Est-ce que ChatGPT peut remplacer les analystes de données ? Générez facilement des requêtes SQL complexes avec ChatGPT

- Runcell Science : l'alternative open source à Claude Science pour la recherche
- Empêcher un Mac de se mettre en veille : capot fermé, Codex et Claude Code
- OpenClaw vs ZeroClaw vs Pi Agent vs Nanobot : quelle stack d’agents IA choisir en 2026 ?
- Comment Claude Code analyse un notebook Jupyter en Data Science : capacités réelles et limites
- Claude Code routines : triggers, cron jobs et automatisation d’agents IA
- Claude Code Desktop : activer le mode Bypass permissions
- Comment Créer Deux Agents Python avec le Protocole A2A de Google - Tutoriel Étape par Étape
- Top 10 bibliothèques de visualisation de données en Python en pleine croissance en 2025
Introduction
SQL (Structured Query Language) est un langage de programmation largement utilisé pour gérer et manipuler des données dans des bases de données relationnelles. Les entreprises et les organisations ont besoin de stocker, récupérer et analyser des données. Cependant, rédiger des requêtes SQL peut être une tâche longue et sujette aux erreurs pour les humains, surtout pour les requêtes complexes ou les bases de données volumineuses.
Dans cet article, nous explorerons les capacités de ChatGPT, un modèle de langage développé par OpenAI, dans la génération de requêtes SQL efficaces. Nous montrerons comment ChatGPT peut rapidement générer des requêtes complexes, filtrer les données avec une grande précision et un rappel élevé, et optimiser les requêtes existantes.
Générer une base de données d'exemple
Pour clarifier les choses, nous avons une base de données d'exemple qui contient les éléments suivants :
Tableau 1 : books
Ce tableau contiendra des informations sur tous les livres de la librairie, y compris leurs titres, auteurs, éditeurs et ISBN.
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255),
publisher VARCHAR(255),
isbn VARCHAR(13)
); Tableau 2 : customers
Ce tableau stockera des informations sur les clients qui se sont inscrits à la librairie, y compris leurs noms, adresses e-mail et numéros de téléphone.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
phone VARCHAR(20)
); Tableau 3 : orders
Ce tableau stockera des informations sur toutes les commandes passées par les clients, y compris le client qui a passé la commande, le(s) livre(s) commandé(s), la date de la commande et l'état de la commande.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
book_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
); Tableau 4 : inventory
Ce tableau permettra de suivre les niveaux de stock actuels de chaque livre dans le magasin.
CREATE TABLE inventory (
book_id INT PRIMARY KEY,
quantity INT,
FOREIGN KEY (book_id) REFERENCES books(book_id)
); Ce ne sont là que les tables de base dont vous auriez besoin pour commencer avec une base de données de librairie. Selon vos besoins spécifiques, vous pouvez ajouter d'autres tables ou colonnes à ces tables.
ChatGPT Prompt pour l'agrégation de données
L'une des tâches les plus courantes dans le travail avec des bases de données est l'agrégation de données. Cela consiste à résumer des données en fonction de certaines conditions. Par exemple, calculer les ventes totales pour une catégorie de produits spécifique ou le salaire moyen des employés dans un certain département. Les requêtes d'agrégation peuvent être complexes à rédiger et peuvent prendre beaucoup de temps pour les humains.
ChatGPT, cependant, peut générer ces requêtes rapidement et avec précision. Il peut comprendre la structure des données et le résultat souhaité, et générer une requête efficace qui peut récupérer les informations requises avec un effort minimal. Cela réduit le risque d'erreurs et permet de gagner du temps pour l'utilisateur.
Voici un exemple de requête d'agrégation de données générée par ChatGPT avec la consigne suivante :
"Trouvez les 5 livres les plus vendus du dernier trimestre, ainsi que leurs auteurs et le chiffre d'affaires total des ventes."
Pour effectuer cette agrégation, vous devrez joindre les tables books, orders et inventory, grouper les résultats par livre et auteur, filtrer par les commandes du dernier trimestre et calculer le chiffre d'affaires total des ventes pour chaque livre. Enfin, vous devrez trier les résultats par chiffre d'affaires et limiter la sortie aux 5 premiers livres.
ChatGPT génère le code SQL suivant pour accomplir cette tâche :
SELECT books.title, books.author, SUM(inventory.quantity * orders.price) AS revenue
FROM books
JOIN inventory ON books.book_id = inventory.book_id
JOIN orders ON inventory.book_id = orders.book_id
WHERE orders.order_date >= DATEADD(QUARTER, -1, GETDATE())
GROUP BY books.title, books.author
ORDER BY revenue DESC
LIMIT 5; Filtrage des données
Une autre tâche importante dans le travail avec des bases de données est le filtrage des données. Cela consiste à extraire des données spécifiques d'une base de données en fonction de certains critères. Par exemple, extraire toutes les transactions effectuées par des clients dans un certain lieu ou tous les employés qui font partie de l'entreprise depuis plus de cinq ans. Les requêtes de filtrage peuvent également être complexes à rédiger et peuvent prendre beaucoup de temps aux humains.
ChatGPT peut générer ces requêtes avec une grande précision et un rappel élevé. Il peut comprendre la structure des données et le résultat souhaité et générer une requête qui peut récupérer les données les plus pertinentes. Cela permet d'obtenir des données plus précises pour l'analyse et la prise de décision. Voici un exemple de requête de filtrage de données générée en utilisant cette consigne ChatGPT :
"Trouvez tous les livres publiés par 'Penguin Random House' et actuellement en stock, triés par ordre croissant du nom de l'auteur."
Pour effectuer ce filtrage, vous devrez joindre les tables books et inventory, filtrer par les livres publiés par 'Penguin Random House' et sélectionner uniquement les livres actuellement en stock. Enfin, vous devrez trier les résultats par ordre croissant du nom de l'auteur.
ChatGPT génère le code SQL suivant pour réaliser cette exigence :
SELECT books.title, books.author, books.publisher, inventory.quantity
FROM books
JOIN inventory ON books.book_id = inventory.book_id Optimisation de requête
En plus de générer de nouvelles requêtes SQL, ChatGPT peut également aider à optimiser les requêtes existantes. En analysant la structure et les performances d'une requête, ChatGPT peut suggérer des améliorations pour rendre la requête plus rapide et plus efficace. Par exemple, ChatGPT peut suggérer d'utiliser des index ou de réécrire la requête pour tirer parti des capacités de la base de données.
L'optimisation des requêtes peut être une tâche difficile pour les humains, surtout pour les bases de données volumineuses et complexes. ChatGPT peut simplifier cette tâche et aider à améliorer les performances de la base de données. Voici un exemple d'optimisation de requête générée en utilisant cette instruction ChatGPT :
"Trouvez les 10 meilleurs clients qui ont dépensé le plus en livres au cours de la dernière année, avec leurs dépenses totales et leurs dépenses moyennes par commande."
Pour optimiser cette requête, vous devez réduire au minimum le nombre d'opérations que la base de données doit effectuer pour produire les résultats. Voici quelques techniques d'optimisation que vous pouvez considérer :
-
Utilisez des index : Ajoutez des index sur les colonnes pertinentes des tables customers et orders pour accélérer les opérations de jointure et de filtrage.
-
Agrégez avant de joindre : Au lieu de joindre directement les tables customers et orders, vous pouvez d'abord agréger la table orders par client, puis joindre la table résultante avec la table customers.
-
Utilisez des sous-requêtes : Au lieu de joindre directement les tables customers et orders, vous pouvez utiliser des sous-requêtes pour filtrer la table orders par plage de dates et calculer les dépenses totales et les dépenses moyennes par commande pour chaque client.
