Top 9 bibliothèques DataFrame open-source pour Python

Python s'est imposé comme le langage de prédilection pour les développeurs et les passionnés de données. Une raison clé de sa popularité dans le traitement des données est son vaste écosystème de bibliothèques, notamment celles axées sur les DataFrames. Ces structures puissantes, semblables à des tableaux, facilitent la manipulation et l'analyse des données structurées, les rendant indispensables pour quiconque travaille avec des ensembles de données.
Si vous avez déjà utilisé Python pour l'analyse de données, vous avez probablement rencontré Pandas, la bibliothèque DataFrame la plus connue et la plus appréciée. Mais à mesure que les données deviennent plus volumineuses et plus complexes, de nouvelles bibliothèques ont émergé pour relever les défis de l'échelle, de la vitesse et des performances. Dans cet article, nous explorerons certaines des bibliothèques DataFrame open-source les plus populaires en Python, chacune offrant des fonctionnalités uniques pour vous aider à tirer le meilleur parti de vos données.
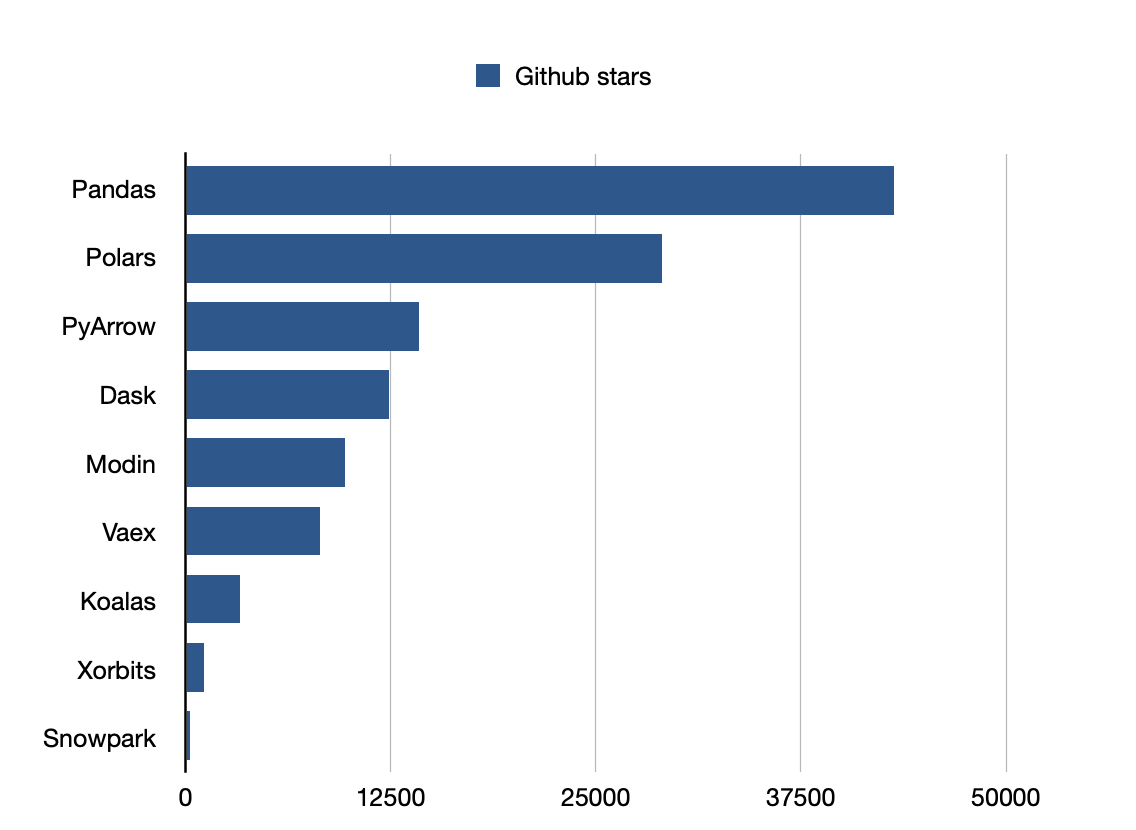
Pandas est la bibliothèque la plus populaire.
