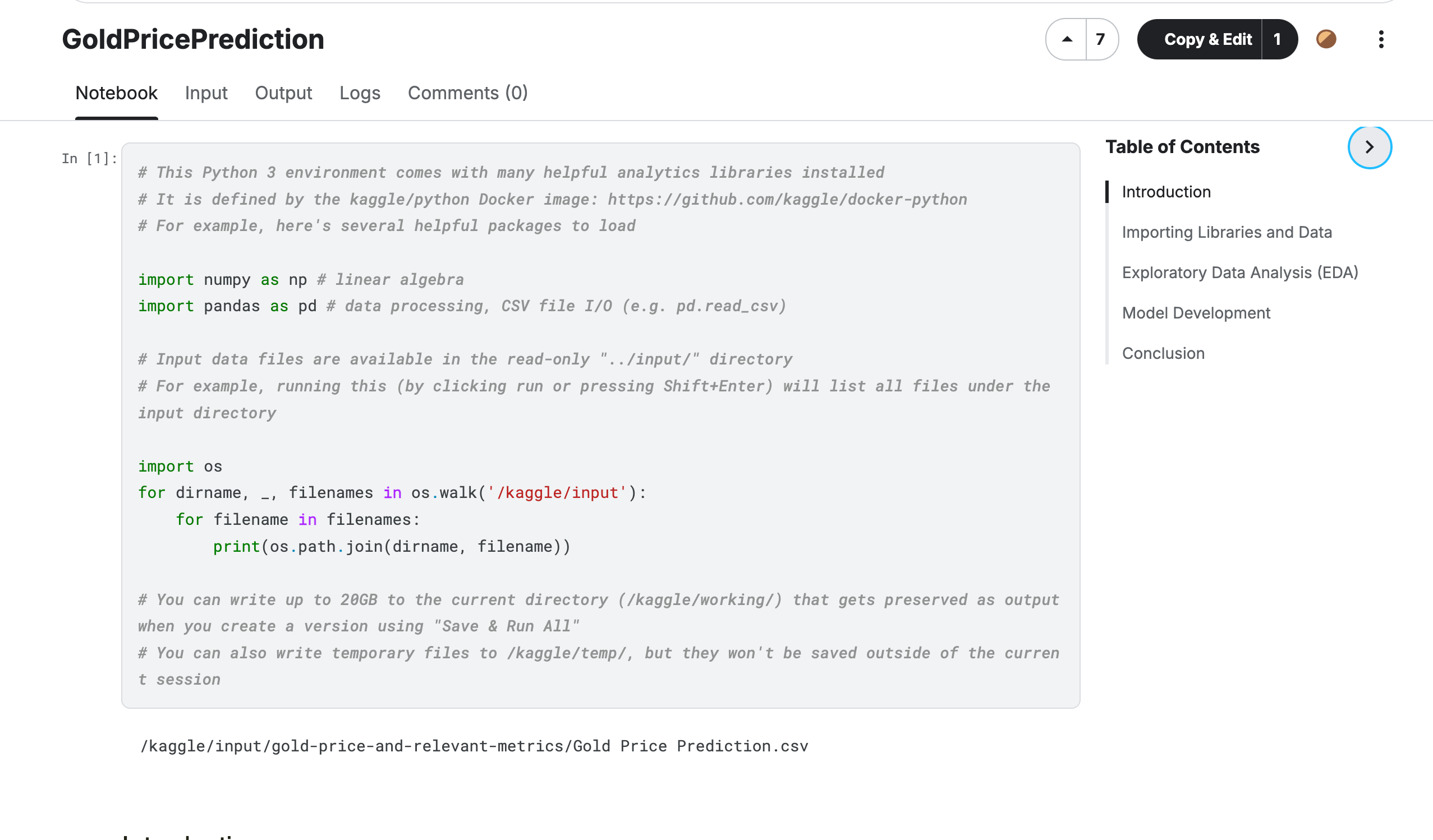
- Accès aux ensembles de données publics: Les cahiers de Kaggle offrent un accès facile à un vaste éventail d'ensembles de données publics.
- Plateforme axée sur la communauté: Apprenez des autres en explorant une riche collection de cahiers publiés par la communauté.