Voici un exemple de requête SQL qui met en œuvre ces optimisations générées par ChatGPT :
SELECT customers.name,
total_spending,
total_spending / order_count AS avg_spending_per_order
FROM (
SELECT customer_id,
SUM(price * quantity) AS total_spending,
COUNT(*) AS order_count
FROM orders
WHERE order_date >= DATEADD(YEAR, -1, GETDATE())
GROUP BY customer_id
) AS order_totals
JOIN customers ON order_totals.customer_id = customers.customer_id
ORDER BY total_spending DESC
LIMIT 10;Une autre option d'analyse de données automatisée : RATH
En plus des capacités de ChatGPT à générer des requêtes SQL efficaces, il existe également RATH (opens in a new tab), une alternative open-source aux outils d'analyse et de visualisation de données tels que Tableau. RATH fait passer l'analyse de données au niveau supérieur en automatisant le workflow de l'Analyse Exploratoire des Données (EDA) avec un moteur d'analyse augmentée.
RATH prend en charge un large éventail de sources de données. Voici quelques-unes des principales solutions de bases de données auxquelles vous pouvez vous connecter à RATH : MySQL, ClickHouse, Amazon Athena, Amazon Redshift, Apache Spark SQL, Apache Doris, Apache Hive, Apache Impala, Apache Kylin, Oracle et PostgreSQL.
