Qwen3-VL: IA Multimodal Open Source con Visión Avanzada

TL;DR — Qwen acaba de lanzar Qwen3‑VL, la nueva serie visión‑lenguaje de pesos abiertos. El buque insignia Qwen3‑VL‑235B‑A22B (Instruct + Thinking) es abierto bajo Apache‑2.0, con contexto nativo de 256K (extensible a 1M), razonamiento espacial/vídeo más fuerte y OCR en 32 idiomas. No se limita al reconocimiento, sino que apunta a un razonamiento multimodal más profundo y a control de UI agentic. Es enorme (~471 GB de pesos), así que la mayoría de equipos empezarán vía APIs o inferencia alojada. (GitHub (opens in a new tab))
Qué se lanzó (y por qué importa)
Qwen3‑VL es la última familia visión‑lenguaje del equipo Qwen. El repo y las model cards destacan mejoras en comprensión de texto, percepción/razonamiento visual, comprensión de vídeo de largo contexto y en interacción como agente (p. ej., operar GUIs de PC/móvil). A nivel de arquitectura, introduce Interleaved‑MRoPE para vídeo de largo horizonte, DeepStack para fusión ViT multinivel y Text–Timestamp Alignment para modelado temporal preciso en vídeo. (GitHub (opens in a new tab))
La primera liberación de pesos abiertos es el modelo MoE de ≈235B parámetros (A22B = ~22B expertos activos por token), disponible en ediciones Instruct y Thinking y con licencia Apache‑2.0. El modelo enfatiza razonamiento en STEM/multimodal, percepción espacial/2D–3D grounding, comprensión de vídeo largo y OCR en 32 idiomas. (Hugging Face (opens in a new tab))
Fecha de lanzamiento: Qwen lista los pesos de Qwen3‑VL‑235B‑A22B Instruct y Thinking como lanzados el 23 de septiembre de 2025. (GitHub (opens in a new tab))
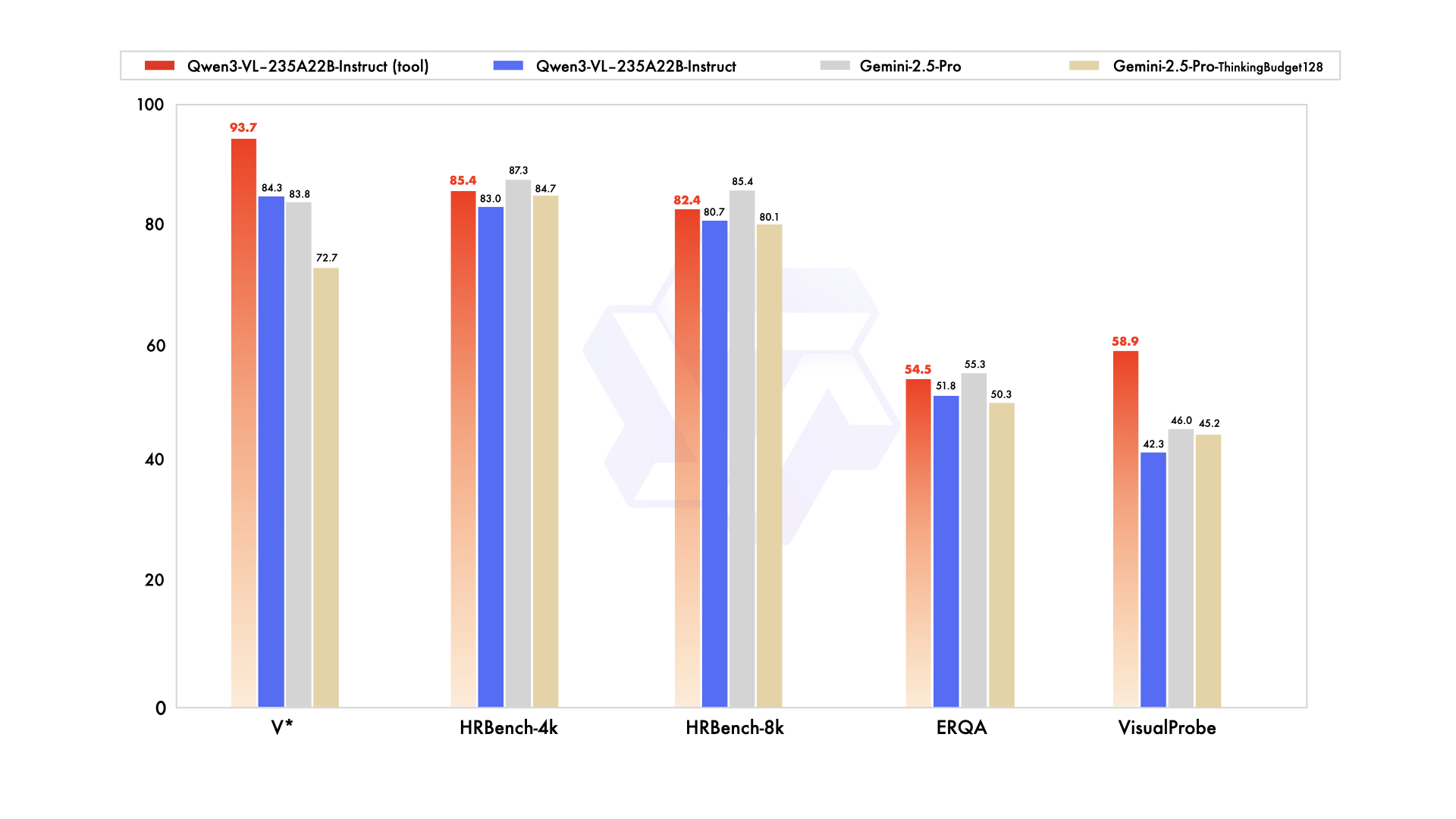
Especificaciones clave de un vistazo
| Capacidad | Detalle de Qwen3‑VL |
|---|---|
| Open‑weight variants | 235B A22B Instruct y Thinking (Apache‑2.0) |
| Context length | 256K nativo, ampliable a 1M (guía de Qwen) |
| Vision/Video | Razonamiento espacial mejorado, grounding temporal en vídeo de larga duración |
| OCR | 32 idiomas, robusto a poca luz/desenfoque/inclinación |
| Agentic | Puede leer GUIs y planificar acciones para tareas en PC/móvil |
| Size | Las fichas de HF informan ≈236B parámetros; la comunidad señala ~471 GB de pesos |
| Framework support | Integración oficial con Transformers desde mediados de sept. 2025 |
Fuentes: repo+cards para funciones/ediciones, longitud de contexto y claims de agente; docs de HF para integración con Transformers; Simon Willison sobre el tamaño práctico de los pesos. (GitHub (opens in a new tab))
¿Qué es nuevo frente a Qwen2.5‑VL?
- Modelado temporal y espacial más nítido: Interleaved‑MRoPE + Text–Timestamp Alignment buscan localizar eventos en vídeos largos con más precisión que enfoques T‑RoPE previos. DeepStack afina la alineación imagen‑texto de grano fino. (GitHub (opens in a new tab))
- Contexto más largo y envolvente multimodal más amplio: 256K tokens por defecto con ruta de expansión a 1M; mejor comprensión de GUI, documentos y vídeo largo. (GitHub (opens in a new tab))