1. Pandas : Le vétéran de la science des données
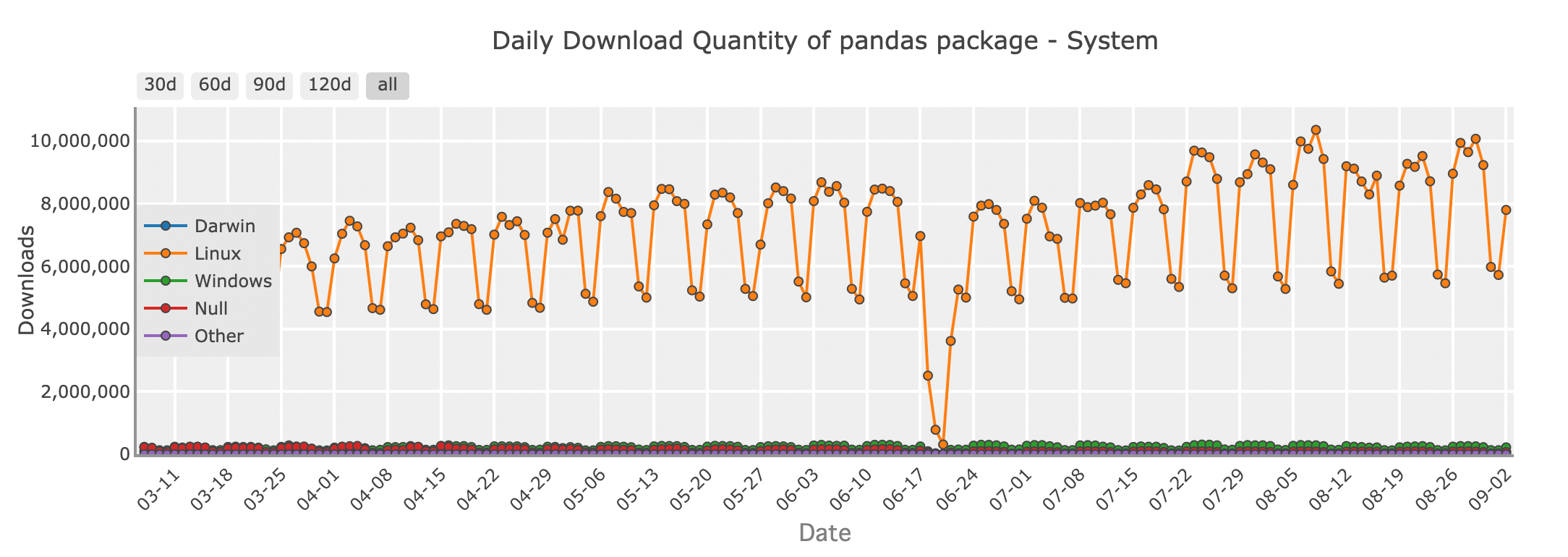
Quantité de téléchargements quotidiens du package Pandas - système
Pour de nombreux développeurs Python, Pandas est la première bibliothèque qui vient à l'esprit lorsqu'il s'agit de travailler avec des DataFrames. Son ensemble riche de fonctionnalités et son API intuitive rendent facile le chargement, la manipulation et l'analyse des données. Que vous nettoyiez un jeu de données désordonné, fusionniez des données de plusieurs sources ou effectuiez une analyse statistique, Pandas vous fournit tous les outils nécessaires dans un format familier, semblable à une feuille de calcul.
import pandas as pd
# Création d'un DataFrame
data = {
'Nom': ['Amy', 'Bob', 'Cat', 'Dog'],
'Âge': [31, 27, 16, 28],
'Département': ['RH', 'Ingénierie', 'Marketing', 'Ventes'],
'Salaire': [70000, 80000, 60000, 75000]
}
df = pd.DataFrame(data)
# Afficher le DataFrame
print(df)Pandas excelle dans la gestion des jeux de données petits à moyens qui tiennent confortablement dans la mémoire de votre ordinateur. C'est parfait pour les tâches quotidiennes de données, de l'exploration de données dans les notebooks Jupyter à la création de pipelines plus complexes en production. Cependant, à mesure que vos ensembles de données augmentent, Pandas peut montrer ses limites. C'est là que d'autres bibliothèques DataFrame entrent en jeu.