RATH (opens in a new tab) est open source. Visitez le dépôt GitHub de RATH et découvrez l'outil Auto-EDA de nouvelle génération. Vous pouvez également essayer la démo en ligne de RATH comme terrain de jeu pour l'analyse de données !

Les fonctionnalités principales de RATH sont les suivantes :
| Fonctionnalité | Description | Aperçu |
|---|---|---|
| AutoEda | Moteur d'analyse augmentée pour découvrir les motifs, les insights et les relations causales. Une manière entièrement automatisée d'explorer votre ensemble de données et de visualiser vos données en un clic. | 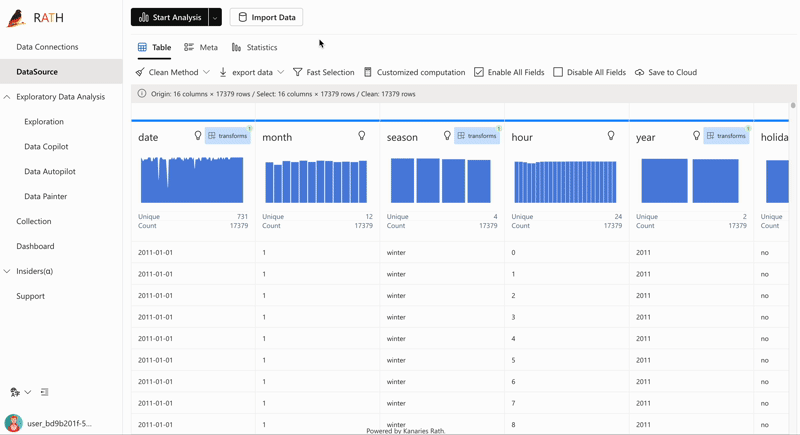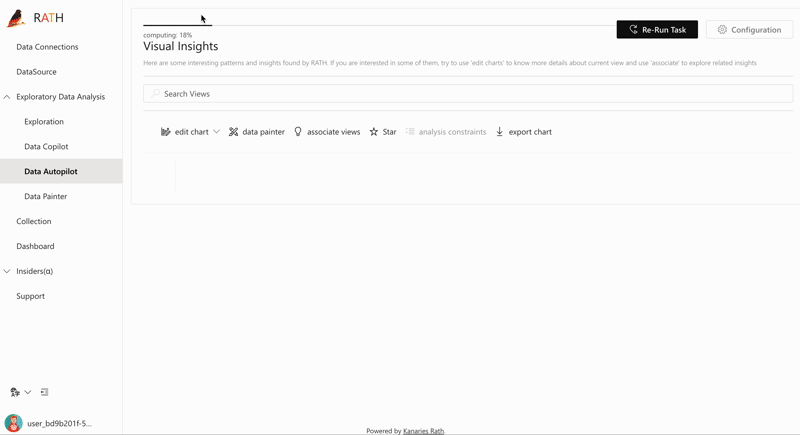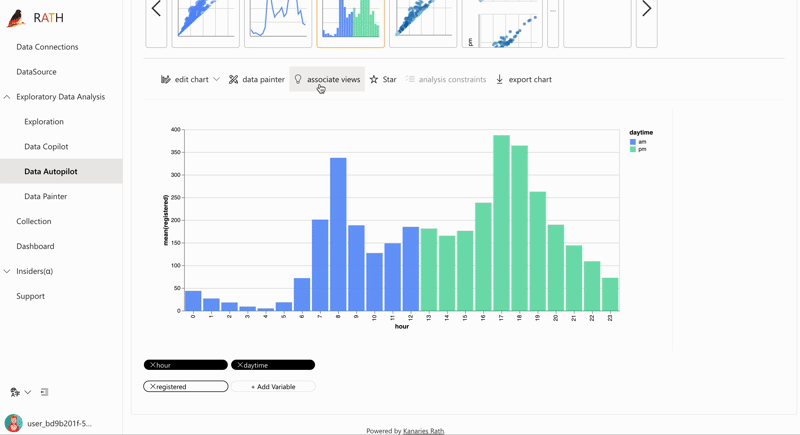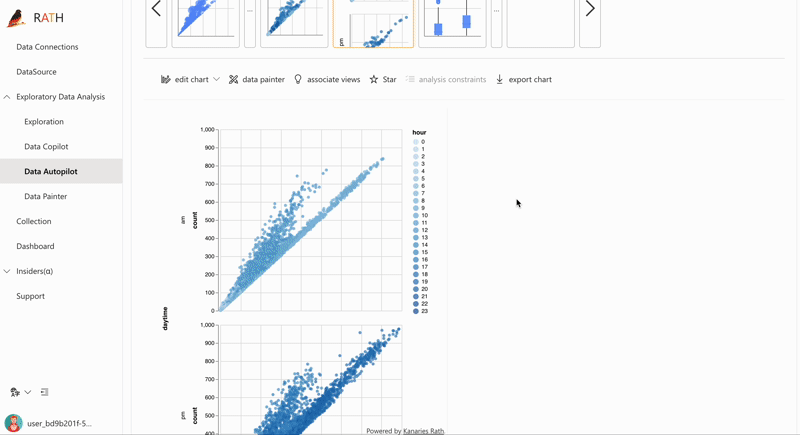 |
| Visualisation de données | Créez une visualisation de données multidimensionnelle basée sur le score d'efficacité. | 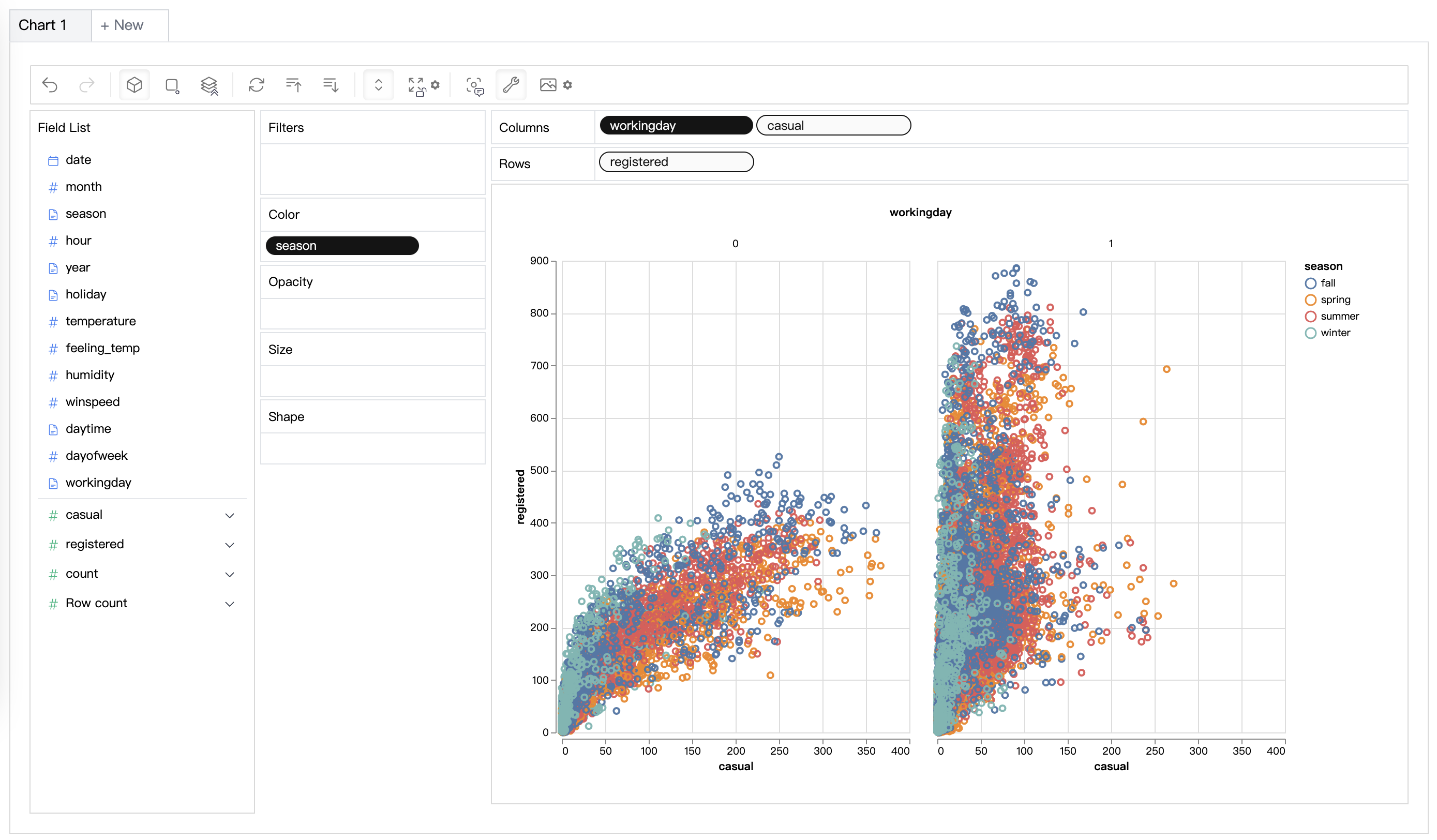 |
| Data Wrangler | Data Wrangler automatisé pour générer un résumé des données et des transformations de données. | 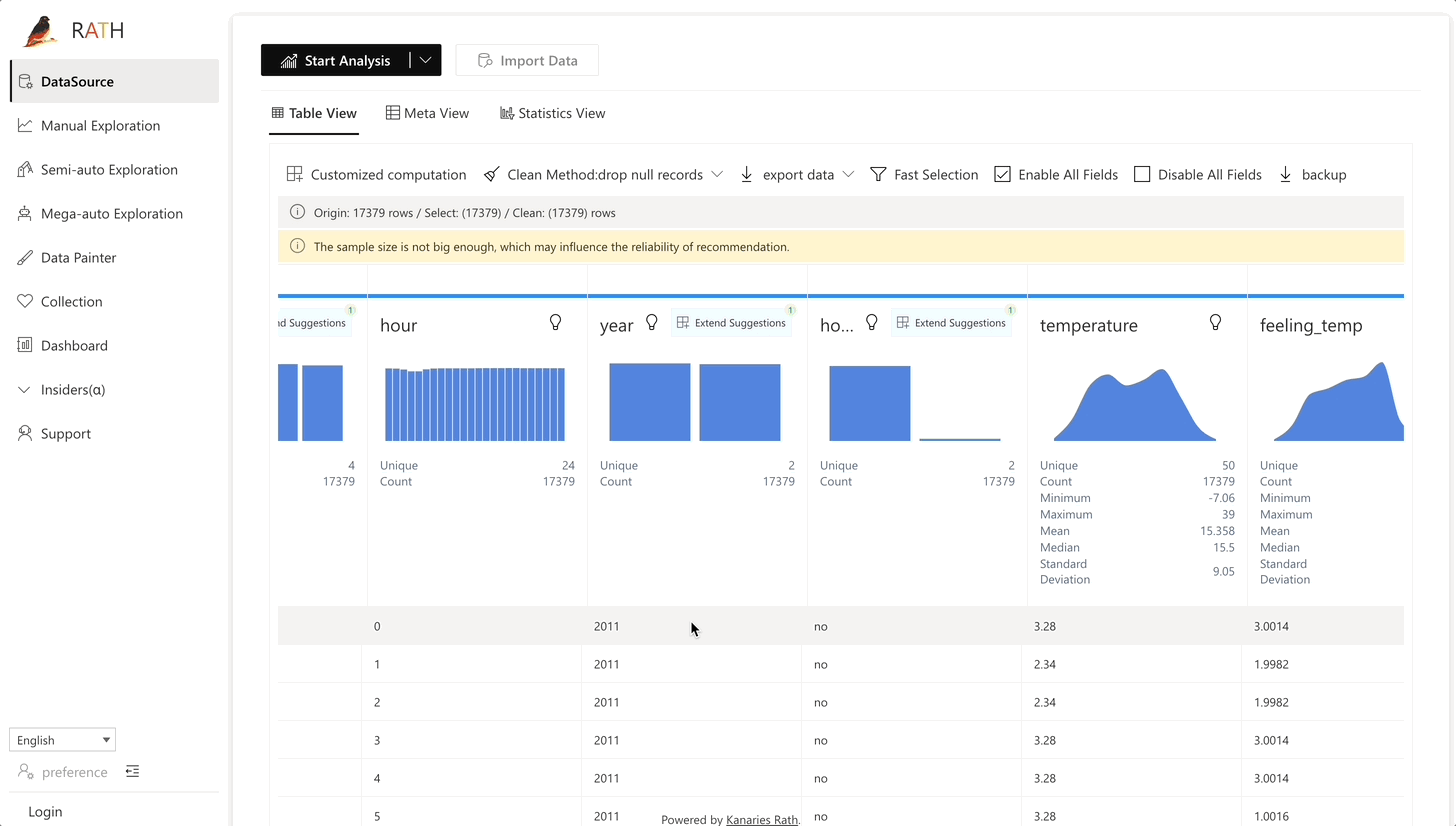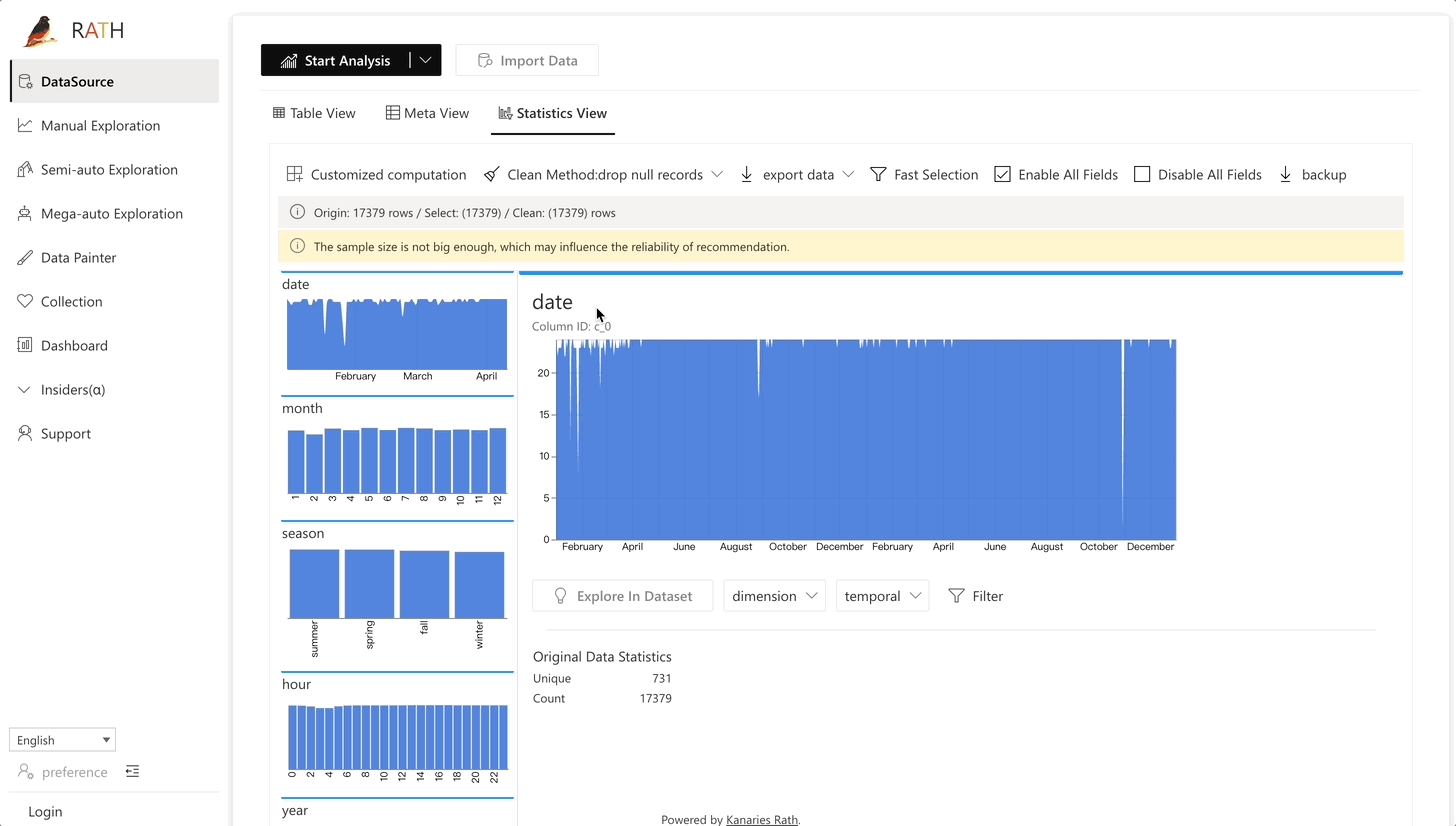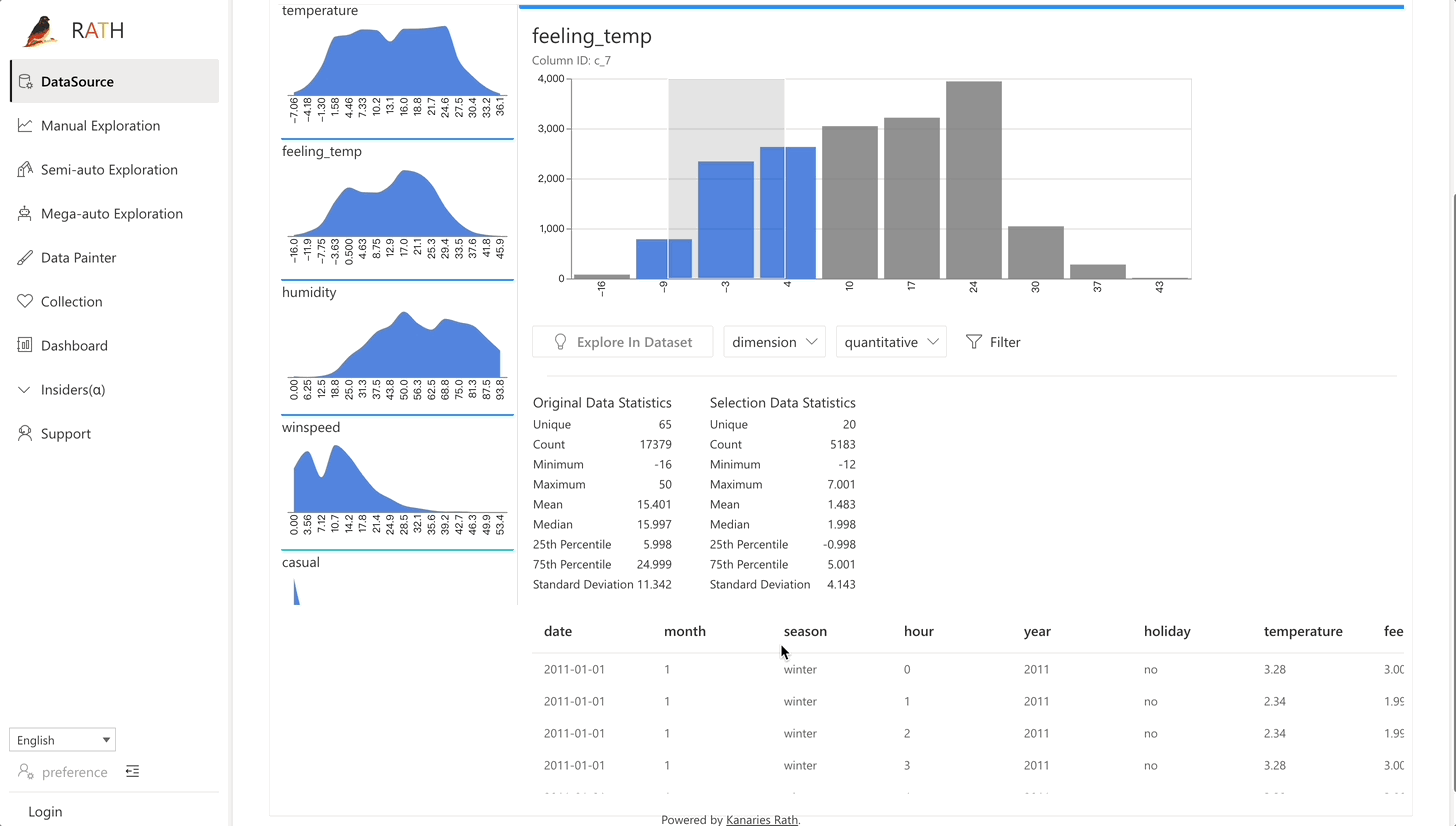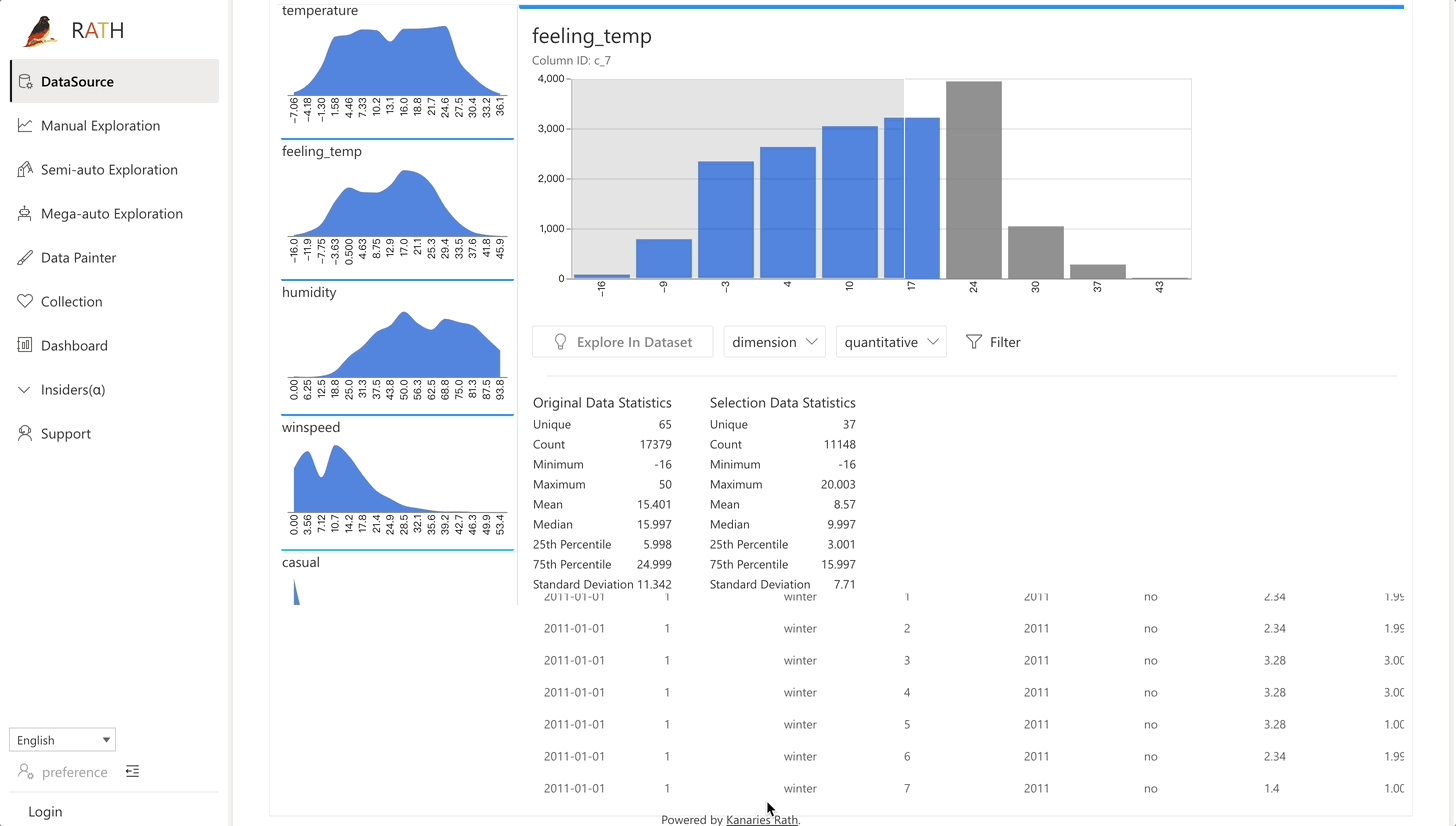 |
