Visualização do Pandas: Um Tutorial Passo a Passo
- Name
- Rajiv Chandra
Atualizado em
A biblioteca Pandas do Python é uma ferramenta poderosa que cientistas de dados e analistas de todo o mundo usam diariamente. Uma de suas características mais convincentes são suas capacidades de visualização de dados robustas. Este artigo irá guiá-lo pelo processo de criação de gráficos convincentes usando o Pandas, fornecendo as habilidades necessárias para transformar dados brutos em gráficos perspicazes.
A plotagem do Pandas não se trata apenas de tornar seus dados bonitos. Trata-se de desvendar as histórias ocultas dentro dos números. Se você está explorando um novo conjunto de dados ou se preparando para compartilhar suas descobertas mais recentes, as visualizações são essenciais para comunicar insights baseados em dados.
Com certeza, vamos nos aprofundar em cada segmento com explicações mais detalhadas e trechos de código de amostra.
Use a Função de Plotagem para Visualização do Pandas
O Pandas fornece uma estrutura de dados de alto nível, flexível e eficiente chamada DataFrame, que é extremamente propícia para visualização. Com a função .plot(), você pode gerar uma variedade de gráficos como linha, barra, dispersão e outros. Essa função é um invólucro sobre a versátil biblioteca Matplotlib, facilitando a criação de visualizações complexas.