Github stars: 43200
2. Modin : Porter Pandas à de nouveaux sommets
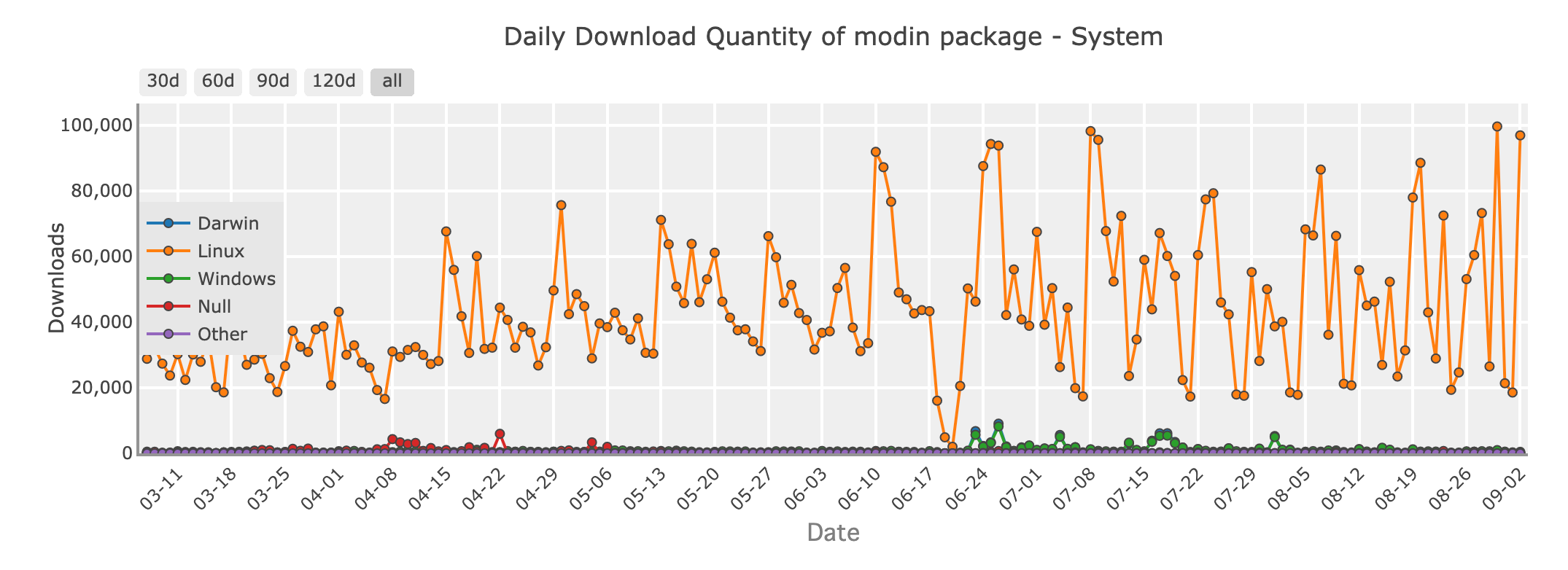
Quantité de téléchargements quotidiens du package Modin - système
Imaginez travailler avec un jeu de données trop volumineux pour que Pandas le gère efficacement. Vous ne voulez pas réécrire tout votre code, mais vous avez besoin de plus de vitesse et de scalability. Entrez Modin, une bibliothèque conçue pour rendre votre code Pandas plus rapide, sans nécessiter de changements majeurs.
Modin est un remplacement direct pour Pandas, ce qui signifie que vous pouvez prendre votre code Pandas existant et le paralléliser simplement en changeant la déclaration d'importation. En coulisses, Modin utilise des frameworks puissants comme Ray ou Dask pour distribuer vos calculs sur plusieurs cœurs ou même un cluster de machines. Il apporte des temps de traitement plus rapides pour vos opérations de données.
Avec Modin, vous obtenez l'API Pandas familière que vous aimez, mais avec la capacité de gérer des ensembles de données plus volumineux et de tirer pleinement parti de votre matériel.
