Explorer les données Netflix avec PyGWalker
Netflix se distingue comme une plateforme de premier plan pour les films et les séries télévisées. Avec une bibliothèque en constante expansion, comprendre les tendances et les schémas de son contenu devient crucial pour les analystes, les cinéastes et même les spectateurs. Dans ce notebook, nous plongerons profondément dans le jeu de données Netflix en utilisant la bibliothèque PyGWalker, un puissant outil de visualisation et d'exploration des données.
Qu'est-ce que PyGWalker ?
PyGWalker (opens in a new tab) est une bibliothèque Python conçue pour simplifier le processus de visualisation des données. Il permet aux utilisateurs de créer des graphiques interactifs avec un code minimal, ce qui facilite la découverte d'informations et de schémas dans les jeux de données.

En utilisant PyGWalker, nous pouvons générer des visualisations instructives qui offrent une meilleure compréhension de l'univers du contenu Netflix.
Étapes pour explorer les données Netflix avec PyGWalker
Configuration de l'environnement
Pour commencer, nous devons nous assurer que notre environnement est prêt pour l'analyse. Cela implique d'installer la bibliothèque PyGWalker et d'importer les packages Python nécessaires.
!pip install pygwalker -q --preimport pandas as pd
import pygwalker as pyg
df = pd.read_csv("/kaggle/input/netflix-shows/netflix_titles.csv")Chargement du jeu de données Netflix et prétraitement
Notre première tâche est de charger le jeu de données Netflix. Une fois chargé, nous le prétraiterons pour faciliter notre analyse ultérieure. Ce prétraitement consiste à :
- Convertir la colonne "date_added" au format datetime.
- Extraire l'année et le mois de la colonne "date_added".
- Nettoyer la colonne "duration" pour représenter soit la durée totale en minutes pour les films, soit le nombre de saisons pour les séries télévisées.
- Filtrer les données post-2019.
df["date_added"] = pd.to_datetime(df["date_added"])
df["date_added_year"] = df["date_added"].dt.year.fillna(0).astype(int)
df["date_added_month"] = df["date_added"].dt.month.fillna(0).astype(int)
df["duration"] = df["duration"].fillna("0").str.split(" ").str[0].astype(int)
df = df[df["date_added_year"] <= 2019]
df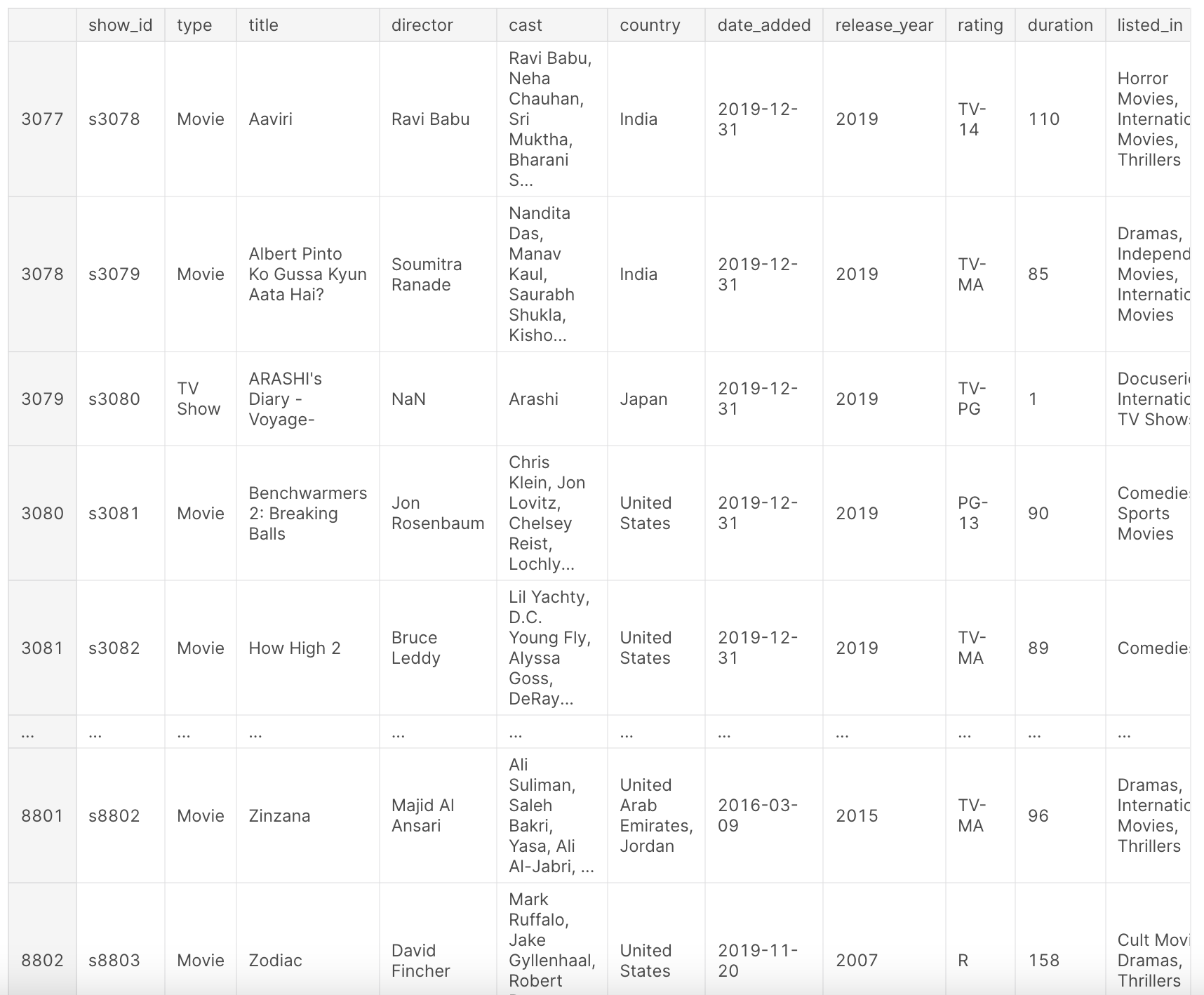
Aperçu du jeu de données Netflix
Après le prétraitement ci-dessus, notre jeu de données df offre une vue complète des titres Netflix. Il contient des informations telles que le type de contenu (film ou série télévisée), le titre, le réalisateur, la distribution, le pays de production, la date d'ajout à Netflix, l'année de sortie, la classification, la durée, le genre et une brève description.
