Top 9 bibliotecas de DataFrame de código aberto para Python

Python se estabeleceu como a linguagem preferida para desenvolvedores e entusiastas de dados. Uma razão chave para sua popularidade no processamento de dados é seu extenso ecossistema de bibliotecas, especialmente aquelas focadas em DataFrames. Essas estruturas poderosas, semelhantes a tabelas, facilitam a manipulação e análise de dados estruturados, tornando-se indispensáveis para qualquer pessoa que trabalhe com conjuntos de dados.
Se você já usou Python para análise de dados, provavelmente encontrou o Pandas, a biblioteca de DataFrame mais conhecida e amada. Mas à medida que os dados crescem em tamanho e complexidade, novas bibliotecas emergem para enfrentar os desafios de escala, velocidade e desempenho. Neste artigo, faremos uma viagem pelas bibliotecas de DataFrame de código aberto mais populares em Python, cada uma oferecendo recursos únicos para ajudar você a aproveitar ao máximo seus dados.
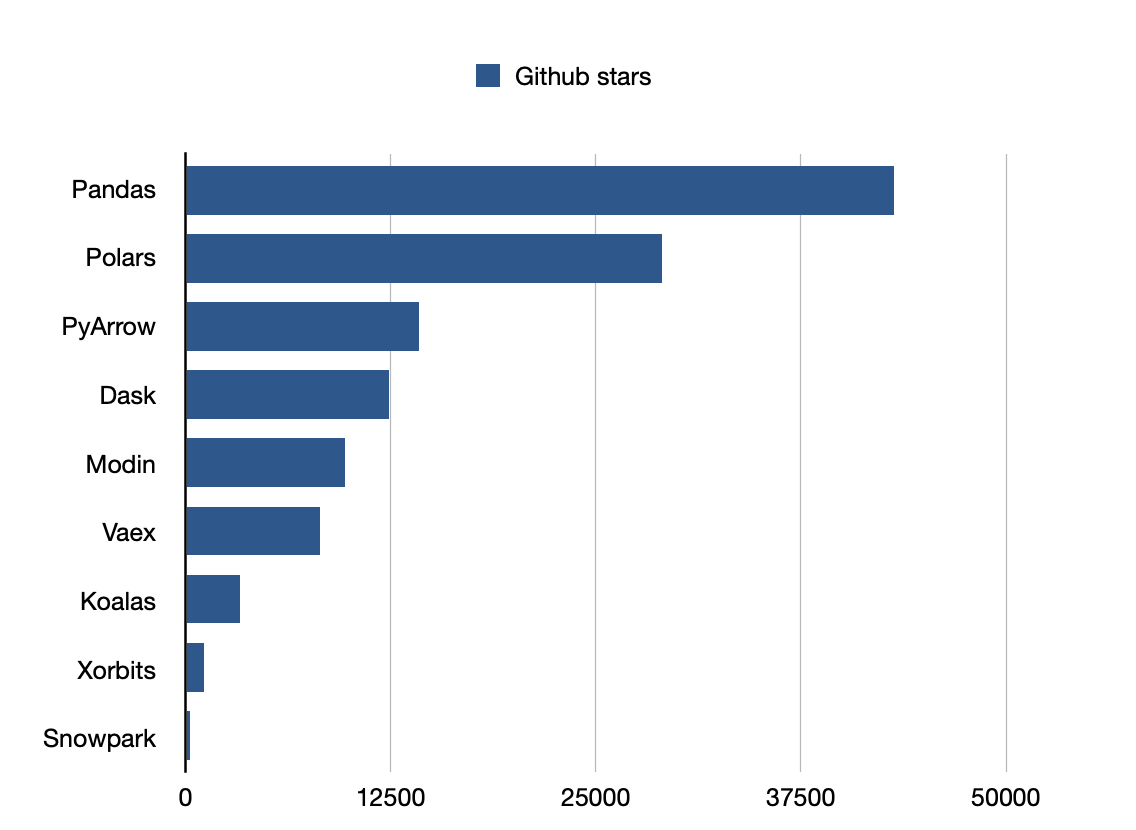
Pandas é a biblioteca mais popular.