Por exemplo, se você está apenas começando sua jornada com o Pandas, em breve estará criando gráficos de linha básicos que podem revelar tendências valiosas em seus dados. Gráficos de linha são excelentes para mostrar dados ao longo do tempo, tornando-os perfeitos para análise de dados de séries temporais.
Aqui está um exemplo simples de como criar um gráfico de linha com o Pandas:
import pandas as pd
import numpy as np
# Criar um DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
df.plot(kind='line')Neste código, primeiro importamos as bibliotecas necessárias. Em seguida, criamos um DataFrame com duas colunas, cada uma preenchida com números aleatórios. Por fim, usamos a função .plot() para criar um gráfico de linha.
Mas e se você quiser usar uma interface visual para plotar Dataframes do Pandas sem código? Bem, felizmente existe um Dataframe do Pandas que pode ajudar a resolver o problema:
Use o PyGWalker para Visualização do Pandas
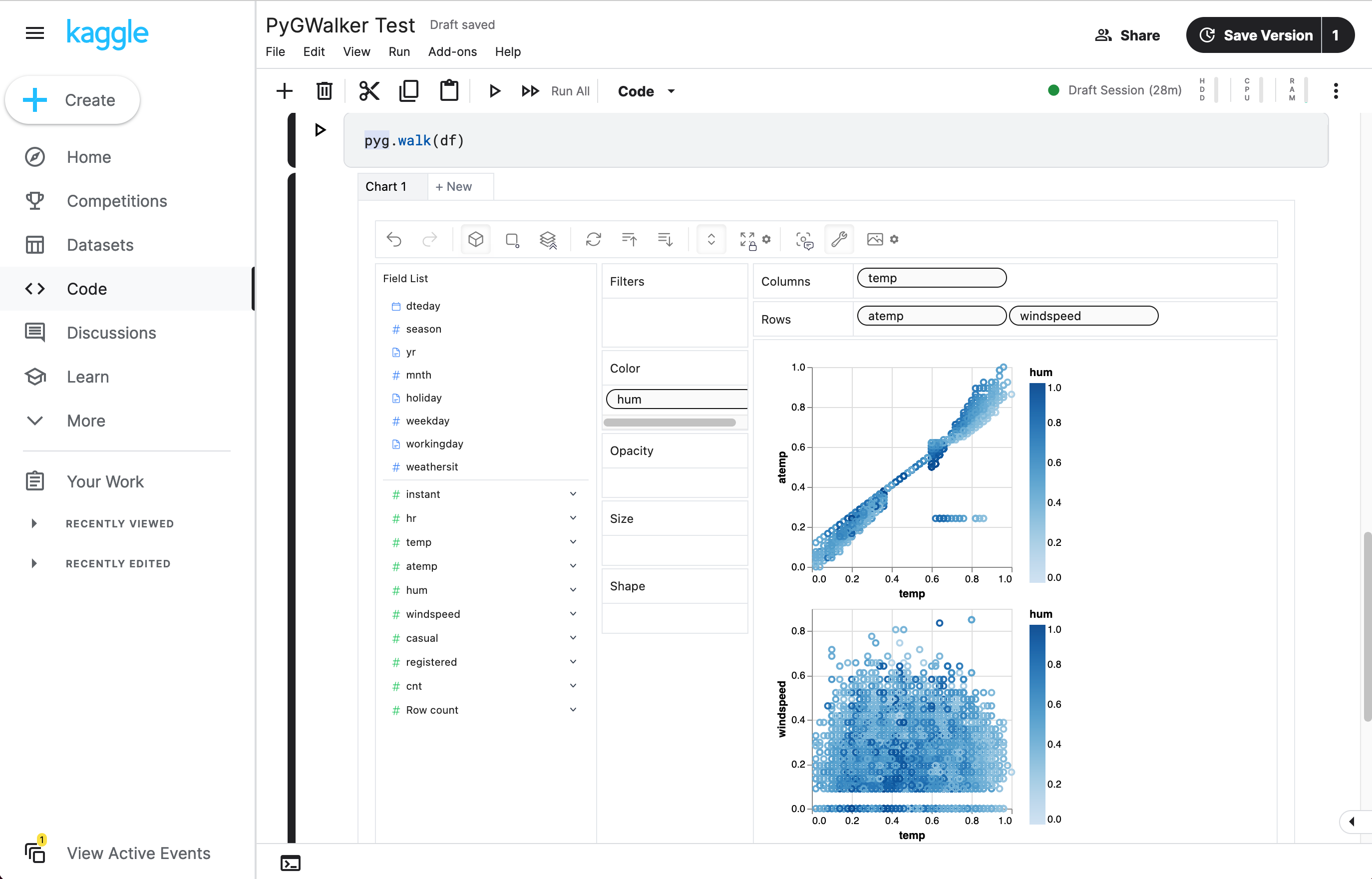
O PyGWalker é uma biblioteca Python desenvolvida para Análise Exploratória de Dados e Visualização de Dados Fácil. Pense nele como a execução de um Tableau de código aberto dentro do seu Jupyter Notebook. Você pode facilmente