Visualisation avec Pandas : un tutoriel étape par étape
- Name
- Rajiv Chandra
Mis à jour le
La bibliothèque Pandas de Python est un outil puissant utilisé quotidiennement par les data scientists et les analystes du monde entier. L'une de ses fonctionnalités les plus convaincantes est ses capacités de visualisation des données. Cet article vous guidera à travers le processus de création de graphiques convaincants à l'aide de Pandas, vous fournissant les compétences nécessaires pour transformer des données brutes en graphiques significatifs.
La création de graphiques avec Pandas ne consiste pas seulement à rendre vos données jolies. Il s'agit de révéler les histoires cachées derrière les chiffres. Que vous exploriez un nouvel ensemble de données ou que vous vous prépariez à partager vos dernières découvertes, les visualisations sont essentielles pour communiquer des informations basées sur les données.
Absolument, plongeons plus en profondeur dans chaque segment avec des explications détaillées et des extraits de code d'exemple.
Utiliser la fonction plot pour la visualisation avec Pandas
Pandas fournit une structure de données de haut niveau, flexible et efficace appelée DataFrame, qui est extrêmement propice à la visualisation. Avec la fonction .plot(), vous pouvez générer une variété d'histogrammes tels que des lignes, des barres, des points, etc. Cette fonction est un enveloppe de la bibliothèque polyvalente Matplotlib, ce qui facilite la création de visualisations complexes.
Par exemple, si vous commencez tout juste votre parcours avec Pandas, vous créerez bientôt des graphiques basiques à ligne qui peuvent révéler des tendances précieuses dans vos données. Les graphiques à ligne sont excellents pour mettre en valeur les données au fil du temps, ce qui les rend parfaits pour l'analyse des séries chronologiques.
Voici un exemple simple de création d'un graphique à ligne avec Pandas :
import pandas as pd
import numpy as np
# Créer un DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
df.plot(kind='line')Dans ce code, nous importons d'abord les bibliothèques nécessaires. Ensuite, nous créons un DataFrame avec deux colonnes, chacune remplie de nombres aléatoires. Enfin, nous utilisons la fonction .plot() pour créer un graphique à ligne.
Mais que faire si vous voulez utiliser une interface visuelle pour tracer des DataFrame Pandas sans écrire de code ? Eh bien, heureusement, il existe un DataFrame Pandas qui peut vous aider à résoudre le problème :
Utiliser PyGWalker pour la visualisation avec Pandas
PyGWalker est une bibliothèque Python conçue pour l'analyse exploratoire des données et la visualisation facile des données. Pensez-y comme si vous exécutiez un tableau open source dans votre notebook Jupyter. Vous pouvez facilement créer des visualisations en faisant glisser et déposer des variables au lieu de consulter des tutoriels de programmation complexes :
Voici comment vous pouvez rapidement commencer :
Importez pygwalker et pandas dans votre notebook Jupyter pour commencer.