- Ediciones más grandes afinadas para razonamiento: las versiones Thinking se orientan a tareas de razonamiento multimodal; Qwen afirma rendimiento competitivo o superior a baselines multimodales propietarios en algunos benchmarks (autoinformados). (Simon Willison’s Weblog (opens in a new tab))
El blog y publicaciones sociales de Qwen afirman paridad/ventaja frente a Gemini 2.5 Pro en benchmarks de percepción clave y SOTA en varios conjuntos de razonamiento multimodal—vale la pena una verificación independiente. (Simon Willison’s Weblog (opens in a new tab))

Artefactos de lanzamiento y dónde ejecutarlo
-
GitHub: fragmentos de código (Transformers), cookbooks (OCR, grounding, video, agents). El paper está “en camino”. (GitHub (opens in a new tab))
-
Hugging Face:
- Qwen3‑VL‑235B‑A22B‑Instruct (Apache‑2.0) (Hugging Face (opens in a new tab))
- Qwen3‑VL‑235B‑A22B‑Thinking (Apache‑2.0) (Hugging Face (opens in a new tab))
-
Transformers support: Qwen3‑VL llegó a la documentación de Transformers a mediados de sept. 2025. (Hugging Face (opens in a new tab))
-
Hosted options: OpenRouter lista Qwen3‑VL 235B para uso vía API; Model Studio de Alibaba Cloud ofrece SKUs de API Qwen‑Plus/Qwen3‑VL‑Plus con modos thinking vs non‑thinking y diferentes precios. (OpenRouter (opens in a new tab))
Nota sobre nombres: Lectores de HN señalan que Qwen3‑VL‑Plus (API) y Qwen‑VL‑Plus (serie anterior) son diferentes, y que el esquema de snapshots como qwen‑plus‑2025‑09‑11 puede confundir a recién llegados. No estás solo. (Hacker News (opens in a new tab))
Benchmarks (léase con cautela)
Los canales de anuncio de Qwen afirman que Instruct “iguala/supera” a Gemini 2.5 Pro en pruebas centradas en percepción y que Thinking logra SOTA en varios suites de razonamiento multimodal. Estas cifras son autoinformadas; las evaluaciones independientes importarán, especialmente en comprensión de gráficos/tablas, razonamiento con diagramas y video QA, donde la curación de datos puede inclinar resultados. (Simon Willison’s Weblog (opens in a new tab))
Dicho esto, notas tempranas de la comunidad comparan Qwen3‑Omni → Qwen3‑VL‑235B en conjuntos compartidos (p. ej., HallusionBench, MMMU‑Pro, MathVision) y sugieren mejoras significativas—de nuevo, aún no revisadas por pares. (Reddit (opens in a new tab))
Por qué la academia sigue eligiendo Qwen (y probablemente adoptará Qwen3‑VL rápido)
Aunque muchas apps de negocio se inclinan por GPT/Claude/Gemini por conveniencia y SLAs, los grupos de investigación a menudo necesitan pesos abiertos para reproducibilidad, auditoría, ablaciones y fine‑tuning por dominio. El catálogo de Qwen lo ha facilitado:
- Pesos abiertos en múltiples escalas (desde <2B hasta 235B+ MoE), lo que permite experimentar en GPUs de laboratorio y escalar después. (Qwen (opens in a new tab))
- Licenciamiento permisivo (Apache‑2.0 en muchos checkpoints) reduce fricción para colaboración academia/industria. (Hugging Face (opens in a new tab))
- Uso demostrado en papers: p. ej., BioQwen (modelos biomédicos bilingües); RCP‑Merging que usa bases Qwen2.5 para estudiar long CoT/domain merging; múltiples trabajos de RL‑tuning en VLM médicos parten de Qwen2.5. (ciblab.net (opens in a new tab))