| Data Exploration Copilot | Combine l'exploration de données automatisée et l'exploration manuelle. RATH agira comme votre copilote en science des données, apprendra vos intérêts et utilisera le moteur d'analyse augmentée pour générer des recommandations pertinentes. | 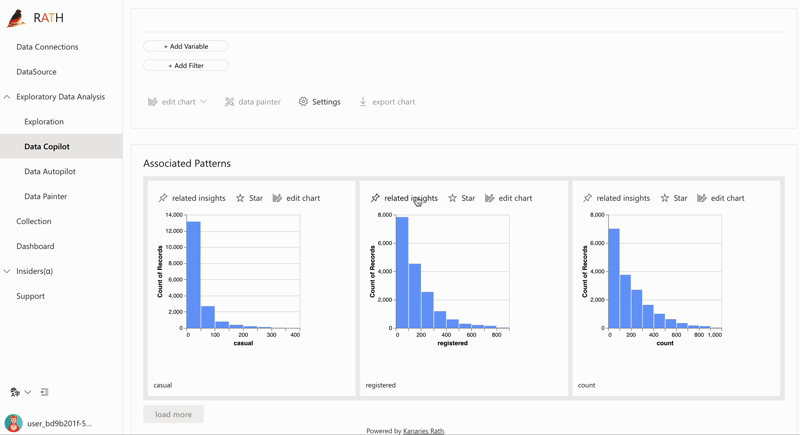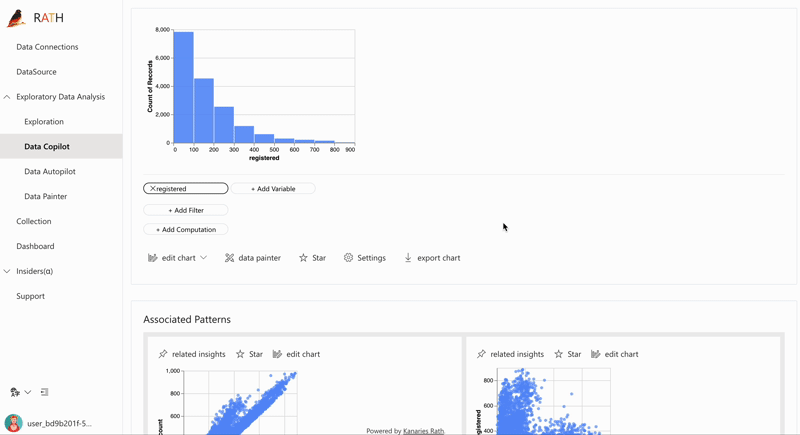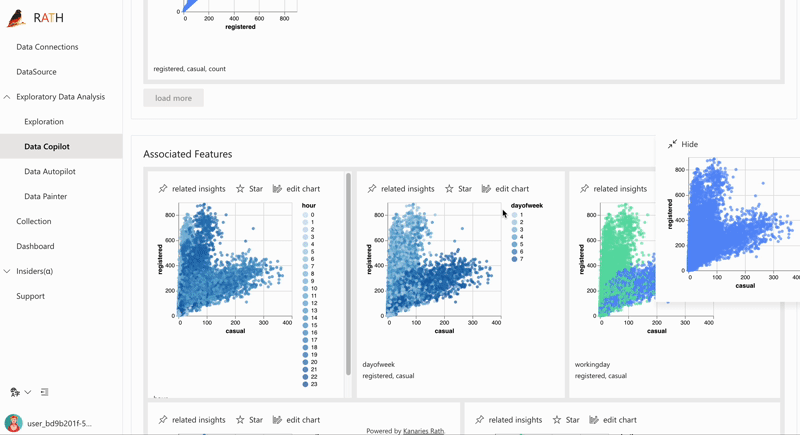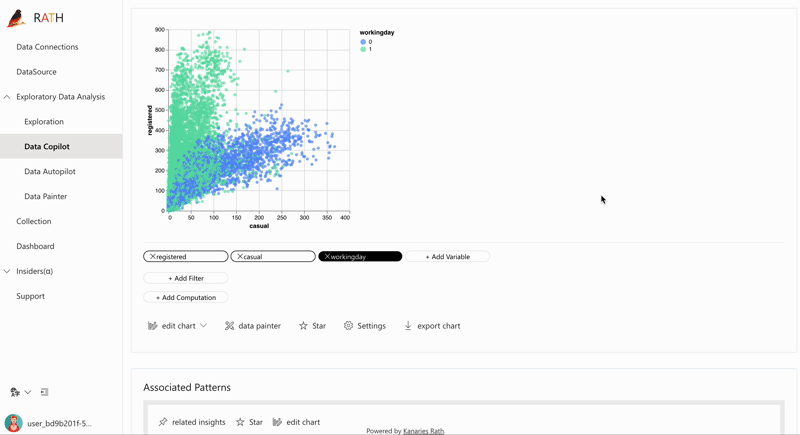 |
| Data Painter | Un outil interactif, intuitif mais puissant pour l'analyse exploratoire des données en colorant directement vos données, avec des fonctionnalités analytiques supplémentaires. | 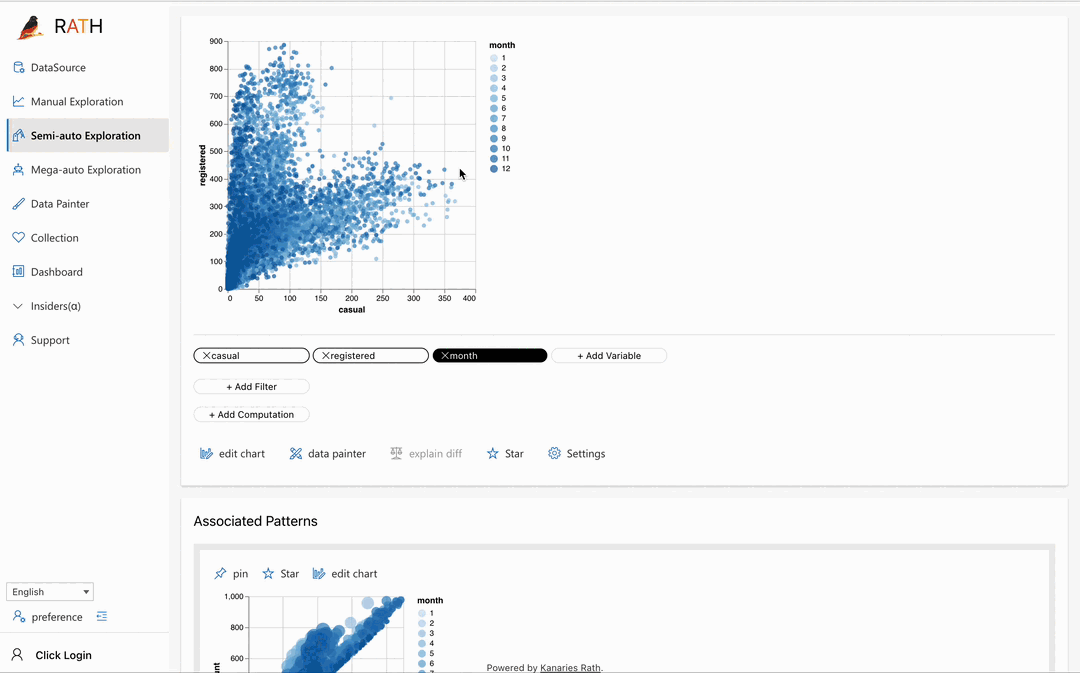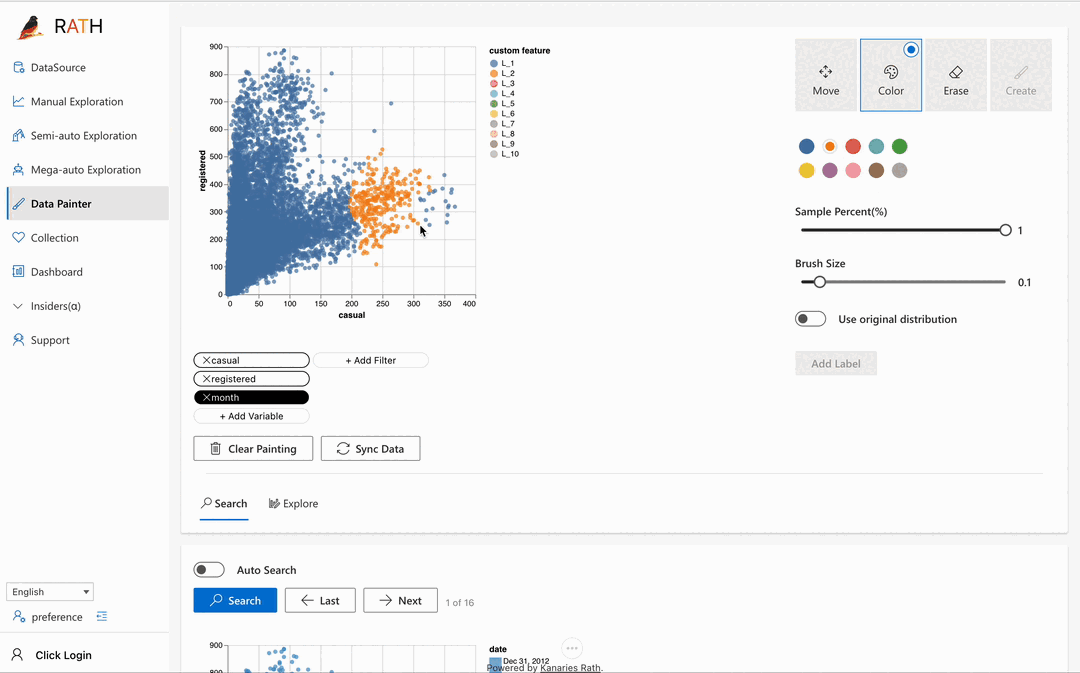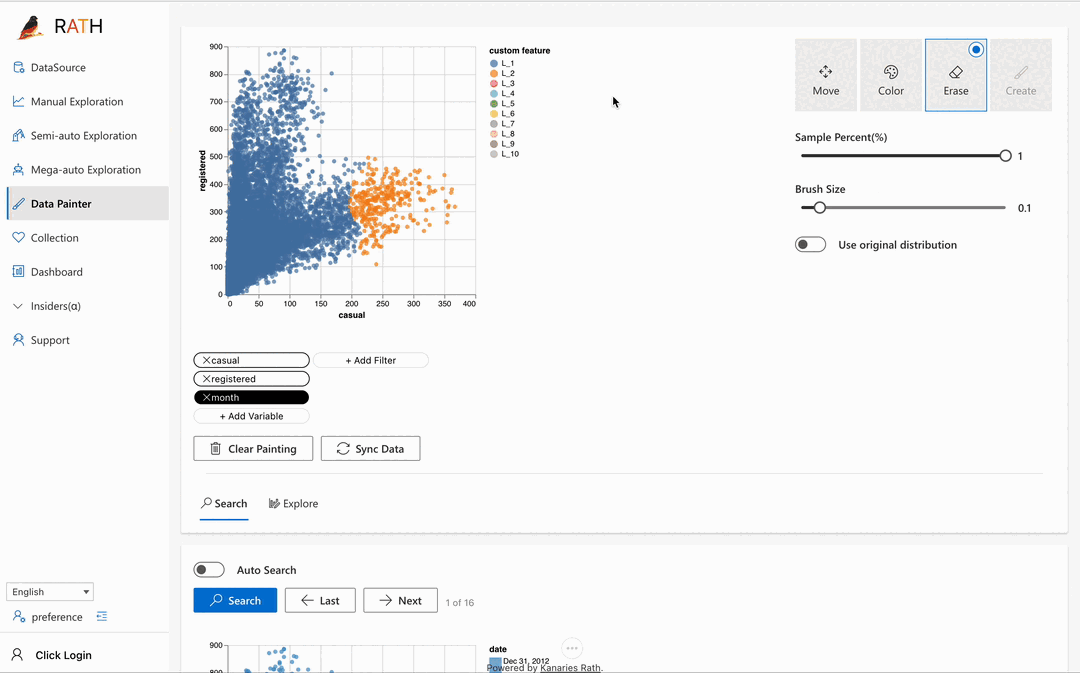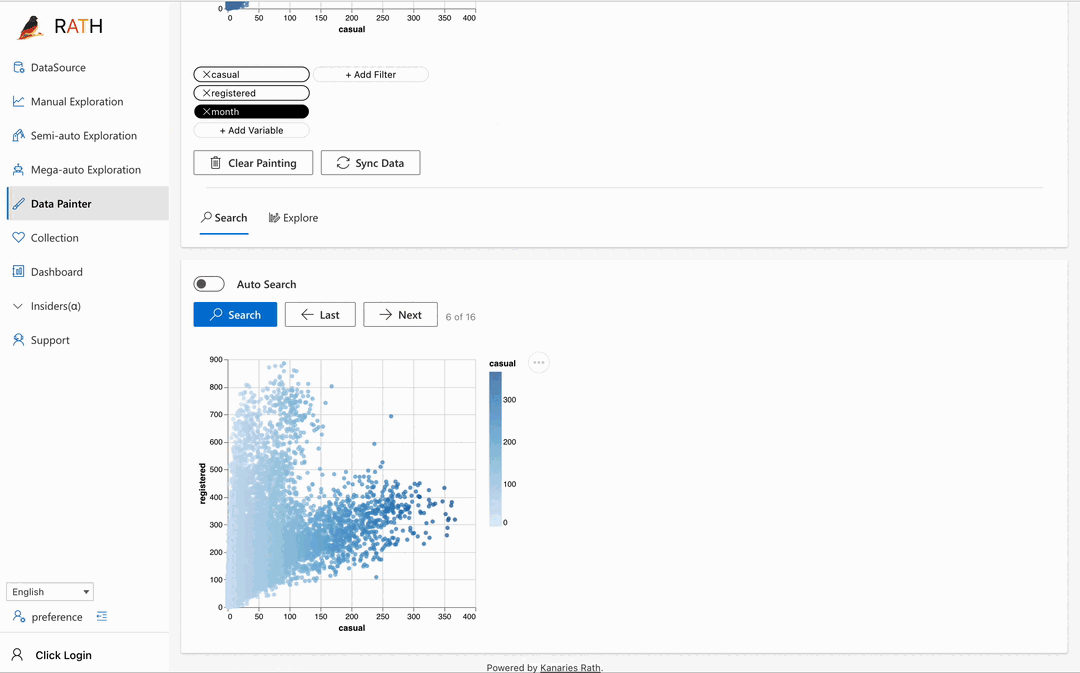 |