criar visualizações arrastando e soltando variáveis em vez de consultar tutoriais de codificação complexos:
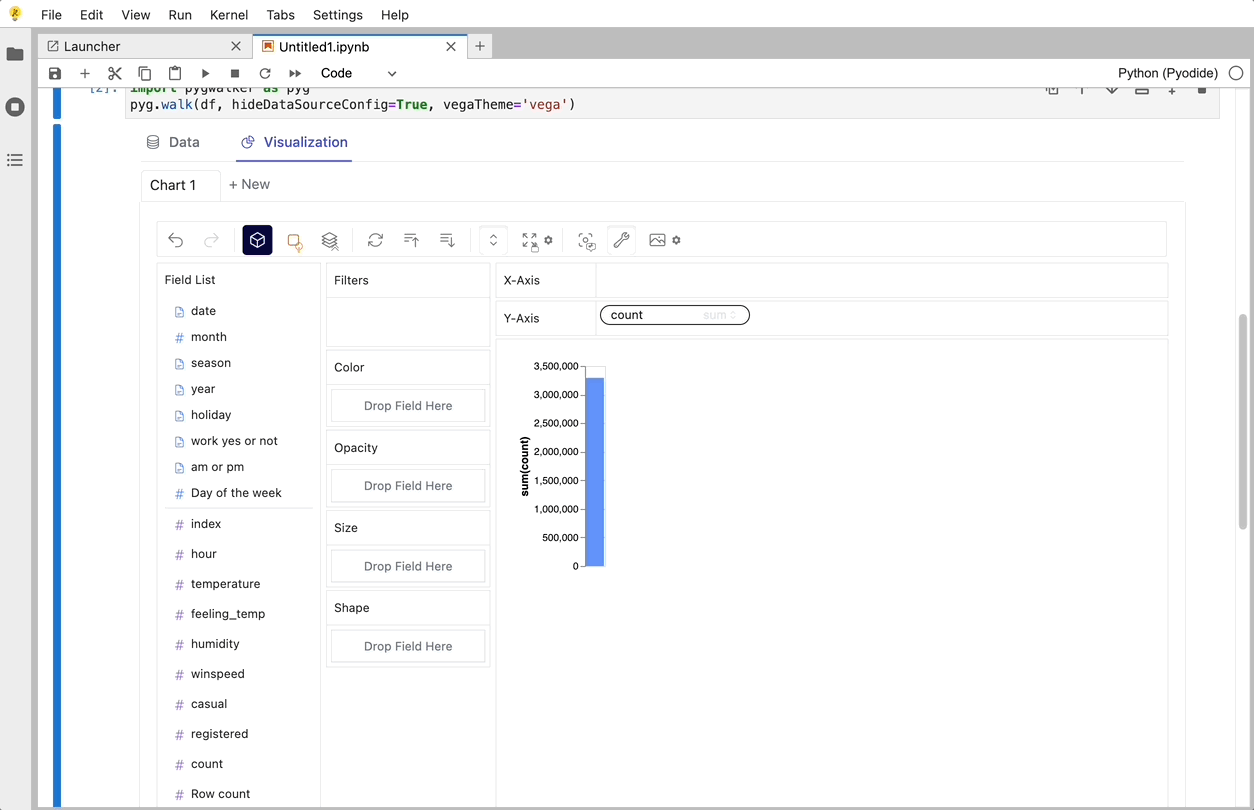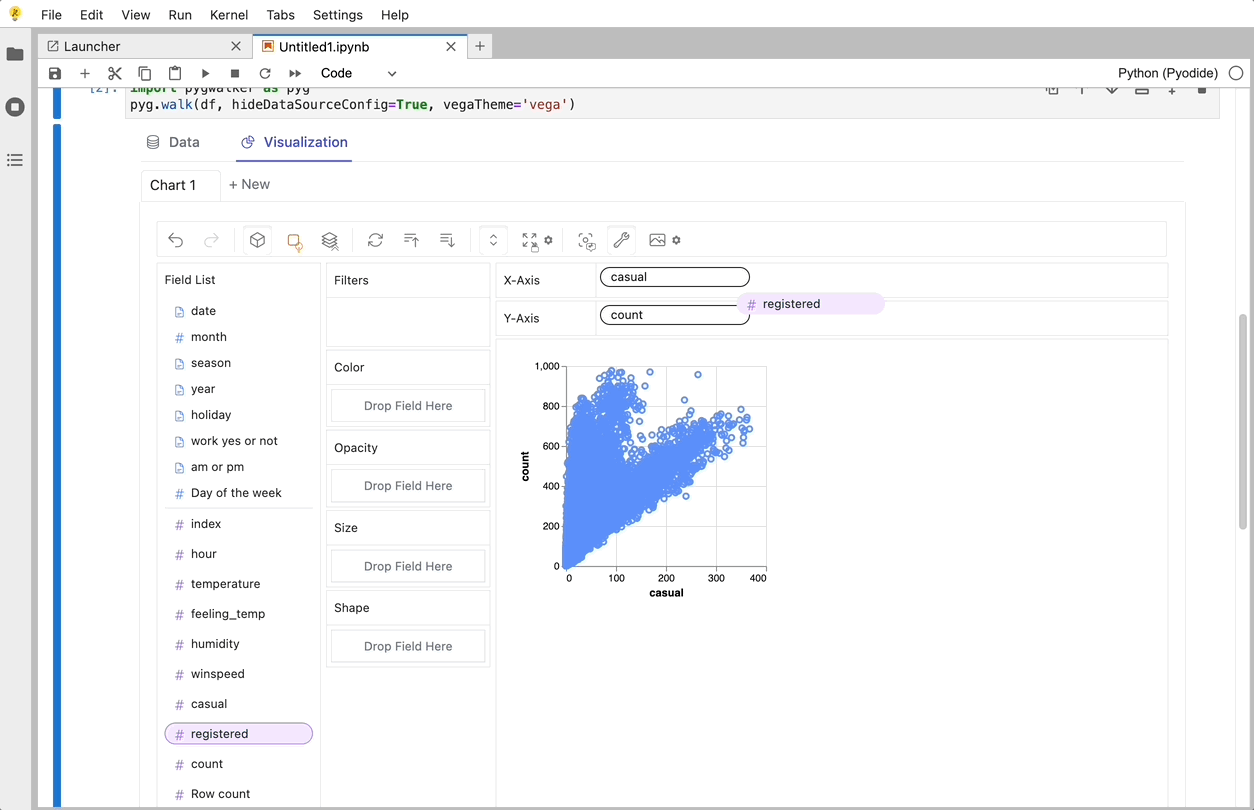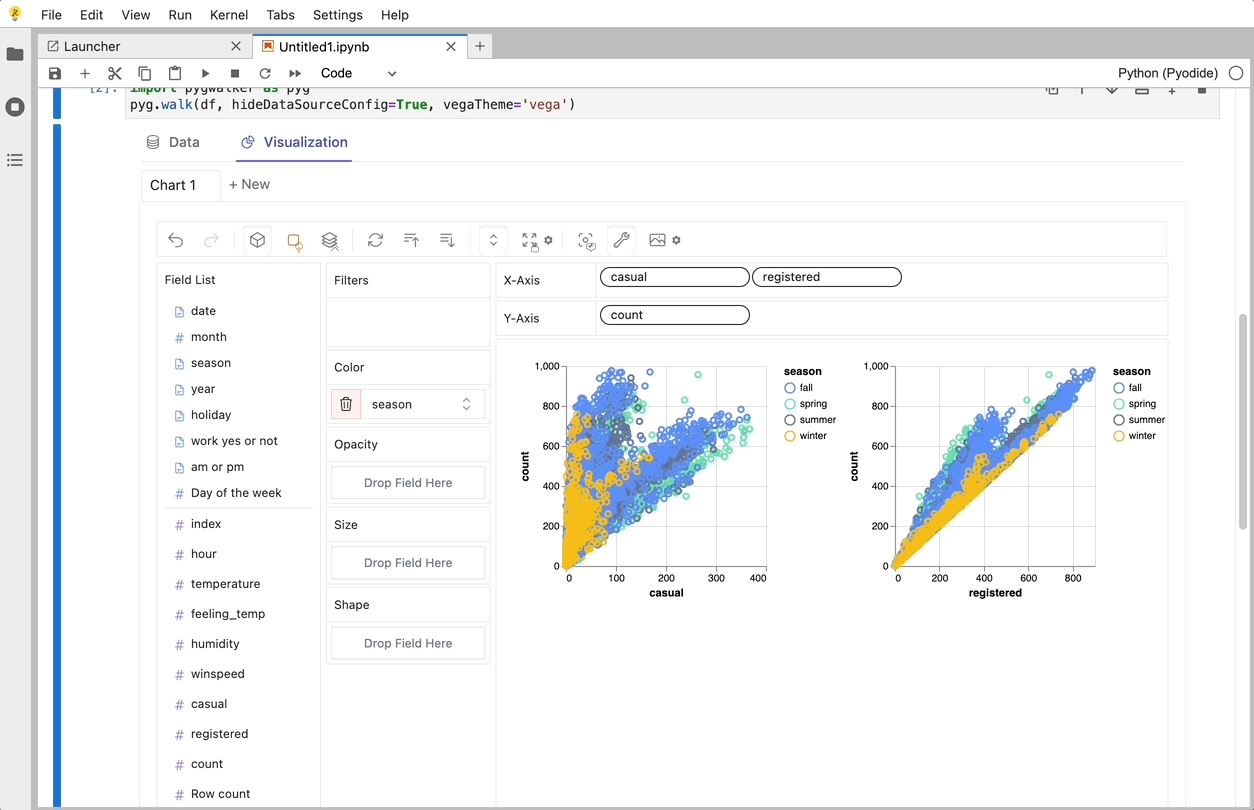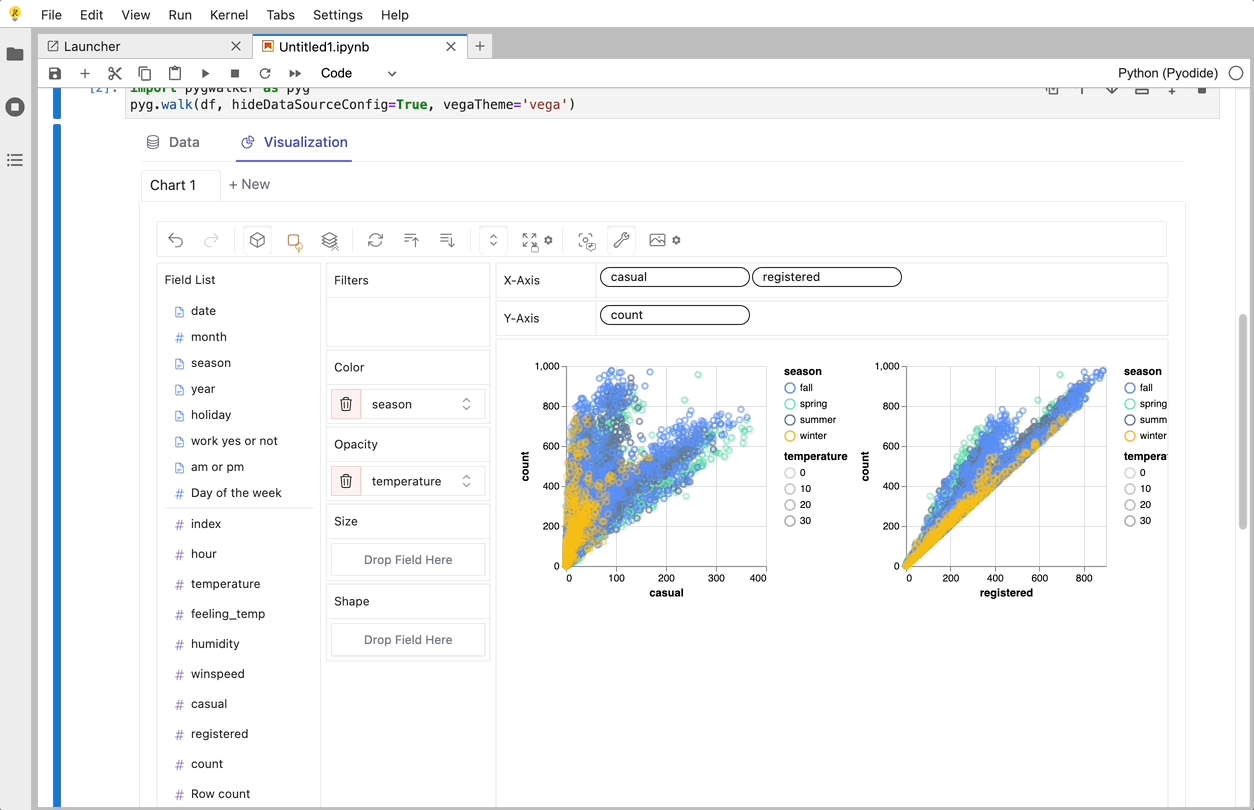
Veja como você pode começar rapidamente:
Importe o pygwalker e o pandas para o seu Jupyter Notebook para começar.
import pandas as pd
import pygwalker as pygVocê pode usar o pygwalker sem interromper seu fluxo de trabalho existente. Por exemplo, você pode chamar o Graphic Walker com o dataframe carregado dessa maneira:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)E