Con Qwen3‑VL sumando mejoras en vídeo largo y grounding espacial y manteniéndose de pesos abiertos, es de esperar que se convierta en un baseline por defecto para proyectos académicos multimodales, en particular en inteligencia documental, diagramas científicos, medical VQA e investigación embodied/agentic.
Para equipos de producto: guía práctica
- Empieza alojado y luego optimiza: El modelo insignia es enorme (notas de la comunidad: ~471 GB de pesos). A menos que tengas clústeres multi‑GPU (A100/H100/MI300), comienza vía API (p. ej., OpenRouter, Model Studio de Alibaba) y reevalúa despliegue local/edge cuando lleguen tamaños Qwen3‑VL más pequeños (como ocurrió con Qwen2.5‑VL 72B/32B/7B/3B). (Simon Willison’s Weblog (opens in a new tab))
- “Thinking” ≠ siempre mejor: Las APIs de Qwen exponen modos thinking vs non‑thinking con distintos presupuestos de tokens y precios. Usa thinking de forma selectiva (p. ej., tareas multimodales largas/ambiguas). (AlibabaCloud (opens in a new tab))
- Cuidado con el coste de contexto: Los contextos de 256K–1M son potentes pero caros. Parte documentos/vídeo con criterio; apóyate en pre‑parsing (OCR/layout) y RAG para minimizar la carga del prompt. (GitHub (opens in a new tab))
- Agentic UX: Si necesitas automatización de UI a partir de capturas de pantalla o streams, las funciones de agente visual de Qwen3‑VL merecen un piloto—pero invierte en APIs de herramientas y guardarraíles robustos. (GitHub (opens in a new tab))
Inicio rápido (Transformers)
from transformers import Qwen3VLMoeForConditionalGeneration, AutoProcessor # HF >= 4.57
model_id = "Qwen/Qwen3-VL-235B-A22B-Instruct" # or ...-Thinking
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(model_id, dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
messages = [{"role": "user", "content": [
{"type": "image", "image": "https://.../app-screenshot.png"},
{"type": "text", "text": "What button should I tap to turn on dark mode? Explain briefly."}
]}]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(processor.batch_decode(outputs[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0])Esto refleja el ejemplo de la model card de Qwen (activa FlashAttention‑2 si está disponible). Para multi‑image o video, pasa múltiples entradas {"type": "image"} o un elemento {"type": "video"} con controles de frames/píxeles como se muestra en el repo. (Hugging Face (opens in a new tab))
Escollos y gotchas comunes
- Naming drift: “Qwen3‑VL‑Plus” (API) vs. “Qwen‑VL‑Plus” (línea de pesos abiertos anterior) no son lo mismo. Revisa la documentación de Model Studio y la página de HF que realmente estás cargando. (Hacker News (opens in a new tab))
- Memory illusions: El 235B MoE tiene pesos abiertos, pero “MoE” no lo hace pequeño para inferencia. Presupuesta memoria y ancho de banda en consecuencia. La comunidad sitúa los pesos alrededor de 471 GB. (Simon Willison’s Weblog (opens in a new tab))
- Leaderboards autoinformados: Trata los gráficos de marketing como hipótesis. Repite tus propias evals—especialmente para charts/tablas, documentos y video QA.