- Compétitions et ressources d'apprentissage: Participez à des compétitions et accédez à des tutoriels directement depuis l'environnement des cahiers.
- Supporte
pygwalker: Vous pouvez utiliserpygwalkeret d'autres bibliothèques populaires dans les cahiers de Kaggle.
Les cahiers Kaggle sont idéaux pour ceux qui cherchent à apprendre, à concourir, ou à explorer des ensembles de données publics avec un minimum de configuration.
7. Azure Notebooks
Azure Notebooks est l'incursion de Microsoft dans les cahiers Jupyter basés sur le cloud, offrant une intégration étroite avec les services Azure.
- Cahiers Jupyter basés sur le cloud de Microsoft: Profitez de la puissance de l'infrastructure cloud d'Azure avec une interface Jupyter familière.
- Intégration avec les services Azure: Connectez facilement aux bases de données, au stockage et aux services de machine learning d'Azure.
- Ressources de calcul gratuites: Azure offre des ressources gratuites pour démarrer, ce qui le rend accessible aux débutants.
Les cahiers Azure sont une excellente option pour ceux déjà investis dans l'écosystème Microsoft, mais la plateforme azure reste super complexe pour les utilisateurs.
8. Amazon SageMaker Studio
Amazon SageMaker Studio est un environnement de développement intégré pour le machine learning, conçu pour rationaliser tout le cycle de vie du ML.
- Environnement de développement intégré pour le ML: SageMaker Studio fournit un environnement complet pour développer, entraîner et déployer des modèles de ML.
- Mauvaise expérience utilisateur : Comme d'autres produits AWS, Amazon SageMaker Studio manque de convivialité. Pour les petites équipes cherchant à travailler rapidement et efficacement, il peut ne pas être le choix idéal.
- Outils intégrés pour l'entraînement et le déploiement de modèles: SageMaker Studio simplifie le processus d'entraînement et de déploiement des modèles de machine learning à grande échelle.
Pour les entreprises utilisant déjà AWS, SageMaker Studio est un choix évident offrant une intégration profonde avec d'autres services AWS. Cependant, pour les petites équipes, il pourrait ne pas valoir l'investissement.
9. Snowflake Notebooks