você pode usar o pygwalker com o polars (desde pygwalker>=0.1.4.7a0):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Agora você carregou seu Pandas Dataframe para Visualização.
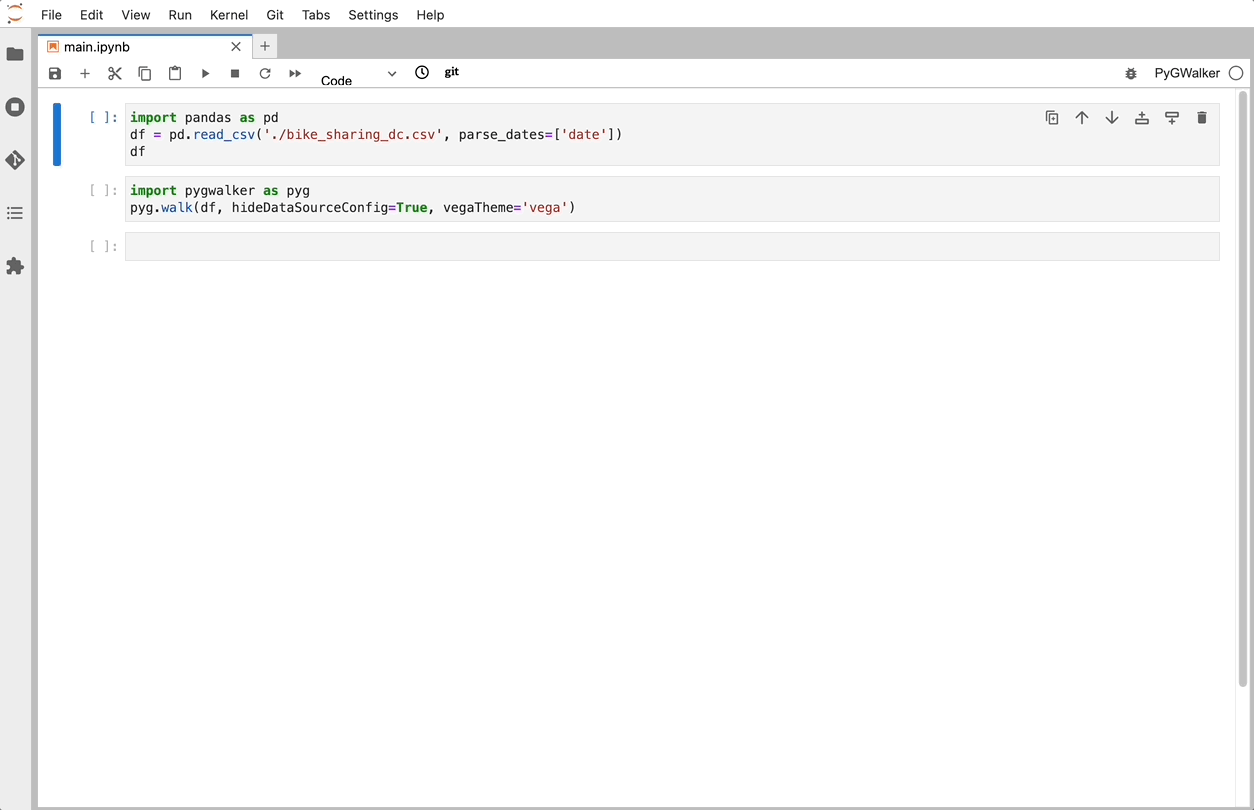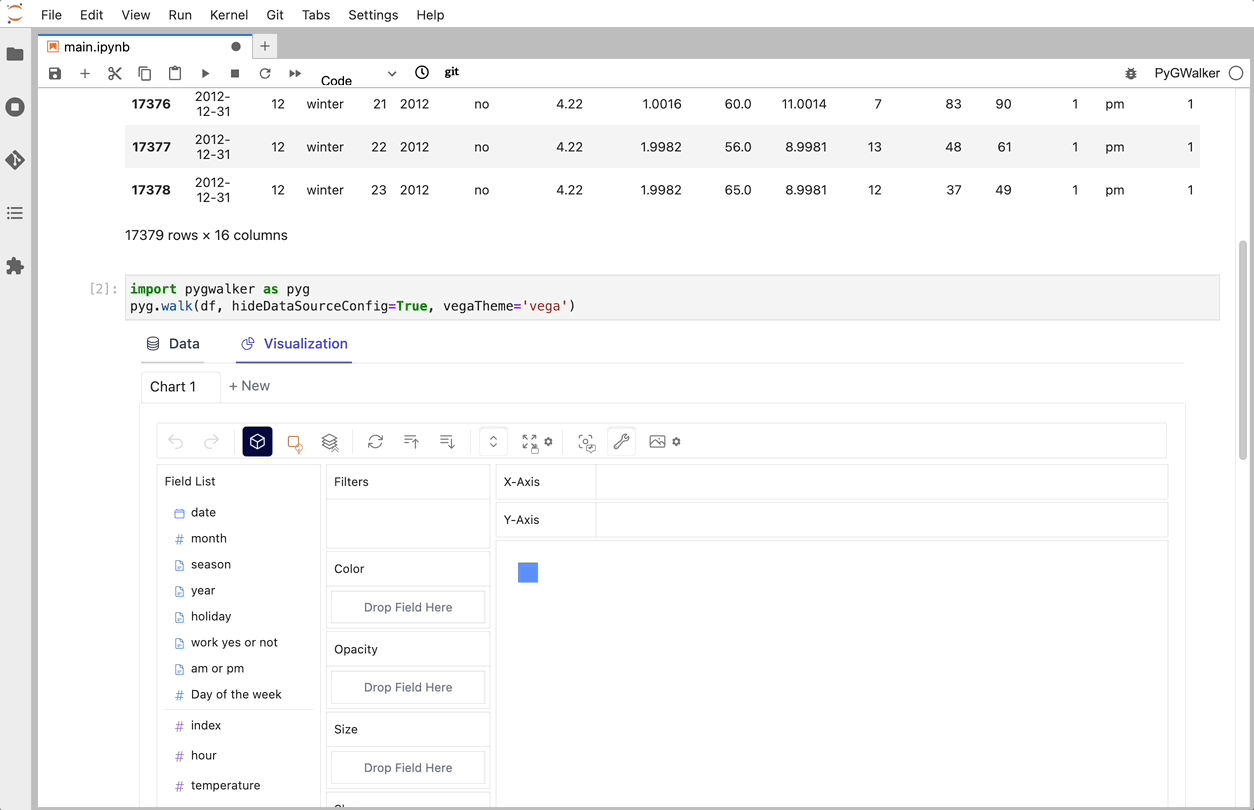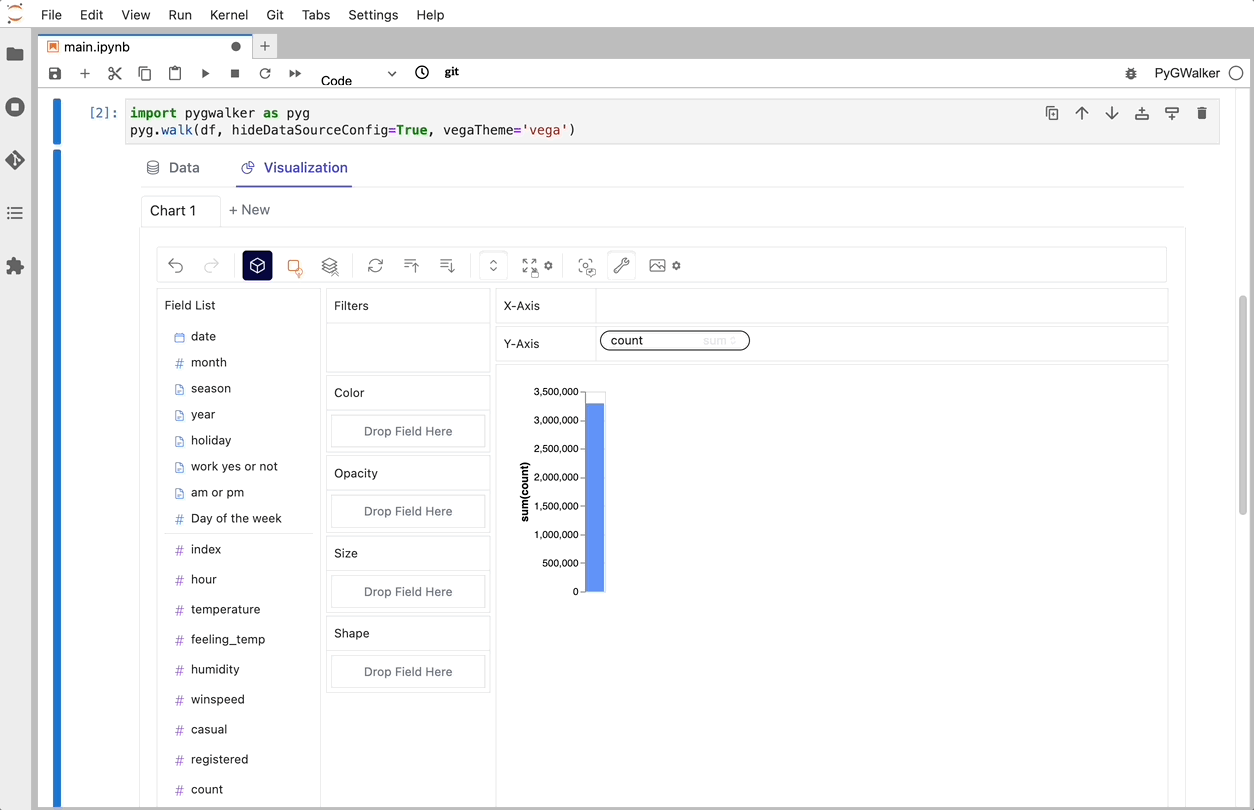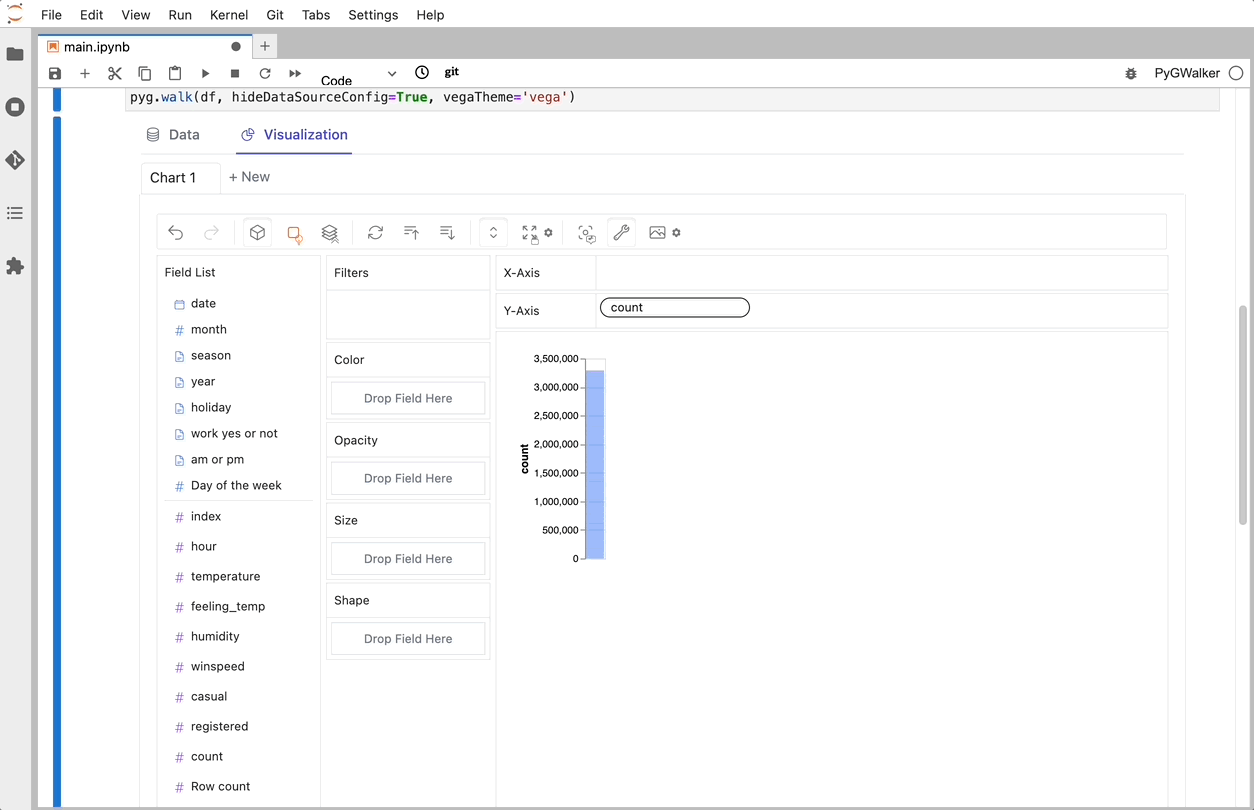
Isso é tudo. Agora você tem uma interface de usuário semelhante ao Tableau para analisar e visualizar dados arrastando e soltando variáveis.
O PyGWalker é apoiado por uma comunidade ativa de desenvolvedores e cientistas de dados. Visite o PyGWalker GitHub (opens in a new tab) e deixe uma ⭐️!