| Dashboard | Créez un magnifique tableau de bord interactif (y compris un concepteur de tableau de bord automatisé qui peut fournir des suggestions pour votre tableau de bord). | 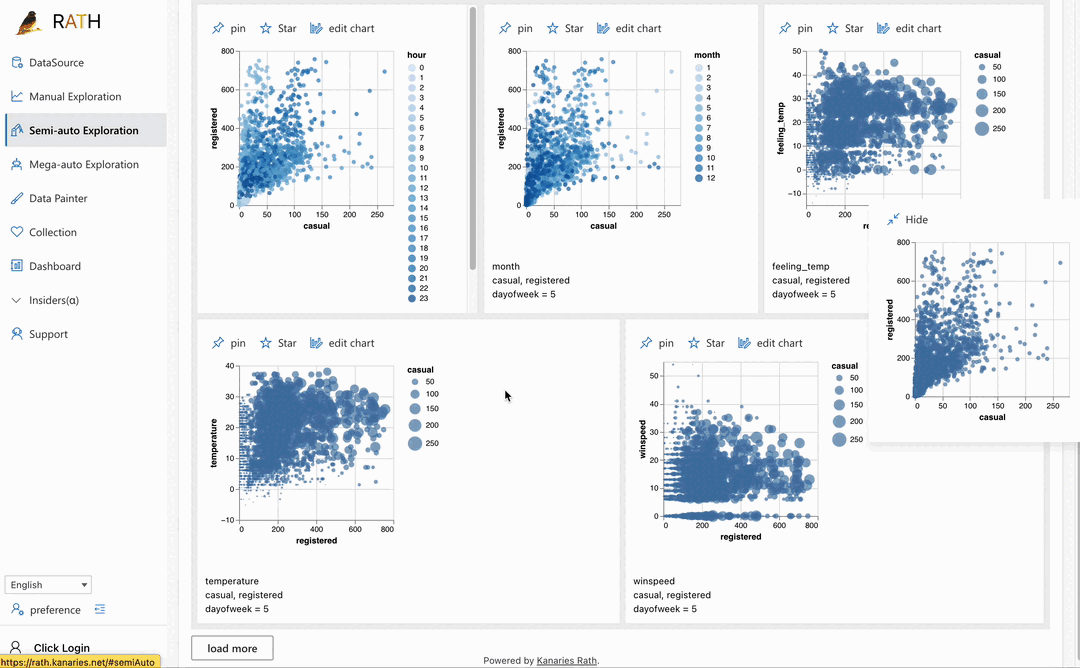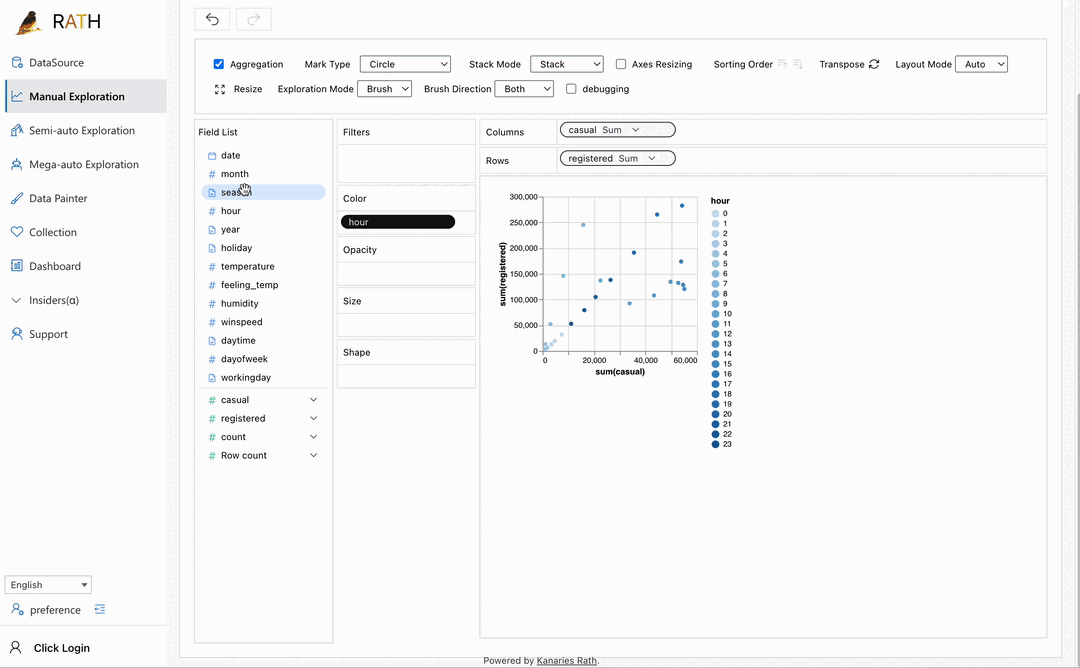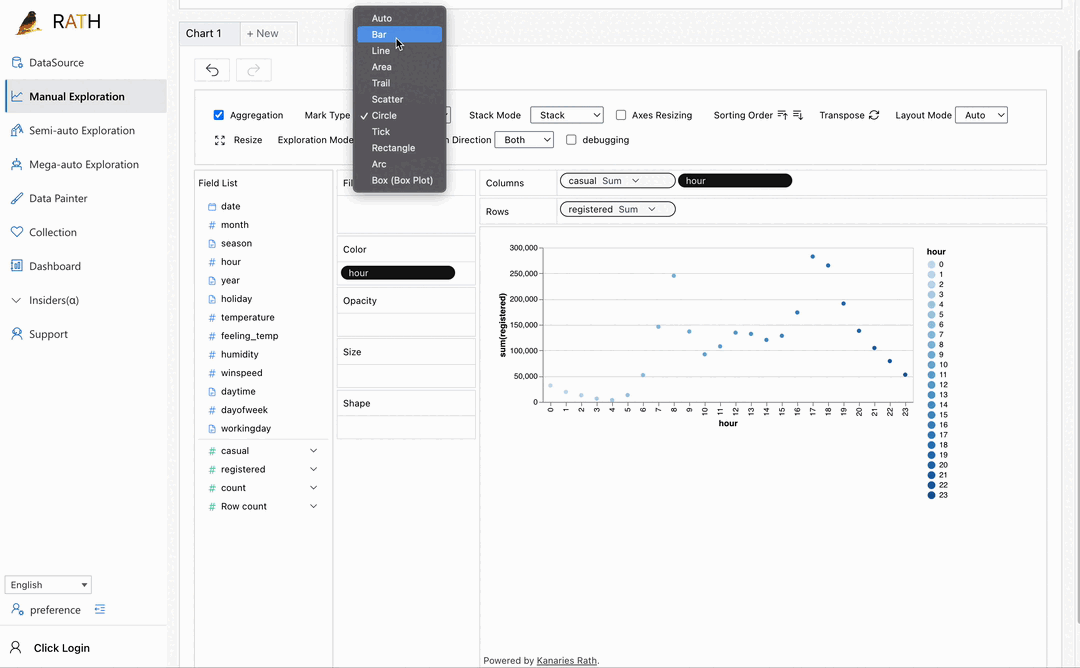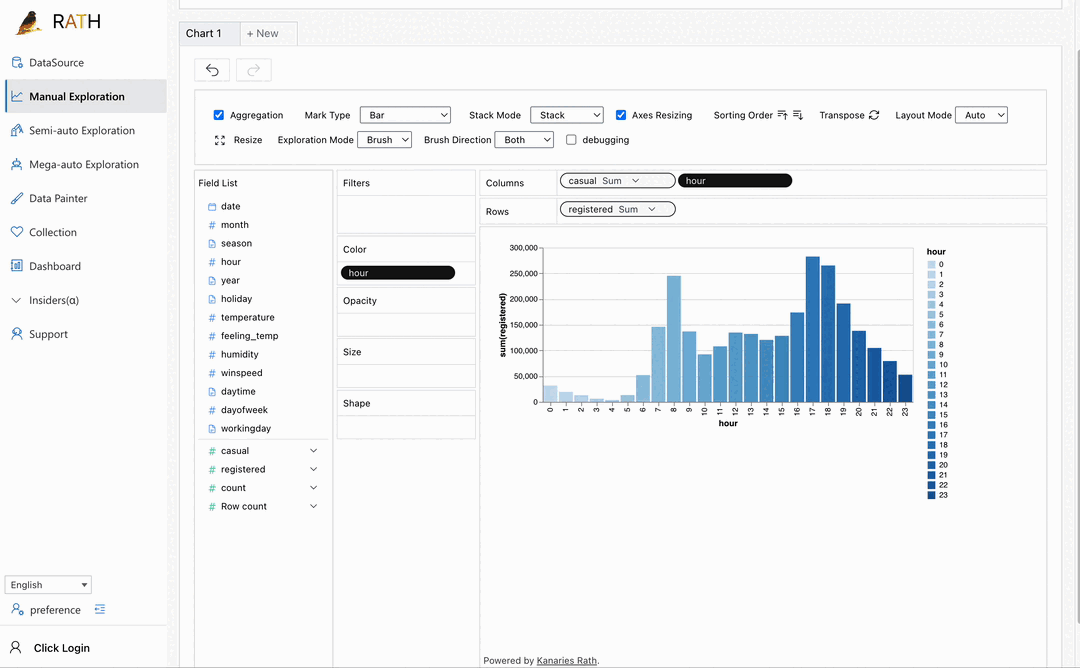 |
| Analyse causale | Fournit la découverte et les explications causales pour l'analyse des relations complexes. | 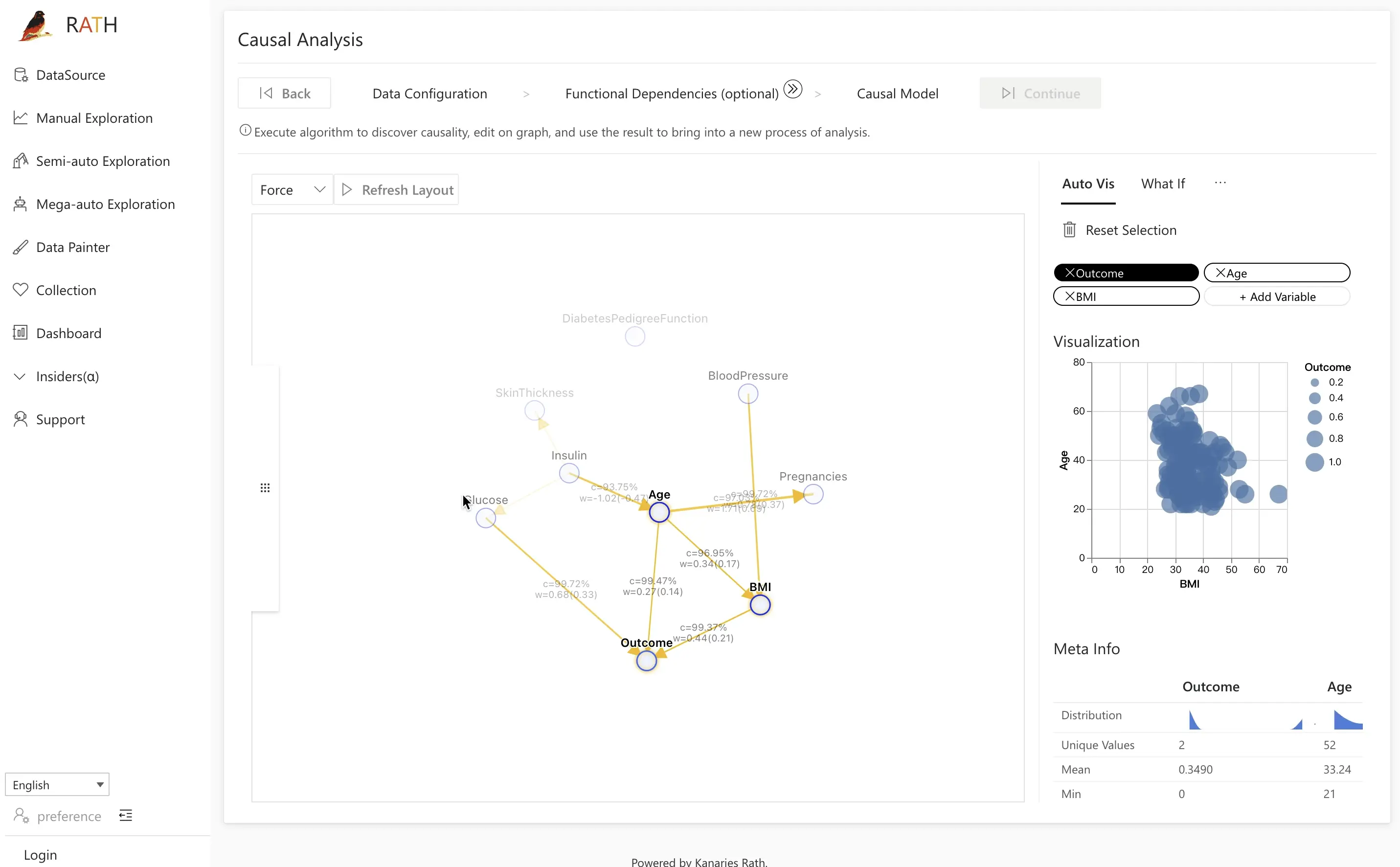 |
Conclusion
En conclusion, ChatGPT est un outil puissant pour générer des requêtes SQL efficaces. Il peut générer rapidement des requêtes complexes pour l'agrégation, le filtrage et l'optimisation des données, réduisant ainsi les risques d'erreurs et permettant de gagner du temps pour l'utilisateur.
En plus des capacités de ChatGPT à générer des requêtes SQL efficaces, il existe également RATH, un outil open-source qui automatise le flux de travail de l'Analyse Exploratoire des Données (EDA) et offre une exploration de données, une visualisation automatisée et une exploration semi-automatique des données pour rendre l'analyse de données plus efficace et plus efficace.