Github stars: 9700
3. Polars : Vitesse et efficacité redéfinies
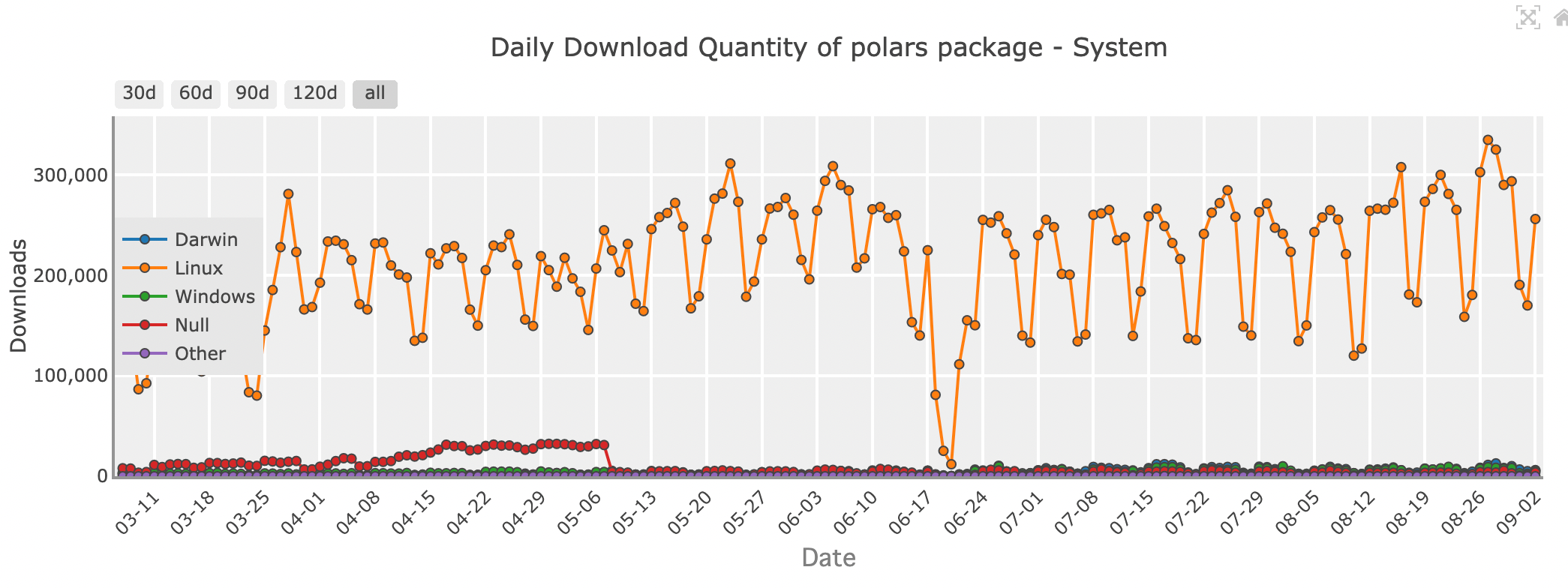
Quantité de téléchargements quotidiens du package Polars - système
En matière de vitesse brute et d'efficacité, Polars fait sensation dans la communauté des sciences des données. Écrit en Rust, un langage de programmation connu pour ses performances et sa sécurité, Polars est conçu pour être rapide - vraiment rapide. Si vous gérez de grands ensembles de données ou devez effectuer rapidement des opérations complexes, Polars pourrait être la bibliothèque qu'il vous faut.
Polars utilise une technique appelée évaluation paresseuse, où les opérations ne sont exécutées que lorsque cela est absolument nécessaire. Cela lui permet d'optimiser l'ensemble du pipeline de calcul, minimisant ainsi le temps et les ressources nécessaires. De plus, Polars est conçu avec le multi-threading à l'esprit, il peut donc utiliser efficacement tous les cœurs de votre machine, ce qui en fait un choix idéal pour les tâches critiques en termes de performances.
Bien que Polars offre une vitesse impressionnante, il présente une courbe d'apprentissage. Son API est différente de celle de Pandas, il peut donc falloir un certain temps pour s'habituer. Cependant, pour ceux qui sont prêts à investir du temps, Polars offre des performances inégalées et la capacité de gérer des jeux de données qui ne seraient pas réalisables avec d'autres bibliothèques.