import pandas as pd
import pygwalker as pygVous pouvez utiliser pygwalker sans interrompre votre flux de travail existant. Par exemple, vous pouvez appeler Graphic Walker avec le dataframe chargé de cette manière :
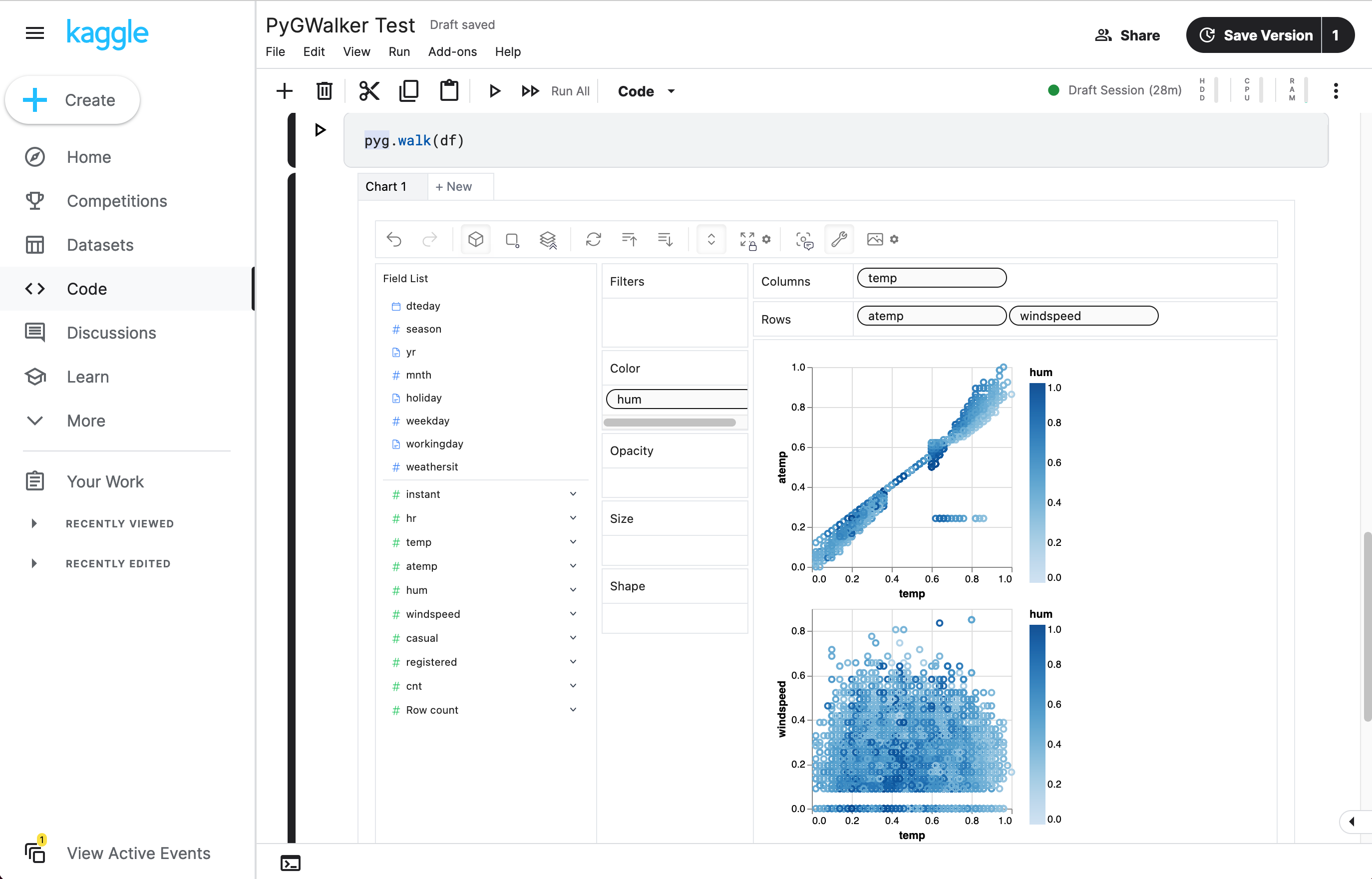
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Et vous pouvez utiliser pygwalker avec polars (depuis pygwalker>=0.1.4.7a0):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Maintenant, vous avez chargé votre DataFrame Pandas pour la visualisation.