1. Pandas: O Veterano da Ciência de Dados
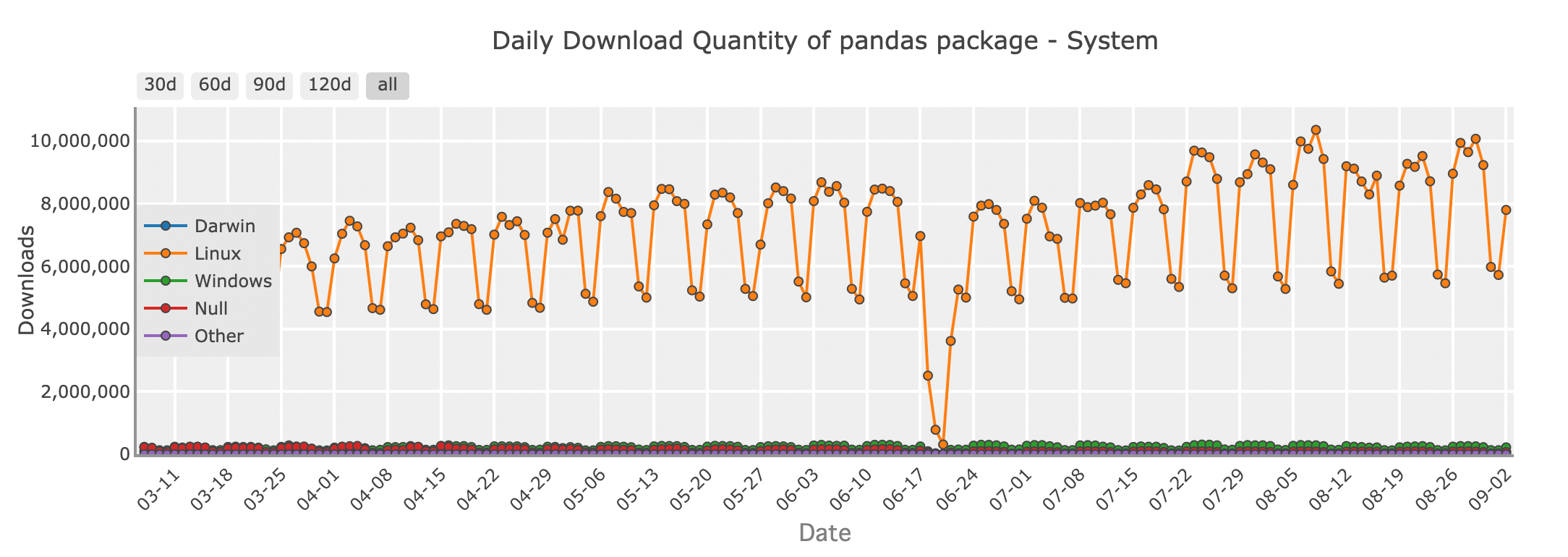
Quantidade de downloads diários do pacote Pandas - sistema
Para muitos desenvolvedores Python, Pandas é a primeira biblioteca que vem à mente ao trabalhar com DataFrames. Seu conjunto rico de recursos e API intuitiva tornam fácil carregar, manipular e analisar dados. Seja limpando um conjunto de dados bagunçado, mesclando dados de várias fontes ou realizando análises estatísticas, Pandas fornece todas as ferramentas necessárias em um formato familiar, semelhante a uma planilha.
import pandas as pd
# Criando um DataFrame
data = {
'Name': ['Amy', 'Bob', 'Cat', 'Dog'],
'Age': [31,27,16,28],
'Department': ['HR', 'Engineering', 'Marketing', 'Sales'],
'Salary': [70000, 80000, 60000, 75000]
}
df = pd.DataFrame(data)
# Exibindo o DataFrame
print(df)Pandas se destaca no manuseio de conjuntos de dados pequenos a médios que cabem confortavelmente na memória do seu computador. É perfeito para tarefas diárias de dados, desde explorar dados em notebooks Jupyter até construir pipelines mais complexos em produção. No entanto, à medida que seus conjuntos de dados crescem em tamanho, o Pandas pode começar a mostrar suas limitações. É aí que outras bibliotecas de DataFrame entram em cena.