Ce jeu de données offre un aperçu de l'univers du contenu Netflix jusqu'à l'année 2019, ce qui nous permet d'analyser les tendances, les préférences et les schémas de croissance au fil des années. Jetez un œil aux colonnes suivantes :
show_id: Identifiant unique pour chaque film/série téléviséetype: Identificateur pour Film ou Série téléviséetitle: Titre du film/série téléviséedirector: Réalisateur du filmcast: Acteurs impliqués dans le film/la série téléviséecountry: Pays où le film/la série télévisée a été produitdate_added: Date d'ajout sur Netflixrelease_year: Année de sortie réelle du film/de la série téléviséerating: Classification TV du film/de la série téléviséeduration: Durée totale - en minutes ou en nombre de saisonslisted_in: Genredescription: Brève description du film/de la série télévisée
Visualiser les données Netflix avec PyGWalker
Maintenant, passons à la partie excitante : les visualisations. Avec PyGWalker, nous allons générer des visualisations interactives pour découvrir des informations à partir de notre jeu de données.
1. Aperçu général des données Netflix
Ici, nous initialisons un "walker" pour notre jeu de données principal. Cela nous permettra de générer une série de graphiques en fonction des spécifications enregistrées dans "0.json".
walker0 = pyg.walk(df, spec="0.json", use_preview=True)
Vous pouvez explorer ce jeu de données de manière interactive avec une version en ligne de PyGWalker ici (opens in a new tab).
walker0.display_chart("Graphique 1", title="Type de contenu sur Netflix")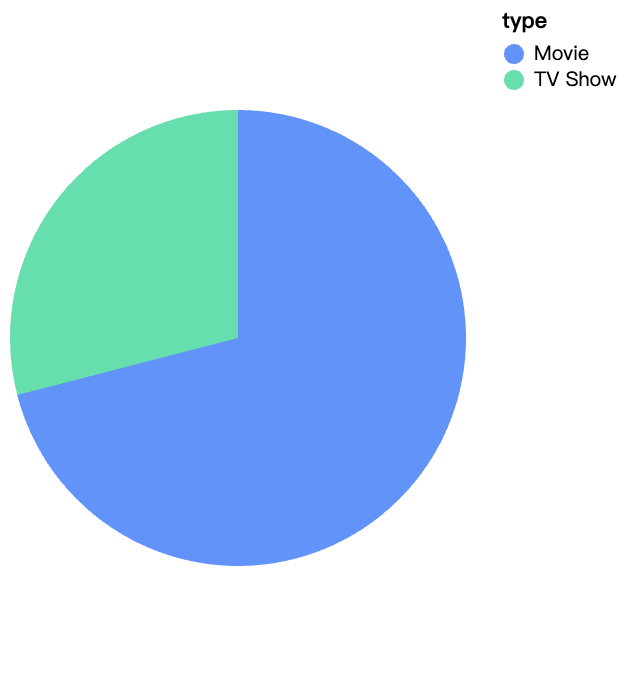
walker0.display_chart("Graphique 2", title="Contenu ajouté au fil des années", desc="Le nombre de films sur Netflix augmente beaucoup plus rapidement que les séries télévisées, le contenu cinématographique a considérablement augmenté après 2016.")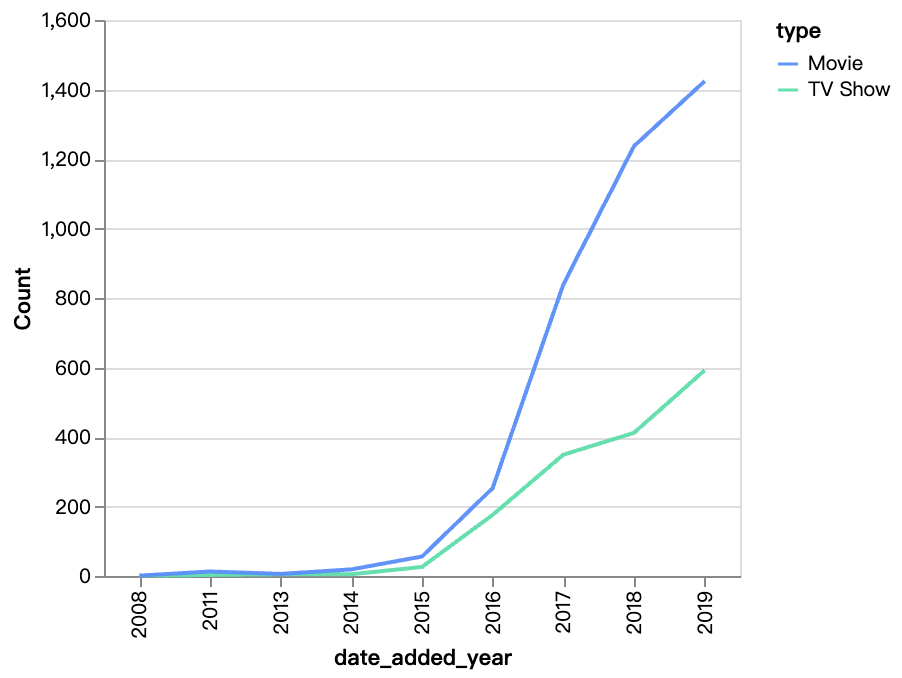