Você pode experimentar o PyGWalker com o Google Colab ou o Notebook do Kaggle agora mesmo:
| Executar no Kaggle (opens in a new tab) | Executar no Colab (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 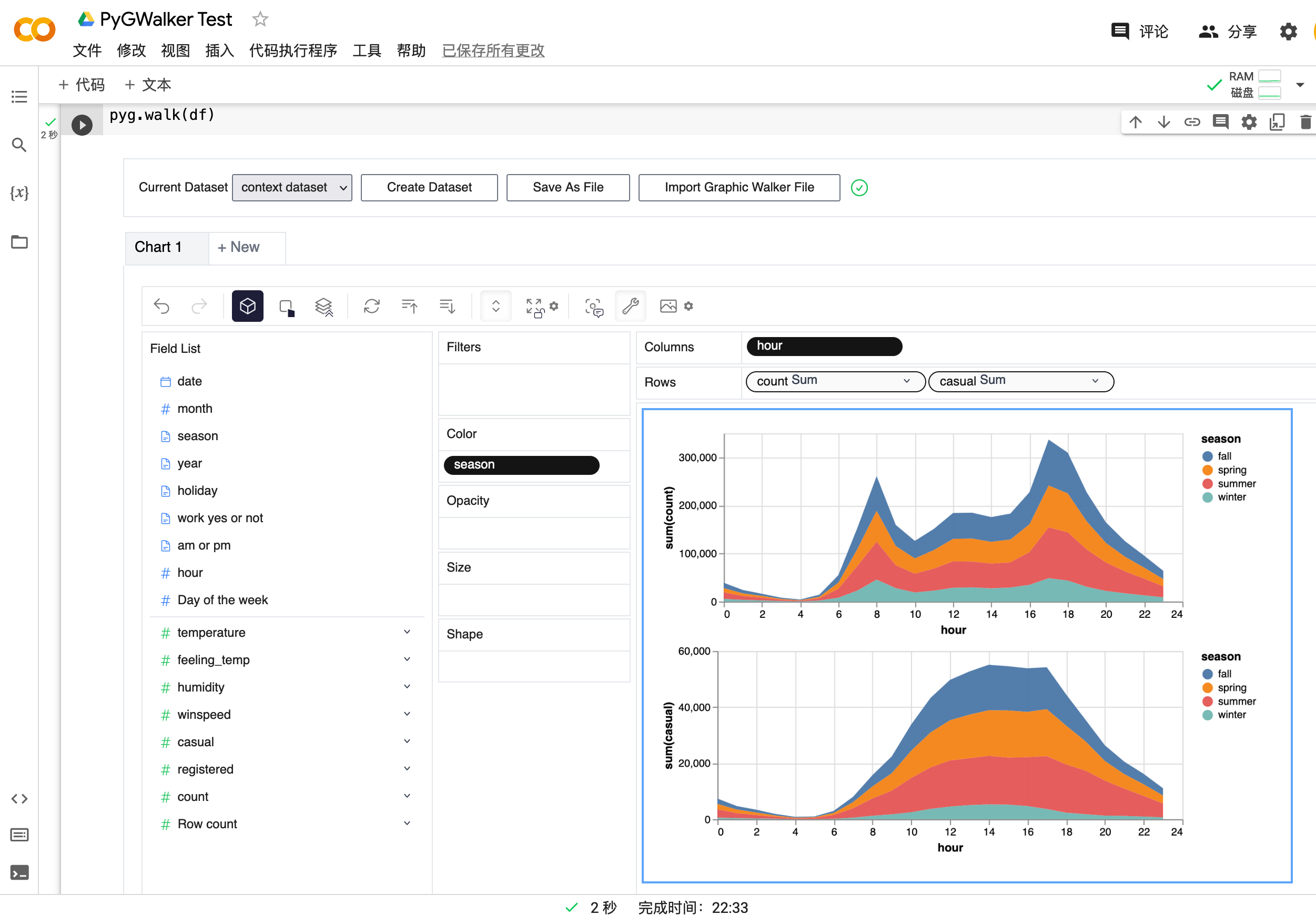 (opens in a new tab) (opens in a new tab) |
Mergulhando em Diferentes Tipos de Gráficos
O Pandas oferece uma variedade de tipos de gráficos, cada um adequado a diferentes tipos de dados e perguntas diferentes. Por exemplo, histogramas são ótimos para obter uma visão geral da distribuição dos seus dados, enquanto gráficos de dispersão podem ajudar a descobrir correlações entre diferentes pontos de dados.
Cada tipo de gráfico no Pandas possui um conjunto de parâmetros que você pode ajustar para personalizar sua visualização. Compreender esses parâmetros e quando usá-los pode aumentar muito sua capacidade de criar visualizações significativas.
Aqui está como você pode criar um histograma e um gráfico de dispersão:
# Histograma
df['A'].plot(kind='hist')
# Gráfico de dispersão
df.plot(kind='scatter', x='A', y='B')No primeiro gráfico, estamos criando um histograma da coluna 'A'. No segundo gráfico, estamos criando um gráfico de dispersão com 'A' no eixo x e 'B' no eixo y.
Manipulando Dados Categóricos com o Pandas
Dados categóricos são um tipo comum de dados que você encontrará em muitos conjuntos de dados. O Pandas fornece várias ferramentas poderosas para visualizar esse tipo de dados. Por exemplo, gráficos de barras podem ajudá-lo a comparar diferentes categorias, enquanto gráficos de pizza são excelentes para visualizar as proporções entre as categorias.