Github stars: 43200
2. Modin: Elevando Pandas a Novos Altos
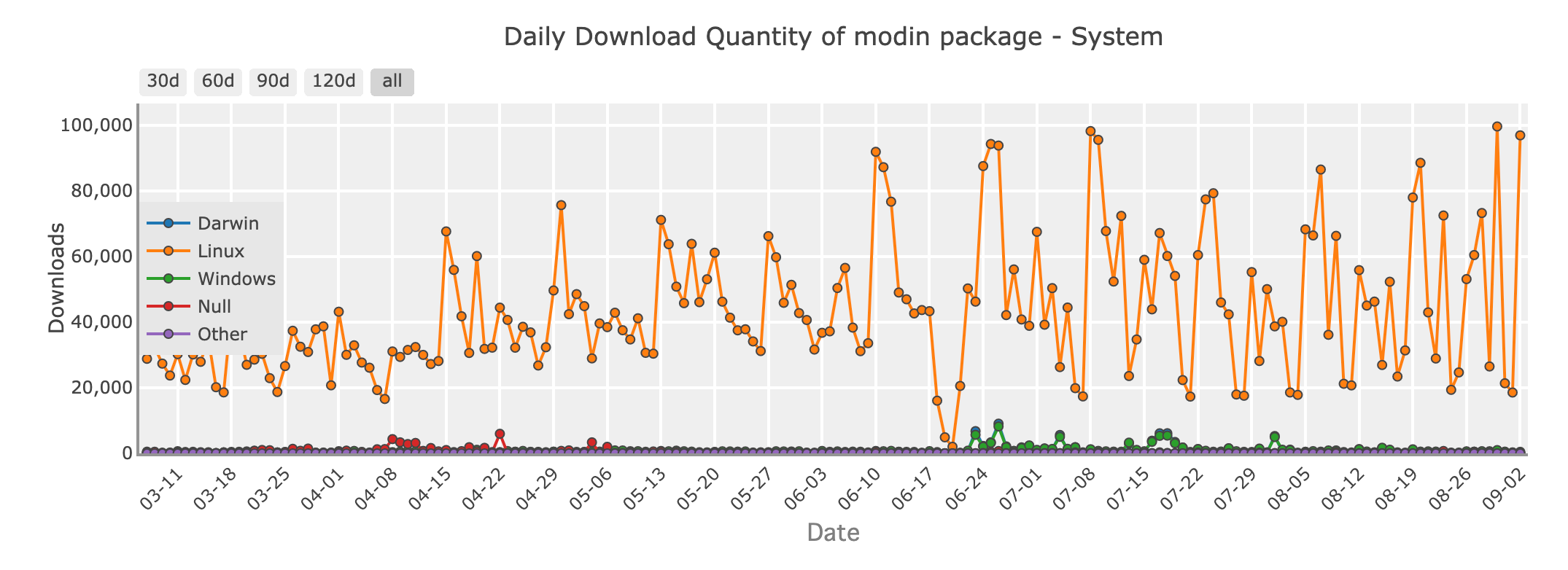
Quantidade de downloads diários do pacote Modin - sistema
Imagine trabalhar com um conjunto de dados muito grande para Pandas lidar eficientemente. Você não quer reescrever todo o seu código, mas precisa de mais velocidade e escalabilidade. Entra o Modin, uma biblioteca projetada para fazer seu código Pandas rodar mais rápido, sem exigir grandes mudanças.
Modin é um substituto direto para Pandas, o que significa que você pode pegar seu código Pandas existente e torná-lo paralelo simplesmente alterando a declaração de importação. Por trás dos bastidores, Modin usa frameworks poderosos como Ray ou Dask para distribuir suas computações em vários núcleos ou até mesmo em um cluster de máquinas. Isso traz tempos de processamento mais rápidos para suas operações de dados.
Com Modin, você obtém a API Pandas familiar que você conhece e ama, mas com a capacidade de lidar com conjuntos de dados maiores e tirar total proveito do seu hardware.