Preguntas frecuentes
Q: ¿Qué significa “A22B” en Qwen3‑VL‑235B‑A22B? A: Es un modelo Mixture‑of‑Experts con ~235B parámetros y ~22B activos por token—intercambia eficiencia de cómputo por capacidad. (Qwen (opens in a new tab))
Q: Instruct vs Thinking—¿cuándo elegir cada uno? A: Instruct está alineado para uso general y suele ser más rápido/barato. Thinking añade trazas de razonamiento internas (la API expone “thinking mode”), lo que puede ayudar en tareas composicionales o de largo horizonte, pero cuesta más tokens. Prueba ambos en tu conjunto de eval. (Hugging Face (opens in a new tab))
Q: ¿Realmente es “mejor que Gemini 2.5 Pro”? A: Qwen afirma victorias en ciertos benchmarks de percepción y SOTA en varias tareas multimodales, pero son resultados autoinformados. Las comparaciones independientes llevarán tiempo—sigue las evals de la comunidad y tus pruebas específicas de dominio. (Simon Willison’s Weblog (opens in a new tab))
Q: ¿Puedo ejecutarlo localmente? A: Solo si tienes hardware serio (multi‑GPU con mucha RAM). La mayoría usará inferencia alojada primero (p. ej., OpenRouter, Model Studio). Para pruebas locales más pequeñas, considera tamaños anteriores de Qwen2.5‑VL (72B/32B/7B/3B) hasta que lleguen variantes más pequeñas de Qwen3‑VL. (OpenRouter (opens in a new tab))
Q: ¿Cuál es la situación de la licencia? A: Los pesos liberados de Qwen3‑VL‑235B‑A22B están bajo Apache‑2.0 según las model cards de HF. Confirma siempre la licencia del checkpoint específico. (Hugging Face (opens in a new tab))
Q: ¿Por qué los investigadores siguen eligiendo Qwen? A: Pesos abiertos en varios tamaños, licenciamiento permisivo y fuerte capacidad multilingüe—además de muchos ejemplos de fine‑tuning basado en Qwen en la literatura (p. ej., BioQwen, long‑CoT model merging, medical VQA con RL‑tuning partiendo de Qwen2.5). (ciblab.net (opens in a new tab))
Reacción de la comunidad y discusión
El hilo en Hacker News sacó rápidamente a relucir la confusión de nombres (Qwen3‑VL‑Plus vs snapshots como qwen-plus-2025-09-11) y preguntas prácticas de despliegue, pero también entusiasmo por el ritmo de lanzamientos de pesos abiertos. Es una buena ventana al sentir de los early adopters. (Hacker News (opens in a new tab))
Para un resumen conciso desde la comunidad de desarrolladores, consulta la nota de Simon Willison—útil para una comprobación de cordura sobre el tamaño del modelo y la probable cadencia de seguimientos más pequeños. (Simon Willison’s Weblog (opens in a new tab))
Conclusión
Qwen3‑VL eleva el listón de los modelos multimodales de pesos abiertos al ir más allá de “reconocer esta imagen” hacia razonar‑y‑actuar en imágenes, documentos y vídeos—y aterriza en un stack abierto familiar (Transformers). Para investigación, es un nuevo baseline obvio. Para equipos de producto, el insignia es demasiado grande para que la mayoría lo autohospede hoy, pero es valioso de inmediato vía APIs—especialmente para inteligencia documental, comprensión de pantallas y video QA. Espera el verdadero punto de inflexión cuando lleguen tamaños Qwen3‑VL más pequeños siguiendo el patrón de Qwen2.5.
Referencias y lecturas adicionales
- Repositorio: QwenLM/Qwen3‑VL — features, notas de arquitectura, cookbooks, registro de lanzamientos. (GitHub (opens in a new tab))
- Model cards: Instruct y Thinking (Apache‑2.0), con quickstarts y gráficos de rendimiento. (Hugging Face (opens in a new tab))
- Documentación de Transformers: integración de Qwen3‑VL. (Hugging Face (opens in a new tab))
- Visión general de Qwen3 y tamaños MoE (explicación de A22B, línea de pesos abiertos). (Qwen (opens in a new tab))
- Debate en HN: impresiones de la comunidad y confusión de nombres. (Hacker News (opens in a new tab))
- API/precios: Alibaba Cloud Model Studio (thinking vs non‑thinking, presupuestos de tokens). (AlibabaCloud (opens in a new tab))
- Ejemplos de investigación usando Qwen: BioQwen; RCP‑Merging; medical VQA con RL‑tuning sobre bases Qwen2.5. (ciblab.net (opens in a new tab))