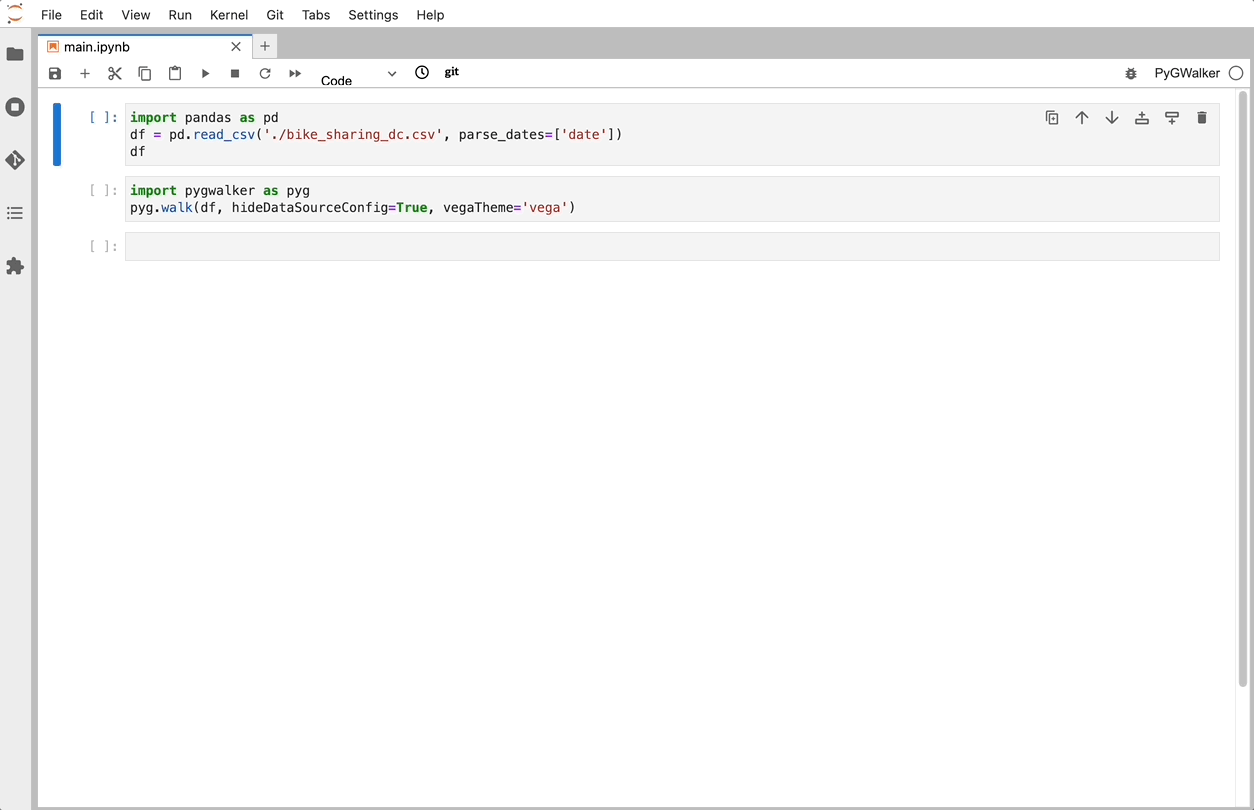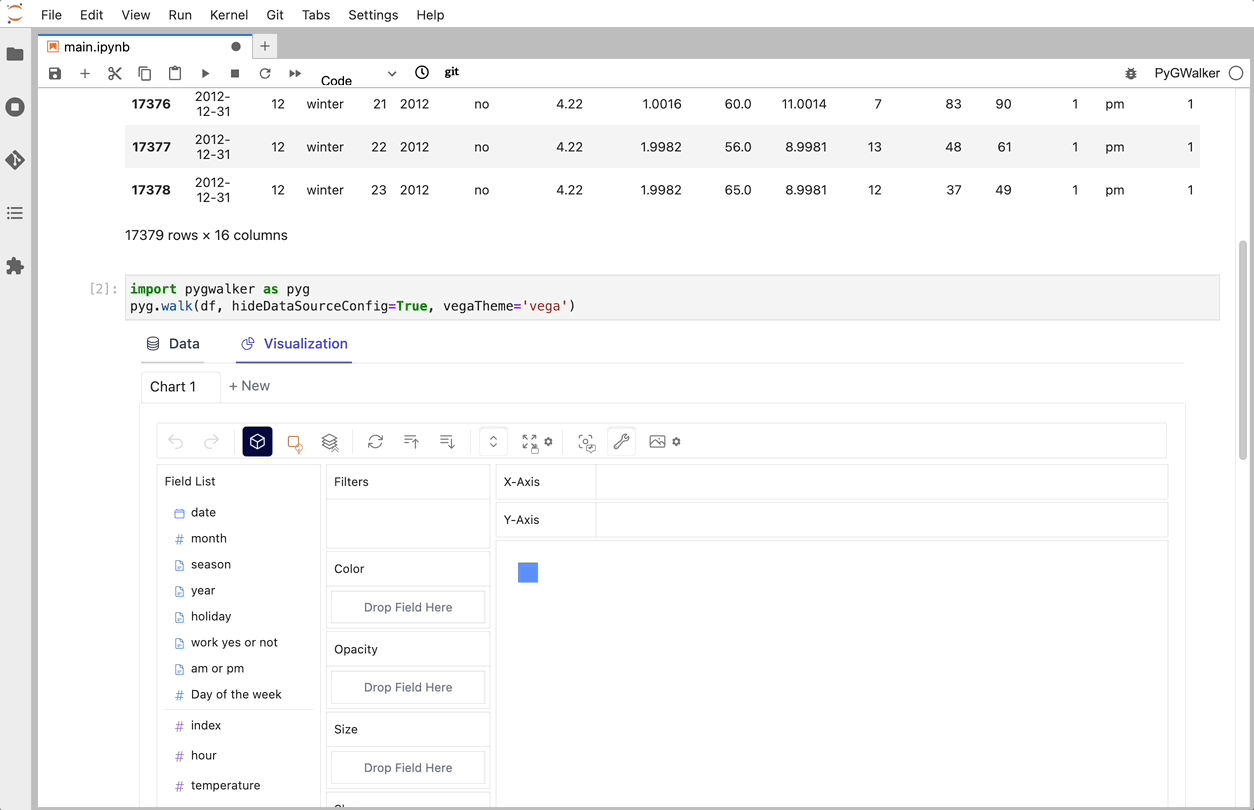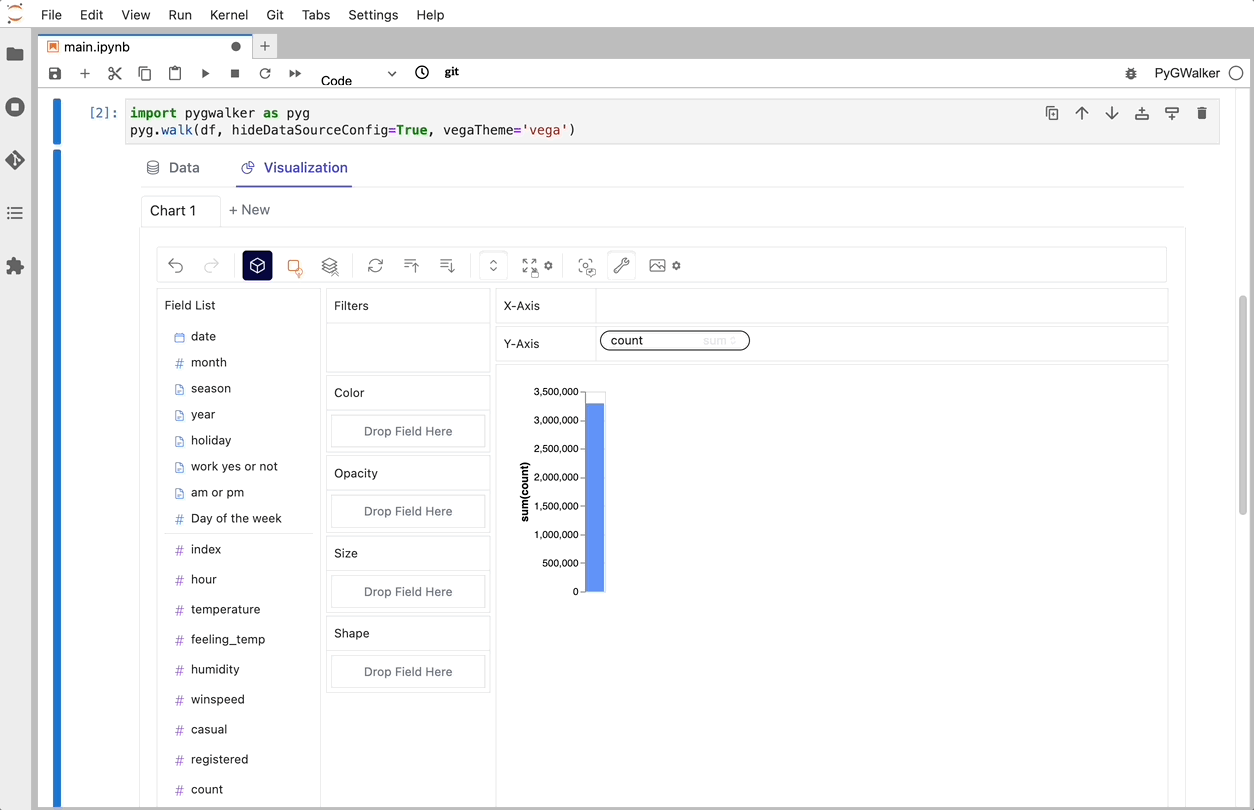