Snowflake, connu pour sa plateforme de données cloud, a introduit une nouvelle fonctionnalité de cahier qui permet une interaction directe avec les données stockées dans Snowflake.
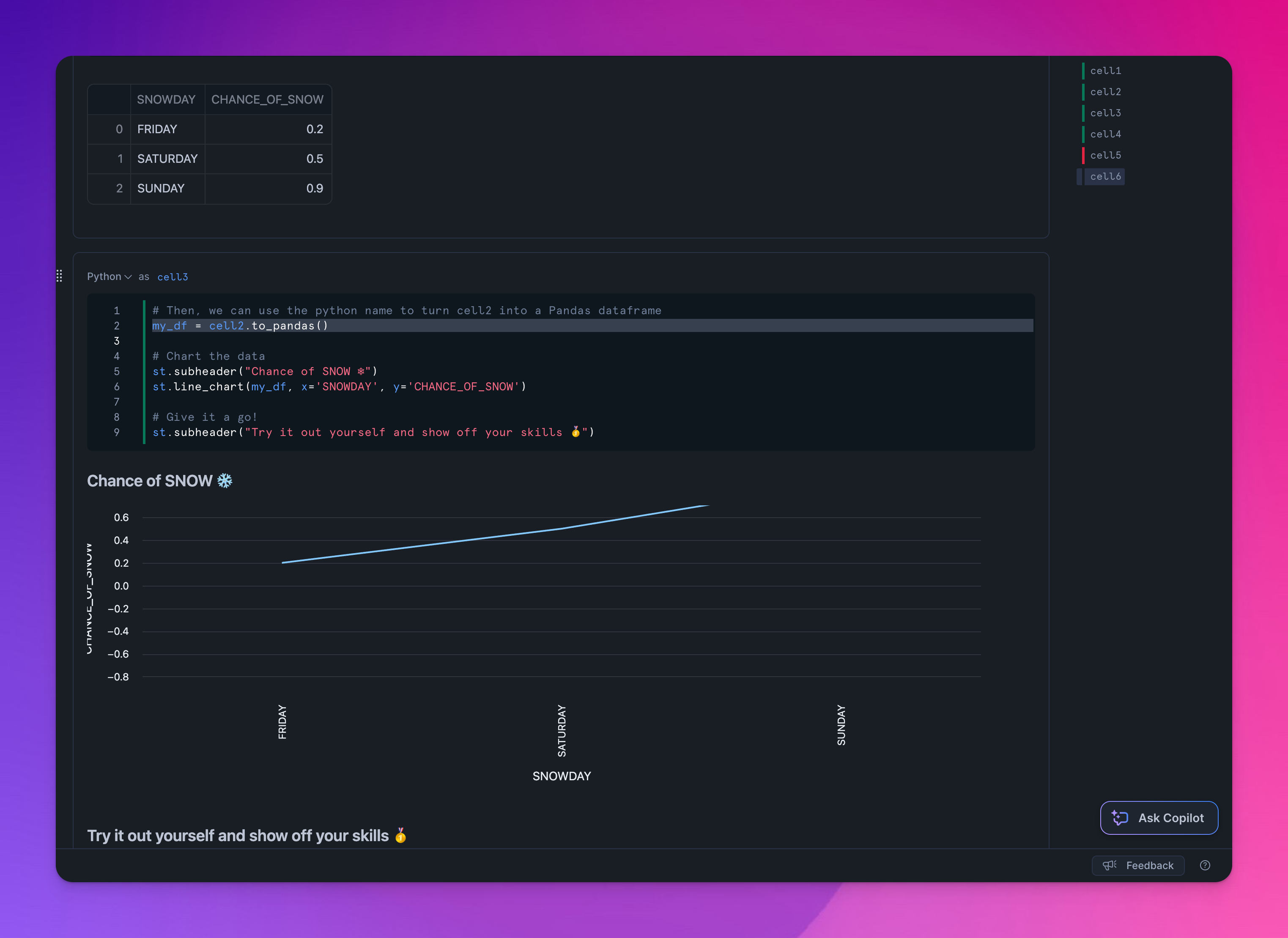
- Interagir directement avec les données dans Snowflake: Exécutez des requêtes SQL et du code Python directement dans l'environnement Snowflake.
- Supporte SQL, Python, Markdown: Le cahier supporte plusieurs langages, le rendant polyvalent pour différentes tâches.
- Utilisable avec Streamlit: Intégrez des applications Streamlit directement dans une cellule de cahier pour créer des tableaux de bord interactifs.
- Problème : limitations des packages: Les utilisateurs ne peuvent pas installer de packages Python supplémentaires ou utiliser Conda, ce qui peut être restrictif.
Les cahiers Snowflake sont parfaits pour les utilisateurs qui travaillent intensivement dans l'écosystème Snowflake, bien que les limitations sur l'installation des packages puissent être un inconvénient pour certains.
10. Zeppelin
Zeppelin est un cahier open-source qui supporte une variété d'interprètes, en faisant un outil polyvalent pour les scientifiques des données.
- Support pour plusieurs interprètes: Zeppelin supporte SQL, Scala, Python et plus, ce qui en fait un choix flexible pour les projets multi-langages.
- Options de visualisation intégrées: Zeppelin inclut une gamme d'outils de visualisation, aidant les utilisateurs à explorer visuellement leurs données.
- Intégration avec des outils de big data: Zeppelin s'intègre bien avec des outils de big data comme Hadoop et Spark, le rendant adapté au traitement de données à grande échelle.
Zeppelin est un bon choix pour ceux qui ont besoin d'un environnement multi-langages avec des capacités de big data, surtout dans les projets open-source.
Caractéristiques Clés à Comparer
Lors du choix d'un cahier de science des données, considérez les caractéristiques clés suivantes :
- Facilité d'utilisation: L'interface est-elle intuitive ? Est-il facile à configurer et à démarrer ?
- Capacités de collaboration: Le cahier supporte-t-il la collaboration en temps réel ? Comment s'intègre-t-il avec les systèmes de contrôle de version ?