Github stars: 29000
| Caractéristique/Aspect | Pandas | Modin | Polars |
|---|---|---|---|
| Architecture | Mono-thread, Python/Cython | Multi-thread, distribué (Ray/Dask) | Multi-thread, écrit en Rust |
| Performances | Bon pour petits à moyens jeux de données | S'étend sur plusieurs cœurs ou clusters | Extrêmement rapide, gère de grands jeux de données |
| Utilisation de la mémoire | Haute utilisation de la mémoire | Similaire à Pandas | Faible utilisation de la mémoire, support hors-noyau |
| Facilité d'utilisation | Très facile, vaste support communautaire | Transition facile depuis Pandas | Intuitif mais API différente |
| Écosystème | Mature, bien intégré à d'autres bibliothèques | Compatible avec l'écosystème Pandas | Écosystème plus petit mais en croissance |
| Cas d'utilisation | Petits à moyens jeux de données, manipulation des données | Grands jeux de données, mise à l'échelle des opérations Pandas | Calculs à haute performance, grands jeux de données |
| Installation | pip install pandas | pip install modin[all] | pip install polars |
4. Dask : Un DataFrame distribué pour les Big Data
Quantité de téléchargements quotidiens du package Dask - système
Lorsque vos données deviennent si volumineuses qu'elles ne tiennent plus en mémoire, Dask peut servir comme un puissant assistant. Dask est une bibliothèque de calcul parallèle qui étend l'API Pandas pour gérer des jeux de données trop grands pour une seule machine.
Dask fonctionne en divisant votre DataFrame géant en morceaux plus petits et en les traitant en parallèle, soit sur votre machine locale, soit sur un cluster. Cela vous permet d'échelonner vos calculs sans vous soucier de manquer de mémoire. Que vous travailliez avec de grandes données ou que vous construisiez des pipelines de données nécessitant des milliers de tâches, Dask offre la flexibilité et la puissance dont vous avez besoin.
Github stars: 12400
5. PyArrow : Échange rapide de données avec Apache Arrow
Quantité de téléchargements quotidiens du package PyArrow - système
Dans le domaine de l'ingénierie des données, PyArrow brille comme une bibliothèque cruciale pour l'échange de données efficace entre différents systèmes. Construit sur le format Apache Arrow, PyArrow offre un format mémoire colonne qui permet des lectures sans copie pour de grands ensembles de données. Cela en fait un choix parfait pour les scénarios où performance et interopérabilité sont clés.
PyArrow est largement utilisé pour permettre le transfert rapide de données entre des langages comme Python, R et Java, et joue un rôle central dans de nombreux cadres de traitement de big data. Si vous traitez des pipelines de données à grande échelle, en particulier là où les données doivent être partagées entre différents outils ou plateformes, PyArrow est un outil précieux dans votre arsenal.
Github stars: 14200
6. Snowpark : DataFrames dans le Cloud avec Snowflake
Quantité de téléchargements quotidiens du package Snowpark - système
À mesure que de plus en plus d'organisations déplacent leurs opérations de données vers le cloud, Snowpark émerge comme une solution innovante pour les développeurs Python. Snowpark est une fonctionnalité de Snowflake, un entrepôt de données basé sur le cloud, qui vous permet d'utiliser des opérations de type DataFrame directement dans l'environnement Snowflake. Cela signifie que vous pouvez effectuer des transformations de données et des analyses complexes sans déplacer vos données hors de Snowflake, réduisant ainsi la latence et augmentant l'efficacité.
Avec Snowpark, vous pouvez écrire du code Python qui s'exécute nativement sur l'infrastructure de Snowflake, tirant parti de la puissance du cloud pour traiter facilement des ensembles de données massifs. C'est un excellent choix pour les équipes utilisant déjà Snowflake et cherchant à rationaliser leurs flux de traitement des données.
Github stars: 253
7. Xorbits : Une solution unifiée pour l'échelle des sciences des données
Quantité de téléchargements quotidiens du package Xorbits - système
Xorbits est un cadre puissant conçu pour échelonner les opérations de science des données dans des environnements distribués. Il offre une API unifiée qui abstrait les complexités de l'informatique distribuée, vous permettant d'échelonner vos opérations DataFrame sur plusieurs nœuds sans avoir à vous soucier de l'infrastructure sous-jacente.
Xorbits s'intègre facilement aux outils existants comme Pandas, Dask et PyTorch, en faisant un choix idéal pour les applications de machine learning et de science des données nécessitant de la flexibilité. Que vous formiez de grands modèles ou que vous traitiez d'énormes quantités de données, Xorbits offre la flexibilité et la puissance nécessaires pour accomplir la tâche.