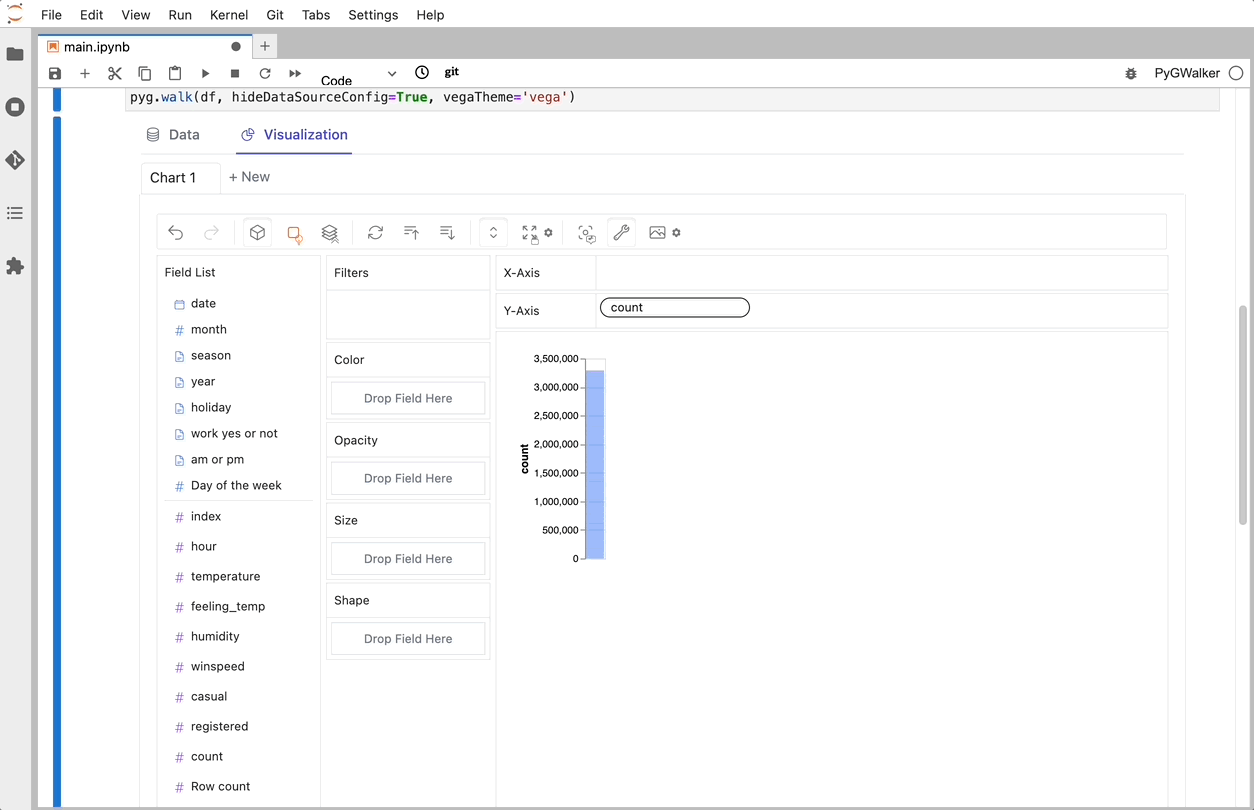
C'est tout. Maintenant, vous disposez d'une interface utilisateur similaire à celle de Tableau pour analyser et visualiser des données en faisant glisser et déposer des variables.