walker0.display_chart("Graphique 3", title="Sortie de contenu au fil des années")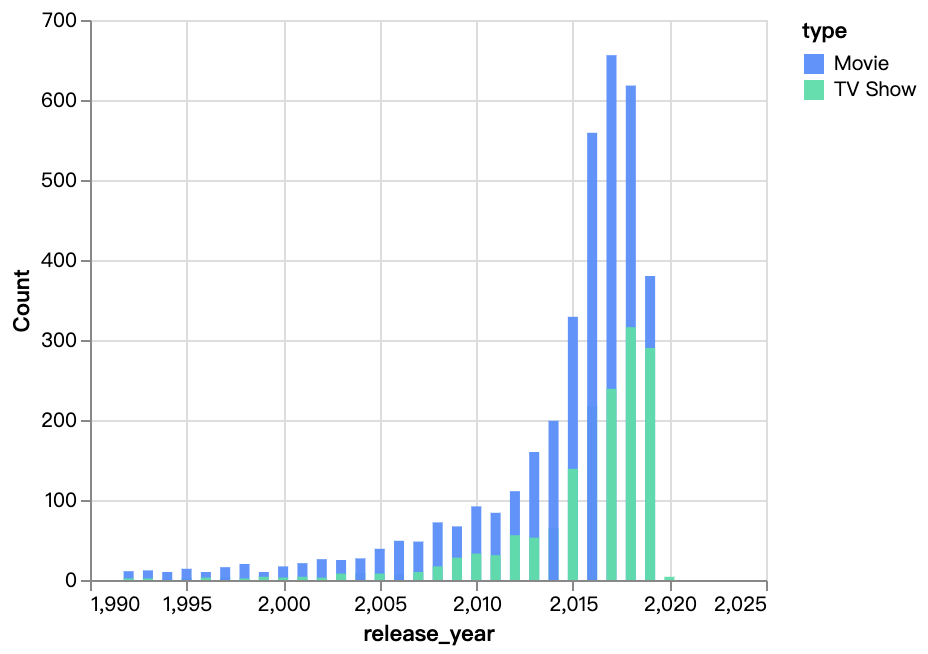
walker0.display_chart("Graphique 4", title="Contenu ajouté par mois", desc="")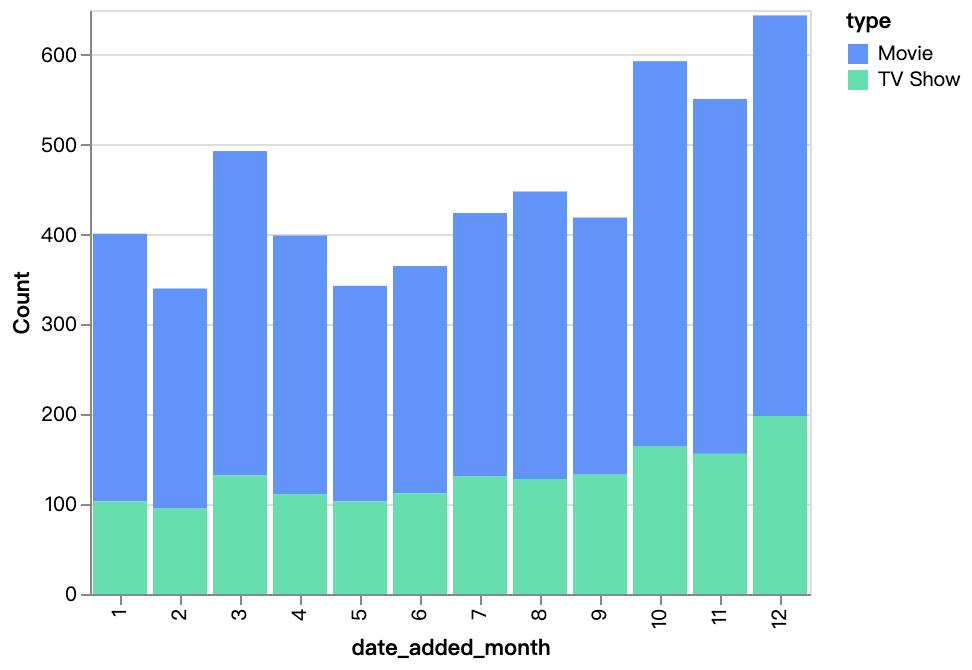
walker0.display_chart("Graphique 5", title="Contenu ajouté au fil des années selon la classification", desc="TV-MA, TV-14 sont les classifications de la plupart du contenu de Netflix, et le contenu classé R augmente également d'année en année")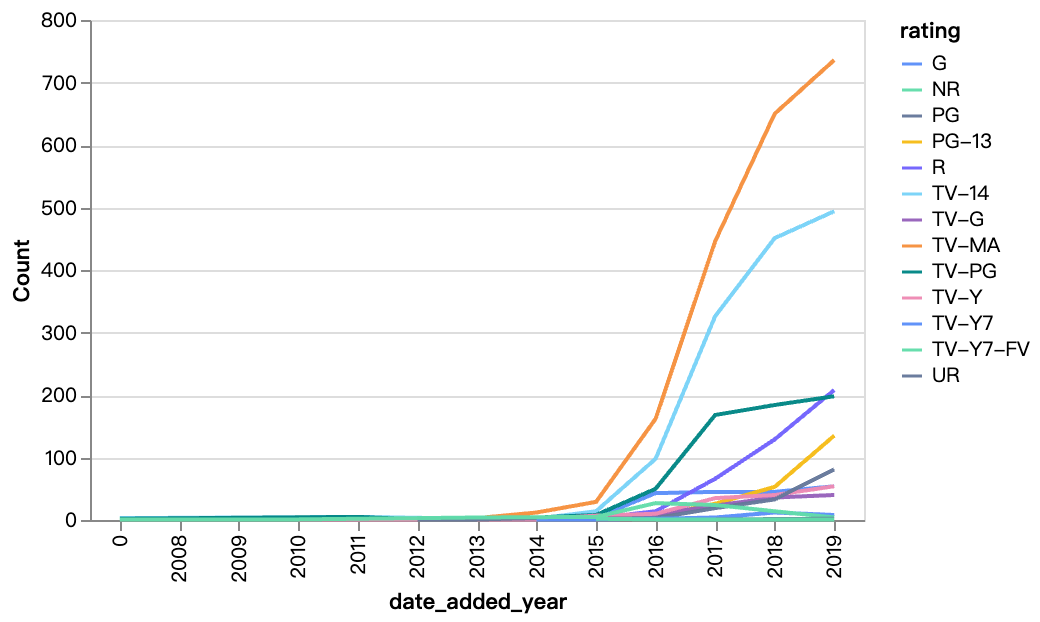
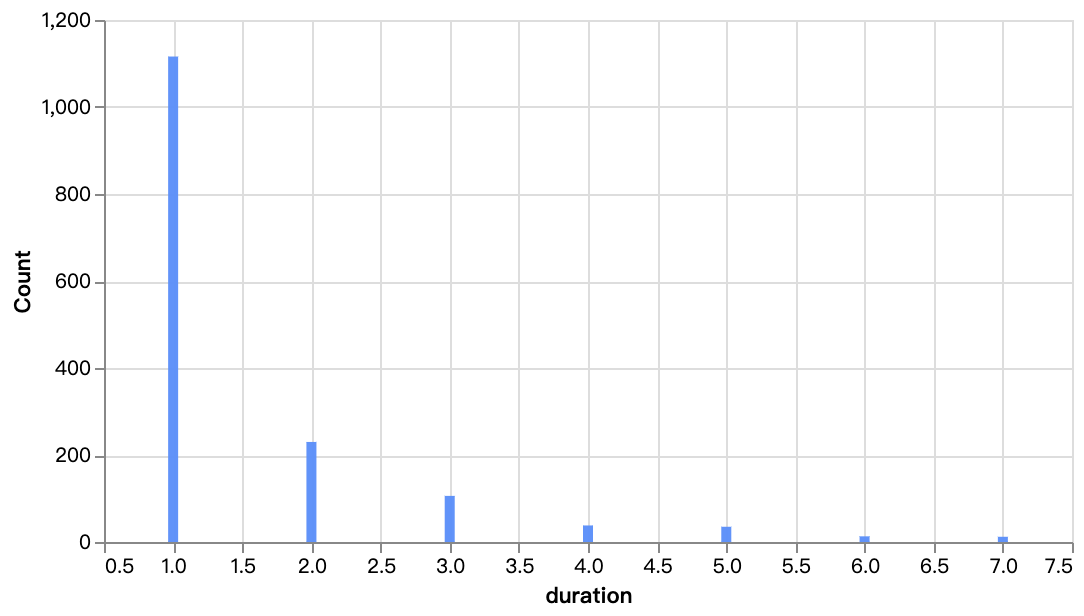
walker0.display_chart("Graphique 6", title="Distribution de la durée des films", desc="Principalement concentrée entre 90 et 110 minutes")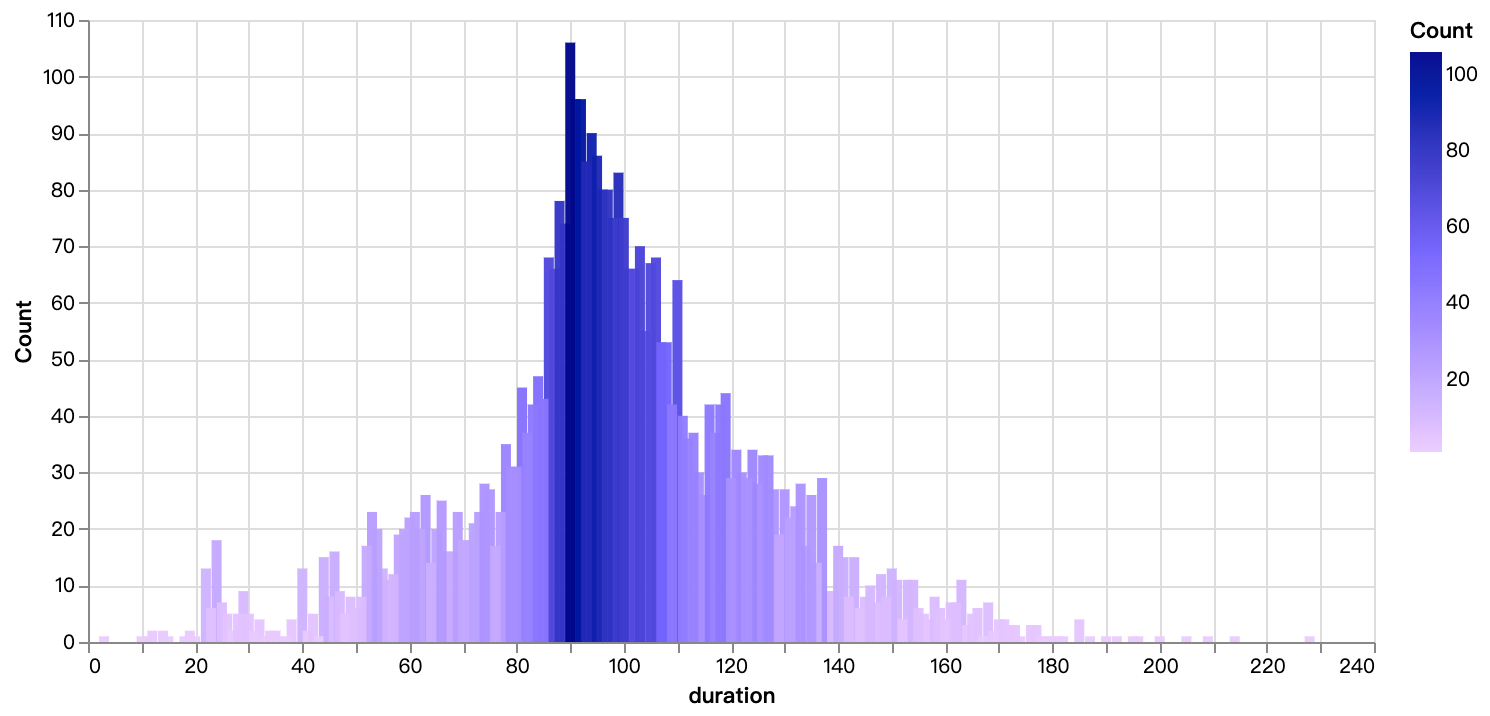
walker0.display_chart("Graphique 7", title="Distribution des saisons de séries télévisées")