Github stars: 9700
3. Polars: Rapidez e Eficiência Redefinidas
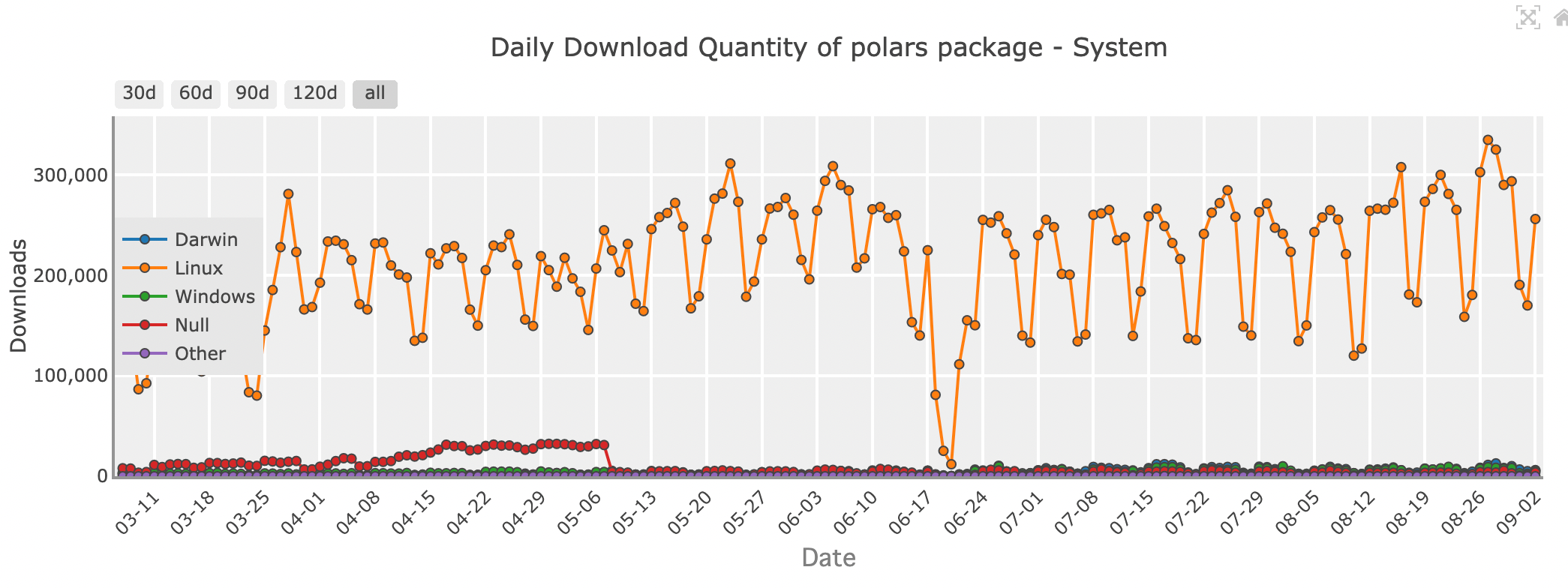
Quantidade de downloads diários do pacote Polars - sistema
Quando se trata de velocidade bruta e eficiência, Polars está causando impacto na comunidade de ciência de dados. Escrito em Rust, uma linguagem de programação conhecida por seu desempenho e segurança, Polars foi projetado para ser rápido—realmente rápido. Se você está lidando com grandes conjuntos de dados ou precisa realizar operações complexas rapidamente, Polars pode ser a biblioteca para você.
Polars usa uma técnica chamada avaliação preguiçosa, onde as operações são executadas apenas quando absolutamente necessário. Isso permite que ele otimize todo o pipeline de computação, minimizando o tempo e os recursos necessários. Além disso, Polars é construído com multithreading em mente, portanto, pode usar eficientemente todos os núcleos em sua máquina, tornando-o uma escolha ideal para tarefas críticas de desempenho.
Embora o Polars apresente uma impressionante velocidade, ele vem com uma curva de aprendizado. Sua API é diferente da Pandas, então pode levar algum tempo para se acostumar. No entanto, para aqueles dispostos a investir tempo, o Polars oferece desempenho incomparável e a capacidade de lidar com conjuntos de dados que simplesmente não seriam viáveis com outras bibliotecas.