PyGWalker est soutenu par une communauté active de développeurs et de data scientists. Visitez PyGWalker GitHub (opens in a new tab) et laissez une ⭐️ !
Vous pouvez essayer PyGWalker dès maintenant avec Google Colab ou Kaggle Notebook :
| Exécuter dans Kaggle (opens in a new tab) | Exécuter dans Colab (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 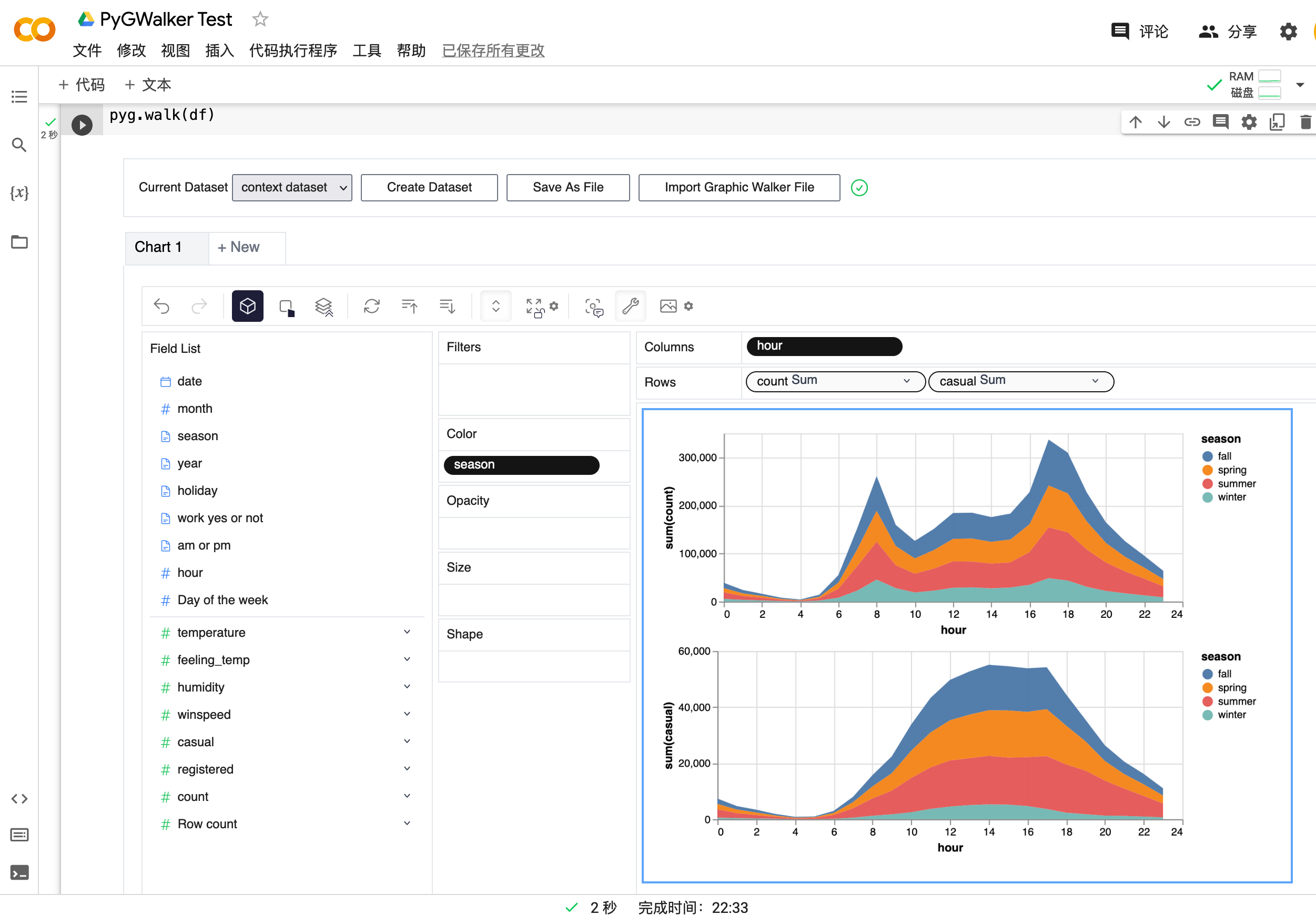 (opens in a new tab) (opens in a new tab) |
Approfondir les différents types de graphiques
Pandas propose une variété de types de graphiques, chacun adapté à différents types de données et à différentes questions. Par exemple, les histogrammes sont excellents pour avoir un aperçu de la distribution de vos données, tandis que les diagrammes de dispersion peuvent vous aider à découvrir des corrélations entre différentes données.