### 2. Analyse spécifique par pays des données Netflix
Dans ce segment, nous analysons le contenu par pays. En divisant et en restructurant la colonne des pays, nous pouvons analyser la répartition du contenu dans différents pays.
```python copy
country_df = df["country"].str.split(",", expand=True).stack().reset_index(level=1, drop=True).to_frame('country')
country_df["country"] = country_df["country"].str.strip()
walker1 = pyg.walk(country_df, spec="1.json", use_preview=True)Vous pouvez essayer PyGWalker User Interface facilement ici (opens in a new tab)
walker1.display_chart("Chart 1", title="Pays avec le plus de contenu")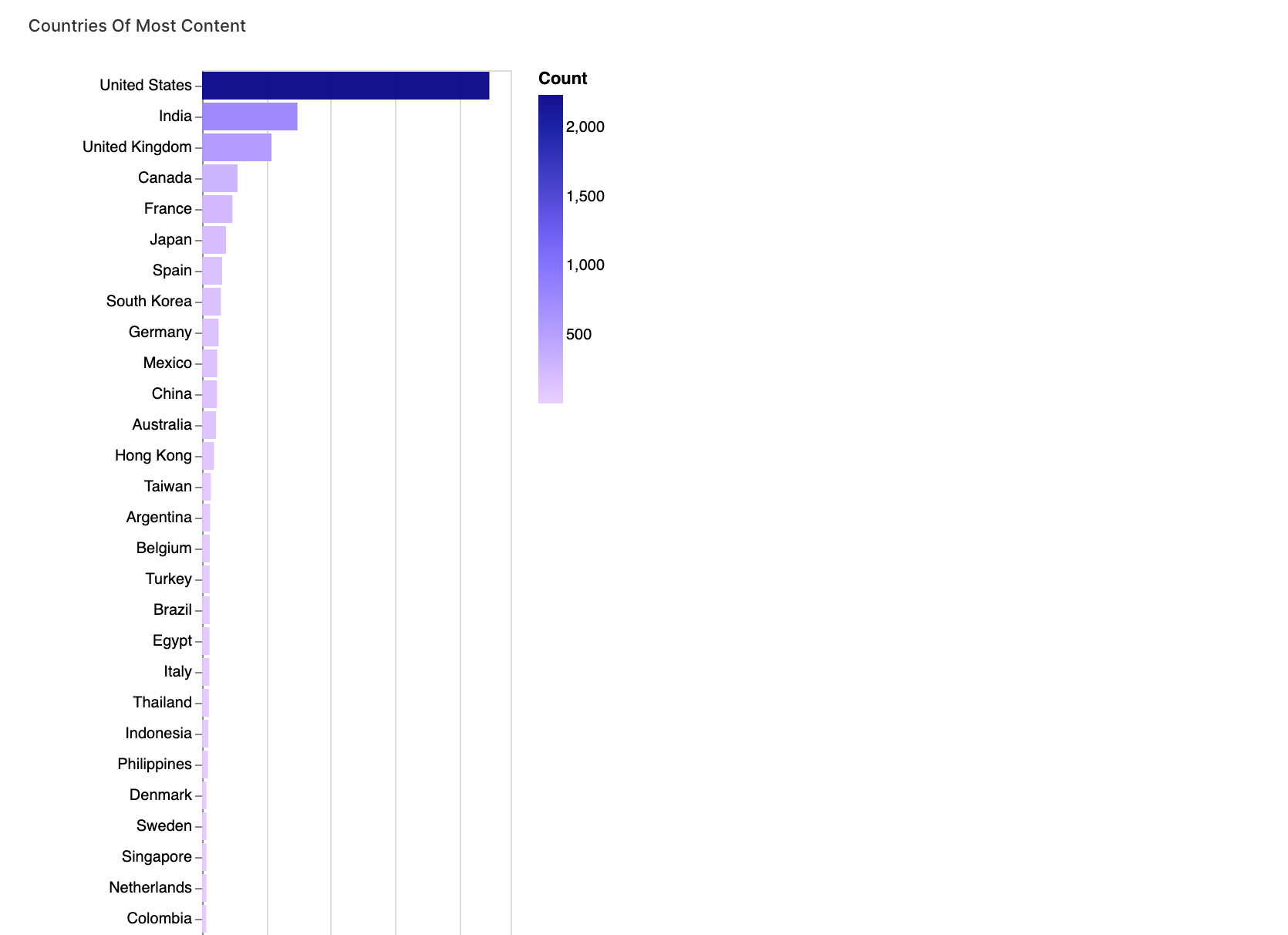
3. Analyse des catégories et des notes
Enfin, nous nous concentrons sur les catégories et les notes. Cette section nous permettra de comprendre la répartition du contenu dans les genres et de voir comment les notes varient à l'intérieur de ces genres.