Além disso, o Pandas permite agrupar seus dados com base em categorias, o que pode ser incrivelmente útil quando você deseja agregar seus dados e obter insights no nível da categoria.
Aqui está um exemplo de como criar um gráfico de barras e um gráfico de pizza:
# Criar um DataFrame com dados categóricosimport pandas as pd
import numpy as np
df = pd.DataFrame({
'Fruta': ['Maçã', 'Banana', 'Cereja', 'Maçã', 'Cereja', 'Banana', 'Maçã', 'Cereja', 'Banana', 'Maçã'],
'Quantidade': np.random.randint(1, 10, 10)
})
# Gráfico de barras
df.groupby('Fruta')['Quantidade'].sum().plot(kind='bar')
# Gráfico de pizza
df.groupby('Fruta')['Quantidade'].sum().plot(kind='pie')Neste código, primeiro criamos um DataFrame com dados categóricos. Em seguida, agrupamos os dados pela coluna 'Fruta' e somamos a 'Quantidade' para cada fruta. Por fim, criamos um gráfico de barras e um gráfico de pizza das quantidades somadas.
Personalizando seus gráficos
Uma das características mais poderosas da visualização do Pandas é a capacidade de personalizar seus gráficos. Isso inclui a alteração da cor e estilo dos gráficos, a adição de rótulos e títulos, e muito mais.
Aqui está um exemplo de como personalizar um gráfico de linha:
import pandas as pd
import numpy as np
# Criar um DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
# Criar um gráfico de linha com personalizações
df.plot(kind='line',
color=['red', 'blue'],
style=['-', '--'],
title='Meu Gráfico de Linha',
xlabel='Índice',
ylabel='Valor')Neste código, primeiro criamos um DataFrame com duas colunas, cada uma preenchida com números aleatórios. Em seguida, criamos um gráfico de linha e personalizamos definindo a cor e estilo das linhas, e adicionando um título e rótulos para os eixos x e y.
Lidando com estruturas de dados mais complexas
O Pandas não se limita a lidar com estruturas de dados simples. Ele também pode lidar com estruturas de dados mais complexas, como DataFrames com múltiplos índices e dados de séries temporais.
Aqui está um exemplo de como criar um gráfico de linha a partir de um DataFrame com múltiplos índices:
import pandas as pd
import numpy as np
# Criar um DataFrame com múltiplos índices
index = pd.MultiIndex.from_tuples([(i,j) for i in range(5) for j in range(5)])
df = pd.DataFrame({
'A': np.random.rand(25),
'B': np.random.rand(25)
}, index=index)
# Criar um gráfico de linha
df.plot(kind='line')Neste código, primeiro criamos um DataFrame com múltiplos índices, com duas colunas preenchidas com números aleatórios. Em seguida, criamos um gráfico de linha a partir deste DataFrame.
Visualização avançada com Seaborn
Embora o Pandas forneça uma base sólida para visualização de dados, às vezes você pode precisar de ferramentas mais avançadas. O Seaborn é uma biblioteca de visualização de dados em Python baseada no Matplotlib que fornece uma interface de alto nível para criar visualizações bonitas e informativas.
Aqui está um exemplo de como criar um gráfico Seaborn a partir de um DataFrame do Pandas:
import pandas as pd
import seaborn as sns
# Carregar o DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Criar um gráfico Seaborn
sns.lineplot(data=df, x='date', y='count')Neste código, primeiro importamos a biblioteca Seaborn. Em seguida, carregamos um DataFrame e criamos um gráfico de linha com a coluna 'date' no eixo x e a coluna 'count' no eixo y.
Visualização interativa com Plotly
Para visualizações interativas, o Plotly é uma ótima escolha. O Plotly é uma biblioteca de gráficos em Python que cria gráficos interativos e de qualidade para publicação.
Aqui está um exemplo de como criar um gráfico Plotly a partir de um DataFrame do Pandas:
import pandas as pd
import plotly.express as px
# Carregar o DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Criar um gráfico Plotly
fig = px.line(df, x='date', y='count')
fig.show()Neste código, primeiro importamos o módulo Plotly Express. Em seguida, carregamos um DataFrame e criamos um gráfico de linha com a coluna 'date' no eixo x e a coluna 'count' no eixo y. O comando fig.show() exibe o gráfico interativo.
Conclusão
O Pandas é uma ferramenta poderosa para análise e visualização de dados em Python. Com suas capacidades robustas de plotagem e compatibilidade com outras bibliotecas de visualização como Matplotlib, Seaborn, Plotly e PyGWalker, você pode criar uma ampla variedade de visualizações para obter insights dos seus dados. Seja você um iniciante começando ou um cientista de dados experiente, dominar a visualização do Pandas é uma habilidade valiosa que permitirá aprimorar seu fluxo de trabalho de análise de dados.
FAQs
-
O que é o Pandas em Python?
- O Pandas é uma biblioteca de software escrita para a linguagem de programação Python, utilizada para manipulação e análise de dados. Ele fornece estruturas de dados e funções necessárias para manipular dados estruturados.
-
Como o Pandas é usado para visualização de dados?
- O Pandas fornece visualização de dados permitindo o uso de sua função plot() e vários métodos de plotagem para plotar dados diretamente de objetos DataFrame e Series.
-
Quais são algumas das bibliotecas de visualização de dados mais populares do Pandas?
- Algumas das bibliotecas mais populares para visualização de dados no Pandas incluem Matplotlib, Seaborn, Plotly e PyGWalker. Essas bibliotecas oferecem uma variedade de ferramentas e funcionalidades para criar gráficos estáticos, animados e interativos em Python.