Github stars: 1100
8. Vaex : DataFrames hors mémoire pour une analyse efficace
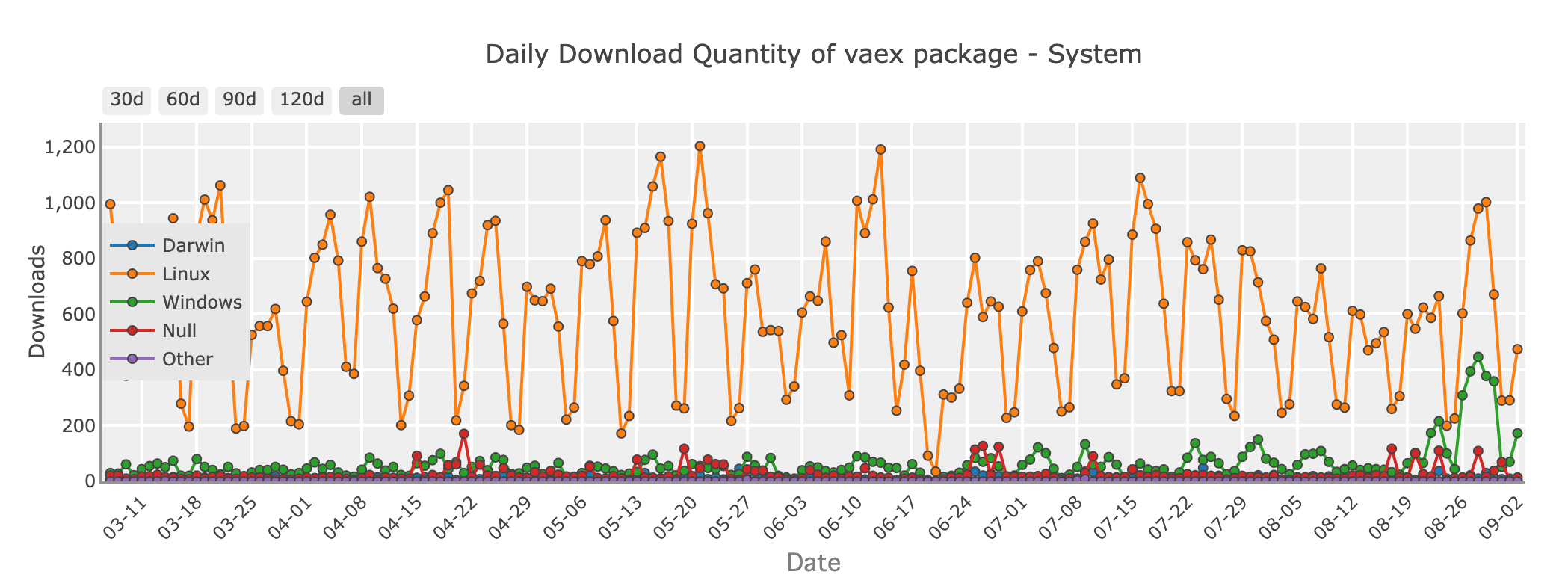
Quantité de téléchargements quotidiens du package Vaex - système
Si vous traitez avec des jeux de données énormes qui dépassent la mémoire de votre système mais que vous souhaitez conserver la simplicité de Pandas, Vaex mérite d'être exploré. Vaex est conçu pour le calcul hors mémoire, ce qui signifie qu'il peut gérer les jeux de données plus grands que votre RAM en traitant les données par morceaux, sans tout charger en mémoire à la fois.
Vaex est optimisé pour la vitesse et offre des fonctionnalités telles que le filtrage rapide, le regroupement et l'agrégation, tout en minimisant l'utilisation de la mémoire. Il est particulièrement utile pour des tâches telles que l'exploration de données, l'analyse statistique et même le machine learning sur de grands ensembles de données.