category_df = df.loc[:, ("listed_in", "rating", "type")]
category_df["category"] = category_df["listed_in"].str.split(",")
category_df = category_df[["category", "rating", "type"]]
category_df = category_df.explode("category").reset_index(drop=True)
walker2 = pyg.walk(category_df, spec="2.json", use_preview=True)Vous pouvez essayer PyGWalker User Interface facilement ici (opens in a new tab)
walker2.display_chart("Catégorie TV", title="Répartition des catégories de séries TV")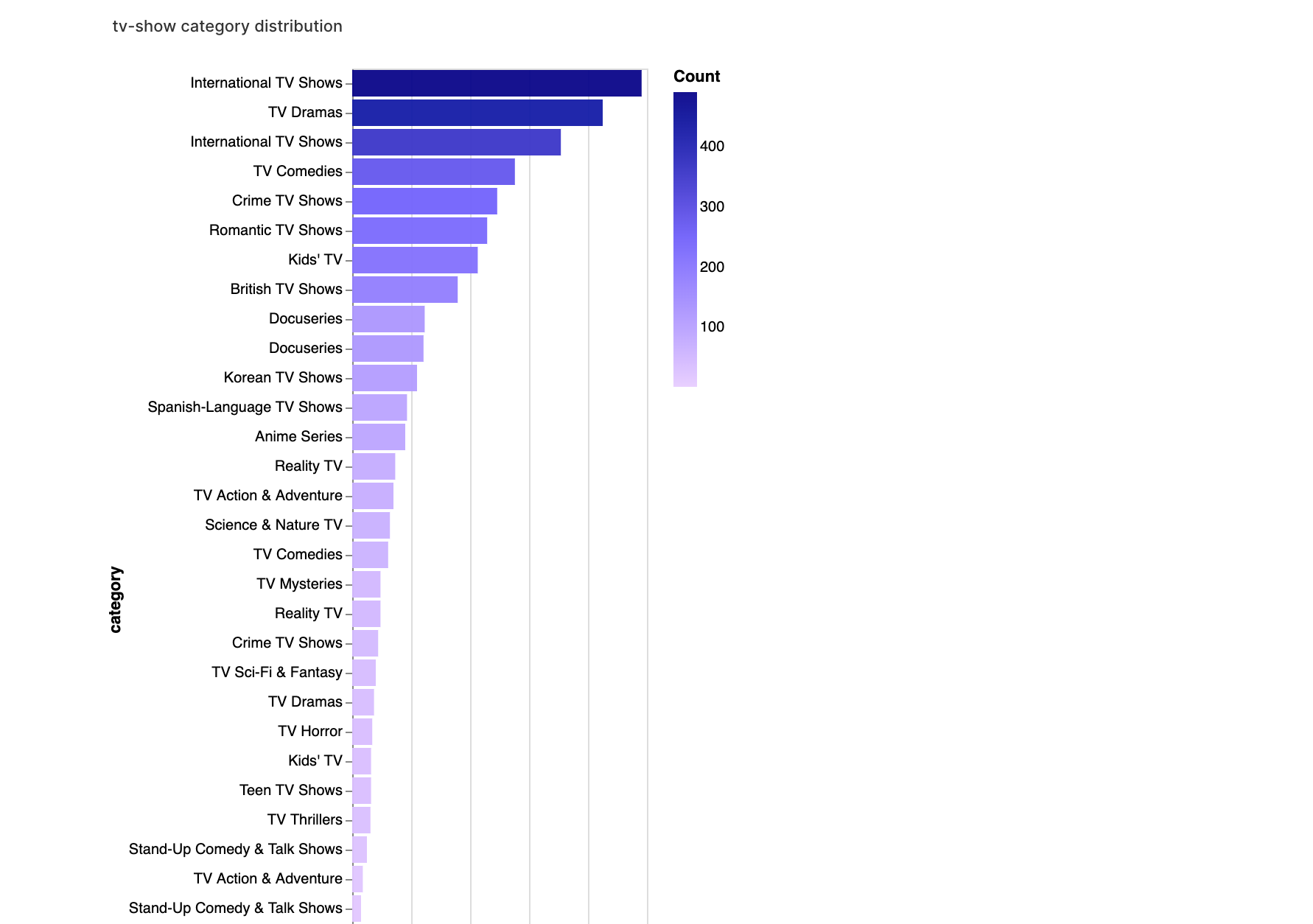
walker2.display_chart("Catégorie Films", title="Répartition des catégories de films")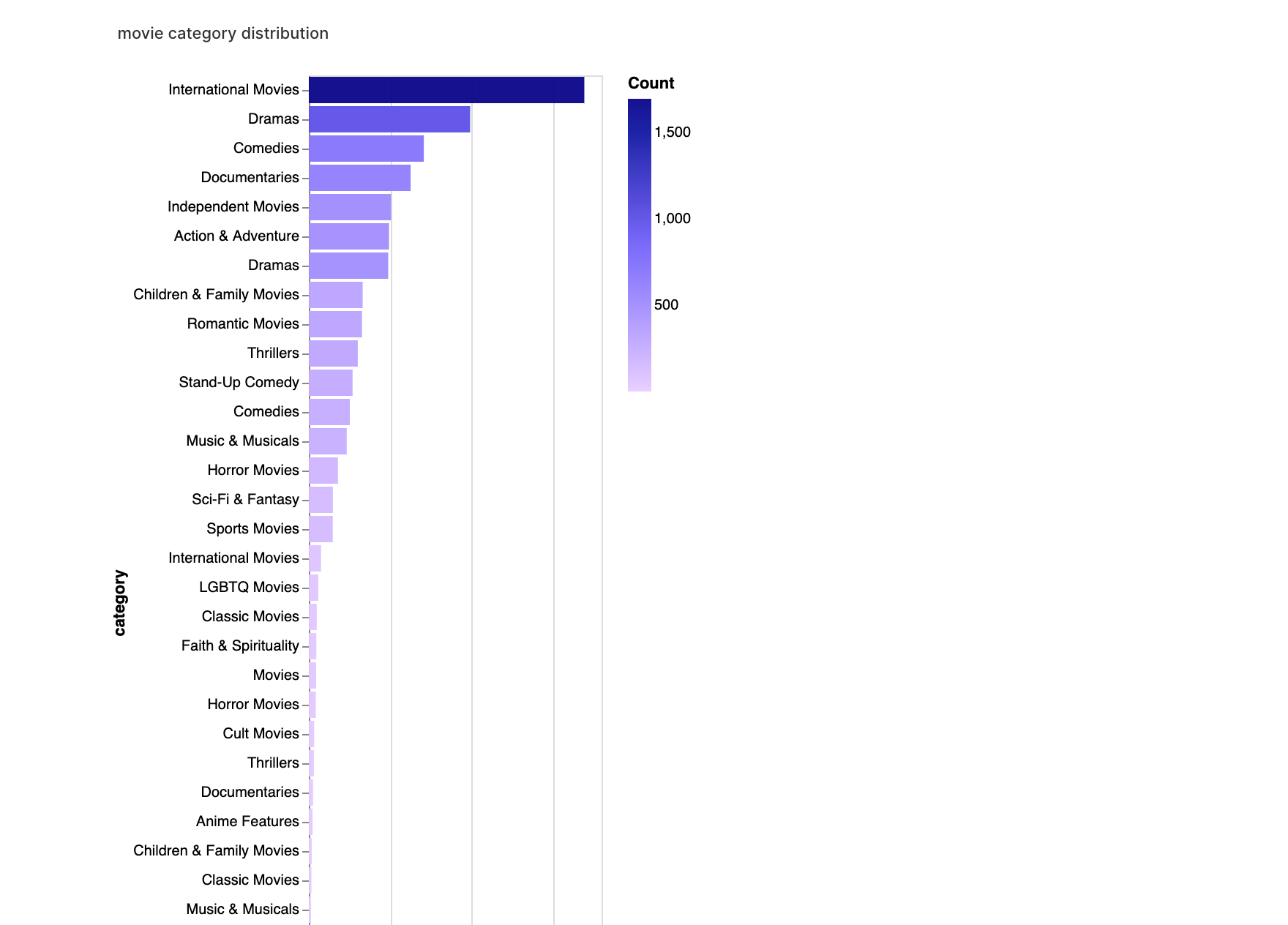
walker2.display_chart("Catégorie de notes (séries TV)", title="Heatmap des catégories de notes (séries TV)")
walker2.display_chart("Catégorie de notes (films)", title="Heatmap des catégories de notes (films)")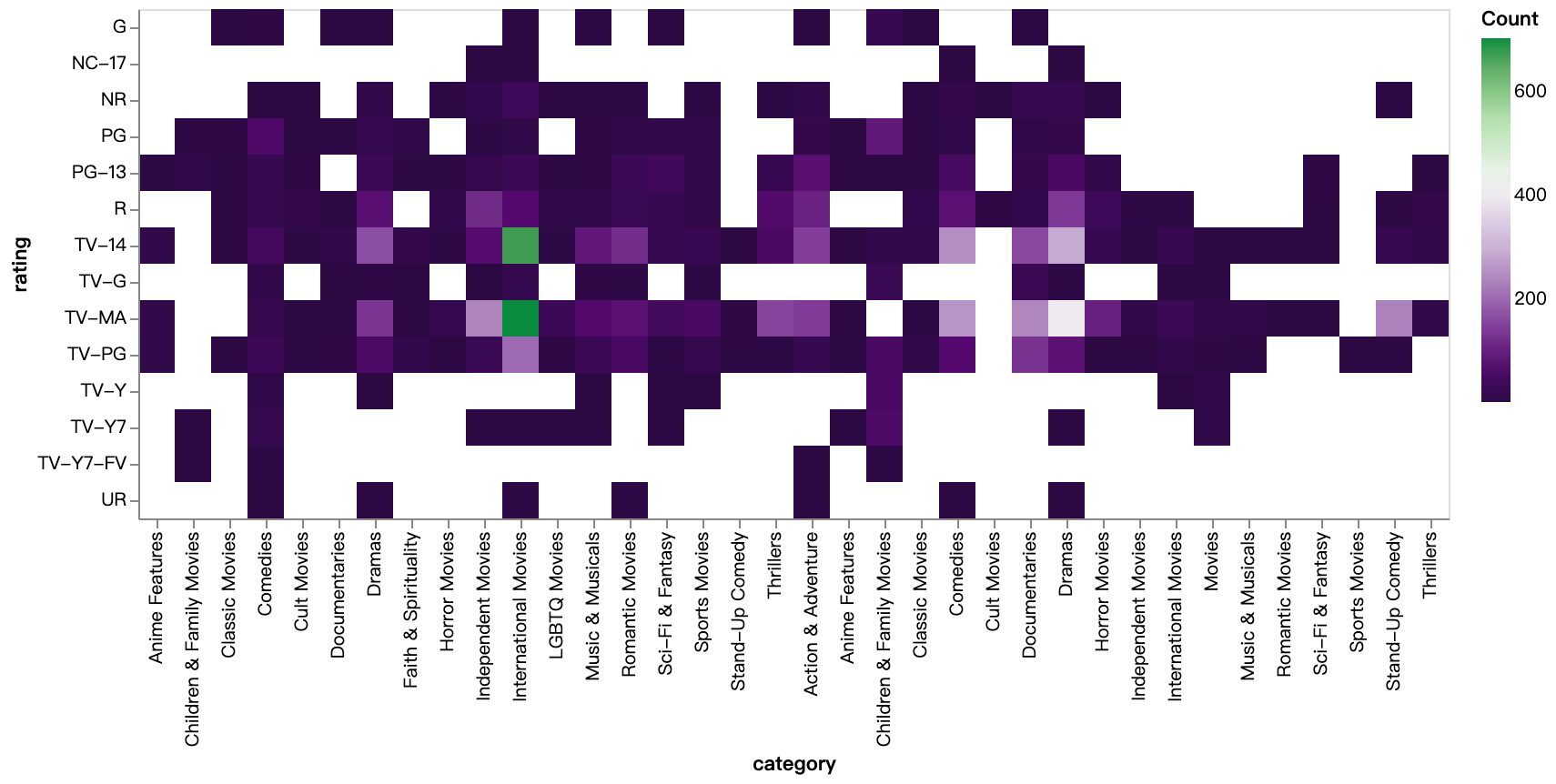
Conclusion
Dans cette exploration complète de l'ensemble de données Netflix à l'aide de la bibliothèque PyGWalker, nous avons approfondi les nombreux aspects du paysage du contenu Netflix. PyGWalker s'est révélé un outil puissant, simplifiant le processus de visualisation pour mettre en évidence les tendances