Github stars: 29000
| Característica/Aspecto | Pandas | Modin | Polars |
|---|---|---|---|
| Arquitetura | Single-threaded, Python/Cython | Multi-threaded, distribuído (Ray/Dask) | Multi-threaded, escrito em Rust |
| Desempenho | Bom para conjuntos de dados pequenos a médios | Escala em vários núcleos ou clusters | Extremamente rápido, lida com conjuntos de dados grandes |
| Uso de Memória | Uso de memória alto | Semelhante ao Pandas | Uso de memória menor, suporte para dados fora de núcleo |
| Facilidade de Uso | Muito fácil, suporte comunitário extenso | Transição fácil do Pandas | Intuitivo, mas API diferente |
| Ecossistema | Maduro, bem integrado com outras bibliotecas | Compatível com o ecossistema Pandas | Ecossistema menor, mas em crescimento |
| Casos de Uso | Conjuntos de dados pequenos a médios, manipulação de dados | Conjuntos de dados maiores, escalando operações Pandas | Computação de alto desempenho, conjuntos de dados grandes |
| Instalação | pip install pandas | pip install modin[all] | pip install polars |
4. Dask: Um DataFrame Distribuído para Big Data
Quantidade de downloads diários do pacote Dask - sistema
Quando seus dados crescem tanto que não cabem mais na memória, o Dask pode servir como um assistente poderoso. Dask é uma biblioteca de computação paralela que estende a API do Pandas para lidar com conjuntos de dados grandes demais para uma única máquina.
O Dask funciona dividindo seu grande DataFrame em pedaços menores e processando-os em paralelo, seja na sua máquina local ou em um cluster. Isso permite escalar suas computações sem se preocupar com a falta de memória. Se você está trabalhando com big data ou construindo pipelines de dados que precisam escalar para milhares de tarefas, o Dask fornece a flexibilidade e o poder que você precisa.
Github stars: 12400
5. PyArrow: Intercâmbio Rápido de Dados com Apache Arrow
Quantidade de downloads diários do pacote PyArrow - sistema
No reino da engenharia de dados, o PyArrow se destaca como uma biblioteca crucial para o intercâmbio eficiente de dados entre diferentes sistemas. Construído sobre o formato Apache Arrow, PyArrow fornece um maravilhoso formato de memória colunar que permite leituras zero-copy para grandes conjuntos de dados. Isso o torna uma escolha perfeita para cenários onde o desempenho e a interoperabilidade são essenciais.
PyArrow é amplamente utilizado para habilitar a transferência rápida de dados entre linguagens como Python, R e Java, e desempenha um papel crucial em muitos frameworks de processamento de big data. Se você está lidando com pipelines de dados em larga escala, particularmente onde os dados precisam ser compartilhados entre diferentes ferramentas ou plataformas, PyArrow é uma ferramenta valiosa no seu arsenal.
Github stars: 14200
6. Snowpark: DataFrames na Nuvem com Snowflake
Quantidade de downloads diários do pacote Snowpark - sistema
À medida que mais organizações movem suas operações de dados para a nuvem, o Snowpark surge como uma solução inovadora para desenvolvedores Python. Snowpark é um recurso do Snowflake, um data warehouse baseado em nuvem, que permite usar operações no estilo DataFrame diretamente dentro do ambiente Snowflake. Isso significa que você pode operar transformações e análises de dados complexas sem mover seus dados para fora do Snowflake, reduzindo a latência e aumentando a eficiência.
Com Snowpark, você pode escrever código Python que roda nativamente na infraestrutura do Snowflake, aproveitando o poder da nuvem para processar conjuntos de dados massivos facilmente. É uma excelente escolha para equipes que já usam o Snowflake e buscam simplificar seus fluxos de trabalho de processamento de dados.
Github stars: 253
7. Xorbits: Uma Solução Unificada para Escalar Ciência de Dados
Quantidade de downloads diários do pacote Xorbits - sistema
Xorbits é um framework poderoso projetado para escalar operações de ciência de dados em ambientes distribuídos. Ele oferece uma API unificada que abstrai as complexidades da computação distribuída, permitindo que você escale suas operações de DataFrame em vários nós sem precisar se preocupar com a infraestrutura subjacente.