- Intégration avec les sources de données et les outils: Pouvez-vous facilement vous connecter aux bases de données, services cloud, ou autres outils dans votre flux de travail ?
- Ressources de calcul disponibles: Le cahier offre-t-il un accès aux GPU, TPU, ou instances de grande mémoire pour les calculs lourds ?
- Capacités de visualisation: Les outils de visualisation intégrés sont-ils robustes et flexibles ?
- Support pour différents langages de programmation: Le cahier supporte-t-il les langages de programmation dont vous avez besoin pour votre travail ?
- Coût et modèles de tarification: Quels sont les coûts associés à l'utilisation du cahier, et sont-ils alignés avec votre budget ?
Basé sur l'article fourni et des informations supplémentaires, voici un tableau comparatif des 10 meilleurs cahiers de science des données en 2024. Ce tableau vise à vous aider à décider quel logiciel de cahier convient le mieux à vos besoins.
Tableau Comparatif des 10 Meilleurs Cahiers de Science des Données
| Logiciel de Cahier | Fonctionnalités Clés | Avantages | Inconvénients | Mieux Adapté Pour |
|---|---|---|---|---|
| Jupyter Notebook/Lab | - Open-source - Supporte plusieurs langages - Accès complet aux packages | - Hautement personnalisable - Support communautaire étendu - S’intègre avec de nombreux outils | - Nécessite une installation locale (sauf utilisation d'une version hébergée) - Moins de fonctionnalités de collaboration | Individus et équipes ayant besoin d’un environnement robuste et personnalisable |
| Google Colab | - Environnement Jupyter basé sur le cloud - Accès gratuit au GPU/TPU - Partage facile | - Pas d’installation nécessaire - Ressources de calcul puissantes - Supporte la plupart des packages | - Durée des sessions limitée - Nécessite une connexion Internet | Utilisateurs needing powerful resources without hardware investment |
| Databricks Notebook | - Intégré avec Apache Spark - Traitement des big data - Fonctionnalités de collaboration | - Gère de vastes ensembles de données - Collaboration en temps réel - Calcul évolutif | - Peut être complexe pour les débutants - Les coûts peuvent s'accumuler pour les grands clusters | Organisations dealing with big data and needing team collaboration |
| Hex.tech | - Combine SQL et Python - Visualisation intégrée - Interface de cahier | - Intégration transparente SQL-Python - Exploration des données facile - Interface moderne | - Visualisation avancée limitée - Peut manquer de soutien pour certains packages | Data scientists working with both SQL and Python workflows |
| Deepnote | - Collaboration en temps réel - Intégration du contrôle de version - Déploiement facile des modèles de ML | - Collaboration en équipe - Versionnement intégré - Flux de travail ML simplifié | - Plateforme relativement nouvelle - Peut manquer de ressources communautaires | Teams needing collaborative features and quick ML deployment |
| Kaggle Notebooks | - Accès aux ensembles de données publics - Plateforme communautaire - Intégration des compétitions | - Ressources d'apprentissage riches - Partage et fork des cahiers facile - Supporte des bibliothèques populaires | - Limité à l’environnement de Kaggle - Moins de contrôle sur les ressources de calcul | Learners, competitors, and those exploring public datasets |
| Azure Notebooks | - Cahiers Jupyter basés sur le cloud - Intégration des services Azure - Ressources gratuites pour démarrer | - Scalable avec Azure - Bon pour les utilisateurs de l'écosystème Microsoft - Pas de configuration locale nécessaire | - Complexe pour les nouveaux utilisateurs - Les coûts peuvent augmenter avec l'utilisation | Utilisateurs déjà investis dans les services Microsoft Azure |
| Amazon SageMaker Studio | - Environnement ML intégré - Outils d’entraînement et de déploiement de modèles - Intégration AWS | - Outils complets pour le ML - Infrastructure évolutive - Avantages de l'écosystème AWS | - Courbe d'apprentissage abrupte - Expérience utilisateur complexe - Coûts potentiellement élevés | Enterprises using AWS needing end-to-end ML solutions |
| Snowflake Notebooks | - Interaction directe avec les données Snowflake |