essentielles. L'analyse a permis de clarifier les modèles de croissance, les préférences et les tendances du contenu Netflix jusqu'en 2019, en examinant les catégories et les notes, la variété et la répartition des genres entre les films et les séries télévisées, ainsi que la façon dont les notes varient à l'intérieur de ces genres.
Cette documentation est également disponible sur Kaggle Notebook (opens in a new tab).
FAQs
1. Quels sont les ensembles de données Netflix ?
- Les ensembles de données Netflix sont des collections de données fournissant des informations détaillées sur le contenu disponible sur la plateforme Netflix. Ces données incluent généralement des aspects tels que le type de contenu (film ou série télévisée), le titre, le réalisateur, le casting, le pays de production, la date d'ajout à Netflix, l'année de sortie, la note, la durée, le genre et une brève description. Ces ensembles de données permettent aux chercheurs et aux analystes de mieux comprendre le paysage du contenu de la plateforme.
2. Comment peut-on utiliser les ensembles de données Netflix ?
- Les ensembles de données Netflix peuvent être utilisés de différentes manières :
- Analyse des tendances : Comprendre les modèles de croissance, les préférences et les tendances au fil des ans.
- Analyse par pays : Déterminer les pays qui produisent le plus de contenu et quel type de contenu est populaire dans différentes régions.
- Répartition des genres : Explorer les genres les plus populaires et comment ils varient entre les films et les séries télévisées.
- Réflexions sur les notes : Analyser la répartition des notes selon les différents types de contenu et déterminer les préférences du public.
- Visualisation des données : Utiliser des outils tels que PyGWalker pour créer des visualisations interactives pour obtenir des informations approfondies.
3. Qu'est-ce que PyGWalker et pourquoi est-il bénéfique pour l'exploration des données ?
- PyGWalker est une bibliothèque Python spécialement conçue pour simplifier le processus de visualisation des données. Il permet aux utilisateurs de générer des graphiques interactifs avec un code minimal, facilitant la découverte de modèles et d'informations dans les ensembles de données. Pour des plateformes comme Netflix, qui possèdent de vastes ensembles de données, PyGWalker peut être précieux pour simplifier l'exploration des données et générer des visualisations facilement compréhensibles.