Github stars: 8200
9. Koalas : Apporter Pandas au Big Data avec Apache Spark
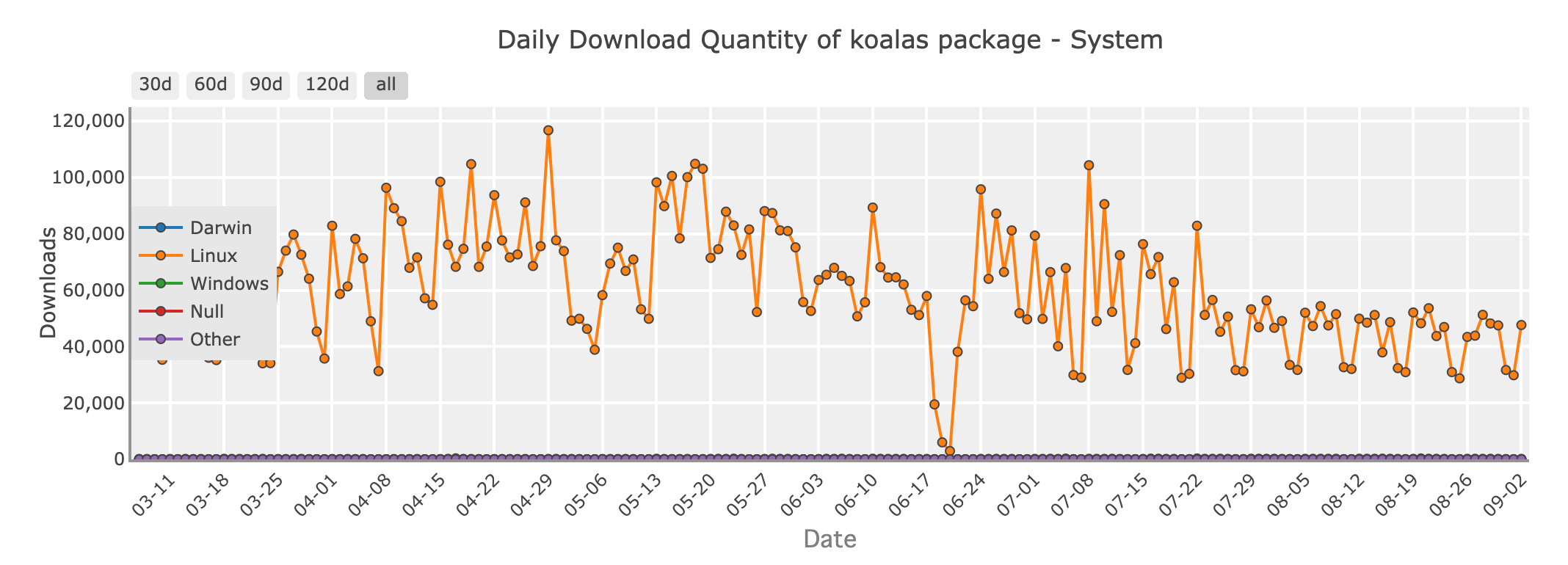
Quantité de téléchargements quotidiens du package Koalas - système
Pour les développeurs Python travaillant dans le monde du big data, Apache Spark est un nom familier. Koalas est une bibliothèque qui connecte Pandas à Spark, vous permettant d'utiliser une syntaxe semblable à Pandas sur des jeux de données distribués gérés par Spark. Cela signifie que vous pouvez tirer parti de la scalabilité de Spark tout en écrivant du code qui ressemble à Pandas.
Koalas est une excellente option si vous passez de Pandas à des environnements de big data, car il minimise la courbe d'apprentissage associée à Spark et vous permet d'écrire du code qui s'adapte sans perdre la simplicité de Pandas.
Github stars: 3300
Choisir le bon outil pour le travail
Avec tant d'options disponibles, comment choisir la bonne bibliothèque DataFrame pour votre projet ? Voici quelques lignes directrices :
- Petits à moyens jeux de données : Si vos données tiennent confortablement en mémoire, Pandas reste le meilleur choix pour sa facilité d'utilisation et ses fonctionnalités riches.
- Scalabilité de Pandas : Si vous atteignez des goulots d'étranglement de performance avec Pandas, mais que vous ne voulez pas changer votre code, Modin offre une voie facile pour une exécution plus rapide.
- Tâches critiques en termes de performance : Pour des besoins de haute performance et de grands ensembles de données, Polars offre une vitesse impressionnante et une efficacité en raison de son design léger, ce qui le rend particulièrement efficace sur les appareils locaux. Cependant, il est important de noter que Polars n'est pas principalement conçu pour le traitement de données distribuées à grande échelle, où des solutions comme Modin pourraient être plus appropriées.
- Big Data et informatique distribuée : Lorsque vous travaillez avec de grosses données, Dask, Koalas et Xorbits sont d'excellents choix pour échelonner vos calculs sur plusieurs machines.
- Interopérabilité et partage de données : Si vous avez besoin d'un échange efficace de données entre différents systèmes ou langages, PyArrow est la bibliothèque à utiliser.
- Opérations basées sur le cloud : Pour