Xorbits integra-se facilmente com ferramentas existentes como Pandas, Dask e PyTorch, tornando-o uma escolha ideal para aplicações de aprendizado de máquina e ciência de dados que requerem flexibilidade. Se você está treinando grandes modelos ou processando grandes quantidades de dados, Xorbits fornece a flexibilidade e o poder para lidar com a tarefa.
Github stars: 1100
8. Vaex: DataFrames Fora do Núcleo para Análise Eficiente
Quantidade de downloads diários do pacote Vaex - sistema
Se você está lidando com conjuntos de dados enormes que excedem a memória do seu sistema, mas ainda quer a simplicidade do Pandas, o Vaex vale a pena explorar. Vaex é projetado para computação fora do núcleo, o que significa que ele pode lidar com conjuntos de dados maiores que sua RAM, processando os dados em pedaços, sem carregar tudo na memória de uma só vez.
Vaex é otimizado para velocidade e oferece recursos como filtragem rápida, agrupamento e agregação, tudo mantendo o uso de memória no mínimo. É especialmente útil para tarefas como exploração de dados, análise estatística e até mesmo aprendizado de máquina em grandes conjuntos de dados.
Github stars: 8200
9. Koalas: Trazendo Pandas para Big Data com Apache Spark
Quantidade de downloads diários do pacote Koalas - sistema
Para desenvolvedores Python que trabalham no mundo do big data, Apache Spark é um nome familiar. Koalas é uma biblioteca que conecta o Pandas ao Spark, permitindo que você use sintaxe semelhante ao Pandas em conjuntos de dados distribuídos gerenciados pelo Spark. Isso significa que você pode aproveitar a escalabilidade do Spark enquanto escreve código que se parece com o Pandas.
Koalas é uma ótima opção se você está fazendo a transição do Pandas para ambientes de big data, pois minimiza a curva de aprendizado associada ao Spark e permite que você escreva código que escala sem perder a simplicidade do Pandas.
Github stars: 3300
Escolhendo a Ferramenta Certa para o Trabalho
Com tantas opções disponíveis, como escolher a biblioteca de DataFrame certa para seu projeto? Aqui estão algumas diretrizes:
- Conjuntos de Dados Pequenos a Médios: Se seus dados cabem confortavelmente na memória, Pandas ainda é a melhor escolha por sua facilidade de uso e funcionalidade rica.
- Escalando Pandas: Se você está encontrando gargalos de desempenho com o Pandas, mas não quer mudar seu código, Modin oferece um caminho fácil para execuções mais rápidas.
- Tarefas Críticas de Desempenho: Para necessidades de alto desempenho e grandes conjuntos de dados, Polars oferece uma velocidade e eficiência impressionantes devido ao seu design leve, tornando-o particularmente eficaz em dispositivos locais. No entanto, é importante notar que o Polars não é projetado principalmente para processamento de dados distribuído em grande escala, onde soluções como Modin podem ser mais apropriadas.
- Big Data e Computação Distribuída: Ao trabalhar com big data, Dask, Koalas e Xorbits são ótimas escolhas para escalar suas computações em várias máquinas.
- Interoperabilidade e Compartilhamento de Dados: Se você precisa de um intercâmbio de dados eficiente entre diferentes sistemas ou linguagens, PyArrow é a biblioteca ideal.
- Operações Baseadas em Nuvem: Para aqueles que aproveitam a infraestrutura de nuvem, Snowpark oferece integração perfeita com Snowflake, permitindo poderosas computações dentro do banco de dados.
Seja trabalhando com pequenos conjuntos de dados ou enfrentando pipelines de dados distribuídos massivos, há uma biblioteca Python para atender às suas necessidades. Ao explorar essas bibliotecas de DataFrame de código aberto, você estará melhor equipado para aproveitar ao máximo seus dados, independentemente do tamanho ou complexidade.
Então, vá em frente—mergulhe no mundo dos DataFrames e desbloqueie o poder do Python para sua próxima aventura orientada por dados!