Chaque type de graphique dans Pandas est accompagné d'un ensemble de paramètres que vous pouvez ajuster pour personnaliser votre visualisation. Comprendre ces paramètres et quand les utiliser peut grandement améliorer votre capacité à créer des visualisations significatives.
Voici comment vous pouvez créer un histogramme et un diagramme de dispersion :
# Histogramme
df['A'].plot(kind='hist')
# Diagramme de dispersion
df.plot(kind='scatter', x='A', y='B')Dans le premier graphique, nous créons un histogramme de la colonne 'A'. Dans le deuxième graphique, nous créons un diagramme de dispersion avec 'A' sur l'axe des x et 'B' sur l'axe des y.
Gérer les données catégorielles avec Pandas
Les données catégorielles sont un type de données courant que vous rencontrerez dans de nombreux ensembles de données. Pandas fournit plusieurs outils puissants pour visualiser ce type de données. Par exemple, les graphiques à barres peuvent vous aider à comparer différentes catégories, tandis que les graphiques en secteurs sont excellents pour visualiser les ratios entre les catégories.
De plus, Pandas vous permet de regrouper vos données en fonction des catégories, ce qui peut être extrêmement utile lorsque vous souhaitez regrouper vos données et tirer des enseignements au niveau des catégories.
Voici un exemple de création d'un graphique à barres et d'un graphique en secteurs :
# Créer un DataFrame avec des données catégorielles
df = pd.DataFrame({
'Fruit': ['Pomme', 'Banane', 'Cerise', 'Pomme', 'Cerise', 'Banane', 'Pomme', 'Cerise', 'Banane', 'Pomme'],
'Compte': np.random.randint(1, 10, 10)
})
# Graphique à barres
df.groupby('Fruit')['Compte'].sum().plot(kind='bar')
# Graphique circulaire
df.groupby('Fruit')['Compte'].sum().plot(kind='pie')Dans ce code, nous créons d'abord un DataFrame avec des données catégoriques. Ensuite, nous regroupons les données selon la colonne 'Fruit' et nous additionnons les 'Compte' pour chaque fruit. Enfin, nous créons un graphique à barres et un graphique circulaire des compteurs cumulés.
Personnalisation de vos graphiques
Une des fonctionnalités les plus puissantes de la visualisation avec Pandas est la possibilité de personnaliser vos graphiques. Cela inclut le changement de couleur et de style de vos graphiques, l'ajout d'étiquettes et de titres, et bien plus encore.
Voici un exemple de personnalisation d'un graphique en ligne :
# Création d'un DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
# Création d'un graphique en ligne avec des personnalisations
df.plot(kind='line',
color=['red', 'blue'],
style=['-', '--'],
title='Mon graphique en ligne',
xlabel='Index',
ylabel='Valeur')Dans ce code, nous créons d'abord un DataFrame avec deux colonnes, chacune remplie de chiffres aléatoires. Ensuite, nous créons un graphique en ligne et nous le personnalisons en définissant la couleur et le style des lignes, ainsi qu'un titre et des étiquettes pour les axes x et y.
Gestion de structures de données plus complexes
Pandas n'est pas limité à la manipulation de structures de données simples. Il peut également gérer des structures de données plus complexes telles que des DataFrames à index multiples et des séries temporelles.
Voici un exemple de création d'un graphique en ligne à partir d'un DataFrame à index multiples :
# Création d'un DataFrame à index multiples
index = pd.MultiIndex.from_tuples([(i,j) for i in range(5) for j in range(5)])
df = pd.DataFrame({
'A': np.random.rand(25),
'B': np.random.rand(25)
}, index=index)
# Création d'un graphique en ligne
df.plot(kind='line')Dans ce code, nous créons d'abord un DataFrame à index multiples avec deux colonnes, chacune remplie de chiffres aléatoires. Ensuite, nous créons un graphique en ligne à partir de ce DataFrame.
Visualisation avancée avec Seaborn
Bien que Pandas offre une base solide pour la visualisation de données, il arrive parfois que vous ayez besoin d'outils plus avancés. Seaborn est une bibliothèque de visualisation de données en Python basée sur Matplotlib qui offre une interface de haut niveau pour créer des visualisations belles et informatives.
Voici un exemple de création d'un graphique Seaborn à partir d'un DataFrame Pandas :
import seaborn as sns
# Chargement de votre DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Création d'un graphique Seaborn
sns.lineplot(data=df, x='date', y='count')Dans ce code, nous importons d'abord la bibliothèque Seaborn. Ensuite, nous chargeons un DataFrame et créons un graphique en ligne avec la colonne 'date' sur l'axe des x et la colonne 'count' sur l'axe des y.
Visualisation interactive avec Plotly
Pour des visualisations interactives, Plotly est un excellent choix. Plotly est une bibliothèque de graphiques en Python qui permet de créer des graphiques interactifs de qualité publication.
Voici un exemple de création d'un graphique Plotly à partir d'un DataFrame Pandas :
import plotly.express as px
# Chargement de votre DataFrame
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Création d'un graphique Plotly
fig = px.line(df, x='date', y='count')
fig.show()Dans ce code, nous importons d'abord le module Plotly Express. Ensuite, nous chargeons un DataFrame et créons un graphique en ligne avec la colonne 'date' sur l'axe des x et la colonne 'count' sur l'axe des y. La commande fig.show() affiche le graphique interactif.
Conclusion
Pandas est un outil puissant pour l'analyse de données et la visualisation en Python. Avec ses capacités de tracé robustes et sa compatibilité avec d'autres bibliothèques de visualisation telles que Matplotlib, Seaborn, Plotly et PyGWalker, vous pouvez créer une large gamme de visualisations pour obtenir des informations à partir de vos données. Que vous soyez débutant ou expérimenté en science des données, maîtriser la visualisation avec Pandas est une compétence précieuse qui améliorera votre flux de travail d'analyse de données.
FAQ
-
Qu'est-ce que Pandas en Python ?
- Pandas est une bibliothèque logicielle écrite pour le langage de programmation Python destinée à la manipulation et à l'analyse de données. Elle fournit des structures de données et des fonctions nécessaires pour manipuler des données structurées.
-
Comment utilise-t-on Pandas pour la visualisation de données ?
- Pandas fournit la visualisation de données en permettant l'utilisation de sa fonction plot() et de différentes méthodes de tracé pour représenter graphiquement des données directement à partir d'objets DataFrame et Series.
-
Quelles sont certaines des bibliothèques de visualisation de données les plus populaires dans Pandas ?
- Certaines des bibliothèques les plus populaires pour la visualisation de données dans Pandas comprennent Matplotlib, Seaborn, Plotly et PyGWalker. Ces bibliothèques offrent une variété d'outils et de fonctionnalités pour créer des graphiques statiques, animés et interactifs en Python.